
布隆过滤器(Bloom Filter)详解
参考:
https://blog.csdn.net/pipisorry/article/details/62443757
https://www.cnblogs.com/liyulong1982/p/6013002.html
https://blog.csdn.net/pipisorry/article/details/64127666
BitMap算法
http://blog.csdn.net/pipisorry/article/details/62443757
BitMap
BitMap从字面的意思,很多人认为是位图,其实准确的来说,翻译成基于位的映射。
在所有具有性能优化的数据结构中,大家使用最多的就是hash表,是的,在具有定位查找上具有O(1)的常量时间,多么的简洁优美。但是数据量大了,内存就不够了。
当然也可以使用类似外排序来解决问题的,由于要走IO所以时间上又不行。
所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
其实如果你知道计数排序的话(算法导论中有一节讲过),你就会发现这个和计数排序很像。
bitmap应用
1)可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下。
2)去重数据而达到压缩数据
还可以用于爬虫系统中url去重、解决全组合问题。
BitMap应用:排序示例
假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0(如下图:)
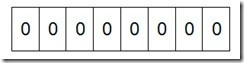
然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作 p+(i/8)|(0×01<<(i%8)) 当然了这里的操作涉及到Big-ending和Little-ending的情况,这里默认为Big-ending。不过计算机一般是小端存储的,如intel。小端的话就是将倒数第5位置1),因为是从零开始的,所以要把第五位置为一(如下图):
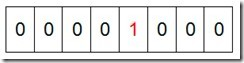
然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
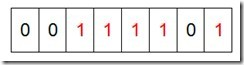
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。
bitmap排序复杂度分析
Bitmap排序需要的时间复杂度和空间复杂度依赖于数据中最大的数字。
bitmap排序的时间复杂度不是O(N)的,而是取决于待排序数组中的最大值MAX,在实际应用上关系也不大,比如我开10个线程去读byte数组,那么复杂度为:O(Max/10)。也就是要是读取的,可以用多线程的方式去读取。时间复杂度方面也是O(Max/n),其中Max为byte[]数组的大小,n为线程大小。
空间复杂度应该就是O(Max/8)bytes吧
BitMap算法流程
假设需要排序或者查找的最大数MAX=10000000(lz:这里MAX应该是最大的数而不是int数据的总数!),那么我们需要申请内存空间的大小为int a[1 + MAX/32]。
其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:
bitmap表为:
a[0]--------->0-31
a[1]--------->32-63
a[2]--------->64-95
a[3]--------->96-127
..........
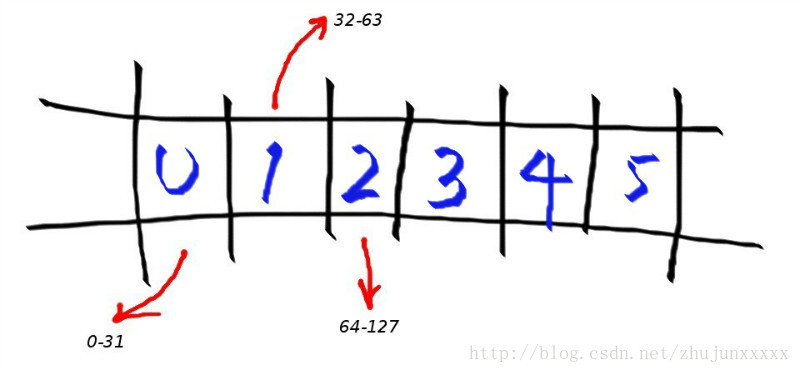
我们要把一个整数N映射到Bit-Map中去,首先要确定把这个N Mapping到哪一个数组元素中去,即确定映射元素的index。我们用int类型的数组作为map的元素,这样我们就知道了一个元素能够表示的数字个数(这里是32)。于是N/32就可以知道我们需要映射的key了。所以余下来的那个N%32就是要映射到的位数。
1.求十进制数对应在数组a中的下标:
先由十进制数n转换为与32的余可转化为对应在数组a中的下标。
如十进制数0-31,都应该对应在a[0]中,比如n=24,那么 n/32=0,则24对应在数组a中的下标为0。又比如n=60,那么n/32=1,则60对应在数组a中的下标为1,同理可以计算0-N在数组a中的下标。
i = N>>K % 结果就是N/(2^K)
Note: map的范围是[0, 原数组最大的数对应的2的整次方数-1]。
2.求十进制数对应数组元素a[i]在0-31中的位m:
十进制数0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得对应0-31中的数。
m = n & ((1 << K) - 1) %结果就是n%(2^K)
3.利用移位0-31使得对应第m个bit位为1
如a[i]的第m位置1:a[i] = a[i] | (1<<m)
如:将当前4对应的bit位置1的话,只需要1左移4位与B[0] | 即可。

