
分布式锁的几种解决方案
参考:
https://www.jianshu.com/p/a1ebab8ce78a
https://www.cnblogs.com/moxiaotao/p/10829799.html
https://www.cnblogs.com/wlwl/p/11651409.html
https://www.cnblogs.com/austinspark-jessylu/p/8043726.html
https://blog.csdn.net/wuzhiwei549/article/details/80692278
什么是分布式锁
概述
为了防止分布式系统中的多个进程之间相互干扰,我们需要一种分布式协调技术来对这些进程进行调度。而这个分布式协调技术的核心就是来实现这个分布式锁。
为什么要使用分布式锁
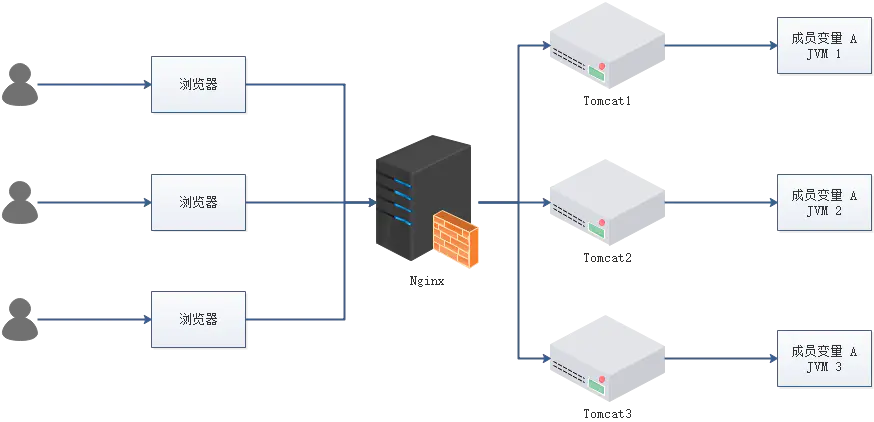

- 成员变量 A 存在 JVM1、JVM2、JVM3 三个 JVM 内存中
- 成员变量 A 同时都会在 JVM 分配一块内存,三个请求发过来同时对这个变量操作,显然结果是不对的
- 不是同时发过来,三个请求分别操作三个不同 JVM 内存区域的数据,变量 A 之间不存在共享,也不具有可见性,处理的结果也是不对的
注:该成员变量 A 是一个有状态的对象
如果我们业务中确实存在这个场景的话,我们就需要一种方法解决这个问题,这就是分布式锁要解决的问题
分布式锁应该具备哪些条件
- 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行
- 高可用的获取锁与释放锁
- 高性能的获取锁与释放锁
- 具备可重入特性(可理解为重新进入,由多于一个任务并发使用,而不必担心数据错误)
- 具备锁失效机制,防止死锁
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
分布式锁的实现有哪些
- Memcached:利用 Memcached 的
add命令。此命令是原子性操作,只有在key不存在的情况下,才能add成功,也就意味着线程得到了锁。 - Redis:和 Memcached 的方式类似,利用 Redis 的
setnx命令。此命令同样是原子性操作,只有在key不存在的情况下,才能set成功。 - Zookeeper:利用 Zookeeper 的顺序临时节点,来实现分布式锁和等待队列。Zookeeper 设计的初衷,就是为了实现分布式锁服务的。
- Chubby:Google 公司实现的粗粒度分布式锁服务,底层利用了 Paxos 一致性算法。
通过 Redis 分布式锁的实现理解基本概念
分布式锁实现的三个核心要素:
加锁
最简单的方法是使用 setnx 命令。key 是锁的唯一标识,按业务来决定命名。比如想要给一种商品的秒杀活动加锁,可以给 key 命名为 “lock_sale_商品ID” 。而 value 设置成什么呢?我们可以姑且设置成 1。加锁的伪代码如下:
setnx(lock_sale_商品ID,1)
当一个线程执行 setnx 返回 1,说明 key 原本不存在,该线程成功得到了锁;当一个线程执行 setnx 返回 0,说明 key 已经存在,该线程抢锁失败。
解锁
有加锁就得有解锁。当得到锁的线程执行完任务,需要释放锁,以便其他线程可以进入。释放锁的最简单方式是执行 del 指令,伪代码如下:
del(lock_sale_商品ID)
释放锁之后,其他线程就可以继续执行 setnx 命令来获得锁。
锁超时
锁超时是什么意思呢?如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住(死锁),别的线程再也别想进来。所以,setnx 的 key 必须设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放。setnx 不支持超时参数,所以需要额外的指令,伪代码如下:
expire(lock_sale_商品ID, 30)
综合伪代码如下:
if(setnx(lock_sale_商品ID,1) == 1){
expire(lock_sale_商品ID,30)
try {
do something ......
} finally {
del(lock_sale_商品ID)
}
}
存在什么问题
以上伪代码中存在三个致命问题
setnx 和 expire 的非原子性
设想一个极端场景,当某线程执行 setnx,成功得到了锁:


setnx 刚执行成功,还未来得及执行 expire 指令,节点 1 挂掉了。
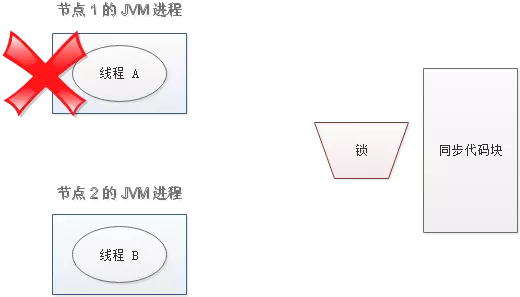

这样一来,这把锁就没有设置过期时间,变成死锁,别的线程再也无法获得锁了。
怎么解决呢?setnx 指令本身是不支持传入超时时间的,set 指令增加了可选参数,伪代码如下:
set(lock_sale_商品ID,1,30,NX)
这样就可以取代 setnx 指令。
del 导致误删
又是一个极端场景,假如某线程成功得到了锁,并且设置的超时时间是 30 秒。


如果某些原因导致线程 A 执行的很慢很慢,过了 30 秒都没执行完,这时候锁过期自动释放,线程 B 得到了锁。
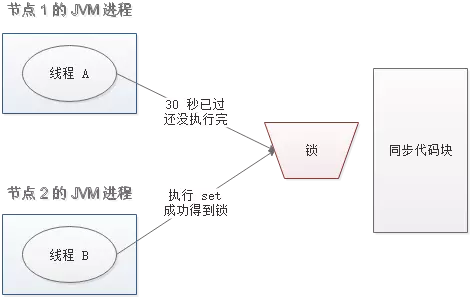

随后,线程 A 执行完了任务,线程 A 接着执行 del 指令来释放锁。但这时候线程 B 还没执行完,线程A实际上 删除的是线程 B 加的锁。


怎么避免这种情况呢?可以在 del 释放锁之前做一个判断,验证当前的锁是不是自己加的锁。至于具体的实现,可以在加锁的时候把当前的线程 ID 当做 value,并在删除之前验证 key 对应的 value 是不是自己线程的 ID。
加锁:
String threadId = Thread.currentThread().getId()
set(key,threadId ,30,NX)
解锁:
if(threadId .equals(redisClient.get(key))){
del(key)
}
但是,这样做又隐含了一个新的问题,判断和释放锁是两个独立操作,不是原子性。
出现并发的可能性
还是刚才第二点所描述的场景,虽然我们避免了线程 A 误删掉 key 的情况,但是同一时间有 A,B 两个线程在访问代码块,仍然是不完美的。怎么办呢?我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁“续航”。
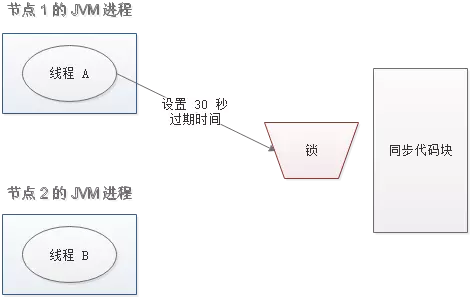

