python基础04
python基础04
python2在编译安装时,可以通过参数 -----enable----unicode=ucs2 或 -----enable--unicode=ucs4
分别用于指定使用2个字节,4个字节表示一个Unicode字符。python3无法进行选择,默认使用usc4.
查看当前python中表示Unicode字符串时占用的空间:
import sys
print(sys.maxunicode)
#如果值是65535,则表示使用usc2标准,即:2个字节表示
#如果值是1114111,则表示使用usc4标准,即:4个字节表示
昨日内容及作业讲解
ASCII:字母,数字,特殊字符,1个字节,8位
Unicode:16位 两个字节 升级32位 四个字节
utf -8:最少一个字节 8位表示。 英文字母8位 1个字节
欧洲16位,2个字节
中文24位,3个字节
gbk:中文2个字节,英文字母1个字节
int : bit_length()
bool : True False
str : str---->bool bool(str):' '------->False
str :
s = 'alexsb'
s1 = s[1]
s2 = s[1:3]
s3 = s[0:] s[:]
s4 = s[0:-1]
s5 = s[0:3:2]
s6 = s[2::2]
字符串的一些常用方法
upper()全大写
lower()全小写
find()通过元素找索引,找不到-1
index()通过元素找索引,找不到报错
swpcase()大小写翻转
len()
replace(old,new,count)
isdigit()返回bool值
isapha()
isnumpha()
startwith endwith
title()首字母大写
center()居中
strip() lstrip rstrip
split()
format()格式化输出
{}
{0}{1}{2}{0}
{name}{age}{hobby} name = age + hobby
len()长度
count 计数
for i in 可迭代对象:
pass
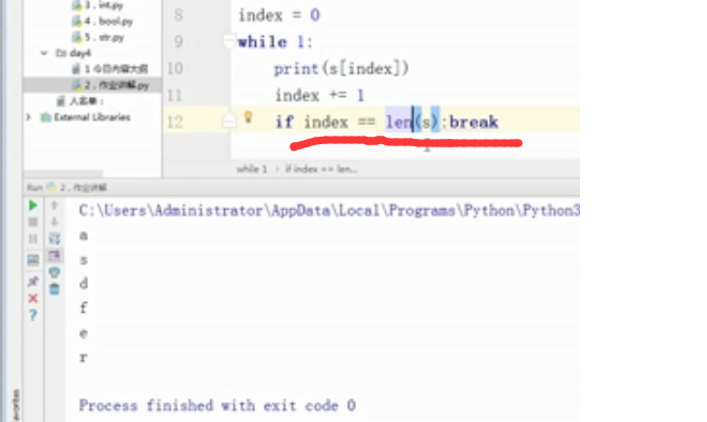
s = 'fkld'
#for i in s:
#print(s[index])
index + =1
if index == len(s):break;
#如:content = input('请输入内容:')#如用户输入:5+9或5 + 9.然后进行分割再进行计算
#content = input('>>>').strip()
#cool = content.split('+')
#li []
#num = 0
#for i in cool:
#num +=int(i)
#print(num)
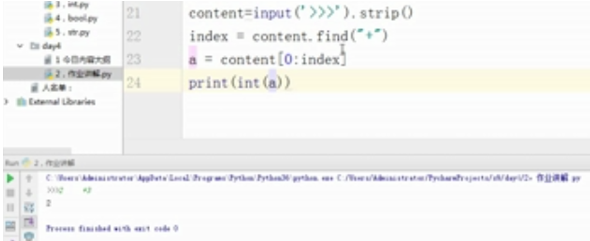
content = input('>>>').strip()
index = content.find("+")
a = content[0:index]
print(int(a))
content = input('>>>').strip()
index = content.find("+")
a = int(content[0:index])
b = int(content[index+1:])
print(a + b)

#任意输入一串文字+数字 统计出来数字的个数
s = input("请输入:")#‘123fdsaflfdsaf1’
count = 0
for i in s:
if i.isdigit():
count + = 1
print(count)