Note: 1 p+(i/8)|(0×01<<(i%8))这样也可以?
2 同理将int型变量a的第k位清0,即a=a&~(1<<k)
[编程珠玑]
BitMap算法评价
优点:
1. 运算效率高,不进行比较和移位;
2. 占用内存少,比如最大的数MAX=10000000;只需占用内存为MAX/8=1250000Byte=1.25M。
缺点:
1. 所有的数据不能重复,即不可对重复的数据进行排序。(少量重复数据查找还是可以的,用2-bitmap)。
2. 当数据类似(1,1000,10万)只有3个数据的时候,用bitmap时间复杂度和空间复杂度相当大,只有当数据比较密集时才有优势。
BitMap算法的拓展
Bloom filter可以看做是对bit-map的扩展。更大数据量的有一定误差的用来判断映射是否重复的算法。[Bloom Filter布隆过滤器]
问题及应用实例
1 使用位图法判断整形数组是否存在重复
判断集合中存在重复是常见编程任务之一,当集合中数据量比较大时我们通常希望少进行几次扫描,这时双重循环法就不可取了。
位图法比较适合于这种情况,它的做法是按照集合中最大元素max创建一个长度为max+1的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上1,如遇到 5就给新数组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这说明这次的数据肯定和以前的数据存在着重复。这种给新数组初始化时置零其后置一的做法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最大值即能事先给新数组定长的话效率还能提高一倍。
2 在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数
解法一:将bit-map扩展一下,采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
[c++直接实现代码大数据:查找不重复的整数 ]
或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
解法二:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
解法三:(lz)类似解法2,只是划分时按照快排partition一样划分,直到划分到每个块都可以放入内存中。
[c实现]
2.1 一个序列里除了一个元素,其他元素都会重复出现3次,设计一个时间复杂度与空间复杂度最低的算法,找出这个不重复的元素。
3 已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)
lz觉得这个是应该用计数排序类似的算法吧,而不是bitmap?
4 给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
解析:bitmap算法就好办多了。申请512M的内存,一个bit位代表一个unsigned int值,读入40亿个数,设置相应的bit位;读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
Note: unsigned int最大数为2^32 - 1,所以需要2^32 - 1个位,也就是(2^32 - 1) / 8 /10 ^ 9G = 0.5G内存。
逆向思维优化:usinged int只有接近43亿(unsigned int最大值为232-1=4294967295,最大不超过43亿),所以可以用某种方式存没有出现过的3亿个数(使用数组{大小为3亿中最大的数/8 bytes}存储),如果出现在3亿个数里面,说明不在40亿里面。3亿个数存储空间一般小于40亿个。(xx存储4294967296需要512MB, 存储294967296只需要35.16MBxx)
5 给定一个数组a,求所有和为SUM的两个数。
如果数组都是整数(负数也可以,将所有数据加上最小的负数x,SUM += 2x就可以了)。如a = [1,2,3,4,7,8],先求a的补数组[8,7,6,5,2,1],开辟两个数组b1,b2(最大数组长度为SUM/8/2{因为两数满足和为SUM,一个数<SUM/2,另一个数也就知道了},这样每个b数组最大内存为SUM/(8*2*1024*1024) = 128M),使用bitmap算法和数组a分别设置b1b2对应的位为1,b1b2相与就可以得到和为SUM的两个数其中一个数了。

