

《大型网站技术架构:核心原理与案例分析》读书笔记-伸缩性
永无止境:网站的伸缩性架构
网站的伸缩性是指不需要改变网站的软硬件设计,仅仅通过改变部署的服务器 数量就可以扩大或者缩小网站的服务处理能力。
在网站从小到大这个渐进式的演化过程中,最重要的技术手段就是使用服务器集群,通过不断地 向集群中添加服务器来增强整个集群的处理能力。这就是网站系统的伸缩性架构,只要 技术上能做到向集群中加入服务器的数量和集群的处理能力成线性关系,那么网站就可 以以此手段不断提升自己的规模,从一个服务几十人的小网站发展成服务几十亿人的大 网站,从只能存储几个G图片的小网站发展成存储几百P图片的大网站。
1. 网站架构的伸缩性设计
网站的伸缩性设计可分成两类,一类是根据功能进行物理分离实现伸缩, 一类是单一功能通过集群实现伸缩。前者是不同的服务器部署不同的服务,提供不同的 功能;后者是集群内的多台服务器部署相同的服务,提供相同的功能。
1.1 不同功能进行物理分离实现伸缩
网站发展早期——通过增加服务器提高网站处理能力时,新增服务器总是从现有服 务器中分离出部分功能和服务,如图6.1所示。
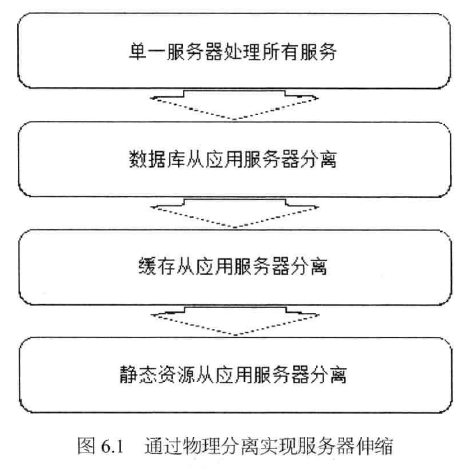
每次分离都会有更多的服务器加入网站,使用新增的服务器处理某种特定服务。事 实上,通过物理上分离不同的网站功能,实现网站伸缩性的手段,不仅可以用在网站发 展早期,而且可以在网站发展的任何阶段使用。具体又可分成如下两种情况。纵向分离(分层后分离):将业务处理流程上的不同部分分离部署,实现系统伸缩性, 如图6.2所示。

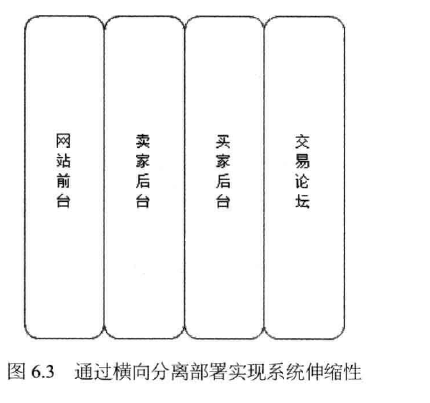
横向分离(业务分割后分离):将不同的业务模块分离部署,实现系统伸缩性,如 图6.3所示。
1.2单一功能通过集群规模实现伸缩
将不同功能分离部署可以实现一定程度的伸缩性,但是随着网站访问量的逐步增加, 即使分离到最小粒度的独立部署,单一的服务器也不能满足业务规模的要求。因此必须 使用服务器集群,即将相同服务部署在多台服务器上构成一个集群整体对外提供服务。当一头牛拉不动车的时候,不要去寻找一头更强壮的牛,而是用两头牛来拉车。
以搜索服务器为例,如果一台服务器可以提供每秒1000次的请求服务,即QPS (Query Per Second )为1000。那么如果网站高峰时每秒搜索访问量为10000,就需要部署 10台服务器构成一个集群。若以缓存服务器为例,如果每台服务器可缓存40GB数据, 那么要缓存100GB数据,就需要部署3台服务器构成一个集群。当然这些例子的计算都 是简化的,事实上,计算一个服务的集群规模,需要同时考虑其对可用性、性能的影响 及关联服务集群的影响。
