
时序数据库入门
参考:
https://www.cnblogs.com/jpfss/p/12183214.html
https://www.sohu.com/a/237660940_130419
时序数据库入门
数据库的模型包含关系型、key-value 型、Document 型等很多种,那么为什么新型的时序数据库成为监控数据存储的新宠呢? 下面就会从
- 为什么需要时序数据库?
- 时序数据库的数据结构
两个方面来介绍一下时序数据库。
1. 为什么需要时序数据库
1.1 时序数据特点
时序数据有如下几个特点:
- 基本上是插入操作较多且无更新的需求
- 数据带有时间属性,且数据量随着时间递增
- 插入数据多,每秒钟插入需要可到达千万甚至是上亿的数据量
- 查询、聚合等操作主要针对近期插入的数据
- 时序数据能够还原数据的变化状态
- 可以通过分析过去时序数据的变化、检测现在的变化,以达到预测未来如何变化的目的
时序数据使用需求:
- 能够按照指标筛选数据
- 能够按照区间、时间范围、统计信息聚合展示数据
1.2 why
为什么不用一个「常规」 的数据库?
-
事实上,你完全可以可以使用非时序序列的数据库,并且也确实有人是这样做的。
![在这里插入图片描述]()
**注**: 数据源 Percona,2017 年 2 月. <https://www.percona.com/blog/2017/02/10/percona-blog-poll-database-engine-using-store-time-series-data/>
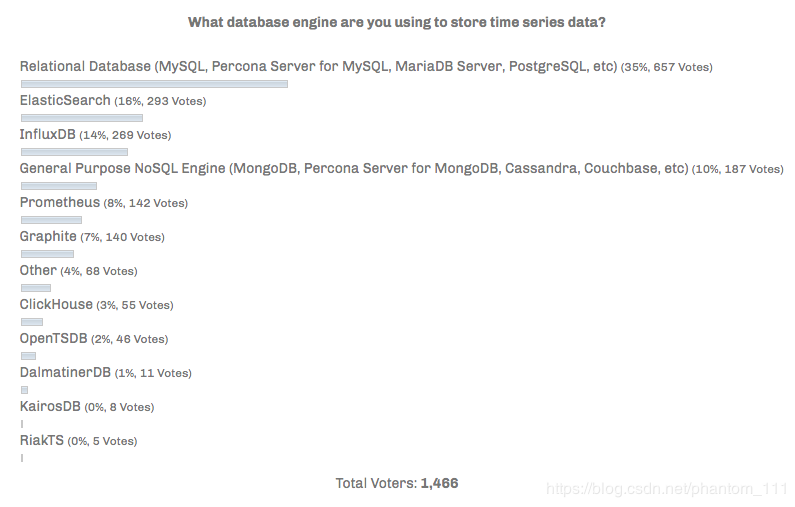
为什么需要时序数据库?
-
规模
时间数据的特点是累计速度非常快,常规数据库在设计之初,并非是为了处理这种规模的数据,而且关系型数据库在处理大规模的数据集的效果非常差。
-
使用特性
时序数据库能够提供一些通用的对时间序列数据分析的功能和操作,比如数据保留策略、连续查询、灵活的时间聚合,此外时序数据库以时间为维度,也提供更快的大规模查询、更好的数据压缩等。
1.3 场景选择
是否所有的数据都适合用时序数据库来存储?
答案:是否定的,时序数据库提供了针对大量数据的插入操作,但同时数据的读取延迟也相对增加。而且时序数据库不支持 SQL 的数据查询。
主要适用时序数据库的场景:
-
监控软件系统: 虚拟机、容器、服务、应用
-
监控物理系统: 水文监控、工厂的设备监控、国家安全相关的数据监控、通讯监控、传感器数据、血糖仪、血压变化、心率等
-
资产跟踪应用: 汽车、卡车、物理容器、运货托盘
-
金融交易系统: 传统证券、新兴的加密数字货币
-
事件应用程序: 跟踪用户、客户的交互数据
-
商业智能工具: 跟踪关键指标和业务的总体健康情况
2. 时序数据库的数据结构
传统数据库存储采用的都是 B+ tree,原因是查询和顺序插入时有利于减少寻道次数的。然而对于 90% 以上场景都是写入的时序数据库,使用了 LSM tree 更合适。
2.1 LSM产生背景
LSM (Log Structured Merge Trees) 通过减少随机的本地更新操作来达到更好的写操作的吞吐量。
影响写操作吞吐量的主要原因还是磁盘的随机操作慢,顺序读写快,解决办法是将文件的随机存储改为顺序存储,因为完全是顺序的,提升写操作性能,比如日志文件就是顺序写入。
写数据的问题解决了,那如何快速的读出数据呢?
