

负载均衡算法总结
参考:
https://www.cnblogs.com/CodeBear/archive/2019/03/11/10508880.html
https://www.cnblogs.com/xrq730/p/5154340.html
https://blog.csdn.net/NRlovestudy/article/details/93237547
https://blog.csdn.net/qq_29373285/article/details/88777503
浅谈负载均衡算法与实现
记得,我刚工作的时候,同事说了一个故事:在他刚工作的时候,他同事有一天兴冲冲的跑到公司说,你们知道吗,公司请了个大牛。大牛?对,那人会写AJAX!哇,真是大牛啊,跟着他,可以学不少东西啊。我听了笑了,但有点难以理解,因为现在几乎只要是一个开发,都会写AJAX,怎么写个AJAX就算大牛呢?后来我明白了,三年前高深莫测的技术到现在变得普普通通,不足为奇,就像我们今天要讲的负载均衡,在几何时,负载均衡只有大牛才能玩转起来,但是到今天,一个小开发都可以聊上几句。现在,就让我们简单的看看负载均衡把。
从负载均衡设备的角度来看,分为硬件负载均衡和软件负载均衡:
- 硬件负载均衡:比如最常见的F5,还有Array等,这些负载均衡是商业的负载均衡器,性能比较好,毕竟他们的就是为了负载均衡而生的,背后也有非常成熟的团队,可以提供各种解决方案,但是价格比较昂贵,所以没有充足的理由,充足的软妹币是不会考虑的。
- 软件负载均衡:包括我们耳熟能详的Nginx,LVS,Tengine(阿里对Nginx进行的改造)等。优点就是成本比较低,但是也需要有比较专业的团队去维护,要自己去踩坑,去DIY。
从负载均衡的技术来看,分为服务端负载均衡和客户端负载均衡:
- 服务端负载均衡:当我们访问一个服务,请求会先到另外一台服务器,然后这台服务器会把请求分发到提供这个服务的服务器,当然如果只有一台服务器,那好说,直接把请求给那一台服务器就可以了,但是如果有多台服务器呢?这时候,就会根据一定的算法选择一台服务器。
- 客户端负载均衡:客户端服务均衡的概念貌似是有了服务治理才产生的,简单的来说,就是在一台服务器上维护着所有服务的ip,名称等信息,当我们在代码中访问一个服务,是通过一个组件访问的,这个组件会从那台服务器上取到所有提供这个服务的服务器的信息,然后通过一定的算法,选择一台服务器进行请求。
从负载均衡的算法来看,又分为 随机,轮询,哈希,最小压力,当然可能还会加上权重的概念,负载均衡的算法就是本文的重点了。
随机
随机就是没有规律的,随便从负载中获得一台,又分为完全随机和加权随机:
完全随机
public class Servers {
public List<String> list = new ArrayList<>() {
{
add("192.168.1.1");
add("192.168.1.2");
add("192.168.1.3");
}
};
}
public class FullRandom {
static Servers servers = new Servers();
static Random random = new Random();
public static String go() {
var number = random.nextInt(servers.list.size());
return servers.list.get(number);
}
public static void main(String[] args) {
for (var i = 0; i < 15; i++) {
System.out.println(go());
}
}
}
运行结果:
虽说现在感觉并不是那么随机,有的服务器经常被获得到,有的服务器获得的次数比较少,但是当有充足的请求次数,就会越来越平均,这正是随机数的一个特性。
完全随机是最简单的负载均衡算法了,缺点比较明显,因为服务器有好有坏,处理能力是不同的,我们希望性能好的服务器多处理些请求,性能差的服务器少处理一些请求,所以就有了加权随机。
加权随机
加权随机,虽然还是采用的随机算法,但是为每台服务器设置了权重,权重大的服务器获得的概率大一些,权重小的服务器获得的概率小一些。
关于加权随机的算法,有两种实现方式:
一种是网上流传的,代码比较简单:构建一个服务器的List,如果A服务器的权重是2,那么往List里面Add两次A服务器,如果B服务器的权重是7,那么我往List里面Add7次B服务器,以此类推,然后我再生成一个随机数,随机数的上限就是权重的总和,也就是List的Size。这样权重越大的,被选中的概率当然越高,代码如下:
public class Servers {
public HashMap<String, Integer> map = new HashMap<>() {
{
put("192.168.1.1", 2);
put("192.168.1.2", 7);
put("192.168.1.3", 1);
}
};
}
public class WeightRandom {
static Servers servers = new Servers();
static Random random = new Random();
public static String go() {
var ipList = new ArrayList<String>();
for (var item : servers.map.entrySet()) {
for (var i = 0; i < item.getValue(); i++) {
ipList.add(item.getKey());
}
}
int allWeight = servers.map.values().stream().mapToInt(a -> a).sum();
var number = random.nextInt(allWeight);
return ipList.get(number);
}
public static void main(String[] args) {
for (var i = 0; i < 15; i++) {
System.out.println(go());
}
}
}
运行结果:
可以很清楚的看到,权重小的服务器被选中的概率相对是比较低的。
当然我在这里仅仅是为了演示,一般来说,可以把构建服务器List的代码移动到静态代码块中,不用每次都构建。
这种实现方式相对比较简单,很容易就能想到,但是也有缺点,如果我几台服务器权重设置的都很大,比如上千,上万,那么服务器List也有上万条数据,这不是白白占用内存吗?
