

GPT系列算法
首先附上一些资源链接:
按时间顺序, GPT系列资源罗列如下:
-
GPT(也称GPT-1)
-
GPT-2
- OpenAI官网:GPT-2官网信息
- 文章:Language Models are Unsupervised Multitask Learners
- Github 官网:https://github.com/openai/gpt-2
-
GPT-3
- OpenAI官网:GPT-3官网信息
- 文章:Language Models are Few-Shot Learners
- Github官网:https://github.com/openai/gpt-3,虽然有Github官网,但是代码并没有release
- 非官方开源代码:EleutherAI(高质量)
-
InstructGPT
-
GPT-4
- OpenAI官网:GPT-4官网信息
- 文章:GPT-4 Technical Report
- Github官网:暂无
-
下图[1]总结了GPT-1到GPT-3.5的发展时间线
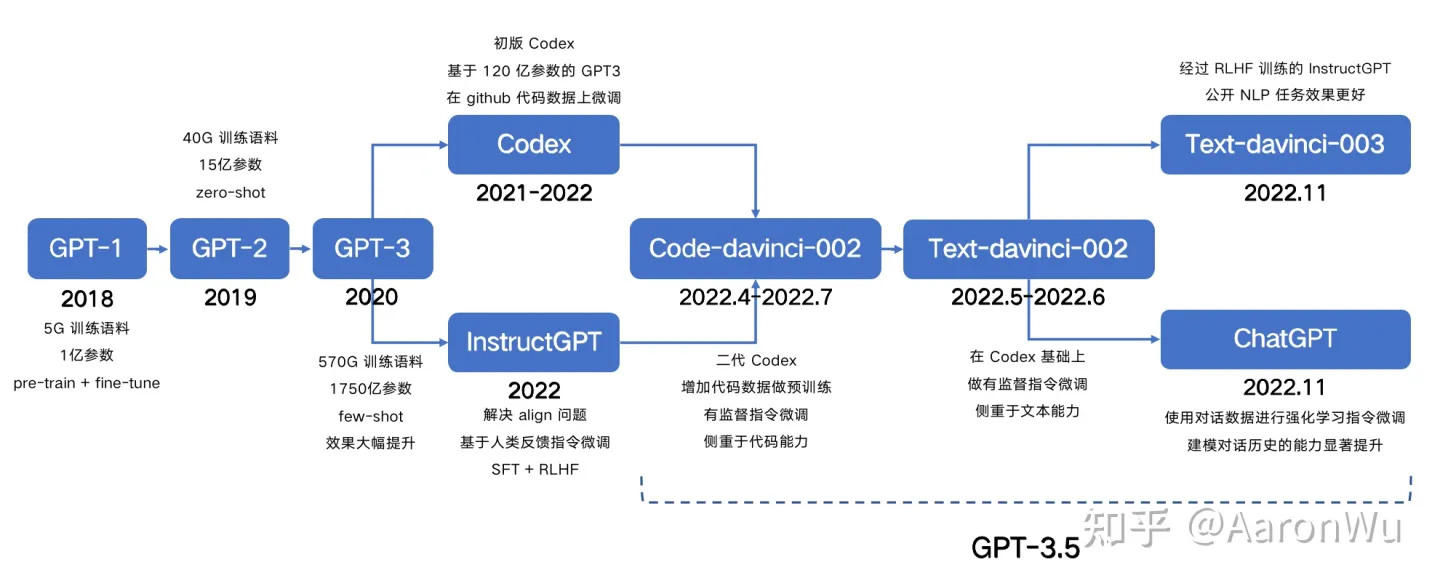
-
对GPT3.5能力的拆解,这个文章:拆解追溯 GPT-3.5 各项能力的起源[2]说得很好.