BitMap的实现
Python
lz写的一个比较好的实现
import os, sys, array
CWD = os.path.split(os.path.realpath(__file__))[0]
sys.path.append(os.path.join(CWD, '../..'))
def power2n(x):
'''
求比x大且是2的n次方的数
'''
for i in (1, 2, 4, 8, 16, 32): # 支持到64位int型,加上64则可以支持到128等等
x |= x >> i
# print(x + 1)
return x + 1
class BitMap():
def __init__(self):
self.K = 5
self.BIT_NUM = 1 << self.K
self.BIT_TYPE = 'I' # 32位unsighed int存储位。note:可能8位char存储对小数据更好一丢丢
self.shift = 0 # 如果数组中有<0的数,则所有数都要减去最小的那个负数
def fit(self, x):
'''
将数据读入bitmap中存储
'''
MIN_NUM = min(x)
if MIN_NUM < 0:
self.shift = -MIN_NUM # 如果数组中有<0的数,则所有数都要减去最小的那个负数
x = [i + self.shift for i in x]
else:
self.shift = 0
MAX_NUM = max(x)
num_int = power2n(MAX_NUM) >> self.K
num_int = num_int if num_int > 0 else 1 # 至少应该有一个数组
# print(num_int)
self.a = array.array(self.BIT_TYPE, [0] * num_int)
for xi in x:
self.set(xi)
def set(self, xi, value=1):
'''
设置数xi在数组a中对应元素对应的位为1
'''
array_ix = xi >> self.K # 数组的元素位置(从0开始)
bit_ix = xi & ((1 << self.K) - 1) # 数组元素中的bit位置(从0开始),取模
if value == 1:
self.a[array_ix] |= 1 << bit_ix # 对应的第bit_ix位置的2**bit_ix置1
else:
self.a[array_ix] &= ~((1 << bit_ix)) # 对应的第bit_ix位置的2**bit_ix置0
def show_array(self):
for ai in self.a:
print('{:032b}'.format(ai)) # bin(ai)
def search(self, xi):
'''
bitmap查找
'''
if self.shift != 0:
xi += self.shift
array_ix = xi >> self.K
bit_ix = xi & ((1 << self.K) - 1)
if (self.a[array_ix] & (1 << bit_ix)):
flag = True
else:
flag = False
return flag
def sort(self):
'''
bitmap排序
'''
sorted_x = []
for array_ix, ai in enumerate(self.a):
for bit_ix in range(self.BIT_NUM):
# 首先得到该第j位的掩码(0x01<<j),将内存区中的,位和此掩码作与操作。最后判断掩码是否和处理后的结果相同
if (ai & (1 << bit_ix)) == (1 << bit_ix):
sorted_x.append(self.BIT_NUM * array_ix + bit_ix)
# print(sorted_x)
if self.shift != 0:
sorted_x = [i - self.shift for i in sorted_x]
return sorted_x
def test():
bm = BitMap()
bm.fit([-3, -44, 7, 2, 5, 3, 32])
bm.show_array()
print(bm.search(7))
print(bm.search(6))
print(bm.sort())
test()
00000000000000000000000000000001
00000000000010101100001000000000
00000000000000000001000000000000
00000000000000000000000000000000
True
False
[-44, -3, 2, 3, 5, 7, 32]
Python package[bitsets 0.7.9]
Python 实现类似C++的bitset类:[Python 实现类似C++的bitset类 ]
C/C++
c++有bitset模块
也可以自己实现:[海量数据处理算法—Bit-Map ]
Java
其实某些语言是对BitMap算法进行了封装的,比如java中对应BitMap的数据结构就有BitSet类。其使用方法相当简单,看看API就ok,还是给个例子吧:
import java.util.BitSet;
public class Test{
public static void main(String[] args) {
int [] array = new int [] {1,2,3,22,0,3};
BitSet bitSet = new BitSet(6);
//将数组内容组bitmap
for(int i=0;i<array.length;i++)
{
bitSet.set(array[i], true);
}
System.out.println(bitSet.size());
System.out.println(bitSet.get(3));
}
}
对应的bit位如果有对应整数那么通过bitSet.get(x)会返回true,反之false。其中x为BitMap位置下标。
from: http://blog.csdn.net/pipisorry/article/details/62443757
ref: [经典算法题每日演练——第十一题 Bitmap算法]
布隆过滤器(Bloom Filter)详解
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中。
和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。
算法:
1. 首先需要k个hash函数,每个函数可以把key散列成为1个整数
2. 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
优点:不需要存储key,节省空间
缺点:
1. 算法判断key在集合中时,有一定的概率key其实不在集合中
2. 无法删除
典型的应用场景:
某些存储系统的设计中,会存在空查询缺陷:当查询一个不存在的key时,需要访问慢设备,导致效率低下。
比如一个前端页面的缓存系统,可能这样设计:先查询某个页面在本地是否存在,如果存在就直接返回,如果不存在,就从后端获取。但是当频繁从缓存系统查询一个页面时,缓存系统将会频繁请求后端,把压力导入后端。
这是只要增加一个bloom算法的服务,后端插入一个key时,在这个服务中设置一次
需要查询后端时,先判断key在后端是否存在,这样就能避免后端的压力。