顺序写入的日志文件,在读取一些数据的时候需要全文扫描,但这一操作耗时取决于需要读取的数据在日志文件中的位置,所以其使用场景有限,适用于数据被整体的访问的情况下,像大部分数据的 WAL。
对于读操作,可以记录更多的内容比如 key、range 来提高性能,比较常用的方法有:
- 二分查找:将文件数据有序保存,使用二分查找来完成特定 key 的查找。
- 哈希:用哈希将数据分为不同的 bucket。
- B+ 树:使用 B+ 树,减少外部文件的存取。
以上的方案都是将数据按照特定的方式存储,对于读操作友好,但写操作的性能必然下降,主要原因是这种存储数据产生的是磁盘的随机读写,不适用于时序数据库 90% 都是写入的场景。
2.2 LSM 算法
LSM 是将之前使用的一个大的查找结构(造成随机读写,影响写性能的结构,比如 B+ 树),变换为将写操作顺序的保存到有序文件中,且每个文件只保存短时间内的改动。文件是有序的,所以读取的时候,查找会非常快 。且文件不可修改,新的更新操作只会写入到新的文件中。读操作检查有序的文件。然后周期性的合并文件来减少文件的个数。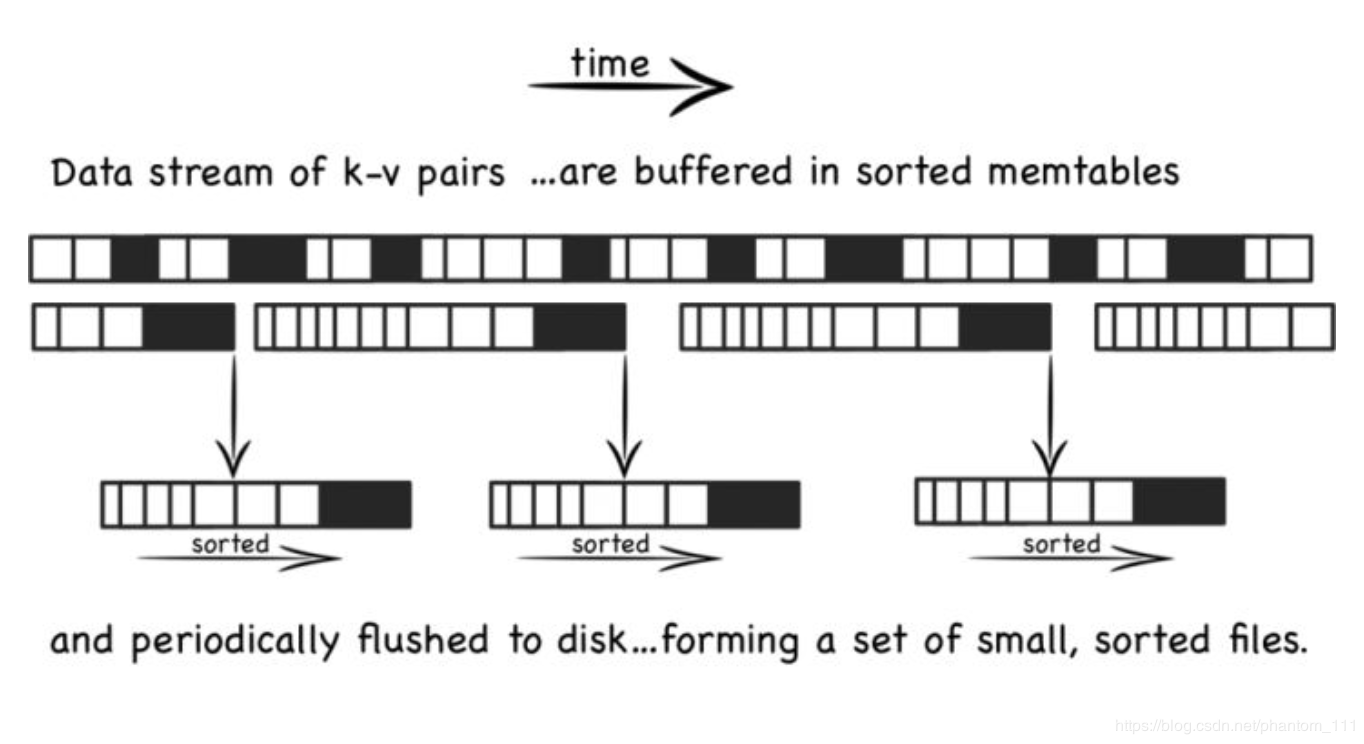
-
写入操作
数据先在内存中缓存(memtable) 中,memtable 使用树的结构来保持 key 是有序的,同时使用 WAL 的方式备份数据到磁盘。当 memtable 中数据达到一定规模后会刷新数据到磁盘生成文件。
-
更新写入操作
文件不允许被编辑,所以新的内容或修改只是简单的生成新的文件。当越多的数据存储到系统中,就会有越多的不可修改、顺序的有序文件被创建。但比较旧的文件不会被更新,重复的激流只会通过创建新的记录来达到覆盖的目的,但这这就产生了冗余的数据。
系统会周期性的执行合并的操作,合并操作用于移除重复的更新或者删除记录,同时还能够减少文件个数的增加,保证读操作的性能。
-
读取操作
查询的时候首先检查内存数据(memtable),如果没有找到这个 key,就会逆序的一个个的检查磁盘上的文件,但读操作耗时会随着磁盘上文件个数的增加而增加。(O(K log N), K为文件个数, N 为文件平均大小)。可以使用如下策略减少耗时
- 将文件按照 LRU 缓存到内存中
- 周期性的合并文件,减少文件的个数
