
rocketmq-消息存储结构
参考:
https://blog.csdn.net/GAMEloft9/article/details/100562191
https://blog.csdn.net/meilong_whpu/article/details/76919267
https://www.cnblogs.com/fanguangdexiaoyuer/p/10496112.html
RocketMQ消息存储结构简介--CommitLog
RocketMQ消息存储是整个系统的核心,直接决定着吞吐性能和高可用性。RocketMQ存储消息并没有借助oracle、mysql等关系型数据库,而是直接操作文件。借助java NIO的力量,使得I/O性能十分高。当消息来的时候,顺序写入CommitLog。为了Consumer消费消息的时候,能够方便的根据topic查询消息,在CommitLog的基础上衍生出了CosumerQueue文件,存放了某topic的消息在CommitLog中的偏移位置。此外为了支持根据消息key查询消息,还构建了index文件。这三个文件(逻辑上是三个),就是RocketMQ的主要存储内容,大致结构如下图所示(图片来自书籍《RocketMQ技术内幕》):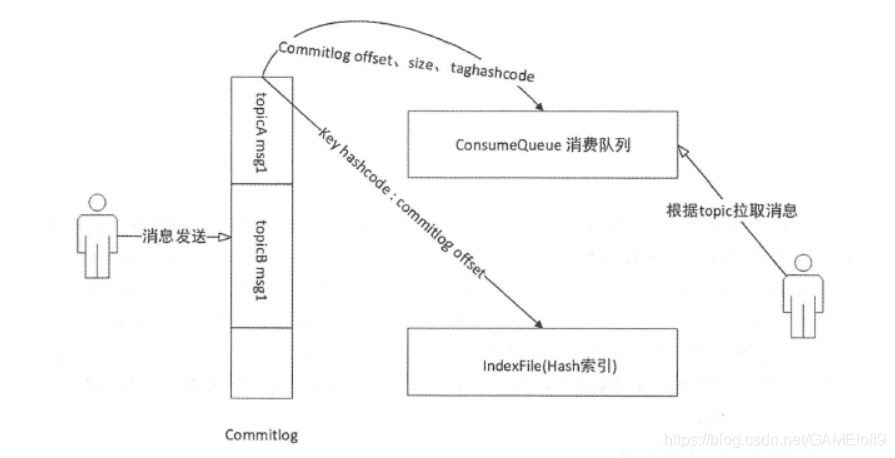
限于篇幅,这篇文章仅介绍CommitLog相关的一些东西。
CommitLog类、MappedFileQueue、MappedFile
CommitLog名字取得非常好,除了消息本身,它记录了消息的方方面面的信息,通过一条CommitLog我们可以还原出很多东西。例如消息是何时、由哪个producer发送的,被发送到了哪个消息队列,属于哪个topic,有哪些属性等等。RokcetMQ存储的消息其实存储的就是这个CommitLog记录。后面的叙述中,如果没有特别说明,我们可以将CommitLog记录等同于消息,而CommitLog特指存储消息的文件。
CommitLog类如下所示:
public class CommitLog {
// Message's MAGIC CODE daa320a7
public final static int MESSAGE_MAGIC_CODE = 0xAABBCCDD ^ 1880681586 + 8;
// End of file empty MAGIC CODE cbd43194
private final static int BLANK_MAGIC_CODE = 0xBBCCDDEE ^ 1880681586 + 8;
private final MappedFileQueue mappedFileQueue; // 存放的文件队列
// 省略代码
}
CommitLog类属性很多,但是最重要的是mappedFileQueue属性。之前我们一直说消息最终存储在CommitLog里,实际上CommitLog是一个逻辑上的概念。真正的文件是一个个MappedFile,然后组成了mappedFileQueue。一个MappedFile最多能存放1G的CommitLog,这个大小在MessageStoreConfi类里面定义了的:
当一个MappedFile写满了之后,就会创建第二MappedFile,然后继续存CommitLog,如下所示:
MappedFileQueue是存放MappedFile的队列结构,如下所示:
public class MappedFileQueue {
private static final int DELETE_FILES_BATCH_MAX = 10;
private final String storePath; // 文件存储路径,例如/home/gameloft9/store/commitlog
private final int mappedFileSize; // 单个MappedFile大小,默认1G
private final CopyOnWriteArrayList<MappedFile> mappedFiles = new CopyOnWriteArrayList<MappedFile>(); // mappedFile列表
private final AllocateMappedFileService allocateMappedFileService; // 分配mappedFile的service
// 省略代码
}
MappedFileQueue存放了一个个MappedFile,然后还记录了一些额外的信息,例如存储文件路径、单个MappedFile大小等等。
下面我们再来看MappedFile的结构:
public class MappedFile extends ReferenceResource {
protected int fileSize;
protected FileChannel fileChannel; // 读写通道
/**
* Message will put to here first, and then reput to FileChannel if writeBuffer is not null.
*/
protected ByteBuffer writeBuffer = null; // 缓冲区,使用的是直接堆外内存
private String fileName;
private File file;
private MappedByteBuffer mappedByteBuffer; // 内存映射
}
如果之前没有接触过FileChannel、ByteBuffer、MappedByteBuffer,可以先补习一下这篇文章:ByteBuffer介绍
writeBuffer使用的是堆外内存,mappedByteBuffer是直接将文件映射到内存中,两者的使用是互斥的。如果启用了临时缓冲池(默认不启用),那么就会使用writeBuffer写commitlog,否则就是mappedBtyeBuffer写commitlog。
CommitLog、MappedFileQueue和MappedFile的大致关系如下所示: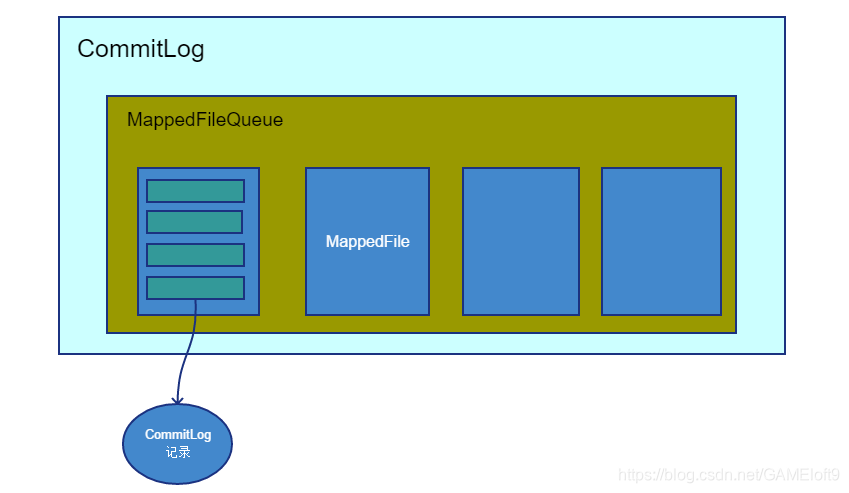
CommitLog记录
一条CommitLog记录包括哪些内容呢?CommitLog要实现的功能,决定了它需要存储哪些内容。首先要实现消息的存储,肯定需要把消息存下来。其次,为了方便创建ConsumerQueue,需要记录topic、queueId等信息。为了能跟踪消息,需要记录消息发送方地址、发送时间等。。。
完整的CommitLog记录如下所示: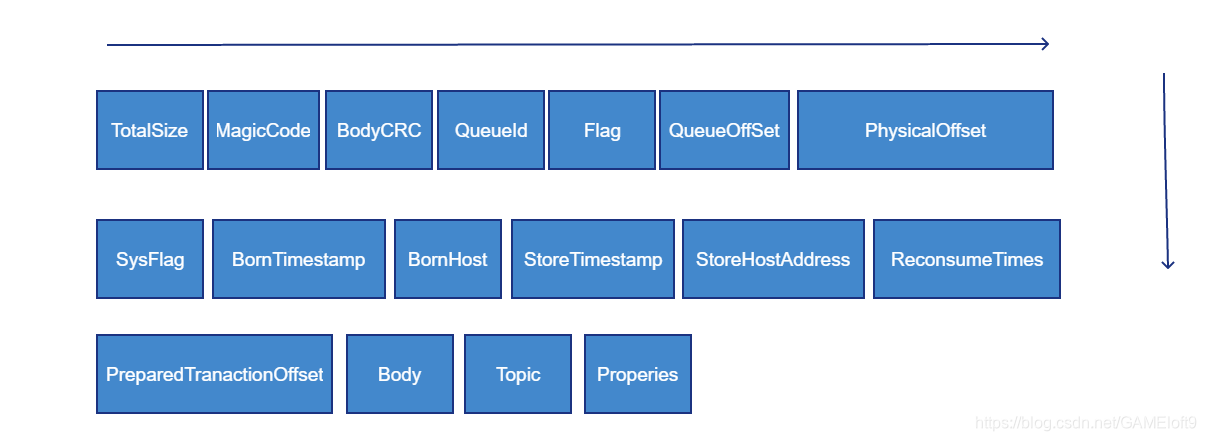
为什么会先跳过消息存储流程先讲存储内容结构呢?因为流程实在是太复杂、内容太多了,很容易晕头转向。如果先对存储的内容有一个大致的概念,后面再理解消息存储过程会好很多。骨头难啃,总要挑一处简单的下嘴嘛。下面从功能上解释为什么要存这些字段。不了解整个流程,理解这些字段也会有些困难,我会尽量保证通俗易懂。
