
遗传算法计算异面直线之间的最短距离
为什么想做这个项目
- 偶然在网上看到了遗传算法的相关概念,结合自身近期在学习计算机有关知识,又因为高中时期对生物这门学科较感兴趣,且精通遗传相关知识,所以想尝试用代码实现这个算法。在思考解决什么问题的时候,也是废了很多心思去寻找一个相对简单问题来解决,所以也就找到了异面直线之间的最短距离这么一个普通方法不好计算的问题。
- 在网上找了许多资源,发现还是这个链接更为详细(https://www.jianshu.com/p/ae5157c26af9)
遗传算法的相关知识
科学定义
- 遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
- 其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
- 遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。
过程图解

编码方法
二进制编码
- 就像人类的基因有AGCT 4种碱基序列一样。不过在这里我们只用了0和1两种碱基,然后将他们串成一条链形成染色体。一个位能表示出2种状态的信息量,因此足够长的二进制染色体便能表示所有的特征。这便是二进制编码。如下:1110001010111
- 看起来较为复杂,但是也是有极大缺陷,因为只有0和1两个数字,改变一个就是改变了2的n次方,对于一些连续函数的优化问题,由于其随机性使得其局部搜索能力较差,如对于一些高精度的问题,当解迫近于最优解后,由于其变异后表现型变化很大,不连续,所以会远离最优解,达不到稳定,且以我目前的编程技术也很难做到完美实现,因此我介绍下一种方法。
浮点编码法
- 所谓浮点法,是指个体的每个基因值用某一范围内的一个浮点数来表示。在浮点数编码方法中,必须保证基因值在给定的区间限制范围内,遗传算法中所使用的交叉、变异等遗传算子也必须保证其运算结果所产生的新个体的基因值也在这个区间限制范围内。
如下所示:1.2-3.2-5.3-7.2-1.4-9.7 - 浮点数编码方法有下面几个优点:
- 适用于在遗传算法中表示范围较大的数
- 适用于精度要求较高的遗传算法
- 便于较大空间的遗传搜索
- 改善了遗传算法的计算复杂性,提高了运算交率
- 便于遗传算法与经典优化方法的混合使用
- 便于设计针对问题的专门知识的知识型遗传算子
- 便于处理复杂的决策变量约束条件
符号编码法
- 符号编码法是指个体染色体编码串中的基因值取自一个无数值含义、而只有代码含义的符号集如{A,B,C…}。在此我不做过多阐述。
