
Prometheus+Grafana+Alertmanager实现告警推送教程 ----- 图文详解
前言
本文主要介绍的是Prometheus采集数据,通过Grafana加上PromQL语句实现数据可视化以及通过Alertmanage实现告警推送功能。温馨提示,本篇文章特长,2w多的文字加上几十张图片,建议收藏观看。
Prometheus 介绍
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特点:
- 强大的多维度数据模型: 时间序列数据通过 metric 名和键值对来区分。 所有的 metrics 都可以设置任意的多维标签。
- 数据模型更随意,不需要刻意设置为以点分隔的字符串。 可以对数据模型进行聚合,切割和切片操作。
- 支持双精度浮点类型,标签可以设为全unicode。 灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 metrics进行乘法、加法、连接、取分数位等操作。
- 易于管理: Prometheus server是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。 高效:平均每个采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。 使用 pull模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。 可以采用 push gateway 的方式把时间序列数据推送至 Prometheus server 端。 可以通过服务发现或者静态配置去获取监控的 targets。
- 有多种可视化图形界面。 易于伸缩。 需要指出的是,由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100%
- 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
示例图:

Prometheus的适用场景
在选择Prometheus作为监控工具前,要明确它的适用范围,以及不适用的场景。
Prometheus在记录纯数值时间序列方面表现非常好。它既适用于以服务器为中心的监控,也适用于高动态的面向服务架构的监控。
在微服务的监控上,Prometheus对多维度数据采集及查询的支持也是特殊的优势。
Prometheus更强调可靠性,即使在故障的情况下也能查看系统的统计信息。权衡利弊,以可能丢失少量数据为代价确保整个系统的可用性。因此,它不适用于对数据准确率要求100%的系统,比如实时计费系统(涉及到钱)。
Prometheus核心组件介绍
Prometheus Server:
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。 Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。 Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporters:
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus
Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。 一般来说可以将Exporter分为2类:
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
PushGateway:
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。
