
常见限流算法总结
参考:
https://blog.csdn.net/weixin_41846320/article/details/95941361
https://www.cnblogs.com/taromilk/p/11751211.html
https://zhuanlan.zhihu.com/p/110596981
https://www.cnblogs.com/huangqingshi/p/10290615.html
常用4种限流算法介绍及比较
1、计数器(固定窗口)算法
计数器算法是使用计数器在周期内累加访问次数,当达到设定的限流值时,触发限流策略。下一个周期开始时,进行清零,重新计数。
此算法在单机还是分布式环境下实现都非常简单,使用redis的incr原子自增性和线程安全即可轻松实现。

这个算法通常用于QPS限流和统计总访问量,对于秒级以上的时间周期来说,会存在一个非常严重的问题,那就是临界问题,如下图: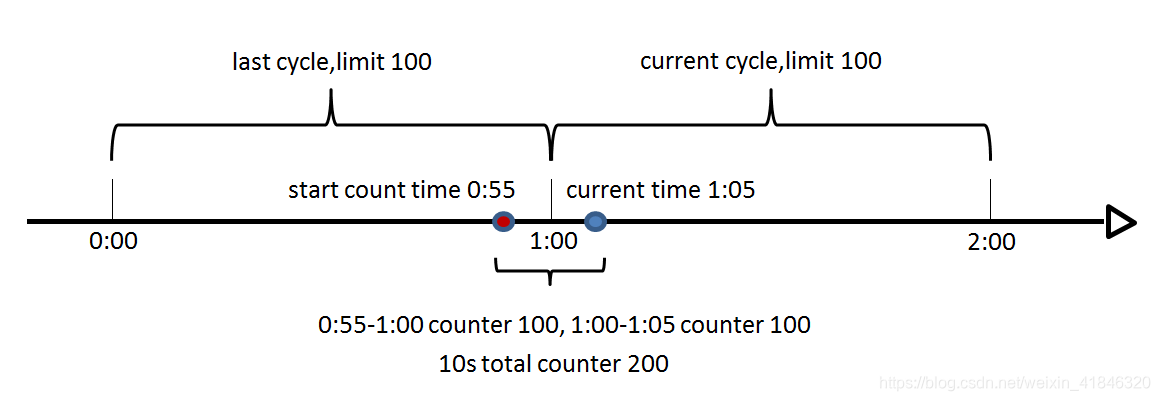
假设1min内服务器的负载能力为100,因此一个周期的访问量限制在100,然而在第一个周期的最后5秒和下一个周期的开始5秒时间段内,分别涌入100的访问量,虽然没有超过每个周期的限制量,但是整体上10秒内已达到200的访问量,已远远超过服务器的负载能力,由此可见,计数器算法方式限流对于周期比较长的限流,存在很大的弊端。
2、滑动窗口算法
滑动窗口算法是将时间周期分为N个小周期,分别记录每个小周期内访问次数,并且根据时间滑动删除过期的小周期。
如下图,假设时间周期为1min,将1min再分为2个小周期,统计每个小周期的访问数量,则可以看到,第一个时间周期内,访问数量为75,第二个时间周期内,访问数量为100,超过100的访问则被限流掉了
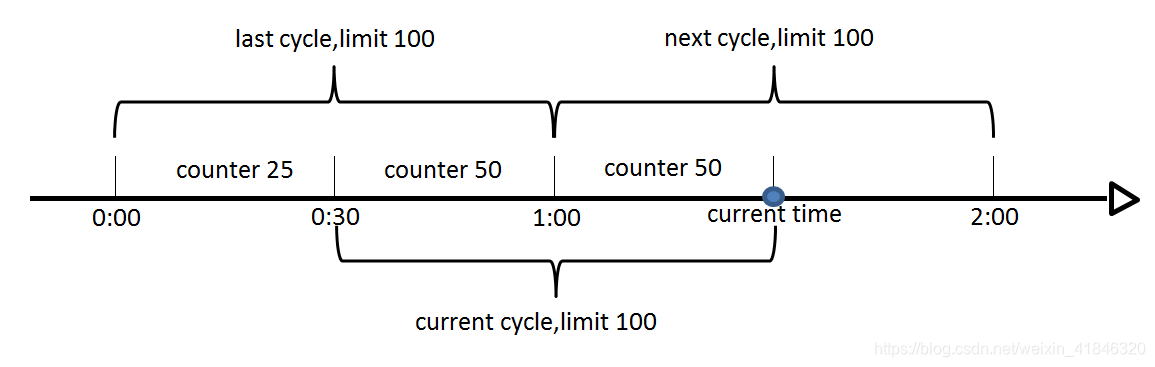
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
此算法可以很好的解决固定窗口算法的临界问题。
3、漏桶算法
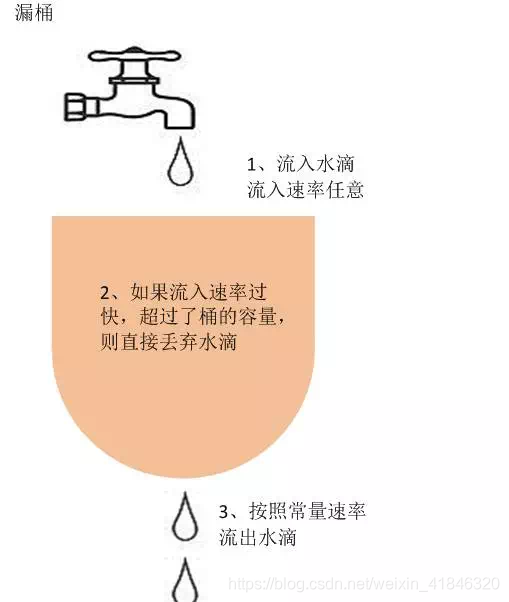
漏桶算法是访问请求到达时直接放入漏桶,如当前容量已达到上限(限流值),则进行丢弃(触发限流策略)。漏桶以固定的速率进行释放访问请求(即请求通过),直到漏桶为空。
4、令牌桶算法
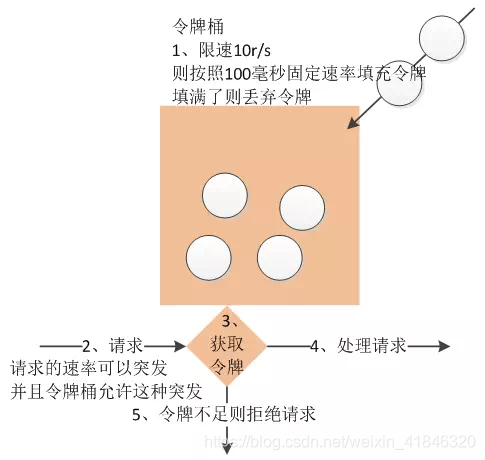
令牌桶算法是程序以r(r=时间周期/限流值)的速度向令牌桶中增加令牌,直到令牌桶满,请求到达时向令牌桶请求令牌,如获取到令牌则通过请求,否则触发限流策略
各个算法比较
|
算法 |
确定参数 |
空间复杂度 |
时间复杂度 |
限制突发流量 |
平滑限流 |
分布式环境下实现难度 |
|
固定窗口 |
计数周期T、 周期内最大访问数N |
低O(1) (记录周期内访问次数及周期开始时间) |
低O(1) |
否 |
否 |
低 |
|
滑动窗口 |
计数周期T、 周期内最大访问数N |
高O(N) (记录每个小周期中的访问数量) |
中O(N) |
是 |
相对实现。滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑 |
中 |
|
漏桶 |
漏桶流出速度r、漏桶容量N |
低O(1) (记录当前漏桶中容量) |
高O(N) |
是 |
是 |
高 |
|
令牌桶 |
令牌产生速度r、令牌桶容量N |
低O(1) (记录当前令牌桶中令牌数) |
高O(N) |
是 |
是 |
高
|
常用限流算法
引言
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。今天我们要聊的就是限流(Rate Limit),限流的目的很简单,就是为了保护系统不被瞬时大流量冲垮,
限流这个概念我其实很早之前就有去了解过,不过无奈之前工作所接触业务的并发量实在是谈不上限流。目前公司大促峰值QPS在2w往上,自然而然需要用到限流,特别是类似秒杀这种瞬时流量非常大但实际成单率低的业务场景。
