
jvm-垃圾收集器与内存分配策略
垃圾收集器与内存分配策略
参考:
https://my.oschina.net/hosee/blog/644085
http://www.cnblogs.com/zhguang/p/Java-JVM-GC.html
http://www.cnblogs.com/zhguang/p/3257367.html
1. GC的概念
Garbage Collection 垃圾收集
Java中,GC的对象是堆空间和永久区(如果对Java内存区域不太了解,请查看Java内存区域)
2. GC算法
2.1 引用计数法
老牌垃圾回收算法
通过引用计算来回收垃圾
使用者:
- COM
- ActionScript3
- Python
引用计数器的实现很简单,对于一个对象A,只要有任何一个对象引用了A,则A的引用计数器就加1,当引用失效时,引用计数器就减1。只要对象A的引用计数器的值为0,则对象A就不可能再被使用。
所以当一个对象的引用数量为0,就意味着没有人引用了这个对象,就可以将这个对象GC掉。

引用计数法的问题:
- 引用和去引用伴随加法和减法,影响性能
- 很难处理循环引用

从上图可以看出,右边的3个对象,最后的引用计数都是1,但是都不被根对象所引用,三个垃圾对象循环引用,导致都无法被回收。
这里要注意的是,引用计数法在Java中没有采用。
2.2 标记-清除
2.3 标记-整理
标记-整理算法适合用于存活对象较多的场合,如老年代。它在标记-清除算法的基础上做了一些优化。和标记-清除算法一样,标记-整理算法也首先需要从根节点开始,对所有可达对象做一次标记。但之后,它并不简单的清理未标记的对象,而是将所有的存活对象移动到内存的一端。之后,清理边界外所有的空间。
2.4 复制算法
- 与标记-清除算法相比,复制算法是一种相对高效的回收方法
- 不适用于存活对象较多的场合 如老年代
- 将原有的内存空间分为两块,每次只使用其中一块,在垃圾回收时,将正在使用的内存中的存活对象复制到未使用的内存块中,之后,清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收
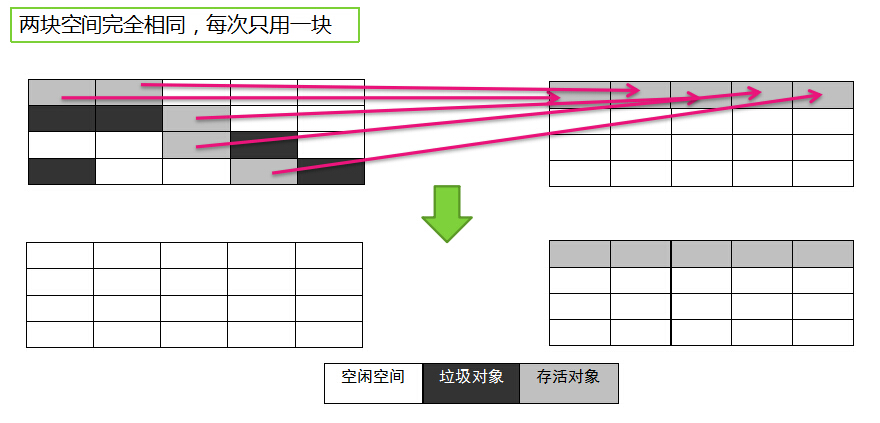
复制算法的问题:空间浪费,只能使用一半空间
通过整合标记清理思想来使得空间不怎么浪费
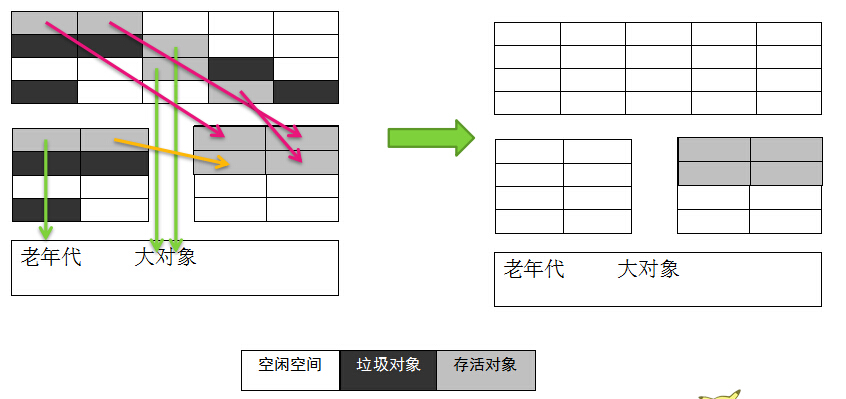
上图中老年代与复制算法关系不大,老年代一般是担保空间。
中间那块就是复制算法的核心区域,两块区域相同大小的空间。
具体步骤是:
1. 在最上面那块大的区域产生新对象。
2. 大对象不太适合在复制空间,因为复制空间的容量是有限的,所以需要一个大的空间做担保,所以让老年代做担保。这样产生的大对象直接进入老年代。
3. 每一次GC,对象的年龄就会+1,一个对象在几次GC后仍然没有被回收,则这个对象就是一个老年对象。老年对象是一个长期被引用的对象,老年对象将被放入老年代。
4. 步骤1中产生的小对象,将进入到复制空间。原先复制空间中的新对象也将被复制到另一块复制空间
5. 清空垃圾对象
-XX:+PrintGCDetails的输出

根据-XX:+PrintGCDetails的输出,我们可以看到
一个堆分为new generation(新生代) , tenured generation(老年代)和compacting perm gen。
而new generation分为eden space,from space(有些地方称为s0和s1,表示幸存代) , to space。
eden space就是上面那种图中,对象产生的地方。
from space和to space是两块大小一样的区域,是上图中的复制空间。
new generation的可用总空间就是eden space+一块复制空间(另一块不算),但是根据new generation的地址访问可以算出是eden space + 两块复制空间区域,所以复制算法浪费了一部分空间。
2.5 分代思想
依据对象的存活周期进行分类,短命对象归为新生代,长命对象归为老年代。
根据不同代的特点,选取合适的收集算法
- 少量对象存活,适合复制算法
- 大量对象存活,适合标记清除或者标记整理
进入老年代的对象有两种情况:
1. 新生代空间不够,老年代做担保存放一些大对象
2. 某些对象多次GC后仍然存在,进入老年代。
老年代的大多数对象都是第2种情况,所以老年代的对象的生命周期比较长,GC的发生也比较少,会有大量对象存活,所以不用复制算法,而改为标记清除或者标记整理。
所有的算法,需要能够识别一个垃圾对象,因此需要给出一个可触及性的定义
3. 可触及性
可触及的
- 从根节点可以触及到这个对象
可复活的
- 一旦所有引用被释放,就是可复活状态
- 因为在finalize()中可能复活该对象
不可触及的
- 在finalize()后,可能会进入不可触及状态
- 不可触及的对象不可能复活
- 可以回收
下面举个例子来说明可复活这个状态:
见:深入了解jvm书籍一般我们认为,对象赋值null后,对象就可以被GC了,在上述实例中,在finalize中,又将obj=this,使对象复活。因为finalize只能调用一次,所以第二次GC时,obj被回收。
因此对于finalize会有这样的建议:
- 经验:避免使用finalize(),操作不慎可能导致错误。
- finalize优先级低,何时被调用(在GC时被调用,何时发生GC不确定) 不确定
- 可以使用try-catch-finally来替代它
另外在之前,我们一直在提到从根出发,那么根是指哪些对象呢?
- 栈中引用的对象
- 方法区中静态成员或者常量引用的对象(全局对象)
- JNI方法栈中引用对象
4. Stop-The-World
Stop-The-World是Java中一种全局暂停的现象。
全局停顿,所有Java代码停止,native代码可以执行,但不能和JVM交互
多半由于GC引起,当然Dump线程、死锁检查、堆Dump都有可能引起Stop-The-World
GC时为什么会有全局停顿?
类比在聚会时打扫房间,聚会时很乱,又有新的垃圾产生,房间永远打扫不干净,只有让大家停止活动了,才能将房间打扫干净。
危害
长时间服务停止,没有响应
遇到HA系统,可能引起主备切换,严重危害生产环境。
新生代的GC(Minor GC),停顿时间比较短
老年代的GC(Full GC),停顿时间可能比较长
这篇Blog主要是讨论这些GC的算法在JVM中的不同应用。
1. 串行收集器
串行收集器是最古老,最稳定以及效率高的收集器
可能会产生较长的停顿,只使用一个线程去回收
-XX:+UseSerialGC
- 新生代、老年代使用串行回收
- 新生代复制算法
- 老年代标记-整理

串行收集器的日志输出:
0.844: [GC 0.844: [DefNew: 17472K->2176K(19648K), 0.0188339 secs] 17472K->2375K(63360K), 0.0189186 secs] [Times: user=0.01 sys=0.00, real=0.02 secs] 8.259: [Full GC 8.259: [Tenured: 43711K->40302K(43712K), 0.2960477 secs] 63350K->40302K(63360K), [Perm : 17836K->17836K(32768K)], 0.2961554 secs] [Times: user=0.28 sys=0.02, real=0.30 secs]
2. 并行收集器
2.1 ParNew
-XX:+UseParNewGC(new代表新生代,所以适用于新生代)
- 新生代并行
- 老年代串行
Serial收集器新生代的并行版本
在新生代回收时使用复制算法
多线程,需要多核支持
-XX:ParallelGCThreads 限制线程数量

并行收集器的日志输出:
0.834: [GC 0.834: [ParNew: 13184K->1600K(14784K), 0.0092203 secs] 13184K->1921K(63936K), 0.0093401 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2.2 Parallel收集器
新生代复制算法
老年代标记-整理
更加关注吞吐量
-XX:+UseParallelGC
- 使用Parallel收集器+ 老年代串行
- 使用Parallel收集器+ 老年代并行