Service Discovery:
服务发现在Prometheus中是特别重要的一个部分,基于Pull模型的抓取方式,需要在Prometheus中配置大量的抓取节点信息才可以进行数据收集。有了服务发现后,用户通过服务发现和注册的工具对成百上千的节点进行服务注册,并最终将注册中心的地址配置在Prometheus的配置文件中,大大简化了配置文件的复杂程度,
也可以更好的管理各种服务。 在众多云平台中(AWS,OpenStack),Prometheus可以
通过平台自身的API直接自动发现运行于平台上的各种服务,并抓取他们的信息Kubernetes掌握并管理着所有的容器以及服务信息,那此时Prometheus只需要与Kubernetes打交道就可以找到所有需要监控的容器以及服务对象.
- Consul(官方推荐)等服务发现注册软件
- 通过DNS进行服务发现
- 通过静态配置文件(在服务节点规模不大的情况下)
Prometheus UI
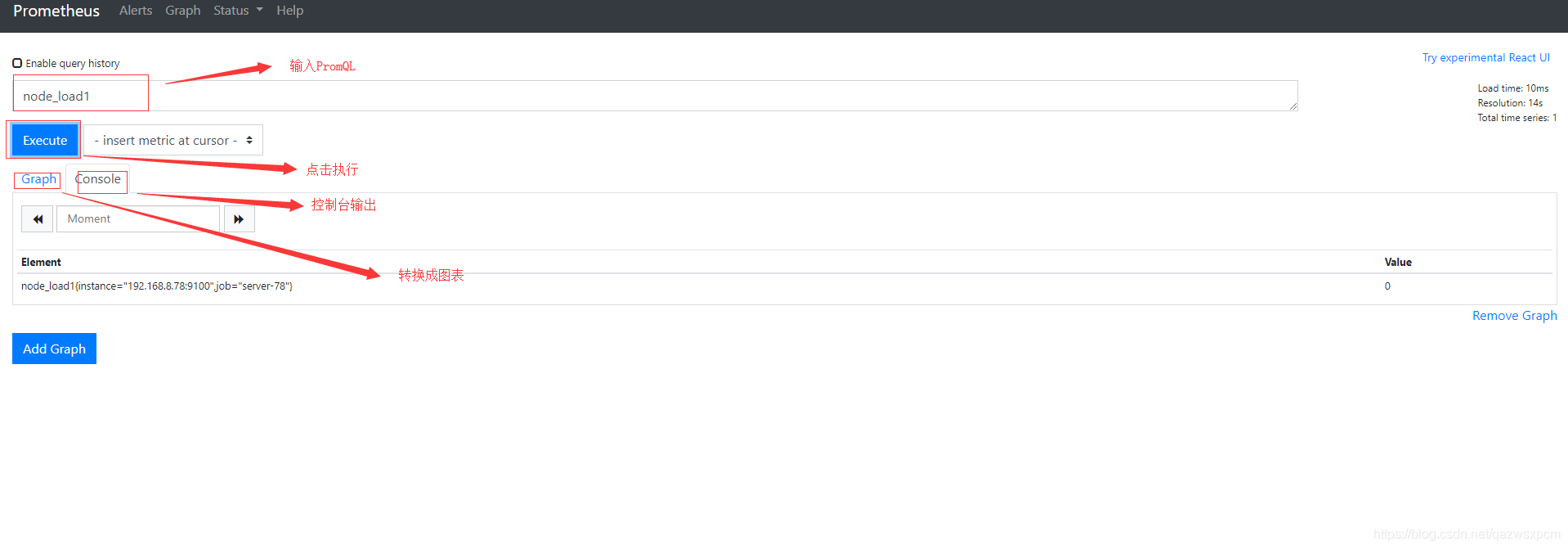
Prometheus UI是Prometheus内置的一个可视化管理界面,通过Prometheus UI用户能够轻松的了解Prometheus当前的配置,监控任务运行状态等。 通过Graph面板,用户还能直接使用PromQL实时查询监控数据。访问ServerIP:9090/graph打开WEB页面,通过PromQL可以查询数据,可以进行基础的数据展示。
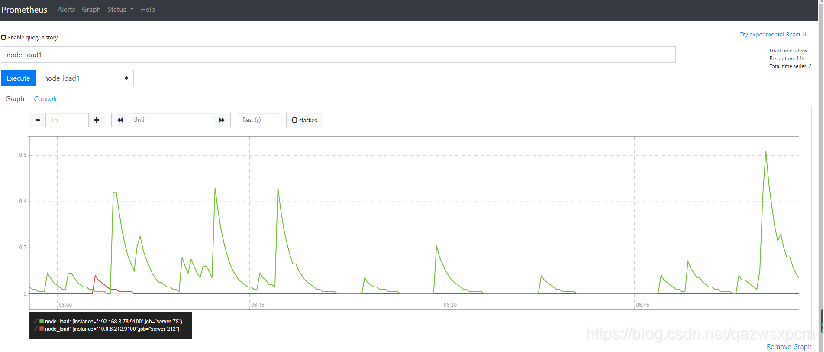
如下所示,查询主机负载变化情况,可以使用关键字node_load1可以查询出Prometheus采集到的主机负载的样本数据,这些样本数据按照时间先后顺序展示,形成了主机负载随时间变化的趋势图表:
Grafana介绍
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示。Grafana提供了对prometheus的友好支持,各种工具帮助你构建更加炫酷的数据可视化。
Grafana特点
- 可视化:快速和灵活的客户端图形具有多种选项。面板插件为许多不同的方式可视化指标和日志。
- 报警:可视化地为最重要的指标定义警报规则。Grafana将持续评估它们,并发送通知。
- 通知:警报更改状态时,它会发出通知。接收电子邮件通知。
- 动态仪表盘:使用模板变量创建动态和可重用的仪表板,这些模板变量作为下拉菜单出现在仪表板顶部。
- 混合数据源:在同一个图中混合不同的数据源!可以根据每个查询指定数据源。这甚至适用于自定义数据源。
- 注释:注释来自不同数据源图表。将鼠标悬停在事件上可以显示完整的事件元数据和标记。
- 过滤器:过滤器允许您动态创建新的键/值过滤器,这些过滤器将自动应用于使用该数据源的所有查询。
这里我们使用上面Prometheus使用关键字node_load1来使用Grafana进行可视化,点击侧边栏的加号图标,然后单击Dashboard点击创建,然后把刚刚Prometheus使用的查询语句放到Metries,点击右上角的apply即可。
示例图:
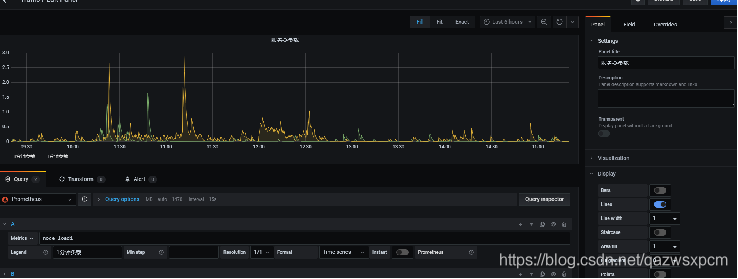
Grafana UI
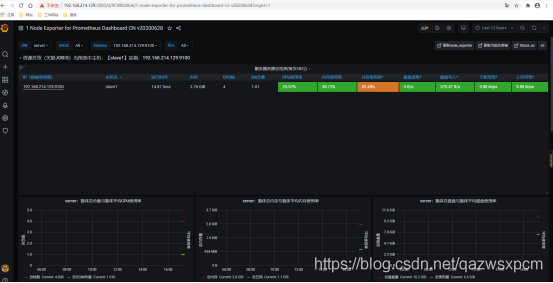
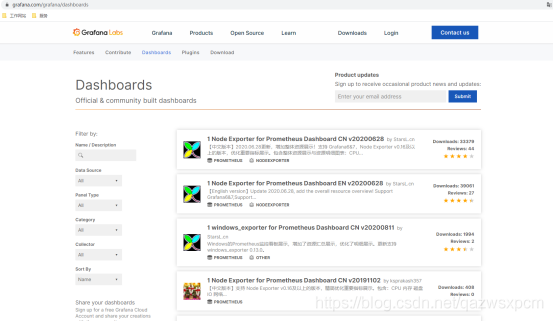
上面的示例中我们通过prometheus+grafana通过PromQL进行了简单的服务器负载的监控可视化。我们也可以通过第三方提供可视化JSON文件来帮助我们快速实现服务器、Elasticsearch、MYSQL等等监控。这里我们在grafana提供的第三方dashboards的地址https://grafana.com/grafana/dashboards来下载对应的json文件然后导入到grafana实现服务器的监控。
