
ElasticSearch实战系列四: ElasticSearch理论知识介绍
前言
在前几篇关于ElasticSearch的文章中,简单的讲了下有关ElasticSearch的一些使用,这篇文章讲一下有关 ElasticSearch的一些理论知识以及自己的一些见解。
虽然本人是一个实战派,不太喜欢讲这些理论知识,因为这块可以查看官方文档,那里会写得非常详细,但是在使用了ElasticSearch之后,发现有的知识点需要掌握一定的理论知识才能理解,对于初学者来说有的不好理解,因此写下该篇文章,希望读者在看完之后能够有所帮助。
ElasticSearch 理论知识介绍
ElasticSearch是什么
Elasticsearch 是一个基于JSON的分布式搜索和分析引擎。它可以从RESTful Web服务接口访问,并使用模式少JSON(JavaScript对象符号)文档来存储数据。它是基于Java编程语言,这使Elasticsearch能够在不同的平台上运行。使用户能够以非常快的速度来搜索非常大的数据量。
ElasticSearch可以做什么
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
Lucene是什么
ApacheLucene将写入索引的所有信息组织成一种倒排索引(Inverted Index)的结构之中,该结构是种将词项映射到文档的数据结构。其工作方式与传统的关系数据库不同,大致来说倒排索引是面向词项而不是面向文档的。且Lucene索引之中还存储了很多其他的信息,如词向量等等,每个Lucene都是由多个段构成的,每个段只会被创建一次但会被查询多次,段一旦创建就不会再被修改。多个段会在段合并的阶段合并在一起,何时合并由Lucene的内在机制决定,段合并后数量会变少,但是相应的段本身会变大。段合并的过程是非常消耗I/O的,且与之同时会有些不再使用的信息被清理掉。在Lucene中,将数据转化为倒排索引,将完整串转化为可用于搜索的词项的过程叫做分析。文本分析由分析器(Analyzer)来执行,分析其由分词器(Tokenizer),过滤器(Filter)和字符映射器(Character Mapper)组成,其各个功能显而易见。
Elk架构
“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。Elasticsearch 是一个搜索和分析引擎。Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
ElasticSearch名词
集群(cluster)
一个集群由一个或多个共享相同的群集名称的节点组成。每个群集有一个单独的主节点,这是由程序自动选择,如果当前主节点失败,程序会自动选择其他节点作为主节点。
节点(node)
一个节点属于一个集群。通常情况下一个服务器有一个节点,但有时候为了测试方便,一台服务器也可以有多个节点。在启动时,一个节点将使用广播来发现具有相同群集名称的现有群集,并将尝试加入该群集。节点属性根据elasticsearch.yml的一些配置来决定!其中master和datanode是必不可少的,其他的可以按照情况来进行添加!为了防止脑裂以及后续维护,建议将节点属性分离!
elasticsearch.yml配置:
-
node.master: true 并且 node.data: true
这种组合表示这个节点即有成为主节点的资格,又存储数据。
如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。ElasticSearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,因为这样相当于主节点和数据节点的角色混合到一块了。 -
node.master: false 并且 node.data: true
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。 这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据,后期提供存储和查询服务。 -
node.master: true 并且 node.data: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点,这个节点我们称为master节点。 -
node.master: false node.data: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。 -
node.ingest: true
执行预处理管道,不负责数据和集群相关的事物。
它在索引之前预处理文档,拦截文档的bulk和index请求,然后加以转换。
将文档传回给bulk和index API,用户可以定义一个管道,指定一系列的预处理器。