Parallel收集器的日志输出:
1.500: [Full GC [PSYoungGen: 2682K->0K(19136K)] [ParOldGen: 28035K->30437K(43712K)] 30717K->30437K(62848K) [PSPermGen: 10943K->10928K(32768K)], 0.2902791 secs] [Times: user=1.44 sys=0.03, real=0.30 secs]
2.3 其他GC参数
-XX:MaxGCPauseMills
- 最大停顿时间,单位毫秒
- GC尽力保证回收时间不超过设定值
-XX:GCTimeRatio
- 0-100的取值范围
- 垃圾收集时间占总时间的比
- 默认99,即最大允许1%时间做GC
这两个参数是矛盾的。因为停顿时间和吞吐量不可能同时调优
3. CMS收集器
- Concurrent Mark Sweep 并发标记清除(应用程序线程和GC线程交替执行)
- 使用标记-清除算法
- 并发阶段会降低吞吐量(停顿时间减少,吞吐量降低)
- 老年代收集器(新生代使用ParNew)
- -XX:+UseConcMarkSweepGC
CMS运行过程比较复杂,着重实现了标记的过程,可分为
1. 初始标记(会产生全局停顿)
- 根可以直接关联到的对象
- 速度快
2. 并发标记(和用户线程一起)
- 主要标记过程,标记全部对象
3. 重新标记 (会产生全局停顿)
- 由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正
4. 并发清除(和用户线程一起)
- 基于标记结果,直接清理对象
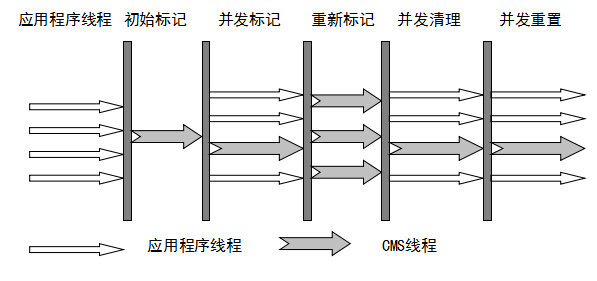
这里就能很明显的看出,为什么CMS要使用标记清除而不是标记压缩,如果使用标记压缩,需要多对象的内存位置进行改变,这样程序就很难继续执行。但是标记清除会产生大量内存碎片,不利于内存分配。
CMS收集器的日志输出:
1.662: [GC [1 CMS-initial-mark: 28122K(49152K)] 29959K(63936K), 0.0046877 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 1.666: [CMS-concurrent-mark-start] 1.699: [CMS-concurrent-mark: 0.033/0.033 secs] [Times: user=0.25 sys=0.00, real=0.03 secs] 1.699: [CMS-concurrent-preclean-start] 1.700: [CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 1.700: [GC[YG occupancy: 1837 K (14784 K)]1.700: [Rescan (parallel) , 0.0009330 secs]1.701: [weak refs processing, 0.0000180 secs] [1 CMS-remark: 28122K(49152K)] 29959K(63936K), 0.0010248 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 1.702: [CMS-concurrent-sweep-start] 1.739: [CMS-concurrent-sweep: 0.035/0.037 secs] [Times: user=0.11 sys=0.02, real=0.05 secs] 1.739: [CMS-concurrent-reset-start] 1.741: [CMS-concurrent-reset: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
CMS收集器特点:
尽可能降低停顿
会影响系统整体吞吐量和性能
- 比如,在用户线程运行过程中,分一半CPU去做GC,系统性能在GC阶段,反应速度就下降一半
清理不彻底
- 因为在清理阶段,用户线程还在运行,会产生新的垃圾,无法清理
因为和用户线程一起运行,不能在空间快满时再清理(因为也许在并发GC的期间,用户线程又申请了大量内存,导致内存不够)
- -XX:CMSInitiatingOccupancyFraction设置触发GC的阈值
- 如果不幸内存预留空间不够,就会引起concurrent mode failure
33.348: [Full GC 33.348: [CMS33.357: [CMS-concurrent-sweep: 0.035/0.036 secs] [Times: user=0.11 sys=0.03, real=0.03 secs] (concurrent mode failure): 47066K->39901K(49152K), 0.3896802 secs] 60771K->39901K(63936K), [CMS Perm : 22529K->22529K(32768K)], 0.3897989 secs] [Times: user=0.39 sys=0.00, real=0.39 secs]
一旦 concurrent mode failure产生,将使用串行收集器作为后备。
CMS也提供了整理碎片的参数:
-XX:+ UseCMSCompactAtFullCollection Full GC后,进行一次整理
- 整理过程是独占的,会引起停顿时间变长
-XX:+CMSFullGCsBeforeCompaction
- 设置进行几次Full GC后,进行一次碎片整理
-XX:ParallelCMSThreads
- 设定CMS的线程数量(一般情况约等于可用CPU数量)
CMS的提出是想改善GC的停顿时间,在GC过程中的确做到了减少GC时间,但是同样导致产生大量内存碎片,又需要消耗大量时间去整理碎片,从本质上并没有改善时间。
4. G1收集器
G1是目前技术发展的最前沿成果之一,HotSpot开发团队赋予它的使命是未来可以替换掉JDK1.5中发布的CMS收集器。
与CMS收集器相比G1收集器有以下特点:
1. 空间整合,G1收集器采用标记整理算法,不会产生内存空间碎片。分配大对象时不会因为无法找到连续空间而提前触发下一次GC。
2. 可预测停顿,这是G1的另一大优势,降低停顿时间是G1和CMS的共同关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为N毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
上面提到的垃圾收集器,收集的范围都是整个新生代或者老年代,而G1不再是这样。使用G1收集器时,Java堆的内存布局与其他收集器有很大差别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔阂了,它们都是一部分(可以不连续)Region的集合。
G1的新生代收集跟ParNew类似,当新生代占用达到一定比例的时候,开始出发收集。
和CMS类似,G1收集器收集老年代对象会有短暂停顿。
步骤:
- 标记阶段,首先初始标记(Initial-Mark),这个阶段是停顿的(Stop the World Event),并且会触发一次普通Mintor GC。对应GC log:GC pause (young) (inital-mark)
- Root Region Scanning,程序运行过程中会回收survivor区(存活到老年代),这一过程必须在young GC之前完成。
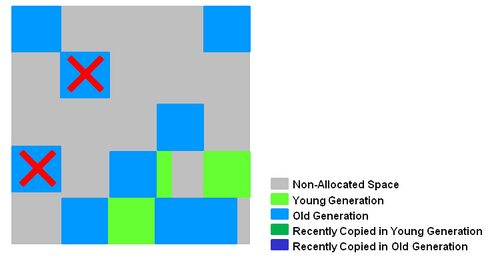
- Concurrent Marking,在整个堆中进行并发标记(和应用程序并发执行),此过程可能被young GC中断。在并发标记阶段,若发现区域对象中的所有对象都是垃圾,那个这个区域会被立即回收(图中打X)。同时,并发标记过程中,会计算每个区域的对象活性(区域中存活对象的比例)。
![]()
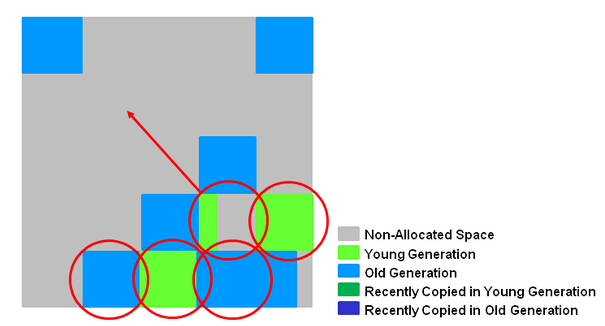
- Remark, 再标记,会有短暂停顿(STW)。再标记阶段是用来收集 并发标记阶段 产生新的垃圾(并发阶段和应用程序一同运行);G1中采用了比CMS更快的初始快照算法:snapshot-at-the-beginning (SATB)。
- Copy/Clean up,多线程清除失活对象,会有STW。G1将回收区域的存活对象拷贝到新区域,清除Remember Sets,并发清空回收区域并把它返回到空闲区域链表中。
![]()
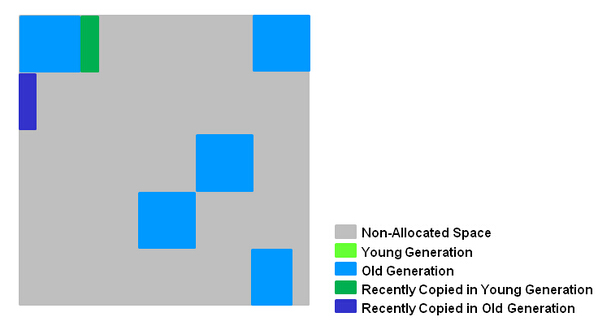
- 复制/清除过程后。回收区域的活性对象已经被集中回收到深蓝色和深绿色区域。
![]()
5. 安全点
GC的停顿主要来源于可达性分析上,程序执行时并非在所有地方都能停顿下来开始GC,只有在到达安全点时才能暂停。
安全点的选定基本上是以程序“是否具有让程序长时间执行的特征”为标准进行选定的——因为每条指令执行的时间都非常短暂,程序不太可能因为指令流长度太长这个原因而过长时间运行,“长时间执行”的最明显特征就是指令序列复用,例如方法调用、循环跳转、异常跳转等,所以具有这些功能的指令才会产生安全点。
接下来的问题就在于,如何让程序在需要GC时都跑到安全点上停顿下来,大多数JVM的实现都是采用主动式中断的思想。
主动式中断的思想是当GC需要中断线程的时候,不直接对线程操作,仅仅简单地设置一个标志,各个线程执行时主动去轮询这个标志,发现中断标志为真时就自己中断挂起,轮询标志的地方和安全点是重合的,另外再加上创建对象需要分配内存的地方。
其他:
只要记住流行的组合就这几种情况
Serial
ParNew + CMS
ParallelYoung + ParallelOld
G1GC
Reference:
1. 《深入理解Java虚拟机》
2. http://www.importnew.com/15311.html
3. http://www.zhihu.com/question/30538696
目录
- Java垃圾回收概况
- Java内存区域
- Java对象的访问方式
- Java内存分配机制
- Java GC机制
- 垃圾收集器
Java GC(Garbage Collection,垃圾收集,垃圾回收)机制,是Java与C++/C的主要区别之一,作为Java开发者,一般不需要专门编写内存回收和垃圾清理代码,对内存泄露和溢出的问题,也不需要像C程序员那样战战兢兢。这是因为在Java虚拟机中,存在自动内存管理和垃圾清扫机制。概括地说,该机制对JVM(Java Virtual Machine)中的内存进行标记,并确定哪些内存需要回收,根据一定的回收策略,自动的回收内存,永不停息(Nerver Stop)的保证JVM中的内存空间,防止出现内存泄露和溢出问题。
关于JVM,需要说明一下的是,目前使用最多的Sun公司的JDK中,自从1999年的JDK1.2开始直至现在仍在广泛使用的JDK6,其中默认的虚拟机都是HotSpot。2009年,Oracle收购Sun,加上之前收购的EBA公司,Oracle拥有3大虚拟机中的两个:JRockit和HotSpot,Oracle也表明了想要整合两大虚拟机的意图,但是目前在新发布的JDK7中,默认的虚拟机仍然是HotSpot,因此本文中默认介绍的虚拟机都是HotSpot,相关机制也主要是指HotSpot的GC机制。
Java GC机制主要完成3件事:确定哪些内存需要回收,确定什么时候需要执行GC,如何执行GC。经过这么长时间的发展(事实上,在Java语言出现之前,就有GC机制的存在,如Lisp语言),Java GC机制已经日臻完善,几乎可以自动的为我们做绝大多数的事情。然而,如果我们从事较大型的应用软件开发,曾经出现过内存优化的需求,就必定要研究Java GC机制。
学习Java GC机制,可以帮助我们在日常工作中排查各种内存溢出或泄露问题,解决性能瓶颈,达到更高的并发量,写出更高效的程序。
我们将从4个方面学习Java GC机制,1,内存是如何分配的;2,如何保证内存不被错误回收(即:哪些内存需要回收);3,在什么情况下执行GC以及执行GC的方式;4,如何监控和优化GC机制。
了解Java GC机制,必须先清楚在JVM中内存区域的划分。在Java运行时的数据区里,由JVM管理的内存区域分为下图几个模块:

其中:
1,程序计数器(Program Counter Register):程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行到了第几行,可以理解为是当前线程的行号指示器。字节码解释器在工作时,会通过改变这个计数器的值来取下一条语句指令。
每个程序计数器只用来记录一个线程的行号,所以它是线程私有(一个线程就有一个程序计数器)的。
如果程序执行的是一个Java方法,则计数器记录的是正在执行的虚拟机字节码指令地址;如果正在执行的是一个本地(native,由C语言编写完成)方法,则计数器的值为Undefined,由于程序计数器只是记录当前指令地址,所以不存在内存溢出的情况,因此,程序计数器也是所有JVM内存区域中唯一一个没有定义OutOfMemoryError的区域。
2,虚拟机栈(JVM Stack):一个线程的每个方法在执行的同时,都会创建一个栈帧(Statck Frame),栈帧中存储的有局部变量表、操作站、动态链接、方法出口等,当方法被调用时,栈帧在JVM栈中入栈,当方法执行完成时,栈帧出栈。
局部变量表中存储着方法的相关局部变量,包括各种基本数据类型,对象的引用,返回地址等。在局部变量表中,只有long和double类型会占用2个局部变量空间(Slot,对于32位机器,一个Slot就是32个bit),其它都是1个Slot。需要注意的是,局部变量表是在编译时就已经确定好的,方法运行所需要分配的空间在栈帧中是完全确定的,在方法的生命周期内都不会改变。
虚拟机栈中定义了两种异常,如果线程调用的栈深度大于虚拟机允许的最大深度,则抛出StatckOverFlowError(栈溢出);不过多数Java虚拟机都允许动态扩展虚拟机栈的大小(有少部分是固定长度的),所以线程可以一直申请栈,直到内存不足,此时,会抛出OutOfMemoryError(内存溢出)。
每个线程对应着一个虚拟机栈,因此虚拟机栈也是线程私有的。
3,本地方法栈(Native Method Statck):本地方法栈在作用,运行机制,异常类型等方面都与虚拟机栈相同,唯一的区别是:虚拟机栈是执行Java方法的,而本地方法栈是用来执行native方法的,在很多虚拟机中(如Sun的JDK默认的HotSpot虚拟机),会将本地方法栈与虚拟机栈放在一起使用。
本地方法栈也是线程私有的。
4,堆区(Heap):堆区是理解Java GC机制最重要的区域,没有之一。在JVM所管理的内存中,堆区是最大的一块,堆区也是Java GC机制所管理的主要内存区域,堆区由所有线程共享,在虚拟机启动时创建。堆区的存在是为了存储对象实例,原则上讲,所有的对象都在堆区上分配内存(不过现代技术里,也不是这么绝对的,也有栈上直接分配的)。
一般的,根据Java虚拟机规范规定,堆内存需要在逻辑上是连续的(在物理上不需要),在实现时,可以是固定大小的,也可以是可扩展的,目前主流的虚拟机都是可扩展的。如果在执行垃圾回收之后,仍没有足够的内存分配,也不能再扩展,将会抛出OutOfMemoryError:Java heap space异常。
关于堆区的内容还有很多,将在下节“Java内存分配机制”中详细介绍。
5,方法区(Method Area):在Java虚拟机规范中,将方法区作为堆的一个逻辑部分来对待,但事实上,方法区并不是堆(Non-Heap);另外,不少人的博客中,将Java GC的分代收集机制分为3个代:青年代,老年代,永久代,这些作者将方法区定义为“永久代”,这是因为,对于之前的HotSpot Java虚拟机的实现方式中,将分代收集的思想扩展到了方法区,并将方法区设计成了永久代。不过,除HotSpot之外的多数虚拟机,并不将方法区当做永久代,HotSpot本身,也计划取消永久代。本文中,由于笔者主要使用Oracle JDK6.0,因此仍将使用永久代一词。
方法区是各个线程共享的区域,用于存储已经被虚拟机加载的类信息(即加载类时需要加载的信息,包括版本、field、方法、接口等信息)、final常量、静态变量、编译器即时编译的代码等。
方法区在物理上也不需要是连续的,可以选择固定大小或可扩展大小,并且方法区比堆还多了一个限制:可以选择是否执行垃圾收集。一般的,方法区上执行的垃圾收集是很少的,这也是方法区被称为永久代的原因之一(HotSpot),但这也不代表着在方法区上完全没有垃圾收集,其上的垃圾收集主要是针对常量池的内存回收和对已加载类的卸载。
在方法区上进行垃圾收集,条件苛刻而且相当困难,效果也不令人满意,所以一般不做太多考虑,可以留作以后进一步深入研究时使用。
在方法区上定义了OutOfMemoryError:PermGen space异常,在内存不足时抛出。
运行时常量池(Runtime Constant Pool)是方法区的一部分,用于存储编译期就生成的字面常量、符号引用、翻译出来的直接引用(符号引用就是编码是用字符串表示某个变量、接口的位置,直接引用就是根据符号引用翻译出来的地址,将在类链接阶段完成翻译);运行时常量池除了存储编译期常量外,也可以存储在运行时间产生的常量(比如String类的intern()方法,作用是String维护了一个常量池,如果调用的字符“abc”已经在常量池中,则返回池中的字符串地址,否则,新建一个常量加入池中,并返回地址)。
6,直接内存(Direct Memory):直接内存并不是JVM管理的内存,可以这样理解,直接内存,就是JVM以外的机器内存,比如,你有4G的内存,JVM占用了1G,则其余的3G就是直接内存,JDK中有一种基于通道(Channel)和缓冲区(Buffer)的内存分配方式,将由C语言实现的native函数库分配在直接内存中,用存储在JVM堆中的DirectByteBuffer来引用。由于直接内存收到本机器内存的限制,所以也可能出现OutOfMemoryError的异常。
一般来说,一个Java的引用访问涉及到3个内存区域:JVM栈,堆,方法区。
以最简单的本地变量引用:Object obj = new Object()为例:
- Object obj表示一个本地引用,存储在JVM栈的本地变量表中,表示一个reference类型数据;
- new Object()作为实例对象数据存储在堆中;
- 堆中还记录了Object类的类型信息(接口、方法、field、对象类型等)的地址,这些地址所执行的数据存储在方法区中;
在Java虚拟机规范中,对于通过reference类型引用访问具体对象的方式并未做规定,目前主流的实现方式主要有两种:
1,通过句柄访问(图来自于《深入理解Java虚拟机:JVM高级特效与最佳实现》):
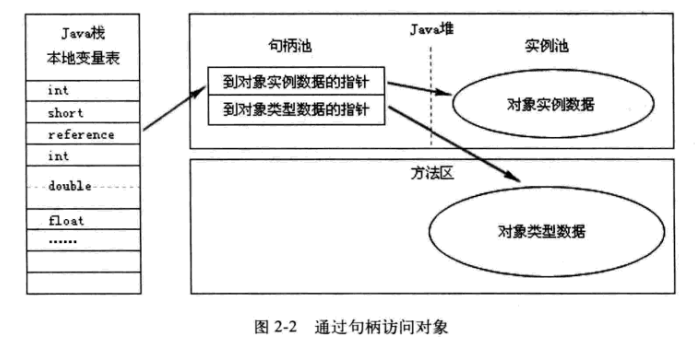
通过句柄访问的实现方式中,JVM堆中会专门有一块区域用来作为句柄池,存储相关句柄所执行的实例数据地址(包括在堆中地址和在方法区中的地址)。这种实现方法由于用句柄表示地址,因此十分稳定。
2,通过直接指针访问:(图来自于《深入理解Java虚拟机:JVM高级特效与最佳实现》)
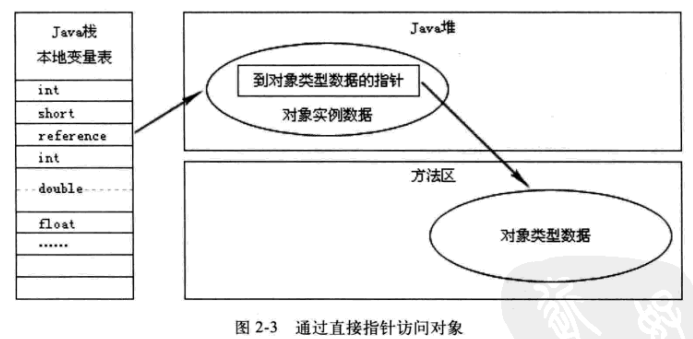
通过直接指针访问的方式中,reference中存储的就是对象在堆中的实际地址,在堆中存储的对象信息中包含了在方法区中的相应类型数据。这种方法最大的优势是速度快,在HotSpot虚拟机中用的就是这种方式。
这里所说的内存分配,主要指的是在堆上的分配,一般的,对象的内存分配都是在堆上进行,但现代技术也支持将对象拆成标量类型(标量类型即原子类型,表示单个值,可以是基本类型或String等),然后在栈上分配,在栈上分配的很少见,我们这里不考虑。
Java内存分配和回收的机制概括的说,就是:分代分配,分代回收。对象将根据存活的时间被分为:年轻代(Young Generation)、年老代(Old Generation)、永久代(Permanent Generation,也就是方法区)。如下图(来源于《成为JavaGC专家part I》,http://www.importnew.com/1993.html):
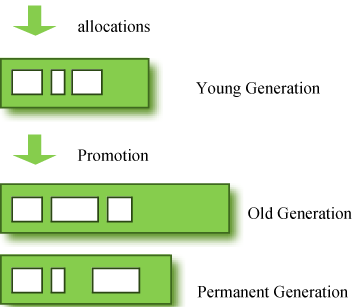
年轻代(Young Generation):对象被创建时,内存的分配首先发生在年轻代(大对象可以直接被创建在年老代),大部分的对象在创建后很快就不再使用,因此很快变得不可达,于是被年轻代的GC机制清理掉(IBM的研究表明,98%的对象都是很快消亡的),这个GC机制被称为Minor GC或叫Young GC。注意,Minor GC并不代表年轻代内存不足,它事实上只表示在Eden区上的GC。
年轻代上的内存分配是这样的,年轻代可以分为3个区域:Eden区(伊甸园,亚当和夏娃偷吃禁果生娃娃的地方,用来表示内存首次分配的区域,再贴切不过)和两个存活区(Survivor 0 、Survivor 1)。内存分配过程为(来源于《成为JavaGC专家part I》,http://www.importnew.com/1993.html):