TotalSize
TotalSize很好理解,就是整个CommitLog记录的大小,包括上面列出来的所有字段大小。TotalSize占用4个字节,在往byteBuffer写CommitLog的时候,首先就会写入这个CommitLog大小,如下所示:
// 1 TOTALSIZE
this.msgStoreItemMemory.putInt(msgLen);
MagicCode
MagicCode是一个特殊的字段,它可以标志ByteBuffer中的某个CommitLog是一个正常的CommitLog,还是因为ByteBuffer没有多余的空间存放该CommitLog,导致该CommitLog是一个空的CommitLog。
MagicCode有两个值,如下所示:
// Message's MAGIC CODE daa320a7
public final static int MESSAGE_MAGIC_CODE = 0xAABBCCDD ^ 1880681586 + 8;
// End of file empty MAGIC CODE cbd43194
private final static int BLANK_MAGIC_CODE = 0xBBCCDDEE ^ 1880681586 + 8;
MESSAGE_MAGIC_CODE表明该CommitLog记录是一条正常的记录,BLANK_MAGIC_CODE表明该CommitLog记录是一个空的CommitLog记录。
如果存储CommitLog发现空间不够,会马上开辟第二个文件重新存储CommitLog记录,但是之前的空的CommitLog也一样会保存下来。在Broker正常退出或者异常退出,重启之后需要恢复Broker的时候,就会根据这个MagicCode判断该条CommitLog是否是正常的。
BodyCRC
学过计算机网络的人一定知道CRC,CRC即循环冗余校验码,是数据通信领域中最常用的一种查错校验码,通过CRC就可以知道数据的正确性和完整性。RocketMQ通过CRC来校验消息部分,如下所示:
if (checkCRC) {
int crc = UtilAll.crc32(bytesContent, 0, bodyLen);
if (crc != bodyCRC) {
log.warn("CRC check failed. bodyCRC={}, currentCRC={}", crc, bodyCRC);
return new DispatchRequest(-1, false/* success */);
}
}
queueId
queueId很熟悉的,就是消息发往哪个队列。queueId在producer发送消息时会选择出来,这个在文章RocketMQ发送消息时如何选择队列中已经很详细的讲过了,这里就不再赘述queueId是如何产生的了。
Topic下会有一堆消息队列(ConsumerQueue),RocketMQ在保存完消息后,会随后构建ConsumerQueue,里面存放着Topic下消息的在CommitLog文件中的偏移量,方便根据Topic查询消费消息。ConsumerQueue的构建、消息的消费都是重点内容,会在单独的文章中进行介绍。
Flag
暂时不知道有什么用,默认值是0。
QueueOffset
我们之前讲过,为了方便Consumer能根据Topic快速的查询消息,在CommitLog的基础上构建了ConsumerQueue,里面存放了某个Topic下面的所有消息在CommitLog中的位置。
同样的,这里的QueueOffset存放了消息记录应该在ConsumerQueue中的位置,这样构建ConsumerQueue的时候,就知道该条记录在ConsummerQueue的位置顺序,在消费消息的时候很有用处。QueueOffset一般是是累加1的,如下所示:
case MessageSysFlag.TRANSACTION_COMMIT_TYPE:
// The next update ConsumeQueue information
CommitLog.this.topicQueueTable.put(key, ++queueOffset);
break;
这个与ConsumerQueue的存储结构有关,后面介绍ConsumerQueue存储结构的时候会涉及到。
PhysicalOffset
这个很简单了,就是消息在CommitLog中的物理位置。需要注意的是,我们CommitLog对应着磁盘上的多个文件,这里的偏移量不是从某个文件开始算的,而是从第一个文件偏移开始算起的。
SysFlag
SysFlag是RocketMQ内部使用的标记位,通过位运算进行标记。例如是否对消息进行了压缩、是否属于事务消息。SysFlag初始值为0,可与下面的标记进行位运算。
public final static int COMPRESSED_FLAG = 0x1;
public final static int MULTI_TAGS_FLAG = 0x1 << 1; // 2
public final static int TRANSACTION_NOT_TYPE = 0; // 不参与位运算,用作结果比较,表示无事务
public final static int TRANSACTION_PREPARED_TYPE = 0x1 << 2; // 4
public final static int TRANSACTION_COMMIT_TYPE = 0x2 << 2; // 8
public final static int TRANSACTION_ROLLBACK_TYPE = 0x3 << 2; // 12
例如对消息进行了压缩,那么SysFlag = 0 | 0x1。又例如flag & TRANSACTION_ROLLBACK_TYPE,可以判断消息是否是事务消息,如果等于0说明不是事务消息。BornTimestamp
Producer发送消息的时间,如下所示:
requestHeader.setBornTimestamp(System.currentTimeMillis());
BornHost
Producer发送消息使用的套接字地址
msgInner.setBornHost(ctx.channel().remoteAddress());
CommitLog存的时候是读取4个字节的rao ip + 4个字节的端口号:
byteBuffer.put(inetSocketAddress.getAddress().getAddress(), 0, 4);
byteBuffer.putInt(inetSocketAddress.getPort());
StoreTimestamp
消息在broker上存储时间。
StoreHostAddress
Broker的套接字地址,存储方式同BornHost。
ReconsumeTimes
重复消费次数,初始为0。我们消费消息的时候,如果发生异常,可以选择晚一点重新消费,如下所示:
consumer.registerMessageListener(new MessageListenerConcurrently() {
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try{
for(MessageExt msg : msgs){
if(msg.getTopic().equals("test")){
log.info("收到test类型消息:" + new String(msg.getBody()));
}
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; // 消费成功
}catch(Exception e){
return ConsumeConcurrentlyStatus.RECONSUME_LATER; // 稍后重新消费
}
}
});
Broker重试的时候,这个ReconsumeTimes就会+1,默认最大重试次数是16次。
PreparedTransactionOffset
事务消息相关的一个属性。RocketMQ事务消息基于两阶段提交,这里仅仅了解一点就够了,涉及到事务消息的时候会再提到。
Body
消息体,没什么好说的。需要注意的是,Body前面其实会有4字节(int)的Body长度,这里没有画出来。
Topic
主题,没什么好说的。需要注意的是,Topic前面其实会有1字节(byte)的Topic长度,这里没有画出来。
Properties
消息属性。需要注意的是,Properties前面其实会有2字节(short)的Properties长度,这里没有画出来。
Properties既存放了RocketMQ内部用到的一些属性,也存放了用户的一些属性。例如发送消息的TAG就存放在Properties里面:
Message msg = new Message("test",// topic
"TagB",// tag就会存放在Properties里面
("我发了一条消息").getBytes());// body
Properties中的一些常用key都定义在了MessageConstant里面,如下所示:
public class MessageConst {
public static final String PROPERTY_KEYS = "KEYS";
public static final String PROPERTY_TAGS = "TAGS";
public static final String PROPERTY_WAIT_STORE_MSG_OK = "WAIT";
public static final String PROPERTY_DELAY_TIME_LEVEL = "DELAY";
public static final String PROPERTY_RETRY_TOPIC = "RETRY_TOPIC";
public static final String PROPERTY_REAL_TOPIC = "REAL_TOPIC";
public static final String PROPERTY_REAL_QUEUE_ID = "REAL_QID";
public static final String PROPERTY_TRANSACTION_PREPARED = "TRAN_MSG";
public static final String PROPERTY_PRODUCER_GROUP = "PGROUP";
public static final String PROPERTY_MIN_OFFSET = "MIN_OFFSET";
public static final String PROPERTY_MAX_OFFSET = "MAX_OFFSET";
public static final String PROPERTY_BUYER_ID = "BUYER_ID";
public static final String PROPERTY_ORIGIN_MESSAGE_ID = "ORIGIN_MESSAGE_ID";
public static final String PROPERTY_TRANSFER_FLAG = "TRANSFER_FLAG";
public static final String PROPERTY_CORRECTION_FLAG = "CORRECTION_FLAG";
public static final String PROPERTY_MQ2_FLAG = "MQ2_FLAG";
public static final String PROPERTY_RECONSUME_TIME = "RECONSUME_TIME";
public static final String PROPERTY_MSG_REGION = "MSG_REGION";
public static final String PROPERTY_TRACE_SWITCH = "TRACE_ON";
public static final String PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX = "UNIQ_KEY";
public static final String PROPERTY_MAX_RECONSUME_TIMES = "MAX_RECONSUME_TIMES";
public static final String PROPERTY_CONSUME_START_TIMESTAMP = "CONSUME_START_TIME";
}
小结
通过了解CommitLog记录的一些属性,可以帮助我们更好的了解RocketMQ消息存储、消费的一些细节。
RocketMQ存储篇——CommitLog
CommitLog
commitlog文件的存储地址:$HOME\store\commitlog\${fileName},每个文件的大小默认1G =1024*1024*1024,commitlog的文件名fileName,名字长度为20位,左边补零,剩余为起始偏移量;比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当这个文件满了,第二个文件名字为00000000001073741824,起始偏移量为1073741824,以此类推,第三个文件名字为00000000002147483648,起始偏移量为2147483648
消息存储的时候会顺序写入文件,当文件满了,写入下一个文件。
文件的消息单元存储结构
| 顺序编号 | 字段简称 | 字段大小(字节) | 字段含义 |
|---|---|---|---|
| 1 | msgSize | 4 | 代表这个消息的大小 |
| 2 | MAGICCODE | 4 | MAGICCODE = daa320a7 |
| 3 | BODY CRC | 4 | 消息体BODY CRC 当broker重启recover时会校验 |
