
dubbo超时重试和异常处理
参考:
https://www.cnblogs.com/ASPNET2008/p/7292472.html
https://www.tuicool.com/articles/YfA3Ub
https://www.cnblogs.com/binyue/p/5380322.html
https://blog.csdn.net/mj158518/article/details/51228649
dubbo源码分析:超时原理以及应用场景
本篇主要记录dubbo中关于超时的常见问题,实现原理,解决的问题以及如何在服务降级中体现作用等。
超时问题
为了检查对dubbo超时的理解,尝试回答如下几个问题,如果回答不上来或者不确定那么说明此处需要再多研究研究。
我只是针对个人的理解提问题,并不代表我理解的就是全面深入的,但我的问题如果也回答不了,那至少说明理解的确是不够细的。
- 超时是针对消费端还是服务端?
- 超时在哪设置?
- 超时设置的优先级是什么?
- 超时的实现原理是什么?
- 超时解决的是什么问题?
问题解答
RPC场景
本文所有问题均以下图做为业务场景,一个web api做为前端请求,product service是产品服务,其中调用comment service(评论服务)获取产品相关评论,comment service从持久层中加载数据。

超时是针对消费端还是服务端?
-
如果是针对消费端,那么当消费端发起一次请求后,如果在规定时间内未得到服务端的响应则直接返回超时异常,但服务端的代码依然在执行。
-
如果是针对服务端,那么当消费端发起一次请求后,一直等待服务端的响应,服务端在方法执行到指定时间后如果未执行完,此时返回一个超时异常给到消费端。
dubbo的超时是针对客户端的,由于是一种NIO模式,消费端发起请求后得到一个ResponseFuture,然后消费端一直轮询这个ResponseFuture直至超时或者收到服务端的返回结果。虽然超时了,但仅仅是消费端不再等待服务端的反馈并不代表此时服务端也停止了执行。
按上图的业务场景,看看生成的日志:
product service:报超时错误,因为comment service 加载数据需要5S,但接口只等1S 。
Caused by: com.alibaba.dubbo.remoting.TimeoutException: Waiting server-side response timeout. start time: 2017-08-05 18:14:52.751, end time: 2017-08-05 18:14:53.764, client elapsed: 6 ms, server elapsed: 1006 ms, timeout: 1000 ms, request: Request [id=0, version=2.0.0, twoway=true, event=false, broken=false, data=RpcInvocation [methodName=getCommentsByProductId, parameterTypes=[class java.lang.Long], arguments=[1], attachments={traceId=6299543007105572864, spanId=6299543007105572864, input=259, path=com.jim.framework.dubbo.core.service.CommentService, interface=com.jim.framework.dubbo.core.service.CommentService, version=0.0.0}]], channel: /192.168.10.222:53204 -> /192.168.10.222:7777
at com.alibaba.dubbo.remoting.exchange.support.DefaultFuture.get(DefaultFuture.java:107) ~[dubbo-2.5.3.jar:2.5.3]
at com.alibaba.dubbo.remoting.exchange.support.DefaultFuture.get(DefaultFuture.java:84) ~[dubbo-2.5.3.jar:2.5.3]
at com.alibaba.dubbo.rpc.protocol.dubbo.DubboInvoker.doInvoke(DubboInvoker.java:96) ~[dubbo-2.5.3.jar:2.5.3]
... 42 common frames omittedcomment service : 并没有异常,而是慢慢悠悠的执行自己的逻辑:
2017-08-05 18:14:52.760 INFO 846 --- [2:7777-thread-5] c.j.f.d.p.service.CommentServiceImpl : getComments start:Sat Aug 05 18:14:52 CST 2017
2017-08-05 18:14:57.760 INFO 846 --- [2:7777-thread-5] c.j.f.d.p.service.CommentServiceImpl : getComments end:Sat Aug 05 18:14:57 CST 2017从日志来看,超时影响的是消费端,与服务端没有直接关系。
超时在哪设置?
消费端
- 全局控制
<dubbo:consumer timeout="1000"></dubbo:consumer>- 接口控制
- 方法控制
服务端
- 全局控制
<dubbo:provider timeout="1000"></dubbo:provider>- 接口控制
- 方法控制
可以看到dubbo针对超时做了比较精细化的支持,无论是消费端还是服务端,无论是接口级别还是方法级别都有支持。
超时设置的优先级是什么?
上面有提到dubbo支持多种场景下设置超时时间,也说过超时是针对消费端的。那么既然超时是针对消费端,为什么服务端也可以设置超时呢?
这其实是一种策略,其实服务端的超时配置是消费端的缺省配置,即如果服务端设置了超时,任务消费端可以不设置超时时间,简化了配置。
另外针对控制的粒度,dubbo支持了接口级别也支持方法级别,可以根据不同的实际情况精确控制每个方法的超时时间。所以最终的优先顺序为:客户端方法级>服务端方法级>客户端接口级>服务端接口级>客户端全局>服务端全局
超时的实现原理是什么?