-
绝大多数刚创建的对象会被分配在Eden区,其中的大多数对象很快就会消亡。Eden区是连续的内存空间,因此在其上分配内存极快;
-
最初一次,当Eden区满的时候,执行Minor GC,将消亡的对象清理掉,并将剩余的对象复制到一个存活区Survivor0(此时,Survivor1是空白的,两个Survivor总有一个是空白的);
-
下次Eden区满了,再执行一次Minor GC,将消亡的对象清理掉,将存活的对象复制到Survivor1中,然后清空Eden区;
-
将Survivor0中消亡的对象清理掉,将其中可以晋级的对象晋级到Old区,将存活的对象也复制到Survivor1区,然后清空Survivor0区;
- 当两个存活区切换了几次(HotSpot虚拟机默认15次,用-XX:MaxTenuringThreshold控制,大于该值进入老年代,但这只是个最大值,并不代表一定是这个值)之后,仍然存活的对象(其实只有一小部分,比如,我们自己定义的对象),将被复制到老年代。
从上面的过程可以看出,Eden区是连续的空间,且Survivor总有一个为空。经过一次GC和复制,一个Survivor中保存着当前还活着的对象,而Eden区和另一个Survivor区的内容都不再需要了,可以直接清空,到下一次GC时,两个Survivor的角色再互换。因此,这种方式分配内存和清理内存的效率都极高,这种垃圾回收的方式就是著名的“停止-复制(Stop-and-copy)”清理法(将Eden区和一个Survivor中仍然存活的对象拷贝到另一个Survivor中),这不代表着停止复制清理法很高效,其实,它也只在这种情况下高效,如果在老年代采用停止复制,则挺悲剧的。
在Eden区,HotSpot虚拟机使用了两种技术来加快内存分配。分别是bump-the-pointer和TLAB(Thread-Local Allocation Buffers),这两种技术的做法分别是:由于Eden区是连续的,因此bump-the-pointer技术的核心就是跟踪最后创建的一个对象,在对象创建时,只需要检查最后一个对象后面是否有足够的内存即可,从而大大加快内存分配速度;而对于TLAB技术是对于多线程而言的,将Eden区分为若干段,每个线程使用独立的一段,避免相互影响。TLAB结合bump-the-pointer技术,将保证每个线程都使用Eden区的一段,并快速的分配内存。
年老代(Old Generation):对象如果在年轻代存活了足够长的时间而没有被清理掉(即在几次Young GC后存活了下来),则会被复制到年老代,年老代的空间一般比年轻代大,能存放更多的对象,在年老代上发生的GC次数也比年轻代少。当年老代内存不足时,将执行Major GC,也叫 Full GC。
如果对象比较大(比如长字符串或大数组),Young空间不足,则大对象会直接分配到老年代上(大对象可能触发提前GC,应少用,更应避免使用短命的大对象)。用-XX:PretenureSizeThreshold来控制直接升入老年代的对象大小,大于这个值的对象会直接分配在老年代上。
可能存在年老代对象引用新生代对象的情况,如果需要执行Young GC,则可能需要查询整个老年代以确定是否可以清理回收,这显然是低效的。解决的方法是,年老代中维护一个512 byte的块——”card table“,所有老年代对象引用新生代对象的记录都记录在这里。Young GC时,只要查这里即可,不用再去查全部老年代,因此性能大大提高。
GC机制的基本算法是:分代收集,这个不用赘述。下面阐述每个分代的收集方法。
年轻代:
事实上,在上一节,已经介绍了新生代的主要垃圾回收方法,在新生代中,使用“停止-复制”算法进行清理,将新生代内存分为2部分,1部分 Eden区较大,1部分Survivor比较小,并被划分为两个等量的部分。每次进行清理时,将Eden区和一个Survivor中仍然存活的对象拷贝到 另一个Survivor中,然后清理掉Eden和刚才的Survivor。
这里也可以发现,停止复制算法中,用来复制的两部分并不总是相等的(传统的停止复制算法两部分内存相等,但新生代中使用1个大的Eden区和2个小的Survivor区来避免这个问题)
由于绝大部分的对象都是短命的,甚至存活不到Survivor中,所以,Eden区与Survivor的比例较大,HotSpot默认是 8:1,即分别占新生代的80%,10%,10%。如果一次回收中,Survivor+Eden中存活下来的内存超过了10%,则需要将一部分对象分配到 老年代。用-XX:SurvivorRatio参数来配置Eden区域Survivor区的容量比值,默认是8,代表Eden:Survivor1:Survivor2=8:1:1.
老年代:
方法区(永久代):
永久代的回收有两种:常量池中的常量,无用的类信息,常量的回收很简单,没有引用了就可以被回收。对于无用的类进行回收,必须保证3点:
- 类的所有实例都已经被回收
- 加载类的ClassLoader已经被回收
- 类对象的Class对象没有被引用(即没有通过反射引用该类的地方)
在GC机制中,起重要作用的是垃圾收集器,垃圾收集器是GC的具体实现,Java虚拟机规范中对于垃圾收集器没有任何规定,所以不同厂商实现的垃圾 收集器各不相同,HotSpot 1.6版使用的垃圾收集器如下图(图来源于《深入理解Java虚拟机:JVM高级特效与最佳实现》,图中两个收集器之间有连线,说明它们可以配合使用):
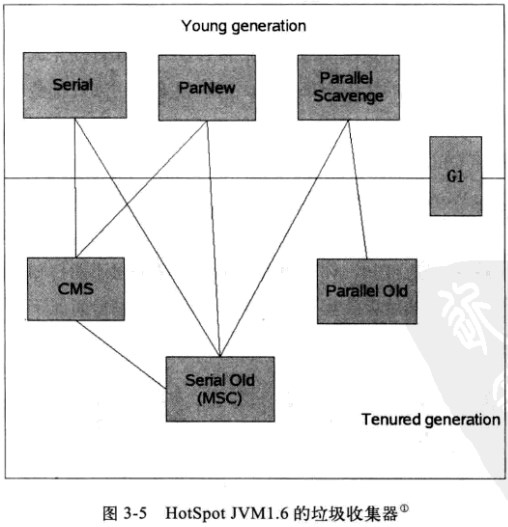
在介绍垃圾收集器之前,需要明确一点,就是在新生代采用的停止复制算法中,“停 止(Stop-the-world)”的意义是在回收内存时,需要暂停其他所 有线程的执行。这个是很低效的,现在的各种新生代收集器越来越优化这一点,但仍然只是将停止的时间变短,并未彻底取消停止。
- Serial收集器:新生代收集器,使用停止复制算法,使用一个线程进行GC,串行,其它工作线程暂停。使用-XX:+UseSerialGC可以使用Serial+Serial Old模式运行进行内存回收(这也是虚拟机在Client模式下运行的默认值)
- ParNew收集器:新生代收集器,使用停止复制算法,Serial收集器的多线程版,用多个线程进行GC,并行,其它工作线程暂停,关注缩短垃圾收集时间。使用-XX:+UseParNewGC开关来控制使用ParNew+Serial Old收集器组合收集内存;使用-XX:ParallelGCThreads来设置执行内存回收的线程数。
- Parallel Scavenge 收集器:新生代收集器,使用停止复制算法,关注CPU吞吐量,即运行用户代码的时间/总时间,比如:JVM运行100分钟,其中运行用户代码99分钟,垃 圾收集1分钟,则吞吐量是99%,这种收集器能最高效率的利用CPU,适合运行后台运算(关注缩短垃圾收集时间的收集器,如CMS,等待时间很少,所以适 合用户交互,提高用户体验)。使用-XX:+UseParallelGC开关控制使用Parallel Scavenge+Serial Old收集器组合回收垃圾(这也是在Server模式下的默认值);使用-XX:GCTimeRatio来设置用户执行时间占总时间的比例,默认99,即1%的时间用来进行垃圾回收。使用-XX:MaxGCPauseMillis设置GC的最大停顿时间(这个参数只对Parallel Scavenge有效),用开关参数-XX:+UseAdaptiveSizePolicy可以进行动态控制,如自动调整Eden/Survivor比例,老年代对象年龄,新生代大小等,这个参数在ParNew下没有。
- Serial Old收集器:老年代收集器,单线程收集器,串行,使用标记整理(整理的方法是Sweep(清理)和Compact(压缩),清理是将废弃的对象干掉,只留幸存的对象,压缩是将移动对象,将空间填满保证内存分为2块,一块全是对象,一块空闲)算法,使用单线程进行GC,其它工作线程暂停(注意,在老年代中进行标记整理算法清理,也需要暂停其它线程),在JDK1.5之前,Serial Old收集器与ParallelScavenge搭配使用。
- Parallel Old收集器:老年代收集器,多线程,并行,多线程机制与Parallel Scavenge差不错,使用标记整理(与Serial Old不同,这里的整理是Summary(汇总)和Compact(压缩),汇总的意思就是将幸存的对象复制到预先准备好的区域,而不是像Sweep(清理)那样清理废弃的对象)算法,在Parallel Old执行时,仍然需要暂停其它线程。Parallel Old在多核计算中很有用。Parallel Old出现后(JDK 1.6),与Parallel Scavenge配合有很好的效果,充分体现Parallel Scavenge收集器吞吐量优先的效果。使用-XX:+UseParallelOldGC开关控制使用Parallel Scavenge +Parallel Old组合收集器进行收集。
- CMS(Concurrent Mark Sweep)收集器:老年代收集器,致力于获取最短回收停顿时间(即缩短垃圾回收的时间),使用标记清除算法,多线程,优点是并发收集(用户线程可以和GC线程同时工作),停顿小。使用-XX:+UseConcMarkSweepGC进行ParNew+CMS+Serial Old进行内存回收,优先使用ParNew+CMS(原因见后面),当用户线程内存不足时,采用备用方案Serial Old收集。
CMS收集的执行过程是:初始标记(CMS-initial-mark) -> 并发标记(CMS-concurrent-mark) -->预清理(CMS-concurrent-preclean)-->可控预清理(CMS-concurrent-abortable-preclean)-> 重新标记(CMS-remark) -> 并发清除(CMS-concurrent-sweep) ->并发重设状态等待下次CMS的触发(CMS-concurrent-reset)具体的说,先2次标记,1次预清理,1次重新标记,再1次清除。1,首先jvm根据-XX:CMSInitiatingOccupancyFraction,-XX:+UseCMSInitiatingOccupancyOnly来决定什么时间开始垃圾收集;2,如果设置了-XX:+UseCMSInitiatingOccupancyOnly,那么只有当old代占用确实达到了-XX:CMSInitiatingOccupancyFraction参数所设定的比例时才会触发cms gc;3,如果没有设置-XX:+UseCMSInitiatingOccupancyOnly,那么系统会根据统计数据自行决定什么时候触发cms gc;因此有时会遇到设置了80%比例才cms gc,但是50%时就已经触发了,就是因为这个参数没有设置的原因;4,当cms gc开始时,首先的阶段是初始标记(CMS-initial-mark),是stop the world阶段,因此此阶段标记的对象只是从root集最直接可达的对象;CMS-initial-mark:961330K(1572864K),指标记时,old代的已用空间和总空间5,下一个阶段是并发标记(CMS-concurrent-mark),此阶段是和应用线程并发执行的,所谓并发收集器指的就是这个,主要作用是标记可达的对象,此阶段不需要用户停顿。此阶段会打印2条日志:CMS-concurrent-mark-start,CMS-concurrent-mark6,下一个阶段是CMS-concurrent-preclean,此阶段主要是进行一些预清理,因为标记和应用线程是并发执行的,因此会有些对象的状态在标记后会改变,此阶段正是解决这个问题因为之后的Rescan阶段也会stop the world,为了使暂停的时间尽可能的小,也需要preclean阶段先做一部分工作以节省时间此阶段会打印2条日志:CMS-concurrent-preclean-start,CMS-concurrent-preclean7,下一阶段是CMS-concurrent-abortable-preclean阶段,加入此阶段的目的是使cms gc更加可控一些,作用也是执行一些预清理,以减少Rescan阶段造成应用暂停的时间此阶段涉及几个参数:-XX:CMSMaxAbortablePrecleanTime:当abortable-preclean阶段执行达到这个时间时才会结束-XX:CMSScheduleRemarkEdenSizeThreshold(默认2m):控制abortable-preclean阶段什么时候开始执行,即当eden使用达到此值时,才会开始abortable-preclean阶段-XX:CMSScheduleRemarkEdenPenetratio(默认50%):控制abortable-preclean阶段什么时候结束执行此阶段会打印一些日志如下:CMS-concurrent-abortable-preclean-start,CMS-concurrent-abortable-preclean,CMS:abort preclean due to time XXX8,再下一个阶段是第二个stop the world阶段了,即Rescan阶段,此阶段暂停应用线程,停顿时间比并发标记小得多,但比初始标记稍长。对对象进行重新扫描并标记;YG occupancy:964861K(2403008K),指执行时young代的情况CMS remark:961330K(1572864K),指执行时old代的情况此外,还打印出了弱引用处理、类卸载等过程的耗时9,再下一个阶段是CMS-concurrent-sweep,进行并发的垃圾清理10,最后是CMS-concurrent-reset,为下一次cms gc重置相关数据结构有2种情况会触发CMS 的悲观full gc,在悲观full gc时,整个应用会暂停A,concurrent-mode-failure:预清理阶段可能出现,当cms gc正进行时,此时有新的对象要进行old代,但是old代空间不足造成的。其可能性有:1,O区空间不足以让新生代晋级,2,O区空间用完之前,无法完成对无引用的对象的清理。这表明,当前有大量数据进入内存且无法释放。B,promotion-failed:新生代young gc可能出现,当进行young gc时,有部分young代对象仍然可用,但是S1或S2放不下,因此需要放到old代,但此时old代空间无法容纳此。影响cms gc时长及触发的参数是以下2个:-XX:CMSMaxAbortablePrecleanTime=5000-XX:CMSInitiatingOccupancyFraction=80解决也是针对这两个参数来的,根本的原因是每次请求消耗的内存量过大解决方式:A,针对cms gc的触发阶段,调整-XX:CMSInitiatingOccupancyFraction=50,提早触发cms gc,就可以缓解当old代达到80%,cms gc处理不完,从而造成concurrent mode failure引发full gcB,修改-XX:CMSMaxAbortablePrecleanTime=500,缩小CMS-concurrent-abortable-preclean阶段的时间C,考虑到cms gc时不会进行compact,因此加入-XX:+UseCMSCompactAtFullCollection(cms gc后会进行内存的compact)和-XX:CMSFullGCsBeforeCompaction=4(在full gc4次后会进行compact)参数在CMS清理过程中,只有初始标记和重新标记需要短暂停顿,并发标记和并发清除都不需要暂停用户线程,因此效率很高,很适合高交互的场合。CMS也有缺点,它需要消耗额外的CPU和内存资源,在CPU和内存资源紧张,CPU较少时,会加重系统负担(CMS默认启动线程数为(CPU数量+3)/4)。另外,在并发收集过程中,用户线程仍然在运行,仍然产生内存垃圾,所以可能产生“浮动垃圾”,本次无法清理,只能下一次Full GC才清理,因此在GC期间,需要预留足够的内存给用户线程使用。所以使用CMS的收集器并不是老年代满了才触发Full GC,而是在使用了一大半(默认68%,即2/3,使用-XX:CMSInitiatingOccupancyFraction来设置)的时候就要进行Full GC,如果用户线程消耗内存不是特别大,可以适当调高-XX:CMSInitiatingOccupancyFraction以降低GC次数,提高性能,如果预留的用户线程内存不够,则会触发Concurrent Mode Failure,此时,将触发备用方案:使用Serial Old 收集器进行收集,但这样停顿时间就长了,因此-XX:CMSInitiatingOccupancyFraction不宜设的过大。还有,CMS采用的是标记清除算法,会导致内存碎片的产生,可以使用-XX:+UseCMSCompactAtFullCollection来设置是否在Full GC之后进行碎片整理,用-XX:CMSFullGCsBeforeCompaction来设置在执行多少次不压缩的Full GC之后,来一次带压缩的Full GC。
- G1收集器:在JDK1.7中正式发布,与现状的新生代、老年代概念有很大不同,目前使用较少,不做介绍。
目录
参数设置
收集器搭配
启动内存分配
监控工具和方法
调优方法
调优实例
光说不练假把式,学习Java GC机制的目的是为了实用,也就是为了在JVM出现问题时分析原因并解决之。通过学习,我觉得JVM监控与调优主要的着眼点在于如何配置、如何监控、如何优化3点上。下面就将针对这3点进行学习。
(如果您对Java的内存区域划分和内存回收机制尚不明确,那在阅读本文前,请先阅读我的前一篇博客《Java系列笔记(3) - Java 内存区域和GC机制》,在该博客中,详细叙述了Java HotSpot虚拟机(Sun/Oracle JDK系列默认的虚拟机)的内存分配和垃圾回收机制。本文很多内容将依据上一篇博客,同时,本文所针对的虚拟机,也是HotSpot虚拟机。)
参数设置
在Java虚拟机的参数中,有3种表示方法(出自:http://www.cnblogs.com/wenfeng762/archive/2011/08/14/2137810.html),用“ps -ef |grep "java"命令,可以得到当前Java进程的所有启动参数和配置参数:
- 标准参数(-),所有的JVM实现都必须实现这些参数的功能,而且向后兼容;
- 非标准参数(-X),默认jvm实现这些参数的功能,但是并不保证所有jvm实现都满足,且不保证向后兼容;
- 非Stable参数(-XX),此类参数各个jvm实现会有所不同,将来可能会随时取消,需要慎重使用(但是,这些参数往往是非常有用的);
(额外的,-DpropertyName=“value”的形式定义了一些全局属性值,下面有介绍。)
本文只重点介绍一些重要和常用的参数,如果想了解全部参数,可以参考下面的文章:
其实标准参数是用过Java的人都最熟悉的,就是你在运行java命令时后面加上的参数,如java -version, java -jar 等,输入命令java -help或java -?就能获得当前机器所有java的标准参数列表。
-client
设置jvm使用client模式,这是一般在pc机器上使用的模式,启动很快,但性能和内存管理效率并不高;多用于桌面应用;
-server
使用server模式,启动速度虽然慢(比client模式慢10%左右),但是性能和内存管理效率很高,适用于服务器,用于生成环境、开发环境或测试环境的服务端;
如果没有指定-server或-client,JVM启动的时候会自动检测当前主机是否为服务器,如果是就以server模式启动,64位的JVM只有server模式,所以无法使用-client参数;
默认情况下,不同的启动模式,执行GC的方式有所区别:
| 启动模式 | 新生代GC方式 | 旧生代和持久代GC的方式 |
| client | 串行 | 串行 |
| server | 并行 | 并发 |
如果没有指定-server或-client模式,则判断方法如下:
-classpath / -cp
JVM加载和搜索文件的目录路径,多个路径用;分隔。注意,如果使用了-classpath,JVM就不会再搜索环境变量中定义的CLASSPATH路径。
JVM搜索路径的顺序为:
1,先搜索JVM自带的jar或zip包(Bootstrat,搜索路径可以用System.getProperty("sun.boot.class.path")获得);
2,搜索JRE_HOME/lib/ext下的jar包(Extension,搜索路径可以用System.getProperty("java.ext.dirs")获得);
3,搜索用户自定义目录,顺序为:当前目录(.),CLASSPATH,-cp;(搜索路径用System.getProperty("java.class.path")获得)
-DpropertyName=value
定义系统的全局属性值,如配置文件地址等,如果value有空格,可以用-Dname="space string"这样的形式来定义,用System.getProperty("propertyName")可以获得这些定义的属性值,在代码中也可以用System.setProperty("propertyName","value")的形式来定义属性。
-verbose
这是查询GC问题最常用的命令之一,具体参数如:
-verbose:class
输出jvm载入类的相关信息,当jvm报告说找不到类或者类冲突时可此进行诊断。
-verbose:gc
输出每次GC的相关情况,后面会有更详细的介绍。
-verbose:jni
输出native方法调用的相关情况,一般用于诊断jni调用错误信息。
非标准参数
非标准参数,是在标准参数的基础上进行扩展的参数,输入“java -X”命令,能够获得当前JVM支持的所有非标准参数列表(你会发现,其实并不多哦)。
在不同类型的JVM中,采用的参数有所不同,
在讲解非标准参数时,请参考下面的图,对内存区域的大小有个形象的了解(下图出自:http://iamzhongyong.iteye.com/blog/1333100):

