
python(1):数据类型/string/list/dict/set等
本系列文章中, python用的idle是spyder或者pycharm, 两者都很好用, spyder 是在anaconda 中的, 自带了很多包可以用,
pycharm 只是个编译器, 没有很多包, 但是可以从anaconda 中传过来, 具体操作可以见我的另一篇博文.
Python2 与python3 语法略有差别. 本系列文章全部针对 python3 以上版本!
spyder 中的快捷键: ctrl+1 注释 , F5 运行, 上下键调用, #注释, \表示续行
''' abdfa''' 三引号可以实现换行
一行写多条语句, 需要用分号;
pycharm中的快捷键: Ctrl + / 行注释/取消行注释,
ctrl+D 复制本行到下一行(nice), ctrl+y 删除本行 , Shift + F10 运行, Shift + F9 调试 ,ctrl+r 替换 ctrl+f 查找
如果运行的按钮是灰色的, 需要在倒三角的下拉菜单中
地方选择一下

左上角的下拉三角这边 选择 python ,同时在script path中找到文件的路径, 之后就可以了.
(一) python 基础知识
python的代码极为精简, 没有分号, if,for不用对应写end, 缩进是 代码的灵魂
区分大小写 fish 与Fish不同的
v='28C' 字符串可以单引号也可双引号 , v[-1]='C' ; v[0:2] 表示0,1, 取不到2
长度为n的序列索引: 0,1,2,3..n-1, 倒过来为-1,-2,...-n
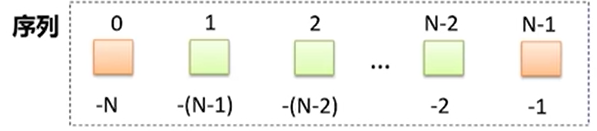
v[0:-1] 获取除去最后一个字符串以外的部分; v[::-1] 倒序
float(v[0:-1]) 将字符串转化为小数
格式化输出: print(' the price is: %.2f yuan'%x) %.2f表示小数点有两位
range(10) 表示 0-9 , 取不到10
简单输入输出: price=input('please input a number:')
注: input()返回的类型是字符型str, 需要用int(), float()得到数值 , 可以用eval()将input当做表达式来处理.
关键字: false, none, true, and as, break...
表达式: **乘方, //整除(得到商), % 取余, ~ , & , | , <=, >=, !=,==, not, and, or
增量赋值: m%=5 表示 m=m%5, a=a+3等价于a+=3 , 还有m**=2, a/=8
链式赋值: m=n=3.14, 先把3.14赋值给n, 再把n 赋值给m,
多重赋值: x=1, y=2,可以输出x,y=(1,2) , x,y=y,x 则马上交换了顺序, 不需要通过第三个变量, 其中逗号, 表示元组
可以多个一起赋值: x,y=1,2 两个同时赋值
3<4<7 表示 (3<4) and (4<7)
f=open(r'c:\python\test.py','w'); 或者f=open('c:\\python\\test.py','w');
错误 f=open('c:\python\test.py','w');
python 自己的内建函数: abs(), bool(), round()四舍五入, int(), divmod(), pow(), float(), chr(), complex(), dir(), input(), help(),
输入dir(__builtins__) 得到所有内建函数名, help(zip) 查看zip 函数的使用指导.
(二)六种数据类型
(1) 数值型(int , float , complex复数)
int(4.5)=4, 不可以int('你好')
float(4)=4.0
9.8e3 代表9800.0, -4.78e-2
complex(4)=4+0j
x=2.1+5.6j, x.imag 虚部 , x.real 实部, x.conjugate() 获得共轭
str(123)
x//y商 x%y 余数 divmod(x,y)=(x//y, x%y)
-10//3=-4, 保证余数是正的, abs(x)
(2) string 字符串, 可以用单引号, 双引号, 三引号
print('\'nihao\'') #'nihao' print('\"nihao\"') #"nihao"
\转义符,
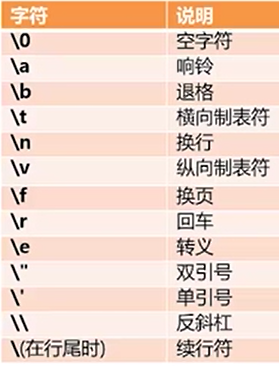
其他也可以用转义字符表示
a='\101\t\x41\n' b='\141\t\x61\n' print(a,b) #A A # a a
字符串的索引: 从0 开始计数
注意, s='abc', 直接在console中输入s 得到 'abc', 但是写print(s) 则为 abc
s="I'm a student" s Out[2]: "I'm a student" type(s) Out[3]: str s='abc' s Out[5]: 'abc' s='''hello # 三引号可以让字符串保持原貌 word''' s Out[7]: 'hello\nword' s=r'd:\python\test.py' # 原始字符串 s Out[9]: 'd:\\python\\test.py'
实例
a='hello' #也可以 a=''hello'', a='''hello''' print(a[2]) #l print(a[0:2]) # he print(3*'pine') # pinepinepine print('like'+'pine') # likepine 通过+ * 实现字符串的连接 print(len('apple')) # 5
实例
month='janfebmaraprmayjunaugsepoctnovdec' n=input('please input num(1-12):') pos=3*(int(n)-1) month_abbrev=month[pos:pos+3] print(type(month_abbrev)) print("月份简写为"+month_abbrev+'!')