示例图:
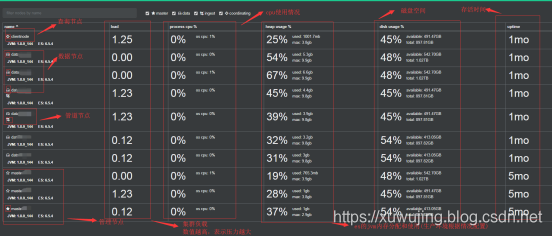
上述的节点属性可以根据实际的情况来进行配置。如果只有三台配置一般的服务器,在测试环境可以将master节点和datanode节点共用,也就是 node.master: true 并且 node.data: true ;在生产环境中,最好将节点分离,特别是masternode和datanode,哪怕是用配置非常差的服务器安装masternode。至于clientnode则需要看情况,如果有大量的查询,并且有很多的聚合分析查询的话,可以部署;ingestnode这个也是看具体的情况,如果有使用ingest等api的情况,也可以进行部署。至于集群规划这个我们在后续的文章中再来讲解。
索引(index)
索引是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。你可以把索引看成关系型数据库的表。然而,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。如果你知道MongoDB,可以Elasticsearch的索引看成MongoDB里的一个集合。如果你熟悉CouchDB,可以把索引看成CouchDB数据库索引。Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)。
根据<ElasticSearch权威指南>将ElasticSearch和传统关系型数据库作比较的话如下类比表:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
但是根据最新的ElasticSearch7.x中已经将Types移除了,并且在日常的使用中,我建议最好把一个索引(index)当做数据库的一张表来使用,类型(type)除了必要的情况,最好无视它,将它和索引库名设置一样即可。
这里顺便再来说下创建索引库的结构。我们知道在关系型数据库中需要创建表才能添加数据,但是在ElasticSearch中可以直接插入数据,它会根据你的第一条数据来自动创建索引库的结构, 但是这种在很多情况下是不符合我们要求的。如果我们想自己进行创建的话,那么就有必要了解一下index的setting和mapping了。
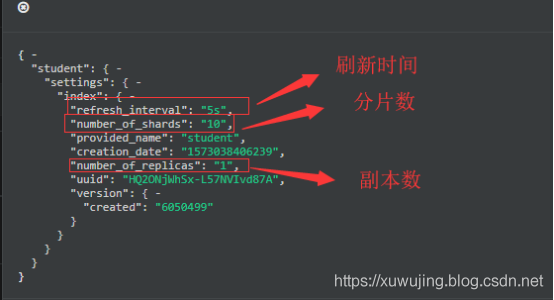
setting
setting可以理解为管理这个index的一些重要属性的,比如分片(shard)和副本(replica),它决定这个索引库最终的配置形态。初学者的话,可以只用管这三个配置参数即可:
- number_of_shards: 是设置的分片数,设置之后无法更改!
- refresh_interval: 是设置es缓存的刷新时间,如果写入较为频繁,但是查询对实时性要求不那么高的话,可以设置高一些来提升性能。可以更改
- number_of_replicas : 是设置该索引库的副本数,建议设置为1以上。
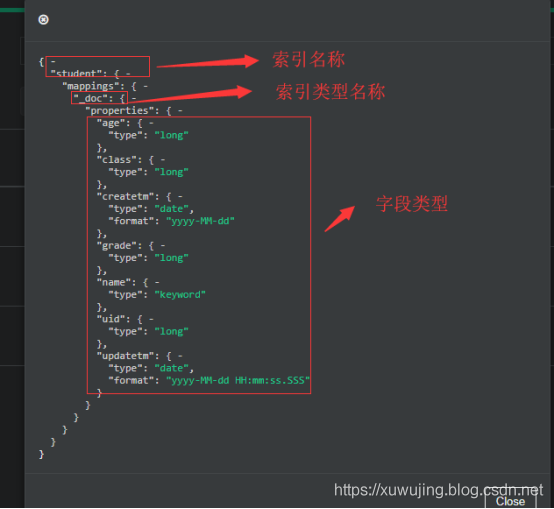
mapping
mapping可以理解为关系型数据库的表结构,指定字段的类型。初学者可以先只用关心text、keyword、byte、short、integer、long、float、double、boolean、date这几个字段,其中text和keyword都是string类型,选择区分很简单,需要进行分词用text,不需要并且进行排序或聚合的可以用keyword。
分片(shard)
分片是一个单一的Lucene实例。这个是由Elasticsearch管理的比较底层的功能。索引是指向主分片和副本分片的逻辑空间。对于使用,只需要指定分片的数量,其他不需要做过多的事情。在开发使用的过程中,我们对应的对象都是索引,Elasticsearch会自动管理集群中所有的分片,当发生故障的时候,一个Elasticsearch会把分片移动到不同的节点或者添加新的节点。
-
主分片(primary shard):每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,然后会复制到不同的副本中。默认情况下,一个索引有5个主分片。你可以在事先制定分片的数量,当分片一旦建立,分片的数量则不能修改。
-
副本分片(replica shard):每一个分片有零个或多个副本。副本主要是主分片的复制,其中有两个目的:
1、增加高可用性:当主分片失败的时候,可以从副本分片中选择一个作为主分片。
2、提高性能:当查询的时候可以到主分片或者副本分片中进行查询。默认情况下,一个主分配有一个副本,但副本的数量可以在后面动态的配置增加。副本必须部署在不同的节点上,不能部署在和主分片相同的节点上。
分片设置很重要!一个index指定了分片之后是无法修改的,因此在设置分片的时候一定要事前做好规划!