-Xmn
新生代内存大小的最大值,包括E区和两个S区的总和,使用方法如:-Xmn65535,-Xmn1024k,-Xmn512m,-Xmn1g (-Xms,-Xmx也是种写法)
-Xmn只能使用在JDK1.4或之后的版本中,(之前的1.3/1.4版本中,可使用-XX:NewSize设置年轻代大小,用-XX:MaxNewSize设置年轻代最大值);
如果同时设置了-Xmn和-XX:NewSize,-XX:MaxNewSize,则谁设置在后面,谁就生效;如果同时设置了-XX:NewSize -XX:MaxNewSize与-XX:NewRatio则实际生效的值是:min(MaxNewSize,max(NewSize, heap/(NewRatio+1)))(看考:http://www.open-open.com/home/space.php?uid=71669&do=blog&id=8891)
在开发、测试环境,可以-XX:NewSize 和 -XX:MaxNewSize来设置新生代大小,但在线上生产环境,使用-Xmn一个即可(推荐),或者将-XX:NewSize 和 -XX:MaxNewSize设置为同一个值,这样能够防止在每次GC之后都要调整堆的大小(即:抖动,抖动会严重影响性能)
-Xms
初始堆的大小,也是堆大小的最小值,默认值是总共的物理内存/64(且小于1G),默认情况下,当堆中可用内存小于40%(这个值可以用-XX: MinHeapFreeRatio 调整,如-X:MinHeapFreeRatio=30)时,堆内存会开始增加,一直增加到-Xmx的大小;
-Xmx
堆的最大值,默认值是总共的物理内存/64(且小于1G),如果Xms和Xmx都不设置,则两者大小会相同,默认情况下,当堆中可用内存大于70%(这个值可以用-XX: MaxHeapFreeRatio 调整,如-X:MaxHeapFreeRatio=60)时,堆内存会开始减少,一直减小到-Xms的大小;
整个堆的大小=年轻代大小+年老代大小,堆的大小不包含持久代大小,如果增大了年轻代,年老代相应就会减小,官方默认的配置为年老代大小/年轻代大小=2/1左右(使用-XX:NewRatio可以设置-XX:NewRatio=5,表示年老代/年轻代=5/1);
建议在开发测试环境可以用Xms和Xmx分别设置最小值最大值,但是在线上生产环境,Xms和Xmx设置的值必须一样,原因与年轻代一样——防止抖动;
-Xss
这个参数用于设置每个线程的栈内存,默认1M,一般来说是不需要改的。除非代码不多,可以设置的小点,另外一个相似的参数是-XX:ThreadStackSize,这两个参数在1.6以前,都是谁设置在后面,谁就生效;1.6版本以后,-Xss设置在后面,则以-Xss为准,-XXThreadStackSize设置在后面,则主线程以-Xss为准,其它线程以-XX:ThreadStackSize为准。
-Xrs
减少JVM对操作系统信号(OS Signals)的使用(JDK1.3.1之后才有效),当此参数被设置之后,jvm将不接收控制台的控制handler,以防止与在后台以服务形式运行的JVM冲突(这个用的比较少,参考:http://www.blogjava.net/midstr/archive/2008/09/21/230265.html)。
-Xprof
跟踪正运行的程序,并将跟踪数据在标准输出输出;适合于开发环境调试。
-Xnoclassgc
关闭针对class的gc功能;因为其阻止内存回收,所以可能会导致OutOfMemoryError错误,慎用;
-Xincgc
开启增量gc(默认为关闭);这有助于减少长时间GC时应用程序出现的停顿;但由于可能和应用程序并发执行,所以会降低CPU对应用的处理能力。
-Xloggc:file
与-verbose:gc功能类似,只是将每次GC事件的相关情况记录到一个文件中,文件的位置最好在本地,以避免网络的潜在问题。
若与verbose命令同时出现在命令行中,则以-Xloggc为准。
非Stable参数(非静态参数)
以-XX表示的非Stable参数,虽然在官方文档中是不确定的,不健壮的,各个公司的实现也各有不同,但往往非常实用,所以这部分参数对于GC非常重要。JVM(Hotspot)中主要的参数可以大致分为3类(参考http://blog.csdn.net/sfdev/article/details/2063928):
- 性能参数( Performance Options):用于JVM的性能调优和内存分配控制,如初始化内存大小的设置;
- 行为参数(Behavioral Options):用于改变JVM的基础行为,如GC的方式和算法的选择;
- 调试参数(Debugging Options):用于监控、打印、输出等jvm参数,用于显示jvm更加详细的信息;
比较详细的非Stable参数总结,请参考Java 6 JVM参数选项大全(中文版),
对于非Stable参数,使用方法有4种:
- -XX:+<option> 启用选项
- -XX:-<option> 不启用选项
- -XX:<option>=<number> 给选项设置一个数字类型值,可跟单位,例如 32k, 1024m, 2g
- -XX:<option>=<string> 给选项设置一个字符串值,例如-XX:HeapDumpPath=./dump.core
首先介绍性能参数,性能参数往往用来定义内存分配的大小和比例,相比于行为参数和调试参数,一个比较明显的区别是性能参数后面往往跟的有数值,常用如下:
| 参数及其默认值 | 描述 |
|
-XX:NewSize=2.125m
|
新生代对象生成时占用内存的默认值
|
| -XX:MaxNewSize=size | 新生成对象能占用内存的最大值 |
| -XX:MaxPermSize=64m | 方法区所能占用的最大内存(非堆内存) |
| -XX:PermSize=64m | 方法区分配的初始内存 |
|
-XX:MaxTenuringThreshold=15
|
对象在新生代存活区切换的次数(坚持过MinorGC的次数,每坚持过一次,该值就增加1),大于该值会进入老年代 |
|
-XX:MaxHeapFreeRatio=70
|
GC后java堆中空闲量占的最大比例,大于该值,则堆内存会减少
|
| -XX:MinHeapFreeRatio=40 | GC后java堆中空闲量占的最小比例,小于该值,则堆内存会增加 |
| -XX:NewRatio=2 | 新生代内存容量与老生代内存容量的比例 |
| -XX:ReservedCodeCacheSize= 32m | 保留代码占用的内存容量 |
| -XX:ThreadStackSize=512 | 设置线程栈大小,若为0则使用系统默认值 |
| -XX:LargePageSizeInBytes=4m |
设置用于Java堆的大页面尺寸
|
| -XX:PretenureSizeThreshold= size | 大于该值的对象直接晋升入老年代(这种对象少用为好) |
| -XX:SurvivorRatio=8 | Eden区域Survivor区的容量比值,如默认值为8,代表Eden:Survivor1:Survivor2=8:1:1 |
常用的行为参数,主要用来选择使用什么样的垃圾收集器组合,以及控制运行过程中的GC策略等:
| 参数及其默认值 | 描述 |
|
-XX:-UseSerialGC
|
启用串行GC,即采用Serial+Serial Old模式
|
|
-XX:-UseParallelGC
|
启用并行GC,即采用Parallel Scavenge+Serial Old收集器组合(-Server模式下的默认组合)
|
| -XX:GCTimeRatio=99 | 设置用户执行时间占总时间的比例(默认值99,即1%的时间用于GC) |
| -XX:MaxGCPauseMillis=time | 设置GC的最大停顿时间(这个参数只对Parallel Scavenge有效) |
| -XX:+UseParNewGC | 使用ParNew+Serial Old收集器组合 |
| -XX:ParallelGCThreads | 设置执行内存回收的线程数,在+UseParNewGC的情况下使用 |
|
-XX:+UseParallelOldGC
|
使用Parallel Scavenge +Parallel Old组合收集器 |
| -XX:+UseConcMarkSweepGC | 使用ParNew+CMS+Serial Old组合并发收集,优先使用ParNew+CMS,当用户线程内存不足时,采用备用方案Serial Old收集。 |
| -XX:-DisableExplicitGC | 禁止调用System.gc();但jvm的gc仍然有效 |
| -XX:+ScavengeBeforeFullGC | 新生代GC优先于Full GC执行 |
常用的调试参数,主要用于监控和打印GC的信息:
| 参数及其默认值 | 描述 |
| -XX:-CITime | 打印消耗在JIT编译的时间 |
| -XX:ErrorFile=./hs_err_pid<pid>.log | 保存错误日志或者数据到文件中 |
| -XX:-ExtendedDTraceProbes | 开启solaris特有的dtrace探针 |
| -XX:HeapDumpPath=./java_pid<pid>.hprof | 指定导出堆信息时的路径或文件名 |
| -XX:-HeapDumpOnOutOfMemoryError | 当首次遭遇OOM时导出此时堆中相关信息 |
| -XX:OnError="<cmd args>;<cmd args>" | 出现致命ERROR之后运行自定义命令 |
| -XX:OnOutOfMemoryError="<cmd args>;<cmd args>" | 当首次遭遇OOM时执行自定义命令 |
| -XX:-PrintClassHistogram | 遇到Ctrl-Break后打印类实例的柱状信息,与jmap -histo功能相同 |
| -XX:-PrintConcurrentLocks | 遇到Ctrl-Break后打印并发锁的相关信息,与jstack -l功能相同 |
| -XX:-PrintCommandLineFlags | 打印在命令行中出现过的标记 |
| -XX:-PrintCompilation | 当一个方法被编译时打印相关信息 |
| -XX:-PrintGC | 每次GC时打印相关信息 |
| -XX:-PrintGC Details | 每次GC时打印详细信息 |
| -XX:-PrintGCTimeStamps | 打印每次GC的时间戳 |
| -XX:-TraceClassLoading | 跟踪类的加载信息 |
| -XX:-TraceClassLoadingPreorder | 跟踪被引用到的所有类的加载信息 |
| -XX:-TraceClassResolution | 跟踪常量池 |
| -XX:-TraceClassUnloading | 跟踪类的卸载信息 |
| -XX:-TraceLoaderConstraints | 跟踪类加载器约束的相关信息 |
再次声明,上面的三种参数,主要参考了博客:http://blog.csdn.net/sfdev/article/details/2063928和http://kenwublog.com/docs/java6-jvm-options-chinese-edition.htm,后一个比较全面,有兴趣的可以仔细研读。
这些参数将为我们进行GC的监控与调优提供很大助力,是我们进行GC相关操作的重要工具。
收集器搭配
在介绍了常用的配置参数之后,我们将开始真正的JVM实操征程,首先,我们要为应用程序选择一个合适的垃圾收集器组合,本节请参考《Java系列笔记(3) - Java 内存区域和GC机制》一文中的“垃圾收集器”一节,及上节中的行为参数。
这里需要再次引用这幅图(图来源于《深入理解Java虚拟机:JVM高级特效与最佳实现》,图中两个收集器之间有连线,说明它们可以配合使用):