接下来看代码实现
计算平方的函数
- 用于计算空间中两点之间的距离的平方

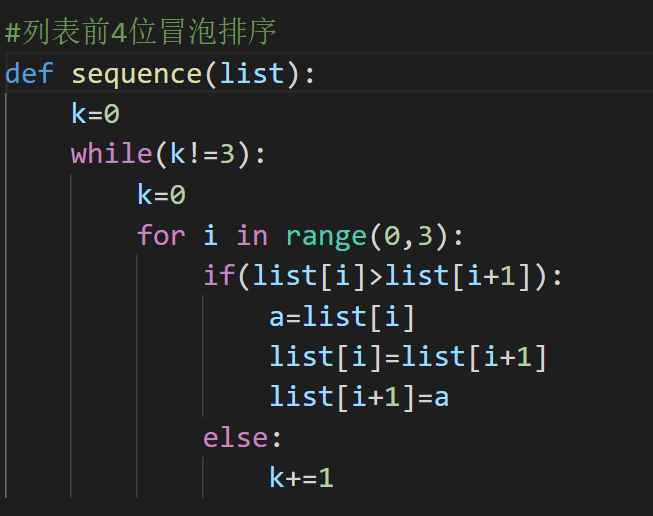
冒泡排序
- 因为学过冒泡排序的知识,我认为可以用来构造一个选择函数,所以在网上找到了这样的代码
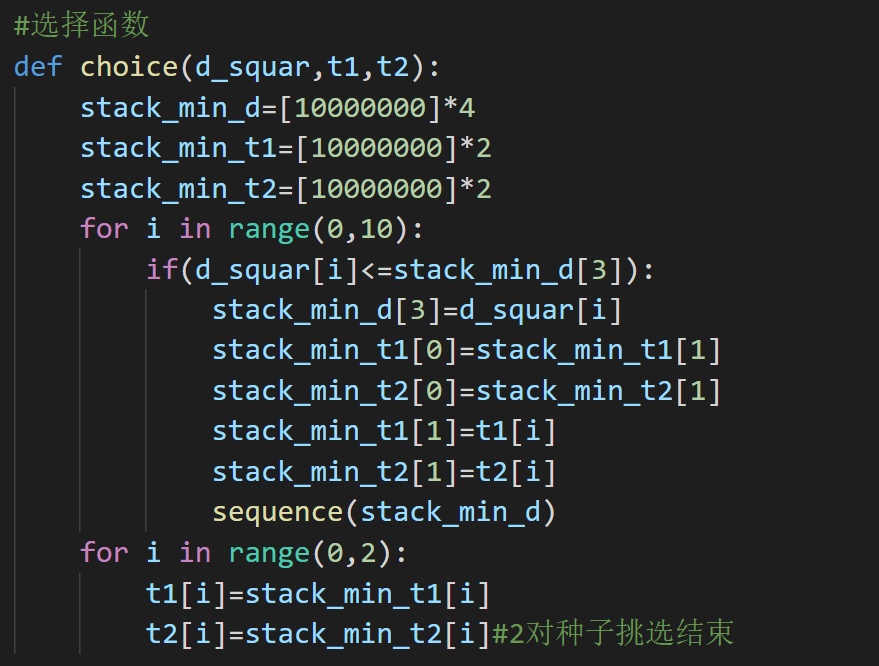
选择函数
基于上面的冒泡排序
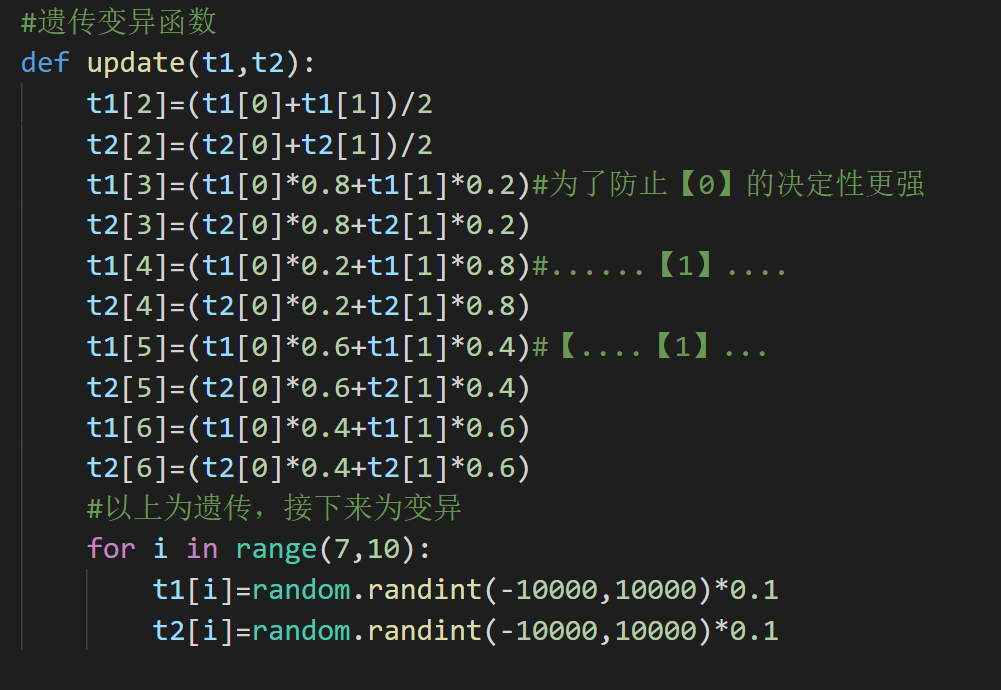
遗传变异函数
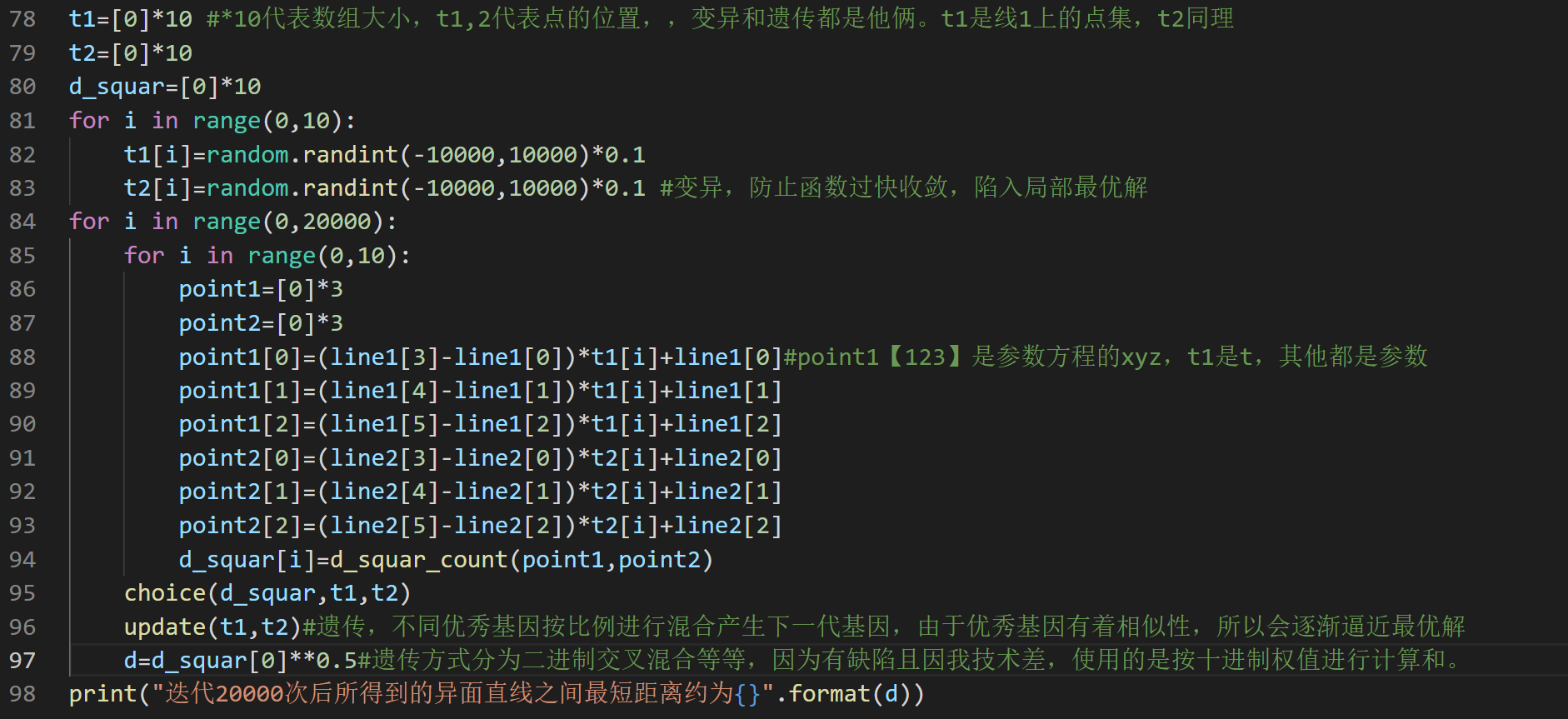
主要代码

运行截图
代码
import re,random
def d_squar_count(list1,list2):
d_squar=0
d_squar=(list2[0]-list1[0])2+(list2[1]-list1[1])2+(list2[2]-list1[2])**2
return d_squar
def sequence(list):
k=0
while(k!=3):
k=0
for i in range(0,3):
if(list[i]>list[i+1]):
a=list[i]
list[i]=list[i+1]
list[i+1]=a
else:
k+=1
def choice(d_squar,t1,t2):
stack_min_d=[10000000]4
stack_min_t1=[10000000]2
stack_min_t2=[10000000]*2
for i in range(0,10):
if(d_squar[i]<=stack_min_d[3]):
stack_min_d[3]=d_squar[i]
stack_min_t1[0]=stack_min_t1[1]
stack_min_t2[0]=stack_min_t2[1]
stack_min_t1[1]=t1[i]
stack_min_t2[1]=t2[i]
sequence(stack_min_d)
for i in range(0,2):
t1[i]=stack_min_t1[i]
t2[i]=stack_min_t2[i]#2对种子挑选结束
def update(t1,t2):
t1[2]=(t1[0]+t1[1])/2
t2[2]=(t2[0]+t2[1])/2
t1[3]=(t1[0]0.8+t1[1]0.2)
t2[3]=(t2[0]0.8+t2[1]0.2)
t1[4]=(t1[0]0.2+t1[1]0.8)
