


高性能的Redis之:Redis单线程为什么如此之快?
一、概述
Redis的高并发和快简单可以归结为一下几点:
1.Redis是基于内存的;
2.Redis是单线程的;
3.Redis使用多路复用技术。
4.高效的数据结构
但具体怎么做的呢,下面来详细看下每一点的具体实现吧~
二、基于内存实现
Redis 是基于内存的数据库,那不可避免的就要与磁盘数据库做对比。对于磁盘数据库来说,是需要将数据读取到内存里的,这个过程会受到磁盘 I/O 的限制。
而对于内存数据库来说,本身数据就存在于内存里,也就没有了这方面的开销。
三、合适的线程模型
Redis 快的原因还有一个是因为使用了合适的线程模型:
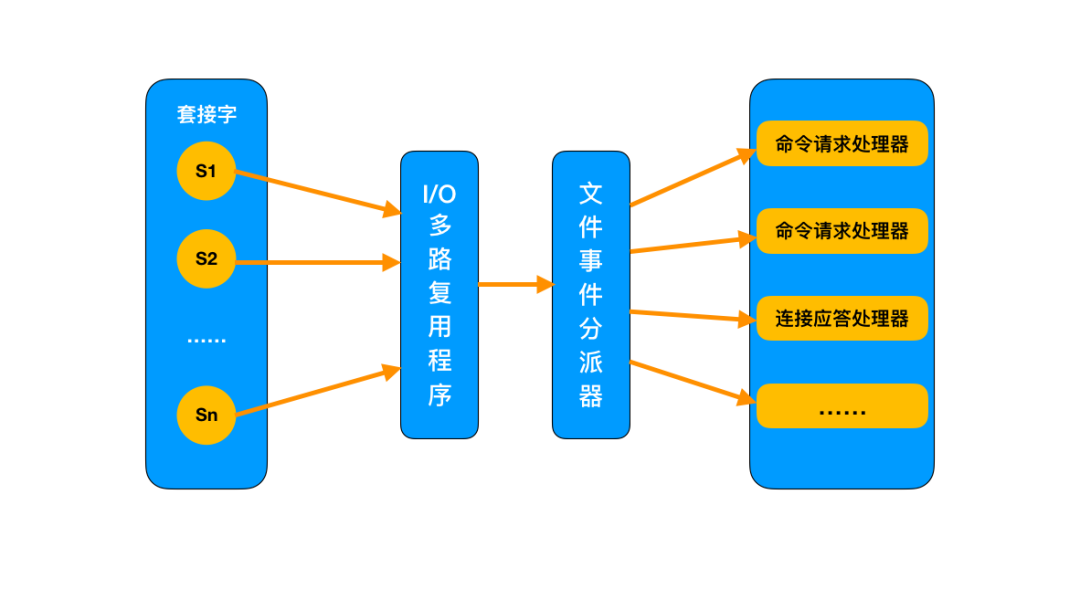
1、I/O多路复用模型
Redis 采用网络IO多路复用技术来保证在多连接的时候, 系统的高吞吐量。
多路-指的是多个socket连接,复用-指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。
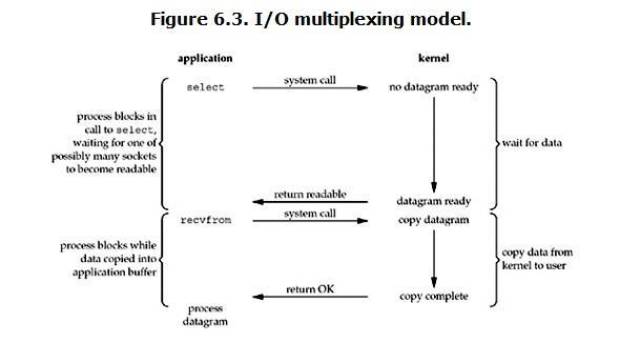
-
I/O :网络 I/O
-
多路:多个 TCP 连接
-
复用:共用一个线程或进程
生产环境中的使用,通常是多个客户端连接 Redis,然后各自发送命令至 Redis 服务器,最后服务端处理这些请求返回结果。
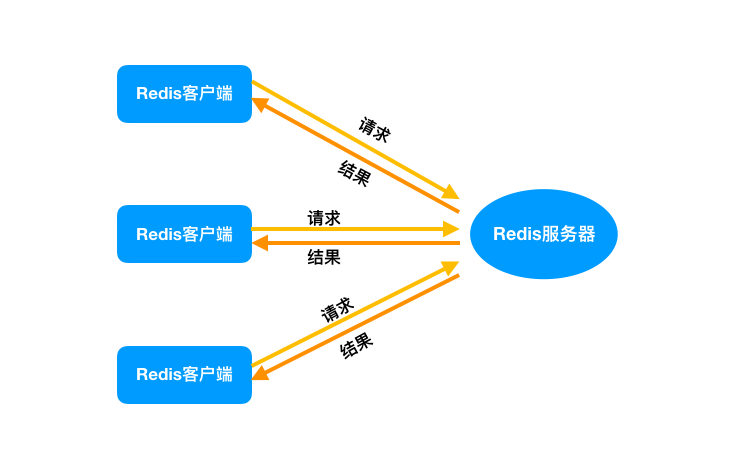
