如何突破百度的拦截,抓取百度搜索结果
如果你使用requests模块去抓取百度搜索结果,你现在是抓取不到的,你只能抓取到【百度安全验证】页。
代码:
import requests #导入request包
url = "https://www.baidu.com/s?" #需要爬虫的地址
header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0'
}#在头部加入请求载体的身份标识,来进行UA伪装来绕过UA检测,必须放在字典中
content = "徐小波"
url_last = url + 'wd=' + f'{content}' + '&pn=0' #需要爬的url地址
#print (url_last)
res = requests.get(url_last,headers=header)
res.encoding = res.apparent_encoding
print (res.url)
print (res.text)
with open('1.8-1.html','w',encoding='utf-8') as file:
file.write(res.text) ##在请求到的数据放在目录下18-1.html文件中.
效果:
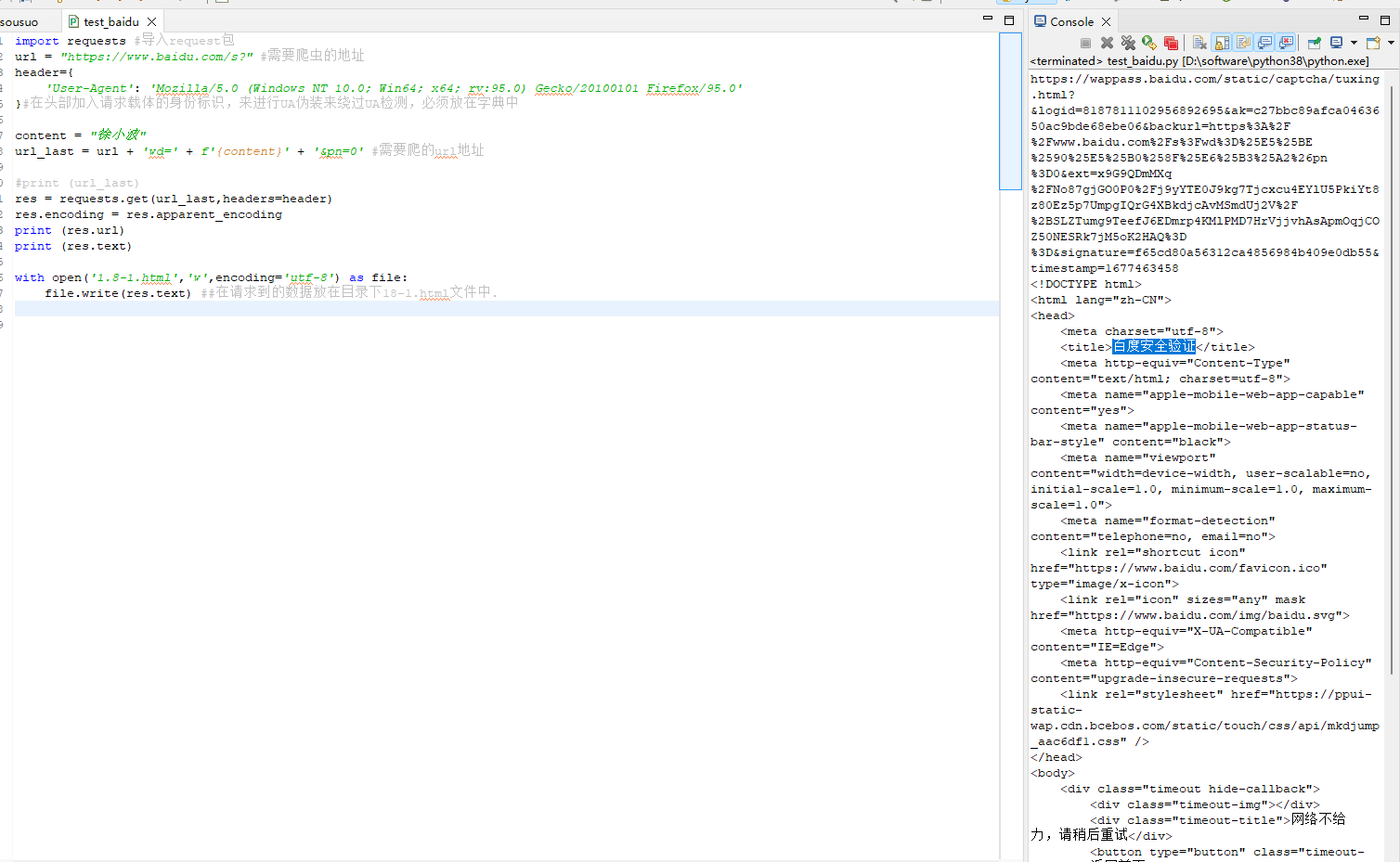
那么就换一种思路:
代码:
from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains import csv import threading import time from lxml import etree from queue import Queue import re,sys class BaiduSpider(object): def __init__(self): self.url = 'https://www.baidu.com/' self.page_num = 1 chrome_driver = r"C:\Users\jsb\AppData\Roaming\Python\Python38\site-packages\selenium\webdriver\chrome\chromedriver.exe" path = Service(chrome_driver) self.driver = webdriver.Chrome(service=path) self.qtitle = Queue() self.qurl = Queue() self.searchkw = '徐小波河北' self.titlekw = '河北大学-徐小波' # 解析页面 def parse_page(self): response = self.driver.page_source response = response.replace('<em>', '') response = response.replace('</em>', '') html = etree.HTML(response) hrefs = html.xpath('//div[@class="result c-container xpath-log new-pmd"]//h3[@class="c-title t t tts-title"]/a/@href') titles = html.xpath('//div[@class="result c-container xpath-log new-pmd"]//h3[@class="c-title t t tts-title"]/a/text()') flag = html.xpath('//div[@id="page"]//a[last()]//@class')[0] return flag, hrefs, titles # 获取每一页数据, 开趴. def get_page_html(self): print("进入百度首页...") self.driver.get(self.url) time.sleep(3) self.driver.find_element(By.NAME, 'wd').send_keys(self.searchkw) self.driver.find_element(By.ID, 'su').click() print("开始抓取首页...") time.sleep(3) flag, urls, titles = self.parse_page() index = 