目前比较常用的限流算法有三种
-
计数器固定窗口算法
-
计数器滑动窗口算法
-
漏桶算法
-
令牌桶算法
计数器固定窗口算法
计数器固定窗口算法是最简单的限流算法,实现方式也比较简单。就是通过维护一个单位时间内的计数值,每当一个请求通过时,就将计数值加1,当计数值超过预先设定的阈值时,就拒绝单位时间内的其他请求。如果单位时间已经结束,则将计数器清零,开启下一轮的计数。
但是这种实现会有一个问题,举个例子:
假设我们设定1秒内允许通过的请求阈值是200,如果有用户在时间窗口的最后几毫秒发送了200个请求,紧接着又在下一个时间窗口开始时发送了200个请求,那么这个用户其实在一秒内成功请求了400次,显然超过了阈值但并不会被限流。其实这就是临界值问题,那么临界值问题要怎么解决呢?
- 代码实现 -- [CounterRateLimit.java](https://github.com/WangJunnan/learn/blob/master/algorithm/src/main/java/com/walm/learn/algorithm/ratelimit/CounterRateLimit.java)
import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicInteger; /** * <p>CounterRateLimit</p> * <p>普通计数限流(单窗口)</p> * * @author wangjn * @since 2019-09-30 */ public class CounterRateLimit implements RateLimit , Runnable { /** * 阈值 */ private Integer limitCount; /** * 当前通过请求数 */ private AtomicInteger passCount; /** * 统计时间间隔 */ private long period; private TimeUnit timeUnit; private ScheduledExecutorService scheduledExecutorService; public CounterRateLimit(Integer limitCount) { this(limitCount, 1000, TimeUnit.MILLISECONDS); } public CounterRateLimit(Integer limitCount, long period, TimeUnit timeUnit) { this.limitCount = limitCount; this.period = period; this.timeUnit = timeUnit; passCount = new AtomicInteger(0); this.startResetTask(); } @Override public boolean canPass() throws BlockException { if (passCount.incrementAndGet() > limitCount) { throw new BlockException(); } return true; } private void startResetTask() { scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(); scheduledExecutorService.scheduleAtFixedRate(this, 0, period, timeUnit); } @Override public void run() { passCount.set(0); } }
计数器滑动窗口算法
计数器滑动窗口法就是为了解决上述固定窗口计数存在的问题而诞生,学过TCP协议的同学应该对滑动窗口不陌生,其实还是不太一样的,下文我们要说的滑动窗口是基于时间来划分窗口的。而TCP的滑动窗口指的是能够接受的字节数,并且大小是可变的(拥塞控制)
滑动窗口是怎么做的?