应对大量的请求,Redis 中使用 I/O 多路复用程序同时监听多个套接字,并将这些事件推送到一个队列里,然后逐个被执行。最终将结果返回给客户端。
2、单线程模型,避免上下文切换
你一定听说过,Redis 是单线程的。那么单线程的 Redis 为什么会快呢?
因为多线程在执行过程中需要进行 CPU 的上下文切换,这个操作比较耗时。Redis 又是基于内存实现的,对于内存来说,没有上下文切换效率就是最高的。多次读写都在一个CPU 上,对于内存来说就是最佳方案。
3、为什么Redis是单线程的
<1>.官方答案
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
<2>.性能指标
关于Redis的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
<3>.详细原因
1)不需要各种锁的性能消耗
Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,在hash当中添加或者删除
一个对象。这些操作可能就需要加非常多的锁,导致的结果是同步开销大大增加。
总之,在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
2)单线程多进程集群方案
单线程的威力实际上非常强大,每核心效率也非常高,多线程自然是可以比单线程有更高的性能上限,但是在今天的计算环境中,即使是单机多线程的上限也往往不能满足需要了,需要进一步摸索的是多服务器集群化的方案,这些方案中多线程的技术照样是用不上的。
所以单线程、多进程的集群不失为一个时髦的解决方案。
3)CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。
但是如果CPU成为Redis瓶颈,或者不想让服务器其他CUP核闲置,那怎么办?
可以考虑多起几个Redis进程,Redis是key-value数据库,不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。
四、高效的数据结构
Redis 中有多种数据类型,每种数据类型的底层都由一种或多种数据结构来支持。正是因为有了这些数据结构,Redis 在存储与读取上的速度才不受阻碍。这些数据结构有什么特别的地方,各位看官接着往下看:
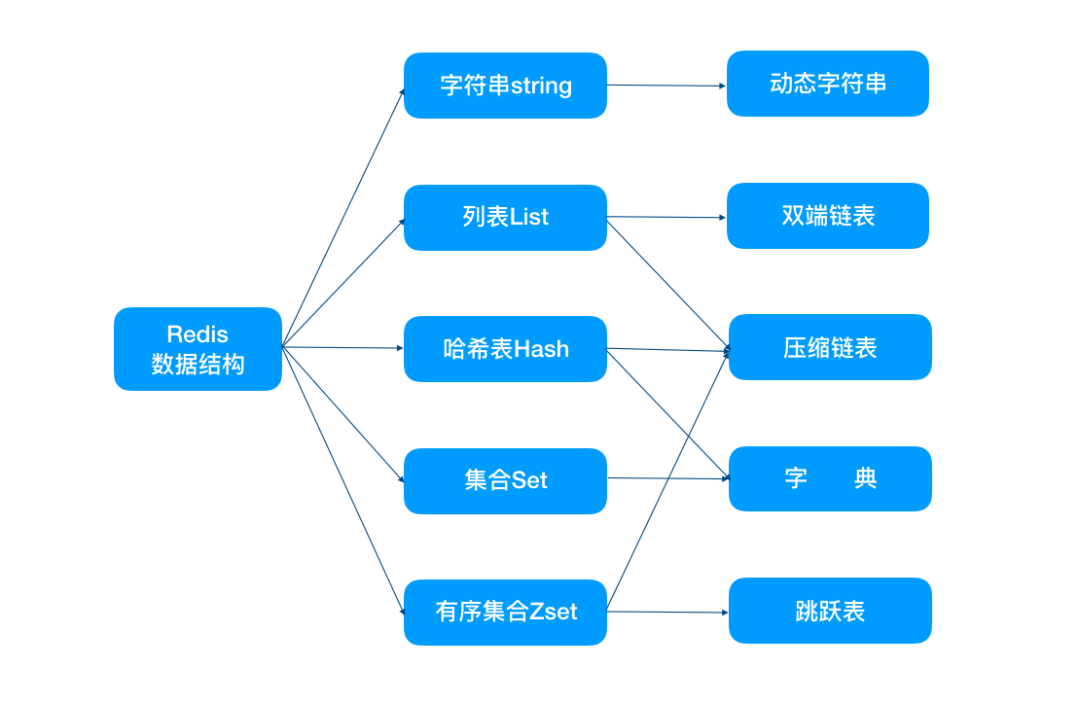
1、简单动态字符串
这个名词可能你不熟悉,换成 SDS 肯定就知道了。这是用来处理字符串的。了解 C 语言的都知道,它是有处理字符串方法的。而 Redis 就是 C 语言实现的,那为什么还要重复造轮子?我们从以下几点来看:
(1)字符串长度处理
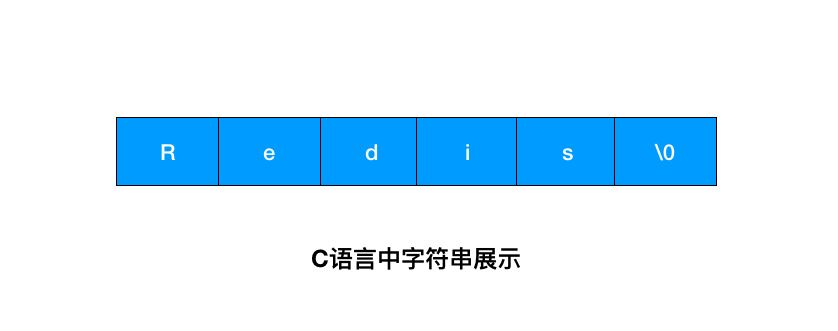
这个图是字符串在 C 语言中的存储方式,想要获取 「Redis」的长度,需要从头开始遍历,直到遇到 '\0' 为止。