具体来说,集群伸缩性又可分为应用服务器集群伸缩性和数据服务器集群伸缩性。 这两种集群由于对数据状态管理的不同,技术实现也有非常大的区别。而数据服务器集 群也可分为缓存数据服务器集群和存储数据服务器集群,这两种集群的伸缩性设计也不 大相同。
2. 应用服务器集群的伸缩性设计
应用服务器应该设计成无状态的,即应用服务器不存储请 求上下文信息,如果将部署有相同应用的服务器组成一个集群,每次用户请求都可以发 送到集群中任意一台服务器上去处理,任何一台服务器的处理结果都是相同的。这样只 要能将用户请求按照某种规则分发到集群的不同服务器上,就可以构成一个应用服务器 集群,每个用户的每个请求都可能落在不同的服务器上。如图6.4所示。
如果HTTP请求分发装置可以感知或者可以配置集群的服务器数量,可以及时发现 集群中新上线或下线的服务器,并能向新上线的服务器分发请求,停止向已下线的服务 器分发请求,那么就实现了应用服务器集群的伸缩性。这里,这个HTTP请求分发装置被称作负载均衡服务器。
负载均衡是网站必不可少的基础技术手段,不但可以实现网站的伸缩性,同时还改 善网站的可用性,可谓网站的杀手锏之一。具体的技术实现也多种多样,从硬件实现到软 件实现,从商业产品到幵源软件,应有尽有,但是实现负载均衡的基础技术不外以下几种。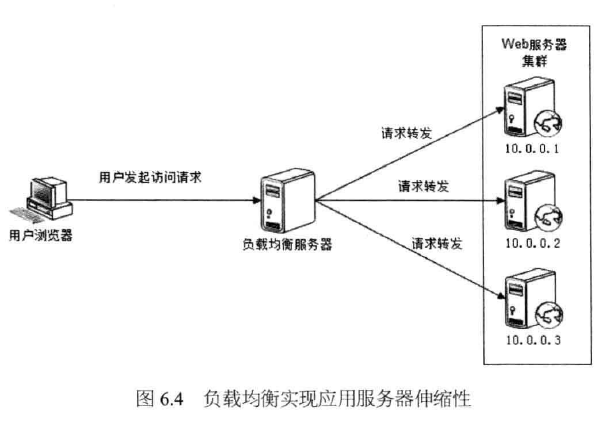
2.1 HTTP重定向负载均衡
利用HTTP重定向协议实现负载均衡。如图6.5所示。
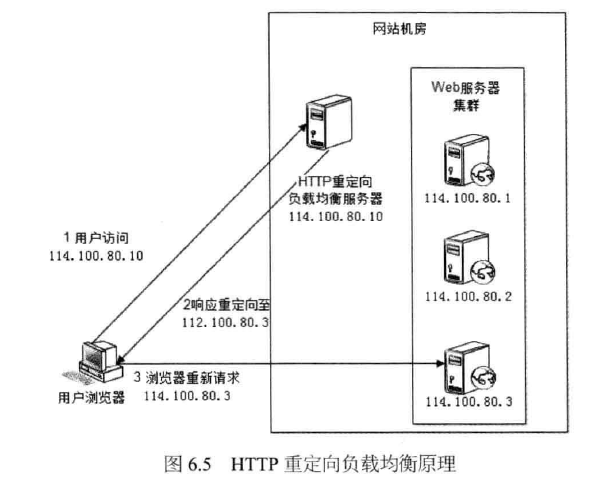 HTTP重定向服务器是一台普通的应用服务器,其唯一的功能就是根据用户的HTTP请求计算一台真实的Web服务器地址,并将该Web服务器地址写入HTTP重定向响应中(响应状态码302 )返回给用户浏览器
HTTP重定向服务器是一台普通的应用服务器,其唯一的功能就是根据用户的HTTP请求计算一台真实的Web服务器地址,并将该Web服务器地址写入HTTP重定向响应中(响应状态码302 )返回给用户浏览器
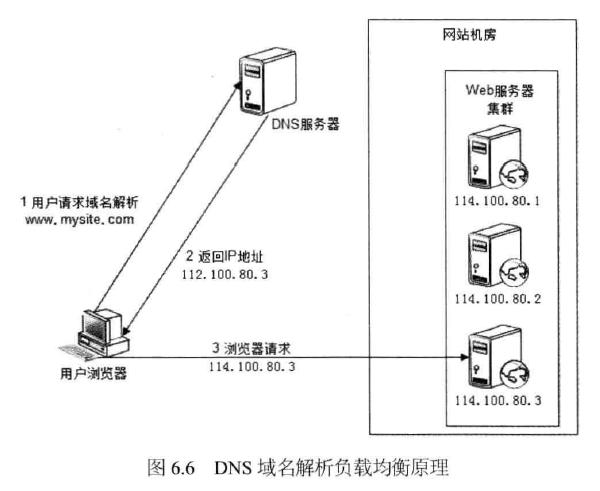
2.2DNS域名解析负载均衡
这是利用DNS处理域名解析请求的同时进行负载均衡处理的一种方案,如图6.6所
2.3反向代理负载均衡
利用反向代理服务器进行负载均衡,如图6.7所示。
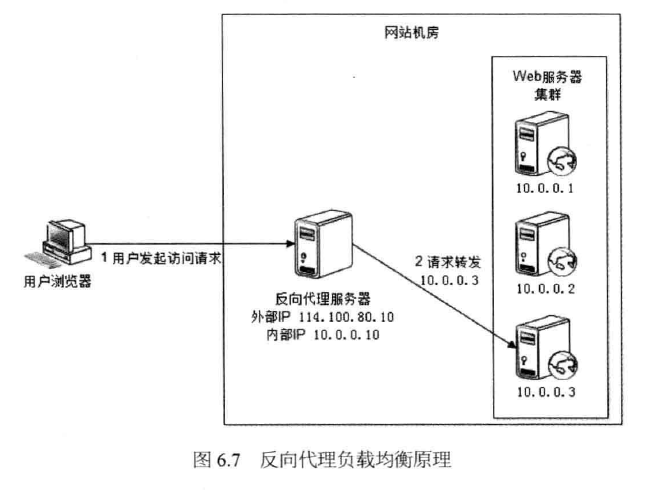