之前有简单提到过, dubbo默认采用了netty做为网络组件,它属于一种NIO的模式。消费端发起远程请求后,线程不会阻塞等待服务端的返回,而是马上得到一个ResponseFuture,消费端通过不断的轮询机制判断结果是否有返回。因为是通过轮询,轮询有个需要特别注要的就是避免死循环,所以为了解决这个问题就引入了超时机制,只在一定时间范围内做轮询,如果超时时间就返回超时异常。
源码
ResponseFuture接口定义
public interface ResponseFuture {
/**
* get result.
*
* @return result.
*/
Object get() throws RemotingException;
/**
* get result with the specified timeout.
*
* @param timeoutInMillis timeout.
* @return result.
*/
Object get(int timeoutInMillis) throws RemotingException;
/**
* set callback.
*
* @param callback
*/
void setCallback(ResponseCallback callback);
/**
* check is done.
*
* @return done or not.
*/
boolean isDone();
}ReponseFuture的实现类:DefaultFuture
只看它的get方法,可以清楚看到轮询的机制。
public Object get(int timeout) throws RemotingException {
if (timeout <= 0) {
timeout = Constants.DEFAULT_TIMEOUT;
}
if (! isDone()) {
long start = System.currentTimeMillis();
lock.lock();
try {
while (! isDone()) {
done.await(timeout, TimeUnit.MILLISECONDS);
if (isDone() || System.currentTimeMillis() - start > timeout) {
break;
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
if (! isDone()) {
throw new TimeoutException(sent > 0, channel, getTimeoutMessage(false));
}
}
return returnFromResponse();
}
超时解决的是什么问题?
设置超时主要是解决什么问题?如果没有超时机制会怎么样?
回答上面的问题,首先要了解dubbo这类rpc产品的线程模型。下图是我之前个人RPC学习产品的示例图,与dubbo的线程模型大致是相同的,有兴趣的可参考我的笔记:简单RPC框架-业务线程池
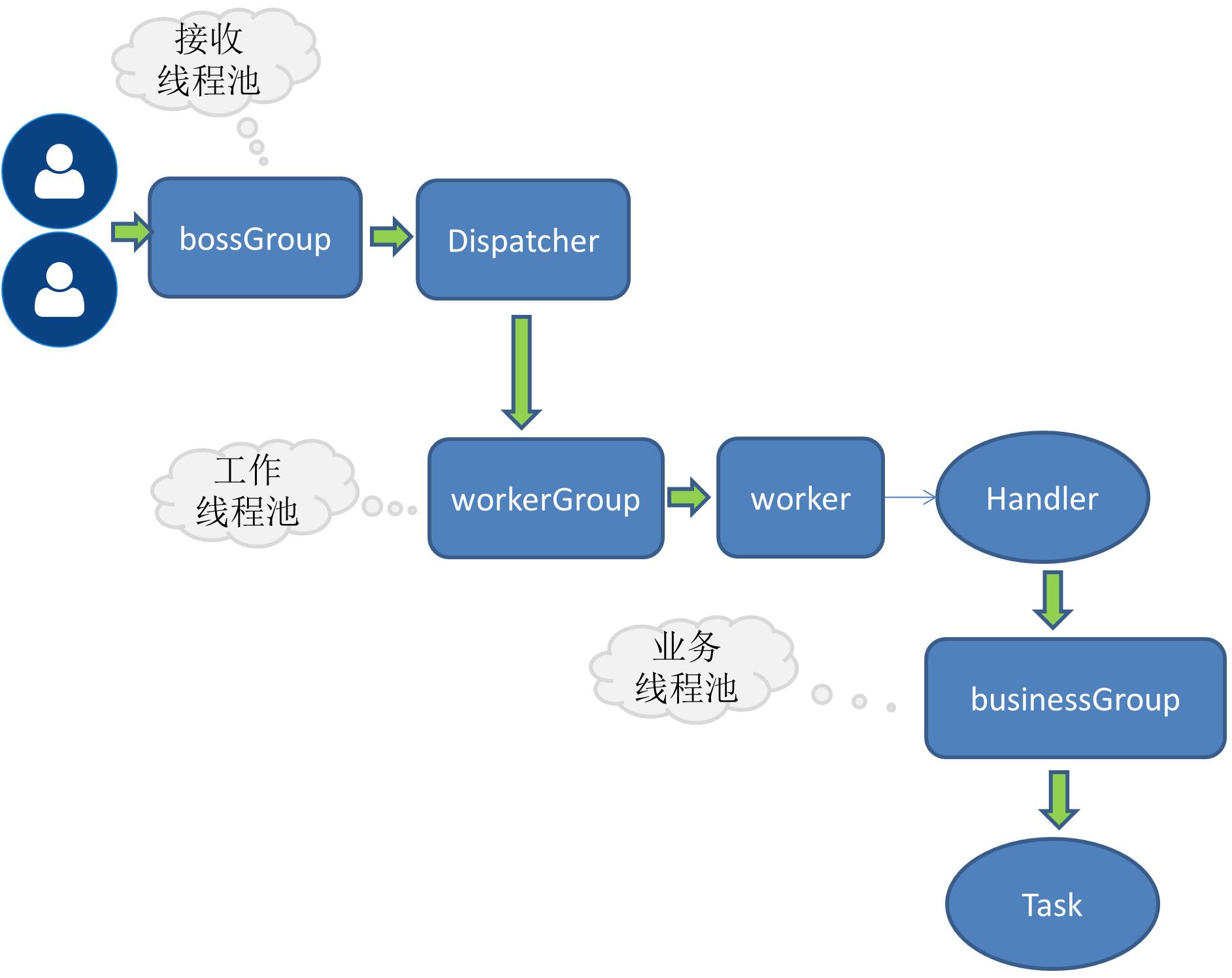
我们从dubbo的源码看下这下线程模型是怎么用的:
netty boss
主要是负责socket连接之类的工作。
netty wokers
将一个请求分给后端的某个handle去处理,比如心跳handle ,执行业务请求的 handle等。
Netty Server中可以看到上述两个线程池是如何初始化的:
首选是open方法,可以看到一个boss一个worker线程池。
protected void doOpen() throws Throwable {
NettyHelper.setNettyLoggerFactory();
ExecutorService boss = Executors.newCachedThreadPool(new NamedThreadFactory("NettyServerBoss", true));
ExecutorService worker = Executors.newCachedThreadPool(new NamedThreadFactory("NettyServerWorker", true));
ChannelFactory channelFactory = new NioServerSocketChannelFactory(boss, worker, getUrl().getPositiveParameter(Constants.IO_THREADS_KEY, Constants.DEFAULT_IO_THREADS));
bootstrap = new ServerBootstrap(channelFactory);
// ......