所以聪明的程序员想到了第二种方式:
为了方便解释,还是就拿上面的例子来说吧:
如果A服务器的权重是2,B服务器的权重是7,C服务器的权重是1:
- 如果我生成的随机数是1,那么落到A服务器,因为1<=2(A服务器的权重)
- 如果我生成的随机数是5,那么落到B服务器,因为5>2(A服务器的权重),5-2(A服务器的权重)=3,3<7(B服务器的权重)
- 如果我生成的随机数是10,那么落到C服务器,因为10>2(A服务器的权重),10-2(A服务器的权重)=8,8>7(B服务器的权重),8-7(B服务器的权重)=1,
1<=1(C服务器的权重)
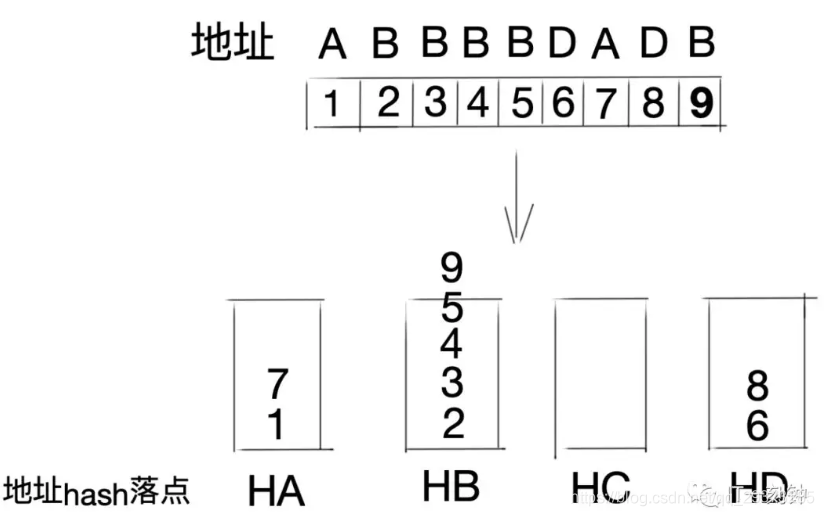
不知道博客对于大于小于符号,会不会有特殊处理,所以我再截个图:
也许,光看文字描述还是不够清楚,可以结合下面丑到爆炸的图片来理解下:
- 如果生成的随机数是5,那么落到第二块区域
- 如果生成的随机数是10,那么落到第三块区域
代码如下:
public class WeightRandom {
static Servers servers = new Servers();
static Random random = new Random();
public static String go() {
int allWeight = servers.map.values().stream().mapToInt(a -> a).sum();
var number = random.nextInt(allWeight);
for (var item : servers.map.entrySet()) {
if (item.getValue() >= number) {
return item.getKey();
}
number -= item.getValue();
}
return "";
}
public static void main(String[] args) {
for (var i = 0; i < 15; i++) {
System.out.println(go());
}
}
}
运行结果:
这种实现方式虽然相对第一种实现方式比较“绕”,但却是一种比较好的实现方式,
对内存没有浪费,权重大小和服务器List的Size也没有关系。
轮询
轮询又分为三种,1.完全轮询 2.加权轮询 3.平滑加权轮询
完全轮询
public class FullRound {
static Servers servers = new Servers();
static int index;
public static String go() {
if (index == servers.list.size()) {
index = 0;
}
return servers.list.get(index++);
}
public static void main(String[] args) {
for (var i = 0; i < 15; i++) {
System.out.println(go());
}
}
}
运行结果:
完全轮询,也是比较简单的,但是问题和完全随机是一样的,所以出现了加权轮询。
加权轮询
加权轮询还是有两种常用的实现方式,和加权随机是一样的,在这里,我就演示我认为比较好的一种:
public class WeightRound {
static Servers servers = new Servers();
static int index;
public static String go() {
int allWeight = servers.map.values().stream().mapToInt(a -> a).sum();
int number = (index++) % allWeight;
for (var item : servers.map.entrySet()) {
if (item.getValue() > number) {
return item.getKey();
}
number -= item.getValue();
}
return "";
}
public static void main(String[] args) {
for (var i = 0; i < 15; i++) {
System.out.println(go());
}
}
}
运行结果:
加权轮询,看起来并没什么问题,但是还是有一点瑕疵,其中一台服务器的压力可能会突然上升,而另外的服务器却很“悠闲,喝着咖啡,看着新闻”。我们希望虽然是按照轮询,但是中间最好可以有交叉,所以出现了第三种轮询算法:平滑加权轮询。
平滑加权轮询
平滑加权是一个算法,很神奇的算法,我们有必要先对这个算法进行讲解。
比如A服务器的权重是5,B服务器的权重是1,C服务器的权重是1。
这个权重,我们称之为“固定权重”,既然这个叫“固定权重”,那么肯定还有叫“非固定权重的”,没错,“非固定权重”每次都会根据一定的规则变动。
- 第一次访问,ABC的“非固定权重”分别是 5 1 1(初始),因为5是其中最大的,5对应的就是A服务器,所以这次选到的服务器就是A,然后我们用当前被选中的服务器的权重-各个服务器的权重之和,也就是A服务器的权重-各个服务器的权重之和。也就是5-7=-2,没被选中的服务器的“非固定权重”不做变化,现在三台服务器的“非固定权重”分别是-2 1 1。
- 第二次访问,把第一次访问最后得到的“非固定权重”+“固定权重”,现在三台服务器的“非固定权重”是3,2,2,因为3是其中最大的,3对应的就是A服务器,所以这次选到的服务器就是A,然后我们用当前被选中的服务器的权重-各个服务器的权重之和,也就是A服务器的权重-各个服务器的权重之和。也就是3-7=-4,没被选中的服务器的“非固定权重”不做变化,现在三台服务器的“非固定权重”分别是-4 1 1。
- 第三次访问,把第二次访问最后得到的“非固定权重”+“固定权重”,现在三台服务器的“非固定权重”是1,3,3,这个时候3虽然是最大的,但是却出现了两个,我们选第一个,第一个3对应的就是B服务器,所以这次选到的服务器就是B,然后我们用当前被选中的服务器的权重-各个服务器的权重之和,也就是B服务器的权重-各个服务器的权重之和。也就是3-7=-4,没被选中的服务器的“非固定权重”不做变化,现在三台服务器的“非固定权重”分别是1 -4 3。
...
