Scrapy爬取简单百度页面
Scrapy爬取百度页面
------------------------------------------
spiders-baiduspider.py
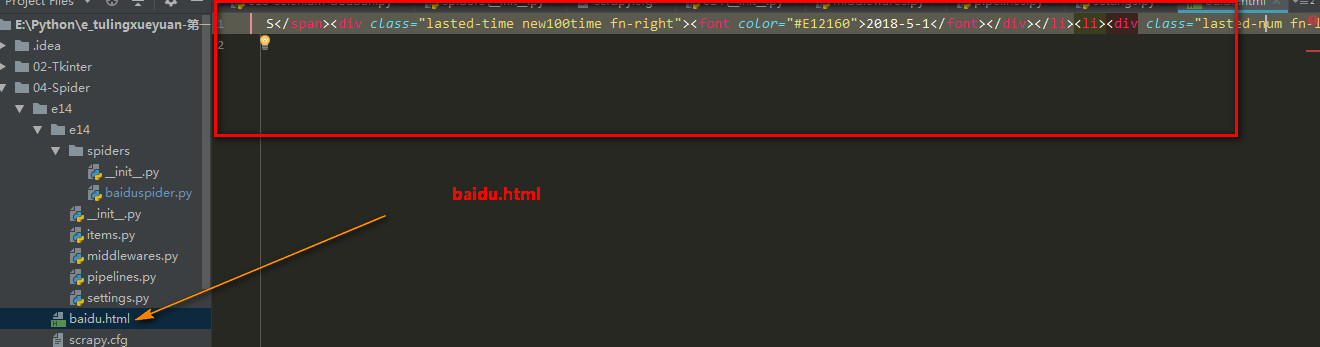
1 ''' 2 要求导入scrapy 3 所有类一般是XXXSpider命名 4 所有爬虫类是scrapy.Spider的子类 5 scrapy爬取百度 6 关闭配置的机器人协议 7 ''' 8 9 import scrapy 10 11 class BaiduSpider(scrapy.Spider): 12 13 # name是爬虫的名称 14 name = "baidu" 15 16 # 起始url列表 17 start_urls = ['http://www.baidu.com'] 18 19 20 # 负责分析downloader下载得到的结果 21 def parse(self, response): 22 ''' 23 只是保存网页即可 24 :param response: 25 :return: 26 ''' 27 with open('baidu.html', 'w', encoding='utf-8') as f: 28 f.write(response.body.decode('utf-8'))

===========================
start_urls = xxxxxxxxxxxxxxxxxxxx 起始地址
parse函数分析网页:网页已经被downloader下来了,重写spider的parse函数
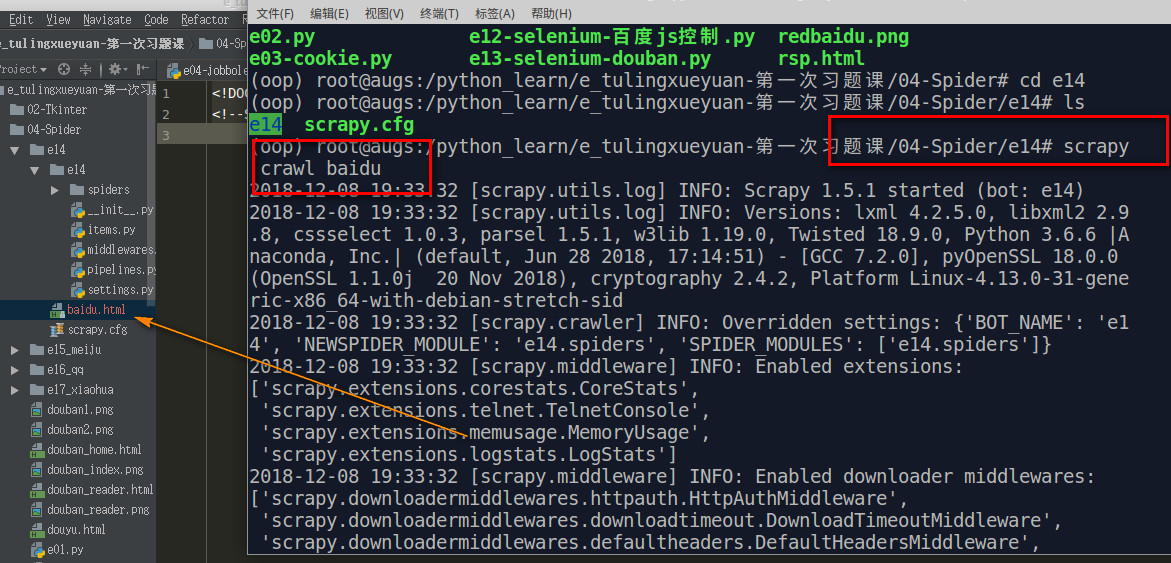
scrapy crawl baidu 终端下运行(name = "baidu")


