

Fluentd: The Missing Log Collector
http://blog.csdn.net/jaysuper/article/details/8021878
http://docs.fluentd.org/articles/install-from-source
http://blog.treasure-data.com/post/13047440992/fluentd-the-missing-log-collector 推荐
About
This post introduces Fluentd, an open-source log collector developed at Treasure Data, Inc.
The Problems
The fundamental problem with logs is that they are usually stored in files although they are best represented as streams (by Adam Wiggins, CTO at Heroku). Traditionally, they have been dumped into text-based files and collected by rsync in hourly or daily fashion. With today’s web/mobile applications, this creates two problems.
Problem 1: Need Ad-Hoc Parsing
The text-based logs have their own format, and analytics engineer need to write a dedicated parser for each format. But that’s probably not the best use of your time. You should be analyzing data to make better business decisions instead of writing one parser after another.
Problem 2: Lacks Freshness
The logs lag. The realtime analysis of user behavior makes feature iterations a lot faster. A nimbler A/B testing will help you differentiate your service from competitors.
This is where Fluentd comes in. We believe Fluentd solves all issues of scalable log collection by getting rid of files and turning logs into true semi-structured data streams.
What’s Fluentd?
The best way to describe Fluentd is ‘syslogd that understands JSON’. The notable features are:
- Easy installation by rpm/deb/gem
- Small footprint with 3000 lines of Ruby
- Semi-Structured data logging
- Easy start with small configuration
- Fully pluggable architecture, and plugin distribution by Ruby gems
Other similar systems are Facebook’s Scribe and Cloudera’s Flume. Here is a table to summarize the differences among Scribe, Flume, and Fluentd. (Note: I don’t know much about next-generation Flume NG branch, but big movement is happening to Flume!):
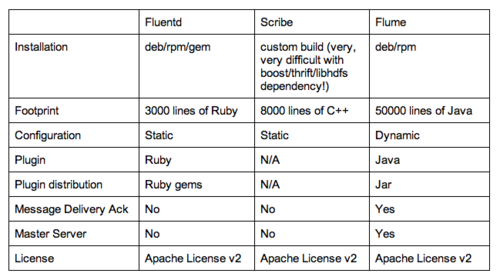
Of course, there’re pros and cons here. Fluentd takes maximum extensibility and flexibility over Ruby’s eco-system, while Scribe takes the performance (although Fluentd is pretty fast too. It can handle 18000msgs/s per core). Flume is powered by Java and therefore integrates natively with many enterprise systems.
The following sections describe the basic concepts of Fluentd in more detail.
LogEntry = time + tag + record
Unlike traditional raw-text log, the log entry of Fluentd consists of three entities: time, tag, and record.

- The time is the UNIX timestamp when the logs are posted.
- The tag is used to route the message in log-forwarding, which is described later.
- The record is represented as JSON, not raw text.
The record is intentionally represented as JSON. Fluentd is designed to collect semi-structured data, not unstructured data. This means no parsing is required at the later analysis pipeline. It’s easy to handle, and faster than ad-hoc regexp. But the application needs to use the logging library for fluentd.
Internal Architecture: Input -> Buffer -> Output
Fluentd consists of three basic components: Input, Buffer, and Output. The basic behavior is 1) Feeding logs from Input, 2) Buffers them, and 3) Forward to Output.
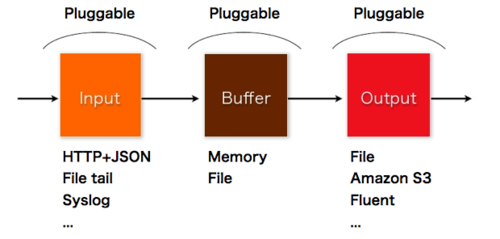
Input
Input is the place where the log comes in. The user can extend it to feed the events from various sources. The example Input supported officially includes: HTTP+JSON, tailing files (Apache log parser is supported), syslog. Of course you can add Input plugin by writing a Ruby plugin.
Buffer
Buffer exists for reliability. When the Output fails, the events are kept by Buffer and automatically retried. Memory or File Buffer is supported now.
Output
Buffer creates chunks of logs, and passes them to the Output. Output stores or forwards chunks. The buffer waits several seconds to 1 minute, to create chunks. This is really efficient for writing into the storage which supports batch-style importing.
Many Input/Output plugins are under heavy development in the community: MongoDB, Redis, CouchDB, Amazon S3, Amazon SQS, Scribe, 0MQ, AMQP, Delayed, Growl, etc.
Log Forwarding
Fluentd works well with one-node, but it can have multi-node configuration.
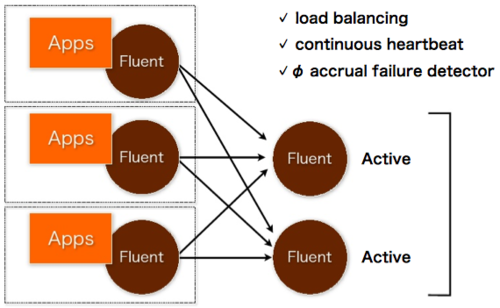
The application servers have one Fluentd locally, and it forwards the local logs into another Fluentd, which aggregates all the logs into one place. The tag is used to determine the destination Fluentd (static configuration by config files).
Conclusion
Fluentd makes real-time log collection dead simple. Out of the possible solutions, we believe Fluentd is easiest to install, configure, extend, and perform well.
Of course it’s an early-stage product compared to Scribe and Flume, but we already have some users aggregating tens of millions of daily logs using Fluentd. The # of committers and plugins are increasing everyday.