前面我们提到利用反向代理缓存资源,以改善网站性能。实际上,在部署位置上, 反向代理服务器处于Web服务器前面(这样才可能缓存Web响应,加速访问),这个位置也正好是负载均衡服务器的位置,所以大多数反向代理服务器同时提供负载均衡的功能,管理一组Web服务器,将请求根据负载均衡算法转发到不同Web服务器上。Web服 务器处理完成的响应也需要通过反向代理服务器返回给用户。由于Web服务器不直接对外提供访问,因此Web服务器不需要使用外部IP ±也址,而反向代理服务器则需要配置双 网卡和内部外部两套丨P地址。
图6.7中,浏览器访问请求的地址是反向代理服务器的地址114.100.80.10,反向代理 服务器收到请求后,根据负载均衡算法计算得到一台真实物理服务器的地址10.0.0.3,并 将请求转发给服务器。10.0.0.3处理完请求后将响应返回给反向代理服务器,反向代理服 务器再将该响应返回给用户。
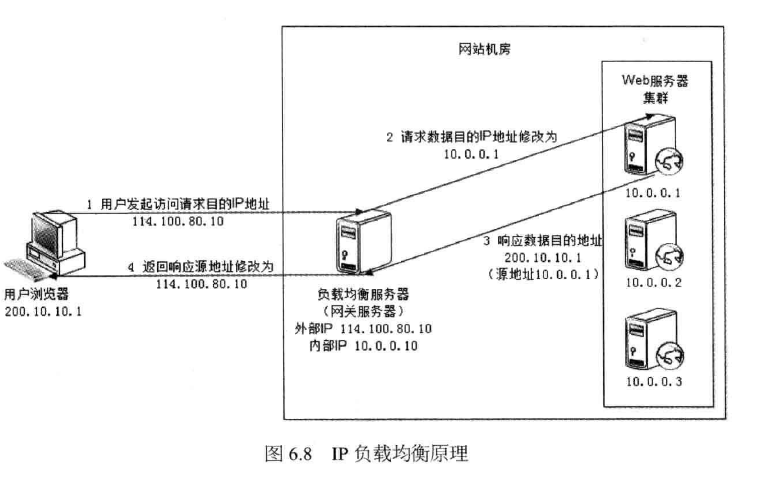
2.4 IP负载均衡
在网络层通过修改请求目标地址进行负载均衡,如图6.8所示。
2.5 数据链路层负载均衡
数据链路层负载均衡是指在通信协议的数据链路层修改mac地址进行负 载均衡,如图6.9所示。
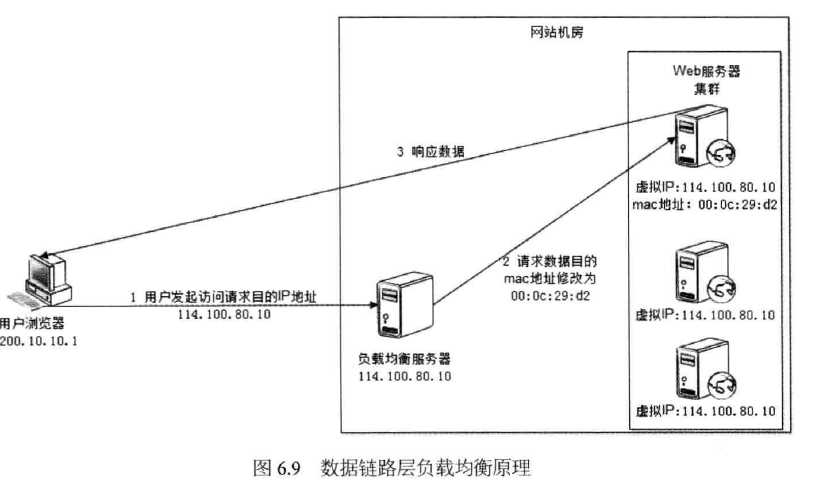
使用三角传输模式的链路层负载均衡是目前大型网站使用最广的一种负载均衡手 段。在Linux平台上最好的链路层负载均衡开源产品是LVS ( Linux Virtual Server )。
2.6负载均衡算法
负载均衡服务器的实现可以分成两个部分:
- 根据负载均衡算法和Web服务器列表计算得到集群中一台Web服务器的地址。
- 将请求数据发送到该地址对应的Web服务器上。
前面描述了如何将请求数据发送到Web服务器,而具体的负载均衡算法通常有以下 几种。
轮询(Round Robin,RR):所有请求被依次分发到每台应用服务器上,即每台服务器需要处理的请求数目都相 同,适合于所有服务器硬件都相同的场景。
加权轮询(Weighted Round Robin, WRR):根据应用服务器硬件性能的情况,在轮询的基础上,按照配置的权重将请求分发到 每个服务器,高性能的服务器能分配更多请求。
随机(Random):请求被随机分配到各个应用服务器,在许多场合下,这种方案都很简单实用,因为 好的随机数本身就很均衡。即使应用服务器硬件配置不同,也可以使用加权随机算法。
最少连接(Least Connections):记录每个应用服务器正在处理的连接数(请求数),将新到的请求分发到最少连接的 服务器上,应该说,这是最符合负载均衡定义的算法。同样,最少连接算法也可以实现 加权最少连接。