int的问题
print(int('1.234')) # 报错 print(eval('1.234'))可以 print(int(1.234)) # 可以
字符串的常用方法
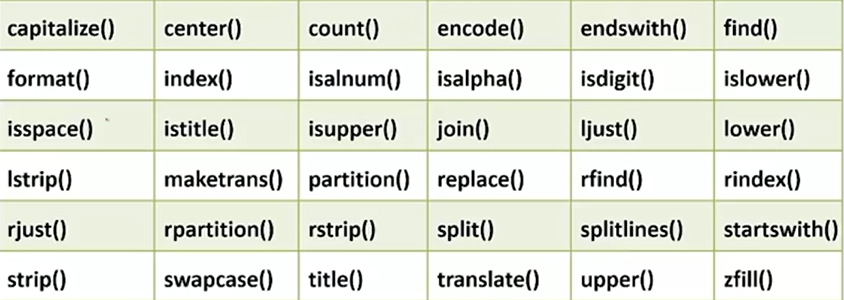
实例
a='thank you' print(a.capitalize()) print(a.center(20)) print(a.center(20,'\'')) print(a.endswith('s')) print(a.find('o')) # 返回第一个o位置的下标 7 print(a.rjust(20,'+'))
注意 以上操作都不会改变a !!! 上述运行结果为
Thank you
thank you
'''''thank you''''''
False
7 ( 从0 开始计数的)
+++++++++++thank you
a='thank you' b='o'.join(a) # 在a的每个字符中都插入o print(b) print(a) # 不改变a print(a.split('k')) # k作为分割点进行分开 print(a.strip()) # 移除字符串头尾指定的字符 空则删除空格 print(a.strip('yu')) print(a.replace('o','ww')) #次序为old, new
结果:
tohoaonoko oyooou
thank you
['than', ' you']
thank you
thank yo
thank ywwu
实例
s='gone with the wind' print(s.find('the')) # 10 找位置 print(s.find('the',4,13)) #找某个范围内的字符串的位置, 10 s1=['hello','world'] print(' '.join(s1)) # hello world 得到字符串
实例: 'What do you think of the saying "No pains, No gains"?' 中双引号的内容是否为标题格式??