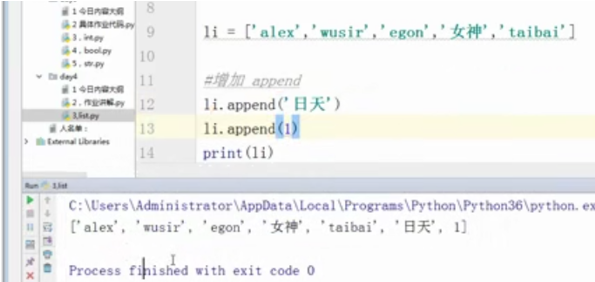
li = ['alex',[1,2,3],'wusir','egon','女神','taibai']
l1= li[0]
print(li)
l2 = li[1]
print(l2)
l3 = li[0:3]
print(l3)

li = ['alex',wusir,'egon','女神,'taibai']
#增加 append
li.append('日天')
li.append(l)
print(li)
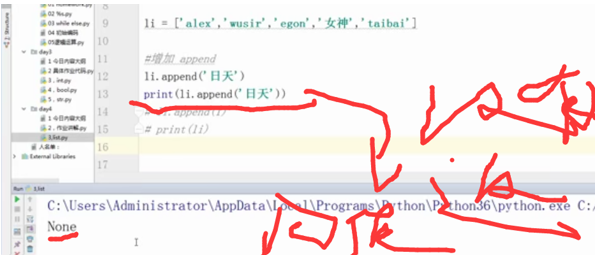
 li = li li li = ['alex','wusir','egon','女神','taibai']
li = li li li = ['alex','wusir','egon','女神','taibai']
#增加 append
li.append('日天')
print(li.append('日天'))
#li.append(1)
#peint(li)
while 1:
username = input('>>>>')
if username.strip().upper() == 'Q':
break
else:
li.append()
print(li)

li.insert(4,'春哥')
print(li)

#li.extend([1,2,3])
print(li)

#删
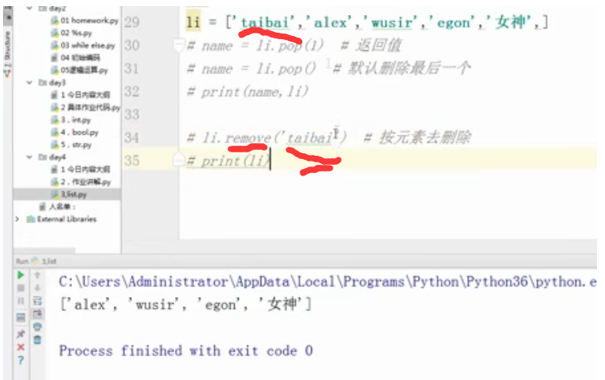
li = ['taibai', 'alex','wusir','egon','女神',]
li.pop(1)
print(li)