Serial收集器: Serial收集器是在client模式下默认的新生代收集器,其收集效率大约是100M左右的内存需要几十到100多毫秒;在client模式下,收集桌面应用的内存垃圾,基本上不影响用户体验。所以,一般的Java桌面应用中,直接使用Serial收集器(不需要配置参数,用默认即可)。
ParNew收集器:Serial收集器的多线程版本,这种收集器默认开通的线程数与CPU数量相同,-XX:ParallelGCThreads可以用来设置开通的线程数。
可以与CMS收集器配合使用,事实上用-XX:+UseConcMarkSweepGC选择使用CMS收集器时,默认使用的就是ParNew收集器,所以不需要额外设置-XX:+UseParNewGC,设置了也不会冲突,因为会将ParNew+Serial Old作为一个备选方案;
如果单独使用-XX:+UseParNewGC参数,则选择的是ParNew+Serial Old收集器组合收集器。
一般情况下,在server模式下,如果选择CMS收集器,则优先选择ParNew收集器。
Parallel Scavenge收集器:关注的是吞吐量(关于吞吐量的含义见上一篇博客),可以这么理解,关注吞吐量,意味着强调任务更快的完成,而如CMS等关注停顿时间短的收集器,强调的是用户交互体验。
在需要关注吞吐量的场合,比如数据运算服务器等,就可以使用Parallel Scavenge收集器。
老年代收集器如下:
Serial Old收集器:在1.5版本及以前可以与 Parallel Scavenge结合使用(事实上,也是当时Parallel Scavenge唯一能用的版本),另外就是在使用CMS收集器时的备用方案,发生 Concurrent Mode Failure时使用。
如果是单独使用,Serial Old一般用在client模式中。
Parallel Old收集器:在1.6版本之后,与 Parallel Scavenge结合使用,以更好的贯彻吞吐量优先的思想,如果是关注吞吐量的服务器,建议使用Parallel Scavenge + Parallel Old 收集器。
CMS收集器:这是当前阶段使用很广的一种收集器,国内很多大的互联网公司线上服务器都使用这种垃圾收集器(http://blog.csdn.net/wisgood/article/details/17067203),笔者公司的收集器也是这种,CMS收集器以获取最短回收停顿时间为目标,非常适合对用户响应比较高的B/S架构服务器。
CMSIncrementalMode: CMS收集器变种,属增量式垃圾收集器,在并发标记和并发清理时交替运行垃圾收集器和用户线程。
G1 收集器:面向服务器端应用的垃圾收集器,计划未来替代CMS收集器。
- 一般来说,如果是Java桌面应用,建议采用Serial+Serial Old收集器组合,即:-XX:+UseSerialGC(-client下的默认参数)
- 在开发/测试环境,可以采用默认参数,即采用Parallel Scavenge+Serial Old收集器组合,即:-XX:+UseParallelGC(-server下的默认参数)
- 在线上运算优先的环境,建议采用Parallel Scavenge+Serial Old收集器组合,即:-XX:+UseParallelGC
- 在线上服务响应优先的环境,建议采用ParNew+CMS+Serial Old收集器组合,即:-XX:+UseConcMarkSweepGC
另外在选择了垃圾收集器组合之后,还要配置一些辅助参数,以保证收集器可以更好的工作。关于这些参数,请在http://kenwublog.com/docs/java6-jvm-options-chinese-edition.htm中查询其意义和用法,如:
- 选用了ParNew收集器,你可能需要配置4个参数: -XX:SurvivorRatio, -XX:PretenureSizeThreshold, -XX:+HandlePromotionFailure,-XX:MaxTenuringThreshold;
- 选用了 Parallel Scavenge收集器,你可能需要配置3个参数: -XX:MaxGCPauseMillis,-XX:GCTimeRatio, -XX:+UseAdaptiveSizePolicy ;
- 选用了CMS收集器,你可能需要配置3个参数: -XX:CMSInitiatingOccupancyFraction, -XX:+UseCMSCompactAtFullCollection, -XX:CMSFullGCsBeforeCompaction;
关于GC有一个常见的疑问是,在启动时,我的内存如何分配?经过前面的学习,已经很容易知道,用-Xmn,-Xmx,-Xms,-Xss,-XX:NewSize,-XX:MaxNewSize,-XX:MaxPermSize,-XX:PermSize,-XX:SurvivorRatio,-XX:PretenureSizeThreshold,-XX:MaxTenuringThreshold就基本可以配置内存启动时的分配情况。但是,具体配置多少?设置小了,频繁GC(甚至内存溢出),设置大了,内存浪费。结合前面对于内存区域和其作用的学习,尽量考虑如下建议:
- -XX:PermSize尽量比-XX:MaxPermSize小,-XX:MaxPermSize>= 2 * -XX:PermSize, -XX:PermSize> 64m,一般对于4G内存的机器,-XX:MaxPermSize不会超过256m;
- -Xms = -Xmx(线上Server模式),以防止抖动,大小受操作系统和内存大小限制,如果是32位系统,则一般-Xms设置为1g-2g(假设有4g内存),在64位系统上,没有限制,不过一般为机器最大内存的一半左右;
- -Xmn,在开发环境下,可以用-XX:NewSize和-XX:MaxNewSize来设置新生代的大小(-XX:NewSize<=-XX:MaxNewSize),在生产环境,建议只设置-Xmn,一般-Xmn的大小是-Xms的1/2左右,不要设置的过大或过小,过大导致老年代变小,频繁Full GC,过小导致minor GC频繁。如果不设置-Xmn,可以采用-XX:NewRatio=2来设置,也是一样的效果;
- -Xss一般是不需要改的,默认值即可。
- -XX:SurvivorRatio一般设置8-10左右,推荐设置为10,也即:Survivor区的大小是Eden区的1/10,一般来说,普通的Java程序应用,一次minorGC后,至少98%-99%的对象,都会消亡,所以,survivor区设置为Eden区的1/10左右,能使Survivor区容纳下10-20次的minor GC才满,然后再进入老年代,这个与 -XX:MaxTenuringThreshold的默认值15次也相匹配的。如果XX:SurvivorRatio设置的太小,会导致本来能通过minor回收掉的对象提前进入老年代,产生不必要的full gc;如果XX:SurvivorRatio设置的太大,会导致Eden区相应的被压缩。
- -XX:MaxTenuringThreshold默认为15,也就是说,经过15次Survivor轮换(即15次minor GC),就进入老年代, 如果设置的小的话,则年轻代对象在survivor中存活的时间减小,提前进入年老代,对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象在年轻代的存活时间,增加在年轻代即被回收的概率。需要注意的是,设置了 -XX:MaxTenuringThreshold,并不代表着,对象一定在年轻代存活15次才被晋升进入老年代,它只是一个最大值,事实上,存在一个动态计算机制,计算每次晋入老年代的阈值,取阈值和MaxTenuringThreshold中较小的一个为准。
- -XX:PretenureSizeThreshold一般采用默认值即可。
在JVM运行的过程中,为保证其稳定、高效,或在出现GC问题时分析问题原因,我们需要对GC进行监控。所谓监控,其实就是分析清楚当前GC的情况。其目的是鉴别JVM是否在高效的进行垃圾回收,以及有没有必要进行调优。
通过监控GC,我们可以搞清楚很多问题,如:
1,minor GC和full GC的频率;
2,执行一次GC所消耗的时间;
3,新生代的对象何时被移到老生代以及花费了多少时间;
4,每次GC中,其它线程暂停(Stop the world)的时间;
5,每次GC的效果如何,是否不理想;
………………
监控GC的工具分为2种:命令行工具和图形工具;
常用的命令行工具有:
注:下面的命令都在JAVA_HOME/bin中,是java自带的命令。如果您发现无法使用,请直接进入Java安装目录调用或者先设置Java的环境变量,一个简单的办法为:直接运行命令 export PATH=$JAVA_HOME/bin:$PATH;另外,一般的,在Linux下,下面的命令需要sudo权限,在windows下,部分命令的部分选项不能使用。
1,jps
jps命令用于查询正在运行的JVM进程,常用的参数为:
-q:只输出LVMID,省略主类的名称
-m:输出虚拟机进程启动时传给主类main()函数的参数
-l:输出主类的全类名,如果进程执行的是Jar包,输出Jar路径
-v:输出虚拟机进程启动时JVM参数
命令格式:jps [option] [hostid]
一个简单的例子:

在上图中,有一个vid为309的apache进程在提供web服务。
2,jstat
jstat可以实时显示本地或远程JVM进程中类装载、内存、垃圾收集、JIT编译等数据(如果要显示远程JVM信息,需要远程主机开启RMI支持)。如果在服务启动时没有指定启动参数-verbose:gc,则可以用jstat实时查看gc情况。
jstat有如下选项:
-class:监视类装载、卸载数量、总空间及类装载所耗费的时间
-gc:监听Java堆状况,包括Eden区、两个Survivor区、老年代、永久代等的容量,以用空间、GC时间合计等信息
-gccapacity:监视内容与-gc基本相同,但输出主要关注java堆各个区域使用到的最大和最小空间
-gcutil:监视内容与-gc基本相同,但输出主要关注已使用空间占总空间的百分比
-gccause:与-gcutil功能一样,但是会额外输出导致上一次GC产生的原因
-gcnew:监视新生代GC状况
-gcnewcapacity:监视内同与-gcnew基本相同,输出主要关注使用到的最大和最小空间
-gcold:监视老年代GC情况
-gcoldcapacity:监视内同与-gcold基本相同,输出主要关注使用到的最大和最小空间
-gcpermcapacity:输出永久代使用到最大和最小空间
-compiler:输出JIT编译器编译过的方法、耗时等信息
-printcompilation:输出已经被JIT编译的方法
命令格式:jstat [option vmid [interval[s|ms] [count]]]
jstat可以监控远程机器,命令格式中VMID和LVMID特别说明:如果是本地虚拟机进程,VMID和LVMID是一致的,如果是远程虚拟机进程,那么VMID格式是: [protocol:][//]lvmid[@hostname[:port]/servername],如果省略interval和count,则只查询一次
查看gc情况的例子:

在图中,命令sudo jstat -gc 309 1000 5代表着:搜集vid为309的java进程的整体gc状态, 每1000ms收集一次,共收集5次;XXXC表示该区容量,XXXU表示该区使用量,各列解释如下:
S0C:S0区容量(S1区相同,略)
S0U:S0区已使用
EC:E区容量
EU:E区已使用
OC:老年代容量
OU:老年代已使用
PC:Perm容量
PU:Perm区已使用
YGC:Young GC(Minor GC)次数
YGCT:Young GC总耗时
FGC:Full GC次数
FGCT:Full GC总耗时
GCT:GC总耗时
用gcutil查看内存的例子:

图中的各列与用gc参数时基本一致,不同的是这里显示的是已占用的百分比,如S0为86.53,代表着S0区已使用了86.53%
3,jinfo
用于查询当前运行这的JVM属性和参数的值。
jinfo可以使用如下选项:
-flag:显示未被显示指定的参数的系统默认值
-flag [+|-]name或-flag name=value: 修改部分参数
-sysprops:打印虚拟机进程的System.getProperties()
命令格式:jinfo [option] pid
4,jmap
用于显示当前Java堆和永久代的详细信息(如当前使用的收集器,当前的空间使用率等)
-dump:生成java堆转储快照
-heap:显示java堆详细信息(只在Linux/Solaris下有效)
-F:当虚拟机进程对-dump选项没有响应时,可使用这个选项强制生成dump快照(只在Linux/Solaris下有效)
-finalizerinfo:显示在F-Queue中等待Finalizer线程执行finalize方法的对象(只在Linux/Solaris下有效)
-histo:显示堆中对象统计信息
-permstat:以ClassLoader为统计口径显示永久代内存状态(只在Linux/Solaris下有效)
命令格式:jmap [option] vmid
其中前面3个参数最重要,如:
查看对详细信息:sudo jmap -heap 309
生成dump文件: sudo jmap -dump:file=./test.prof 309
部分用户没有权限时,采用admin用户:sudo -u admin -H jmap -dump:format=b,file=文件名.hprof pid
查看当前堆中对象统计信息:sudo jmap -histo 309:该命令显示3列,分别为对象数量,对象大小,对象名称,通过该命令可以查看是否内存中有大对象;
有的用户可能没有jmap权限:sudo -u admin -H jmap -histo 309 | less
5,jhat
用于分析使用jmap生成的dump文件,是JDK自带的工具,使用方法为: jhat -J -Xmx512m [file]
不过jhat没有mat好用,推荐使用mat(Eclipse插件: http://www.eclipse.org/mat ),mat速度更快,而且是图形界面。
6,jstack
用于生成当前JVM的所有线程快照,线程快照是虚拟机每一条线程正在执行的方法,目的是定位线程出现长时间停顿的原因。
-F:当正常输出的请求不被响应时,强制输出线程堆栈
-l:除堆栈外,显示关于锁的附加信息
-m:如果调用到本地方法的话,可以显示C/C++的堆栈
命令格式:jstack [option] vmid
7,-verbosegc
-verbosegc是一个比较重要的启动参数,记录每次gc的日志,下面的表格对比了jstat和-verbosegc:
|
jstat |
-verbosegc
|
|
|
监控对象
|
运行在本机的Java应用可以把日志输出到终端上,或者借助jstatd命令通过网络连接远程的Java应用。
|
只有那些把-verbogc作为启动参数的JVM。
|
|
输出信息
|
堆状态(已用空间,最大限制,GC执行次数/时间,等等)
|
执行GC前后新生代和老年代空间大小,GC执行时间。
|
|
输出时间
|
Every designated time
每次设定好的时间。 |
每次GC发生的时候。
|
| 用途 |
观察堆空间变化情况
|
了解单次GC产生的效果。
|
与-verbosegc配合使用的一些常用参数为:
-XX:+PrintGCDetails,打印GC信息,这是-verbosegc默认开启的选项
-XX:+PrintGCTimeStamps,打印每次GC的时间戳
-XX:+PrintHeapAtGC:每次GC时,打印堆信息
-XX:+PrintGCDateStamps (from JDK 6 update 4) :打印GC日期,适合于长期运行的服务器
-Xloggc:/home/admin/logs/gc.log:制定打印信息的记录的日志位置
每条verbosegc打印出的gc日志,都类似于下面的格式:
time [GC [<collector>: <starting occupancy1> -> <ending occupancy1>(total occupancy1), <pause time1> secs] <starting occupancy3> -> <ending occupancy3>(total occupancy3), <pause time3> secs]
如:

这些选项的意义是:
time:执行GC的时间,需要添加-XX:+PrintGCDateStamps参数才有;
collector:minor gc使用的收集器的名字。
starting occupancy1:GC执行前新生代空间大小。
ending occupancy1:GC执行后新生代空间大小。
total occupancy1:新生代总大小
pause time1:因为执行minor GC,Java应用暂停的时间。
starting occupancy3:GC执行前堆区域总大小
ending occupancy3:GC执行后堆区域总大小
total occupancy3:堆区总大小
pause time3:Java应用由于执行堆空间GC(包括full GC)而停止的时间。
8,可视化工具
监控和分析GC也有一些可视化工具,比较常见的有JConsole和VisualVM,有兴趣的可以看看下面的文章,在此不再赘述:
http://blog.csdn.net/java2000_wl/article/details/8049707
调优方法
一切都是为了这一步,调优,在调优之前,我们需要记住下面的原则:
- 多数的Java应用不需要在服务器上进行GC优化;
- 多数导致GC问题的Java应用,都不是因为我们参数设置错误,而是代码问题;
- 在应用上线之前,先考虑将机器的JVM参数设置到最优(最适合);
- 减少创建对象的数量;
- 减少使用全局变量和大对象;
- GC优化是到最后不得已才采用的手段;
- 在实际使用中,分析GC情况优化代码比优化GC参数要多得多;
GC优化的目的有两个(http://www.360doc.com/content/13/0305/10/15643_269388816.shtml):
- 将转移到老年代的对象数量降低到最小;
- 减少full GC的执行时间;
为了达到上面的目的,一般地,你需要做的事情有:
- 减少使用全局变量和大对象;
- 调整新生代的大小到最合适;
- 设置老年代的大小为最合适;
- 选择合适的GC收集器;
在上面的4条方法中,用了几个“合适”,那究竟什么才算合适,一般的,请参考上面“收集器搭配”和“启动内存分配”两节中的建议。但这些建议不是万能的,需要根据您的机器和应用情况进行发展和变化,实际操作中,可以将两台机器分别设置成不同的GC参数,并且进行对比,选用那些确实提高了性能或减少了GC时间的参数。
真正熟练的使用GC调优,是建立在多次进行GC监控和调优的实战经验上的,进行监控和调优的一般步骤为:
1,监控GC的状态
使用各种JVM工具,查看当前日志,分析当前JVM参数设置,并且分析当前堆内存快照和gc日志,根据实际的各区域内存划分和GC执行时间,觉得是否进行优化;
2,分析结果,判断是否需要优化
如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化;如果GC时间超过1-3秒,或者频繁GC,则必须优化;
注:如果满足下面的指标,则一般不需要进行GC:
- Minor GC执行时间不到50ms;
- Minor GC执行不频繁,约10秒一次;
- Full GC执行时间不到1s;
- Full GC执行频率不算频繁,不低于10分钟1次;
3,调整GC类型和内存分配
如果内存分配过大或过小,或者采用的GC收集器比较慢,则应该优先调整这些参数,并且先找1台或几台机器进行beta,然后比较优化过的机器和没有优化的机器的性能对比,并有针对性的做出最后选择;
4,不断的分析和调整
通过不断的试验和试错,分析并找到最合适的参数
5,全面应用参数
如果找到了最合适的参数,则将这些参数应用到所有服务器,并进行后续跟踪。
调优实例
上面的内容都是纸上谈兵,下面我们以一些真实例子来进行说明:
实例1:
笔者昨日发现部分开发测试机器出现异常:java.lang.OutOfMemoryError: GC overhead limit exceeded,这个异常代表:GC为了释放很小的空间却耗费了太多的时间,其原因一般有两个:1,堆太小,2,有死循环或大对象;
笔者首先排除了第2个原因,因为这个应用同时是在线上运行的,如果有问题,早就挂了。所以怀疑是这台机器中堆设置太小;
使用ps -ef |grep "java"查看,发现:

该应用的堆区设置只有768m,而机器内存有2g,机器上只跑这一个java应用,没有其他需要占用内存的地方。另外,这个应用比较大,需要占用的内存也比较多;
笔者通过上面的情况判断,只需要改变堆中各区域的大小设置即可,于是改成下面的情况:

跟踪运行情况发现,相关异常没有再出现;
实例2:(http://www.360doc.com/content/13/0305/10/15643_269388816.shtml)
一个服务系统,经常出现卡顿,分析原因,发现Full GC时间太长:
jstat -gcutil:
S0 S1 E O P YGC YGCT FGC FGCT GCT
12.16 0.00 5.18 63.78 20.32 54 2.047 5 6.946 8.993
分析上面的数据,发现Young GC执行了54次,耗时2.047秒,每次Young GC耗时37ms,在正常范围,而Full GC执行了5次,耗时6.946秒,每次平均1.389s,数据显示出来的问题是:Full GC耗时较长,分析该系统的是指发现,NewRatio=9,也就是说,新生代和老生代大小之比为1:9,这就是问题的原因:
1,新生代太小,导致对象提前进入老年代,触发老年代发生Full GC;
2,老年代较大,进行Full GC时耗时较大;
优化的方法是调整NewRatio的值,调整到4,发现Full GC没有再发生,只有Young GC在执行。这就是把对象控制在新生代就清理掉,没有进入老年代(这种做法对一些应用是很有用的,但并不是对所有应用都要这么做)
实例3:
一应用在性能测试过程中,发现内存占用率很高,Full GC频繁,使用sudo -u admin -H jmap -dump:format=b,file=文件名.hprof pid 来dump内存,生成dump文件,并使用Eclipse下的mat差距进行分析,发现:

从图中可以看出,这个线程存在问题,队列LinkedBlockingQueue所引用的大量对象并未释放,导致整个线程占用内存高达378m,此时通知开发人员进行代码优化,将相关对象释放掉即可。
说明
本文是Java系列笔记的第4篇,这篇文章写了近3个月,一方面是这部分对我来说也是学习阶段,另一方面是这段时间一直在做项目,直到最近才比较有时间。
本人能力有限,如果有错漏,请留言指正。
参考资料
《深入理解Java虚拟机:JVM高级特效与最佳实现》
JVM启动参数大全, http://www.blogjava.net/midstr/archive/2008/09/21/230265.html
JVM系列三:JVM参数设置、分析, http://www.cnblogs.com/redcreen/archive/2011/05/04/2037057.html
Java 6 JVM参数选项大全(中文版), http://kenwublog.com/docs/java6-jvm-options-chinese-edition.htm
成为JavaGC专家Part II — 如何监控Java垃圾回收机制, http://www.importnew.com/2057.html
成为Java GC专家系列(3) — 如何优化Java垃圾回收机制, http://www.importnew.com/3146.html
JDK5.0垃圾收集优化之--Don't Pause, http://calvin.iteye.com/blog/91905
Java HOTSPOT VM参数大全, http://tech.sina.com.cn/s/2009-09-23/09561077572.shtml
【原】GC的默认方式, http://iamzhongyong.iteye.com/blog/1447314
JAVA启动参数大全之三:非Stable参数, http://blog.csdn.net/sfdev/article/details/2063928
Java虚拟机学习 - 内存调优, http://blog.csdn.net/java2000_wl/article/details/8090940
内存溢出, http://www.open-open.com/home/space.php?uid=71669&do=blog&id=8891
如何查看JVM的扩展参数:-X, http://www.blogjava.net/beansoft/archive/2012/03/01/371088.html
JVM内存状况查看方法和分析工具, http://hi.baidu.com/kingfly666666/item/e710a4371c60b0f1e7bb7a32
虚拟机学习系列 - 附 - 虚拟机参数, http://blog.csdn.net/su1216/article/details/7780924
JVM系列四:生产环境参数实例及分析【生产环境实例增加中】, http://www.cnblogs.com/redcreen/archive/2011/05/05/2038331.html
垃圾收集器与内存分配策略, http://raging-sweet.iteye.com/blog/1170198
JVM垃圾收集器使用调查:CMS最受欢迎 , http://blog.csdn.net/wisgood/article/details/17067203
Xms Xmx PermSize MaxPermSize 区别, http://www.cnblogs.com/mingforyou/archive/2012/03/03/2378143.html
Java虚拟机学习 - JDK可视化监控工具, http://blog.csdn.net/java2000_wl/article/details/8049707
虚拟机学习系列 - 6 - JDK工具, http://blog.csdn.net/su1216/article/details/7780857
JVM监控工具介绍jstack, jconsole, jinfo, jmap, jdb, jstat, http://hi.baidu.com/lotusxyhf/item/9cd8fcb8d6f8c1a5ebba935b
JVM 与 jstat, http://blog.sina.com.cn/s/blog_56fcfd620100hdcp.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号