前面说了固定窗口存在临界值问题,要解决这种临界值问题,显然只用一个窗口是解决不了问题的。假设我们仍然设定1秒内允许通过的请求是200个,但是在这里我们需要把1秒的时间分成多格,假设分成5格(格数越多,流量过渡越平滑),每格窗口的时间大小是200毫秒,每过200毫秒,就将窗口向前移动一格。为了便于理解,可以看下图
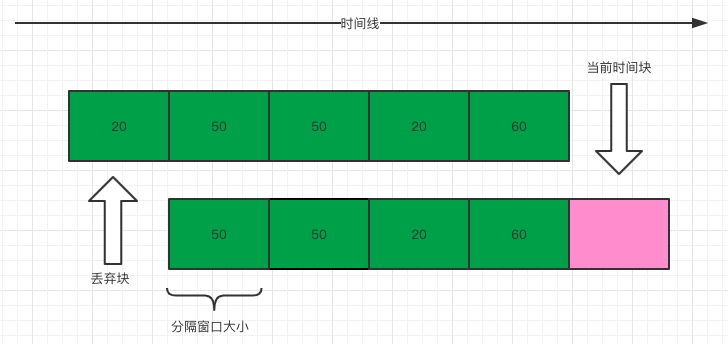
图中将窗口划为5份,每个小窗口中的数字表示在这个窗口中请求数,所以通过观察上图,可知在当前时间快(200毫秒)允许通过的请求数应该是20而不是200(只要超过20就会被限流),因为我们最终统计请求数时是需要把当前窗口的值进行累加,进而得到当前请求数来判断是不是需要进行限流。
那么滑动窗口限流法是完美的吗?
细心观察的我们应该能马上发现问题,滑动窗口限流法其实就是计数器固定窗口算法的一个变种。流量的过渡是否平滑依赖于我们设置的窗口格数也就是统计时间间隔,格数越多,统计越精确,但是具体要分多少格我们也说不上来呀...
- 代码实现 -- [SlidingWindowRateLimit.java](https://github.com/WangJunnan/learn/blob/master/algorithm/src/main/java/com/walm/learn/algorithm/ratelimit/SlidingWindowRateLimit.java)
import lombok.Data; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicInteger; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; /** * <p>SlidingWindowRateLimit</p> * <p>滑动窗口限流</p> * * @author wangjn * @since 2019-09-30 */ @Slf4j public class SlidingWindowRateLimit implements RateLimit, Runnable { /** * 阈值 */ private Integer limitCount; /** * 当前通过的请求数 */ private AtomicInteger passCount; /** * 窗口数 */ private Integer windowSize; /** * 每个窗口时间间隔大小 */ private long windowPeriod; private TimeUnit timeUnit; private Window[] windows; private volatile Integer windowIndex = 0; private Lock lock = new ReentrantLock(); public SlidingWindowRateLimit(Integer limitCount) { // 默认统计qps, 窗口大小5 this(limitCount, 5, 200, TimeUnit.MILLISECONDS); } /** * 统计总时间 = windowSize * windowPeriod */ public SlidingWindowRateLimit(Integer limitCount, Integer windowSize, Integer windowPeriod, TimeUnit timeUnit) { this.limitCount = limitCount; this.windowSize = windowSize; this.windowPeriod = windowPeriod; this.timeUnit = timeUnit; this.passCount = new AtomicInteger(0); this.initWindows(windowSize); this.startResetTask(); } @Override public boolean canPass() throws BlockException { lock.lock(); if (passCount.get() > limitCount) { throw new BlockException(); } windows[windowIndex].passCount.incrementAndGet(); passCount.incrementAndGet(); lock.unlock(); return true; } private void initWindows(Integer windowSize) { windows = new Window[windowSize]; for (int i = 0; i < windowSize; i++) { windows[i] = new Window(); } } private ScheduledExecutorService scheduledExecutorService; private void startResetTask() { scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(); scheduledExecutorService.scheduleAtFixedRate(this, windowPeriod, windowPeriod, timeUnit); } @Override public void run() { // 获取当前窗口索引 Integer curIndex = (windowIndex + 1) % windowSize; log.info("info_reset_task, curIndex = {}", curIndex); // 重置当前窗口索引通过数量,并获取上一次通过数量 Integer count = windows[curIndex].passCount.getAndSet(0); windowIndex = curIndex; // 总通过数量 减去 当前窗口上次通过数量 passCount.addAndGet(-count); log.info("info_reset_task, curOldCount = {}, passCount = {}, windows = {}", count, passCount, windows); } @Data class Window { private AtomicInteger passCount; public Window() { this.passCount = new AtomicInteger(0); } } }
漏桶算法
上面所介绍的两种算法都不能非常平滑的过渡,下面就是漏桶算法登场了
什么是漏桶算法?