0 for title in titles: if self.titlekw in title: self.qtitle.put(title) self.qurl.put(urls[index]) else: pass index = index + 1 response = self.driver.page_source html = etree.HTML(response) hasnext = html.xpath('//div[@id="page"]//a[last()]//text()')[0] hasnext = hasnext.strip() while hasnext == '下一页 >': self.page_num = self.page_num + 1 print("开始抓取第%s页..." % self.page_num) self.driver.find_element(By.XPATH, '//div[@id="page"]//a[last()]').click() time.sleep(3) flag, urls, titles = self.parse_page() index = 0 for title in titles: if self.titlekw in title: self.qtitle.put(title) self.qurl.put(urls[index]) else: pass index = index + 1 response = self.driver.page_source html = etree.HTML(response) hasnext = html.xpath('//div[@id="page"]//a[last()]//text()')[0] hasnext = hasnext.strip() print("抓取完毕") # 获取详情页 def get_detail_html(self): while True: if self.qtitle.qsize() != 0: title = self.qtitle.get() url = self.qurl.get() print("%s:%s\n" % (title, url)) js = "window.open('"+url+"')" self.driver.execute_script(js) time.sleep(3) windows = self.driver.window_handles self.driver.switch_to.window(windows[0]) else: time.sleep(5) def run(self): # 获取每页URL c = threading.Thread(target=self.get_page_html) c.start() # 解析详情页 t = threading.Thread(target=self.get_detail_html) t.start() if __name__ == '__main__': zhuce = BaiduSpider() zhuce.run()
效果:

控制台输出:
进入百度首页... 开始抓取首页... 开始抓取第2页... 用Python执行程序的4种方式 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=HFjw_CWpBpx7g1MonBIcZTCYZfjDUyF4PxNZ7nEqJsZhu9REyWfs71JaJNpIvduzyoS-oa4hi3NetQGDT7T-ua 开始抓取第3页... ...中如何实现对比两张相似的图片 - 河北大学-徐小波 - 博...:http://www.baidu.com/link?url=HFjw_CWpBpx7g1MonBIcZTCYZfjDUyF4PxNZ7nEqJsZhu9REyWfs71JaJNpIvduzfxgY9xJ1pZGe6_ZdrHve3_ 开始抓取第4页... springboot整合es - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=uDTzdgrHSrsJqZJrdHKCLmsVy970GU_bmn8DPAcw11J-aurFI_DdZHAsVw_2y15X42CV3m_V0pcejvEEERiVKK 开始抓取第5页... https ssl证书 