数据采集与融合技术第三次作业
作业内容
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
主要代码:
单线程:
class zy1_Pipeline:
count = 0
desktopDir = str(pathlib.Path.home()).replace('\\', '\\\\') + '\\Desktop'
def open_spider(self, spider):
picture_path = self.desktopDir + '\\images'
if os.path.exists(picture_path): # 判断文件夹是否存在
for root, dirs, files in os.walk(picture_path, topdown=False):
for name in files:
os.remove(os.path.join(root, name)) # 删除文件
for name in dirs:
os.rmdir(os.path.join(root, name)) # 删除文件夹
os.rmdir(picture_path) # 删除文件夹
os.mkdir(picture_path) # 创建文件夹
def process_item(self, item, spider):
if isinstance(item, zy1_Item):
url = item['img_url']
print(f"Processing image URL: {url}")
if self.count < 13: # 只处理前13个项目
try:
img_data = urllib.request.urlopen(url=url).read()
img_path = self.desktopDir + '\\images\\' + str(self.count + 1) + '.jpg' # 从1开始编号
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(f"Downloaded image to {img_path}")
self.count += 1 # 增加计数
except Exception as e:
print(f"Error downloading image from {url}: {e}")
return item
def close_spider(self, spider):
# 单线程下,不需要等待线程结束
pass
多线程:
class zy1_Pipeline:
count = 0
desktopDir = str(pathlib.Path.home()).replace('\\', '\\\\') + '\\Desktop'
threads = []
downloaded_urls = set() # 用于记录已下载的图片 URL
def open_spider(self, spider):
picture_path = self.desktopDir + '\\images'
if os.path.exists(picture_path): # 判断文件夹是否存在
for root, dirs, files in os.walk(picture_path, topdown=False):
for name in files:
os.remove(os.path.join(root, name)) # 删除文件
for name in dirs:
os.rmdir(os.path.join(root, name)) # 删除文件夹
os.rmdir(picture_path) # 删除文件夹
os.mkdir(picture_path) # 创建文件夹
