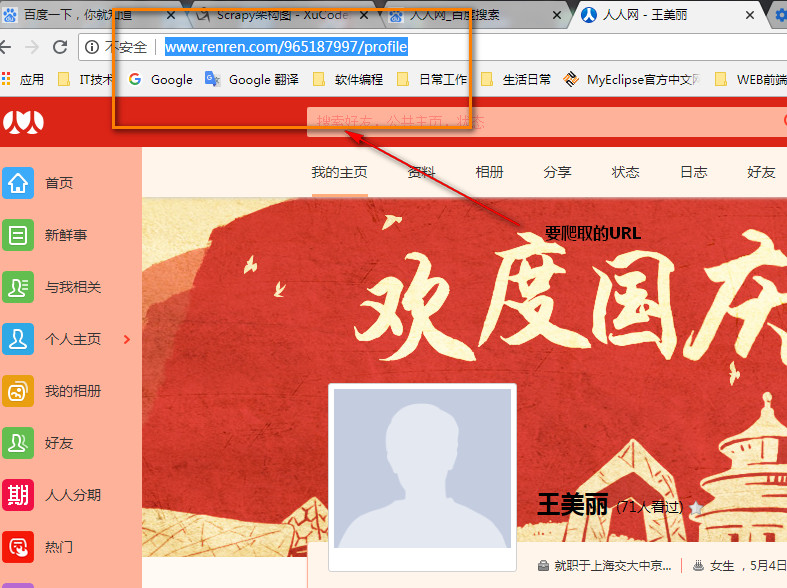
Python爬虫-访问人人网
访问人人网
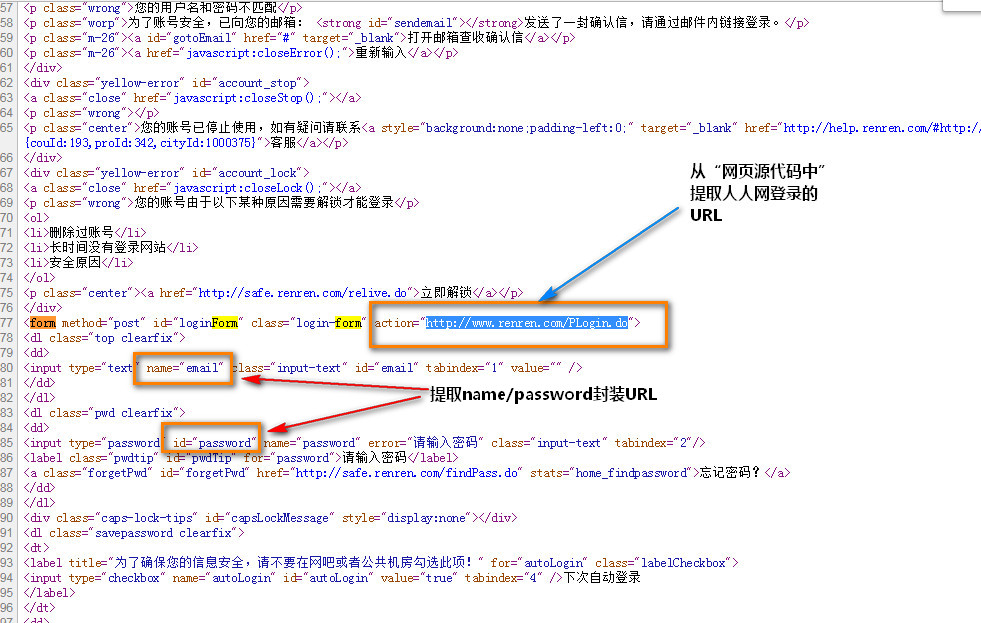
1 from urllib import request, parse 2 from http import cookiejar 3 4 # 创建cookiejar的实例 5 cookie = cookiejar.CookieJar() 6 7 # 生成 cookie的管理器 8 cookie_handler = request.HTTPCookieProcessor(cookie) 9 # 创建http请求管理器 10 http_handler = request.HTTPHandler() 11 12 # 生成https管理器 13 https_handler = request.HTTPSHandler() 14 15 # 创建请求管理器 16 opener = request.build_opener(http_handler, https_handler, cookie_handler) 17 18 def login(): 19 ''' 20 负责初次登录 21 需要输入用户名密码,用来获取登录cookie凭证 22 :return: 23 ''' 24 25 # 此url需要从登录form的action属性中提取 26 url = "http://www.renren.com/PLogin.do" 27 28 # 此键值需要从登录form的两个对应input中提取name属性 29 data = { 30 "email": "13119144223", 31 "password": "123456" 32 } 33 34 # 把数据进行编码 35 data = parse.urlencode(data) 36 37 # 创建一个请求对象 38 req = request.Request(url, data=data.encode()) 39 40 # 使用opener发起请求 41 rsp = opener.open(req) 42 43 def getHomePage(): 44 url = "http://www.renren.com/965187997/profile" 45 46 # 如果已经执行了login函数,则opener自动已经包含相应的cookie值 47 rsp = opener.open(url) 48 49 50 html = rsp.read().decode() 51 with open("rsp.html", "w") as f: 52 f.write(html) 53 54 if __name__ == '__main__': 55 login()
====================================