以此类推,最终得到这样的表格:
| 请求 | 获得服务器前的非固定权重 | 选中的服务器 | 获得服务器后的非固定权重 |
|---|---|---|---|
| 1 | {5, 1, 1} | A | {-2, 1, 1} |
| 2 | {3, 2, 2} | A | {-4, 2, 2} |
| 3 | {1, 3, 3} | B | {1, -4, 3} |
| 4 | {6, -3, 4} | A | {-1, -3, 4} |
| 5 | {4, -2, 5} | C | {4, -2, -2} |
| 6 | {9, -1, -1} | A | {2, -1, -1} |
| 7 | {7, 0, 0} | A | {0, 0, 0} |
| 8 | {5, 1, 1} | A | {-2, 1, 1} |
当第8次的时候,“非固定权重“又回到了初始的5 1 1,是不是很神奇,也许算法还是比较绕的,但是代码却简单多了:
public class Server {
public Server(int weight, int currentWeight, String ip) {
this.weight = weight;
this.currentWeight = currentWeight;
this.ip = ip;
}
private int weight;
private int currentWeight;
private String ip;
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
public int getCurrentWeight() {
return currentWeight;
}
public void setCurrentWeight(int currentWeight) {
this.currentWeight = currentWeight;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
}
public class Servers {
public HashMap<String, Server> serverMap = new HashMap<>() {
{
put("192.168.1.1", new Server(5,5,"192.168.1.1"));
put("192.168.1.2", new Server(1,1,"192.168.1.2"));
put("192.168.1.3", new Server(1,1,"192.168.1.3"));
}
};
}
public class SmoothWeightRound {
private static Servers servers = new Servers();
public static String go() {
Server maxWeightServer = null;
int allWeight = servers.serverMap.values().stream().mapToInt(Server::getWeight).sum();
for (Map.Entry<String, Server> item : servers.serverMap.entrySet()) {
var currentServer = item.getValue();
if (maxWeightServer == null || currentServer.getCurrentWeight() > maxWeightServer.getCurrentWeight()) {
maxWeightServer = currentServer;
}
}
assert maxWeightServer != null;
maxWeightServer.setCurrentWeight(maxWeightServer.getCurrentWeight() - allWeight);
for (Map.Entry<String, Server> item : servers.serverMap.entrySet()) {
var currentServer = item.getValue();
currentServer.setCurrentWeight(currentServer.getCurrentWeight() + currentServer.getWeight());
}
return maxWeightServer.getIp();
}
public static void main(String[] args) {
for (var i = 0; i < 15; i++) {
System.out.println(go());
}
}
}
运行结果:
这就是平滑加权轮询,巧妙的利用了巧妙算法,既有轮询的效果,又避免了某台服务器压力突然升高,不可谓不妙。
哈希
负载均衡算法中的哈希算法,就是根据某个值生成一个哈希值,然后对应到某台服务器上去,当然可以根据用户,也可以根据请求参数,或者根据其他,想怎么来就怎么来。如果根据用户,就比较巧妙的解决了负载均衡下Session共享的问题,用户小明走的永远是A服务器,用户小笨永远走的是B服务器。
那么如何用代码实现呢,这里又需要引出一个新的概念:哈希环。
什么?我只听过奥运五环,还有“啊 五环 你比四环多一环,啊 五环 你比六环少一环”,这个哈希环又是什么鬼?容我慢慢道来。
哈希环,就是一个环!这...好像...有点难解释呀,我们还是画图来说明把。
一个圆是由无数个点组成的,这是最简单的数学知识,相信大家都可以理解吧,哈希环也一样,哈希环也是有无数个“哈希点”构成的,当然并没有“哈希点”这样的说法,只是为了便于大家理解。