}
再看ChannelFactory的构造函数:
public NioServerSocketChannelFactory(Executor bossExecutor, Executor workerExecutor, int workerCount) {
this(bossExecutor, 1, workerExecutor, workerCount);
}
可以看出,boss线程池的大小为1,worker线程池的大小也是可以配置的,默认大小是当前系统的核心数+1,也称为IO线程。
busines(业务线程池)
为什么会有业务线程池,这里不多解释,可以参考我上面的文章。
缺省是采用固定大小的线程池,dubbo提供了三种不同类型的线程池供用户选择。我们看看这个类:AllChannelHandler,它是其中一种handle,处理所有请求,它的一个作用就是调用业务线程池去执行业务代码,其中有获取线程池的方法:
private ExecutorService getExecutorService() {
ExecutorService cexecutor = executor;
if (cexecutor == null || cexecutor.isShutdown()) {
cexecutor = SHARED_EXECUTOR;
}
return cexecutor;
}
上面代码中的变量executor来自于AllChannelHandler的父类WrappedChannelHandler,看下它的构造函数:
public WrappedChannelHandler(ChannelHandler handler, URL url) {
//......
executor = (ExecutorService) ExtensionLoader.getExtensionLoader(ThreadPool.class).getAdaptiveExtension().getExecutor(url);
//......
}获取线程池来自于SPI技术,从代码中可以看出线程池的缺省配置就是上面提到的固定大小线程池。
@SPI("fixed")
public interface ThreadPool {
/**
* 线程池
*
* @param url 线程参数
* @return 线程池
*/
@Adaptive({Constants.THREADPOOL_KEY})
Executor getExecutor(URL url);
}最后看下是如何将请求丢给线程池去执行的,在AllChannelHandler中有这样的方法:
public void received(Channel channel, Object message) throws RemotingException {
ExecutorService cexecutor = getExecutorService();
try {
cexecutor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}典型问题:拒绝服务
如果上面提到的dubbo线程池模型理解了,那么也就容易理解一个问题,当前端大量请求并发出现时,很有可以将业务线程池中的线程消费完,因为默认缺省的线程池是固定大小(我现在版本缺省线程池大小为200),此时会出现服务无法按预期响应的结果,当然由于是固定大小的线程池,当核心线程滿了后也有队列可排,但默认是不排队的,需要排队需要单独配置,我们可以从线程池的具体实现中看:
public class FixedThreadPool implements ThreadPool {
public Executor getExecutor(URL url) {
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS);
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}上面代码的结论是:
- 默认线程池大小为200(不同的dubbo版本可能此值不同)
- 默认线程池不排队,如果需要排队,需要指定队列的大小
当业务线程用完后,服务端会报如下的错误:
Caused by: java.util.concurrent.RejectedExecutionException: Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-192.168.10.222:9999, Pool Size: 1 (active: 1, core: 1, max: 1, largest: 1), Task: 8 (completed: 7), Executor status:(isShutdown:false, isTerminated:false, isTerminating:false), in dubbo://192.168.10.222:9999!