漏桶算法以一个常量限制了出口流量速率,因此漏桶算法可以平滑突发的流量。其中漏桶作为流量容器我们可以看做一个FIFO的队列,当入口流量速率大于出口流量速率时,因为流量容器是有限的,当超出流量容器大小时,超出的流量会被丢弃。
下图比较形象的说明了漏桶算法的原理,其中水龙头是入口流量,漏桶是流量容器,匀速流出的水是出口流量。
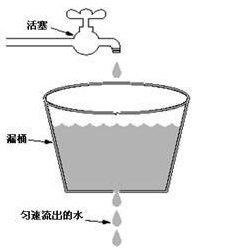
漏桶算法的特点
-
漏桶具有固定容量,出口流量速率是固定常量(流出请求)
-
入口流量可以以任意速率流入到漏桶中(流入请求)
-
如果入口流量超出了桶的容量,则流入流量会溢出(新请求被拒绝)
-
代码实现 -- [LeakyBucketRateLimit.java](https://github.com/WangJunnan/learn/blob/master/algorithm/src/main/java/com/walm/learn/algorithm/ratelimit/LeakyBucketRateLimit.java)
import lombok.extern.slf4j.Slf4j; import java.util.Objects; import java.util.concurrent.*; import java.util.concurrent.locks.LockSupport; /** * <p>LeakyBucketRateLimit</p> * * @author wangjn * @since 2019-10-08 */ @Slf4j public class LeakyBucketRateLimit implements RateLimit, Runnable { /** * 出口限制qps */ private Integer limitSecond; /** * 漏桶队列 */ private BlockingQueue<Thread> leakyBucket; private ScheduledExecutorService scheduledExecutorService; public LeakyBucketRateLimit(Integer bucketSize, Integer limitSecond) { this.limitSecond = limitSecond; this.leakyBucket = new LinkedBlockingDeque<>(bucketSize); scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(); long interval = (1000 * 1000 * 1000) / limitSecond; scheduledExecutorService.scheduleAtFixedRate(this, 0, interval, TimeUnit.NANOSECONDS); } @Override public boolean canPass() throws BlockException { if (leakyBucket.remainingCapacity() == 0) { throw new BlockException(); } leakyBucket.offer(Thread.currentThread()); LockSupport.park(); return true; } @Override public void run() { Thread thread = leakyBucket.poll(); if (Objects.nonNull(thread)) { LockSupport.unpark(thread); } } }
不过因为漏桶算法限制了流出速率是一个固定常量值,所以漏桶算法不支持出现突发流出流量。但是在实际情况下,流量往往是突发的。
令牌桶算法
令牌桶算法是漏桶算法的改进版,可以支持突发流量。不过与漏桶算法不同的是,令牌桶算法的漏桶中存放的是令牌而不是流量。
那么令牌桶算法是怎么突发流量的呢?
最开始,令牌桶是空的,我们以恒定速率往令牌桶里加入令牌,令牌桶被装满时,多余的令牌会被丢弃。当请求到来时,会先尝试从令牌桶获取令牌(相当于从令牌桶移除一个令牌),获取成功则请求被放行,获取失败则阻塞活拒绝请求。
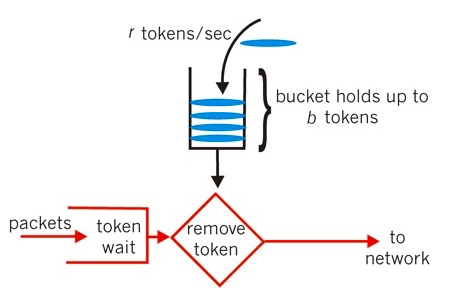
令牌桶算法的特点
-
最多可以存发b个令牌。如果令牌到达时令牌桶已经满了,那么这个令牌会被丢弃
-
请求到来时,如果令牌桶中少于n个令牌,那么不会删除令牌。该请求会被限流(阻塞活拒绝)
-
算法允许最大b(令牌桶大小)个请求的突发
令牌桶算法限制的是平均流量,因此其允许突发流量(只要令牌桶中有令牌,就不会被限流)
- 代码实现 -- [TokenBucketRateLimit.java](https://github.com/WangJunnan/learn/blob/master/algorithm/src/main/java/com/walm/learn/algorithm/ratelimit/TokenBucketRateLimit.java)
import com.walm.common.util.StringUtils; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.*; /** * <p>TokenBucketRateLimit</p> * * @author wangjn * @since 2019-10-08 */ @Slf4j public class TokenBucketRateLimit implements RateLimit, Runnable { /** * token 生成 速率 (每秒) */ private Integer tokenLimitSecond; /** * 令牌桶队列 */ private BlockingQueue<String /* token */> tokenBucket; private static final String TOKEN = "__token__"; private ScheduledExecutorService scheduledExecutorService; public TokenBucketRateLimit(Integer bucketSize, Integer tokenLimitSecond) { this.tokenLimitSecond = tokenLimitSecond; this.tokenBucket = new LinkedBlockingDeque<>(bucketSize); scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(); long interval = (1000 * 1000 * 1000) / tokenLimitSecond; scheduledExecutorService.scheduleAtFixedRate(this, 0, interval, TimeUnit.NANOSECONDS); } @Override public boolean canPass() throws BlockException { String token = tokenBucket.poll(); if (StringUtils.isEmpty(token)) { throw new BlockException(); } return true; } @Override public void run() { if (tokenBucket.remainingCapacity() == 0) { return; } tokenBucket.offer(TOKEN); } }
总结
至此,基本把以上4种限流算法的原理都解释清楚了。每种限流算法都有其固定特点,及各自适用的场景,其中计数器算法是其中最简单的,相当于滑动窗口算法的简化版,令牌桶算法相比漏桶算法对资源的利用率更高(允许突发流量)
限流限速RateLimiter
01 Why
分布式系统中,由于接口API无法控制上游调用方的行为,因此当瞬时请求量突增时,会导致服务器占用过多资源,发生响应速度降低、超时、乃至宕机,甚至引发雪崩造成整个系统不可用。
限流,Rate Limiting,就是对API的请求量进行限制,对于超出限制部分的请求作出快速拒绝、快速失败、丢弃处理,以保证本服务以及下游资源系统的稳定。
哪些原因会带来瞬时请求量突增?