| 4 | queueId | 4 | |
| 5 | flag | 4 | |
| 6 | QUEUEOFFSET | 8 | 这个值是个自增值不是真正的consume queue的偏移量,可以代表这个consumeQueue队列或者tranStateTable队列中消息的个数,若是非事务消息或者commit事务消息,可以通过这个值查找到consumeQueue中数据,QUEUEOFFSET * 20才是偏移地址;若是PREPARED或者Rollback事务,则可以通过该值从tranStateTable中查找数据 |
| 7 | PHYSICALOFFSET | 8 | 代表消息在commitLog中的物理起始地址偏移量 |
| 8 | SYSFLAG | 4 | 指明消息是事物事物状态等消息特征,二进制为四个字节从右往左数:当4个字节均为0(值为0)时表示非事务消息;当第1个字节为1(值为1)时表示表示消息是压缩的(Compressed);当第2个字节为1(值为2)表示多消息(MultiTags);当第3个字节为1(值为4)时表示prepared消息;当第4个字节为1(值为8)时表示commit消息;当第3/4个字节均为1时(值为12)时表示rollback消息;当第3/4个字节均为0时表示非事务消息; |
| 9 | BORNTIMESTAMP | 8 | 消息产生端(producer)的时间戳 |
| 10 | BORNHOST | 8 | 消息产生端(producer)地址(address:port) |
| 11 | STORETIMESTAMP | 8 | 消息在broker存储时间 |
| 12 | STOREHOSTADDRESS | 8 | 消息存储到broker的地址(address:port) |
| 13 | RECONSUMETIMES | 8 | 消息被某个订阅组重新消费了几次(订阅组之间独立计数),因为重试消息发送到了topic名字为%retry%groupName的队列queueId=0的队列中去了,成功消费一次记录为0; |
| 14 | PreparedTransaction Offset | 8 | 表示是prepared状态的事物消息 |
| 15 | messagebodyLength | 4 | 消息体大小值 |
| 16 | messagebody | bodyLength | 消息体内容 |
| 17 | topicLength | 1 | topic名称内容大小 |
| 18 | topic | topicLength | topic的内容值 |
| 19 | propertiesLength | 2 | 属性值大小 |
| 20 | properties | propertiesLength | propertiesLength大小的属性数据 |
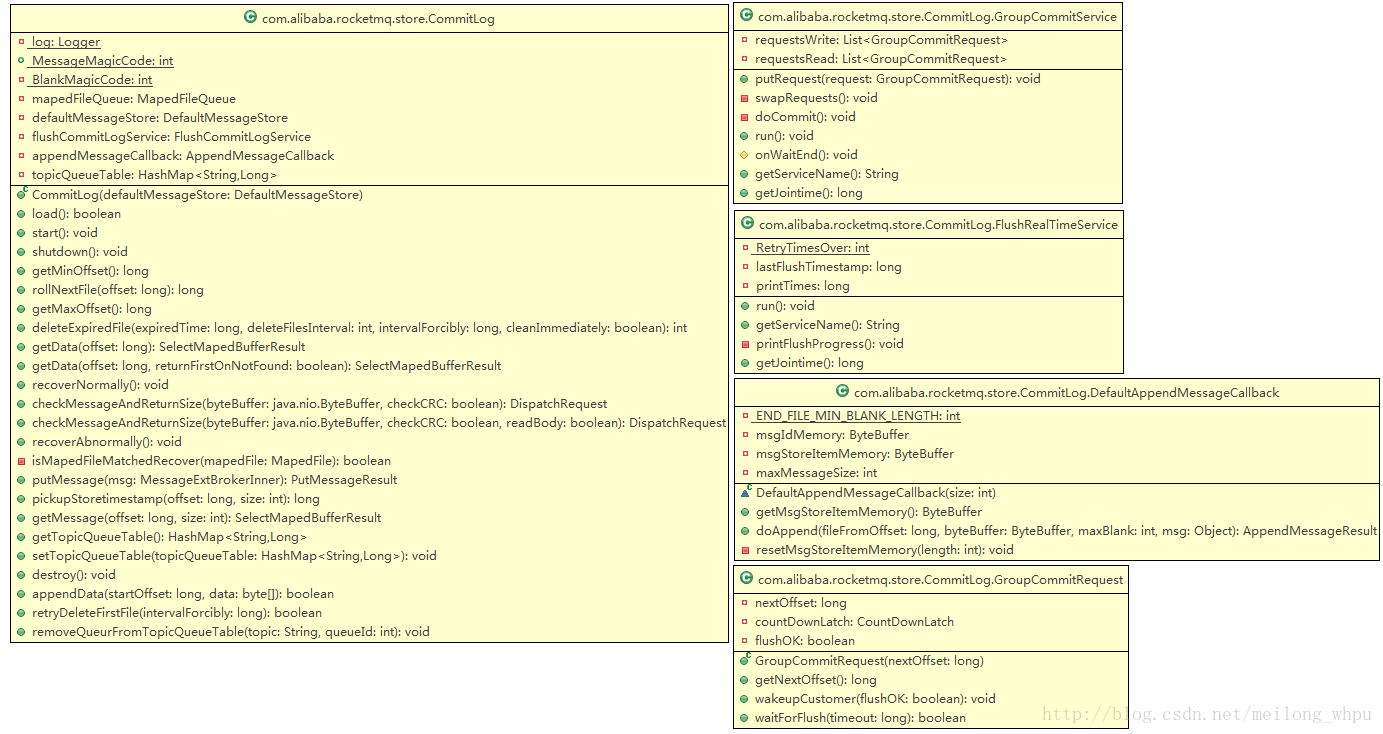
CommitLog类结构
功能清单如下:
获取最小Offset(getMinOffset)
从MapedFileQueue中获取第一个MapedFile对象(即第一个文件),若该文件可用(MapedFile对象的availabe变量值)则返回该对象的fileFromOffset值,若不可用,则取下一个文件的起始偏移量,计算方式为:fileFromOffset值+文件的固定大小1G-fileFromOffset%1G。fileFromOffset%1G一般情况下为0。
获取最大物理偏移量(getMaxOffset)
调用MapedFileQueue类的方法获取在MapedFile队列中的最大Offset值,即为当前写入消息的最大位置。
读取指定起始位置offset所在文件的全部剩余消息(getData)
调用MapedFileQueue的findMapedFileByOffset方法取指定起始位置offset所在的文件对应的MapedFile对象。然后计算在该文件内部的起始位置,由于参数中的指定起始位置是从第一个文件开始位置算起的,针对文件内部的起始位置应该是offset%fileSize。最后调用MapedFile对象的selectMapedBuffer方法获取该文件中从起始位置开始的所有剩余信息。
正常恢复CommitLog内存数据(recoverNormally)
主要是恢复MapedFileQueue对象的commitedWhere变量值(即刷盘的位置),删除该commitedWhere值所在文件之后的commitlog文件以及对应的MapedFile对象。
在Broker启动过程中会调用该方法。从MapedFileQueue的MapedFile列表的倒数第三个对象(即倒数第三个文件)开始遍历每块消息单元,若总共没有三个文件,则从第一个文件开始遍历每块消息单元。
首先,每次读取到消息单元块之后,进行CRC的校验,在校验过程中,若检查到第5至8字节MAGICCODE字段等于BlankMagicCode(cbd43194)则返回msgSize=0的DispatchRequest对象;若校验未通过或者读取到的信息为空则返回msgSize=-1的DispatchRequest对象;否则返回msgSize等于第1个4字节的msgSize字段值的DispatchRequest对象。
对于msgSize大于零,则读取的偏移量mapedFileOffset累加msgSize;若等于零,则表示读取到了文件的最后一块信息,则继续读取下一个MapedFile对象的文件;直到消息的CRC校验未通过或者读取完所有信息为止。
计算有效信息的最后位置processOffset,计算方式为:取最后读取的MapedFile对象的fileFromOffset加上最后读取的位置mapedFileOffset值。
最后更新内存中的对象数据信息:设置MapedFileQueue对象的commitedWhere等于processOffset;调用truncateDirtyFiles方法将processOffset所在文件之后的文件全部清理掉,并且将所在文件对应的MapedFile对象的wrotepostion和commitPosition设置为processOffset%fileSize,即等于mapedFileOffset值。
异常恢复CommitLog内存数据(recoverAbnormally)
在Broker启动过程中会调用该方法。与正常恢复的区别在于:正常恢复是从倒数第3个文件开始恢复;而异常恢复是从最后的文件开始往前寻找与checkpoint文件的记录相匹配的一个文件。
首先,若该MapedFile队列为空,则MapedFileQueue对象的commitedWhere等于零,并且调用DefaultMessageStore.destroyLogics() 方法删除掉逻辑队列consumequeue中的物理文件以及清理内存数据。否则从MapedFileQueue的MapedFile列表找到从哪个文件(对应的MapedFile对象)开始恢复数据,查找逻辑如下:
1、从MapedFile列表中的最后一个对象开始往前遍历每个MapedFile对象,检查该MapedFile对象对应的文件是否满足恢复条件,查找逻辑如下,若查找完整个队列未找到符合条件的MapedFile对象,则从第一个文件开始恢复。
A)从该文件中获取第一个消息单元的第5至8字节的MAGICCODE字段,若该字段等于MessageMagicCode(即不是正常的消息内容),则直接返回后继续检查前一个文件;
B)获取第一个消息单元的第56位开始的8个字节的storeTimeStamp字段,若等于零,也直接返回后继续检查前一个文件;
C)检查是否开启消息索引功能(MessageStoreConfig .messageIndexEnable,默认为true)并且是否使用安全的消息索引功能(MessageStoreConfig. MessageIndexSafe,默认为false,在可靠模式下,异常宕机恢复慢;非可靠模式下,异常宕机恢复快),若开启可靠模式下面的消息索引,则消息的storeTimeStamp字段表示的时间戳必须小于checkpoint文件中物理队列消息时间戳、逻辑队列消息时间戳、索引队列消息时间戳这三个时间戳中最小值,才满足恢复数据的条件;否则消息的storeTimeStamp字段表示的时间戳必须小于checkpoint文件中物理队列消息时间戳、逻辑队列消息时间戳这两个时间戳中最小值才满足恢复数据的条件;
2、从找到的MapedFile对象开始往后开始遍历每个文件的消息单元,首先,每次读取到消息单元块之后,进行CRC的校验,在校验过程中,若检查到第5至8字节MAGICCODE字段等于BlankMagicCode(cbd43194)则返回msgSize=0的DispatchRequest对象;若校验未通过或者读取到的信息为空则返回msgSize=-1的DispatchRequest对象;否则返回msgSize等于第1个4字节的msgSize字段值的DispatchRequest对象。
对于msgSize大于零,则读取的偏移量mapedFileOffset累加msgSize,并将DispatchRequest对象放入DefaultMessageStore.DispatchMessageService服务线程中,由该线程在后台进行ConsumeQueue队列和Index服务的数据加载;若等于零,则表示读取到了文件的最后一块信息,则继续读取下一个MapedFile对象的文件;直到消息的CRC校验未通过或者读取完所有信息为止。
计算有效信息的最后位置processOffset,计算方式为:取最后读取的MapedFile对象的fileFromOffset加上最后读取的位置mapedFileOffset值。
3、更新内存中的对象数据信息:设置MapedFileQueue对象的commitedWhere等于processOffset;调用MapedFileQueue.truncateDirtyFiles方法将processOffset所在文件之后的文件全部清理掉,并且将所在文件对应的MapedFile对象的wrotepostion和commitPosition设置为processOffset%fileSize,即等于mapedFileOffset值。
4、调用DefaultMessageStore.truncateDirtyLogicFiles(long processOffset) 方法,在该方法中遍历DefaultMessageStore.consumeQueueTable的values值(即ConcurrentHashMap<Integer/* queueId */,ConsumeQueue>),对于调用每个ConsumeQueue对象的truncateDirtyLogicFiles(long processOffset)方法,该方法根据物理偏移值processOffset删除无效的逻辑文件。
写入消息(putMessage)
在Broker接受到生产者的消息之后,会间接的调用CommitLog.putMessage(MessageExtBrokerInner msg)方法完成消息的写入操作。具体逻辑如下:
1、获取消息的sysflag字段,检查消息是否是非事务性(第3/4字节为0)或者提交事务(commit,第4字节为1,第3字节为0)消息,若是,再从消息properties属性中获取"DELAY"参数(该参数在应用层通过Message.setDelayTimeLevel(int level)方法设置,消息延时投递时间级别,0表示不延时,大于0表示特定延时级别)属性的值(即延迟级别),若该值大于0,则将此消息设置为定时消息;即更改该消息为定时消息,更改如下信息:第一,将MessageExtBrokerInner对象的topic值更改为"SCHEDULE_TOPIC_XXXX",第二,根据延迟级别获取延时消息的队列ID(queueId等于延迟级别减去1)并更改queueId值;第三,将消息中原真实的topic和queueId存入消息属性中;第四,该延迟消息的consumequeue队列中的tagscode等于存储时间加上延迟级别对应的时长,若没有该延迟级别则将存储时间加上1000;
2、调用MapedFileQueue.getLastMapedFile方法获取或者创建最后一个文件(即MapedFile列表中的最后一个MapedFile对象),若还没有文件或者已有的最后一个文件已经写满则创建一个新的文件,即创建一个新的MapedFile对象并返回;
3、调用MapedFile.appendMessage(Object msg, AppendMessageCallback cb)方法将消息内容写入MapedFile.mappedByteBuffer:MappedByteBuffer对象,即写入消息缓存中;由后台服务线程定时的将缓存中的消息刷盘到物理文件中;
4、若最后一个MapedFile剩余空间不足够写入此次的消息内容,即返回状态为END_OF_FILE标记,则再次调用MapedFileQueue.getLastMapedFile方法获取新的MapedFile对象然后调用MapedFile.appendMessage方法重写写入,最后继续执行后续处理操作;若为PUT_OK标记则继续后续处理;若为其他标记则返回错误信息给上层;
5、初始化DispatchRequest对象,其中包括topic、queueID、wroteOffset(写入的开始物理位置)、wroteBytes(写入的大小)、logicsOffset(已经写入的消息块个数)、消息key值等;调用DefaultMessageStore.DispatchMessageService.putRequest(DispatchRequest dispatchRequest)将请求消息放入DispatchMessageService.requestsWrite队列中;由DispatchMessageService服务处理该请求;为请求中的信息创建consumequeue数据和index索引。