- 使用布隆过滤器避免大量的读文件操作(如果bloom说一个key不存在,就一定不存在,而当bloom说一个文件存在是,可能是不存在的,只是通过概率来保证)
2.3 时序数据库的存储
-
单机上的存储
![在这里插入图片描述]()
核心就是通过内存写和后序磁盘的顺序写入获取更高的写入性能,避免随机写入,但同时也牺牲了读取性能
-
分布式存储
分布式存储需要考虑如何将数据分布到多台机器上面,即分片(sharding)的问题。分片问题包括分片方法的选择和分片的设计问题。
分片方法:
- 哈希分片: 均衡性较好,但集群不易扩展
- 执行哈希:均衡性好,集群扩展易,但实现复杂
- 范围划分:复杂度在于合并和分裂,全局有序
分片设计
分片的会直接影响到写入的性能,结合时序数据库的特点,根据 metric + tags 分片是比较好的方式,查询大都是按照一个时间范围进行的,这样形同的 metric + tags 数据会被分配到一台机器上连续存放,顺序的磁盘读取是很快的。
在时间范围很长的情况下,可以根据时间访问再进行分段,分别存储到不同的机器上,这样大范围的数据就可以支持并发查询,优化查询速度。
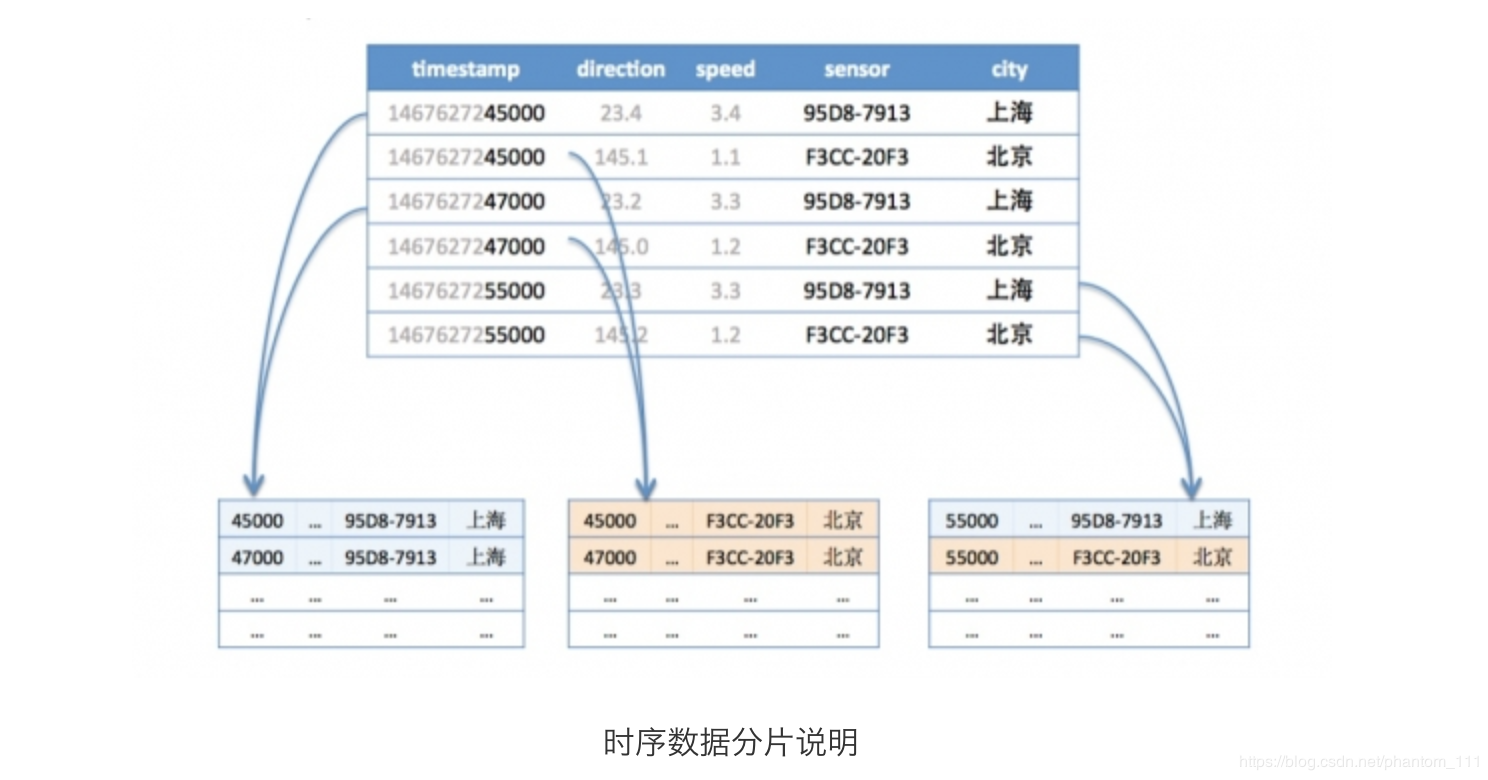
如下图,第一行和第三行都是同样的tag(sensor=95D8-7913;city=上海),所以分配到同样的分片,而第五行虽然也是同样的tag,但是根据时间范围再分段,被分到了不同的分片。第二、四、六行属于同样的tag(sensor=F3CC-20F3;city=北京)也是一样的道理。
![在这里插入图片描述]()
计划后面写一篇 关于InfluxDB 的文章,上文的大部分内容是 google + 个人理解,如果发现哪里有误,欢迎指出。
3. 参考资料
- LSM 算法的原理是什么
- 我们为什么需要一个时序数据库
- 时序数据库简介
- 时序数据库设计体系(1):时序数据存储模型设计
- 时序数据库技术体系(2):初识 InfluxDB
- 十分钟看懂时序数据库——存储篇
原文地址:https://blog.csdn.net/phantom_111/article/details/88920956
五分钟看懂时序数据库