li = ['taibai','alex','wusir','egon','女神',]
#name = li.pop(1)#返回值
#name = li.pop()#默认删除最后一个
#print(name,li)
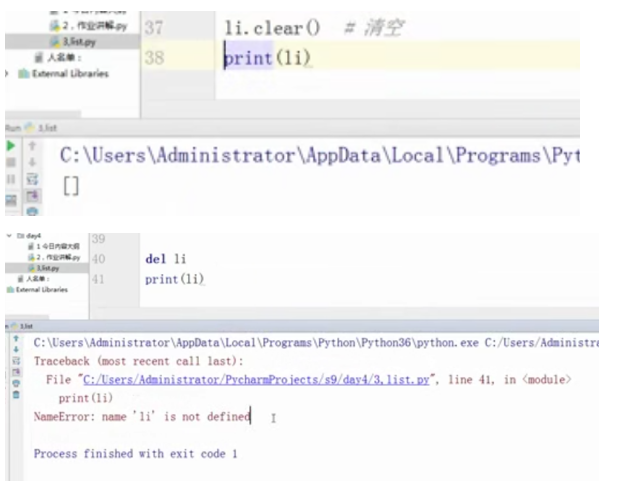
#li.clear()#清空
#print(li)
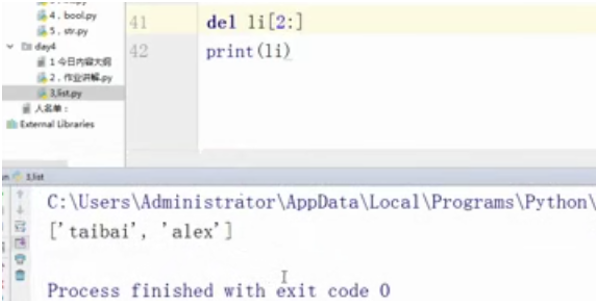
del li[2:]
print(li)
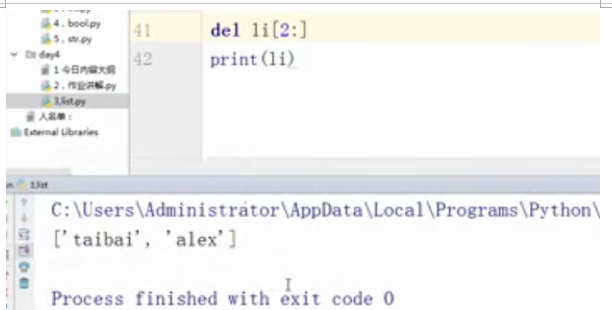
del li[2:]
print(li)
#del li
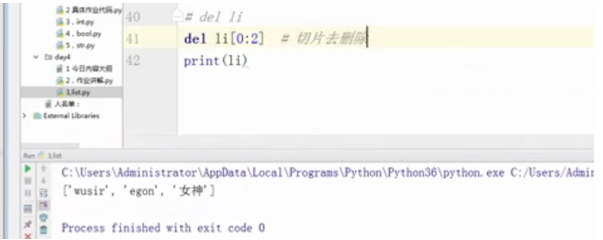
del li[0:2] #切片去删除
print(li)
#改
li[0] = '男兽'
print(li)

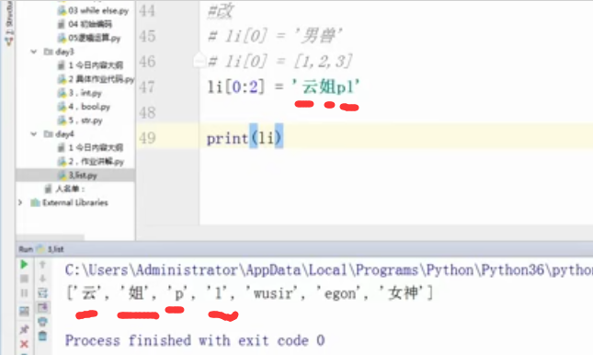
#改
#li[0] = '男兽'
#li[0] = [1,2,3]
li[0:2] = '云姐pl'
print(li)
#改
#li[0] = '男兽'
#li[0] = [1,2,3]
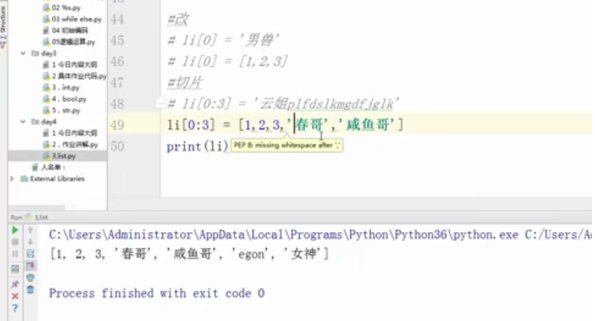
#切片
#li[0:3] = '云姐plfdslkmgdfjglk'
li[0:3] = [1,2,3,'春哥‘,'咸鱼哥']
print(li)
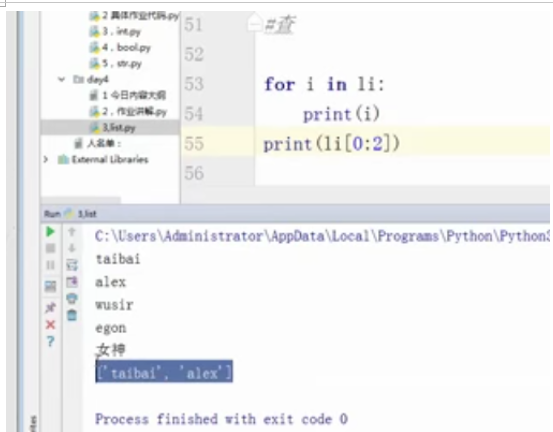
#查
for i in li:
print(i)
print(li[0:2])
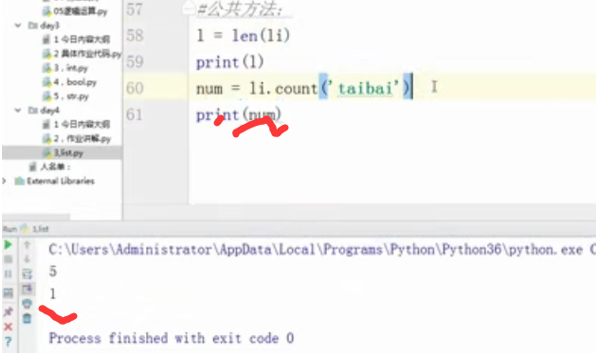
#公共方法:
l = len(li)
print(l)
num = li.print('taibai')
print(num)
print(li.index('wusir'))
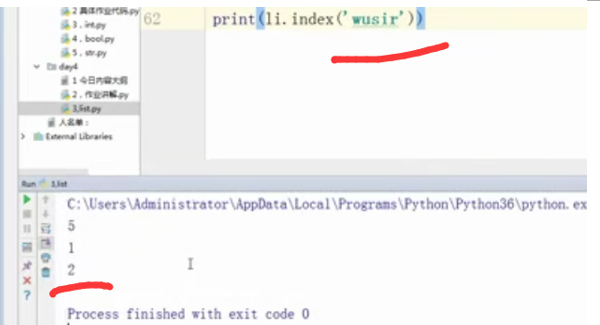
print(li.index('wusir2'))