t2[4]=(t2[0]0.2+t2[1]0.8)
t1[5]=(t1[0]0.6+t1[1]0.4)
t2[5]=(t2[0]0.6+t2[1]0.4)
t1[6]=(t1[0]0.4+t1[1]0.6)
t2[6]=(t2[0]0.4+t2[1]0.6)
for i in range(7,10):
t1[i]=random.randint(-1000,1000)
t2[i]=random.randint(-1000,1000)
line1=[0]6
line2=[0]6
input_=input("请选择输入数据的方式,0为TXT输入,1为终端手动输入(文本输入只支持个位数作为坐标):")
if(input_=='0'):
file = open('yimian.txt','r')
s_=file.read()
s__=re.split('',s_)
for i in range(0,3):
line1[i]=int(s__[2i+1])
line1[i+3]=int(s__[2i+7])
line2[i]=int(s__[2i+13])
line2[i+3]=int(s__[2i+19])
else:
line1[0],line1[1],line1[2]=input("请输入第一条直线的第一个点坐标,空格隔开").split()
line1[3],line1[4],line1[5]=input("请输入第一条直线的第二个点坐标,空格隔开").split()
line2[0],line2[1],line2[2]=input("请输入第二条直线的第一个点坐标,空格隔开").split()
line2[3],line2[4],line2[5]=input("请输入第二条直线的第二个点坐标,空格隔开").split()
for i in range(0,6):
line1[i]=int(line1[i])
line2[i]=int(line2[i])
t1=[0]10
t2=[0]10
d_squar=[0]10
for i in range(0,10):
t1[i]=random.randint(-1000,1000)
t2[i]=random.randint(-1000,1000)
for i in range(0,200000):
for i in range(0,10):
point1=[0]3
point2=[0]3
point1[0]=(line1[3]-line1[0])t1[i]+line1[0]
point1[1]=(line1[4]-line1[1])t1[i]+line1[1]
