SQL入门(2): Oracle内置函数-字符/数值/日期/转换/NVL/分析函数与窗口函数/case_decode
本文介绍Oracle 的内置函数. 常用!
一. 字符函数
ASCII 码与字符的转化函数
chr(n) 例如 select chr(65) || chr(66) || chr(67) , chr(54678) from dual;
ascii(char) 作用于chr相反 例如 select ascii('徐'), ascii('asd') from dual;
其他常用字符函数:
(1) 大小写控制函数(UPPER、LOWER和INITCAP); initcap (char) 表示首字母大写
select * from emp where job = upper('salesman'); select * from emp where lower(job) = 'clerk';
(2) 字符控制函数(CONCAT、SUBSTR、LENGTH、INSERT、LPAD、RPAD、TRIM、REPLACE)
CONCAT(str1, str2):连接字符串
select concat(concat(ename, ':'),sal) from emp;
select concat(concat(sname, ':'),sno) stud_info from student;--列别名
substr(str,m,n) 用于截取字符串
m用于指定从哪个位置开始截取,n用于指定截取字符串的长度。m为0或者1则从首字母开始,m为负数则从尾部开始。
substr('hello'1,3)--> hel;substr('hello',0,3)--> hel, 两个结果一样;substr('hello',-1,1)--> o


m 是负数, 为啥长度不起作用, ???? 输出都是 o, 这个很奇怪

LENGTH(char) 返回长度
INSTR(char1, char2, n,m):该函数用于取得子串在字符串中的位置,char1用于指定源字符串,char2用于指定子串,n用于指定起始搜索位置(默认值1),m用于指定子串的第m次出现的次数(默认1)。
instr('hello oracle', 'oracle')=7;instr('hello oracle hello oracle', 'oracle', 1, 2)=20。
LPAD(char1, n, char2):该函数用于在字符串的左端填充字符,char1用于指定源字符串,char2用于指定被填充的字符,n用于指定填充后的char1的总长度。
lpad('hello',10,'#')--> #####hello。
select lpad('21',6,'0') stock_code from dual;-- 格式化股票代码 --得到 000021 select lpad('1234567',6,'0') stock_code from dual;--超过长度了,截取左边开始6个字符 --得到123456
RPAD(char1, n ,char2):该函数用于在字符串的右端填充字符.
rpad('hello',10,'#')--> hello#####。
lpad,rpad 在SSMS中出错了....不是可以识别的内置函数名称....
REPLACE(char, old, new):该函数用于替换字符串的子串内容。
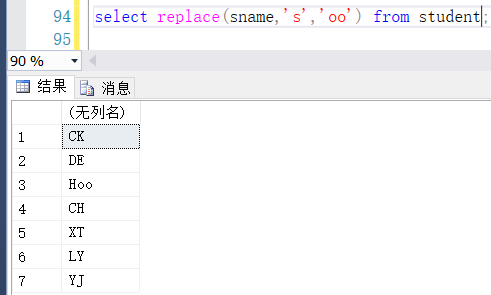
replace('hello oracle', 'oracle', 'world'),结果为:hello world。
trim(char1,char2) 删除给定的字符
select trim(' test '), trim('test*fft*', '*ft') from dual; --得到test? select rtrim(' test ') , rtrim('* test*fft*', '*ft') from dual; - 删除右边的
二. 数值函数
abs(n) 绝对值
round(n, m) 四舍五入 : ROUND(25.328)=25;ROUND(25.328, 2)=25.33;ROUND(25.328, -1)=30
select sal/30, round(sal/30, 2) from emp;
trunc(n, m) 截取数字,其中n可以是任意数字,m必须是整数
trunc(25.328)=25;trunc(25.328, 2)=25.32;trunc(25.328, -1)=20
mod(m, n) : select mod(5,2), mod(10,2) from dual;
注意: n=0 时,返回m, mod(25,6)=1;mod(25, 0)=25。
sign(n) 符号函数
三角函数: sin(n), asin(n), cos(n), acos(n), tan(n), atan(n)
取整: ceil(n), floor(n)
指数对数: sqrt(n) , power(n,m) =n^m, log(n,m)
三.时间与日期函数
常见几个函数为: SYSDATE、MONTHS_BETWEEN、ADD_MONTHS、NEXT_DAY、LAST_DAY、ROUND、TRUNC。
select sysdate-1 昨天, sysdate 今天,sysdate + 1明天 from dual; select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') from dual; --??? 可行
MONTHS_BETWEEN(d1, d2) ,返回日期d1和d2之间相差的月数。d1大于d2结果为正数,否则为负数。
--计算员工入职时长 select months_between(sysdate, hiredate) from emp;
select months_between('19-12月-1999','19-3月-1999') mon_between from dual; --9
add_months(date, integer)该函数用于返回特定日期时间之后或者之前的月份所对应的日期时间。
--每位员工入职30年后的日期 select ename, add_months(hiredate, 30* 12) from emp; select to_char(add_months(to_date(199912,'yyyymm'),2),'yyyymm') from dual; -- 得到200002 select to_char(add_months(to_date('2009-9-14', 'yyyy-mm-dd'),1), 'yyyy-mm-dd') from dual;
NEXT_DAY(d,char):该函数用于返回特定日期下一周的日期. d用于指定日期时间值,char用于指定工作日。
使用该函数时,工作日必须与日期语言匹配,假如日期语言为AMERICAN,那么周一对应于MONDAY;假如日期语言为简体中文,那么周一对应于“星期一”。
--查询今天起 下一个周一的日期 select sysdate, next_day(sysdate, '星期一') 下一个周一 from dual;