布隆过滤器[1](Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它实际上是由一个很长的二进制向量和一系列随机映射函数组成,布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率(假正例False positives,即Bloom Filter报告某一元素存在于某集合中,但是实际上该元素并不在集合中)和删除困难,但是没有识别错误的情形(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。
在日常生活中,包括在设计计算机软件时,我们经常要判断一个元素是否在一个集合中。比如在字处理软件中,需要检查一个英语单词是否拼写正确(也就是要判断 它是否在已知的字典中);在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上;在网络爬虫里,一个网址是否被访问过等等。最直接的方法就是将集合中全部的元素存在计算机中,遇到一个新 元素时,将它和集合中的元素直接比较即可。一般来讲,计算机中的集合是用哈希表(hash table)来存储的。它的好处是快速准确,缺点是费存储空间。当集合比较小时,这个问题不显著,但是当集合巨大时,哈希表存储效率低的问题就显现出来 了。比如说,一个象 Yahoo,Hotmail 和 Gmai 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。如果用哈希表,每存储一亿 个 email 地址, 就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹(详见:googlechinablog.com/2006/08/blog-post.html), 然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB, 即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。除非是超级计算机,一般服务器是无法存储的[2]。(该段引用谷歌数学之美:http://www.google.com.hk/ggblog/googlechinablog/2007/07/bloom-filter_7469.html)
基本概念
如果想判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。
Hash面临的问题就是冲突。假设 Hash 函数是良好的,如果我们的位阵列长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100 个元素。显然这就不叫空间有效了(Space-efficient)。解决方法也简单,就是使用多个 Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash 函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器可以表示全集,其它任何数据结构都不能;
k 和 m 相同,使用同一组 Hash 函数的两个布隆过滤器的交并差运算可以使用位操作进行。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素. 我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
False positives 概率推导
假设 Hash 函数以等概率条件选择并设置 Bit Array 中的某一位,m 是该位数组的大小,k 是 Hash 函数的个数,那么位数组中某一特定的位在进行元素插入时的 Hash 操作中没有被置位的概率是:

那么在所有 k 次 Hash 操作后该位都没有被置 "1" 的概率是:

如果我们插入了 n 个元素,那么某一位仍然为 "0" 的概率是:

因而该位为 "1"的概率是:

现在检测某一元素是否在该集合中。标明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 "1",但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),该概率由以下公式确定:

其实上述结果是在假定由每个 Hash 计算出需要设置的位(bit) 的位置是相互独立为前提计算出来的,不难看出,随着 m (位数组大小)的增加,假正例(False Positives)的概率会下降,同时随着插入元素个数 n 的增加,False Positives的概率又会上升,对于给定的m,n,如何选择Hash函数个数 k 由以下公式确定:

此时False Positives的概率为:

而对于给定的False Positives概率 p,如何选择最优的位数组大小 m 呢,

上式表明,位数组的大小最好与插入元素的个数成线性关系,对于给定的 m,n,k,假正例概率最大为:

下图是布隆过滤器假正例概率 p 与位数组大小 m 和集合中插入元素个数 n 的关系图,假定 Hash 函数个数选取最优数目:

Bloom Filter 用例
Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数[3]。
Squid 网页代理缓存服务器在 cache digests 中使用了也布隆过滤器[4]。
Venti 文档存储系统也采用布隆过滤器来检测先前存储的数据[5]。
SPIN 模型检测器也使用布隆过滤器在大规模验证问题时跟踪可达状态空间[6]。
Google Chrome浏览器使用了布隆过滤器加速安全浏览服务[7]。
在很多Key-Value系统中也使用了布隆过滤器来加快查询过程,如 Hbase,Accumulo,Leveldb,一般而言,Value 保存在磁盘中,访问磁盘需要花费大量时间,然而使用布隆过滤器可以快速判断某个Key对应的Value是否存在,因此可以避免很多不必要的磁盘IO操作,只是引入布隆过滤器会带来一定的内存消耗,下图是在Key-Value系统中布隆过滤器的典型使用:

布隆过滤器相关扩展
Counting filters
基本的布隆过滤器不支持删除(Deletion)操作,但是 Counting filters 提供了一种可以不用重新构建布隆过滤器但却支持元素删除操作的方法。在Counting filters中原来的位数组中的每一位由 bit 扩展为 n-bit 计数器,实际上,基本的布隆过滤器可以看作是只有一位的计数器的Counting filters。原来的插入操作也被扩展为把 n-bit 的位计数器加1,查找操作即检查位数组非零即可,而删除操作定义为把位数组的相应位减1,但是该方法也有位的算术溢出问题,即某一位在多次删除操作后可能变成负值,所以位数组大小 m 需要充分大。另外一个问题是Counting filters不具备伸缩性,由于Counting filters不能扩展,所以需要保存的最大的元素个数需要提前知道。否则一旦插入的元素个数超过了位数组的容量,false positive的发生概率将会急剧增加。当然也有人提出了一种基于 D-left Hash 方法实现支持删除操作的布隆过滤器,同时空间效率也比Counting filters高。
Data synchronization
Byers等人提出了使用布隆过滤器近似数据同步[9]。
Bloomier filters
Chazelle 等人提出了一个通用的布隆过滤器,该布隆过滤器可以将某一值与每个已经插入的元素关联起来,并实现了一个关联数组Map[10]。与普通的布隆过滤器一样,Chazelle实现的布隆过滤器也可以达到较低的空间消耗,但同时也会产生false positive,不过,在Bloomier filter中,某 key 如果不在 map 中,false positive在会返回时会被定义出的。该Map 结构不会返回与 key 相关的在 map 中的错误的值。
Compact approximators[11]
Stable Bloom filters[12]
Scalable Bloom filters[13]
Attenuated Bloom filters[14]
Bloom Filter布隆过滤器
http://blog.csdn.net/pipisorry/article/details/64127666
Bloom Filter简介
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。
Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。BF其中的元素越多,false positive rate(误报率)越大,但是false negative (漏报)是不可能的。
在计算机科学中,我们常常会碰到时间换空间或者空间换时间的情况,即为了达到某一个方面的最优而牺牲另一个方面。Bloom Filter在时间空间这两个因素之外又引入了另一个因素:错误率。在使用Bloom Filter判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。
Bloom Filter的应用
可以用来实现数据字典,进行数据的判重,或者集合求交集。在垃圾邮件过滤的黑白名单方法、爬虫(Crawler)的网址判重模块中等等经常被用到。
Bloom Filter就被广泛用于拼写检查和数据库系统中。
Bloom Filter在网络领域获得了新生,各种Bloom Filter变种和新的应用不断出现。
集合表示和元素查询
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。
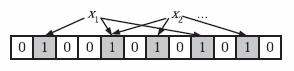
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。
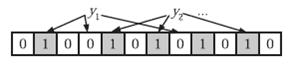
错误率f估计
Note: 这个错误率f是将不属于本集合的元素引进来的概率。如果外集有(u-n)个元素,则有(u-n)f个外元素可能被引进来。
假设:布隆过滤器中的hash function满足simple uniform hashing假设:每个元素都等概率地hash到m个slot中的任何一个,与其它元素被hash到哪个slot无关。
前面我们已经提到了,Bloom Filter在判断一个元素是否属于它表示的集合时会有一定的错误率(false positive rate),下面我们就来估计错误率的大小。在估计之前为了简化模型,我们假设kn<m且各个哈希函数是完全随机的。当集合S={x1, x2,…,xn}的所有元素都被k个哈希函数映射到m位的位数组中时,这个位数组中某一位还是0的概率是:
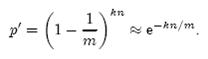
Note: m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)
其中1/m表示任意一个哈希函数选中这一位的概率(前提是哈希函数是完全随机的),(1-1/m)表示哈希一次没有选中这一位的概率。要把S完全映射到位数组中,需要做kn次哈希。某一位还是0意味着kn次哈希都没有选中它,因此这个概率就是(1-1/m)的kn次方。令p = e-kn/m是为了简化运算,这里用到了计算e时常用的近似:
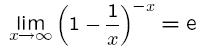
令ρ为位数组中0的比例,则ρ的数学期望E(ρ)= p’。在ρ已知的情况下,要求的错误率(false positive rate)为:
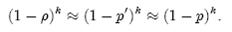