point1[2]=(line1[5]-line1[2])t1[i]+line1[2]
point2[0]=(line2[3]-line2[0])t2[i]+line2[0]
point2[1]=(line2[4]-line2[1])t2[i]+line2[1]
point2[2]=(line2[5]-line2[2])*t2[i]+line2[2]
d_squar[i]=d_squar_count(point1,point2)
choice(d_squar,t1,t2)
update(t1,t2)
d=d_squar[0]**0.5
print("迭代200000次后所得到的异面直线之间最短距离约为{}".format(d))
总结
- 1.迭代的次数越多,得到的结果越准确。一开始我的迭代次数是20,由于重复计算的结果差距较大,我将迭代次数逐渐提高到了200000次(又因为计算时间实在过长,所以退回20000)。
- 2、变异产生的随机数越大,同时需要进行互相竞争的染色体就更多,否则变异的效果反而会下降,因为在本次实验中我将空间直线用参数方程的形式表示,变量t1或t2分别控制两条直线上的点集合。由于线段是无限长的,但是我产生的随机数不可能无限大,因此我一开始把随机数调到了-100到100,后来由于多次在相同输入情况下运算得到最短距离近似值相差较大,于是我怀疑是变异太小,可能最优解是在100或-100以外产生的,于是我将随机数范围增大到了-1000到1000,效果显著提高,多次重复试验,计算的近似值相差减小到了0.1左右,我进一步大胆的猜想:将随机数范围扩大到-10000到10000是否会更好?经过重复试验,发现效果反而大大变差,我猜测是因为大部分我们输入的方程的近似解在-1000到1000以内,产生过大的随机数是无效的,大约浪费了我9倍的迭代次数。
- 3、染色体遗传有常见的两种形式:一是以二进制。二是以十进制形式。这次实验中我选用的是十进制,我将每次取得较短距离的前两组染色体的t1、t2分别使用(0.5,0.5)、(0.8,0.2)、(0.6,0.4)、(0.4,0.6)、(0.2,0.8)的权值产生了新的5对染色体,然后通过随机数变异产生3对变异染色体,加上原本的2对较优染色体刚好又是10对,继续进行迭代。由于我的遗传方法会导致新的染色体会向t1、t2间靠拢,但是最优解可能在他们的单侧,并不在中间,因此我的变异随机数设置要较大于t1、t2,并通过变异染色体不断防止其迅速收敛于局部最优解。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端