1,热点业务、突发热点数据带来的激增。例如微博热搜的爆点。
2,上游系统的bug导致。
3,恶意的攻击流量。
实现限流的方法很多,一句话来讲,就是限制每秒钟内API可处理的请求量。常见的有以下几种算法:固定窗口计数法、滑动窗口计数法、漏桶算法、令牌桶算法。
02 How - 固定窗口计数法

固定窗口计数法的思路是:
- 将时间划分为固定的窗口大小,例如1s
- 在窗口时间段内,每来一个请求,对计数器加1。
- 当计数器达到设定限制后,该窗口时间内的之后的请求都被丢弃处理。
- 该窗口时间结束后,计数器清零,从新开始计数。
固定窗口计数法是最简单、也最直观的限流算法。但在最坏的情况下,会让通过的请求量是限制数量的两倍,例如,假设限制的是每个窗口5个请求:
- T窗口的前1/2时间 无流量进入,后1/2时间通过5个请求;
- T+1窗口的前 1/2时间 通过5个请求,后1/2时间因达到限制丢弃请求。
- 因此在 T的后1/2和(T+1)的前1/2时间组成的完整窗口内,通过了10个请求。
03 How - 滑动窗口计数法
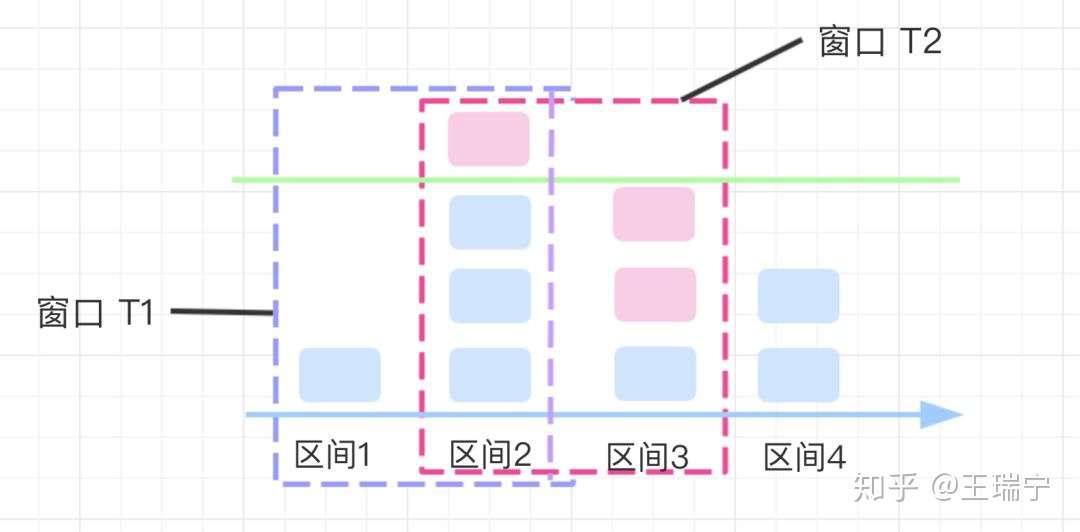
滑动窗口计数法的思路是:
- 将时间划分为细粒度的区间,每个区间维持一个计数器,每进入一个请求则将计数器加一。
- 多个区间组成一个时间窗口,每流逝一个区间时间后,则抛弃最老的一个区间,纳入新区间。如图中示例的窗口T1 变为 窗口T2
- 若当前窗口的区间计数器总和超过设定的限制数量,则本窗口内的后续请求都被丢弃。
04 How - 漏桶算法
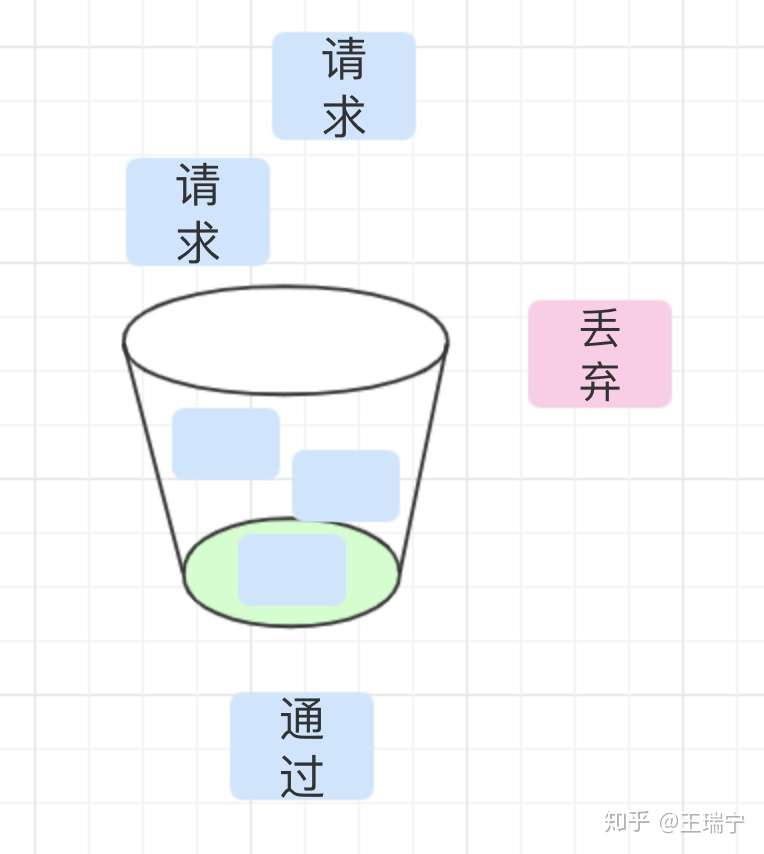
漏桶算法的思路是:
1,每个请求看作“水滴” 一样,放入漏桶中暂存。
2,漏桶以固定的速率,漏出请求来执行;如果漏桶空了,则停止漏水。3,如果漏桶满了,则新来的请求会被丢弃。
很明显,漏桶算法在实现的数据结构会选择有容量限制的队列,请求执行者定期定点从队列取出请求来执行,新来的请求会被暂存在队列中或者被丢弃。
漏桶算法的缺点是,不论当前系统的负载压力如何,所有请求都得进行排队,即便此时服务器负载处于低位。
05 How - 令牌桶算法
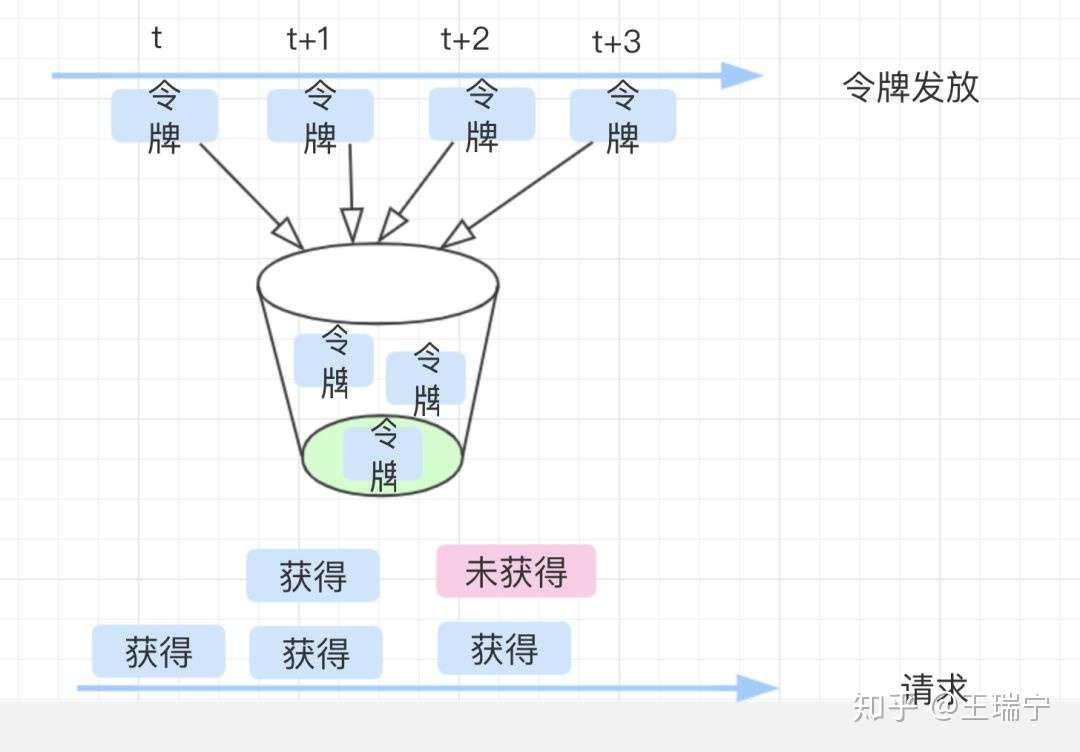
令牌桶算法:
1,令牌按固定速率发放,生成的令牌放入令牌桶中。2,令牌桶有容量限制,当桶满时,新生成的令牌会被丢弃。
3,请求到来时,先从令牌桶中获取令牌,如果取得,则执行请求;如果令牌桶为空,则丢弃该请求。
令牌桶算法可以把请求平均分散在时间段内,是使用较为广发的限流算法。
06 单点应用限流 vs 分布式集群限流
单点应用下,对应用进行限流,既能满足本服务的需求,又可以很好的保护好下游资源。在选型上,可以采用Google Guava的RateLimiter即可。
而在多机部署场景下,对单点的限流,则不能达到最好效果,需要引入分布式限流。分布式限流的算法,依然可以采用令牌桶算法,只不过将令牌桶的发放、存储改为全局的模型。真正实现中,可以采用redis+lua的方式,通过把逻辑放在redis端,来减少调用次数。
lua的逻辑如下:
1,redis中存储剩余令牌的数量cur_token,和上次获取令牌的时间last_time。
2,在每次申请令牌时,可以根据(当前时间cur_time - last_time)的时间差 乘以 令牌发放速率,算出当前可用令牌数。