监控服务器的示例图:
除了服务端的监控,可以监控应用服务。Prometheus 监控应用的方式非常简单,只需要进程暴露了一个用于获取当前监控样本数据的 HTTP 访问地址。这样的一个程序称为Exporter,Exporter 的实例称为一个 Target 。Prometheus 通过轮训的方式定时从这些 Target 中获取监控数据样本,对于应用来讲,只需要暴露一个包含监控数据的 HTTP 访问地址即可,当然提供的数据需要满足一定的格式,这个格式就是 Metrics 格式: metric name>{
Prometheus+Grafana+Alertmanager等安装配置
Prometheus以及相关组件使用的是2.x版本,Grafana使用的是7.x版本。
下载地址推荐使用清华大学或华为的开源镜像站。
下载地址:
https://prometheus.io/download/
https://mirrors.tuna.tsinghua.edu.cn/grafana/
Prometheus以及相关组件百度网盘地址:
链接:https://pan.baidu.com/s/1btErwq8EyAzG2-34lwGO4w
提取码:4nlh
Prometheus安装
1,文件准备
将下载好的Prometheus文件解压
输入
tar -zxvf prometheus-2.19.3.linux-amd64.tar.gz
然后移动到/opt/prometheus文件夹里面,没有该文件夹则创建
2,配置修改
在prometheus-2.19.3.linux-amd64文件夹目录下找到prometheus.yml配置文件并更改
prometheus.yml文件配置如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['192.168.8.181:9090']
3,prometheus 启动
在/opt/prometheus/prometheus-2.19.3.linux-amd64的目录下输入:
nohup ./prometheus >/dev/null 2>&1 &
启动成功之后,在浏览器上输入 ip+9090可以查看相关信息。

Grafana安装
1,文件准备
将下载下来的grafana-7.1.1-1.x86_64.rpm的文件通过apm方式安装
输入:
rpm -ivh grafana-7.1.1-1.x86_64.rpm
进行安装
如果出现如下错误:
error: Failed dependencies:
urw-fonts is needed by grafana-6.1.4-1.x86_64
一个依赖包没有安装,需要先安装这个依赖包,然后再安装grafana
# yum install -y urw-fonts
2,grafana 启动
root用户下启动
输入:
sudo /bin/systemctl start grafana-server.service
启动成功之后,在浏览器上输入 ip+3000可以查看相关信息
Alertmanager安装
1,文件准备
将下载好的Alertmanager文件解压
输入
tar -zxvf alertmanager-0.21.0.linux-386.tar.gz
然后移动到/opt/prometheus文件夹里面,没有该文件夹则创建
2,alertmanager启动
root用户下启动
输入:
nohup ./alertmanager >/dev/null 2>&1 &
启动成功之后,在浏览器上输入 ip+9093可以查看相关信息
示例图:
Pushgateway 安装
1,文件准备
将下载好的pushgateway文件解压
