

flannel vxlan工作基本原理及常见排障方法
写在前面
最近用kubeadm鼓捣了几个cluster集群测试用,网络用的flannel。因为这些机器都不是纯净的环境(以前部署过其他的k8s或者有一些特别的设置),所以部署起来遇到了很多问题。看了下相关的文章,梳理了flannel的vxlan的工作原理,成功对这几个环境进行了排障。本文主要是相关流程的笔记记录。
容器间通信
本文以两个节点上的两个容器间通信为例,介绍网络报文的流转过程以及可能出现的问题。
flannel使用的镜像为quay.io/coreos/flannel:v0.11.0-amd64
我现在部署有两个node节点,节点ip为10.10.10.216和10.10.10.217。本文将以这两个节点上的容器为例。介绍两个容器是如何通讯的。
| 节点 | 容器IP段 | 容器IP |
|---|---|---|
| 10.10.10.216 | 10.244.0.0/24 | 10.244.0.6 |
| 10.10.10.217 | 10.244.1.0/24 | 10.244.1.2 |
首先讲下 10.244.0.6 和 10.244.1.2 两个容器间的通信流程。我们这里以从10.244.0.6向10.244.1.2 发送数据包为例。
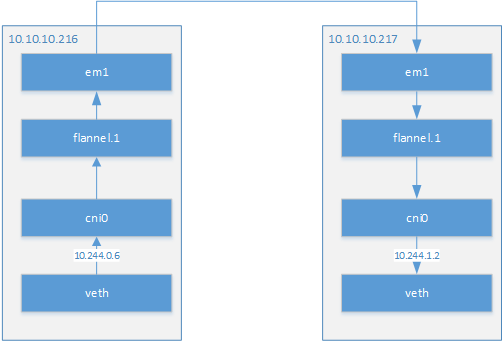
10.244.0.6容器在节点10.10.10.216。我们可以通过ip add命令查看到容器在物理机上的veth卡。
[root@node-64-216 ~]# ip add
2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether e0:db:55:13:7a:74 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.216/24 brd 10.10.10.255 scope global em1
valid_lft forever preferred_lft forever
23: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether 8a:28:fa:8e:8c:4b brd ff:ff:ff:ff:ff:ff
inet 10.244.0.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
24: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
link/ether ee:b2:9e:95:af:9d brd ff:ff:ff:ff:ff:ff
inet 10.244.0.1/24 scope global cni0
valid_lft forever preferred_lft forever
29: vethb547248d@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default
link/ether 8e:f6:51:f5:9b:a3 brd ff:ff:ff:ff:ff:ff link-netnsid 2
因为这里使用了cni接口标准,这个veth卡会桥接在cni0的网桥上。这个我们可以通过brctl show进行查看。
[root@node-64-216 ~]# brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.eeb29e95af9d no vethb547248d
vethe527455b
vetheb3a1d6b
数据包走到了cni0的网桥后,根据已经的目标ip,10.244.1.2,可以查找路由表,根据路由和掩码,选择对应的iface,也就是flannel.1。且下一跳,也就是10.244.1.0。
[root@node-64-216 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.10.10.1 0.0.0.0 UG 0 0 0 em1
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 em1
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
进入到flannel.1如何知道应该发向哪个物理机呢。这个时候,其实是通过arp来获取。可以通过arp命令查看到对应的mac地址。
[root@node-64-216 ~]# arp -e
Address HWtype HWaddress Flags Mask Iface
10.244.1.0 ether 3e:01:ed:47:de:7f CM flannel.1
这个mac地址在vxlan中,可以通过bridge fdb show来进行查看。可以看到,如果是发向3e:01:ed:47:de:7f 的地址,则目标机器在10.10.10.217机器上。则数据就会流转到10.10.10.217上了。经过vxlan封包后的数据包就会经过em1设备发向到10.10.10.217上。
[root@node-64-216 ~]# bridge fdb show
3e:01:ed:47:de:7f dev flannel.1 dst 10.10.10.217 self permanent
在10.10.10.217上,首先经过了iptables链,而后在flannel.1的Iface上则接收到该数据包。这里我们可以看到,flannel.1的mac地址就是3e:01:ed:47:de:7f。
这里我曾经就是遇到过被iptables的forward链拦住的情况。如果数据包在216的flannel.1上可以监测到,但是217的flannel.1中断了,则可以检查216到217之间的路由情况以及217的iptables链的情况。
[root@node-64-217 ~]# ip add
2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 90:b1:1c:33:b4:b1 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.217/24 brd 10.10.10.255 scope global em1
valid_lft forever preferred_lft forever
152: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether 3e:01:ed:47:de:7f brd ff:ff:ff:ff:ff:ff
inet 10.244.1.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
153: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
link/ether 36:11:ab:93:2f:6f brd ff:ff:ff:ff:ff:ff
inet 10.244.1.1/24 scope global cni0
valid_lft forever preferred_lft forever
154: veth7f8b8e9e@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default
link/ether 06:2f:35:74:cd:de brd ff:ff:ff:ff:ff:ff link-netnsid 0
到达flannel.1后,根据路由表,查看10.244.1.2的路由应送到217的cni0的网桥上。
[root@node-64-217 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.10.10.1 0.0.0.0 UG 0 0 0 em1
10.10.10.0 0.0.0.0 255.255.255.0 U 0 0 0 em1
10.244.0.0 10.244.0.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
这里我们查看cni0的网桥信息。
[root@node-64-217 ~]# brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.3611ab932f6f no veth5a89e906
veth7f8b8e9e
到达网桥后,就可以根据地址将数据送到10.244.1.2的对应的veth上,进而在容器中收到对应的数据包了。
以上就是两个处于不同物理机上的容器间发送数据包的流程。相比较来说,从容器到物理机的ping就简单多了。这个流程就是veth->cni0->em1->对端物理机ip。这里就不详细叙述了。
同一台物理机上不同容器的ping只需要经过cni0的网桥就可以了。
排障的主要思路
在梳理了数据包的正常流转过程后,就可以用tcpdump来进行问题的定位,进而排查出哪个环节出现了问题,进而查看问题产生的原因。
还是以两个物理机上的两个容器之间的通信为例,可以从一个容器向另一个容器进行ping,然后使用tcpdump分别在发起ping的容器的物理机上抓cni0,flannel.1,以及目标容器的物理机上抓flannel.1,cni0上进行抓包。看看是在哪个环节丢失的数据包。
比如在发起ping的物理机的cni0上有数据包,但是发起ping的物理机的flannel.1上没有,则可能路由发生了问题,需要查看路由表。
又比如前文中提到过的在发起ping的容器的物理机上flannel.1上可以抓到数据包,但是在目标容器的物理机的flannel.1上抓不到,则可能是二者之间的路由问题或者iptables导致的。
参考资料
- vxlan 协议原理简介 https://cizixs.com/2017/09/25/vxlan-protocol-introduction/
- VXLAN技术研究 https://blog.csdn.net/sinat_31828101/article/details/50504656
- Flannel中vxlan backend的原理和实现 http://dockone.io/article/2216
|
作者:xuxinkun 出处:xinkun的博客 链接:https://www.cnblogs.com/xuxinkun/ 本文版权归作者所有,欢迎转载。 未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 欢迎扫描右侧二维码关注微信公众号xinkun的博客进行订阅。也可以通过微信公众号留言同作者进行交流。 |

|