s='What do you think of the saying "No pains, No gains"?' lindex=s.index('\"',0,len(s)) rindex=s.rindex('\"',0,len(s)) s1=s[lindex+1:rindex] print(s1) # No pains, No gains if s1.istitle(): print('it is title format') else: print('it is not title format') # 简化上述 split s='What do you think of the saying "No pains, No gains"?' s1=s.split('\"')[1] # 用" 隔开并取中间的字符串 print(s1) # No pains, No gains if s1.istitle(): print('it is title format') else: print('it is not title format')
实例 : 将字符串"hello, world!" 中的world 换成python , 并计算其包含的标点符号个数
s1="hello, world!" s2=s1[:7]+'python!' print(s2) cnt=0 for ch in s2[:]: if ch in ',.?!': cnt=cnt+1 print('there are %d punctuation marks.'%cnt) print('there are {0:d} punctuation marks.'.format(cnt))
上述用到了 print输出的格式化的两种方法, 第二种中 {} 内部的参数含义是
{参数的序号:格式说明符}
格式说明符还有以下这些: d,f 常用, f 还可规定 +m.nf 的形式规定小数点的个数等
整个宽度是m列, 如果实际宽度超出了就突破m 的限制
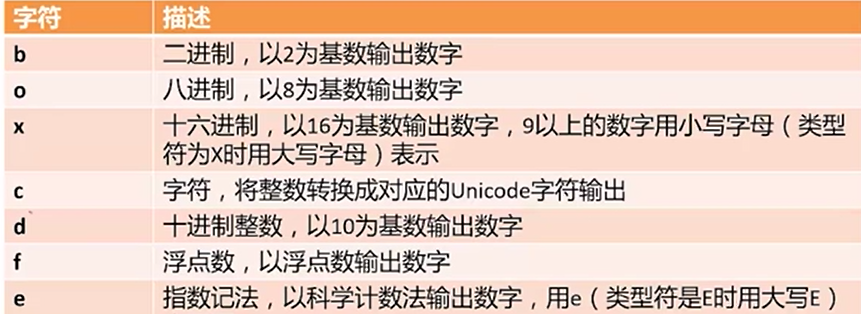
另外还有 < 表示 左对齐, 默认用空格填充
0>5d 表示右对齐, 用0填充左边, 宽度为5
^ 居中对齐
{{}} 表示输出一个{}
例子
age,height=21,1.783 print("Age:{0:<5d}, Height:{1:5.2f}".format(age,height)) # 上述如果顺序是好的, 那么{}第一个参数可以不写0,1,2 # Age:21 , Height: 1.78
例子
name=['AXP','BA','CAT','CVX'] price=['100.23','128.34','239.15','309.213'] for i in range(4): print('{:<8d}{:8s}{:8s}'.format(i,name[i],price[i])) # < 左对齐, 其实字符串默认就是左对齐, 整数默认方式是右对齐, 需要用<实现左对齐 print('I get {:d}{{}}!'.format(32)) # I get 32{}!
0 AXP 100.23
1 BA 128.34
2 CAT 239.15
3 CVX 309.213
(3) 元组 tuple 可以包含多个数据类型,用逗号分开, 小括号括起来的(a,b,c), 记忆->元组就用圆括号!!
tuple('hel') =('h','e','l')
元组的元素不支持赋值, 元组不可变!!
t=(12,'hha',45) t1=12,'hha',45 # 可以不加括号 print(t) print(t1) # (12, 'hha', 45)
元组定义后不可以更改了,使程序更安全,但是不灵活,
t1=(12,) t2=(12) print(type(t1)) # <class 'tuple'> print(type(t2)) # <class 'int'>
注意元组定义的逗号
print(8*(8)) # 64 print(8*(8,)) # (8, 8, 8, 8, 8, 8, 8, 8)
sorted(tuple) 报错, 元组不可改变
元组用在什么地方?
(1) 在映射类型中当做键使用
(2) 函数的特殊类型参数
(3) 作为函数的特殊返回值
可变长函数参数(吸收参数) 加一个*,
def fun(x,*y): print(x) print(y) fun('hello','pyhton','world') #hello #('pyhton', 'world') 多个参数合并成一个元组
多个返回值
def fun(): return 1,2,3 fun() #Out[56]: (1, 2, 3)
函数的返回对象个数
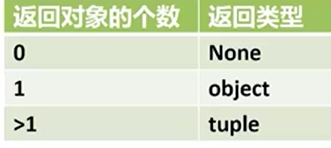
(4) list : Python 中的苦力
元组元素不可变, 但是列表可变! 列表也可以存放不同类型的数据, 列表用中括号 ,用逗号分开 ,列表可更改 [a,b,c]