输入
tar -zxvf pushgateway-1.2.0.linux-amd64.tar.gz
然后移动到/opt/prometheus文件夹里面,没有该文件夹则创建
2,启动
root用户下启动
输入:
nohup ./pushgateway >/dev/null 2>&1 &
启动成功之后,在浏览器上输入 ip+9091可以查看相关信息
5,Node_export安装
1,文件准备
将下载好的Node_export文件解压
输入
tar -zxvf node_exporter-0.17.0.linux-amd64.tar.gz
然后移动到/opt/prometheus文件夹里面,没有该文件夹则创建
2,启动
root用户下启动
输入:
nohup ./consul_exporter >/dev/null 2>&1 &
启动成功之后,在浏览器上输入 ip+9100可以查看相关信息
Prometheus使用教程
Prometheus界面地址: ip+9090。
这里我就使用图片加上注释来进行讲解。
1,基本使用
1>,Prometheus主界面说明
2>,Graph使用示例
3>,查看运行信息
4>,查看命令标记值
5>,查看配置信息
6,>查看集成的组件
集成的组件需要下载对应export服务并启动运行,并且在prometheus的配置中进行添加!
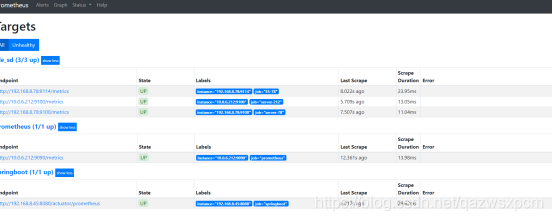
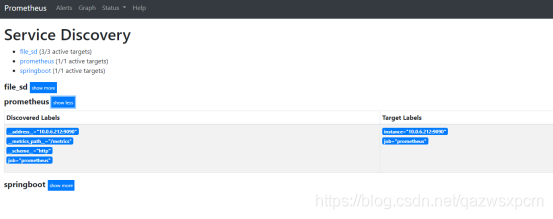
7>,查看服务发现
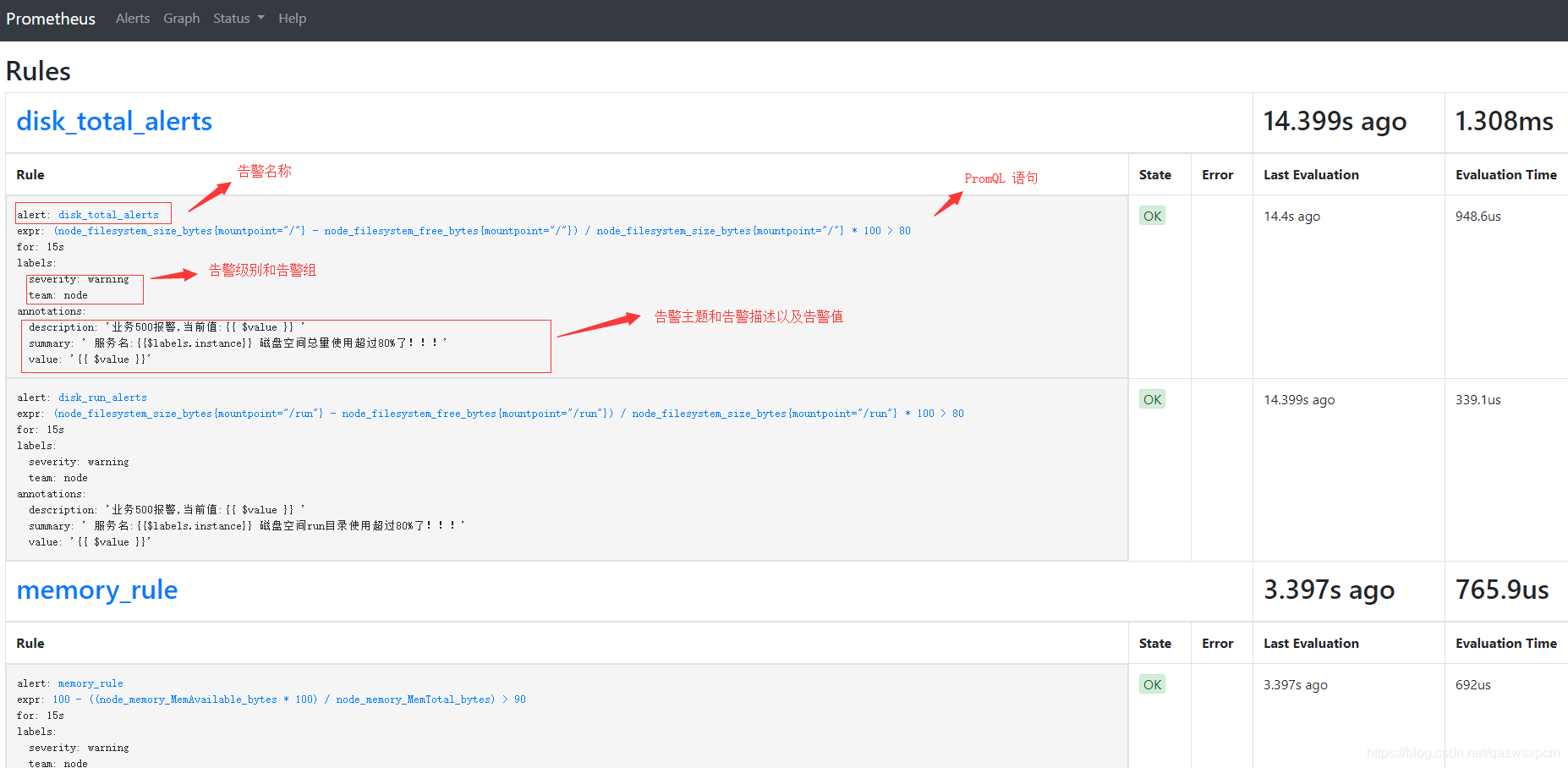
8>,查看告警规则
first_rules.yml的配置。
9>,查看是否触发告警
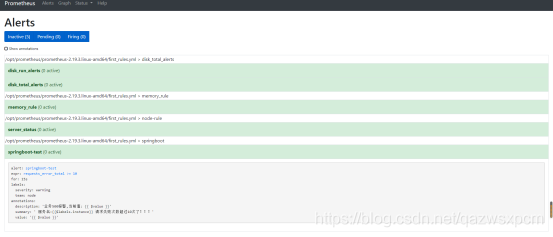
相关文档:https://prometheus.io/docs/prometheus/latest/getting_started/
Grafana使用
Grafanf 界面地址: ip+3000
初始账号密码: admin, admin
这里我依旧用图片加注释来进行讲解,想必这样会更容易理解吧。。。
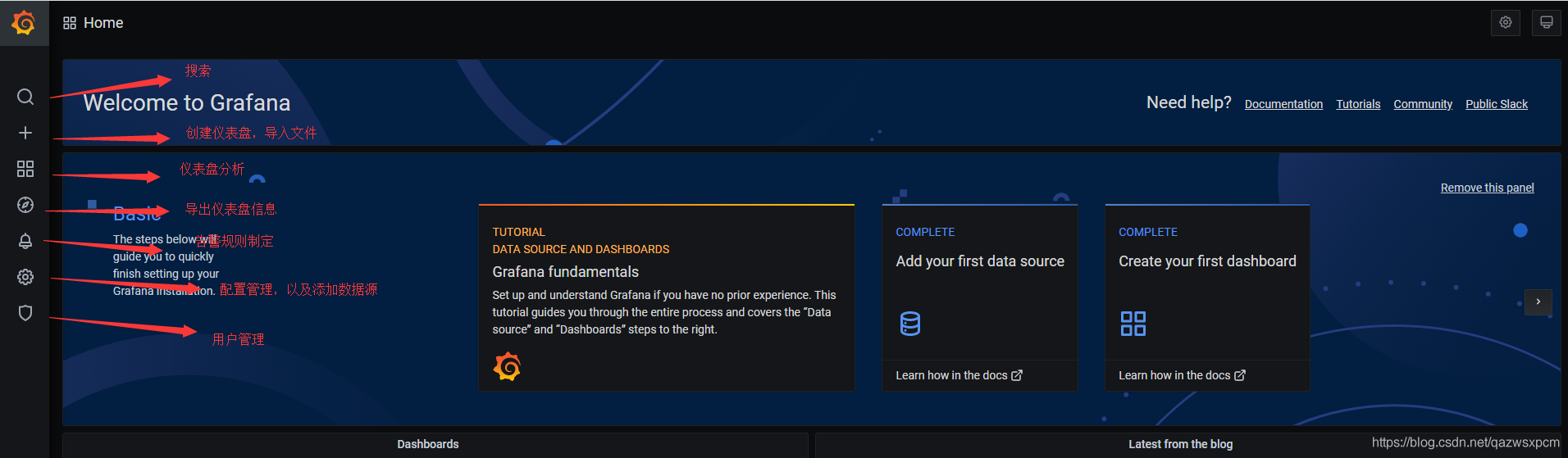
1>,主界面信息
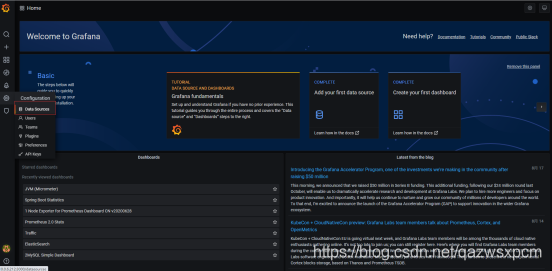
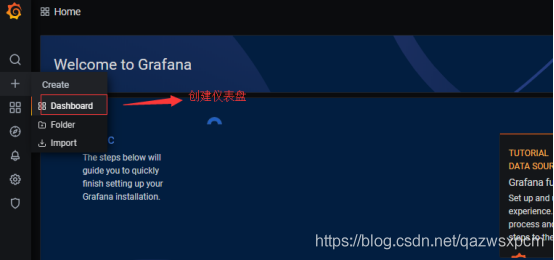
2>,创建仪表盘监控实现
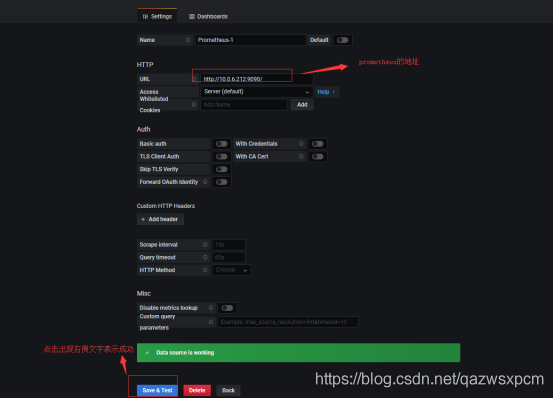
1.添加数据源
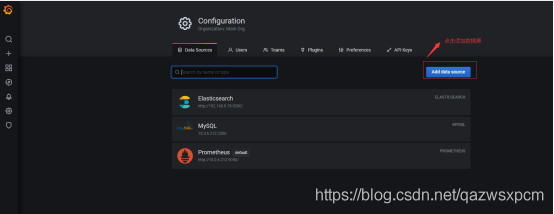
2.选择prometheus
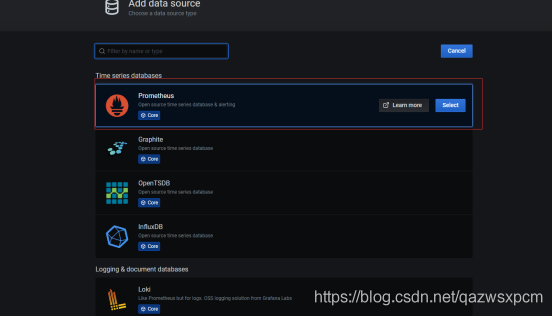
3.点击创建仪表盘
4.点击创建
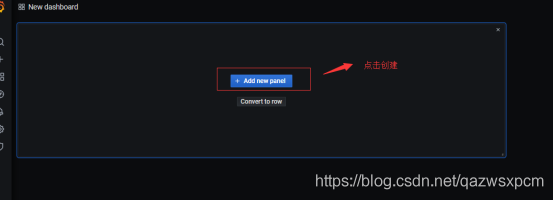
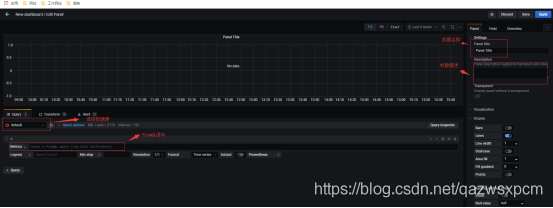
5.输入node_load1表示语句,填写相关信息,点击apply完成,并将名称保存为Test
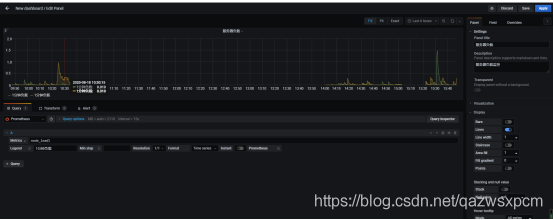
6.点击搜索Test,点击就可以查看
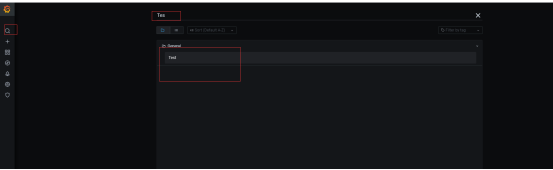
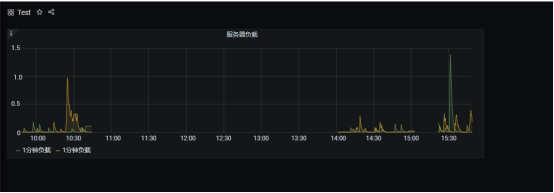
3>,使用第三方仪表盘监控实现
注:需提前添加好数据源。
1.点击左上角的加号,点击import
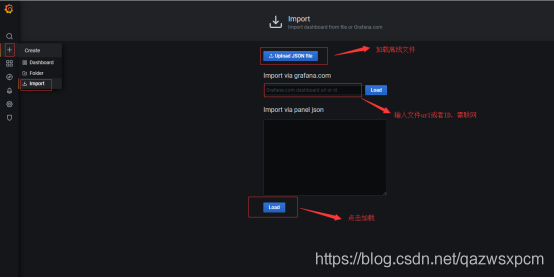
在线模式