at com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport.rejectedExecution(AbortPolicyWithReport.java:53) ~[dubbo-2.5.3.jar:2.5.3]
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:823) [na:1.8.0_121]
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1369) [na:1.8.0_121]
at com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler.caught(AllChannelHandler.java:65) ~[dubbo-2.5.3.jar:2.5.3]
... 17 common frames omitted
通过上面的分析,对调用的服务设置超时时间,是为了避免因为某种原因导致线程被长时间占用,最终出现线程池用完返回拒绝服务的异常。
超时与服务降级
按我们文章之前的场景,web api 请求产品明细时调用product service,为了查询产品评论product service调用comment service。如果此时由于comment service异常,响应时间增大到10S(远大于上游服务设置的超时时间),会发生超时异常,进而导致整个获取产品明细的接口异常,这也就是平常说的强依赖。这类强依赖是超时不能解决的,解决方案一般是两种:
- 调用comment service时做异常捕获,返回空值或者返回具体的错误码,消费端根据不同的错误码做不同的处理。
- 调用coment service做服务降级,比如发生异常时返回一个mock的数据,dubbo默认支持mock。
只有通过做异常捕获或者服务降级才能确保某些不重要的依赖出问题时不影响主服务的稳定性。而超时就可以与服务降级结合起来,当消费端发生超时时自动触发服务降级, 这样即使我们的评论服务一直慢,但不影响获取产品明细的主体功能,只不过会牺牲部分体验,用户看到的评论不是真实的,但评论相对是个边缘功能,相比看不到产品信息要轻的多,某种程度上是可以舍弃的。
Dubbo超时机制导致的雪崩连接
BUG作者: 许晓
Bug 标题: Dubbo超时机制导致的雪崩连接
Bug 影响: Dubbo 服务提供者出现无法获取 Dubbo 服务处理线程异常,后端 DB 爆出拿不到数据库连接池,导致前端响应时间异常飙高,系统处理能力下降,核心基础服务无法提供正常服务。
Bug 发现过程:
线 上,对于高并发的服务化接口应用,时常会出现Dubbo连接池爆满情况,通常,我们理所应当的认为,这是客户端并发连接过高所致,一方面调整连接池大小, 一方面考虑去增加服务接口的机器,当然也会考虑去优化服务接口的应用。很自然的,当我们在线上压测一个营销页面(为大促服务,具备高并发)时,我们遇到了 这种情况。而通过不断的深入研究,我发现了一个特别的情况。
场景描述:

压力从Jmeter压至前端web应用marketingfront,场景是批量获取30个产品的信息。wsproductreadserver有一个批量接口,会循环从tair中获取产品信息,若缓存不存在,则命中db。
压测后有两个现象:
1) Dubbo的服务端爆出大量连接拿不到的异常,还伴随着无法获取数据库连接池的情况

2) Dubbo Consumer端有大量的Dubbo超时和重试的异常,且重试3次后,均失败。
3) Dubbo Consumer端的最大并发时91个

Dubbo Provider端的最大并发却是600个,而服务端配置的dubbo最大线程数即为600。

这个时候,出于性能测试的警觉性,发现这两个并发数极为不妥。
按照正常的请求模式,DubboConsumer和DubboProvider展示出来的并发应该是一致的。此处为何会出现服务端的并发数被放大6倍,甚至有可能不止6倍,因为服务端的dubbo连接数限制就是600。
此处开始发挥性能测试各种大胆猜想:
1)是否是因为服务端再dubboServerHandle处理请求时,开启了多线程,而这块儿的多线程会累计到Dubbo的连接上,dragoon采集的这个数据可以真实的反应目前应用活动的线程对系统的压力情况;
2)压测环境不纯洁?我的小伙伴们在偷偷和我一起压测?(这个被我生生排除了,性能测试基本环境还是要保持独立性)
3)是否是因为超时所致?这里超时会重试3次,那么顺其自然的想,并发有可能最多会被放大到3倍,3*91=273<<600....还是不止3倍?
有了猜想,就得小心求证!
首先通过和dubbo开发人员 【草谷】分析,Dubbo连接数爆满的原因,猜想1被否决,Dubbo服务端连接池是计数DubboServerHandle个数的业务是否采用多线程无关。
通过在压测时,Dump provider端的线程数,也证明了这个。

那么,可能还是和超时有很大关系。
再观察wsproductreadserver接口的处理时间分布情况:

从 RT 的分布来看 。基本上 78.5% 的响应时间是超过 1s 的。那么这个接口方法的 dubbo 超时时间是 500ms ,此时 dubbo 的重试机制会带来怎样的 雪崩效应 呢?

如果按照上图,虽然客户端只有1个并发在做操作,但是由于服务端执行十分耗时,每个请求的执行RT远远超过了超时时间500ms,此时服务端的最大并发会有多少呢?
和服务端处理的响应时间有特比特别大的关系。服务端处理时间变长,但是如果超时,客户端的阻塞时间却只有可怜的500ms,超过500ms,新一轮压力又将发起。
上图可直接看到的并发是8个,如果服务端RT再长些,那么并发可能还会再大些!
这也是为什么从marketingfront consumer的dragoon监控来看,只有90个并发。但是到服务端,却导致dubbo连接池爆掉的直接原因。
查看了wsproductreadserver的堆栈,600个dubboServerHandle大部分都在做数据库的读取和数据库连接获取以及tair的操作。

所以,为什么Dubbo服务端的连接池会爆掉?很有可能就是因为你的服务接口,在高并发下的大部分RT分布已经超过了你的Dubbo设置的超时时间!这将直接导致Dubbo的重试机制会不断放大你的服务端请求并发。
所 以如果,你在线上曾经遇到过类似场景,您可以采取去除Dubbo的重试机器,并且合理的设置Dubbo的超时时间。目前国际站的服务中心,已经开始去除 Dubbo的重试机制。当然Dubbo的重试机制其实是非常好的QOS保证,它的路由机制,是会帮你把超时的请求路由到其他机器上,而不是本机尝试,所以 dubbo的重试机器也能一定程度的保证服务的质量。但是请一定要综合线上的访问情况,给出综合的评估。
------------ 等等等,别着急,我们似乎又忽略了一些细节,元芳,你怎么看? ------------------------
我们重新回顾刚才的业务流程架构,wsproductReadserver层有DB和tair两级存储。那么对于同样接口为什么服务化的接口RT如此之差,按照前面提到的架构,包含tair缓存,怎么还会有数据库连接获取不到的情况?