a=[1,2,3] print(2*a) # [1, 2, 3, 1, 2, 3] 重复 #对列表进行修改 a=[1,2,3] a.append('e') print(a) # [1, 2, 3, 'e'] a.insert(2,10) # 位置2 插入10 print(a) # a改变了, [1, 2, 10, 3, 'e'] a.pop(3) #删除3位置的元素 print(a) # [1, 2, 10, 'e'] print(a[::-1]) #反向排列 ['e', 10, 2, 1] #a[:] 得到全部 #a[2:] 2位置到最后 a1=a.count(1) # a1=1 计算1 出现的次数 a=[1,2,3] a.append('e') print(a+a) # 只是连接而已 [1, 2, 3, 'e', 1, 2, 3, 'e'] b=list('ok') print(a+b) # [1, 2, 3, 'e', 'o', 'k'] a=[1,2,13] a.append('e') a.append('b') a.sort(key=lambda x:len(str(x))) # 根据长度大小进行排序, 不能直接a.sort(key=len) 报错, int没有len! print(a) # [1, 2, 'e', 'b', 13] a=[1,2,13] a.append('e') import random as rd a.append('21') rd.shuffle(a) # a改变, 打乱顺序 print(a) #[13, 1, 'e', '21', 2]
字符串可以变成列表
a='do you like python'.split() print(a) # ['do', 'you', 'like', 'python']
实例: 评委打分(去掉高低)+ 观众打分-->平均分, help(list.sort)
s1=[9,9,8.5,10,9.4,9.4,8.5,9,8.1,9.1] s2=9 s1.sort() # 从小到大排序 s1.pop() # 去最后一个, 弹出 print(s1) s1.pop(0) s1.append(s2) avg=sum(s1)/len(s1) print('avg score is %.2f'%avg)
注意:如果上述用sorted(s1), 不会改变s1, 通过赋值可以s3=sorted(s1)
append 与extend对比
week=['monday','tuesday','wednesday','thursday','friday'] weekend=['saturday','sunday'] #week.append(weekend) #print(week) # ['monday', 'tuesday', 'wednesday', 'thursday', 'friday', ['saturday', 'sunday']] week.extend(weekend) print(week) #['monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday', 'sunday'] for i,j in enumerate(week): print(i+1,j) #1 monday #2 tuesday #3 wednesday #4 thursday #5 friday #6 saturday #7 sunday
list.sort(key=none, reverse=False)
l=[1,2,11,9,4] l.sort(reverse=True) print(l) # [11, 9, 4, 2, 1] s=['apple','egg','banana'] s.sort(key=len) print(s) # ['egg', 'apple', 'banana']
列表解析
[x for x in range(5)] Out[49]: [0, 1, 2, 3, 4] [x**2 for x in range(5)] Out[50]: [0, 1, 4, 9, 16] [x+2 for x in range(10) if x%3==0] Out[51]: [2, 5, 8, 11] [(x+1,y+1) for x in range(2) for y in range(3)] Out[52]: [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3)]
(5) dict : 字典. 字典可以实现映射, 用花括号 {'a':1, 'b':2}
想要查找某个人的工资
name=['mike','peter','lily'] sal=[100,200,130] print(sal[name.index('mike')]) # 100
上述方式比较复杂, 字典可以使其更简洁, 字典是一种映射类型: 键(key)--> 值(value) , key-value 对
创建字典的方法
#(1) 直接创建 d1={'mike':100, 'allice':120} #(2) 用列表创建 info1=[('mike',100),('alice',120)] # 元素是元组 d2=dict(info1) #(3) info2=[['mike',100],['alice',120]] # 元素是列表 d3=dict(info2) #(4) d4=dict((('mike',100),('alice',120))) # 全部用元组 #(5) d5=dict(mike=100,alice=120)
因此, 只要元素之间存在对应关系, 无论是tuple ,还是list 都可以创建字典
sorted(d5)
Out[61]: ['alice', 'mike'] , 字典是无序存储的, 这个只是内部存储结果
字典的其他创建方法.
d={} # 创立一个空字典
p=d.fromkeys([1,2,3],'alpha') # 另一种定义字典的方法, key是1,2,3, values一样都是alpha
p={}.fromkeys([1,2,3],'alpha') # 也可以!!
