JAVA入门到精通-第18讲-排序查找
















java基本语法--排序
插入式排序法--插入排序法
插入式排序属于内部排序法,是对于欲排序的元素以插入的方式找寻该元素的适当位置,以达到排序的目的。
插入式排序法又可分为3种:
1、插入排序法(Insertion Sorting)
2、谢耳排序法(Shell Sorting)(欧洲人员喜欢使用)
3、二叉树排序法(Binary-tree Sorting)
插入排序(Insertion
Sorting)的基本思想是:把n个待排序的元素看成为一个有序表和一个无序表,开始有序表只包含一个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,把它的排序码依次与有序表元素的排序码进行比较,将它插入到有序表中的适当位置,使之成为新的有序表。

//插入式排序法[Demo134.java]排序10万数据用时2秒
public
class Demo134{
public static void main(String []args){
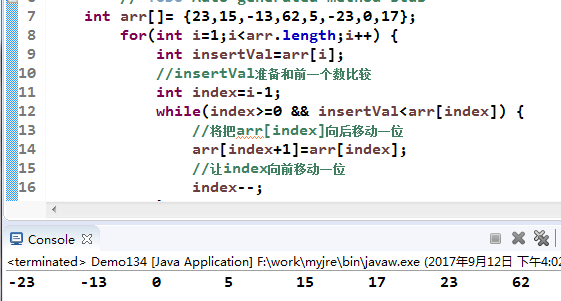
int arr[]={23,15,-13,62,5,-23,0,17};
for(int i=1;i<arr.length;i++){
int insertVal=arr[i];
//insertVal准备和前一个数比较
int index=i-1;
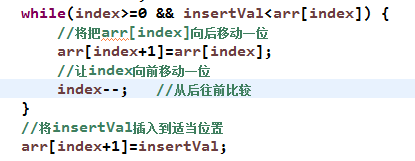
while(index>=0&&insertVal<arr[index]){
//将把arr[index]向后移动一位
arr[index+1]=arr[index];
//让index向前移动一位
index--;
}
//将insertVal插入到适当位置
arr[index+1]=insertVal;
}
//输出最后结果
for(int i=0;i<arr.length;i++){
System.out.print(arr[i]+"\t");
}
}
}
-------------------------------------------------------------------------------
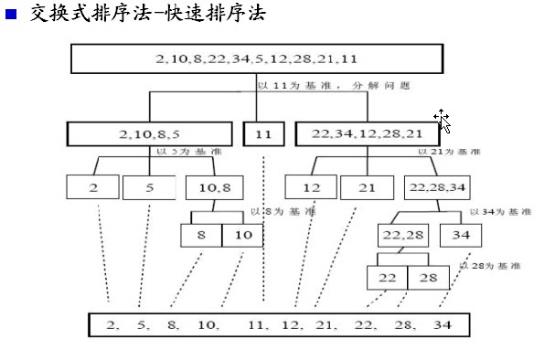
交换式排序法--快速排序法
快速排序(QuickSorting)是对冒泡排序的一种改进,由C.A.R.Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
//快速排序法[Demo135.java]排序1亿数据用时14秒
public
class Demo135{
public static void main(String []args){
int arr[]={-1,-5,6,2,0,9,-3,-8,12,7};
QuickSort qs=new QuickSort();
qs.sort(0, arr.length-1, arr);
//输出最后结果
for(int i=0;i<arr.length;i++){
System.out.print(arr[i]+"\t");
}
}
}
class
QuickSort{
public void sort(int left,int right,int []
arr){
int l=left;
int r=right;
int pivot=arr[(left+right)/2];//找中间值
int temp=0;
while(l<r){
while(arr[l]<pivot) l++;
while(arr[r]>pivot) r--;
if(l>=r) break;
temp=arr[l];
arr[l]=arr[r];
arr[r]=temp;
if(arr[l]==pivot) --r;
if(arr[r]==pivot) ++l;
}
if(l==r){
l++;
r--;
}
if(left<r) sort(left,r,arr);
if(right>l) sort(l,right,arr);
}
}
-------------------------------------------------------------------------------
其它排序法--选堆排序法(主考高级程序员,工作中基本上用不到,不再详解)
将排序码k1,k2,k3,...,kn表示成一棵完全二叉树,然后从第n/2个排序码开妈筛选,使由该结点组成的子二叉树符合堆的定义,然后从第n/2-1个排序码重复刚才操作,直到第一个排序码止,这时候,该二叉树符合堆的定义,初始堆已经建立。