LAST_DAY:该函数用于返回特定日期所在月份的最后一天。
select sysdate, last_day(sysdate) from dual;

extract(datetime) 提取日期特定部分
select extract(year from sysdate) year, extract(minute from timestamp '2010-6-19 12:23:01') min from dual;
四.数据转换函数
日期类型 -> 字符类型(使用TO_CHAR())、字符类型 -> 日期类型(使用TO_DATE())。
字符类型 -> 数值类型(使用TO_NUMBER())、数值类型 -> 字符类型(使用TO_CHAR())
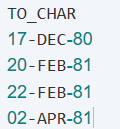
1.将日期型转为字符型 to_char(date)
select to_char(hiredate, 'DD-MON-RR', 'NLS_DATE_LANGUAGE=AMERICAN') to_char
from emp;
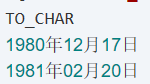
--当在格式模型中增加字符值时,必须用双引号引住字符值 select to_char(hiredate, 'YYYY"年"MM"月"DD"日"') to_char from emp;
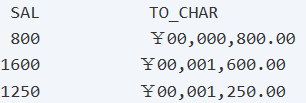
2.将数值类型转换成字符类型:TO_CHAR(number)

SELECT sal, to_char(sal, 'L00,000,000.00') to_char FROM emp; SELECT sal, to_char(sal, 'L99,999,999.99') to_char FROM emp;
结果:

3. 字符串转为日期 to_date(str,'yyyy-mm-dd') , 需要指明格式.
--查看1982之后入职的员工信息 select ename, hiredate from emp
where hiredate > to_date('1981-12-31', 'YYYY-MM-DD');
4. 字符串转换成数值类TO_NUMBER
select ename, sal from emp where sal > to_number('¥3000', 'L99999');
五.NVL函数
此类函数适用于任何数据类型,同时也适用于空值。
如:替换值函数: NVL(expr1, expr2)、NVL2(expr1, expr2, expr3)、NULLIF(expr1, expr2)、COALESCE(expr1 [ , expr2 ] [, ... ])。
1. NVL(expr1, expr2):该函数用于处理NULL。如果expr1是null,则返回expr2,如果expr1不是null,则返回expr1。
NVL2(expr1, expr2, expr3) : 如果expr1不是null,则返回expr2,如果expr1是null,则返回expr3。
select ename, sal, comm, sal + nvl(comm, 0) from emp; --comm 表示补贴
2.NULLIF(expr1, expr2):该函数用于比较表达式expr1和expr2,如果二者相等,则返回NULL,否则返回expr1。
3.COALESCE(expr1, expr2],...) 该函数用于返回表达式列表中第一个NOT NULL表达式的结果。
select ename, sal, comm, coalesce(sal + comm, sal) coalesce from emp;
注意: 数字+null=null
其他补充: select user from dual ; --返回当前登录名;
(六) 分析函数与窗口函数
2018/08/23补充: Oracle高级函数-->分析函数+ 窗口函数! 很有用.
(1) 排名: 根据窗口中的记录生成排序序号, rank() , dense_rank(), row_number()
已知有student(sno, sname, sage), 现在想要对学生的age按从小到大的顺序排列, 并返回各个学生在排序中的位置.
可以用分析函数rank() + 窗口函数 over()
select sname, rank() over (order by sage) position from student;-- position 列别名, rank()用于返回排序序号
-- 相同排名的记录rank()返回相同的序号, 当出现多个排名一致的情况, 则下一个序号出现跳跃, 1 2 2 4 4 6... select sname, dense_rank() over (order by sage) position from student;-- 序号不出现跳跃, 1 2 2 3 3 4 ... select sname, row_number() over (order by sage) position from student;--每次返回唯一的序号 1 2 3 4 5 6
解释: over(order by sage) 用于指定当前记录(即表中的每条记录)的窗口, 此时的窗口为排序后, 第一条记录到当前排名的所有记录!
(2)分区窗口 partition by
已知emp(eno, ename,deptno,sal), 现在要统计每个部门的员工工资高低,
则先利用partition by 进行分区, 然后利用分析函数对分区内的记录进行统计.
select emp.*,dense_rank() over(partition by deptno order by sal) position from emp ;
over(partition by deptno order by sal) 为当前记录获得分区窗口, 分区列为deptno, 每个区按照sal 排序
在源表基础上, 增加该员工所在部门的总工资, 平均工资
select emp.*, sum(sal) over(partition by deptno) total_sal, round( avg(sal) over(partition by deptno) ) avg_sal from emp ;
sum(sal) 为对窗口函数所获得的记录集进行求和. 结果就是增加两列数据.
注意: round 的作用不是在avg(sal) 上, 因为sum() over() , avg() over () 这些都是整体! ,不可分割.
(3) 窗口子句: rows, range
rows 的原理, 在已经确定的窗口中, 各个记录已经按照某种标准进行了排序, rows 以当前记录为参照物, 可以向前向后移动, 形成新的结果集,
作为最终的操作窗口.
例1: emp 中增加一列, 以eno 为顺序, 计算相邻三个员工的工资和
select eno, ename, sal, sum(sal) over(order by eno rows between 1 preceding and 1 following) three_total from emp;
注意: 第一条 最后一条数据没有相邻三个数据, 只有两条数据相加.
order by eno 将窗口的记录按照eno 排序, 因为没有partition by 限制, 此时的窗口为排序后, 第一条记录到当前排名的所有记录.
rows between 1 preceding and 1 following 进一步限制了窗口的大小, 当前记录的前一条和下一条之间的所有记录.
rows 必须要和位置相关, 必须有order by , 否则报错!
range 按照列值进行窗口的进一步限制
例2:
select eno, ename, sal, count(1) over(partition by deptno order by sal range between 500 preceding and 500 following) as emp_count from emp order by eno;