地址:https://grafana.com/grafana/dashboards

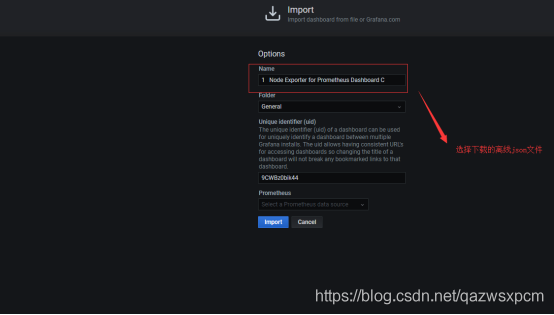
离线模式
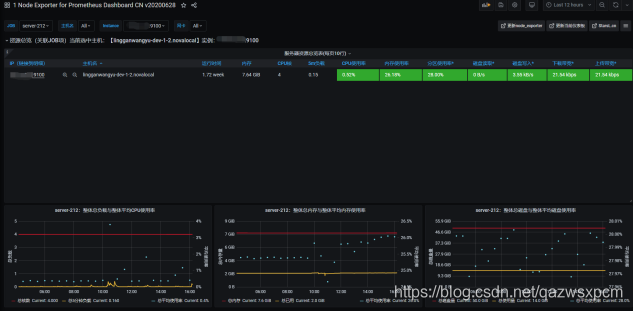
监控示例:
监控告警实现
监控告警实现需要依赖 Alertmanager,已经相关的组件,比如上述实例中的监控服务器应用的node_server组件。
邮件告警实现
需要安装Alertmanager,这里因为邮件发送比较简单,所以这里我就直接贴配置了,其中带有xxx字符的参数是需要根据情况进行更改的。下面的企业微信告警同理。
Alertmanagers服务的alertmanager.yml的配置如下:
global:
resolve_timeout: 5m
smtp_from: 'xxx@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: 'xxx@qq.com'
smtp_auth_password: 'xxx'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'xxx@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
注: smtp_from、smtp_auth_username、to的邮箱可以填写同一个,smtp_auth_password填写鉴权码,需要开启POS3。
如果不知道怎么开启POS3,可以查看我的这篇文章: https://www.cnblogs.com/xuwujing/p/10945698.html
Prometheus服务的Prometheus.yml配置如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- '192.168.214.129:9093'
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/opt/prometheus/prometheus-2.19.3.linux-amd64/first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['192.168.214.129:9090']
- job_name: 'server'
static_configs:
- targets: ['192.168.214.129:9100']
注:targets如果有多个配置的话,在后面加上其他服务的节点即可。alertmanagers最好写服务器的ip,不然可能会出现告警数据无法发送的情况。
Error sending alert" err="Post \"http://alertmanager:9093/api/v1/alerts\": context deadline exceeded
配置了Prometheus.yml之后,我们还需要配置告警的规则,也就是触发条件,达到条件之后就进行触发。我们新建一个first_rules.yml,用于检测服务器挂掉的时候进行发送消息
first_rules.yml告警配置:
注:job等于的服务名称填写Prometheus.yml配置对应的名称,比如这里设置的server对应Prometheus.yml配置的server。
groups:
- name: node
rules:
- alert: server_status
expr: up{job="server"} == 0
for: 15s
annotations:
summary: "机器{{ $labels.instance }} 挂了"
description: "报告.请立即查看!"