2017年时序数据库忽然火了起来。开年2月Facebook开源了beringei时序数据库;到了4月基于PostgreSQL打造的时序数据库TimeScaleDB也开源了,而早在2016年7月,百度云在其天工物联网平台上发布了国内首个多租户的分布式时序数据库产品TSDB,成为支持其发展制造,交通,能源,智慧城市等产业领域的核心产品,同时也成为百度战略发展产业物联网的标志性事件。时序数据库作为物联网方向一个非常重要的服务,业界的频频发声,正说明各家企业已经迫不及待的拥抱物联网时代的到来。
本文会从时序数据库的基本概念、使用场景、解决的问题一一展开,最后会从如何解决时序数据存储这一技术问题入手进行深入分析。
1. 背景
百度无人车在运行时需要监控各种状态,包括坐标,速度,方向,温度,湿度等等,并且需要把每时每刻监控的数据记录下来,用来做大数据分析。每辆车每天就会采集将近8T的数据。如果只是存储下来不查询也还好(虽然已经是不小的成本),但如果需要快速查询“今天下午两点在后厂村路,速度超过60km/h的无人车有哪些”这样的多纬度分组聚合查询,那么时序数据库会是一个很好的选择。
2. 什么是时序数据库
先来介绍什么是时序数据。时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
对比传统数据库仅仅记录了数据的当前值,时序数据库则记录了所有的历史数据。同时时序数据的查询也总是会带上时间作为过滤条件。
时序数据示例

p1-北上广三地2015年气温变化图

p2-北上广三地当前温度实时展现
下面介绍下时序数据库的一些基本概念(不同的时序数据库称呼略有不同)。
metric: 度量,相当于关系型数据库中的table。
data point: 数据点,相当于关系型数据库中的row。
timestamp:时间戳,代表数据点产生的时间。
field: 度量下的不同字段。比如位置这个度量具有经度和纬度两个field。一般情况下存放的是会随着时间戳的变化而变化的数据。
tag: 标签,或者附加信息。一般存放的是并不随着时间戳变化的属性信息。timestamp加上所有的tags可以认为是table的primary key。