3,如果有剩余令牌,则准许请求通过;否则不通过。
07 总结
不论出于什么风险,要保证系统的抗压能力,限流是不可缺少的一个环节。
单点应用场景下,常用的算法有固定窗口计数法、滑动窗口计数法、漏桶法、令牌桶法。分布式场景下,需要将限流算法的存储信息全局化,而为了性能和一致性,需要进行深度优化。
Redis实现分布式限流
先看一下limit的lua脚本,需要给脚本传两个值,一个值是限流的key,一个值是限流的数量。获取当前key,然后判断其值是否为nil,如果为nil的话需要赋值为0,然后进行加1并且和limit进行比对,如果大于limt即返回0,说明限流了,如果小于limit则需要使用Redis的INCRBY key 1,就是将key进行加1命令。并且设置超时时间,超时时间是秒,并且如果有需要的话这个秒也是可以用参数进行设置。

--lua 下标从 1 开始
-- 限流 key
local key = KEYS[1]
-- 限流大小
local limit = tonumber(ARGV[1])
-- 获取当前流量大小
local curentLimit = tonumber(redis.call('get', key) or "0")
if curentLimit + 1 > limit then
-- 达到限流大小 返回
return 0;
else
-- 没有达到阈值 value + 1
redis.call("INCRBY", key, 1)
-- EXPIRE后边的单位是秒
redis.call("EXPIRE", key, 10)
return curentLimit + 1
end
执行limit的脚本和执行lock的脚本类似。
package com.hqs.distributedlock.limit;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.RedisScript;
import org.springframework.stereotype.Component;
import java.util.Collections;
/**
* @author huangqingshi
* @Date 2019-01-17
*/
@Slf4j
@Component
public class DistributedLimit {
//注意RedisTemplate用的String,String,后续所有用到的key和value都是String的
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
RedisScript<Long> limitScript;
public Boolean distributedLimit(String key, String limit) {
Long id = 0L;
try {
id = redisTemplate.execute(limitScript, Collections.singletonList(key),
limit);
log.info("id:{}", id);
} catch (Exception e) {
log.error("error", e);
}
if(id == 0L) {
return false;