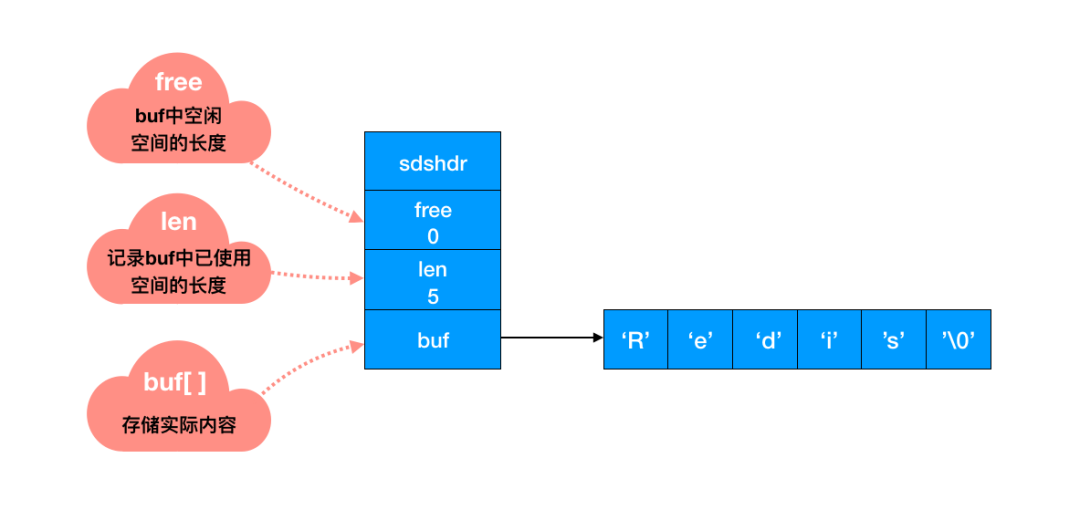
Redis 中怎么操作呢?用一个 len 字段记录当前字符串的长度。想要获取长度只需要获取 len 字段即可。你看,差距不言自明。前者遍历的时间复杂度为 O(n),Redis 中 O(1) 就能拿到,速度明显提升。
(2)内存重新分配
C 语言中涉及到修改字符串的时候会重新分配内存。修改地越频繁,内存分配也就越频繁。而内存分配是会消耗性能的,那么性能下降在所难免。
而 Redis 中会涉及到字符串频繁的修改操作,这种内存分配方式显然就不适合了。于是 SDS 实现了两种优化策略:
-
空间预分配
对 SDS 修改及空间扩充时,除了分配所必须的空间外,还会额外分配未使用的空间。
具体分配规则是这样的:SDS 修改后,len 长度小于 1M,那么将会额外分配与 len 相同长度的未使用空间。如果修改后长度大于 1M,那么将分配1M的使用空间。
-
惰性空间释放
当然,有空间分配对应的就有空间释放。
SDS 缩短时,并不会回收多余的内存空间,而是使用 free 字段将多出来的空间记录下来。如果后续有变更操作,直接使用 free 中记录的空间,减少了内存的分配。
(3)二进制安全
你已经知道了 Redis 可以存储各种数据类型,那么二进制数据肯定也不例外。但二进制数据并不是规则的字符串格式,可能会包含一些特殊的字符,比如 '\0' 等。
前面我们提到过,C 中字符串遇到 '\0' 会结束,那 '\0' 之后的数据就读取不上了。但在 SDS 中,是根据 len 长度来判断字符串结束的。