(1-ρ)为位数组中1的比例,(1-ρ)k就表示k次哈希都刚好选中1的区域,即false positive rate。上式中第二步近似在前面已经提到了,现在来看第一步近似。p’只是ρ的数学期望,在实际中ρ的值有可能偏离它的数学期望值。M. Mitzenmacher已经证明[2] ,位数组中0的比例非常集中地分布在它的数学期望值的附近。因此,第一步的近似得以成立。分别将p和p’代入上式中,得:
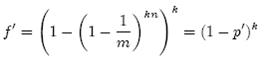
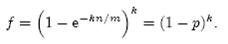
相比p’和f’,使用p和f通常在分析中更为方便。
最优的哈希函数个数k
既然Bloom Filter要靠多个哈希函数将集合映射到位数组中,那么应该选择几个哈希函数才能使元素查询时的错误率降到最低呢?这里有两个互斥的理由:如果哈希函数的个数多,那么在对一个不属于集合的元素进行查询时得到0的概率就大;但另一方面,如果哈希函数的个数少,那么位数组中的0就多。为了得到最优的哈希函数个数,我们需要根据上一小节中的错误率公式进行计算。
先用p和f进行计算。注意到f = exp(k ln(1 − e−kn/m)),我们令g = ln(f),只要让g取到最小,f自然也取到最小。由于p = e-kn/m,我们可以将g写成
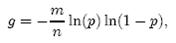
根据对称性法则可以很容易看出当p = 1/2,也就是k = ln2· (m/n)时,g取得最小值。在这种情况下,最小错误率f等于(1/2)^k = ((1/2)^ln2) ^(m/n)≈ (0.6185)^(m/n)。另外,注意到p是位数组中某一位仍是0的概率,所以p = 1/2对应着位数组中0和1各一半。换句话说,要想保持错误率低,最好让位数组有一半还空着。
需要强调的一点是,p = 1/2时错误率最小这个结果并不依赖于近似值p和f。同样对于f’ = exp(k ln(1 − (1 − 1/m)kn)),g’ = k ln(1 − (1 − 1/m)kn),p’ = (1 − 1/m)kn,我们可以将g’写成
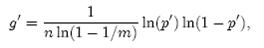
同样根据对称性法则可以得到当p’ = 1/2时,g’取得最小值。
位数组的大小m
下面我们来看看,在不超过一定错误率的情况下,Bloom Filter至少需要多少位才能表示全集中任意n个元素的集合。
{表示任意n个元素的集合的最小m数的推导
假设全集中共有u个元素,允许的最大错误率为є,下面我们来求位数组的位数m。
假设X为全集中任取n个元素的集合,F(X)是表示X的位数组。那么对于集合X中任意一个元素x,在s = F(X)中查询x都能得到肯定的结果,即s能够接受x。显然,由于Bloom Filter引入了错误,s能够接受的不仅仅是X中的元素,它还能够接受є (u - n)个false positive。因此,对于一个确定的位数组来说,它能够接受总共n + є (u - n)个元素。在n + є (u - n)个元素中,s真正表示的只有其中n个,所以一个确定的位数组可以表示
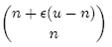
个集合。m位的位数组共有2m个不同的组合,进而可以推出,m位的位数组可以表示
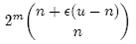
个集合。全集中n个元素的集合总共有
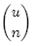
个,因此要让m位的位数组能够表示所有n个元素的集合,必须有
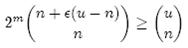
即:
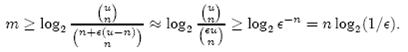
上式中的近似前提是n和єu相比很小,这也是实际情况中常常发生的。
根据上式,我们得出结论:在错误率不大于є的情况下,m至少要等于n log2(1/є)才能表示任意n个元素的集合。
}
上一小节中我们曾算出当k = ln2· (m/n)时错误率f最小,这时f = (1/2)^k = (1/2)^((mln2) / n)。现在令f≤є,可以推出
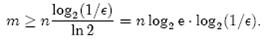
这个结果比前面我们算得的下界n log2(1/є)大了log2 e ≈ 1.44倍。这说明在哈希函数的个数取到最优时,要让错误率不超过є,m至少需要取到最小值的1.44倍。
总结来说就是,当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于є的情况下,m至少要等于n*lg(1/є)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/є)*lge,即m/n = -lnp/(ln2)^2 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子
我们假设错误率为0.01,则此时m应大概是n的9.6倍。这样k大概是7个{6.64个}。 (m应大概是n的13倍。这样k大概是8个。这个计算是错的应该)。
对于一个有1%误报率和一个最优k值的布隆过滤器来说,无论元素的类型及大小,每个元素只需要9.6 bits(m/n=9.6)来存储。这个优点一部分继承自array的紧凑性,一部分来源于它的概率性。如果你认为1%的误报率太高,那么对每个元素每增加4.8 bits {m/n = -ln(p/10)/(ln2)^2 = -lnp/(ln2)^2)+ln(10)/(ln2)^2 = -lnp/(ln2)^2)+4.8},我们就可将误报率降低为原来的1/10。[布隆过滤器 (Bloom Filter) 详解]
[推导参考wikipedia Bloom filter]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号