如下图,度量为Wind,每一个数据点都具有一个timestamp,两个field:direction和speed,两个tag:sensor、city。它的第一行和第三行,存放的都是sensor号码为95D8-7913的设备,属性城市是上海。随着时间的变化,风向和风速都发生了改变,风向从23.4变成23.2;而风速从3.4变成了3.3。
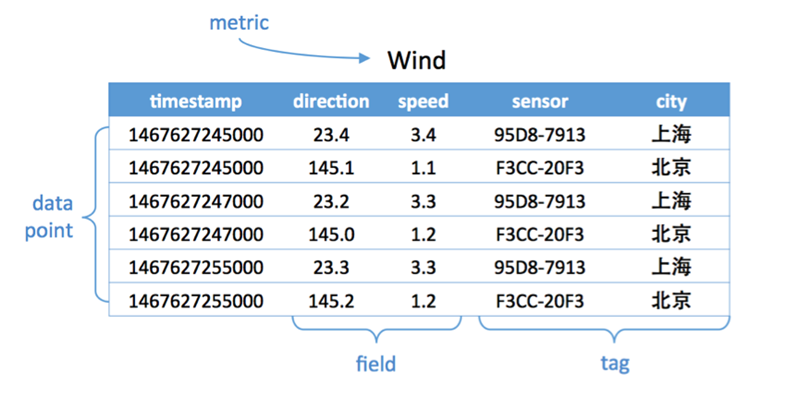
p3-时序数据库基本概念图
3. 时序数据库的场景
所有有时序数据产生,并且需要展现其历史趋势、周期规律、异常性的,进一步对未来做出预测分析的,都是时序数据库适合的场景。
在工业物联网环境监控方向,百度天工的客户就遇到了这么一个难题,由于工业上面的要求,需要将工况数据存储起来。客户每个厂区具有20000个监测点,500毫秒一个采集周期,一共20个厂区。这样算起来一年将产生惊人的26万亿个数据点。假设每个点50Byte,数据总量将达1P(如果每台服务器10T的硬盘,那么总共需要100多台服务器)。这些数据不只是要实时生成,写入存储;还要支持快速查询,做可视化的展示,帮助管理者分析决策;并且也能够用来做大数据分析,发现深层次的问题,帮助企业节能减排,增加效益。最终客户采用了百度天工的时序数据库方案,帮助他解决了难题。
在互联网场景中,也有大量的时序数据产生。百度内部有大量服务使用天工物联网平台的时序数据库。举个例子,百度内部服务为了保障用户的使用体验,将用户的每次网络卡顿、网络延迟都会记录到百度天工的时序数据库。由时序数据库直接生成报表以供技术产品做分析,尽早的发现、解决问题,保证用户的使用体验。
4. 时序数据库遇到的挑战
很多人可能认为在传统关系型数据库上加上时间戳一列就能作为时序数据库。数据量少的时候确实也没问题,但少量数据是展现的纬度有限,细节少,可置信低,更加不能用来做大数据分析。很明显时序数据库是为了解决海量数据场景而设计的。
可以看到时序数据库需要解决以下几个问题
l 时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
l 时序数据的读取:又如何支持在秒级对上亿数据的分组聚合运算。
l 成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
