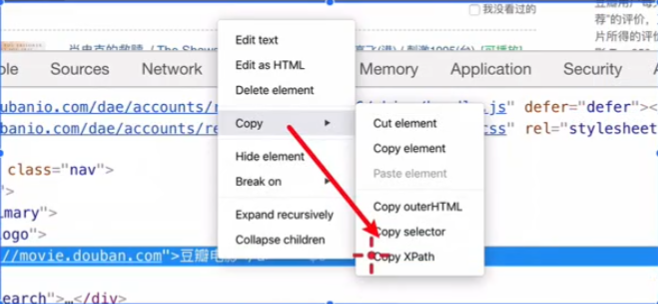
python爬虫 xpath
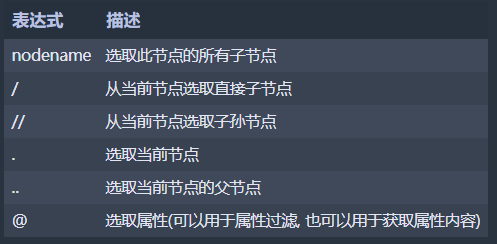
导入模块, 代码: from lxml import etree
将HTML文件解析成 Xpath对象 代码: html = etree.HTML(text)
调用Xpath解析对象的xpath 方法, 对内容进行解析
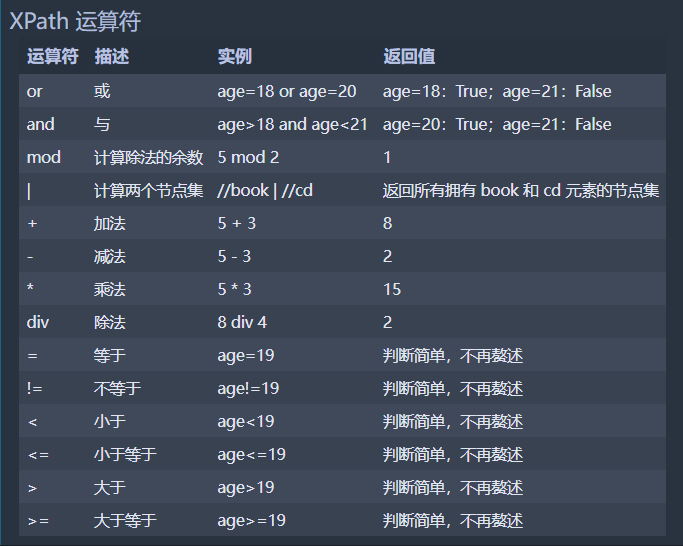
常用运算符 | 计算两个节点集 //book | //cd 返回所有拥有 book 和 cd 元素的节点集
常用函数
contains
last() : html.xpath('//a[last()]') #取多个a标签的最后一个
position :当前位置 html.xpath('//a[positon!=2]') #取多个a标签但不包含第2个a标签