接下来介绍GPT系列工作的主要思想
GPT-1
GPT-1的主要思想是大规模的无监督预训练,结合有监督的task- specific的fine-tuning,目的是利用冗余的无标签数据,在不增加标签成本的前提下,提升语言模型的性能。
-
题目:Improving Language Understanding by Generative Pre-Training,题目很形象,通过生成式预训练提升语言理解
-
研究动机:尽管无标签数据冗余,但有标签数据稀缺,使得充分的判别式训练模型具有挑战性
Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately
-
主要思想:生成式预训练(无监督)+判别式微调(有监督)
We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task.
-
预训练:GPT-1的预训练采用生成式任务,即用前k个单词,生成第k+1个单词(点题了),生成式任务的优点是无需标签,只需要有一句完整的话即可。该工作采用的数据集是BooksCorpus。该工作采用的语言模型是12层的Transformer(仅decoder部分),参数量为117M。具体信息罗列如下:
- 任务:根据前k个单词,预测下一个
- 学习目标:最大化第i个单词的Likelyhood:
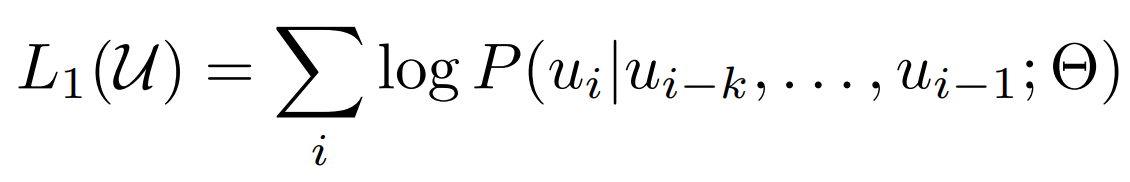
- 语言模型(Language Model,LM):12层Transformer(仅decoder),也就是学习目标中P,\(\theta\)是它的参数,参数量为117M
- 预训练数据集:BooksCorpus[3],BookCorpus是一个由未出版作者撰写的免费小说集合,包含11038本书(约7400M句,1G字,总大小为5G),涉及16个不同的亚流派(如浪漫主义、历史、冒险等)