} else {
return true;
}
}
}
接下来咱们写一个限流注解,并且设置注解的key和限流的大小:
package com.hqs.distributedlock.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 自定义limit注解
* @author huangqingshi
* @Date 2019-01-17
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface DistriLimitAnno {
public String limitKey() default "limit";
public int limit() default 1;
}
然后对注解进行切面,在切面中判断是否超过limit,如果超过limit的时候就需要抛出异常exceeded limit,否则正常执行。
package com.hqs.distributedlock.aspect;
import com.hqs.distributedlock.annotation.DistriLimitAnno;
import com.hqs.distributedlock.limit.DistributedLimit;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
/**
* @author huangqingshi
* @Date 2019-01-17
*/
@Slf4j
@Aspect
@Component
@EnableAspectJAutoProxy(proxyTargetClass = true)
public class LimitAspect {
@Autowired
DistributedLimit distributedLimit;
@Pointcut("@annotation(com.hqs.distributedlock.annotation.DistriLimitAnno)")
public void limit() {};
@Before("limit()")
public void beforeLimit(JoinPoint joinPoint) throws Exception {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
DistriLimitAnno distriLimitAnno = method.getAnnotation(DistriLimitAnno.class);
String key = distriLimitAnno.limitKey();
int limit = distriLimitAnno.limit();
Boolean exceededLimit = distributedLimit.distributedLimit(key, String.valueOf(limit));
if(!exceededLimit) {
throw new RuntimeException("exceeded limit");
}
}
}
因为有抛出异常,这里我弄了一个统一的controller错误处理,如果controller出现Exception的时候都需要走这块异常。如果是正常的RunTimeException的时候获取一下,否则将异常获取一下并且输出。