还有unbounded, current row 不介绍了...
主要的分析函数: 分析函数作用对象是窗口函数捕捉到的记录集, 分析函数具有聚集函数的特点, 大多聚集函数可以
作为分析函数使用, sum(), count(), max(). 除了这些, Oracle 还提供了 first_value(), last_value(), lag(), lead()函数.
(1) first_value() 用于获得窗口函数捕捉的记录集中的第一条记录.
例子: 获得每个部门中工资最低的员工姓名与对应的工资
传统方法: 对emp 表的salary按照dept 分组, 获得每组中的最小salary,
select a.deptno, a.ename, a.sal from (select deptno, min(sal) min_sal from salary group by deptno) t1 left join emp a on a.deptno=t1.deptno and a.sal=t1.min_sal;
用first_value()
select distinct deptno, first_value(ename) over(partition by deptno order by sal) ename,
first(sal) over(partition by deptno order by sal) sal from emp; -- 解释 --over(partition by deptno order by sal) 表示对表emp 中的数据按照 deptno 列进行分区,
--并在分区被按照sal 排序, first_value(ename) 用于获得窗口中的第一条记录, -- distinct 是必要的,因为每个部门中的每条记录都会返回相同的信息
(2) lead() 在当前记录向下推移, 获得新纪录. lead(expression, offset, defaultvalue)
ecpression 为一个表达式, offset 为整数, 表示偏移量, 当无法获取新纪录, 用defaultvalue
例3: 对emp 按照sal 进行排序, 对每一位员工, 获取工资在她后面的员工姓名
select eno, ename, sal, lead(ename,1,'N/A') over(partition by deptno order by sal) ename prev_name from emp order by eno;
lead(ename, 1,'N/A') 表示从当前记录开始向下推一个 , 定位新的记录, 获取该记录的员工姓名, 如果该记录不存在就用N/A.
lag() 与lead() 类似, 获取当前记录的前面记录.
六.条件表示式case 和decode
1.case
select empno, ename, case job when 'CLERK' then '办事员'
when 'SALESMAE' then '销售' when 'MANAGER' then '经理'
when 'ANALYST' then '分析员'
else'总裁' end case from emp;
2.DECODE是PL/SQL是功能强大的函数之一,目前只有ORACLE公司的SQL提供了此函数,其他数据库厂商的SQL还没此功能.
(2) decode(字段或字段的运算,值1,值2,值3): 当运算值=值1,该函数返回值2,否则返回值3, 当然值1,值2,值3也可以是表达式
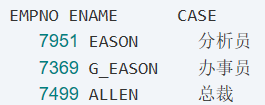
select empno, ename, job, decode(job, 'CLERK', '办事员', 'SALESMAN', '销售', 'MANAGER', '经理', 'ANALYST', '分析员', '总裁') from emp;
结果:
1. 比较大小
select decode(sign(变量1-变量2),-1,变量1,变量2) from dual; --取较小值
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
2. 查询某张表中的男女数量
--通常写法 select count(*) from 表 where 性别 = 男; select count(*) from 表 where 性别 = 女; --利用decode第二种用法 select sum(decode(性别,男,1,0)),sum(decode(性别,女,1,0)) from student;
3. order by对字符列进行特定的排序
--表table_subject,有subject_name列。要求按照:语、数、外的顺序进行排序。 select * from table_subject order by decode(subject_name, '语文', 1, '数学', 2 , '外语',3); -- 根据员工的job_typ 类型 确定它的职位等级, 输出前10行. select empno, decode(job,1,'manager',2,'director',2,'common','unknow') as job_position from emp where rownum<=10;
4.有学生成绩表student,现在要用decode函数实现以下几个功能:成绩>85,显示优秀;>70显示良好;>60及格;否则不及格-->嵌套decode
select id, decode(sign(score-85),1,'优秀',0,'优秀',-1, decode(sign(score-70),1,'良好',0,'良好',-1, decode(sign(score-60),1,'及格',0,'及格',-1,'不及格'))) from student;
5. 比较表达式和搜索字, 看搜索字是否出现在表达式中
SELECT ENAME, SAL,DECODE(INSTR(ENAME, 'S'), 0, '不含有s', '含有s') AS memo FROM EMP;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号