-
微调:基于预训练模型,GPT-1接下来对每个任务进行专门的微调(记住,这里是和GPT-2的不同之处)。微调的任务各种各样,但都被转换为了分类任务。
- 任务:Classification / Entailment / Similarity / Multiple Choice. 如下图右侧展示。所有的都转换为分类任务处理
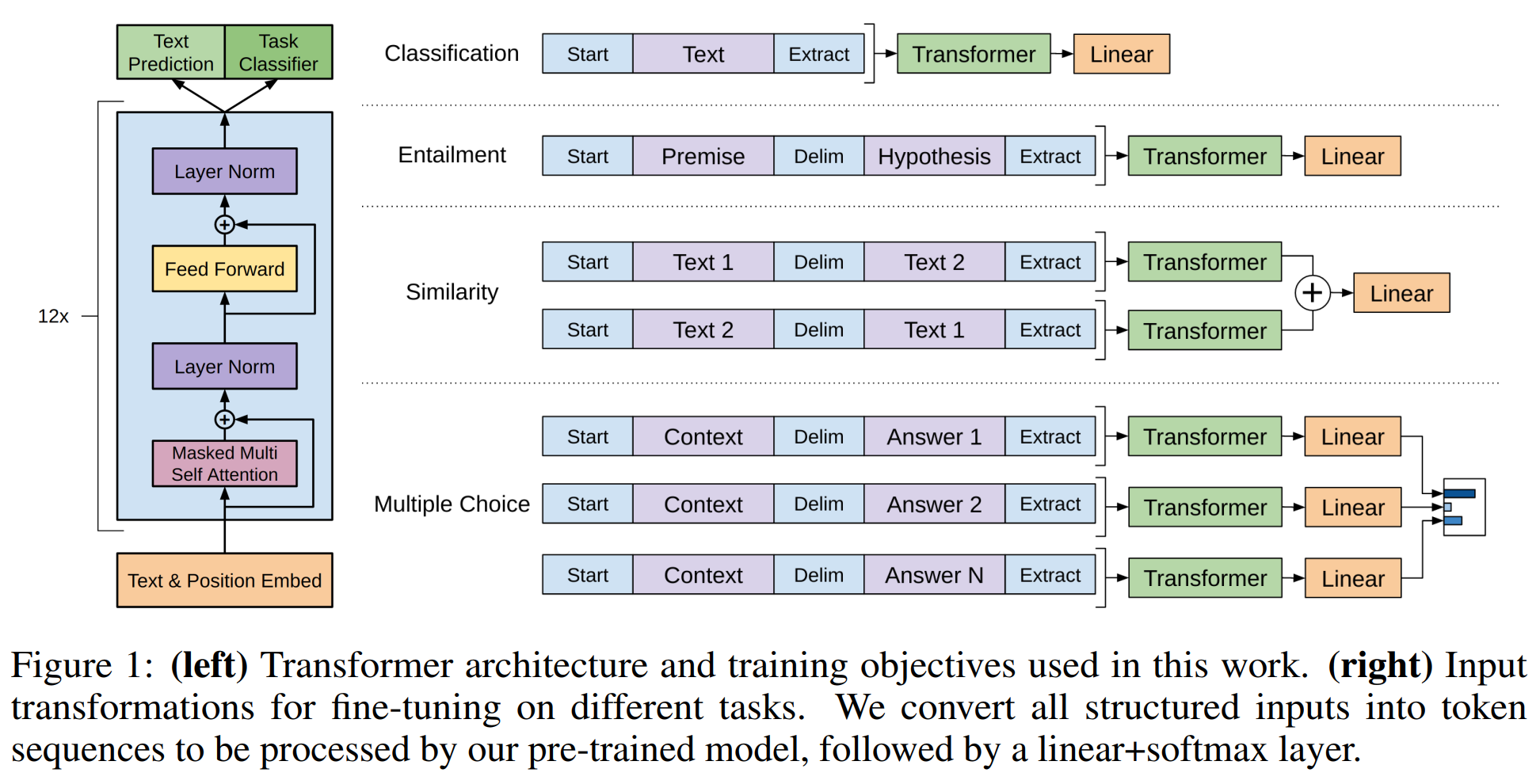
- 学习目标:正确分类
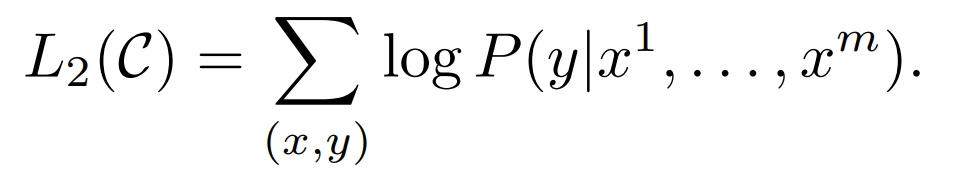
- 任务:Classification / Entailment / Similarity / Multiple Choice. 如下图右侧展示。所有的都转换为分类任务处理
GPT-2
GPT-2在预训练任务上跟GPT-1相同,但不需要fine-tune,主要关注点在大规模数据+大模型上。GPT-2创建了一个含有8 million documents,总共40个G的文本数据集(WebText),它尝试了更大的模型(参数量:GPT-1: 117M, GPT-2: 1.5B)。GPT-2实现了零样本学习任务,它只在WebText上进行生成式的预训练,模型直接用于测试,在大多数任务上,GPT-2都打败了SOTA模型。文章提供了一个很好的思想:语言模型的无监督生成式预训练 等价于 有监督的多任务学习。
-
题目:Language Models are Unsupervised Multitask Learners
-
主要思想:GPT-2展示了模型在足够大的数据集(包含上百万的网页)上进行训练后,在不经过任何task-specific的训练前提下,有能力处理各种不同的任务。(Why?)
-
数据集:WebText,该论文自己收集的数据集,包含8个million的documents(清洗后的数量,清洗前45个m),总共40个G
-
训练:和GPT-1的预训练是一样的
-
模型:一共有4种不同深度的Transformer模型(仍然是decoder only)
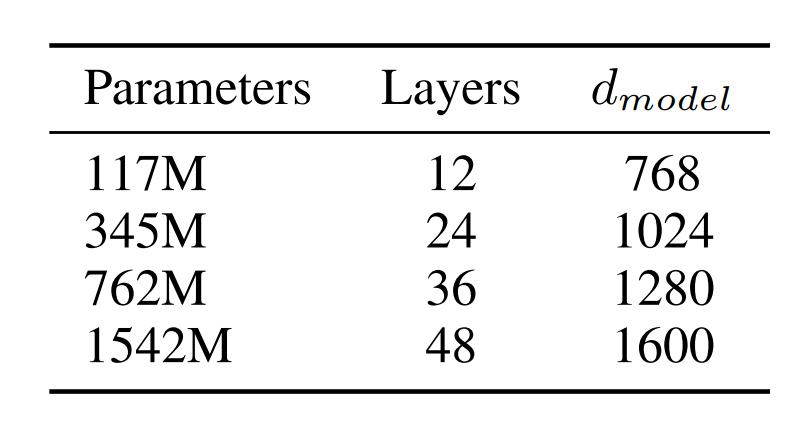
这里的12层模型等价于GPT-1,最大的模型(1.5B)也就是常说的GPT-2
那么问题来了,
-
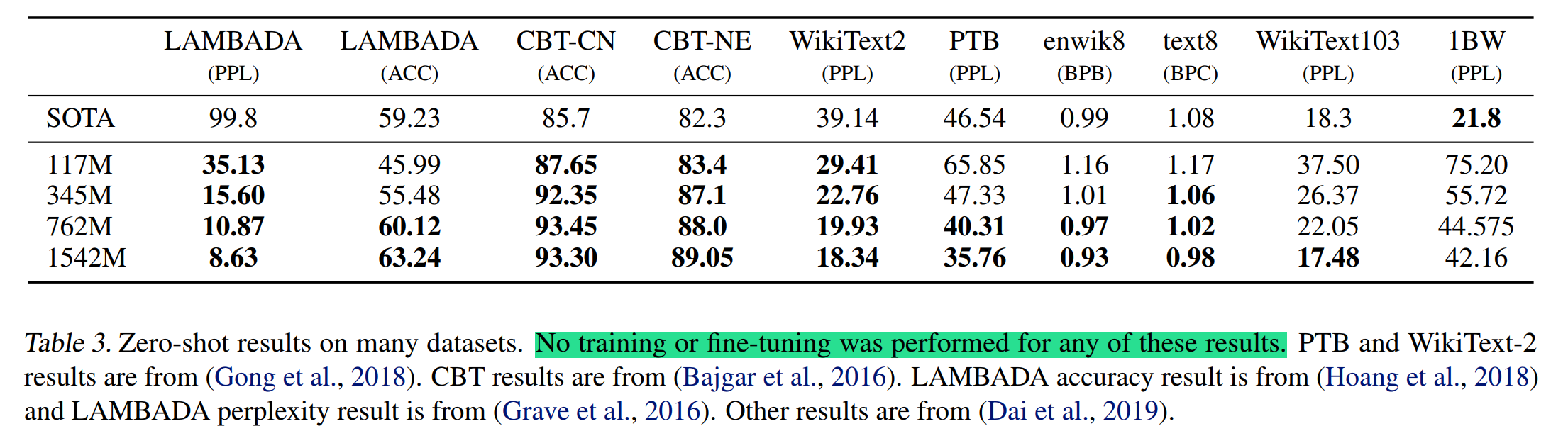
首先,为什么GPT-2能够完成zero-shot任务?如下表所示,在没有任何训练或微调的前提下,GPT-2几乎打败了SOTA模型。它的训练和GPT-1的预训练设定完全一样,为什么GPT-1需要做task-specific fine-tuning。难道只是因为数据量增大了嘛?
-
其次, GPT-2的题目:Language Models are Unsupervised Multitask Learners很奇怪,Multitask体现在哪里,为什么说语言模型是无监督多任务学习器呢?
这两个问题在这篇博客里讲得很清楚,文章中对应的说明是在 2. Approach,看博客之前,我是没理解文章的,结合博客和文章,才了解了GPT-2的思想,思想还是很牛*的。
有个例子很形象
- “The translation of word Machine Learning in Chinese is 机器学习”, 如果在这上面做无监督的训练,其实相当于对“Translation from English to Chinese, Machine Learning, 机器学习”监督训练,因为他包含的信息有:任务,样本,标签。
所以, 无监督预训练 等价于 有监督训练
GPT-3
GPT-3的预训练和GPT-2十分相似,包括模型,数据。不一样在于模型尺寸,数据量,和多样化(我的理解是测试的设定上,它包括了x-shot系列),和训练的长度。预训练任务和GPT-2也十分相似。接下来从4个方面,介绍一下GPT-3和GPT-2的不同之处。
-
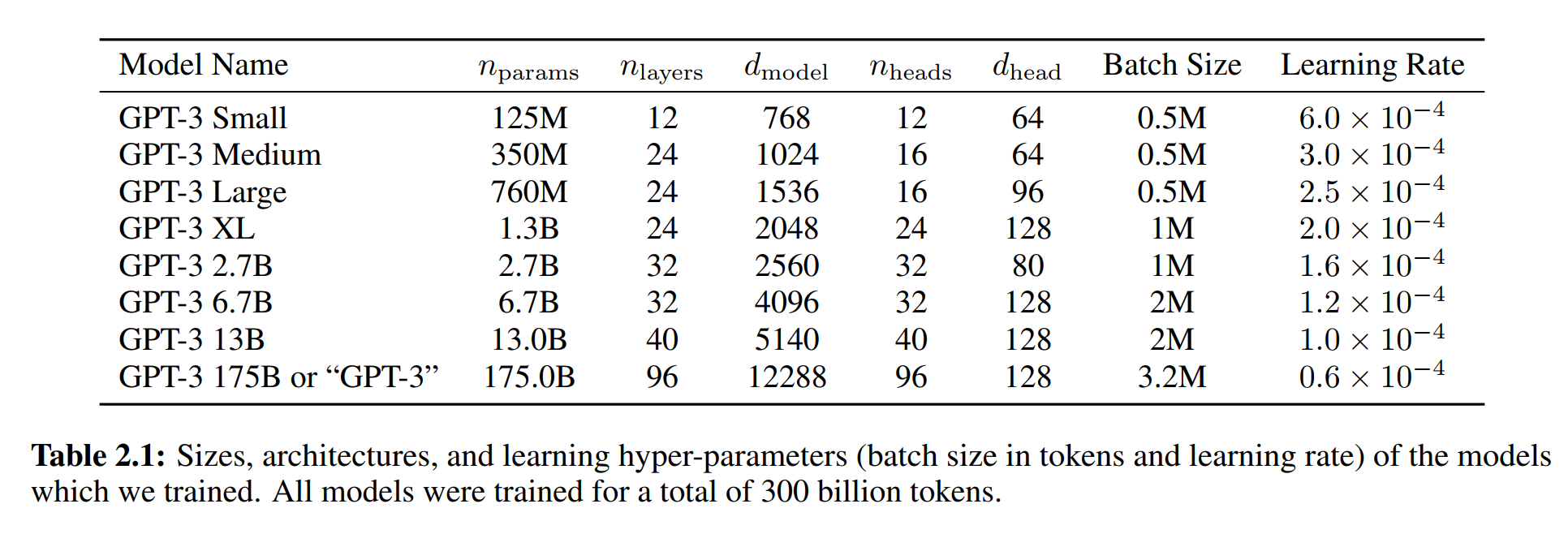
在模型上,GPT-3 考虑了更大的模型,具体信息如下表:
-
在数据上,GPT-3 大大滴扩展了数据规模
-
利用工具 [4],收集了近一万亿个字的数据集(Common Crawl)
-
然后进行数据清洗。数据清洗步骤原文描述如下
(1) we downloaded and filtered a version of CommonCrawl based on similarity to a range of high-quality reference corpora,
(2) we performed fuzzy deduplication at the document level, within and across datasets, to prevent redundancy and preserve the integrity of our held-out validation set as an accurate measure of overfitting, and
(3) we also added known high-quality reference corpora to the training mix to augment CommonCrawl and increase its diversity -
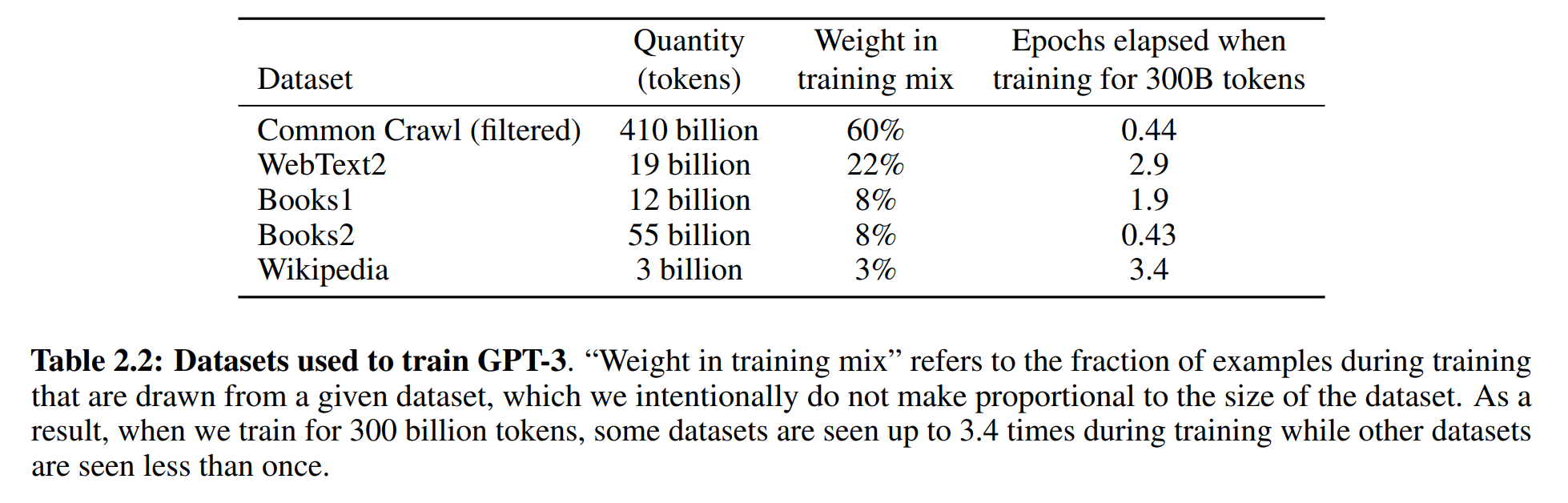
清洗后的Common Crawl包含410 billion个tokens。除它外,还用了一些别的数据集,具体信息如下:
-
-
在测试设定上, GPT-3 考虑了 x-shot(Zero-shot, one-shot, 以及few-shot)。预训练是一样的,就是在3种不同的条件(Zero-shot, one-shot, 以及few-shot)下去测试了模型。虽然GPT-3做的x-shot任务,但是它跟传统的x-shot任务不太一样。下图展示了他们之间的区别,GPT-3只将x-shot额外给的样本作为输入,不更新模型,传统的会对每一个样本进行更新。
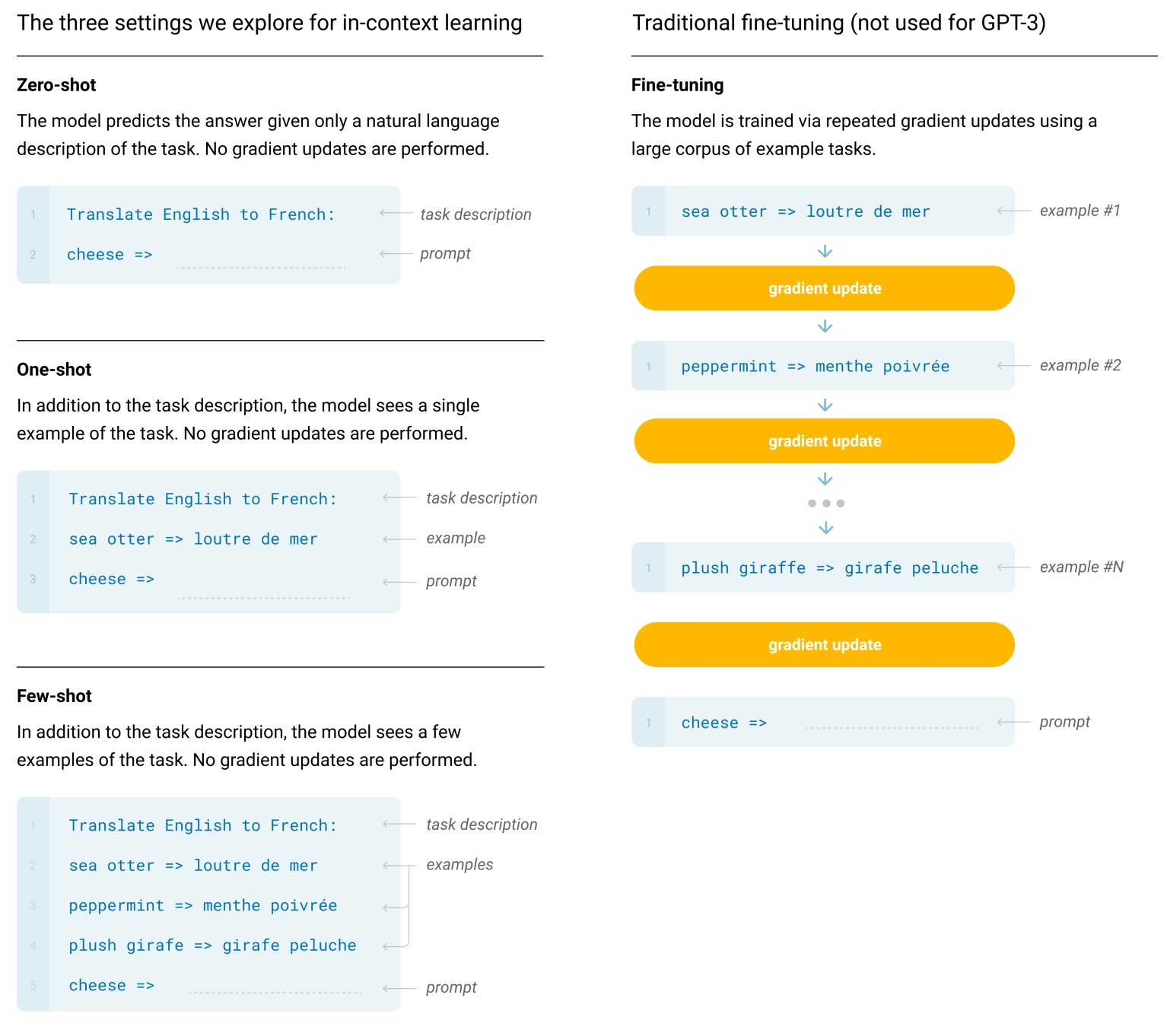
-
在训练过程上,请参考原文P9和Appendix B。训练所耗费计算资源与之前的模型对比如下图:
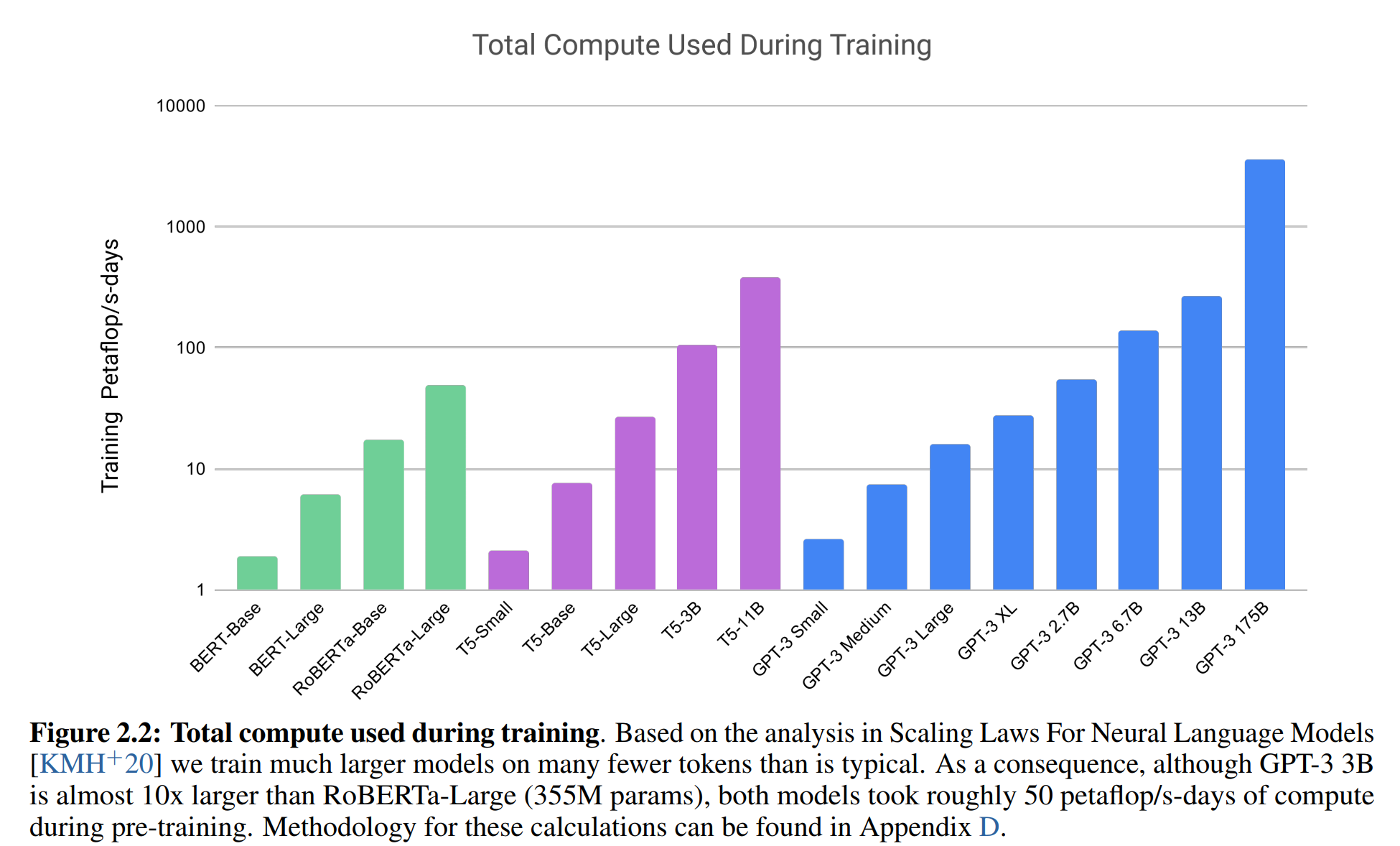
这里有个值得借鉴的经验:训练大模型时,需要 大batch size + 小学习率