看,二进制安全的问题就解决了。
2、双端链表
列表 List 更多是被当作队列或栈来使用的。队列和栈的特性一个先进先出,一个先进后出。双端链表很好的支持了这些特性。
(1)前后节点
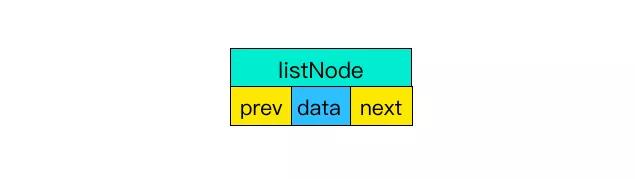
链表里每个节点都带有两个指针,prev 指向前节点,next 指向后节点。这样在时间复杂度为 O(1) 内就能获取到前后节点。
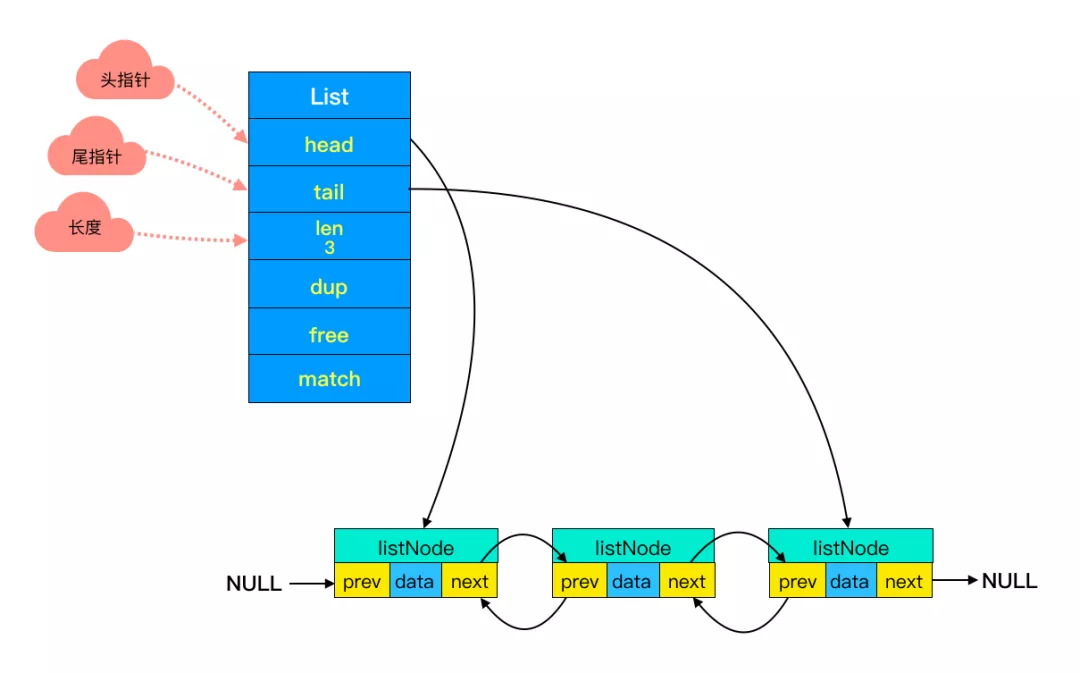
(2)头尾节点

你可能注意到了,头节点里有 head 和 tail 两个参数,分别指向头节点和尾节点。这样的设计能够对双端节点的处理时间复杂度降至 O(1) ,对于队列和栈来说再适合不过。同时链表迭代时从两端都可以进行。
(3)链表长度
头节点里同时还有一个参数 len,和上边提到的 SDS 里类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到 len 值就可以了,这个时间复杂度是 O(1)。
你看,这些特性都降低了 List 使用时的时间开销。
3、压缩列表
双端链表我们已经熟悉了。不知道你有没有注意到一个问题:如果在一个链表节点中存储一个小数据,比如一个字节。那么对应的就要保存头节点,前后指针等额外的数据。
这样就浪费了空间,同时由于反复申请与释放也容易导致内存碎片化。这样内存的使用效率就太低了。
于是,压缩列表上场了!