# 多线程
def process_item(self, item, spider):
if isinstance(item, zy1_Item):
url = item['img_url']
print(f"Processing image URL: {url}")
if url not in self.downloaded_urls and self.count < 13:
image_number = self.count + 1 # 从1开始编号
T = threading.Thread(target=self.download_img, args=(url, image_number))
T.setDaemon(False)
T.start()
self.threads.append(T)
self.downloaded_urls.add(url) # 记录已下载的 URL
self.count += 1
return item
def download_img(self, url, image_number):
try:
img_data = urllib.request.urlopen(url=url).read()
img_path = self.desktopDir + '\\images\\' + str(image_number) + '.jpg'
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(f"Downloaded image to {img_path}")
except Exception as e:
print(f"Error downloading image from {url}: {e}")
def close_spider(self, spider):
for t in self.threads:
t.join()
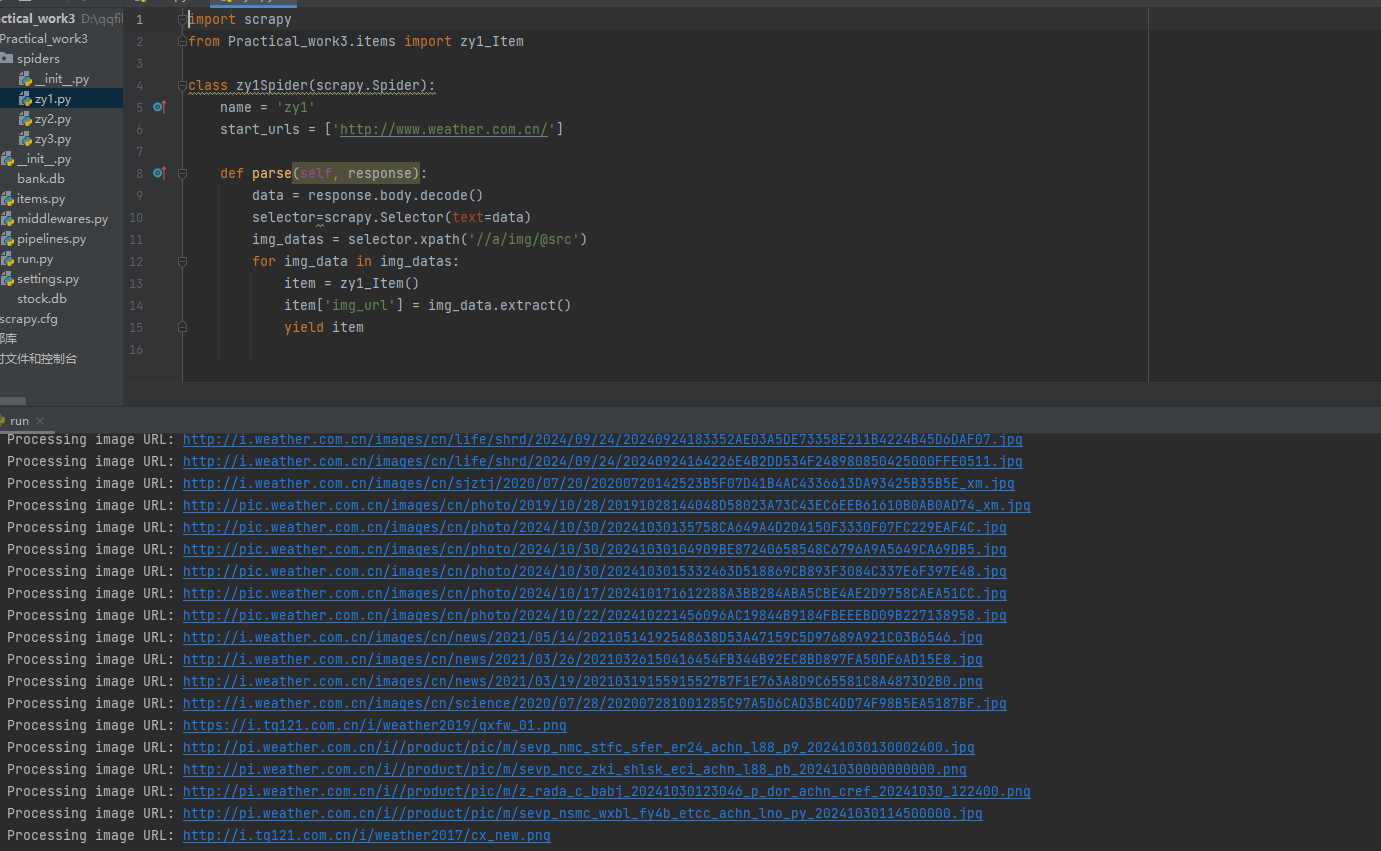
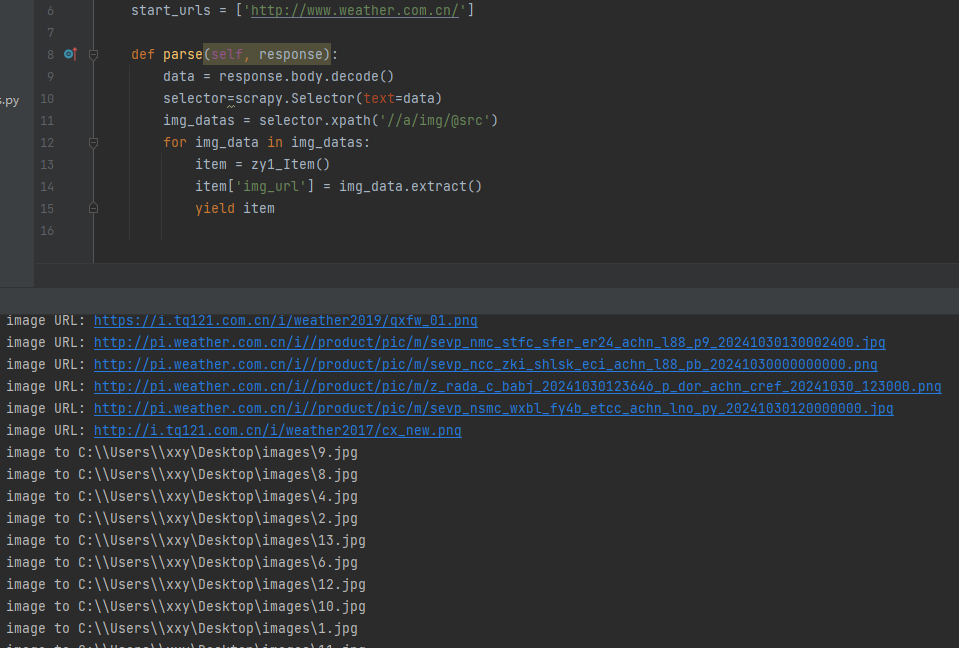
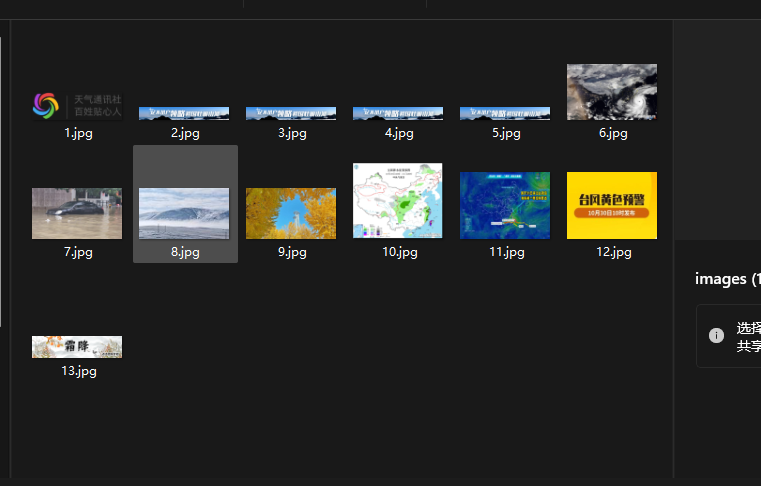
输出信息:
爬取前13张图片
单线程:
多线程:
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
主要代码:
class zy2_Pipeline:
count = 0 # 用于计数
def open_spider(self, spider):
self.conn = sqlite3.connect('stock.db')
self.cursor = self.conn.cursor()
self.cursor.execute('DROP TABLE IF EXISTS stock')
sql = """CREATE TABLE stock(
Latest_quotation REAL,
Chg REAL,
up_down_amount REAL,
turnover REAL,
transaction_volume REAL,
amplitude REAL,
id TEXT PRIMARY KEY,
name TEXT,
highest REAL,
lowest REAL,
today REAL,
yesterday REAL
)"""
self.cursor.execute(sql)
def process_item(self, item, spider):
if isinstance(item, zy2_Item):
if self.count < 113:
sql = """INSERT INTO stock VALUES (?,?,?,?,?,?,?,?,?,?,?,?)"""