这些问题不是用一篇文章就能含盖的,同时每个问题都可以从多个角度去优化解决。在这里只从数据存储这个角度来尝试回答如何解决大数据量的写入和读取。
5. 数据的存储
数据的存储可以分为两个问题,单机上存储和分布式存储。
单机存储
如果只是存储起来,直接写成日志就行。但因为后续还要快速的查询,所以需要考虑存储的结构。
传统数据库存储采用的都是B tree,这是由于其在查询和顺序插入时有利于减少寻道次数的组织形式。我们知道磁盘寻道时间是非常慢的,一般在10ms左右。磁盘的随机读写慢就慢在寻道上面。对于随机写入B tree会消耗大量的时间在磁盘寻道上,导致速度很慢。我们知道SSD具有更快的寻道时间,但并没有从根本上解决这个问题。
对于90%以上场景都是写入的时序数据库,B tree很明显是不合适的。
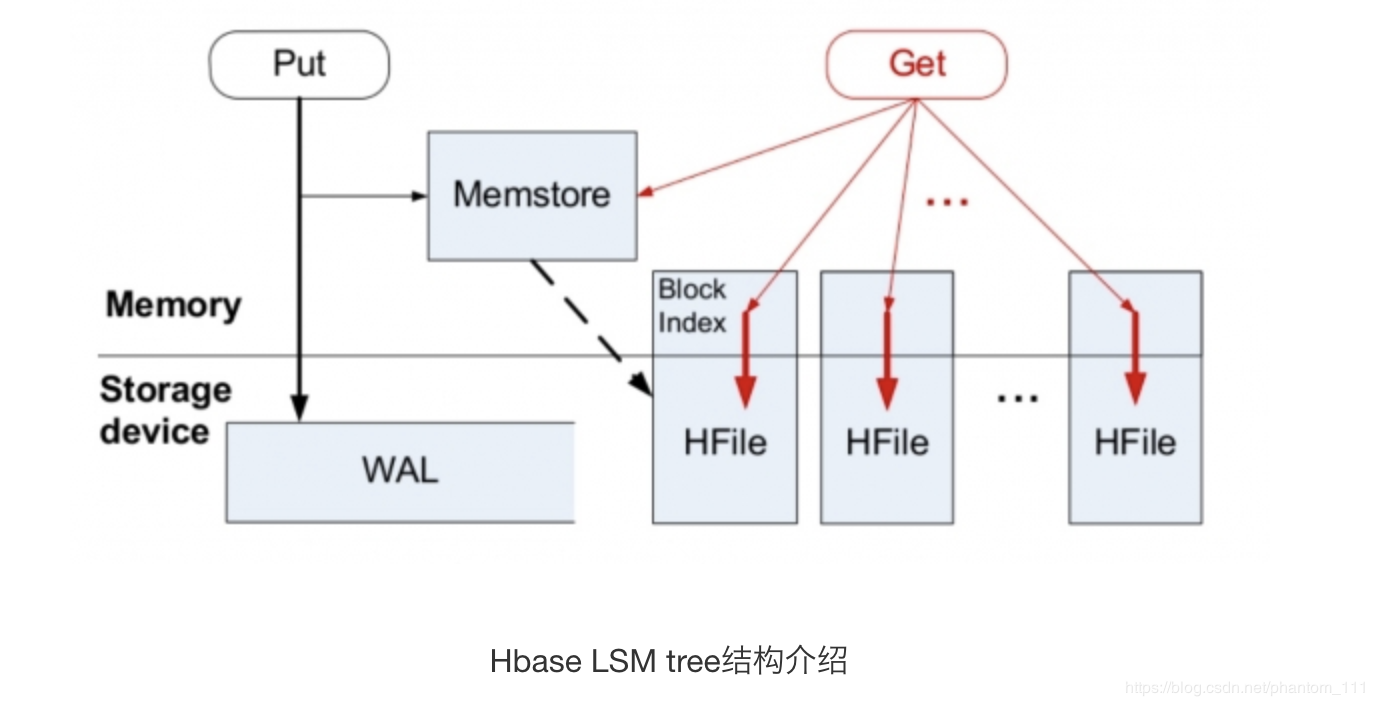
业界主流都是采用LSM tree替换B tree,比如Hbase, Cassandra等nosql中。这里我们详细介绍一下。
LSM tree包括内存里的数据结构和磁盘上的文件两部分。分别对应Hbase里的MemStore和HLog;对应Cassandra里的MemTable和sstable。
LSM tree操作流程如下:
1. 数据写入和更新时首先写入位于内存里的数据结构。为了避免数据丢失也会先写到WAL文件中。
2. 内存里的数据结构会定时或者达到固定大小会刷到磁盘。这些磁盘上的文件不会被修改。
3. 随着磁盘上积累的文件越来越多,会定时的进行合并操作,消除冗余数据,减少文件数量。

p4-Hbase LSM tree结构介绍(注1)
可以看到LSM tree核心思想就是通过内存写和后续磁盘的顺序写入获得更高的写入性能,避免了随机写入。但同时也牺牲了读取性能,因为同一个key的值可能存在于多个HFile中。为了获取更好的读取性能,可以通过bloom filter和compaction得到,这里限于篇幅就不详细展开。
分布式存储
时序数据库面向的是海量数据的写入存储读取,单机是无法解决问题的。所以需要采用多机存储,也就是分布式存储。
分布式存储首先要考虑的是如何将数据分布到多台机器上面,也就是 分片(sharding)问题。下面我们就时序数据库分片问题展开介绍。分片问题由分片方法的选择和分片的设计组成。
