MySQL(1): 基本操作
MySQL 是流行的关系型数据库管理系统之一,特别是在WEB应用方面。推荐用5.6版本。
My Sql客户端有很多

还有PHP MyAdmin, 是以web形式控制和操作MySQL数据库的管理工具。是WAMP软件包集成的工具软件。
Navicat premium 破解版安装连接http://www.downcc.com/soft/322714.html
补充MYSQL
(1)limit 两个数字
select * from student limit 2,4
2 第一位表示从下标为几的数据开始;4第二位表示当前分页显示多少数据。
limit 2,4表示从第三条开始,显示4条数据。
(2)limit 两个数字
select * from student limit 4. 显示4条数据。
(3)分组函数一般与聚合函数一起!!
select sdept, count(*) from student group by sdept;
(4)having 用于分组函数的条件!!
select sdept,count(*) from student group by sdept having count(*)>5
(5)show tables 显示当下数据库的所有表和视图
视图的主要功能是简化查询语句,很多嵌套的复杂查询
(6)存储过程
示例1:
CREATE DEFINER=`root`@`localhost` PROCEDURE `pro1`(OUT `cnt` integer) BEGIN #Routine body goes here... select count(*) into cnt from student where sdept='PC'; END
在查询语句中进行调用
set @shu=0; call pro1(@shu); select @shu;
shu是会话变量,以@开头。
示例2:
在查询脚本中写
CREATE PROCEDURE pro3(IN sig integer,OUT cnt integer) BEGIN IF sig = 1 THEN SELECT count(*) INTO cnt FROM student WHERE sclass = '01'; ELSE SELECT count(*) INTO cnt FROM student WHERE sclass <>'01'; #<> end if; END;
调用,在左侧列表中没有出现pro3 需要刷新一下
call pro3(1,@cnt); select @cnt;
---

(7)索引
可以提高查询数据,在数据里很大的情况下可以用,一般查询中常用的字段加索引。
增加一个索引,会把表“备份”一份,按照索引排序一下,会消耗内存!
chapter1 数据库操作
1. 系统数据库: 是安装完MySQL服务器后,附带的一些数据库。例如information_schema,主要存储数据库对象的信息(用户名信息、列信息、权限信息等)。performance_schema主要用于存储数据库服务器性能参数。
创建数据库 create database xy;或者create schema xy;
不允许两个同名的数据库,可以 create database if not exists xy;
2. 查看、选择、删除数据库
show databases|schemas like|where
show databases like 'db_%' ;找到db开头的数据库。
选择数据库。create database 语句之后,该数据库不会成为当前数据库,需要 写 use database;
删除数据库 drop database|schema, 比如drop database if exists xy;
chapter2 数据类型
1.数字类型
tyniint(如果值不超过127,用tyniint 比int 好);
还有int , float ,double等。
2.字符串类型
(1)普通:char, varchar(变长)
(2)可变:text适合长文本;bolb适合二进制数据,支持任何数据包括文本、声音、图像等。
(3)特殊:enum('value1','value2',……),把列中的内容限制在一种选择上,只能所列举的值之一或者null;
set('value1','value2',……),可以容纳一组值或者null.
3. 日期与时间类型
datetime\date\timestamp\time\year
date格式为 yyyy-mm-dd
time 格式为 hh:mm:ss
datetime 格式为yyyy-mm-dd hh:mm:ss
chapter3 数据表操作
1.表的创建
create table if not exists 表名(列1 属性1,列2 属性2,……);
if not exists 避免了建表时报告错误。
对于成功创建的表,可以show columns 或者 describe 查看表结构
show columns from 表名 from 数据库名 ; 或者 show columns from 数据库名.表名
describe 表名 或者简写为 desc 表名;
或者只看某个字段 desc 表名 列名;
2. 修改表结构
增加新字段 alter table 表名 add sno varchar not null;
修改字段名 alter table 表名 change column 老的字段 新的字段;
删除字段 alter table 表名 drop 字段名;
修改表名 alter table 表名 rename as 新表名 ; 或者 rename table 老的表 to 新的表名;
复制表 create table (if not exists)新的表名 like 源表名 ; 这个语句没有复制表中的数据。
create table (if not exists)新的表名 as select * from 源表名; 这个复制了数据。
删除表 drop table (if exists) 表名;
chapter 4 MYSQL 基础
1. 算术运算符 + - * /
求余% 或 mod
select score,score+score from student;
2. 比较运算符 不等于<> 或者!=
is null ; is not null; between.. and ...; in ;not in;
like; not like ; regexp(正则表达式)
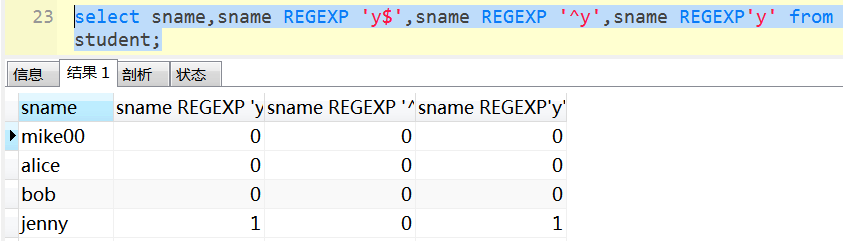
regexp 可以来匹配某个字段的值是否以指定字符开头、结尾,或者包含某个字符串。
返回值是1或者0.