接续深入追踪,将问题暴露和开发讨论,他们拿出tair
可以看到,客户端提交批量查询30个产品的产品信息。在服务端,有一个缓存模块,缓存的key是产品的ID。当产品命中tair时,则直接返回,若不命中,那么回去db中取数,再放入缓存中。
这里可以发现一个潜在的性能问题:
客 户端提交30个产品的查询请求,而服务端,则通过for循环和tair交互,所以这个接口在通常情况下的性能估计也得超过60-100ms。如果不是30 个产品,而是50或者100,那么这个接口的性能将会衰减的非常厉害!(这纯属性能测试的yy,当然这个暂时还不是我们本次关注的主要原因)
那么如此的架构,请求打在db上的可能性是比较小的, 由缓存命中率来保证。从线上真实的监控数据来看,tair的命中率在70%,应该说还不错,为什么在我们的压测场景,DB的压力确是如此凶残,甚至导致db的连接池无法获取呢?
所以性能验证场景就呼之欲出了:
场景: 准备30个产品ID,保持不变,这样最多只会第一次会去访问DB,并将数据存入缓存,后面将会直接命中缓存,db就在后面喝喝茶好了!

但是从测试结果来看,有两点可以观察到:
1)
2)
3)
于是开始检查这30个产品到底有哪几个没有存入缓存。
通 过开发Debug预发布环境代码,最终发现,这两个产品竟然已经被用户移到垃圾箱了。而通过和李浩和跃波沟通SellerCoponList的业务来 看,DA推送过来的产品是存在被用户移除的可能性。因而,每次这两个数据的查询,由于数据库查询不到记录,tair也没有存储相关记录,导致这些查询都将 经过数据库。数据库压力原因也找到了。
但是问题还没有结束,这似乎只像是冰山表面,我们希望能够鸟瞰整个冰山!
细细品味这个问题的最终性能表象 , 这是一种变向击穿缓存的做法啊!也就是具备一定的通用性。如果接口始终传入数据库和缓存都不可能存在的数据,那么每次的访问都就落到db上,导致缓存变相击穿,这个现象很有意思!
目前有一种解决方案,就是Null Object Pattern,将数据库不存在的记录也记录到缓存中,但是value为NULL,使得缓存可以有效的拦截。由于数据的超时时间是10min,所以如果数据有所改动,也可以接受。
我相信这只是一种方案,可能还会有其他方案,但是这种变向的缓存击穿却让我很兴奋。回过头来,如果让我自己去实现这样的缓存机制,数据库和缓存都不存在的数据场景很容易被忽略,并且这个对于业务确实也不会有影响。在线上存在大量热点数据情况下,这样的机制,往往并不会暴露性能问题。巧合的是,特定的场景, 性能却会出现很大的偏差,这考验的既是性能测试工程师的功力,也考验的是架构的功力!
Bug 解决办法:
其实这过程中不仅仅有一些方法论,也有一些是性能测试经验的功底,更重要的是产出了一些通用性的性能问题解决方案,以及部分参数和技术方案的设计对系统架构的影响。
1)对于核心的服务中心,去除dubbo超时重试机制,并重新评估设置超时时间。
2)对于存在tair或者其他中间件缓存产品,对NULL数据进行缓存,防止出现缓存的变相击穿问题
Dubbo超时和重连机制
dubbo启动时默认有重试机制和超时机制。
超时机制的规则是如果在一定的时间内,provider没有返回,则认为本次调用失败,
重试机制在出现调用失败时,会再次调用。如果在配置的调用次数内都失败,则认为此次请求异常,抛出异常。
如果出现超时,通常是业务处理太慢,可在服务提供方执行:jstack PID > jstack.log 分析线程都卡在哪个方法调用上,这里就是慢的原因。
如果不能调优性能,请将timeout设大。
某些业务场景下,如果不注意配置超时和重试,可能会引起一些异常。
1.超时设置
DUBBO消费端设置超时时间需要根据业务实际情况来设定,
如果设置的时间太短,一些复杂业务需要很长时间完成,导致在设定的超时时间内无法完成正常的业务处理。
这样消费端达到超时时间,那么dubbo会进行重试机制,不合理的重试在一些特殊的业务场景下可能会引发很多问题,需要合理设置接口超时时间。
比如发送邮件,可能就会发出多份重复邮件,执行注册请求时,就会插入多条重复的注册数据。
(1)合理配置超时和重连的思路
1.对于核心的服务中心,去除dubbo超时重试机制,并重新评估设置超时时间。
2.业务处理代码必须放在服务端,客户端只做参数验证和服务调用,不涉及业务流程处理
(2)Dubbo超时和重连配置示例
|
1
2
|
<!-- 服务调用超时设置为5秒,超时不重试--> <dubbo:service interface="com.provider.service.DemoService" ref="demoService" retries="0" timeout="5000"/> |
2.重连机制
dubbo在调用服务不成功时,默认会重试2次。
Dubbo的路由机制,会把超时的请求路由到其他机器上,而不是本机尝试,所以 dubbo的重试机制也能一定程度的保证服务的质量。
但是如果不合理的配置重试次数,当失败时会进行重试多次,这样在某个时间点出现性能问题,调用方再连续重复调用,
系统请求变为正常值的retries倍,系统压力会大增,容易引起服务雪崩,需要根据业务情况规划好如何进行异常处理,何时进行重试。
浅谈dubbo的ExceptionFilter异常处理
背景
ExceptionFilter
- /*
- * Copyright 1999-2011 Alibaba Group.