我们先计算出服务器的哈希值,比如根据IP,然后把这个哈希值放到环里,如上图所示。
来了一个请求,我们再根据某个值进行哈希,如果计算出来的哈希值落到了A和B的中间,那么按照顺时针算法,这个请求给B服务器。
理想很丰满,现实很孤单,可能三台服务器掌管的“区域”大小相差很大很大,或者干脆其中一台服务器坏了,会出现如下的情况:
可以看出,A掌管的“区域”实在是太大,B可以说是“很悠闲,喝着咖啡,看着电影”,像这种情况,就叫“哈希倾斜”。
那么怎么避免这种情况呢?虚拟节点。
什么是虚拟节点呢,说白了,就是虚拟的节点...好像..没解释啊...还是上一张丑到爆炸的图吧:
其中,正方形的是真实的节点,或者说真实的服务器,五边形的是虚拟节点,或者说是虚拟的服务器,当一个请求过来,落到了A1和B1之间,那么按照顺时针的规则,应该由B1服务器进行处理,但是B1服务器是虚拟的,它是从B服务器映射出来的,所以再交给B服务器进行处理。
要实现此种负载均衡算法,需要用到一个平时不怎么常用的Map:TreeMap,对TreeMap不了解的朋友可以先去了解下TreeMap,下面放出代码:
private static String go(String client) {
int nodeCount = 20;
TreeMap<Integer, String> treeMap = new TreeMap();
for (String s : new Servers().list) {
for (int i = 0; i < nodeCount; i++)
treeMap.put((s + "--服务器---" + i).hashCode(), s);
}
int clientHash = client.hashCode();
SortedMap<Integer, String> subMap = treeMap.tailMap(clientHash);
Integer firstHash;
if (subMap.size() > 0) {
firstHash = subMap.firstKey();
} else {
firstHash = treeMap.firstKey();
}
String s = treeMap.get(firstHash);
return s;
}
public static void main(String[] args) {
System.out.println(go("今天天气不错啊"));
System.out.println(go("192.168.5.258"));
System.out.println(go("0"));
System.out.println(go("-110000"));
System.out.println(go("风雨交加"));
}
运行结果:
哈希负载均衡算法到这里就结束了。
最小压力
所以的最小压力负载均衡算法就是 选择一台当前最“悠闲”的服务器,如果A服务器有100个请求,B服务器有5个请求,而C服务器只有3个请求,那么毫无疑问会选择C服务器,这种负载均衡算法是比较科学的。但是遗憾的在当前的场景下无法模拟出来“原汁原味”的最小压力负载均衡算法的。
当然在实际的负载均衡下,可能会将多个负载均衡算法合在一起实现,比如先根据最小压力算法,当有几台服务器的压力一样小的时候,再根据权重取出一台服务器,如果权重也一样,再随机取一台,等等。
图解负载均衡算法及分类
什么是负载均衡?
百度词条里的解释是:负载均衡,英文叫Load Balance,意思就是将请求或者数据分摊到多个操作单元上进行执行,共同完成工作任务。它的目的就通过调度集群,达到最佳化资源使用,最大化吞吐率,最小化响应时间,避免单点过载的问题。
负载均衡分类
负载均衡可以根据网络协议的层数进行分类,我们这里以ISO模型为准,从下到上分为:
物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。
当客户端发起请求,会经过层层的封装,发给服务器,服务器收到请求后经过层层的解析,获取到对应的内容。

二层负载均衡
二层负债均衡是基于数据链路层的负债均衡,即让负债均衡服务器和业务服务器绑定同一个虚拟IP(即VIP),客户端直接通过这个VIP进行请求,那么如何区分相同IP下的不同机器呢?没错,通过MAC物理地址,每台机器的MAC物理地址都不一样,当负载均衡服务器接收到请求之后,通过改写HTTP报文中以太网首部的MAC地址,按照某种算法将请求转发到目标机器上,实现负载均衡。
这种方式负载方式虽然控制粒度比较粗,但是优点是负载均衡服务器的压力会比较小,负载均衡服务器只负责请求的进入,不负责请求的响应(响应是有后端业务服务器直接响应给客户端),吞吐量会比较高。

三层负载均衡
三层负载均衡是基于网络层的负载均衡,通俗的说就是按照不同机器不同IP地址进行转发请求到不同的机器上。
这种方式虽然比二层负载多了一层,但从控制的颗粒度上看,并没有比二层负载均衡更有优势,并且,由于请求的进出都要经过负载均衡服务器,会对其造成比较大的压力,性能也比二层负载均衡要差。
四层负载均衡
四层负载均衡是基于传输层的负载均衡,传输层的代表协议就是TCP/UDP协议,除了包含IP之外,还有区分了端口号,通俗的说就是基于IP+端口号进行请求的转发。相对于上面两种,控制力度缩小到了端口,可以针对同一机器上的不用服务进行负载。
这一层以LVS为代表。
七层负载均衡
七层负载均衡是基于应用层的负载均衡,应用层的代表协议有HTTP,DNS等,可以根据请求的url进行转发负载,比起四层负载,会更加的灵活,所控制到的粒度也是最细的,使得整个网络更"智能化"。例如访问一个网站的用户流量,可以通过七层的方式,将对图片类的请求转发到特定的图片服务器并可以使用缓存技术;将对文字类的请求可以转发到特定的文字服务器并可以使用压缩技术。可以说功能是非常强大的负载。