3. 逻辑运算符
and && ; || or ; ! not ; xor 异或
1 xor 1=0; 0 xor 0 =0;
4. 流程控制
(1)if then.. elseif then... else... end if;
(2)case
case value
when .. then...
when..then...
else...
end case
(3)while
while condition DO
...
end while
创建一个procedure
create procedure pro4(out sum int) begin declare i int default 1; declare s int default 0; while i<10 DO set s =s+i; set i=i+1; end while; set sum=s; end
调用
call pro4(@s); select @s
得到45 : 从1+,,,9=45;
(4)loop
loop
...
end loop
(5)repeat 先执行一次循环体,之后判断condition,为真则退出循环。
repeat
...
until conditon
end repeat
create procedure pro5(out sum int) begin declare i int default 1; declare s int default 0; repeat set s =s+i; set i=i+1; until i>10 end REPEAT; set sum=s; end call pro5(@s); select @s
得到55, 从1+,,,10=55
chapter5 表数据的增删改、常用函数
1. 增加数据
(1)insert into 表名 values('','','') ,('','',''); 可以插入多条数据。
(2)insert into 表名 set sname='mike',sno='001'; 指定字段的值。
(3)insert into 表名 select子句。
insert into 表名 (sno,sname) select sno,sname from student;
2. 修改数据
update 表名 set sname='mike' where sno='001';
3. 删除数据
delete from 表名 where sno='001'; 删除一行数据
truncate table 表名 ;删除表中所有的行。
4. group by
select sname,sdept from student group by sdept;
不用函数, group by 一组只显示一条数据
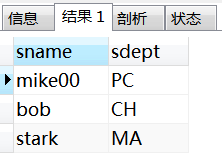

select sdept,count(*)from student group by sdept;
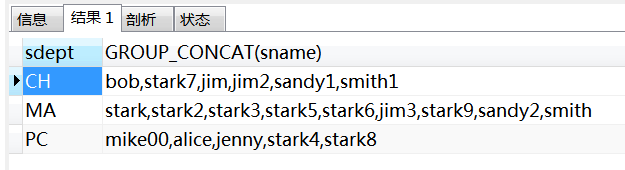
GROUP_CONCAT可以把一个组下面的字段值都显示出来。
select sdept,GROUP_CONCAT(sname) from student group by sdept;
5. exists 查询
exists 使用时,内层查询语句不返回查询的记录,而是返回一个真假值。返回true 时,外层查询进行查询。
如果sc表中存在001的学生序号,那么查找student的表数据。
select * from student where exists(select * from sc where sno='001'); select * from student where sclass='01' and exists (select * from sno='001');
not exists : 如果内层返回false, 外层才开始查询。
6. any 与 all
<any(select score from...) 表示小于所有值。
>all 大于最大值。
7.正则表达式
^x 以x开头
x$ 以x结尾
. 匹配任何一个字符
[字符集合]
[^字符集合] [^abc] 除了abc以外的任意一个字符
a|b|c
* 匹配多个该符号之前的字符,包括0个或者1个;
+ 匹配多个该符号之前的字符,1个以上;
{n} 匹配字符串出现n 次;
{m,n} 出现m-n次;
select sname from student where sname regexp'm$' ; 以 m 结尾。
regexp ‘a{3}’ a 出现3次;
‘J+A’ 至少出现一次J;
8. 数学函数
abs(x); ceil(x); floor(x); rand() 0-1之间的随机数; sign(x); PI();
truncate(x,y) x 保留小数点到y位的值; round(x); pow(x,y) 或者power(x,y);
sqrt,exp,mod(x,y); log(x),基数为2; log10(x); sin(); asin(); cos(); acos();
select abs(-5),sqrt(5);
9.字符串函数
char_length(s) s 的字符数;
length(s) s 的长度(字节);
concat(s1,s2,...)