源地址散列(Source Hashing):根据请求来源的IP ±也址进行Hash计算,得到应用服务器,这样来自同一个IP地址 的请求总在同一个服务器上处理,该请求的上下文信息可以存储在这台服务器上,在一 个会话周期内重复使用,从而实现会话黏滞。
3.分布式缓存集群的伸缩性设计
和所有服务器都部署相同应用的应用服务器集群不同,分布式缓存服务器集群中不 同服务器中缓存的数据各不相同,缓存访问请求不可以在缓存服务器集群中的任意一台 处理,必须先找到缓存有需要数据的服务器,然后才能访问。这个特点会严重制约分布 式缓存集群的伸缩性设计,因为新上线的缓存服务器没有缓存任何数据,而已下线的缓 存服务器还缓存着网站的许多热点数据。
必须让新上线的缓存服务器对整个分布式缓存集群影响最小,也就是说新加入缓存 服务器后应使整个缓存服务器集群中已经缓存的数据尽可能还被访问到,这是分布式缓 存集群伸缩性设计的最主要目标。
简单的路由算法可以使用余数Hash:用服务器数目除以缓存数据KEY的Hash值, 余数为服务器列表下标编号。假设图6.10中’BEIJING’的Hash值是490806430 ( Java中的 HashCode()返回值),用服务器数目3除以该值,得到余数1,对应节点NODE1。由于 HashCode具有随机性,因此使用余数Hash路由算法可保证缓存数据在整个Memcached 服务器集群中比较均衡地分布。
但是,当分布式缓存集群需要扩容的时候,事情就变得棘手了。假设由于业务发展,网站需要将3台缓存服务器扩容至4台。更改服务器列表,仍 旧使用余数Hash,用4除以’BEIJING’的Hash值49080643,余数为2,对应服务器NODE2。 由于数据<’BEIJING',DATA>缓存在NODE1,对NODE2的读缓存操作失败,缓存没有命 中。很容易就可以计算出,3台服务器扩容至4台服务器,大约有75% ( 3/4 )被缓存了 的数据不能正确命中,随着服务器集群规模的增大,这个比例线性上升。当100台服务 器的集群中加入一台新服务器,不能命中的概率是99% (M(yV+l))
这个结果显然是不能接受的,在网站业务中,大部分的业务数据读操作请求事实上 是通过缓存获取的,只有少量读操作请求会访问数据库,因此数据库的负载能力是以有 缓存为前提而设计的。当大部分被缓存了的数据因为服务器扩容而不能正确读取时,这 些数据访问的压力就落到了数据库的身上,这将大大超过数据库的负载能力,严重的可 能会导致数据库宕机(这种情况下,不能简单重启数据库,网站也需要较长时间才能逐 渐恢复正常。)