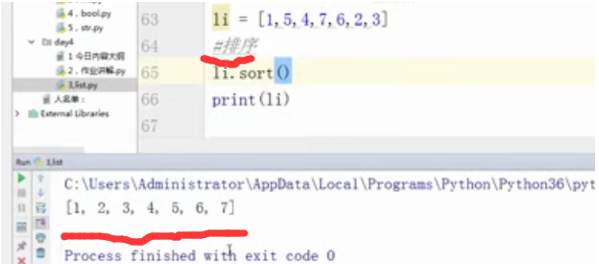
li = [1,5,4,,7,6,2,3]
#排序
li.sort()
print(li)
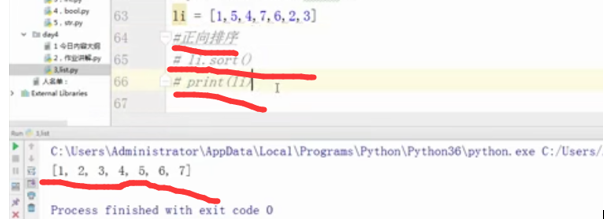
li = [1,5,4,7,6,2,3]
#正向排序
#li.sort()
#print(li)
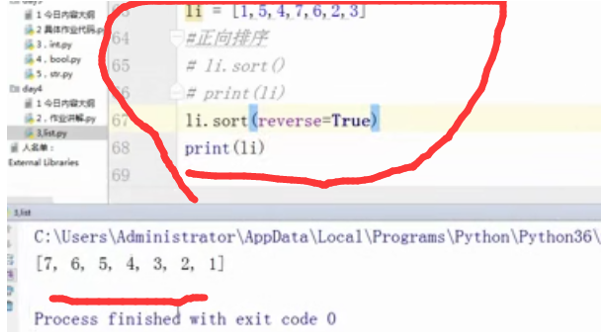
li = [1,5,4,7,6,2,3]
#正向排序
#li.sort()
#print(li)
li.sort(reverse = True)
print(li)
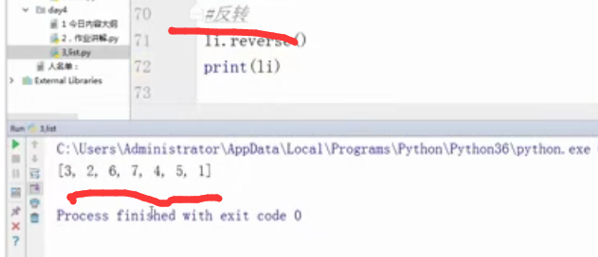
li = [1,5,4,7,6,2,3]
#正向排序
#li.sort()
#print()