这一层以Nginx为代表。
在普通的应用架构中,使用Nginx完全可以满足需求,对于一些大型应用,一般会采用DNS+LVS+Nginx的方式进行多层次负载均衡,以上这些说明都是基于软件层面的负载均衡,在一些超大型的应用中,还会在前面多加一层物理负载均衡,比如知名的F5。
负载均衡算法
负载均衡算法分为两类:
一种是静态负载均衡,一种是动态负载均衡。
静态均衡算法:
1、轮询法
将请求按顺序轮流地分配到每个节点上,不关心每个节点实际的连接数和当前的系统负载。
优点:简单高效,易于水平扩展,每个节点满足字面意义上的均衡;
缺点:没有考虑机器的性能问题,根据木桶最短木板理论,集群性能瓶颈更多的会受性能差的服务器影响。

2、随机法
将请求随机分配到各个节点。由概率统计理论得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配,也就是轮询的结果。
优缺点和轮询相似。

3、源地址哈希法
源地址哈希的思想是根据客户端的IP地址,通过哈希函数计算得到一个数值,用该数值对服务器节点数进行取模,得到的结果便是要访问节点序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会落到到同一台服务器进行访问。
优点:相同的IP每次落在同一个节点,可以人为干预客户端请求方向,例如灰度发布;
缺点:如果某个节点出现故障,会导致这个节点上的客户端无法使用,无法保证高可用。当某一用户成为热点用户,那么会有巨大的流量涌向这个节点,导致冷热分布不均衡,无法有效利用起集群的性能。所以当热点事件出现时,一般会将源地址哈希法切换成轮询法。
4、加权轮询法
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
加权轮询算法要生成一个服务器序列,该序列中包含n个服务器。n是所有服务器的权重之和。在该序列中,每个服务器的出现的次数,等于其权重值。并且,生成的序列中,服务器的分布应该尽可能的均匀。比如序列{a, a, a, a, a, b, c}中,前五个请求都会分配给服务器a,这就是一种不均匀的分配方法,更好的序列应该是:{a, a, b, a, c, a, a}。
优点:可以将不同机器的性能问题纳入到考量范围,集群性能最优最大化;
缺点:生产环境复杂多变,服务器抗压能力也无法精确估算,静态算法导致无法实时动态调整节点权重,只能粗糙优化。
5、加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
6、键值范围法
根据键的范围进行负债,比如0到10万的用户请求走第一个节点服务器,10万到20万的用户请求走第二个节点服务器……以此类推。
优点:容易水平扩展,随着用户量增加,可以增加节点而不影响旧数据;
缺点:容易负债不均衡,比如新注册的用户活跃度高,旧用户活跃度低,那么压力就全在新增的服务节点上,旧服务节点性能浪费。而且也容易单点故障,无法满足高可用。

动态均衡算法:
1、最小连接数法
根据每个节点当前的连接情况,动态地选取其中当前积压连接数最少的一个节点处理当前请求,尽可能地提高后端服务的利用效率,将请求合理地分流到每一台服务器。俗称闲的人不能闲着,大家一起动起来。
优点:动态,根据节点状况实时变化;
缺点:提高了复杂度,每次连接断开需要进行计数;
实现:将连接数的倒数当权重值。
2、最快响应速度法
根据请求的响应时间,来动态调整每个节点的权重,将响应速度快的服务节点分配更多的请求,响应速度慢的服务节点分配更少的请求,俗称能者多劳,扶贫救弱。
优点:动态,实时变化,控制的粒度更细,跟灵敏;
缺点:复杂度更高,每次需要计算请求的响应速度;
实现:可以根据响应时间进行打分,计算权重。
3、观察模式法
观察者模式是综合了最小连接数和最快响应度,同时考量这两个指标数,进行一个权重的分配。
负载均衡的常用算法
https://www.cnblogs.com/saixing/p/6730201.html
https://blog.csdn.net/okiwilldoit/article/details/81738782
【云服务器的负载均衡】https://cloud.tencent.com/document/product/214/5411
负载均衡的策略分为应用服务器和分布式缓存集群两种适应场景。
为什么这么分呢?简单的说,应用服务器只需要转发请求就可以了。但分布式缓存集群,比如redis、Memcached等,更多的是需要再次读取数据的。也正是因为这样,当新加入一台机器后,要尽量对整个集群的影响小。
1、应用服务器
NO.1—— Random 随机
这是最简单的一种,使用随机数来决定转发到哪台机器上。
优点:简单使用,不需要额外的配置和算法。
缺点:随机数的特点是在数据量大到一定量时才能保证均衡,所以如果请求量有限的话,可能会达不到均衡负载的要求。
NO.2—— Round Robin 轮询
这个也很简单,请求到达后,依次转发,不偏不向。每个服务器的请求数量很平均。
缺点:当集群中服务器硬件配置不同、性能差别大时,无法区别对待。引出下面的算法。
NO.3—— 随机轮询
所谓随机轮询,就是将随机法和轮询法结合起来,在轮询节点时,随机选择一个节点作为开始位置index,此后每次选择下一个节点来处理请求,即(index+1)%size。
这种方式只是在选择第一个节点用了随机方法,其他与轮询法无异,缺点跟轮询一样。
NO.4—— Weighted Round Robin 加权轮询
这种算法的出现就是为了解决简单轮询策略中的不足。在实际项目中,经常会遇到这样的情况。
比如有5台机器,两台新买入的性能等各方面都特别好,剩下三台老古董。这时候我们设置一个权重,让新机器接收更多的请求。物尽其用、能者多劳嘛!