能不能通过改进路由算法,使得新加入的服务器不影响大部分缓存数据的正确命中 呢?目前比较流行的算法是一致性Hash算法。
4. 数据存储服务器集群的伸缩性设计
缓存的目的是加速数据读取的速度并减轻数据存储服务器的负载压力,因此部分缓 存数据的丢失不影响业务的正常处理,因为数据还可以从数据库等存储服务器上获取。
而数据存储服务器必须保证数据的可靠存储,任何情况下都必须保证数据的可用性 和正确性。因此缓存服务器集群的伸缩性架构方案不能直接适用于数据库等存储服务器。 存储服务器集群的伸缩性设计相对更复杂一些,具体说来,又可分为关系数据库集群的 伸缩性设计和NoSQL数据库的伸缩性设计。
4.1关系数据库集群的伸缩性设计
图6.14为使用数据复制的MySQL集群伸缩 性方案。
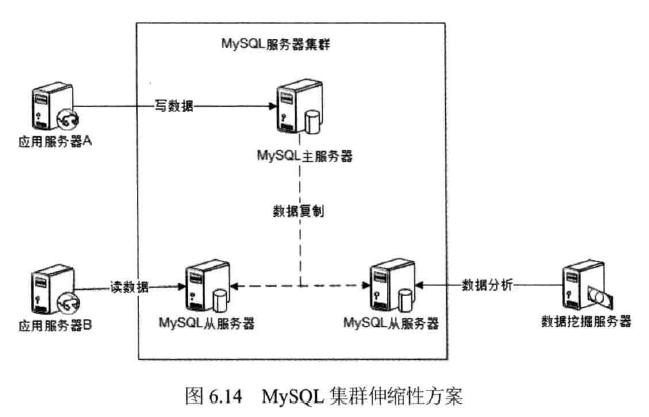
在这种架构中,虽然多台服务器部署MySQL实例,但是它们的角色有主从之分,数 据写操作都在主服务器上,由主服务器将数据同步到集群中其他从服务器,数据读操作 及数据分析等离线操作在从服务器上进行。
除了数据库主从读写分离,前面提到的业务分割模式也可以用在数据库,不同业务 数据表部署在不同的数据库集群上,即俗称的数据分库。这种方式的制约条件是跨库的 表不能进行join操作。
在大型网站的实际应用中,即使进行了分库和主从复制,对一些单表数据仍然很大 的表,比如Facebook的用户数据库,淘宝的商品数据库,还需要进行分片,将一张表拆 开分别存储在多个数据库中。
目前网站在线业务应用中比较成熟的支持数据分片的分布式关系数据库产品主要有开源的 Amoeba ( http://sourceforge.net/projects/amoeba/)和 Cobar ( http://code.alibabatech. com/wiki/display/cobar/Home )。这两个产品有相似的架构设计,以Cobar为例,部署模型如图6.15所示。
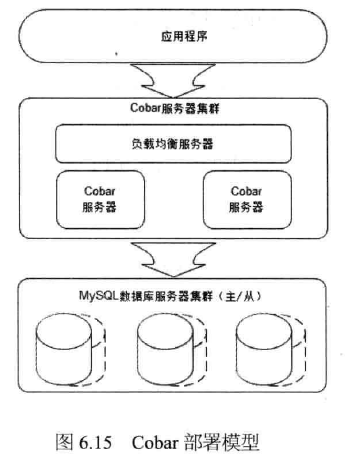
Cobar是一个分布式关系数据库访问代理,介于应用服务器和数据库服务器之间
(Cobar也支持非独立部署,以lib的方式和应用程序部署在一起)。应用程序通过JDBC 驱动访问Cobar集群,Cobar服务器根据SQL和分库规则分解SQL,分发到MySQL集群 不同的数据库实例上执行(每个MySQL实例都部署为主/从结构,保证数据高可用)。
Cobar系统组件模型如图6.16所示。
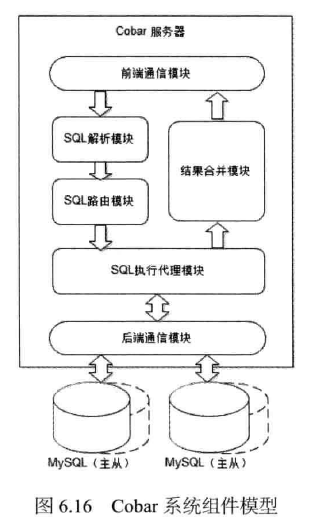