依次启动prometheus、altermanagers、node_server服务,查看告警,然后停止node_export服务,等待一段时间在查看。
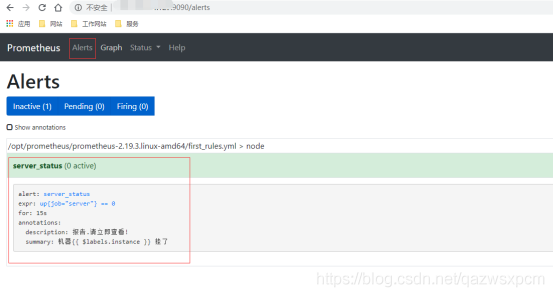
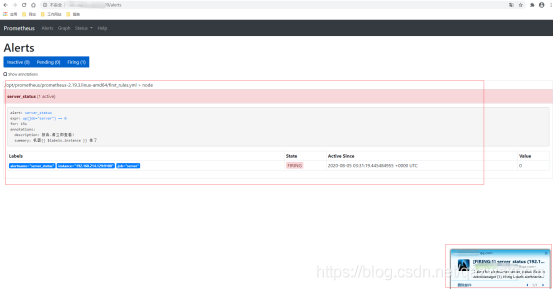
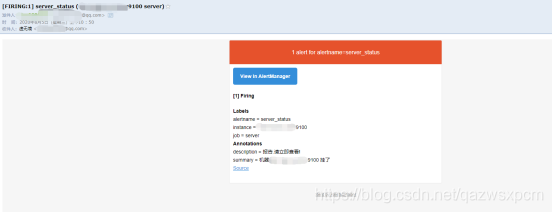
企业微信告警实现
和上面的示例操作基本一致,主要是配置的区别。
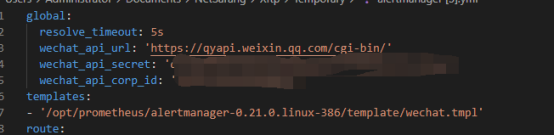
1.在企业微信中创建一个应用,并得到secret、corp_id和agent_id配置。

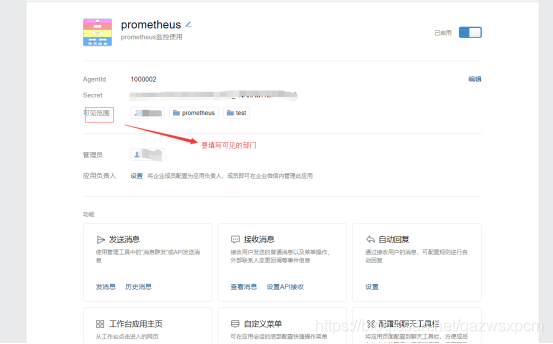
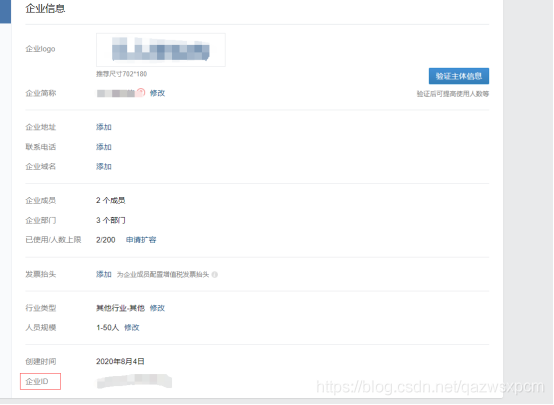
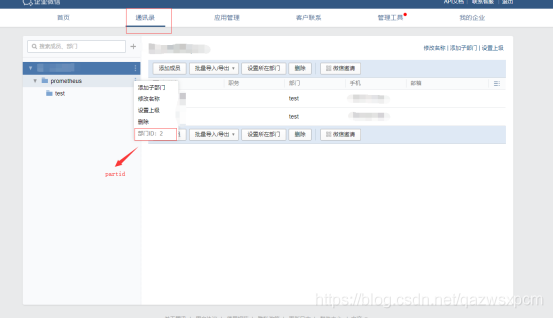
2.然后修改alertmanager.yml配置,alertmanager.yml配置如下:
global:
resolve_timeout: 5s
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_secret: 'xxx'
wechat_api_corp_id: 'xxx'
templates:
- '/opt/prometheus/alertmanager-0.21.0.linux-386/template/wechat.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 10s
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
to_party: '2'
agent_id: xxx
corp_id: 'xxx'
api_secret: 'xxx'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
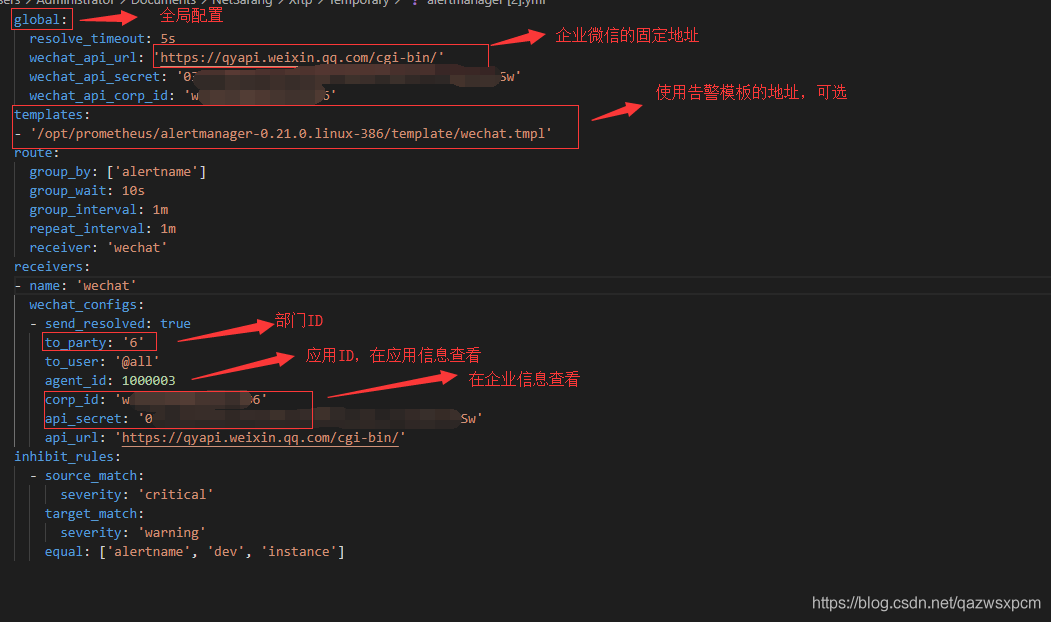
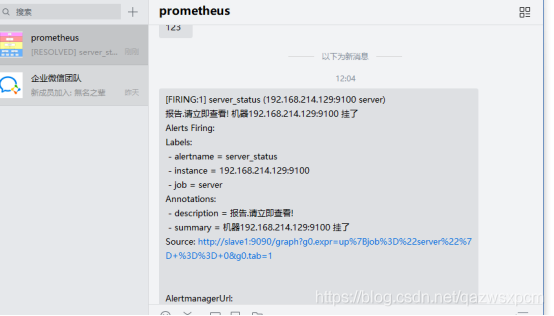
配置成功之后,操作和上述邮件发送的一致,即可在企业微信看到如下信息。
如果觉得上述的示例不好友好的话,我们也可以制定告警模板。
添加告警模板:
在alertmanagers的文件夹下创建一个template文件夹,然后在该文件夹创建一个微信告警的模板wechat.tmpl,添加如下配置:
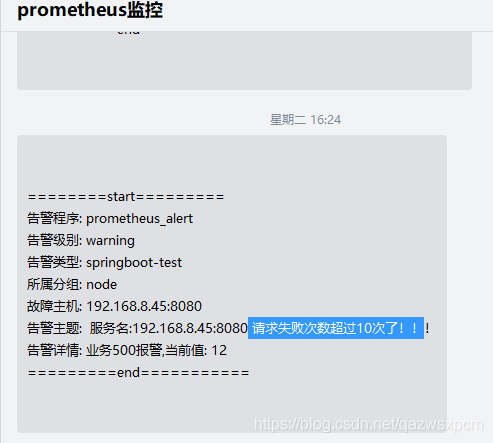
{{ define "wechat.default.message" }}
{{ range .Alerts }}
========start=========
告警程序: prometheus_alert
告警级别: {{ .Labels.severity}}
告警类型: {{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
=========end===========
{{ end }}
{{ end }}
然后再到alertmanager.yml 添加如下配置:
templates:
- '/opt/prometheus/alertmanager-0.21.0.linux-386/template/wechat.tmpl'
效果图:

应用服务监控告警实现
Prometheus 监控应用的方式非常简单,只需要进程暴露了一个用于获取当前监控样本数据的 HTTP
访问地址。这样的一个程序称为Exporter,Exporter 的实例称为一个 Target 。Prometheus通过轮训的方式定时从这些 Target 中获取监控数据样本,对于应用来讲,只需要暴露一个包含监控数据的 HTTP访问地址即可,当然提供的数据需要满足一定的格式,这个格式就是 Metrics 格式: metric name>{