示例图: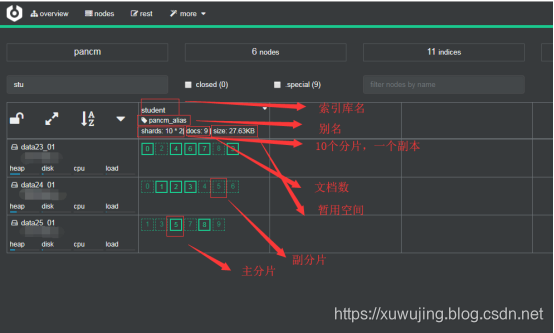
文档
存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。当比较Elasticsearch中的文档和MongoDB中的文档,你会发现两者都可以有不同的结构,但Elasticsearch的文档中,相同字段必须有相同类型。这意味着,所有包含 title 字段的文档, title 字段类型都必须一样,比如 string 。
文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)。每个字段有类型,如文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数组。字段类型在Elasticsearch中很重要,因为它给出了各种操作(如分析或排序)如何被执行的信息。幸好,这可以自动确定,然而,我们仍然建议使用映射。与关系型数据库不同,文档不需要有固定的结构,每个文档可以有不同的字段,此外,在程序开发期间,不必确定有哪些字段。当然,可以用模式强行规定文档结构。从客户端的角度看,文档是一个JSON对象。每个文档存储在一个索引中并有一个Elasticsearch自动生成的唯一标识符和文档类型。文档需要有对应文档类型的唯一标识符,这意味着在一个索引中,两个不同类型的文档可以有相同的唯一标识符。
- 文档类型:
在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评论。文档类型让我们轻易地区分单个索引中的不同对象。每个文档可以有不同的结构,但在实际部署中,将文件按类型区分对数据操作有很大帮助。当然,需要记住一个限制,不同的文档类型不能为相同的属性设置不同的类型。例如,在同一索引中的所有文档类型中,一个叫 title 的字段必须具有相同的类型。
核心数据类型
text 和 keyword数值数据类型
long,integer,short,byte,double,float,half_float,scaled_float日期数据类型
date布尔数据类型
boolean二进制数据类型
binary范围数据类型
integer_range,float_range,long_range,double_range,date_range复杂数据类型
对象数据类型
object 用于单个JSON对象嵌套数据类型
nested 用于JSON对象数组地理数据类型
地理位置数据类型
geo_point 纬度/经度积分地理形状数据类型
geo_shape 用于多边形等复杂形状专业数据类型
IP数据类型
ip 用于IPv4和IPv6地址完成数据类型
completion 提供自动完成建议令牌计数数据类型
token_count 计算字符串中令牌的数量
mapper-murmur3
murmur3 在索引时计算值的哈希并将其存储在索引中
mapper-annotated-text
annotated-text 索引包含特殊标记的文本(通常用于标识命名实体)渗滤器类型
接受来自query-dsl的查询join 数据类型
为同一索引内的文档定义父/子关系别名数据类型
为现有字段定义别名。多字段:
为不同的目的以不同的方式对同一字段建立索引通常很有用。例如,一个string字段可以映射为text用于全文搜索的字段,也可以映射为keyword用于排序或聚合的字段。或者,您可以使用standard分析仪, english分析仪和 french分析仪索引文本字段。
这是多领域的目的。大多数数据类型通过fields参数支持多字段。
-
映射:
在有关全文搜索基础知识部分,我们提到了分析的过程:为建索引和搜索准备输入文本。文档中的每个字段都必须根据不同类型做相应的分析。举例来说,对数值字段和从网页抓取的文本字段有不同的分析,比如前者的数字不应该按字母顺序排序,后者的第一步是忽略HTML标签,因为它们是无用的信息噪音。Elasticsearch在映射中存储有关字段的信息。 -
路由(routing):
当存储一个文档的时候,他会存储在一个唯一的主分片中,具体哪个分片是通过散列值的进行选择。默认情况下,这个值是由文档的id生成。如果文档有一个指定的父文档,从父文档ID中生成,该值可以在存储文档的时候进行修改。
这个属性在学习初期可以不必理会,使用默认即可。在有一定了解ElasticSearch之后可以在进行了解学习。 -
别名(alias):
它是一个或多个索引的一个附加名称,允许使用这个名称来查询索引。一个别名可以对应多个索引,反之亦然,一个索引可以是多个别名的一部分。别名只能用作查询,不能进行数据操作!
示例图:
其它
本文主要介绍了ElasticSearch的一些基础知识,其中ElasticSearch的理论知识远远不止这些,但是介绍的太多的话吸收不过来,其实很多的知识最好是边学边用中在掌握。学习ElasticSearch知识理论可以去官网学习,那里有非常详细的知识。
之后或许会写一篇关于ElasticSearch的集群规划,会从案例中进行讲解,包括机器、节点、索引库、分片副本一些选择和配置的一些具体知识。
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
参考书籍:
《ElasticSearch权威指南》
ElasticSearch实战系列:
ElasticSearch实战系列一: ElasticSearch集群+Kinaba安装教程
ElasticSearch实战系列二: ElasticSearch的DSL语句使用教程---图文详解
ElasticSearch实战系列三: ElasticSearch的JAVA API使用教程
音乐推荐
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
掘金出处:https://juejin.im/user/5ae45d5bf265da0b8a6761e4
个人博客出处:http://www.panchengming.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号