这种情况下,“均衡“就比较相对了,也没必要做到百分百的平均。
Nginx的负载均衡默认算法是加权轮询算法。
Nginx负载均衡算法简介
有三个节点{a, b, c},他们的权重分别是{a=5, b=1, c=1}。发送7次请求,a会被分配5次,b会被分配1次,c会被分配1次。
一般的算法可能是:
1、轮训所有节点,找到一个最大权重节点;
2、选中的节点权重-1;
3、直到减到0,恢复该节点原始权重,继续轮询;
这样的算法看起来简单,最终效果是:{a, a, a, a, a, b, c},即前5次可能选中的都是a,这可能造成权重大的服务器造成过大压力的同时,小权重服务器还很闲。
Nginx的加权轮询算法将保持选择的平滑性,希望达到的效果可能是{a, b, a, a, c, a, a},即尽可能均匀的分摊节点,节点分配不再是连续的。
Nginx加权轮询算法
1、概念解释,每个节点有三个权重变量,分别是:
(1) weight: 约定权重,即在配置文件或初始化时约定好的每个节点的权重。
(2) effectiveWeight: 有效权重,初始化为weight。
在通讯过程中发现节点异常,则-1;
之后再次选取本节点,调用成功一次则+1,直达恢复到weight;
此变量的作用主要是节点异常,降低其权重。
(3) currentWeight: 节点当前权重,初始化为0。
2、算法逻辑
(1) 轮询所有节点,计算当前状态下所有节点的effectiveWeight之和totalWeight;
(2) currentWeight = currentWeight + effectiveWeight; 选出所有节点中currentWeight中最大的一个节点作为选中节点;
(3) 选中节点的currentWeight = currentWeight - totalWeight;
基于以上算法,我们看一个例子:
这时有三个节点{a, b, c},权重分别是{a=4, b=2, c=1},共7次请求,初始currentWeight值为{0, 0, 0},每次分配后的结果如下:
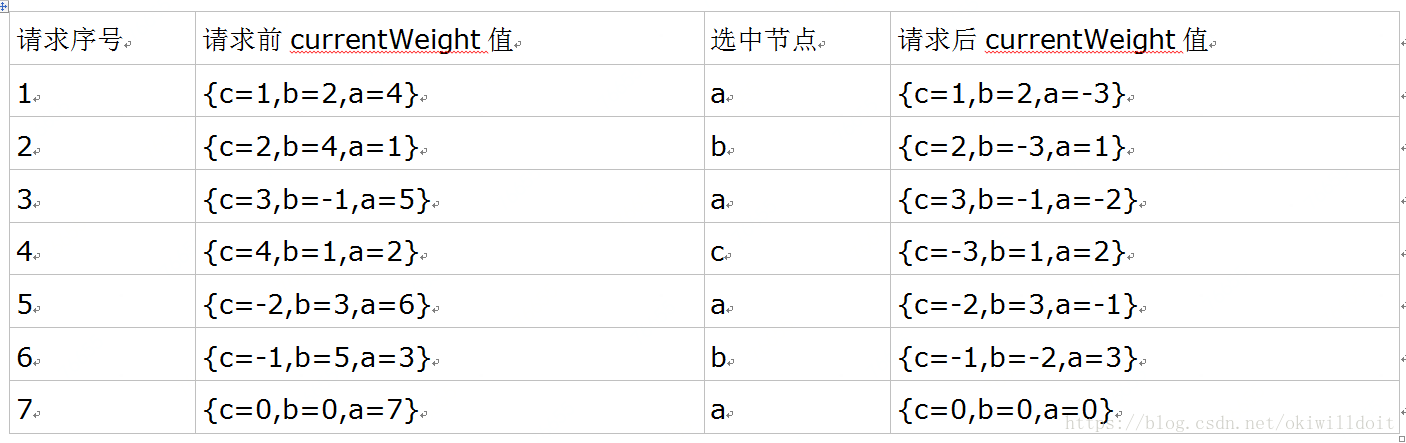
观察到七次调用选中的节点顺序为{a, b, a, c, a, b, a},a节点选中4次,b节点选中2次,c节点选中1次,算法保持了currentWeight值从初始值{c=0,b=0,a=0}到7次调用后又回到{c=0,b=0,a=0}。
参考文档为:https://www.cnblogs.com/markcd/p/8456870.html
NO.5—— Weighted Random 加权随机
加权随机法跟加权轮询法类似,根据后台服务器不同的配置和负载情况,配置不同的权重。
不同的是,它是按照权重来随机选取服务器的,而非顺序。
NO.6—— Least Connections 最少连接
这是最符合负载均衡算法的一个。需要记录每个应用服务器正在处理的连接数,然后将新来的请求转发到最少的那台上。
NO.7—— Latebcy-Aware
与方法6类似,该方法也是为了让性能强的机器处理更多的请求,只不过方法6使用的指标是连接数,而该方法用的请求服务器的往返延迟(RTT),动态地选择延迟最低的节点处理当前请求。该方法的计算延迟的具体实现可以用EWMA算法来实现,它使用滑动窗口来计算移动平均耗时。
Twitter的负载均衡算法基于这种思想,不过实现起来更加简单,即P2C算法。首先随机选取两个节点,在这两个节点中选择延迟低,或者连接数小的节点处理请求,这样兼顾了随机性,又兼顾了机器的性能,实现很简单。
具体参见:https://linkerd.io/1/features/load-balancing/
NO.7—— Source Hashing 源地址散列
根据请求的来源ip进行hash计算,然后对应到一个服务器上。之后所有来自这个ip的请求都由同一台服务器处理。
2、分布式缓存集群
好了,有了前面的基础,再看分布式缓存集群就简单多了。我们只需要多考虑两点就够了。
NO.1—— 取模
这是最简单但最不实用的一个。
以redis为例,假设我们有5台机器,要想取模肯定先得转换为数字,我们将一个请求的key转成数字(比如CRC16算法那),比如现在五个请求转换成的数字后对5取模分别为0、1、2、3、4,正好转发到五台机器上。
这时意外来了,其中一台宕机了,现在集群中还有4台。之后再来请求只能对4取模。问题就暴露出来了,那之前按照5取模的数据命中的机率大大降低了,相当于每宕机一台,之前存入的数据几乎都不能用了。
因此,不推荐此种做法。
NO.2—— 哈希
这种算法叫哈希有些笼统了,具体可以分为ip哈希和url哈希(类似原地址散列)。这里就不多说了。重点说下redis中的设计。
redis中引入了哈希槽来解决这一问题。16384个哈希槽,每次不再对集群中服务器的总数取模,而是16384这个固定的数字。然后将请求分发。这样就可以避免其中一台服务器宕机,原有数据无法命中的问题。
NO.3—— 一致性哈希
终于到重头戏了,不过有了前面的介绍,这个也就不难理解了。
一致性哈希在memcached中有使用,通过一个hash环来实现key到缓存服务器的映射。
这个环的长度为2^32,根据节点名称的hash值将缓存服务器节点放在这个hash环上。
几种简单的负载均衡算法及其Java代码实现
什么是负载均衡
负载均衡,英文名称为Load Balance,指由多台服务器以对称的方式组成一个服务器集合,每台服务器都具有等价的地位,都可以单独对外提供服务而无须其他服务器的辅助。通过某种负载分担技术,将外部发送来的请求均匀分配到对称结构中的某一台服务器上,而接收到请求的服务器独立地回应客户的请求。负载均衡能够平均分配客户请求到服务器阵列,借此提供快速获取重要数据,解决大量并发访问服务问题,这种集群技术可以用最少的投资获得接近于大型主机的性能。
负载均衡分为软件负载均衡和硬件负载均衡,前者的代表是阿里章文嵩博士研发的LVS,后者则是均衡服务器比如F5,当然这只是提一下,不是重点。
本文讲述的是"将外部发送来的请求均匀分配到对称结构中的某一台服务器上"的各种算法,并以Java代码演示每种算法的具体实现,OK,下面进入正题,在进入正题前,先写一个类来模拟Ip列表:


1 public class IpMap
2 {
3 // 待路由的Ip列表,Key代表Ip,Value代表该Ip的权重
4 public static HashMap<String, Integer> serverWeightMap =
5 new HashMap<String, Integer>();
6
7 static
8 {
9 serverWeightMap.put("192.168.1.100", 1);