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
- package com.alibaba.dubbo.rpc.filter;
- import java.lang.reflect.Method;
- import com.alibaba.dubbo.common.Constants;
- import com.alibaba.dubbo.common.extension.Activate;
- import com.alibaba.dubbo.common.logger.Logger;
- import com.alibaba.dubbo.common.logger.LoggerFactory;
- import com.alibaba.dubbo.common.utils.ReflectUtils;
- import com.alibaba.dubbo.common.utils.StringUtils;
- import com.alibaba.dubbo.rpc.Filter;
- import com.alibaba.dubbo.rpc.Invocation;
- import com.alibaba.dubbo.rpc.Invoker;
- import com.alibaba.dubbo.rpc.Result;
- import com.alibaba.dubbo.rpc.RpcContext;
- import com.alibaba.dubbo.rpc.RpcException;
- import com.alibaba.dubbo.rpc.RpcResult;
- import com.alibaba.dubbo.rpc.service.GenericService;
- /**
- * ExceptionInvokerFilter
- * <p>
- * 功能:
- * <ol>
- * <li>不期望的异常打ERROR日志(Provider端)<br>
- * 不期望的日志即是,没有的接口上声明的Unchecked异常。
- * <li>异常不在API包中,则Wrap一层RuntimeException。<br>
- * RPC对于第一层异常会直接序列化传输(Cause异常会String化),避免异常在Client出不能反序列化问题。
- * </ol>
- *
- * @author william.liangf
- * @author ding.lid
- */
- @Activate(group = Constants.PROVIDER)
- public class ExceptionFilter implements Filter {
- private final Logger logger;
- public ExceptionFilter() {
- this(LoggerFactory.getLogger(ExceptionFilter.class));
- }
- public ExceptionFilter(Logger logger) {
- this.logger = logger;
- }
- public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
- try {
- Result result = invoker.invoke(invocation);
- if (result.hasException() && GenericService.class != invoker.getInterface()) {
- try {
- Throwable exception = result.getException();
- // 如果是checked异常,直接抛出
- if (! (exception instanceof RuntimeException) && (exception instanceof Exception)) {
- return result;
- }
- // 在方法签名上有声明,直接抛出
- try {
- Method method = invoker.getInterface().getMethod(invocation.getMethodName(), invocation.getParameterTypes());
- Class<?>[] exceptionClassses = method.getExceptionTypes();
- for (Class<?> exceptionClass : exceptionClassses) {
- if (exception.getClass().equals(exceptionClass)) {
- return result;
- }
- }
- } catch (NoSuchMethodException e) {
- return result;
- }
- // 未在方法签名上定义的异常,在服务器端打印ERROR日志
- logger.error("Got unchecked and undeclared exception which called by " + RpcContext.getContext().getRemoteHost()
- + ". service: " + invoker.getInterface().getName() + ", method: " + invocation.getMethodName()
- + ", exception: " + exception.getClass().getName() + ": " + exception.getMessage(), exception);
- // 异常类和接口类在同一jar包里,直接抛出
- String serviceFile = ReflectUtils.getCodeBase(invoker.getInterface());
- String exceptionFile = ReflectUtils.getCodeBase(exception.getClass());
- if (serviceFile == null || exceptionFile == null || serviceFile.equals(exceptionFile)){
- return result;
- }
- // 是JDK自带的异常,直接抛出
- String className = exception.getClass().getName();
- if (className.startsWith("java.") || className.startsWith("javax.")) {
- return result;
- }
- // 是Dubbo本身的异常,直接抛出
- if (exception instanceof RpcException) {
- return result;
- }
- // 否则,包装成RuntimeException抛给客户端
- return new RpcResult(new RuntimeException(StringUtils.toString(exception)));
- } catch (Throwable e) {
- logger.warn("Fail to ExceptionFilter when called by " + RpcContext.getContext().getRemoteHost()
- + ". service: " + invoker.getInterface().getName() + ", method: " + invocation.getMethodName()
- + ", exception: " + e.getClass().getName() + ": " + e.getMessage(), e);
- return result;
- }
- }
- return result;
- } catch (RuntimeException e) {
- logger.error("Got unchecked and undeclared exception which called by " + RpcContext.getContext().getRemoteHost()
- + ". service: " + invoker.getInterface().getName() + ", method: " + invocation.getMethodName()
- + ", exception: " + e.getClass().getName() + ": " + e.getMessage(), e);
- throw e;
- }
- }
- }
代码分析
- if (result.hasException() && GenericService.class != invoker.getInterface()) {
- //...