分片方法
时序数据库的分片方法和其他分布式系统是相通的。
哈希分片:这种方法实现简单,均衡性较好,但是集群不易扩展。
一致性哈希:这种方案均衡性好,集群扩展容易,只是实现复杂。代表有Amazon的DynamoDB和开源的Cassandra。
范围划分:通常配合全局有序,复杂度在于合并和分裂。代表有Hbase。
分片设计
分片设计简单来说就是以什么做分片,这是非常有技巧的,会直接影响写入读取的性能。
结合时序数据库的特点,根据metric+tags分片是比较好的一种方式,因为往往会按照一个时间范围查询,这样相同metric和tags的数据会分配到一台机器上连续存放,顺序的磁盘读取是很快的。再结合上面讲到的单机存储内容,可以做到快速查询。
进一步我们考虑时序数据时间范围很长的情况,需要根据时间范围再将分成几段,分别存储到不同的机器上,这样对于大范围时序数据就可以支持并发查询,优化查询速度。
如下图,第一行和第三行都是同样的tag(sensor=95D8-7913;city=上海),所以分配到同样的分片,而第五行虽然也是同样的tag,但是根据时间范围再分段,被分到了不同的分片。第二、四、六行属于同样的tag(sensor=F3CC-20F3;city=北京)也是一样的道理。
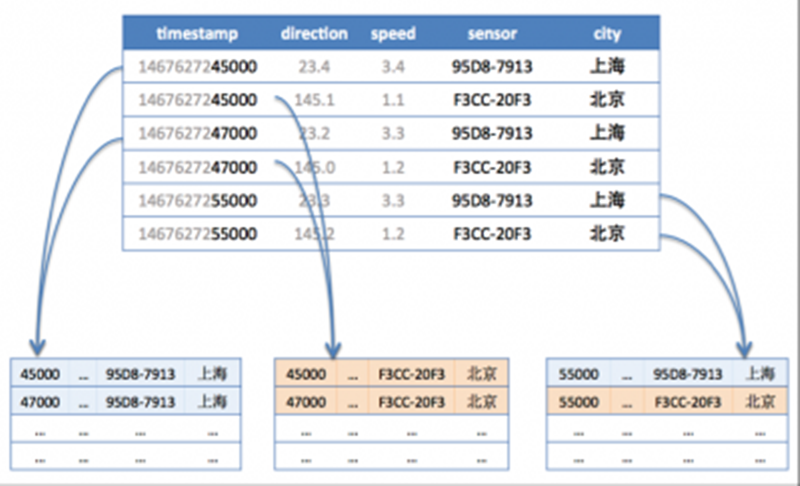
p5-时序数据分片说明
6. 真实案例
下面我以一批开源时序数据库作为说明。
InfluxDB:
非常优秀的时序数据库,但只有单机版是免费开源的,集群版本是要收费的。从单机版本中可以一窥其存储方案:在单机上InfluxDB采取类似于LSM tree的存储结构TSM;而分片的方案InfluxDB先通过+(事实上还要加上retentionPolicy)确定ShardGroup,再通过+的hash code确定到具体的Shard。
这里timestamp默认情况下是7天对齐,也就是说7天的时序数据会在一个Shard中。
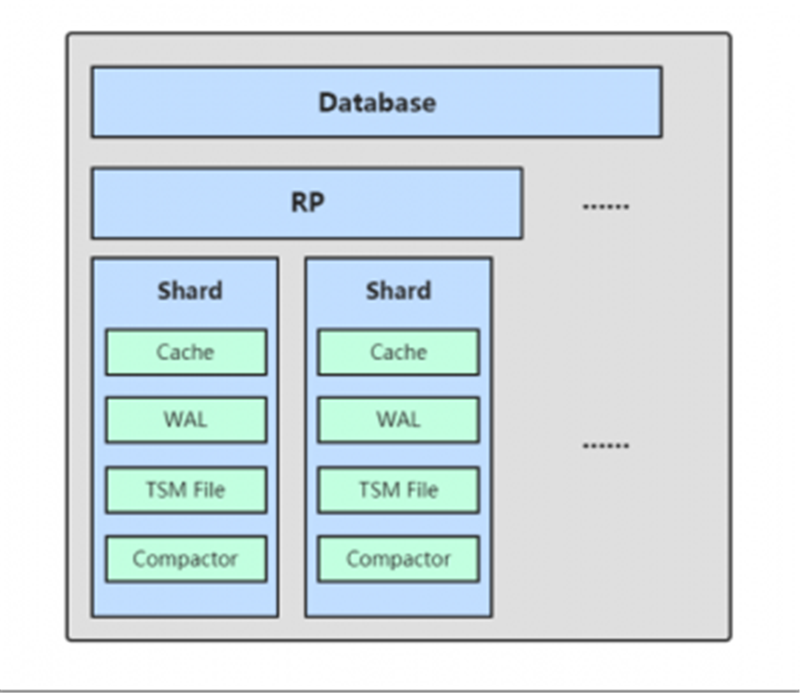
p6-Influxdb TSM结构图(注2)
Kairosdb:
底层使用Cassandra作为分布式存储引擎,如上文提到单机上采用的是LSM tree。
