JVM学习(3):运行时数据区
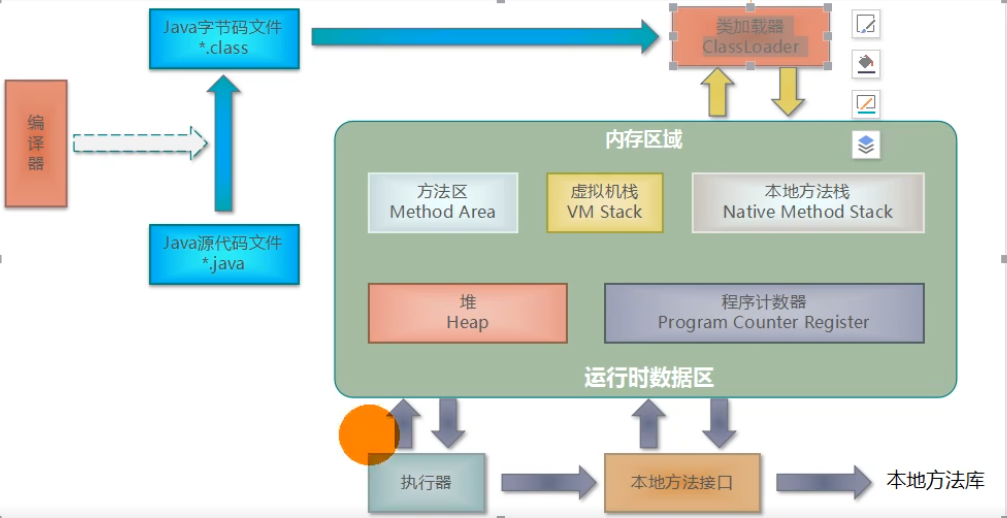
类由静态到动态,会经历运行时数据区这一步:
静态编译:把Java代码编译成字节码文件Class文件,它以静态方式存在
类加载器:把Java字节码文件加载到内存中
【方法区】与【堆】是运行时数据区在所有线程间共享的,它们是存数据的地方
【虚拟机栈】,【本地方法栈】,【程序计数器】是运行时数据区线程私有的,它们是执行逻辑的地方
以下代码为例:
public class Person { String name; public void say(String name){ System.out.println(name); } public static void main(String[] args) { Person person = new Person(); person.say("Hello World!"); } }
方法区:
Person是存放在方法区的,方法区用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码(JIT)
JIT:Java编译成ByteCode(静态编译)然后交由CPU执行本地指令,在CPU执行本地指令之前,会将一些热点代码存储下来保存在方法区,以提高效率,例如:
for (int i=0;i<10000;i++){ function(); }
堆:
当我们new Person的时候,这个对象实例会存在堆中,几乎所有的对象实例都在这里分配内存
当堆里面没有可分配内存的时候,会报OOM错误(内存超出)
程序计数器:类似汇编语言的寄存器(指令寄存器),用于存放下一条指令所在单元的地址的地方
虚拟机栈:存放局部变量表,操作数栈,动态连接/方法返回地址,分配基本类型和自定义对象的引用(局部变量表)
本地方法栈:为了Native的执行和调出(Java源码中的很多Native方法)
在某些虚拟机中,本地方法栈+虚拟机栈+程序计数器=栈区
通常栈底是主方法Main,先入后出,第一个放入的方法是Main,最后执行的方法是Main
当死循环或递归调用栈中方法过多时候,会报StackOverFlow错误
堆栈之间如何配合:
观察以下代码:
String s = "1" + "2" + "3"; String s1 = "hello"; String s2 = new String("hello"); System.out.println(s1 == s2); System.out.println(s1.equals(s2));
打印的是:false\ntrue,说明s1和s2的值相同,地址不同
第一行创建了一个对象,编译的时候进行了字符串折叠(老版本JDK没有优化,会创建四个对象)
第二行只创建一个对象,先在常量池创建字符串“hello”,然后将地址给s1
第三行创建了一个String对象,然后创建常量池字符串,所以栈中变量s2先指向堆中String对象地址,String对象地址再指向常量池中的字符串
因此s1和s2的地址不同
继续看上面的这段代码:
public class Person { String name; public void say(String name){ System.out.println(name); } public static void main(String[] args) { Person person = new Person(); person.say("Hello World!"); } }
(1)还没new之前,person存入栈中的局部变量表(局部变量表可以存八种基本类型和引用类型)
(2)new Person之后会产生一个实例,存在堆中,局部变量表中的person引用指向堆中的实例
(3)在方法区中保存了Person类信息,比如属性name和方法say
(4)调用say方法,局部变量表的person引用指向堆的Person实例,Person实例指向方法区say方法的地址,完成了一系列调用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号