values = (item['f2'], item['f3'], item['f4'], item['f5'], item['f6'], item['f7'], item['f12'], item['f14'], item['f15'], item['f16'], item['f17'], item['f18'])
self.cursor.execute(sql, values)
self.conn.commit()
self.count += 1 # 增加计数
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
输出信息:
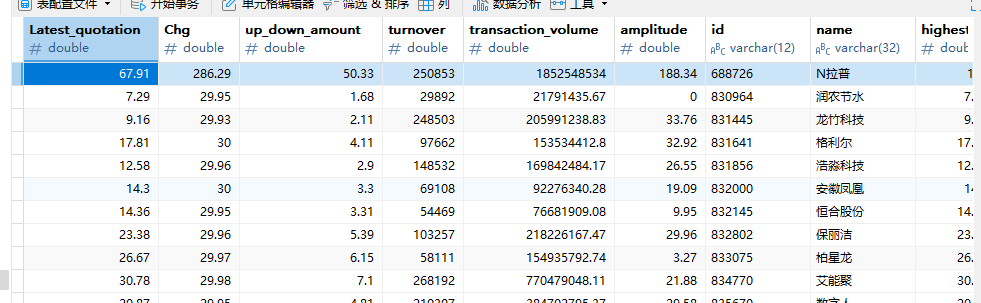
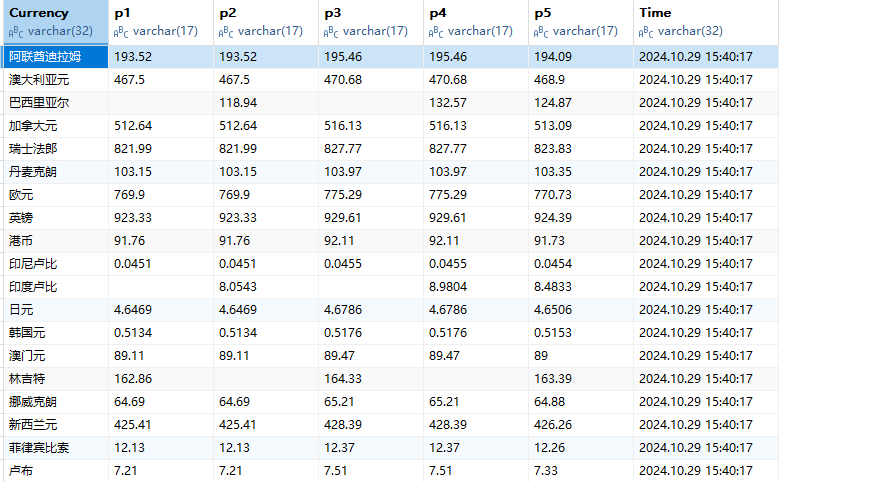
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
主要代码:
class zy3_Pipeline:
count = 0 # 用于计数
def open_spider(self, spider):
self.conn = sqlite3.connect('bank.db')
self.cursor = self.conn.cursor()
self.cursor.execute('DROP TABLE IF EXISTS bank')
sql = """CREATE TABLE bank(
Currency TEXT,
TBP TEXT,
CBP TEXT,
TSP TEXT,
CSP TEXT,
Time TEXT
)"""
self.cursor.execute(sql)
def process_item(self, item, spider):
if isinstance(item, zy3_Item):
if self.count < 113:
sql = 'INSERT INTO bank VALUES (?,?,?,?,?,?)'
values = (item['name'], item['price1'], item['price2'], item['price3'], item['price4'], item['date'])
self.cursor.execute(sql, values)
self.conn.commit()
self.count += 1 # 增加计数
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
输出信息: