
ELK日志管理系统详细安装和配置
ELK组成
ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。官方网站:https://www.elastic.co/cn/products/
Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(如,搜索)。
Kibana 是一个开源和免费的工具,它Kibana可以为Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
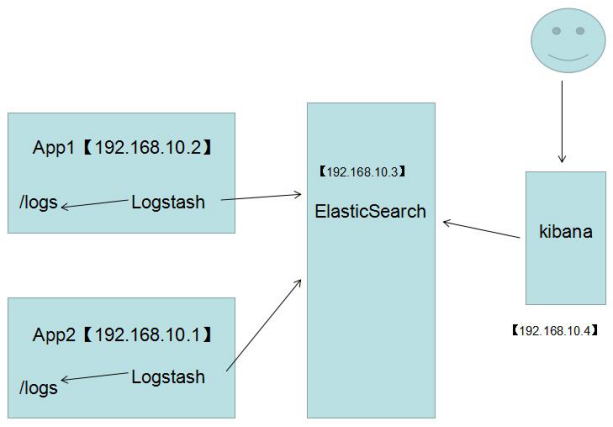
1. 四大组件
Logstash: logstash server端用来搜集日志;
Elasticsearch: 存储各类日志;
Kibana: web化接口用作查寻和可视化日志;
Logstash Forwarder: logstash client端用来通过lumberjack 网络协议发送日志到logstash server;
2. Elasticsearch 简介和安装(ELK的三个组建版本必须保持一致)
2.1 ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
2.2 从ELK官网下载Elasticsearch:
https://www.elastic.co/downloads/elasticsearch
下载elasticsearch-6.1.0.tar.gz的tar包后,
使用 tar -xvf elasticsearch-5.2.1.tar 命令解压,使用cd命令进入文件夹目录;
启动的时候一定要注意,因为es不可以进行root账户启动,所以你还需要开启一个elsearch账户。
groupadd elsearch #新建elsearch组
useradd elsearch -g elsearch -p elasticsearch #新建一个elsearch用户
chown -R elsearch:elsearch ./elasticsearch #指定elasticsearch所属elsearch组
接下来我们默认启动就好了,什么也不用配置,然后在日志中大概可以看到开启了9200,9300端口。
进入bin目录,使用./elasticsearch 命令启动elasticsearch,如果没有出现报错信息的话!这个时候,已经成功启动了!
3. Logstash 安装
Logstash官方文档地址:
https://www.elastic.co/guide/en/logstash/current/index.html
* 一、Logstash 的下载和安装*
3.1 下载对应的版本:
https://www.elastic.co/downloads/past-releases/logstash-6-4-3
解压:
使用tar -xvf logstash-5.1.1.tar.gz 命令解压文件,解压后使用cd命令进入文件夹内部:
主要文件夹包含bin、data、lib、config等。其中bin包含了一写可执行脚本文件,data是用于存储数据的,lib是一些系统所依赖的jar文件,config包含一些配置文件。
解压完之后,我们到config目录中新建一个logstash.conf配置。
[root@slave1 config]# ls
jvm.options log4j2.properties logstash.conf logstash.yml startup.options
[root@slave1 config]# pwd/usr/myapp/logstash/config
[root@slave1 config]# vim logstash.conf
然后做好input ,filter,output三大块, 其中input是吸取logs文件下的所有log后缀的日志文件,filter是一个过滤函数,这里不用配置,output配置了导入到
hosts为127.0.0.1:9200的elasticsearch中,每天一个索引。
input { file { type => "log" path => "/logs/*.log" start_position => "beginning" } } output { stdout { codec => rubydebug { } } elasticsearch { hosts => "127.0.0.1" index => "log-%{+YYYY.MM.dd}" } }
配置完了之后,我们就可以到bin目录下启动logstash了,配置文件设置为conf/logstash.conf,从下图中可以看到,当前开启的是9600端口。
3.2 测试Logstash安装,运行最基本的Logstash管道:
cd logstash-5.1.1
bin/logstash -e 'input { stdin { } } output { stdout {} }'
-e 参数表示执行后边的语句,标志使您能够直接从命令行指定配置。在命令行中指定配置允许您快速测试配置,而无需在迭代之间编辑文件。示例中的管道从标准输入stdin获取输入,并以结构化格式将输入移动到标准输出stdout。
3.3 等待片刻等提示信息之后,就可以在控制台输入任何内容,他都会输出:
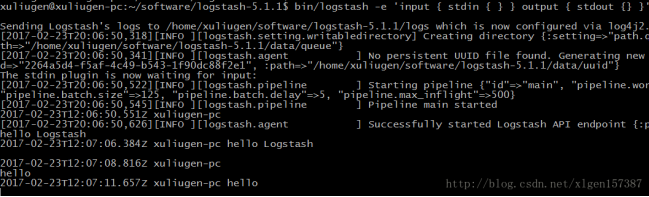
至此,一个Logstash的安装与使用完成!
然后在终端上运行:
bin/logstash -f logstash.conf
-f 表示指定使用哪一个配置文件进行执行。
* 三、Logstash基本原理*
Logstash管道有两个必需的元素,输入和输出,以及一个可选元素,过滤器。输入插件从源消耗数据,过滤器插件根据您指定的内容修改数据,输出插件将数据写入目标。如下图:
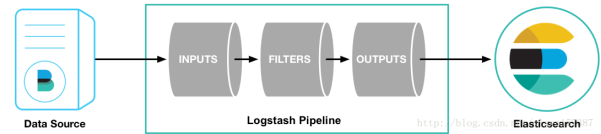
Logstash事件处理管道有三个阶段:输入→过滤器→输出。输入生成事件,过滤器修改它们,并将输出发送到其他地方。输入和输出支持编解码器,使您能够在数据进入或退出流水线时对其进行编码或解码,而无需使用单独的过滤器。也就是说,其实Logstash是一个input–decode –filter–encode–output的数据流!
根据上图可以看到需要将Logstash和Elasticsearch进行关联,这样的话才可以将数据输入到Elasticsearch进行处理。
(1)修改上一篇文章中自己定义的配置文件 logstash.conf,修改为如下内容:
input { beats { port => "5044" } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } geoip { source => "clientip" } } output { elasticsearch { hosts => [ "localhost:9200" ] } } 然后output输出为elasticsearch,退出保存! (2)启动Filebeat ./filebeat -e -c filebeat.yml -d "publish" (3)启动Logstash bin/logstash -f logstash.conf
4. Kibana 安装和配置
4.1 简介
Kibana是一个开源的分析和可视化平台,旨在与Elasticsearch一起工作。您使用Kibana搜索,查看和与存储在Elasticsearch索引中的数据进行交互。您可以轻松地在各种图表,表格和地图中执行高级数据分析和可视化数据。
4.2 下载-安装
下载
https://artifacts.elastic.co/downloads/kibana/kibana-6.4.3-linux-x86_64.tar.gz
使用tar -xvf kibana-5.2.1-linux-x86_64.tar.gz命令进行解压,进入目录
配置Kibana
Kibana的配置文件是在config/kibana.yml
修改配置文件: vi /config/kibana.yml (添加如下配置)
#配置本机ip
server.host: "http://localhost:9200"
#配置es集群url
elasticsearch.url: "http://192.168.177.132:9200"
启动:
>bin/kibana & //&后台启动
[root@slave1 kibana]# cd bin [root@slave1 bin]# ls kibana kibana-plugin nohup.out [root@slave1 bin]# ./kibana log [01:23:27.650] [info][status][plugin:kibana@5.2.0] Status changed from uninitialized to green - Ready log [01:23:27.748] [info][status][plugin:elasticsearch@5.2.0] Status changed from uninitialized to yellow - Waiting for Elasticsearch log [01:23:27.786] [info][status][plugin:console@5.2.0] Status changed from uninitialized to green - Ready log [01:23:27.794] [warning] You're running Kibana 5.2.0 with some different versions of Elasticsearch. Update Kibana or Elasticsearch to the same version to prevent