- }
- return result;
- /**
- * 通用服务接口
- *
- * @author william.liangf
- * @export
- */
- public interface GenericService {
- /**
- * 泛化调用
- *
- * @param method 方法名,如:findPerson,如果有重载方法,需带上参数列表,如:findPerson(java.lang.String)
- * @param parameterTypes 参数类型
- * @param args 参数列表
- * @return 返回值
- * @throws Throwable 方法抛出的异常
- */
- Object $invoke(String method, String[] parameterTypes, Object[] args) throws GenericException;
- }
不适用于此场景,不在此处探讨。
逻辑1
- // 如果是checked异常,直接抛出
- if (! (exception instanceof RuntimeException) && (exception instanceof Exception)) {
- return result;
- }
provider端想抛出受检异常,必须在api上明确写明抛出受检异常;consumer端如果要处理受检异常,也必须使用明确写明抛出受检异常的api。
provider端api新增 自定义的 受检异常, 所有的 consumer端api都必须升级,同时修改代码,否则无法处理这个特定异常。
consumer端DecodeableRpcResult的decode方法会对异常进行处理
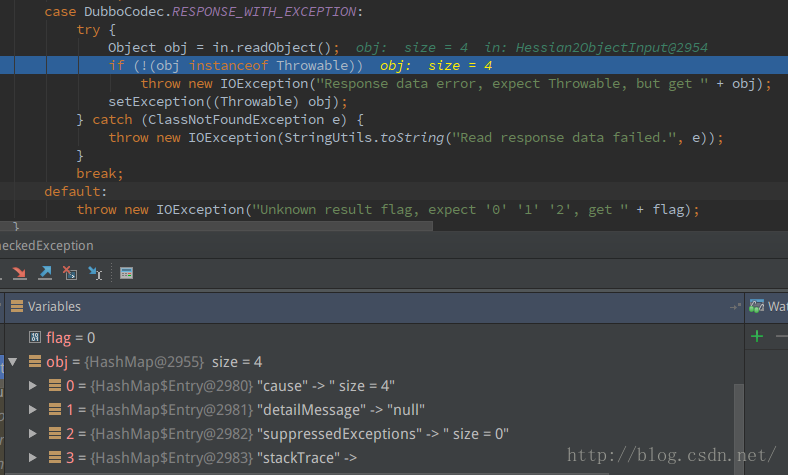
- try {
- decode(channel, inputStream);
- } catch (Throwable e) {
- if (log.isWarnEnabled()) {
- log.warn("Decode rpc result failed: " + e.getMessage(), e);
- }
- response.setStatus(Response.CLIENT_ERROR);
- response.setErrorMessage(StringUtils.toString(e));
- } finally {
- hasDecoded = true;
- }
DefaultFuture判断请求返回的结果,最后抛出RemotingException:
- private Object returnFromResponse() throws RemotingException {
- Response res = response;
- if (res == null) {
- throw new IllegalStateException("response cannot be null");
- }
- if (res.getStatus() == Response.OK) {
- return res.getResult();
- }
- if (res.getStatus() == Response.CLIENT_TIMEOUT || res.getStatus() == Response.SERVER_TIMEOUT) {
- throw new TimeoutException(res.getStatus() == Response.SERVER_TIMEOUT, channel, res.getErrorMessage());
- }
- throw new RemotingException(channel, res.getErrorMessage());
- }
DubboInvoker捕获RemotingException,抛出RpcException:
- try {
- boolean isAsync = RpcUtils.isAsync(getUrl(), invocation);
- boolean isOneway = RpcUtils.isOneway(getUrl(), invocation);
- int timeout = getUrl().getMethodParameter(methodName, Constants.TIMEOUT_KEY,Constants.DEFAULT_TIMEOUT);
- if (isOneway) {
- boolean isSent = getUrl().getMethodParameter(methodName, Constants.SENT_KEY, false);
- currentClient.send(inv, isSent);
- RpcContext.getContext().setFuture(null);
- return new RpcResult();
- } else if (isAsync) {
- ResponseFuture future = currentClient.request(inv, timeout) ;
- RpcContext.getContext().setFuture(new FutureAdapter<Object>(future));
- return new RpcResult();
- } else {
- RpcContext.getContext().setFuture(null);
- return (Result) currentClient.request(inv, timeout).get();
- }
- } catch (TimeoutException e) {
- throw new RpcException(RpcException.TIMEOUT_EXCEPTION, "Invoke remote method timeout. method: " + invocation.getMethodName() + ", provider: " + getUrl() + ", cause: " + e.getMessage(), e);
- } catch (RemotingException e) {
- throw new RpcException(RpcException.NETWORK_EXCEPTION, "Failed to invoke remote method: " + invocation.getMethodName() + ", provider: " + getUrl() + ", cause: " + e.getMessage(), e);
- }
调用栈:
FailOverClusterInvoker.doInvoke -...-> DubboInvoker.doInvoke -> ReferenceCountExchangeClient.request -> HeaderExchangeClient.request -> HeaderExchangeChannel.request -> AbstractPeer.send -> NettyChannel.send -> AbstractChannel.write -> Channels.write --back_to--> DubboInvoker.doInvoke -> DefaultFuture.get -> DefaultFuture.returnFromResponse -> throw new RemotingException