前端通信模块负责和应用程序通信,接收到SQL请求(select * from users where userid in (12,22,23))后转交给SQL解析模块,SQL解析模块解析获得SQL中的路由规则査询 条件(userid in( 12,22,23)两转交给SQL路由模块,SQL路由模块根据路由规则配置(userid 为偶数路由至数据库A,userid为奇数路由至数据库B )将应用程序提交的SQL分解成两 条 SQL( select * from users where userid in (12,22); select * from users where userid in (23);)转交给SQL执行代理模块,发送至数据库A和数据库B分别执行。数据库A和数据库B的执行结果返回至SQL执行模块,通过结果合并模块将两个返 回结果集合并成一个结果集,最终返回给应用程序,完成在分布式数据库中的一次访问请求。
相比关系数据库本身功能上的优雅强大,目前各类分布式关系数据库解决方案都显得非常简陋,限制了关系数据库某些功能的使用。但是当网站业务面临不停增长的海量 业务数据存储压力时,又不得不利用分布式关系数据库的集群伸缩能力,这时就必须从 业务上回避分布式关系数据库的各种缺点:避免事务或利用事务补偿机制代替数据库事 务;分解数据访问逻辑避免JOIN操作等。
Cobar的伸缩有两种:Cobar服务器集群的伸缩和MySQL服务器集群的伸缩。
Cobar服务器可以看作是无状态的应用服务器,因此其集群伸缩可以简单使用负载均 衡的手段实现。而MySQL中存储着数据,要想保证集群扩容后数据一致负载均衡,必须 要做数据迁移,将集群中原来机器中的数据迁移到新添加的机器中.具体迁移哪些数据可以利用一致性Hash算法(即路由模块使用一致性Hash算法进 行路由),尽量使需要迁移的数据最少。但是迁移数据需要遍历数据库中每条记录(的索 引),重新进行路由计算确定其是否需要迁移,这会对数据库访问造成一定压力。并且需 要解决迁移过程中数据的一致性、可访问性、迁移过程中服务器宕机时的可用性等诸多问题。
4.2 NoSQL数据库的伸缩性设计
开源社区有各种NoSQL产品,其支持的数据结构和伸缩特性也各不相同,目前看来, 应用最广泛的是Apache HBase。
HBase为可伸缩海量数据储存而设计,实现面向在线业务的实时数据访问延迟。HBase 的伸缩性主要依赖其可分裂的HRegion及可伸缩的分布式文件系统HDFS实现。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步