compatibility issues: v5.6.4 @ 192.168.23.151:9200 (192.168.23.151) log [01:23:27.811] [info][status][plugin:elasticsearch@5.2.0] Status changed from yellow to green - Kibana index ready log [01:23:28.250] [info][status][plugin:timelion@5.2.0] Status changed from uninitialized to green - Ready log [01:23:28.255] [info][listening] Server running at http://0.0.0.0:5601 log [01:23:28.259] [info][status][ui settings] Status changed from uninitialized to green - Ready
访问:http://192.168.177.132:5601/
浏览器中输入:http://192.168.23.151:5601/ 你就可以打开kibana页面了,,默认让我指定一个查看的Index。
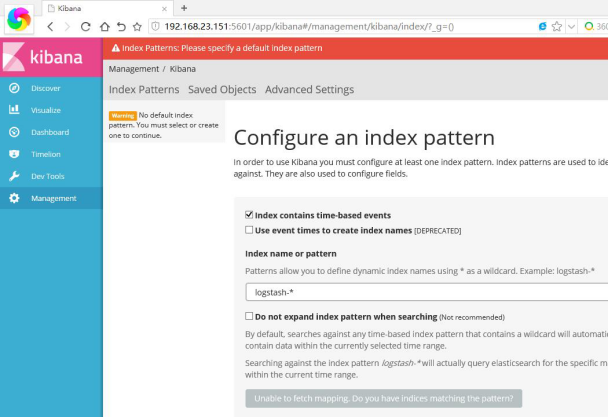
接下来我们在本机的/logs文件夹下创建一个简单的1.log文件,内容为“hello world”,然后在kibana上将logstash-* 改成 log* ,Create按钮就会自动出来。
[root@slave1 logs]# echo 'hello world' > 1.log
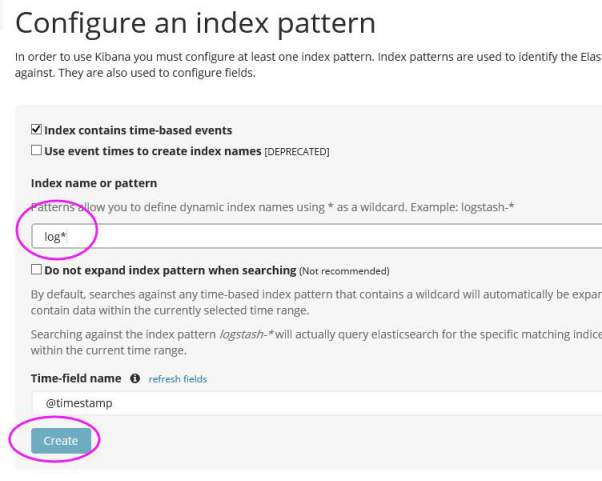
进入之后,点击Discover,你就可以找到你输入的内容啦~~~~ 是不是很帅气。。。
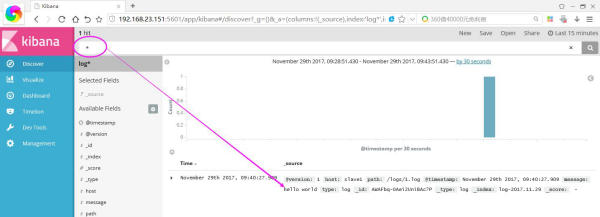
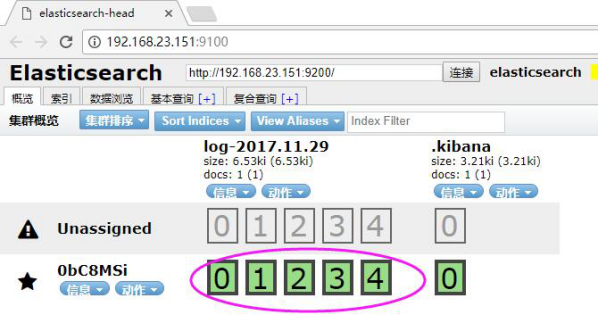
如果你装了head安装包,你还可以看到它确实带了日期模式的Index索引,还自带5个默认分片数。
5.Elasticsearch的扩展
根据业务需求,可添加中文分词器,查阅相关文档官方建议安装ik分词器,目前效果最匹配
5.1 ik分词器的安装
①去github上直接下载直接编译好的zip文件。
→ https://github.com/medcl/elasticsearch-analysis-ik/releases
选择和已经下载的elasticsearch版本兼容的ik。
②下载好了之后解压,将解压后的文件夹放在elasticsearch目录下的plugins目录下,并重命名为analysis-ik
③上传至之前安装的/home/learn/elasticsearch/plugins下,并进行解压与重命名,重命名为iK:
unzip elasticsearch-analysis-ik-6.4.3.zip -d ik-analyzer
④ 在ES的配置文件config/elasticsearch.yml中增加ik的配置,在最后增加:
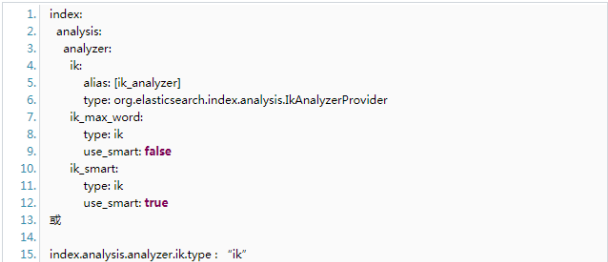
⑤重启elasticsearch,进入elasticsearch/bin,执行./elasticsearch
5.2 ik分词器的使用
Ik带有两个分词器:
ik_max_word :会将文本做最细粒度的拆分;尽可能多的拆分出词语
ik_smart:会做最粗粒度的拆分;已被分出的词语将不会再次被其它词语占有
看下边的例子就会明白他们的区别了:
一般在索引时采用细粒度,搜索时采用粗粒度
ik_smart正确请求方式如下(直接复制粘贴到xshell,回车即可):

返回结果:

ik_max_word正确请求方式如下:

返回结果:




自定义词库:
在plugins下的ik下的config中,有一个IKAnalyzer.cfg.xml,文件内容如下:
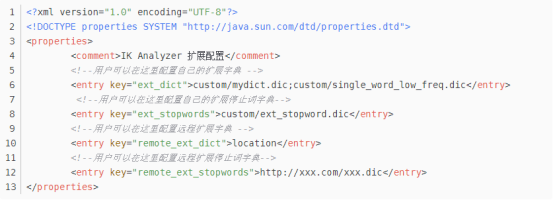
指定自定义的扩展字典,然后创建该xxx.dic文件,把自定义的专用不想被拆分的词语添加进去,编码为utf-8,重启后生效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号