- com.alibaba.dubbo.rpc.RpcException: Failed to invoke the method triggerCheckedException in the service com.xxx.api.DemoService. Tried 1 times of the providers [192.168.1.101:20880] (1/1) from the registry 127.0.0.1:2181 on the consumer 192.168.1.101 using the dubbo version 3.1.9. Last error is: Failed to invoke remote method: triggerCheckedException, provider: dubbo://192.168.1.101:20880/com.xxx.api.DemoService?xxx, cause: java.io.IOException: Response data error, expect Throwable, but get {cause=(this Map), detailMessage=null, suppressedExceptions=[], stackTrace=[Ljava.lang.StackTraceElement;@23b84919}
- java.io.IOException: Response data error, expect Throwable, but get {cause=(this Map), detailMessage=null, suppressedExceptions=[], stackTrace=[Ljava.lang.StackTraceElement;@23b84919}
- at com.alibaba.dubbo.rpc.protocol.dubbo.DecodeableRpcResult.decode(DecodeableRpcResult.java:94)
逻辑2
- // 在方法签名上有声明,直接抛出
- try {
- Method method = invoker.getInterface().getMethod(invocation.getMethodName(), invocation.getParameterTypes());
- Class<?>[] exceptionClassses = method.getExceptionTypes();
- for (Class<?> exceptionClass : exceptionClassses) {
- if (exception.getClass().equals(exceptionClass)) {
- return result;
- }
- }
- } catch (NoSuchMethodException e) {
- return result;
- }
答案是和上面一样,抛出RpcException。
因此如果consumer端不care这种异常,则不需要任何处理;
consumer端有这种异常(路径要完全一致,包名+类名),则不需要任何处理;
没有这种异常,又想进行处理,则需要引入这个异常进行处理(方法有多种,比如升级api,或引入/升级异常所在的包)。
- // 异常类和接口类在同一jar包里,直接抛出
- String serviceFile = ReflectUtils.getCodeBase(invoker.getInterface());
- String exceptionFile = ReflectUtils.getCodeBase(exception.getClass());
- if (serviceFile == null || exceptionFile == null || serviceFile.equals(exceptionFile)){
- return result;
- }

逻辑4
- // 是JDK自带的异常,直接抛出
- String className = exception.getClass().getName();
- if (className.startsWith("java.") || className.startsWith("javax.")) {
- return result;
- }
逻辑5
- // 是Dubbo本身的异常,直接抛出
- if (exception instanceof RpcException) {
- return result;
- }
逻辑6
- // 否则,包装成RuntimeException抛给客户端
- return new RpcResult(new RuntimeException(StringUtils.toString(exception)));
核心思想
给dubbo接口添加白名单——dubbo Filter的使用具体内容如下:
在开发中,有时候需要限制访问的权限,白名单就是一种方法。对于Java Web应用,Spring的拦截器可以拦截Web接口的调用;而对于dubbo接口,Spring的拦截器就不管用了。
dubbo提供了Filter扩展,可以通过自定义Filter来实现这个功能。本文通过一个事例来演示如何实现dubbo接口的IP白名单。
- 扩展Filter
实现com.alibaba.dubbo.rpc.Filter接口:
注意:只能通过setter方式来注入其他的bean,且不要标注注解!- public class AuthorityFilter implements Filter {
- private static final Logger LOGGER = LoggerFactory.getLogger(AuthorityFilter.class);
- private IpWhiteList ipWhiteList;
- //dubbo通过setter方式自动注入
- public void setIpWhiteList(IpWhiteList ipWhiteList) {
- this.ipWhiteList = ipWhiteList;
- }
- @Override
- public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
- if (!ipWhiteList.isEnabled()) {
- LOGGER.debug("白名单禁用");
- return invoker.invoke(invocation);
- }
- String clientIp = RpcContext.getContext().getRemoteHost();
- LOGGER.debug("访问ip为{}", clientIp);
- List<String> allowedIps = ipWhiteList.getAllowedIps();
- if (allowedIps.contains(clientIp)) {
- return invoker.invoke(invocation);
- } else {
- return new RpcResult();
- }
- }
- }
dubbo自己会对这些bean进行注入,不需要再标注@Resource让Spring注入,参见扩展点加载 - 配置文件
参考:调用拦截扩展
在resources目录下添加纯文本文件META-INF/dubbo/com.alibaba.dubbo.rpc.Filter,内容如下:
修改dubbo的provider配置文件,在dubbo:provider中添加配置的filter,如下:- xxxFilter=com.xxx.AuthorityFilter
- <dubbo:provider filter="xxxFilter" />
这样就可以实现dubbo接口的IP白名单功能了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号