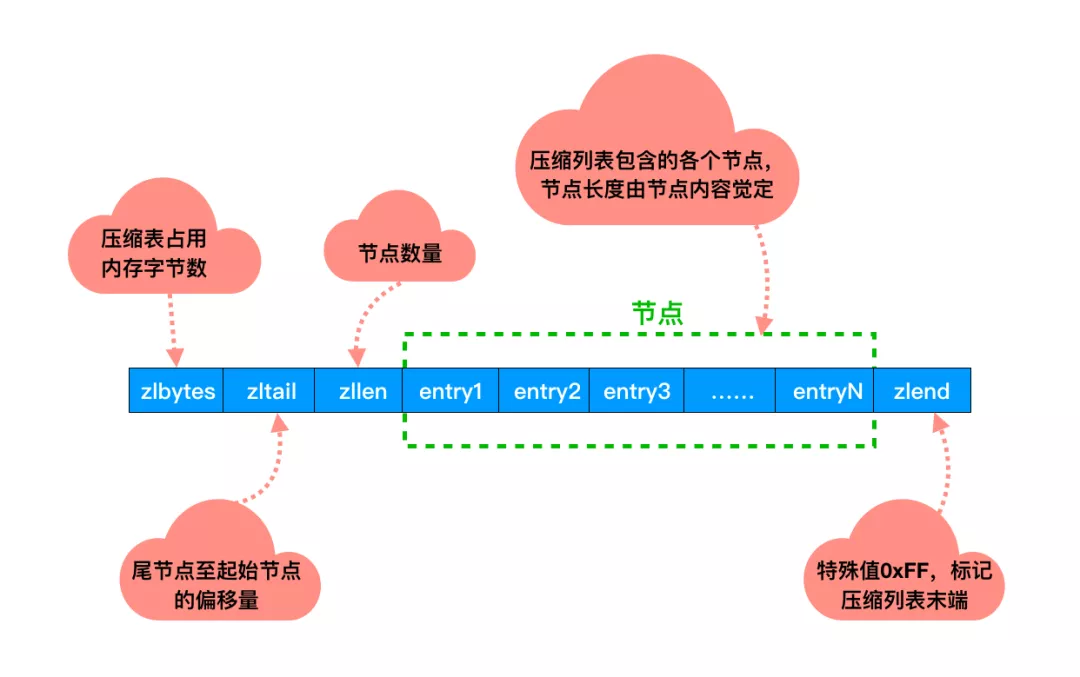
它是经过特殊编码,专门为了提升内存使用效率设计的。所有的操作都是通过指针与解码出来的偏移量进行的。
并且压缩列表的内存是连续分配的,遍历的速度很快。
4、字典
Redis 作为 K-V 型数据库,所有的键值都是用字典来存储的。
日常学习中使用的字典你应该不会陌生,想查找某个词通过某个字就可以直接定位到,速度非常快。这里所说的字典原理上是一样的,通过某个 key 可以直接获取到对应的value。
字典又称为哈希表,这点没什么可说的。哈希表的特性大家都很清楚,能够在 O(1) 时间复杂度内取出和插入关联的值。
5、跳跃表
作为 Redis 中特有的数据结构-跳跃表,其在链表的基础上增加了多级索引来提升查找效率。
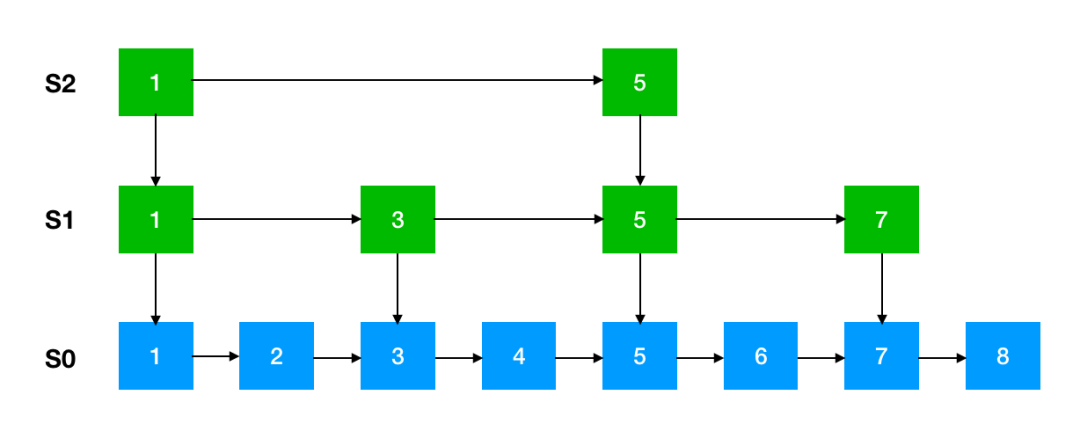
这是跳跃表的简单原理图,每一层都有一条有序的链表,最底层的链表包含了所有的元素。这样跳跃表就可以支持在 O(logN) 的时间复杂度里查找到对应的节点。
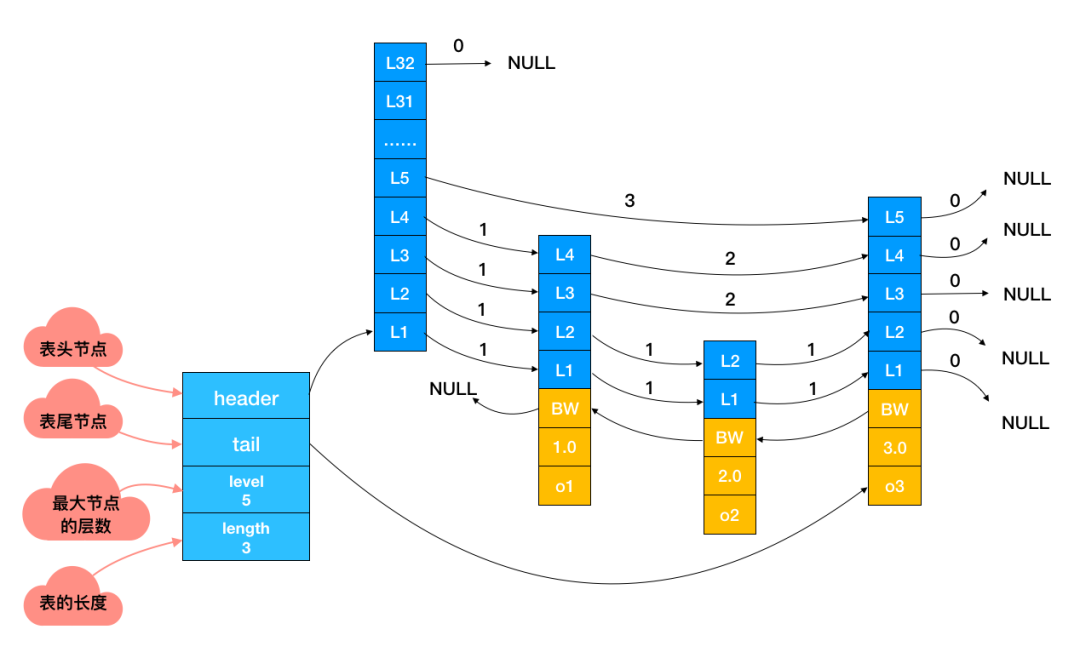
下面这张是跳表真实的存储结构,和其它数据结构一样,都在头节点里记录了相应的信息,减少了一些不必要的系统开销。
6、合理的数据编码
对于每一种数据类型来说,底层的支持可能是多种数据结构,什么时候使用哪种数据结构,这就涉及到了编码转化的问题。
那我们就来看看,不同的数据类型是如何进行编码转化的:
String:存储数字的话,采用int类型的编码,如果是非数字的话,采用 raw 编码;
List:字符串长度及元素个数小于一定范围使用 ziplist 编码,任意条件不满足,则转化为 linkedlist 编码;
Hash:hash 对象保存的键值对内的键和值字符串长度小于一定值及键值对;
Set:保存元素为整数及元素个数小于一定范围使用 intset 编码,任意条件不满足,则使用 hashtable 编码;
Zset:zset 对象中保存的元素个数小于及成员长度小于一定值使用 ziplist 编码,任意条件不满足,则使用 skiplist 编码。
四、Redis高并发快总结
1. 基于内存实现。数据都存储在内存里,减少了一些不必要的 I/O 操作,操作速率很快。
2. 合适的线程模型。
-
I/O 多路复用模型同时监听客户端连接;
-
单线程在执行过程中不需要进行上下文切换和竞争,减少了耗时。
3.高效的数据结构。
-
底层多种数据结构支持不同的数据类型,支持 Redis 存储不同的数据;
-
不同数据结构的设计,使得数据存储时间复杂度降到最低。
4.合理的数据编码。
-
根据字符串的长度及元素的个数适配不同的编码格式。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现