#反转
li.reverse()
print(li)
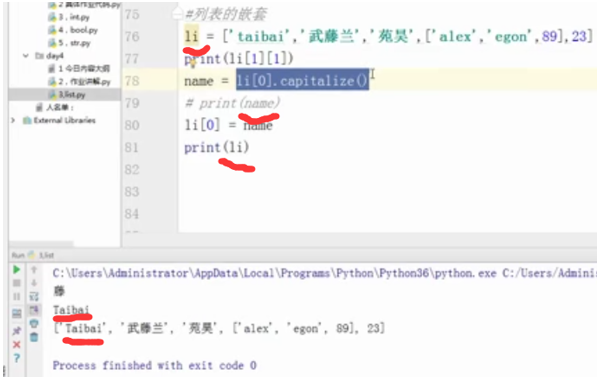
#列表的嵌套
li = ['taibai','武藤兰','苑昊',['alex','egon',89],23]
print(li[1][1])

#列表的嵌套
li = ['taibai','武藤兰',‘苑昊’,['alex','egon',89],23]
print(li[1][1])
name = li[0].capitalize()
#print(name)
li[0] = name
print(li)
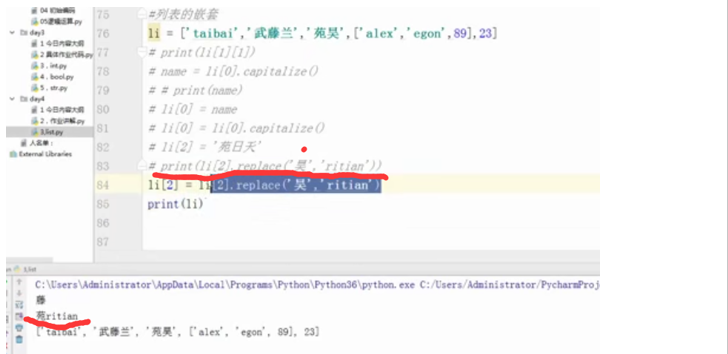
#列表的嵌套
li = ['taibai','武藤兰',‘苑昊’,[‘alex’,'egon',89],23]
#print(li[1][-1])
#name = li[0].capitalize()
# # print(name)
#li[0] = name
#li[0] = li[0].capitalize()
#li[2] = '苑日天'
#print(li[2].replace('昊','ritian'))
li[2] = li[2].replace('昊','ritian')
print(li)
#列表的嵌套
li = ['taibai','武藤兰','苑昊',['alex','egon',89],23]
print(li[1][1])
name = li[0].capitakize()
print(name)
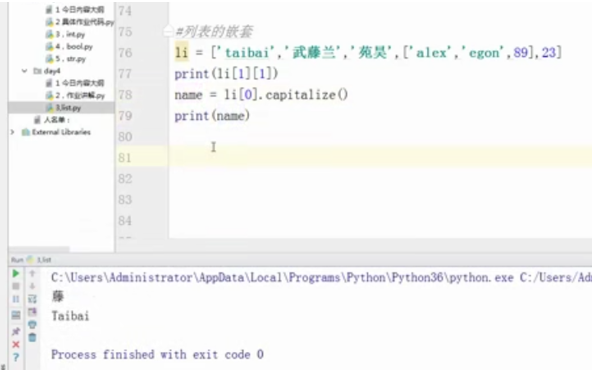
#列表的嵌套
li = ['taibai','武藤兰','苑昊',['alex','egon',89],23]
print(li[1][1])
name = li[0].capitalize()
#print(name)
li[0] = name
print(li)
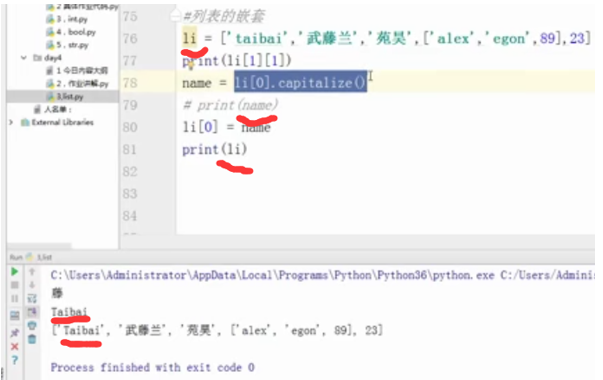
#列表的嵌套
