
浅谈Http协议是怎么回事?
老实说关于http协议这个概念,见到最多的还是各类招聘信息.在平时的工作中,除了了解一些请求,响应,请求头这些概念外,对于http协议也没有太多的关心.因为貌似对平时的工作没有什么影响,所以在写这篇关于http协议的博客的时候,我就问自己.
了解Http协议到底是为了什么?
所谓学以致用,学习知识不是为了秀记忆力或者闲着没事,而是为了使用.那么Http协议的了解对平时工作到底有什么用?坦白说我平时工作的经历是没有发现太大的作用,但是清楚一些基本内容还是能让你快速理解涉及到此的各方面知识,比如Ajax的Status状态码的含义等.
在说Http协议之前,TCP/IP协议也是我们经常能看到或者听到的,我们先来理清一个概念,这两者之间有什么关系?
http协议只能算是tip/ip协议中应用层的一个部分.
tcp/ip协议是当前互联网最基本的协议,它定义了电子设备如何连入互联网,以及数据如何在它们之间传输的标准.整个的tcp/ip协议十分庞大,分为4层结构,每一层都呼叫它的下一层所提供的协议去完成自己的需求.http协议就是最上层应用层的一部分.
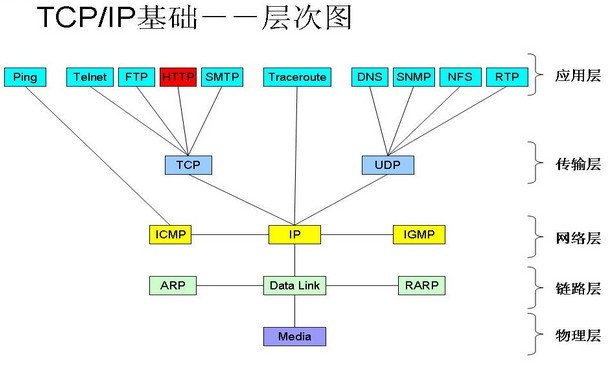
什么是Http协议?
通信网络上的两台计算机进行通信所必须遵守的规则或规定就是协议了,所谓Http协议就是大家规定通信的时候允许将HTML从服务器发送到客户端浏览器.当我们在浏览器输入url,浏览器给服务器发送一个Request,服务器接收并处理之后生成相应的Response发送给浏览器,浏览器解析其中的HTML生成我们看到的页面.这一套流程就是http协议在起作用.

Http中的URL
url在整个http协议中无疑占有最重要的地位,它描述了网络上的一个资源.通过url我们可以获得很多信息,看一个例子:
1 2 3 4 5 6 7 8 | http://www.mywebsite.com/sj/test;id=8079?name=sviergn&x=true#stuff指定底层使用协议(Schema): http服务器地址或域名(host): www.mywebsite.com访问资源路径(path): /sj/test服务器端口号(port):默认80,可以不写省略发送的数据(Query String): name=sviergn&x=true锚(Anchor): stuff |
Http之Request请求
http协议中的内容是繁杂的,这里就是做简单了解,让大家知道是怎么回事.Request的http发的请求,其结构存储了浏览器的一系列要求信息.Request消息包含3个部分,请求行,http header,body.这里我不把他们所有的属性都拿出来一个个晒,没什么意义,从谷歌浏览器的debug模式下,查看一些百度首页的一个请求,把它的Request信息贴出来.
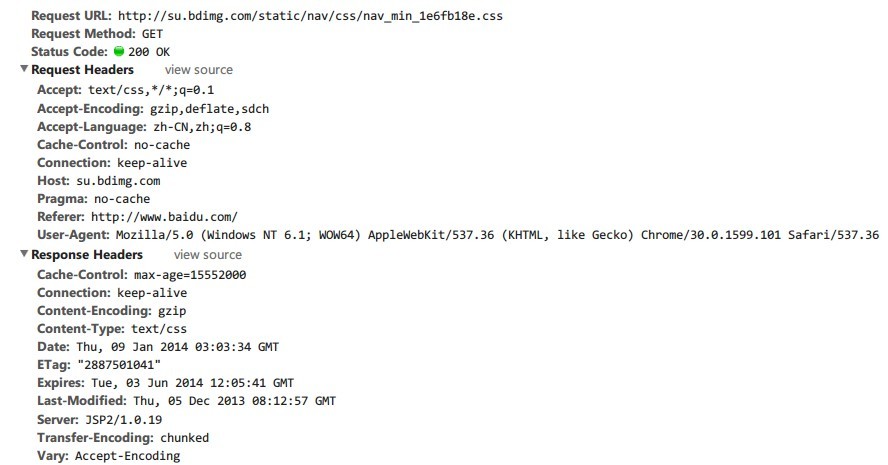
这里我们看到的Request信息结构是经过浏览器调试工具优化显示的,相比原生的结构看起来更加明显.这里面的所包含的就是一个Request的全部信息和结构.比如请求的方式是Get,请求返回的状态码是200,请求的一个css类型资源等等.
Get和Post请求的区别
通常来讲get请求用于查询信息,post请求用于更新信息.
get请求的数据会显示的连在url地址后,从?开始,用&分隔参数.post则是将数据装入请求的body中.所以就请求数据大小而言,get有限制,post则无限制.同样的,因为两种不同的提交方式,在安全性上,get会比post差.但是实际应用最多的恰恰是get请求,因为大多数我们是为了获取信息.
状态码的含义
在Response消息中第一行就叫做状态行,由Http协议,状态码,状态消息三部分组成.状态的作用就是告诉客户端,服务器是否产生了预期的Response.
这其中最著名的就是404状态码了,在打开一些网页的时候有时会出现.
HTTP/1.1中定义了5类状态码, 状态码由三位数字组成,第一个数字定义了响应的类别
1XX 提示信息 - 表示请求已被成功接收,继续处理
2XX 成功 - 表示请求已被成功接收,理解,接受
3XX 重定向 - 要完成请求必须进行更进一步的处理
4XX 客户端错误 - 请求有语法错误或请求无法实现
5XX 服务器端错误 - 服务器未能实现合法的请求
Http协议是无状态的和Connection:keep-alive的区别
阿斯顿之所以说Http是无状态的,通过这个协议的网络连接,同一个浏览器的url访问,服务器不会知道它们是来自同一台机器.从Http1.1起,默认都开启了keep-alive,让浏览器和服务器之间保持了tcp通道.在下次要进行访问时,还会在这个通道进行.当然,keep-alive是有时间限制的.
关于http协议还有很多点,这里仅仅列出比较基础和常用的概念,仅供参考.

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步