

服务CPU高的问题
说明
服务CPU高的本质原因是某个方法一直在执行,导致其他线程阻塞。
场景
场景一:使用RedisLock
CPU高原因:使用RedisLock,导致未获取到锁的线程排队阻塞。
解决办法:减少RedisLock内的操作,特别是耗时长的操作。
场景二:kafka多线程消费
CPU高原因:Kafka的消费者,开启了多个线程进行消费,然后在每个线程中,又开启多线程处理,该子线程可能会出现大量Waiting,导致子线程阻塞,最终处理更慢。
解决办法:多线程消费时,尽量不要再开启多线程处理,可以考虑丢到其它kafka队列中。
场景三:Guava缓存
CPU高原因:使用Guava的get(key, loader)方法,当没有命中缓存时,会向缓存中原子性的加载新值,也就是调用loader方法是采用阻塞的方式。
源码在LocalCache类中:
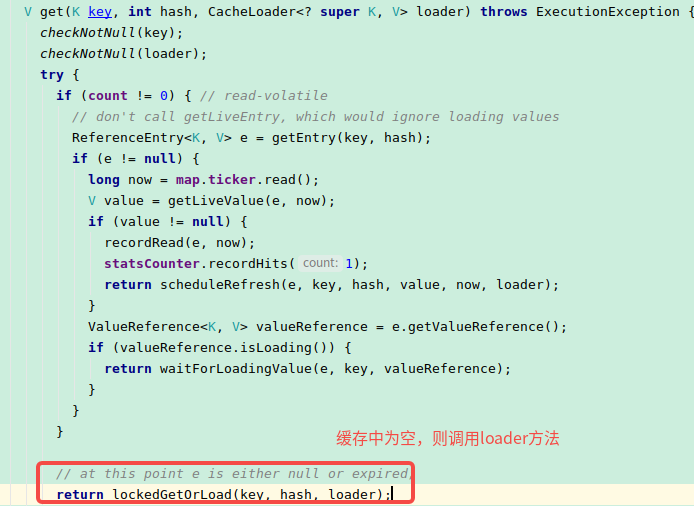
可以看到这里是使用ReentrantLock的方式来实现原子性操作:
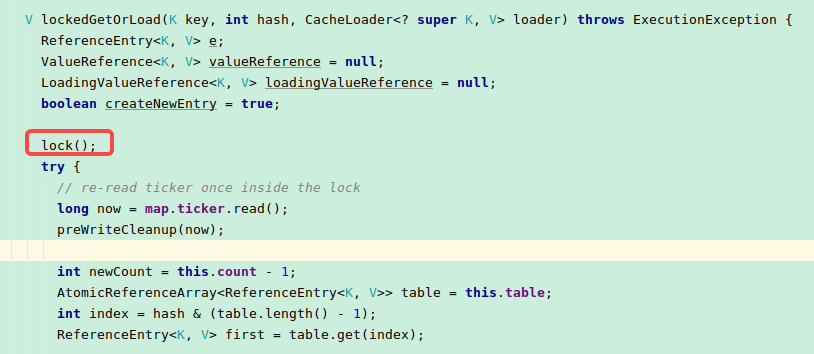
解决办法:
- 方案一:增加缓存失效时间
- 方案二:对于缓存的数据不会发生变化的,可以调用Guava的getIfPresent + put方法
场景四:mongo批量保存
CPU高原因:mongo的批量保存,是调用的 BulkOperations.execute() 方法,当批量保存设置为无序时,mongo会多线程并行保存,当线程数超过了mongo最大连接数,就会阻塞。
业务代码:
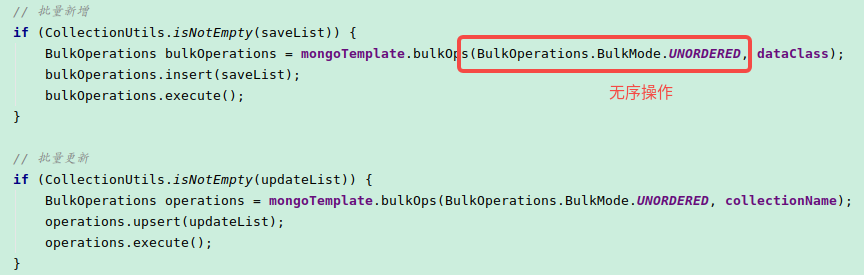
解决办法:每次批量保存时,减少批量保存的文档数
场景五:分布式本地缓存
CPU高原因:使用 DistributedCache,会有一步通过redis发布订阅同步数据到其它节点的操作,当waitAck=true时,会等待所有节点的ack,否则阻塞。
相关源码在LocalCachePubSub类中:
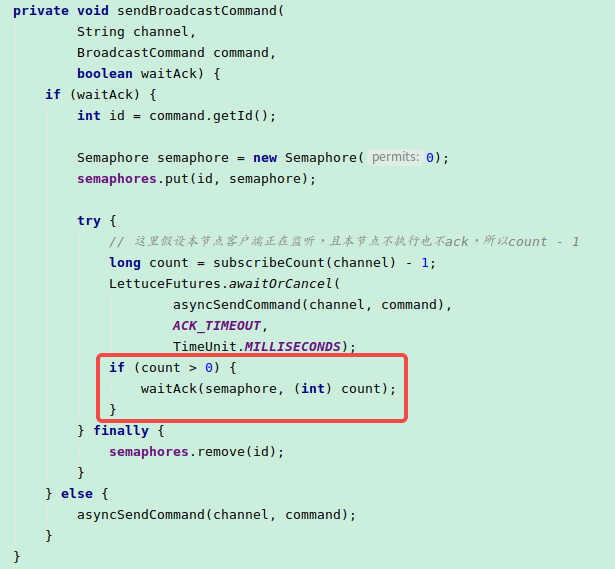
当未收到所有节点的ack时,这里会执行等待:
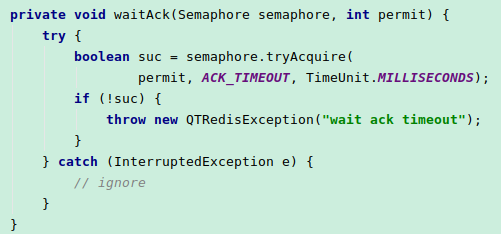
解决办法:短时间内大量缓存,或者缓存总是被更新的场景,尽量不要使用DistributedCache,可以考虑使用Guava的本地缓存,或者redis缓存。
知识改变世界