接着,可以按如下方法进行堆排序:将堆中第一个结点(二叉树根结点)和最后一个结点的数据进行交换(k1与kn),再将k1--kn-1重新建堆,然后k1和kn-1交换,再将k1--kn-2重新建堆,然后k1和kn-2交换,如此重复下去,每次重新建堆的元素个数不断减1,直到重新建堆的元素个数仅剩一个为止。这时堆排序已经完成,则排序码k1,k2,k3,...kn已排成一个有序序列。
若排序是从小到大排列,则可以建立大根堆实现堆排序,若排序是从大到小排列,则可以用建立小根堆实现堆排序。
其它排序法--希尔排序法(知道有这个排序法即可)
希尔排序(Shell Sorting)又称为“缩小增量排序”。是1959年由D.L.Shell提出来的。该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。
因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
其它排序法--二叉树排序法
二分插入排序(Binary Insert Sorting)的基本思想是:在有序表中采用二分查找的方法查找待排元素的插入位置。
其处理过程:先将第一个元素作为有序序列,进行n-1次插入,用二分查找的方法查找待排元素的插入位置,将待排元素插入。
-------------------------------------------------------------------------------
外部排序法
其它排序法--合并排序法(最为常用的排序方法)
合并排序法(Merge Sorting)是外部排序最常使用的排序方法。若数据量太大无法一次完全加载内存,可使用外部辅助内存来处理排序数据,主要应用在文件排序。
排序方法:
将欲排序的数据分别存在数个文件大小可加载内存的文件中,再针对各个文件分别使用“内部排序法”将文件中的数据排序好写回文件。再对所有已排序好的文件两两合并,直到所有文件合并成一个文件后,则数据排序完成。
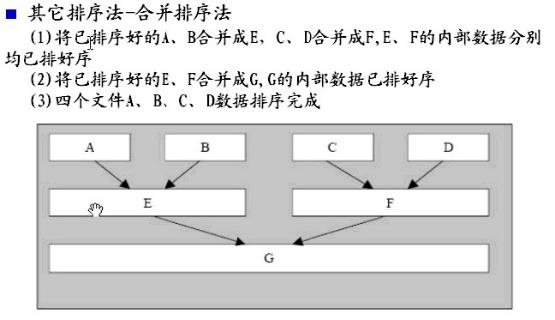
1、将已排序好的A、B合并成E,C、D合并成F,E、F的内部数据分别均已排好序
2、将已排序好的E、F合并成G,G的内部数据已排好序
3、四个文件A、B、C、D数据排序完成
//合并排序法[Demo137.java]
public
class Demo137{
public static void main(String[] args)
{
Merge m=new Merge();
int a[]={5,4,10,8,7,9};
m.merge_sort(a,0,a.length-1);
}
}
class
Merge{
//递归分成小部分
public void merge_sort(int[] arrays,int
start,int end){
if(start<end){
int m=(start+end)/2;
merge_sort(arrays,start,m);
merge_sort(arrays,m+1,end);
combin_arrays(arrays,start,m,end);
}
}
//合并数组
public void combin_arrays(int[] arrays,int
start,int m,int end){
int length=end-start+1;
int temp[]=new int[length];//用来存放比较的数组,用完复制回到原来的数组
int i=start;
int j=m+1;
int c=0;
while(i<=m &&j<=end){
if(arrays[i]<arrays[j]){
temp[c]=arrays[i];
i++;
c++;
}else{
temp[c]=arrays[j];
j++;
c++;
}
}
while(i<=m){
temp[c]=arrays[i];
i++;
}
while(j<=end){
temp[c]=arrays[j];
j++;
}
c=0;
for(int t=start;t<=end;t++,c++){
arrays[t]=temp[c];
}
snp(arrays);
}
//打印数组
public void snp(int[] arrays){
for(int i=0;i<arrays.length;i++){
System.out.print(arrays[i]+"
");
}
System.out.println();
}
}
*******************************************************************************
查找