cncat_ws(x,s1,s2,...) ;每个字符串直接要加上x
select CONCAT_WS('*','aaa','bbb') ; 得到aaa*bbb
upper(s); lower(s);
left(s,n) 左边n 个字符; right(s,n);
Ltrim(s); Rtrim(s);
insert(s1, x,len,s2): s1 从x 位开始的len 长度由s2 代替。select insert('mikj',3,2,'book') 得到mibook
repeat(s,n);s 重复n次;
substring(s,n,len), 获取s 从n位置开始的len长度字符串。
reverse(s), 顺序反过来;
field(s,s1,s2...) 返回第一个与s 匹配的字符串的位置。select field('aa','bfa','faae','aa')得到3.
locate(s1,s) s1在s 中的开始位置;类似的还有 position(s1 in s) 或者 instr(s,s1)
10. 日期函数
curdate(); current_date(); 一样的,获取当前日期。
curtime(); current_time(); 获取当前时间。
获取当下日期和时间:now(), current_timestamp(), localtime(), sysdate();
datediff(d1, d2) 相隔的天数。SELECT datediff('2014-2-4','2015-4-9') -429
adddate(d,n); 相反的是subdate(d,n);
11. 条件判断函数!!! 很重要
if(expr,v1, v2) , expr成立就执行v1;
ifnull(v1,v2) , v1不空则返回v1, 否则返回v2;
case when expr1 then v1 when expr2 then v2 else v0 end
case expr when e1 then v1 when e2 then v2 else v0 end
12.系统信息函数
version() 数据库版本号
connection_ID() 获取服务器的连接数
database(), schema() 获取当前数据库名
user(),system_user(), session_user() 获取当前用户
mysq函数大全 补充
数学函数:
#ABS 绝对值函数 select abs(-5) ; #BIN 返回二进制,OCT()八进制,hex十六进制 select bin(2); #ceiling 天花板整数,也就是大于x的整数 select CEILING(-13.5); #EXP(X)自然对数e为底的x次方 select EXP(2); #FLOOR(X)小于x的最大整数 select FLOOR(3.5); #返回集合中最大的值,least返回最小的,注意跟max,min不一样,max里面跟的是col,返回这个列的最大值最小值 select GREATEST(1,2,3,4); #ln(x)返回对数 select LN(10); #log(x,y),以y为底x的对数 select log(4,2); #mod(x,y)返回x/y的余数 select mod(5,2); #pi() 返回pi select pi(); #RAND()返回0,1之间随机数 select rand(); #round(x,y)返回x四舍五入有y位小数的值 select round(pi(),3); #sign(x) 返回x符号 select sign(-5); #sqrt(x)返回x的平方根 select sqrt(9); #truncate(x,y) 返回数字x截断为y位小数的结果,就是不考虑四舍五入,直接砍掉 select TRUNCATE(pi(),4),ROUND(pi(),4),pi();
聚合函数(常用语group by从句select语句中)
#avg(col)返回指定列平均值 select AVG( quantity) from orderitems; #count(col)返回指定列中非null数量 select count(quantity) from orderitems; #min(col)max(col)返回指定列最大最小值 select max(quantity),min(quantity) from orderitems; #sum(col)返回制定列求和值 select sum(quantity) from orderitems; #group_concat(col)返回这个列连接组合的结果,中间有逗号隔开 select group_concat(prod_id) from orderitems
字符串函数
#ASCII(str)返回字符串的ascii码值
select ASCII('12');
#bit_length(str)返回字符串的比特长度
select bit_length('123');
#concat()连接字符串
select concat('1','我','2');
#concat_ws(sep,s1,s2,s3)连接字符串用sep隔开
select concat_ws('|','1','我','2');
#INSERT(str,pos,len,newstr),将字符串str从pos位置开始的len长度替换为newstr
select 'hello world',INSERT('hello world',2,3,'杰哥哥');
#FIND_IN_SET(str,strlist)分析逗号分隔的list,如果发现str返回list中的位置
select find_in_set('abc','aabc,sdf,det,abc') #返回4
#LCASE(str),LOWER(str)都是返回小写的结果,UPPER(),UCASE() 返回的都是大写结果
select LCASE('UUSU');
#`LEFT`(str,len)从左到右从str中选择长度为len的字符串,`RIGHT`(str,len)相反
select left('hello world',4);
#length(str)返回str字符串长度
select length('hello world');
#trim(),ltrim()rtrim()分别去掉两头的空格,左边的空格,右边的空格
select trim(' hello ');
#POSITION(substr IN str),返回substr首次在str中长线的位置
select POSITION('llo' IN 'hello world');
#QUOTE(str)用反斜杠转义str中的单引号
select QUOTE("hello ' world")
#`REPLACE`(str,from_str,to_str)在str中,把from str 转成to_str
select replace('hello world','hello','hi');
#repeat(str,count)重复str count次