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=uDTzdgrHSrsJqZJrdHKCLmsVy970GU_bmn8DPAcw11J-aurFI_DdZHAsVw_2y15Xtv6NZHl2F8u4VANsLafUpa 开始抓取第6页... python做ocr卡证识别很简单 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=eZucRbOlaaNQqJwRz8hrV80ywnPslukA58tB8nQlJKWOGUx3OOLbkmoVsBi8ZLiK0wyeMt-4bkyNHuxesVYo0_ 开始抓取第7页... CA如何吊销签署过的证书 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=0e0omF6M14tFrYvWs-S_oeoOwFWdQZWEaBnworgqPPYXHS1_ifoDJwuQu7Ap0CEzv1wddYzCcauXqlrQFE_Z_K 开始抓取第8页... Appium错误记录 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=0e0omF6M14tFrYvWs-S_oeoOwFWdQZWEaBnworgqPPYXHS1_ifoDJwuQu7Ap0CEzIrWcWp6_sk7NTkArM3pzBq 开始抓取第9页... ...客户端证书”后,才能访问网站 - 河北大学-徐小波 - 博...:http://www.baidu.com/link?url=0e0omF6M14tFrYvWs-S_oeoOwFWdQZWEaBnworgqPPYXHS1_ifoDJwuQu7Ap0CEzFi4SdtIMoB9Tl3wMCglMuq 开始抓取第10页... elasticsearch win指定jdk版本 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=N_eMyl7Vf0Y2Gr0OEjgMO07vFXdmJVpKsNSsLrmnQKM_tHNTpovNV17TACGNBWjIgO8SAB_9DlG-4dtO9ocIsq 开始抓取第11页... Springboot整合swagger3 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=N_eMyl7Vf0Y2Gr0OEjgMO07vFXdmJVpKsNSsLrmnQKM_tHNTpovNV17TACGNBWjIQ02RvFxEclZenyJ9XJpOHK 开始抓取第12页... springboot上传下载文件原来这么丝滑 - 河北大学-徐小波 -...:http://www.baidu.com/link?url=N_eMyl7Vf0Y2Gr0OEjgMO07vFXdmJVpKsNSsLrmnQKM_tHNTpovNV17TACGNBWjIxruPab38fqcdNVRqVlzbiK 开始抓取第13页... NGINX 配置 SSL 双向认证 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=0jO3h8FOuUZvnJvvAsfOmqHBVUyADuEpMffGibacA7gQUAUoCGXpRFI096t84ZmVJF0Txf4i4giZ__sUZaEpWa 开始抓取第14页... [加密]公钥/私钥/数字签名理解 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=0jO3h8FOuUZvnJvvAsfOmqHBVUyADuEpMffGibacA7gQUAUoCGXpRFI096t84ZmV4GMiXM2GR7Q-EYrxfYD5n_ 开始抓取第15页... Nginx常见的错误及解决方法 - 河北大学-徐小波 - 博客园:http://www.baidu.com/link?url=0jO3h8FOuUZvnJvvAsfOmqHBVUyADuEpMffGibacA7gQUAUoCGXpRFI096t84ZmV_YD-fkBF_jo9UKqmlfIuRK 开始抓取第16页... 开始抓取第17页... 开始抓取第18页...
这样抓百度也没脾气,因为你模拟的是用户
本文来自博客园,作者:河北大学-徐小波,转载请注明原文链接:https://www.cnblogs.com/xuxiaobo/p/17158734.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号