6、若该Broker是同步刷盘,并且消息的property属性中"WAIT"参数(该参数在应用层可以通过Message.setWaitStoreMsgOK(boolean waitStoreMsgOK)方法设置,表示是否等待服务器将消息存储完毕再返回(可能是等待刷盘完成或者等待同步复制到其他服务器))为空或者为TRUE,则利用GroupCommitService后台线程服务进行刷盘操作,具体步骤如下:
1)构建GroupCommitRequest对象,其中nextOffset变量的值等于wroteOffset(写入的开始物理位置)加上wroteBytes(写入的大小),表示下一次写入消息的开始位置;
2)将该对象存入GroupCommitService.requestsWrite写请求队列中,并唤醒GroupCommitService线程将写队列的数据与读队列的数据交互(读队列的数据肯定是空);
3)该线程的doCommit方法中遍历读队列的数据,检查MapedFileQueue.committedWhere(刷盘刷到哪里的记录)是否大于等于GroupCommitRequest.nextOffset,若是表示该请求消息表示nextOffset之前的消息已经被刷盘,否则调用CommitLog.MapedFileQueue.commit(int flushLeastPages) 进行刷盘操作;
4)用MapedFileQueue的存储时间戳storeTimestamp变量值(在MapedFileQueue.commit方法成功执行后更新)更新StoreCheckpoint.physicMsgTimestamp变量值(checkpoint文件内容中其中一个值);
5)清空读请求队列requestRead;
7、若该Broker为异步刷盘(ASYNC_FLUSH),唤醒FlushRealTimeService线程服务。在该线程的run方法处理逻辑如下:
1)若根据CommitLog刷盘间隔时间(默认是1秒)来间断性的调用CommitLog.MapedFileQueue.commit(int flushLeastPages)方法进行刷盘操作;
2)用MapedFileQueue的存储时间戳storeTimestamp变量值(在MapedFileQueue.commit方法成功执行后更新)更新StoreCheckpoint.physicMsgTimestamp变量值(checkpoint文件内容中其中一个值);
8、若该Broker为同步双写主用(SYNC_MASTER),并且消息的property属性中"WAIT"参数为空或者为TRUE,则等待监听主Broker将数据同步到从Broker的结果,若同步失败,则置PutMessageResult对象的putMessageStatus变量为FLUSH_SLAVE_TIMEOUT,监测方法如下:
1)检查主从数据传输是否正常。备用连接是否大于0,主用put的位置masterPutwhere等于wroteOffset(写入的开始物理位置)加上wroteBytes(写入的大小),masterPutwhere减去HAService.push2SlaveMaxOffset(写入到Slave的最大Offset)的差值不能大于256M,否则视为主备同步异常,置PutMessageResult对象的putMessageStatus变量为SLAVE_NOT_AVAILABLE;
2)若主备同步正常,则利用wroteOffset(写入的开始物理位置)加上wroteBytes(写入的大小)的值为参数构建GroupCommitRequest对象,即该对象的nextOffset值等于wroteOffset+wroteBytes;然后调用HAService.GroupTransferService.putRequest(GroupCommitRequest request)方法将请求对象放入 GroupTransferService服务的队列中,用于监听是否同步完成;再调用GroupCommitRequest.waitForFlush(long timeout)方法,该方法一直处于阻塞状态,直到HAService线程服务完成同步工作或者超时才返回结果;若GroupCommitRequest对象的flushOK变量为true则表示同步成功了,在GroupTransferService服务线程中判断是否同步完成的方法是用该对象中的nextOffset值与HAService.push2SlaveMaxOffset比较。
9、返回PutMessageResult对象;若上诉都成功则该对象的putMessageStatus变量为PUT_OK;
读取消息(getMessage)
该方法的入参有两个:读取的起始偏移量offset和读取的大小size。首先调用findMapedFileByOffset方法根据起始偏移量offset所在的MapedFile对象;然后调用MapedFile对象的selectMapedBuffer方法获取从offset开始的size大小的消息内容;由于offset是commitlog文件的全局偏移量,要以offset%mapedFileSize的余数作为单个文件的起始读取位置传入selectMapedBuffer方法中。
指定位置开始写入二进制消息(appendData)
根据入参中的指定位置startOffset值调用getLastMapedFile方法获取最后一个MapedFile对象,若MapedFile队列为空则以startOffset为起始偏移量创建新的文件(即新的MapedFile对象)。然后调用MapedFile对象的appendMessage(final byte[] data)方法将二进制消息写入缓存中。
获取指定位置所在文件的下一个文件的起始偏移量(rollNextFile)
调用rollNextFile(long offset)方法,获取该入参的偏移量所在文件的下一个文件的起始偏移量,算法如下:offset+mapedFileSzie-offset% mapedFileSzie
DefaultAppendMessageCallback类的实现
该类实现了AppendMessageCallback回调类的doAppend(final long fileFromOffset, final ByteBuffer byteBuffer,final int maxBlank, final Object msg)方法,该顺序写方法的具体逻辑如下:
1)获取当前内存对象的写入位置(wrotePostion变量值);若写入位置没有超过文件大小则继续顺序写入;
2)由内存对象mappedByteBuffer创建一个指向同一块内存的ByteBuffer对象,并将内存对象的写入指针指向写入位置;
3)以文件的起始偏移量(fileFromOffset)、ByteBuffer对象、该内存对象剩余的空间(fileSize-wrotePostion)、消息对象msg为参数调用AppendMessageCallback回调类的doAppend方法;