10 serverWeightMap.put("192.168.1.101", 1);
11 // 权重为4
12 serverWeightMap.put("192.168.1.102", 4);
13 serverWeightMap.put("192.168.1.103", 1);
14 serverWeightMap.put("192.168.1.104", 1);
15 // 权重为3
16 serverWeightMap.put("192.168.1.105", 3);
17 serverWeightMap.put("192.168.1.106", 1);
18 // 权重为2
19 serverWeightMap.put("192.168.1.107", 2);
20 serverWeightMap.put("192.168.1.108", 1);
21 serverWeightMap.put("192.168.1.109", 1);
22 serverWeightMap.put("192.168.1.110", 1);
23 }
24 }
轮询(Round Robin)法
轮询法即Round Robin法,其代码实现大致如下:
1 public class RoundRobin
2 {
3 private static Integer pos = 0;
4
5 public static String getServer()
6 {
7 // 重建一个Map,避免服务器的上下线导致的并发问题
8 Map<String, Integer> serverMap =
9 new HashMap<String, Integer>();
10 serverMap.putAll(IpMap.serverWeightMap);
11
12 // 取得Ip地址List
13 Set<String> keySet = serverMap.keySet();
14 ArrayList<String> keyList = new ArrayList<String>();
15 keyList.addAll(keySet);
16
17 String server = null;
18 synchronized (pos)
19 {
20 if (pos > keySet.size())
21 pos = 0;
22 server = keyList.get(pos);
23 pos ++;
24 }
25
26 return server;
27 }
28 }
由于serverWeightMap中的地址列表是动态的,随时可能有机器上线、下线或者宕机,因此为了避免可能出现的并发问题,方法内部要新建局部变量serverMap,现将serverMap中的内容复制到线程本地,以避免被多个线程修改。这样可能会引入新的问题,复制以后serverWeightMap的修改无法反映给serverMap,也就是说这一轮选择服务器的过程中,新增服务器或者下线服务器,负载均衡算法将无法获知。新增无所谓,如果有服务器下线或者宕机,那么可能会访问到不存在的地址。因此,服务调用端需要有相应的容错处理,比如重新发起一次server选择并调用。
对于当前轮询的位置变量pos,为了保证服务器选择的顺序性,需要在操作时对其加锁,使得同一时刻只能有一个线程可以修改pos的值,否则当pos变量被并发修改,则无法保证服务器选择的顺序性,甚至有可能导致keyList数组越界。
轮询法的优点在于:试图做到请求转移的绝对均衡。
轮询法的缺点在于:为了做到请求转移的绝对均衡,必须付出相当大的代价,因为为了保证pos变量修改的互斥性,需要引入重量级的悲观锁synchronized,这将会导致该段轮询代码的并发吞吐量发生明显的下降。
随机(Random)法
通过系统随机函数,根据后端服务器列表的大小值来随机选择其中一台进行访问。由概率统计理论可以得知,随着调用量的增大,其实际效果越来越接近于平均分配流量到每一台后端服务器,也就是轮询的效果。
随机法的代码实现大致如下:
1 public class Random
2 {
3 public static String getServer()
4 {
5 // 重建一个Map,避免服务器的上下线导致的并发问题
6 Map<String, Integer> serverMap =
7 new HashMap<String, Integer>();
8 serverMap.putAll(IpMap.serverWeightMap);
9
10 // 取得Ip地址List
11 Set<String> keySet = serverMap.keySet();
12 ArrayList<String> keyList = new ArrayList<String>();
13 keyList.addAll(keySet);
14
15 java.util.Random random = new java.util.Random();
16 int randomPos = random.nextInt(keyList.size());
17
18 return keyList.get(randomPos);
19 }
20 }
整体代码思路和轮询法一致,先重建serverMap,再获取到server列表。在选取server的时候,通过Random的nextInt方法取0~keyList.size()区间的一个随机值,从而从服务器列表中随机获取到一台服务器地址进行返回。基于概率统计的理论,吞吐量越大,随机算法的效果越接近于轮询算法的效果。
源地址哈希(Hash)法
源地址哈希的思想是获取客户端访问的IP地址值,通过哈希函数计算得到一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是要访问的服务器的序号。源地址哈希算法的代码实现大致如下:
1 public class Hash
2 {
3 public static String getServer()
4 {
5 // 重建一个Map,避免服务器的上下线导致的并发问题
6 Map<String, Integer> serverMap =
7 new HashMap<String, Integer>();
8 serverMap.putAll(IpMap.serverWeightMap);
9
10 // 取得Ip地址List
11 Set<String> keySet = serverMap.keySet();
12 ArrayList<String> keyList = new ArrayList<String>();
13 keyList.addAll(keySet);
14
15 // 在Web应用中可通过HttpServlet的getRemoteIp方法获取