select repeat('hello world',3);
#reverse(str)颠倒str
select reverse('hello world');
#STRCMP(expr1,expr2)比较两个字符串,一模一样返回0,不一样返回1
select STRCMP('hello','world')
日期和时间函数
#curdate()或者current_date() NOW()是返回日期+时间 select current_date(); #curtime()当前时间,或者current_time() select curtime(); #DATE_ADD(date,INTERVAL expr unit)返回date加上int日期后的日期,date_sub()也是一样的 select date_add(curdate(),interval 5 day); select date_add(curtime(),interval 5 hour); #DATE_FORMAT(date,format)按照格式转化日期,具体的format格式可以查查 select date_format(CURDATE(),'%m-%d-%Y'); #dayofweek()DAYOFMONTH(date)DAYOFYEAR(date)返回日期中是一周中第几天,一个月中第几天,一年中第几天 select DAYOFMONTH(CURDATE()); #dayname返回日期星期名 select dayname(CURDATE()); #hour(time),minute(time),month(date) select curtime(),hour(CURTIME()),minute(curtime()); select curdate(),month(curdate()),year(curdate()),day(curdate()); #MONTHNAME(date) 返回月份名称 select monthname(curdate()); #quarter(date)返回日期的第几季度 select quarter(curdate()); #week(date) select week(curdate()); #TIMESTAMPDIFF(unit,datetime_expr1,datetime_expr2)计算两个时间差,还有datediff() select TIMESTAMPDIFF(year,19920202,CURDATE())
chapter 6 索引
索引可以提高查询速度,不需要遍历数据表中的所有数据,只需要查询索引列。
索引就像一本书的目录。但是创建索引和后期维护需要花费很多时间,索引也会占用物理内存。
有索引也会影响表的插入操作,因为新插入数据会按照索引进行排序。(可以先删除索引再插入数据,再重建索引。。)
索引类型:
(1)普通索引normal:
(2)唯一索引:unique , 索引的值唯一。主键就是一种特殊的索引
(3)全文索引fulltext:只能建立在char varchar text类型的字段是。
创建普通索引
create table score(id int(11), auto_increment primary key not null),
name varchar(20) not null, grade int(5) not null, index(id))
创建唯一性索引
create table score(id int(11), auto_increment primary key not null), name varchar(20) not null, grade int(5) not null, unique index(id))
创建全文索引,索引名称是beizhu1
create table score(id int(11), auto_increment primary key not null),
name varchar(20) not null,
grade int(5) not null, beizhu varchar(100),FULLTEXT KEY beizhu1(id))
在已有的表中创立索引
create index 索引名 on 表名(字段)
create index stu_info on student(info) create unique index stu_info on student(info) create fulltext index stu_info on student(info)
修改、删除索引
alter table student add index idx1(sno); drop index idx1 on student; # 删除索引
chapter7 视图
create or replace view view1(sno, cno) as select 。。with check option.
with check option 表示更新视图时要保证在该视图的权限范围之内。
查看视图 desc view名
看视图
看表

这就是表与视图的差别
show create view pc 可以查看视图pc的详细定义。
修改视图,可以更改其中的列
alter view view1(sno) as select sno from student with check option;
更新视图:update view1 set grade=100 where sno=‘001’;
对视图的更新就是对基本表的更新。
并不是所有的视图都可以更新,以下情况不能更新:
(1) 用了函数sum等;
(2) 包含union, distinct,group by, having;
(3) 视图中的select 包含子查询。
最好不要通过视图进行更新。删除视图 drop view if exists view1;
chapter8 数据完整性约束
1.实体完整性
(1)主键约束, 一个表只能有一个主键,主键能够唯一标识一行记录,且不为null. 可以是一列或者多列。primary key.
(2)候选键约束,可以是一列或多列。值唯一且不为空。unique
2. 参照完整性
foreign key(sno) references sc(sno) on delete restrict on update restrict;
reference 后面跟的表是被参照表(父表)。
restrict:禁止对被参照表的删除或者更新;
cascade: 被参照表删除或更新时,参照表的数据也被更新或删除;
set null :被参照表删除或更新时,设置参照表中对应的外键为null;
3.用户定义完整性
check(expr) :
对列:age int not null check(age>0 and age<100)
对表:check sno in (select sno from student)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号