package com.hqs.distributedlock.util;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.HttpStatus;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.ResponseStatus;
import org.springframework.web.context.request.NativeWebRequest;
import javax.servlet.http.HttpServletRequest;
import java.util.HashMap;
import java.util.Map;
/**
* @author huangqingshi
* @Date 2019-01-17
* 统一的controller错误处理
*/
@Slf4j
@ControllerAdvice
public class UnifiedErrorHandler {
private static Map<String, String> res = new HashMap<>(2);
@ExceptionHandler(value = Exception.class)
@ResponseStatus(HttpStatus.OK)
@ResponseBody
public Object processException(HttpServletRequest req, Exception e) {
res.put("url", req.getRequestURL().toString());
if(e instanceof RuntimeException) {
res.put("mess", e.getMessage());
} else {
res.put("mess", "sorry error happens");
}
return res;
}
}
好了,接下来将注解写到自定义的controller上,limit的大小为10,也就是10秒钟内限制10次访问。
@PostMapping("/distributedLimit")
@ResponseBody
@DistriLimitAnno(limitKey="limit", limit = 10)
public String distributedLimit(String userId) {
log.info(userId);
return "ok";
}
也是来一段Test方法来跑,老方式100个线程开始跑,只有10次,其他的都是limit。没有问题。
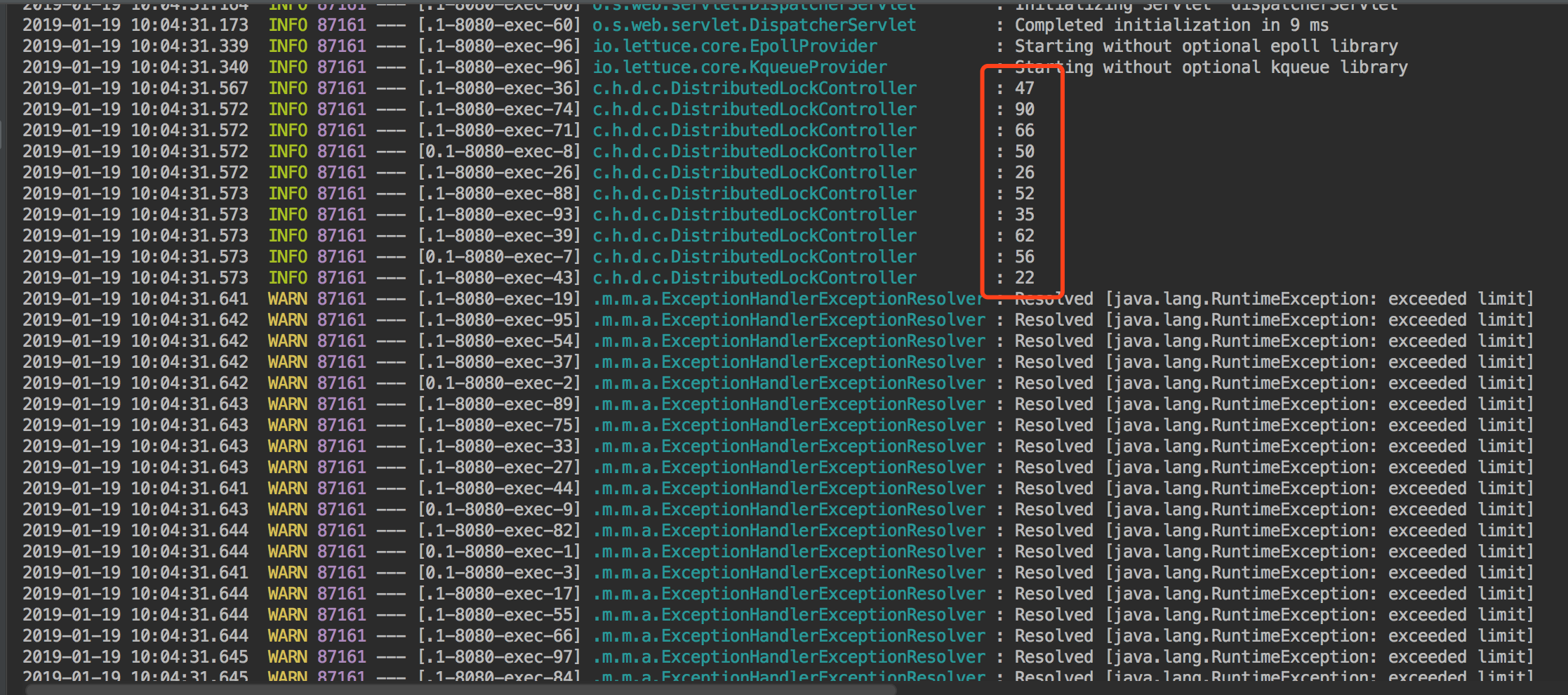
总结一下,这次实现采用了使用lua脚本和Redis实现了锁和限流,但是真实使用的时候还需要多测试,另外如果此次Redis也是采用的单机实现方法,使用集群的时候可能需要改造一下。关于锁这块其实Reids他们自己也实现了RedLock, java实现的版本Redission。也有很多公司使用了,功能非常强大。各种场景下都用到了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号