16 String remoteIp = "127.0.0.1";
17 int hashCode = remoteIp.hashCode();
18 int serverListSize = keyList.size();
19 int serverPos = hashCode % serverListSize;
20
21 return keyList.get(serverPos);
22 }
23 }
前两部分和轮询法、随机法一样就不说了,差别在于路由选择部分。通过客户端的ip也就是remoteIp,取得它的Hash值,对服务器列表的大小取模,结果便是选用的服务器在服务器列表中的索引值。
源地址哈希法的优点在于:保证了相同客户端IP地址将会被哈希到同一台后端服务器,直到后端服务器列表变更。根据此特性可以在服务消费者与服务提供者之间建立有状态的session会话。
源地址哈希算法的缺点在于:除非集群中服务器的非常稳定,基本不会上下线,否则一旦有服务器上线、下线,那么通过源地址哈希算法路由到的服务器是服务器上线、下线前路由到的服务器的概率非常低,如果是session则取不到session,如果是缓存则可能引发"雪崩"。如果这么解释不适合明白,可以看我之前的一篇文章MemCache超详细解读,一致性Hash算法部分。
加权轮询(Weight Round Robin)法
不同的服务器可能机器配置和当前系统的负载并不相同,因此它们的抗压能力也不尽相同,给配置高、负载低的机器配置更高的权重,让其处理更多的请求,而低配置、高负载的机器,则给其分配较低的权重,降低其系统负载。加权轮询法可以很好地处理这一问题,并将请求顺序按照权重分配到后端。加权轮询法的代码实现大致如下:
1 public class WeightRoundRobin
2 {
3 private static Integer pos;
4
5 public static String getServer()
6 {
7 // 重建一个Map,避免服务器的上下线导致的并发问题
8 Map<String, Integer> serverMap =
9 new HashMap<String, Integer>();
10 serverMap.putAll(IpMap.serverWeightMap);
11
12 // 取得Ip地址List
13 Set<String> keySet = serverMap.keySet();
14 Iterator<String> iterator = keySet.iterator();
15
16 List<String> serverList = new ArrayList<String>();
17 while (iterator.hasNext())
18 {
19 String server = iterator.next();
20 int weight = serverMap.get(server);
21 for (int i = 0; i < weight; i++)
22 serverList.add(server);
23 }
24
25 String server = null;
26 synchronized (pos)
27 {
28 if (pos > keySet.size())
29 pos = 0;
30 server = serverList.get(pos);
31 pos ++;
32 }
33
34 return server;
35 }
36 }
与轮询法类似,只是在获取服务器地址之前增加了一段权重计算的代码,根据权重的大小,将地址重复地增加到服务器地址列表中,权重越大,该服务器每轮所获得的请求数量越多。
加权随机(Weight Random)法
与加权轮询法类似,加权随机法也是根据后端服务器不同的配置和负载情况来配置不同的权重。不同的是,它是按照权重来随机选择服务器的,而不是顺序。加权随机法的代码实现如下:
1 public class WeightRandom
2 {
3 public static String getServer()
4 {
5 // 重建一个Map,避免服务器的上下线导致的并发问题
6 Map<String, Integer> serverMap =
7 new HashMap<String, Integer>();
8 serverMap.putAll(IpMap.serverWeightMap);
9
10 // 取得Ip地址List
11 Set<String> keySet = serverMap.keySet();
12 Iterator<String> iterator = keySet.iterator();
13
14 List<String> serverList = new ArrayList<String>();
15 while (iterator.hasNext())
16 {
17 String server = iterator.next();
18 int weight = serverMap.get(server);
19 for (int i = 0; i < weight; i++)
20 serverList.add(server);
21 }
22
23 java.util.Random random = new java.util.Random();
24 int randomPos = random.nextInt(serverList.size());
25
26 return serverList.get(randomPos);
27 }
28 }
这段代码相当于是随机法和加权轮询法的结合,比较好理解,就不解释了。
最小连接数(Least Connections)法
前面几种方法费尽心思来实现服务消费者请求次数分配的均衡,当然这么做是没错的,可以为后端的多台服务器平均分配工作量,最大程度地提高服务器的利用率,但是实际情况是否真的如此?实际情况中,请求次数的均衡真的能代表负载的均衡吗?这是一个值得思考的问题。
上面的问题,再换一个角度来说就是:以后端服务器的视角来观察系统的负载,而非请求发起方来观察。最小连接数法便属于此类。
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它正是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前请求,尽可能地提高后端服务器的利用效率,将负载合理地分流到每一台机器。由于最小连接数设计服务器连接数的汇总和感知,设计与实现较为繁琐,此处就不说它的实现了。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步