Cassandra有两级索引:partition key和clustering key。其中partition key是其分片ID,使用的是一致性哈希;而clustering key在一个partition key中保证有序。
Kairosdb利用Cassandra的特性,将++<数据类型>+作为partition key,数据点时间在timestamp上的偏移作为clustering key,其有序性方便做基于时间范围的查询。
partition key中的timestamp是3周对齐的,也就是说21天的时序数据会在一个clustering key下。3周的毫秒数是18亿正好小于Cassandra每行列数20亿的限制。
OpenTsdb:
底层使用Hbase作为其分布式存储引擎,采用的也是LSM tree。
Hbase采用范围划分的分片方式。使用row key做分片,保证其全局有序。每个row key下可以有多个column family。每个column family下可以有多个column。

上图是OpenTsdb的row key组织方式。不同于别的时序数据库,由于Hbase的row key全局有序,所以增加了可选的salt以达到更好的数据分布,避免热点产生。再由与timestamp间的偏移和数据类型组成column qualifier。
他的timestamp是小时对齐的,也就是说一个row key下最多存储一个小时的数据。并且需要将构成row key的metric和tags都转成对应的uid来减少存储空间,避免Hfile索引太大。下图是真实的row key示例。

p7-open tsdb的row key示例(注3)
7. 结束语
可以看到各分布式时序数据库虽然存储方案都略有不同,但本质上是一致的,由于时序数据写多读少的场景,在单机上采用更加适合大吞吐量写入的单机存储结构,而在分布式方案上根据时序数据的特点来精心设计,目标就是设计的分片方案能方便时序数据的写入和读取,同时使数据分布更加均匀,尽量避免热点的产生。
数据存储是时序数据库设计中很小的一块内容,但也能管中窥豹,看到时序数据库从设计之初就要考虑时序数据的特点。后续我们会从其他的角度进行讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号