3.1)根据broker的ip+port和在整个commitlog上开始位置(fileFromOffset+wrotepostion)生成16个字节的消息ID(messageId);
3.2)根据消息的"topic-queueid"作为key值在CommitLog. topicQueueTable中获取values值(即为queueoffset值),若没有则置为0并以此"topic-queueid"作为key值存入topicQueueTable中;
3.3)通过参数sysflag的标志位判断消息类型,若是PREPARED事务,则取TransactionStateService.tranStateTableOffset变量值(DefaultMessageStore中初始化的TransactionStateService对象)赋值给queueoffset临时变量;若是ROLLBACK事务,则取消息中的queueoffset值赋值给临时变量queueoffset;
3.4)根据消息对象msg计算消息的总长度,若总长度大于消息长度的最大值(MessageStoreConfig.maxMessageSize指定,默认为512K)则返回由status= MESSAGE_SIZE_EXCEEDED 初始化的AppendMessageResult对象;若总长度加上文件末尾剩余的空格8字节的值大于该内存对象剩余的空间,则将剩余的空间用空格填满,即向内存对象中写入剩余空间大小、结尾文件MAGICCODE(cbd43194),内存对象剩余的部分填充空格,并返回由status=END_OF_FILE、写入的字节数(等于剩余空间大小)、消息ID、queueoffset初始化的AppendMessageResult对象;
3.5)将消息内容按照commitlog规定的格式先写入DefaultAppendMessageCallback对象创建的内存对象msgIdMemory中,然后在整体复制到MapedFile的内存对象mappedByteBuffer中,返回由status=PUT_OK、写入的字节数(等于剩余空间大小)、消息ID、queueoffset初始化的AppendMessageResult对象;
3.6)若非事务性或者提交事务消息,在写入完成之后将对应的values值加1;若是PREPARED事务,则将TransactionStateService.tranStateTableOffset变量值加1,该变量值表示在statetable文件中的消息个数;
4)将MapedFile.wrotePostion的值加上写入的字节数(AppendMessageResult对象返回的值);
5)更新存储时间戳MapedFile.storeTimestamp ;
RocketMQ消息存储
存储架构
RMQ存储架构
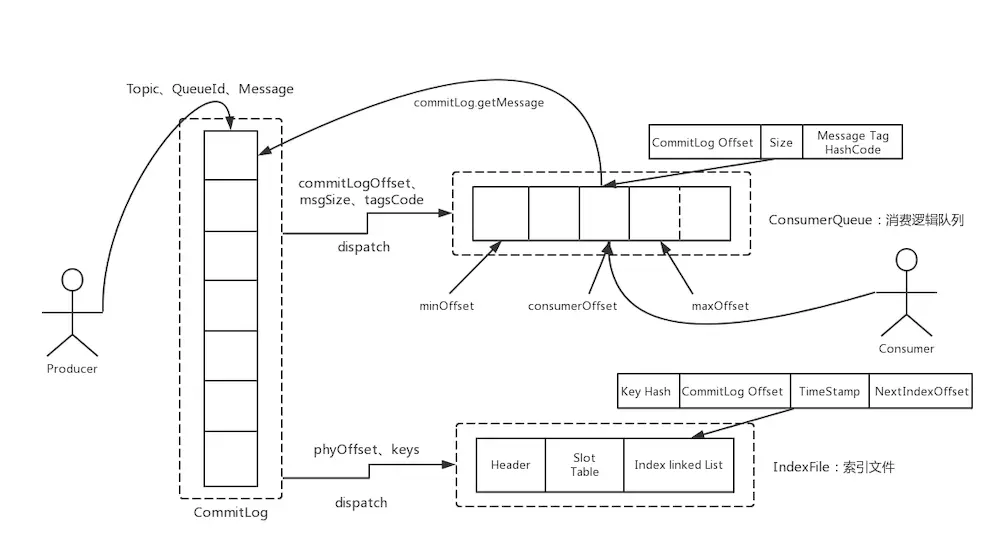
上图即为RocketMQ的消息存储整体架构,RocketMQ采用的是混合型的存储结构,即为Broker单个实例下所有的队列共用一个日志数据文件(即为CommitLog,1G)来存储。
Consume Queue相当于kafka中的partition,是一个逻辑队列,存储了这个Queue在CommiLog中的起始offset,log大小和MessageTag的hashCode。
每次读取消息队列先读取consumerQueue,然后再通过consumerQueue去commitLog中拿到消息主体。
Kafka存储架构
rocketMQ的设计理念很大程度借鉴了kafka,所以有必要介绍下kafka的存储结构设计:
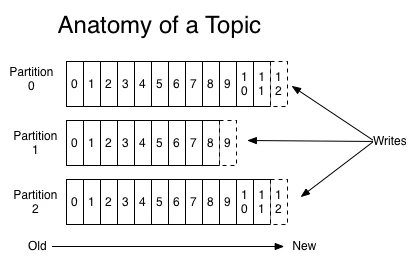
存储特点: 和RocketMQ类似,每个Topic有多个partition(queue),kafka的每个partition都是一个独立的物理文件,消息直接从里面读写。
根据之前阿里中间件团队的测试,一旦kafka中Topic的partitoin数量过多,队列文件会过多,会给磁盘的IO读写造成很大的压力,造成tps迅速下降。
所以RocketMQ进行了上述这样设计,consumerQueue中只存储很少的数据,消息主体都是通过CommitLog来进行读写。
ps:上一行加粗理解:consumerQueue存储少量数据,即使数量很多,但是数据量不大,文件可以控制得非常小,绝大部分的访问还是Page Cache的访问,而不是磁盘访问。正式部署也可以将CommitLog和consumerQueue放在不同的物理SSD,避免多类文件进行IO竞争。
RMQ存储设计优缺点
优点:
队列轻量化,单个队列数据量非常少。对磁盘的访问串行化,避免磁盘竟争,不会因为队列增加导致IOWAIT增高。
缺点:
写虽然完全是顺序写,但是读却变成了完全的随机读。
读一条消息,会先读ConsumeQueue,再读CommitLog,增加了开销。
要保证CommitLog与ConsumeQueue完全的一致,增加了编程的复杂度。
缺点克服:
随机读,尽可能让读命中page cache,减少IO读操作,所以内存越大越好。如果系统中堆积的消息过多,读数据要访问磁盘会不会由于随机读导致系统性能急剧下降,答案是否定的。
访问page cache 时,即使只访问1k的消息,系统也会提前预读出更多数据,在下次读时,就可能命中内存。
随机访问Commit Log磁盘数据,系统IO调度算法设置为NOOP方式,会在一定程度上将完全的随机读变成顺序跳跃方式,而顺序跳跃方式读较完全的随机读性能会高5倍以上。
另外4k的消息在完全随机访问情况下,仍然可以达到8K次每秒以上的读性能。
由于Consume Queue存储数据量极少,而且是顺序读,在PAGECACHE预读作用下,Consume Queue的读性能几乎与内存一致,即使堆积情况下。所以可认为Consume Queue完全不会阻碍读性能。
Commit Log中存储了所有的元信息,包含消息体,类似于Mysql、Oracle的redolog,所以只要有Commit Log在,Consume Queue即使数据丢失,仍然可以恢复出来。
RMQ存储底层实现
MappedByteBuffer
RocketMQ中的文件读写主要就是通过MappedByteBuffer进行操作,来进行文件映射。利用了nio中的FileChannel模型,可以直接将物理文件映射到缓冲区,提高读写速度。
这种Mmap的方式减少了传统IO将磁盘文件数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销。
这里需要注意的是,采用MappedByteBuffer这种内存映射的方式有几个限制,其中之一是一次只能映射1.5~2G 的文件至用户态的虚拟内存,这也是为何RocketMQ默认设置单个CommitLog日志数据文件为1G的原因了。
page cache
刚刚提到的缓冲区,也就是之前说到的page cache。
通俗的说:pageCache是系统读写磁盘时为了提高性能将部分文件缓存到内存中,下面是详细解释:
page cache:这里所提及到的page cache,在我看来是linux中vfs虚拟文件系统层的cache层,一般pageCache默认是4K大小,它被操作系统的内存管理模块所管理,文件被映射到内存,一般都是被mmap()函数映射上去的。
mmap()函数会返回一个指针,指向逻辑地址空间中的逻辑地址,逻辑地址通过MMU映射到page cache上。
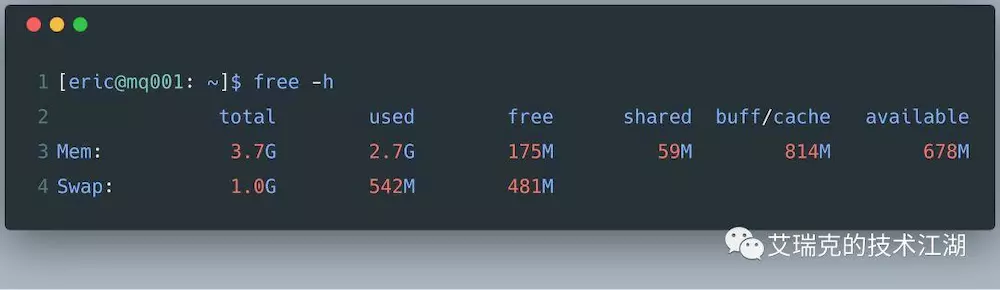
上图中,整个OS有3.7G的物理内存,用掉了2.7G,应当还剩下1G空闲的内存,但OS给出的却是175M。
因为OS发现系统的物理内存有大量剩余时,为了提高IO的性能,就会使用多余的内存当做文件缓存,也就是图上的buff / cache,广义我们说的Page Cache就是这些内存的子集。
pageCache缺点:
内核把可用的内存分配给Page Cache后,free的内存相对就会变少,如果程序有新的内存分配需求或者缺页中断,恰好free的内存不够,内核还需要花费一点时间将热度低的Page Cache的内存回收掉,对性能非常苛刻的系统会产生毛刺。
RMQ发送、消费逻辑
发送逻辑
发送时,Producer不直接与Consume Queue打交道。上文提到过,RMQ所有的消息都会存放在Commit Log中,为了使消息存储不发生混乱,对Commit Log进行写之前就会上锁。
消息持久被锁串行化后,对Commit Log就是顺序写,也就是常说的Append操作。配合上Page Cache,RMQ在写Commit Log时效率会非常高。
Broker端的后台服务线程—ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引文件)数据,不停的轮询,将当前的consumeQueue中的offSet和commitLog中的offSet进行对比,将多出来的offSet进行解析,然后put到consumeQueue中的MapedFile中。
ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。而IndexFile(索引文件)则只是为了消息查询提供了一种通过key或时间区间来查询消息的方法(ps:这种通过IndexFile来查找消息的方法不影响发送与消费消息的主流程)。
消费逻辑
消费时,Consumer不直接与Commit Log打交道,而是从Consume Queue中去拉取数据。拉取的顺序从旧到新,在文件表示每一个Consume Queue都是顺序读,充分利用了Page Cache。光拉取Consume Queue是没有数据的,里面只有一个对Commit Log的引用,所以再次拉取Commit Log。
但整个RMQ只有一个Commit Log,虽然是随机读,但整体还是有序地读,只要那整块区域还在Page Cache的范围内,还是可以充分利用Page Cache。(dstat命令)
对于CommitLog消息存储的日志数据文件来说,读取消息内容时候会产生较多的随机访问读取,严重影响性能。如果选择合适的系统IO调度算法,比如设置调度算法为“Noop”(此时块存储采用SSD的话),随机读的性能也会有所提升。
刷盘方式
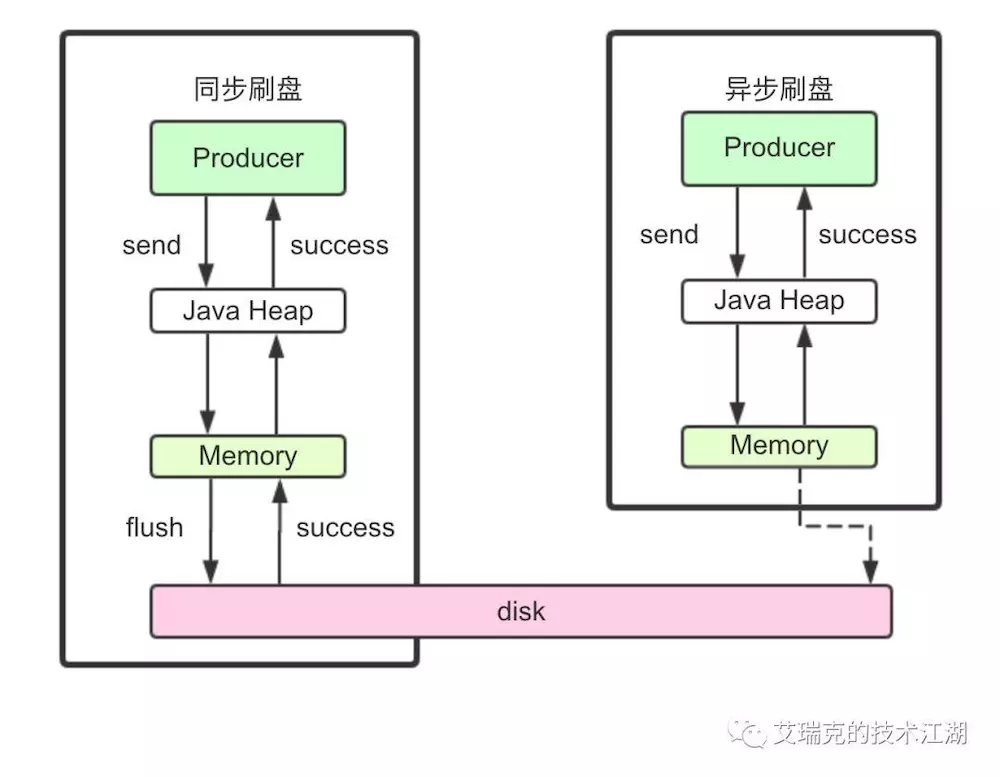
同步刷盘
在消息真正落盘后,才返回成功给Producer,只要磁盘没有损坏,消息就不会丢。一般只用于金融场景。
异步刷盘
读写文件充分利用了Page Cache,即写入Page Cache就返回成功给Producer,RMQ中有两种方式进行异步刷盘,整体原理是一样的。
RMQ文件存储模型层
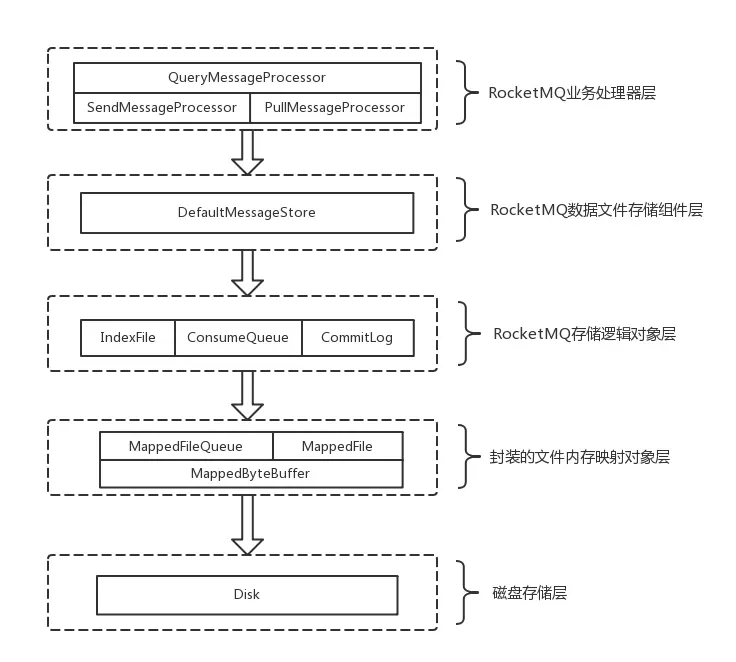
RocketMQ文件存储模型层次结构如上图所示,根据类别和作用从概念模型上大致可以划分为5层,下面将从各个层次分别进行分析和阐述:
(1)RocketMQ业务处理器层
Broker端对消息进行读取和写入的业务逻辑入口,这一层主要包含了业务逻辑相关处理操作(根据解析RemotingCommand中的RequestCode来区分具体的业务操作类型,进而执行不同的业务处理流程),比如前置的检查和校验步骤、构造MessageExtBrokerInner对象、decode反序列化、构造Response返回对象等。
(2)RocketMQ数据存储组件层
该层主要是RocketMQ的存储核心类—DefaultMessageStore,其为RocketMQ消息数据文件的访问入口,通过该类的“putMessage()”和“getMessage()”方法完成对CommitLog消息存储的日志数据文件进行读写操作(具体的读写访问操作还是依赖下一层中CommitLog对象模型提供的方法);另外,在该组件初始化时候,还会启动很多存储相关的后台服务线程,包括AllocateMappedFileService(MappedFile预分配服务线程)、ReputMessageService(回放存储消息服务线程)、HAService(Broker主从同步高可用服务线程)、StoreStatsService(消息存储统计服务线程)、IndexService(索引文件服务线程)等。
(3)RocketMQ存储逻辑对象层
该层主要包含了RocketMQ数据文件存储直接相关的三个模型类IndexFile、ConsumerQueue和CommitLog。IndexFile为索引数据文件提供访问服务,ConsumerQueue为逻辑消息队列提供访问服务,CommitLog则为消息存储的日志数据文件提供访问服务。这三个模型类也是构成了RocketMQ存储层的整体结构(对于这三个模型类的深入分析将放在后续篇幅中)。
(4)封装的文件内存映射层
RocketMQ主要采用JDK NIO中的MappedByteBuffer和FileChannel两种方式完成数据文件的读写。其中,采用MappedByteBuffer这种内存映射磁盘文件的方式完成对大文件的读写,在RocketMQ中将该类封装成MappedFile类。这里限制的问题在上面已经讲过;对于每类大文件(IndexFile/ConsumerQueue/CommitLog),在存储时分隔成多个固定大小的文件(单个IndexFile文件大小约为400M、单个ConsumerQueue文件大小约5.72M、单个CommitLog文件大小为1G),其中每个分隔文件的文件名为前面所有文件的字节大小数+1,即为文件的起始偏移量,从而实现了整个大文件的串联。这里,每一种类的单个文件均由MappedFile类提供读写操作服务(其中,MappedFile类提供了顺序写/随机读、内存数据刷盘、内存清理等和文件相关的服务)。
(5)磁盘存储层
主要指的是部署RocketMQ服务器所用的磁盘。这里,需要考虑不同磁盘类型(如SSD或者普通的HDD)特性以及磁盘的性能参数(如IOPS、吞吐量和访问时延等指标)对顺序写/随机读操作带来的影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号