在java中,常用的查找方式有两种:
1、顺序查找(最简单,效率最低)
2、二分查找
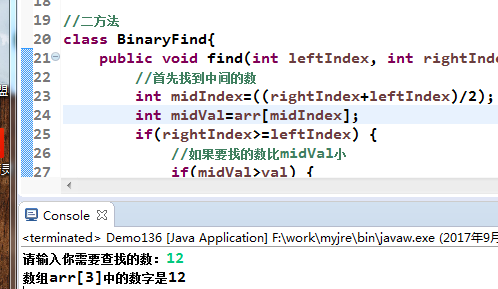
//功能:二分查找[Demo136.java]
import
java.util.*;
public
class Demo136 {
public static void main(String[] args) {
int arr[]={2,5,7,12,25};//定义arr数组并赋值
System.out.print("请输入你需要查找的数:");
Scanner sr=new Scanner(System.in);
int a=sr.nextInt();
BinaryFind bf=new BinaryFind();//创建BinaryFind对象
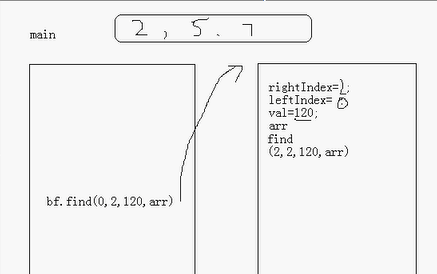
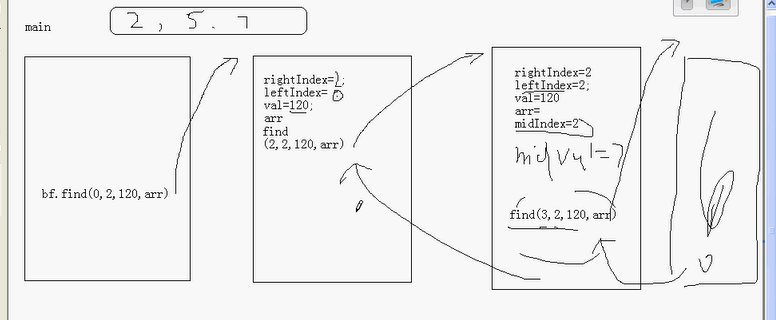
bf.find(0,arr.length-1,a,arr);//调用find方法,并将数据传给方法
}
}
//二分法
class
BinaryFind{
public void find(int leftIndex,int
rightIndex,int val,int arr[]){
//首先找到中间的数
int midIndex=((rightIndex+leftIndex)/2);
int midVal=arr[midIndex];
if(rightIndex>=leftIndex){
//如果要找的数比midVal小
if(midVal>val){
//在arr数组左边数列中找
find(leftIndex,midIndex-1,val,arr);
}else if(midVal<val){
//在arr数组右边数列中找
find(midIndex+1,rightIndex,val,arr);
}else if(midVal==val){
System.out.println("数组arr["+midIndex+"]中的数字是"+arr[midIndex]);
}
}else{
System.out.println("没有找到你要找的数!");
}
}
}
-------------------------------------------------------------------------------
递归
什么是递归?
递归算法:是一种直接或者间接地调用自身的算法,就我个人的理解而言,不论是直接还是间接,其算法的流程走向必须形成封闭(即本身属于广义上的循环过程),否则递归将不能形成。在计算机编写程序中,递归算法对解决很多类问题是十分有效,它使算法的描述简洁而且易于理解。
递归算法的特点:
递归过程一般通过函数或子过程来实现。
递归算法:在函数或子过程的内部,直接或者间接地调用自己的算法。
递归算法的实质:是把问题转化为规模缩小了的同类问题的子问题。然后递归调用函数(或过程)来表示问题的解。
递归算法解决问题的特点:
(1)递归就是在过程或函数里调用自身。
(2)在使用递增归策略时,必须有一个明确的递归结束条件,称为递归出口。
(3)递归算法解题通常显得很简洁,但递归算法解题的运行效率较低,即占用内存很大,有时这种情况用栈来代替解决。所以一般不提倡用递归算法设计程序。
(4)在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储。递归次数过多容易造成栈溢出等。所以一般不提倡用递归算法设计程序。
递归算法所体现的“重复”一般有三个要求:
一是每次调用在规模上都有所缩小(通常是减半);
二是相邻两次重复之间有紧密的联系,前一次要为后一次做准备(通常前一次的输出就作为后一次的输入);
三是在问题的规模极小时必须用直接给出解答而不再进行递归调用,因而每次递归调用都是有条件的(以规模未达到直接解答的大小为条件),无条件递归调用将会成为死循环而不能正常结束。
最后我再补充一点:递归只是用在简单的循环场合中,这种场合就是递归函数体只含有一个IF-ELAE语言的情况:
权限修饰符+(static)+函数返回类型+函数名(参数列表){
if(递归结束条件){递归结束终值赋值语句;return 返回值;}
else{累计计算+循环调用函数语句;
return 返回值;}
}
其余的复杂循环(甚至嵌套)情况建议不用递归,因为递归过程中所用到的变量都在递归结束前的过程中一直占用着内存,如果循环过程又趋于复杂则内存耗用量将显著提升,运行速度也将下降.