print('p=',p)
p1=p #p1不随p变动
p2=p.copy() #p2不随p变动
del p[2] # 删除2 这个键与值
print ('p=',p)
print ('p1=',p1) #p1与p一起变
print ('p2=',p2) #p2不变
p= {1: 'alpha', 2: 'alpha', 3: 'alpha'}
p= {1: 'alpha', 3: 'alpha'}
p1= {1: 'alpha', 3: 'alpha'}
p2= {1: 'alpha', 2: 'alpha', 3: 'alpha'}
对比:
s={'mike':150, 'alice':180,'bob':200}
s1=s
s={} # 导致s指向{}, 但是s1不变
print(s1) # {'mike': 150, 'alice': 180, 'bob': 200}
s={'mike':150, 'alice':180,'bob':200}
s1=s
s.clear() # 真的清空了, 被赋值对象也清空了
print(s1) # {}
总结
![]()
注意: 字典是没有顺序的! 字典不是像list 一样通过索引确定对象 , 而是通过键来确定
字典的基本操作
p=dict(a=1,b=2,c=3) p Out[66]: {'a': 1, 'b': 2, 'c': 3} p[a] # 出错 p['a'] # 查找键对应的值 Out[68]: 1 p['d']=4 # 增加新元素 p Out[70]: {'a': 1, 'b': 2, 'c': 3, 'd': 4} 'f' in p # 判断f 是否在p中 Out[71]: False del p['a'] # 删除 p Out[73]: {'b': 2, 'c': 3, 'd': 4}
注意: 通过键查找值, 推荐使用get
s={'mike':150, 'allice':180,'bob':200}
s['lili'] # 报错
print(s.get('lili'))
# 输出 None , 不报错
实例
x=['boy','girl'];y=[30,25] #两个list z=dict(zip(x,y)) # 利用两个list 生成字典 zip()返回zip对象 print(z) # {'boy': 30, 'girl': 25} print(z.keys()) # dict_keys(['boy', 'girl']) print(z.values()) # dict_values([30, 25]) for m,n in z.items(): # items()返回一个列表, 元素为键值对构成的元组 print(m,n) for i in z: print(i) # 默认输出键 , 要是遍历values 则 为 for i in st.values() print(i+':'+str(z[i])) # 键:value
{'boy': 30, 'girl': 25}
dict_keys(['boy', 'girl'])
dict_values([30, 25])
boy 30
girl 25
boy
boy:30
girl
girl:25
应用: 公司简称与对应的股价提取
s_info=[('AXP','American Express Company','78.61'),('CAT','Caterpillat Inc','98.23')] a=[] b=[] for i in range(2): s1=s_info[i][0] s2=s_info[i][2] a.append(s1) b.append(s2) d=dict(zip(a,b)) print(d) # {'AXP': '78.61', 'CAT': '98.23'}
更加简便的方法
s_info=[('AXP','American Express Company','78.61'),('CAT','Caterpillat Inc','98.23')] d={} for x in s_info: d[x[0]]=x[2] print(d) # {'AXP': '78.61', 'CAT': '98.23'}
实例3. 现在有两张工资dict , 一新一旧, 如何更新?
sal1={'mike':100, 'alice':120}
sal2={'mike':150, 'alice':180,'bob':200}
sal1.update(sal2)
print(sal1) # {'mike': 150, 'alice': 180, 'bob': 200}
(六) set, 集合. set可以实现删除列表中的相同元素, 用大括号
{1,2,3} 无序不重复
print(set([1,2,3,3,4,5,5])) # {1, 2, 3, 4, 5}快速删除重复 print (set('you')) #{'y', 'u', 'o'} 用字符串生成set, 每个元素是字符串的单个字符 a=set([1,2,3]) a.add('you') a.remove(2) print (a) # {1, 3, 'you'} b=set('abcde') # {'a','b','c','d','e'} c=set('cdefg') print (b&c) # {'e', 'c', 'd'} print (b-c) # {'a', 'b'} print (b^c) #交叉积=b并c-b交c={'a', 'f', 'g', 'b'} print (b|c) # {'a', 'e', 'g', 'c', 'f', 'b', 'd'} print (b.issubset(c)) # 子集的判断 False b是否为c的子集? d=set('degdeg') print(d<c)# True 判断集合d在c里面
总结
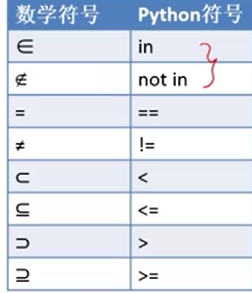
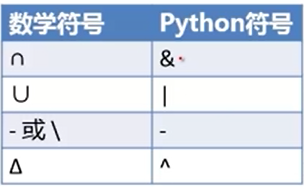
除了上述python 符号, 函数也能完成以上任务

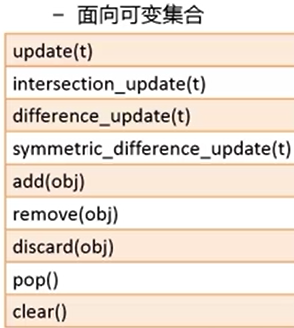
例如
a=set('sunrise') b=set('sunset') a.issubset(b) Out[89]: False a.difference(b) Out[90]: {'i', 'r'}
例如
a=set('sunrise') a.add('y') print(a) # {'n', 'u', 'y', 'r', 's', 'i', 'e'} a.remove('s') print(a) # {'n', 'u', 'y', 'r', 'i', 'e'} a.update('sunset') print(a) # {'n', 'u', 't', 'y', 'r', 's', 'i', 'e'} a.clear() print(a) # set()