Springboot应用实现步骤
1.在pom文件添加
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
2.在代码中添加如下配置:
private Counter requestErrorCount;
private final MeterRegistry registry;
@Autowired
public PrometheusCustomMonitor(MeterRegistry registry) {
this.registry = registry;
}
@PostConstruct
private void init() {
requestErrorCount = registry.counter("requests_error_total", "status", "error");
}
public Counter getRequestErrorCount() {
return requestErrorCount;
}
3.在异常处理中添加如下记录:
monitor.getRequestErrorCount().increment();
4.在prometheus的配置中添加springboot应用服务监控
- job_name: 'springboot'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['192.168.8.45:8080']
5.Prometheu.yml配置如下:
- job_name: 'springboot'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['192.168.8.45:8080']
规则文件配置如下:

6.在prometheus监控即可查看
企业微信告警效果图:
监控的springboot项目地址:https://github.com/xuwujing/springBoot-study
其他配置
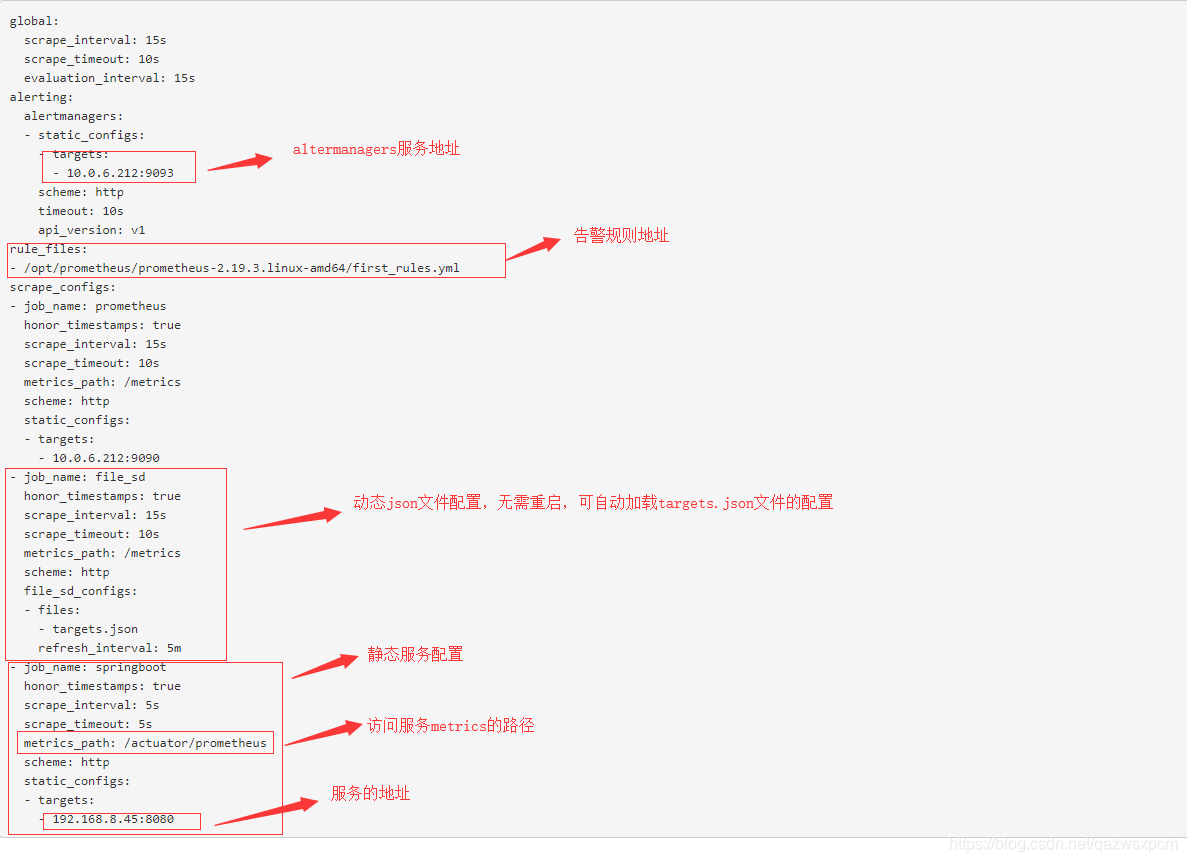
prometheus动态加载配置
Prometheus数据源的配置主要分为静态配置和动态发现, 常用的为以下几类:
- static_configs: 静态服务发现
- file_sd_configs: 文件服务发现
- dns_sd_configs: DNS 服务发现
- kubernetes_sd_configs: Kubernetes 服务发现
- consul_sd_configs:Consul 服务发现(推荐使用)
file_sd_configs的方式提供简单的接口,可以实现在单独的配置文件中配置拉取对象,并监视这些文件的变化并自动加载变化。基于这个机制,我们可以自行开发程序,监控监控对象的变化自动生成配置文件,实现监控对象的自动发现。
在prometheus文件夹目录下创建targets.json文件
配置如下:
[
{
"targets": [ "192.168.214.129:9100"],
"labels": {
"instance": "node",
"job": "server-129"
}
},
{
"targets": [ "192.168.214.134:9100"],
"labels": {
"instance": "node",
"job": "server-134"
}
}
]
然后在prometheus目录下新增如下配置:
- job_name: 'file_sd'
file_sd_configs:
- files:
- targets.json
一些告警配置
这是本人整理的一些服务应用告警的配置,也欢迎大家共同讨论一些常用的相关配置。
内存告警设置
- name: test-rule
rules:
- alert: "内存报警"