li = ['taibai','武藤兰','苑昊',['alex','egon',89],23]
#print(li[1][1])
#name = li[0].capitalize()
#print(name)
#li[0] = name
#li[0] = li[0].capitalize()
#li[2] = '苑日天'
#print(li[2].replace('昊','ritian'))
li[2] = li[2].replace('昊','ritian')
print(li)
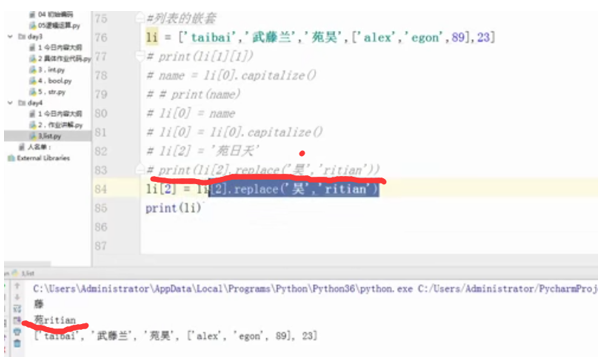
#列表的嵌套
li = ['taibai','武藤兰','苑昊',['alex','egon',89],23]
#print(li[1][1])
#name = li[0].capitalize()
#print(name)
#li[0] = name
#li[0] = li[0].capitalize()
#li[2] = '苑日天'
#print(li[2].replace('昊','ritian'))
#li[2] = li[2].replace('昊','ritian')
#print(li)
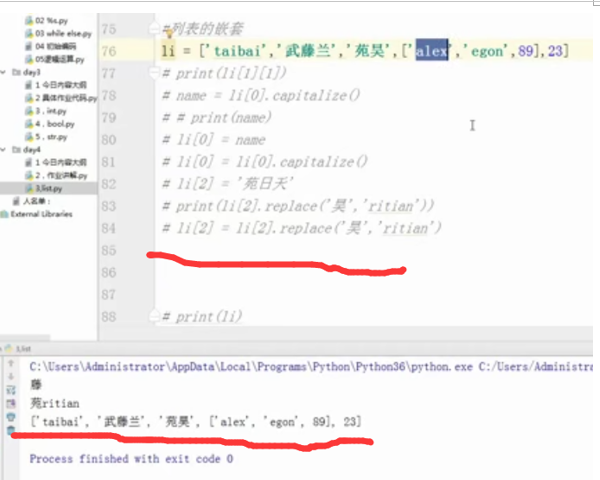
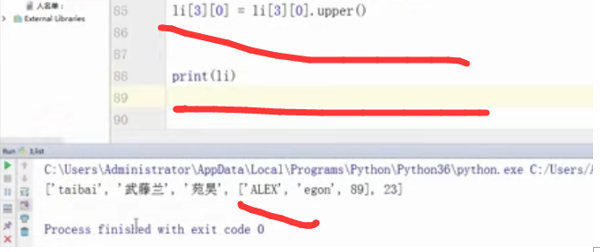
li[3][0] = li[3][0].upper()
print(li)
#元祖 只读列表,可循环查询,可切片
#儿子不能改,孙子可能可以改
tu = (1,2,3,'alex',[2,3,4,'taibai'],'egon')
print(tu[3])
print(tu[0:4])
for i in tu:
print(i)

tu = (1,2,3,'alex',[2,3,4,'taibai'],'egon')
#print(tu[3])
#print(tu[0:4])
#for i in tu:
# print(i)
tu[4][3]=tu[4][3].upper()
print(tu)

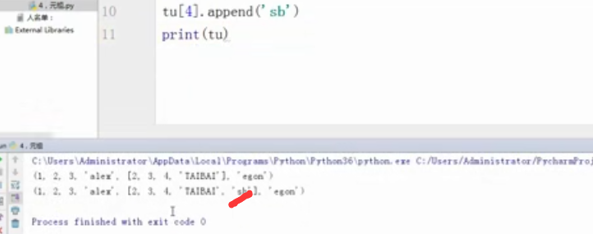
tu[4].append('sb')
print(tu)
s = 'alex'
s1 = '_'.join(s)
print(s1)

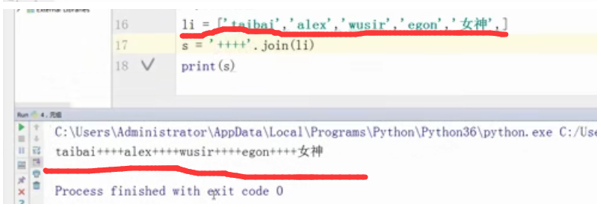
li = ['taibai','alex','wusir','egon','女神',]
s ='++++'.join(li)
print(s)
#列表转化成字符串join
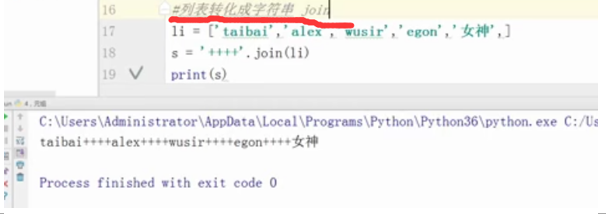
li = ['taibai','alex','wusir','egon','女神',]
s = '++++'.join(li)
print(s)
#列表转化成字符串 list----->str join
#li = ['taibai','alex','wusir','egon','女神']
#s = '++++'.join(li)
#str------>list split()
#print(s)
#for i in range(3,10):
# print(i)
for i in range(10):
print(i)

for i in range(0,10,3):
print(i)

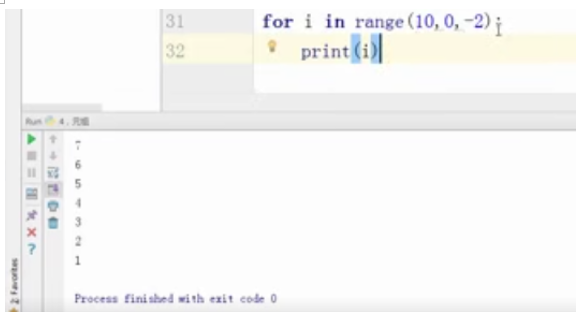
for i in range(10,0,-2):
print(i)
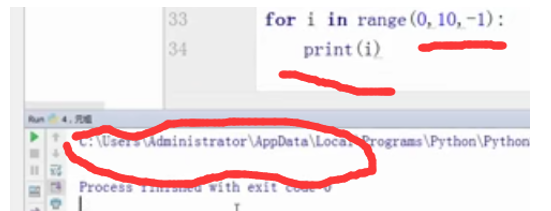
for i in range(0,10,-1):
print(i)
for i in range(10,0,-2):
print(i)

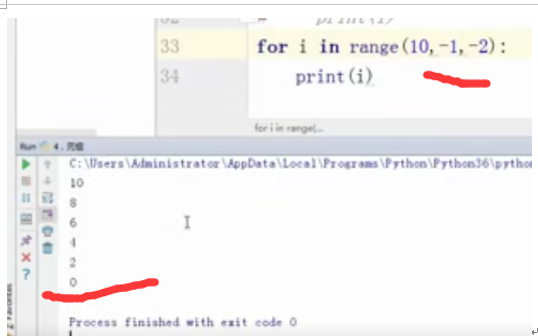
for i in range(10,-1,-2):
print(i)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号