expr: 100 - ((node_memory_MemAvailable_bytes * 100) / node_memory_MemTotal_bytes) > 30
for: 15s
labels:
severity: warning
annotations:
summary: "服务名:{{$labels.instance}}内存使用率超过30%了"
description: "业务500报警: {{ $value }}"
value: "{{ $value }}"
示例图:
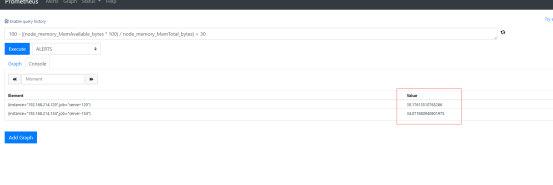

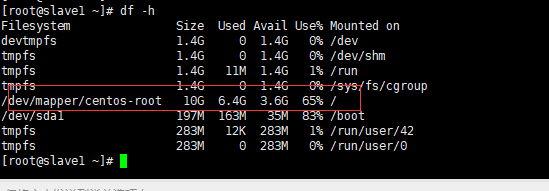
磁盘设置:
总量百分比设置:
(node_filesystem_size_bytes {mountpoint ="/"} - node_filesystem_free_bytes {mountpoint ="/"}) / node_filesystem_size_bytes {mountpoint ="/"} * 100
查看某一目录的磁盘使用百分比
(node_filesystem_size_bytes{mountpoint="/boot"}-node_filesystem_free_bytes{mountpoint="/boot"})/node_filesystem_size_bytes{mountpoint="/boot"} * 100
正则表达式来匹配多个挂载点
(node_filesystem_size_bytes{mountpoint="/|/run"}-node_filesystem_free_bytes{mountpoint="/|/run"})
/ node_filesystem_size_bytes{mountpoint=~"/|/run"} * 100
预计多长时间磁盘爆满
predict_linear(node_filesystem_free_bytes {mountpoint ="/"}[1h],
43600) < 0 predict_linear(node_filesystem_free_bytes
{job="node"}[1h], 43600) < 0
CPU使用率
100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by
(instance) * 100)
空闲内存剩余率
(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes)
/ node_memory_MemTotal_bytes * 100
内存使用率
100 -
(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes)
/ node_memory_MemTotal_bytes * 100
磁盘使用率
100 - (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} /
node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs"} * 100)
其他
这段时间比较忙,ELK相关得等待一段时间在进行更新,虽然发表的博客才对应去年整理的博客。。。。
本篇文章准备了好久,边整理编写,没想到写了这么多。不过感觉这样也不错,一次写出来或许比分开一次次的写对读者而言要好上不上,毕竟不用一篇篇的去找了。
音乐推荐
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
掘金出处:https://juejin.im/user/5ae45d5bf265da0b8a6761e4
个人博客出处:http://www.panchengming.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号