当过去了 29 秒,线程 A 还没执行完,这时候守护线程会执行 expire 指令,为这把锁“续命”20 秒。守护线程从第 29 秒开始执行,每 20 秒执行一次。
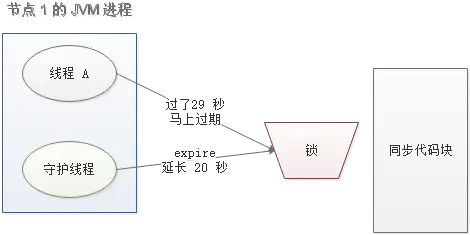

当线程 A 执行完任务,会显式关掉守护线程。
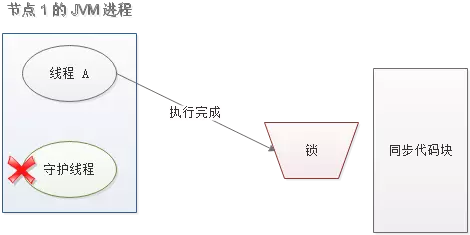

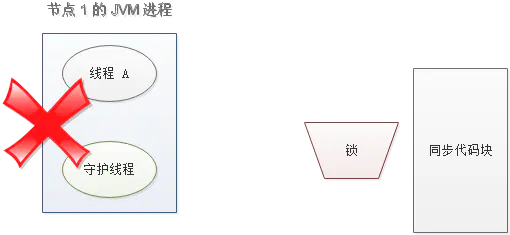
另一种情况,如果节点 1 忽然断电,由于线程 A 和守护线程在同一个进程,守护线程也会停下。这把锁到了超时的时候,没人给它续命,也就自动释放了。

作者:撸帝
链接:https://www.jianshu.com/p/a1ebab8ce78a
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Redis分布式锁的正确实现方式
前言
分布式锁一般有三种实现方式:1. 数据库乐观锁;2. 基于Redis的分布式锁;3. 基于ZooKeeper的分布式锁。本篇博客将介绍第二种方式,基于Redis实现分布式锁。虽然网上已经有各种介绍Redis分布式锁实现的博客,然而他们的实现却有着各种各样的问题,为了避免误人子弟,本篇博客将详细介绍如何正确地实现Redis分布式锁。
可靠性
首先,为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 具有容错性。只要大部分的Redis节点正常运行,客户端就可以加锁和解锁。
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
代码实现
组件依赖
首先我们要通过Maven引入Jedis开源组件,在pom.xml文件加入下面的代码:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
加锁代码
正确姿势
Talk is cheap, show me the code。先展示代码,再带大家慢慢解释为什么这样实现:

public class RedisTool {
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
/**
* 尝试获取分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
可以看到,我们加锁就一行代码:jedis.set(String key, String value, String nxxx, String expx, int time),这个set()方法一共有五个形参:
-
第一个为key,我们使用key来当锁,因为key是唯一的。
-
第二个为value,我们传的是requestId,很多童鞋可能不明白,有key作为锁不就够了吗,为什么还要用到value?原因就是我们在上面讲到可靠性时,分布式锁要满足第四个条件解铃还须系铃人,通过给value赋值为requestId,我们就知道这把锁是哪个请求加的了,在解锁的时候就可以有依据。requestId可以使用
UUID.randomUUID().toString()方法生成。 -
第三个为nxxx,这个参数我们填的是NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作;
-
第四个为expx,这个参数我们传的是PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。
-
第五个为time,与第四个参数相呼应,代表key的过期时间。
总的来说,执行上面的set()方法就只会导致两种结果:1. 当前没有锁(key不存在),那么就进行加锁操作,并对锁设置个有效期,同时value表示加锁的客户端。2. 已有锁存在,不做任何操作。
心细的童鞋就会发现了,我们的加锁代码满足我们可靠性里描述的三个条件。首先,set()加入了NX参数,可以保证如果已有key存在,则函数不会调用成功,也就是只有一个客户端能持有锁,满足互斥性。其次,由于我们对锁设置了过期时间,即使锁的持有者后续发生崩溃而没有解锁,锁也会因为到了过期时间而自动解锁(即key被删除),不会发生死锁。最后,因为我们将value赋值为requestId,代表加锁的客户端请求标识,那么在客户端在解锁的时候就可以进行校验是否是同一个客户端。由于我们只考虑Redis单机部署的场景,所以容错性我们暂不考虑。
错误示例1
比较常见的错误示例就是使用jedis.setnx()和jedis.expire()组合实现加锁,代码如下:
public static void wrongGetLock1(Jedis jedis, String lockKey, String requestId, int expireTime) {
Long result = jedis.setnx(lockKey, requestId);
if (result == 1) {
// 若在这里程序突然崩溃,则无法设置过期时间,将发生死锁
jedis.expire(lockKey, expireTime);
}
}
setnx()方法作用就是SET IF NOT EXIST,expire()方法就是给锁加一个过期时间。乍一看好像和前面的set()方法结果一样,然而由于这是两条Redis命令,不具有原子性,如果程序在执行完setnx()之后突然崩溃,导致锁没有设置过期时间。那么将会发生死锁。网上之所以有人这样实现,是因为低版本的jedis并不支持多参数的set()方法。
错误示例2
public static boolean wrongGetLock2(Jedis jedis, String lockKey, int expireTime) {
long expires = System.currentTimeMillis() + expireTime;
String expiresStr = String.valueOf(expires);
// 如果当前锁不存在,返回加锁成功
if (jedis.setnx(lockKey, expiresStr) == 1) {
return true;
}
// 如果锁存在,获取锁的过期时间
String currentValueStr = jedis.get(lockKey);
if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) {
// 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间
String oldValueStr = jedis.getSet(lockKey, expiresStr);
if (oldValueStr != null && oldValueStr.equals(currentValueStr)) {
// 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才有权利加锁
return true;
}
}
// 其他情况,一律返回加锁失败
return false;
}
这一种错误示例就比较难以发现问题,而且实现也比较复杂。实现思路:使用jedis.setnx()命令实现加锁,其中key是锁,value是锁的过期时间。执行过程:1. 通过setnx()方法尝试加锁,如果当前锁不存在,返回加锁成功。2. 如果锁已经存在则获取锁的过期时间,和当前时间比较,如果锁已经过期,则设置新的过期时间,返回加锁成功。代码如下:
那么这段代码问题在哪里?1. 由于是客户端自己生成过期时间,所以需要强制要求分布式下每个客户端的时间必须同步。 2. 当锁过期的时候,如果多个客户端同时执行jedis.getSet()方法,那么虽然最终只有一个客户端可以加锁,但是这个客户端的锁的过期时间可能被其他客户端覆盖。3. 锁不具备拥有者标识,即任何客户端都可以解锁。
解锁代码
正确姿势
还是先展示代码,再带大家慢慢解释为什么这样实现:
public class RedisTool {
private static final Long RELEASE_SUCCESS = 1L;
/**
* 释放分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @return 是否释放成功
*/
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (RELEASE_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
可以看到,我们解锁只需要两行代码就搞定了!第一行代码,我们写了一个简单的Lua脚本代码,上一次见到这个编程语言还是在《黑客与画家》里,没想到这次居然用上了。第二行代码,我们将Lua代码传到jedis.eval()方法里,并使参数KEYS[1]赋值为lockKey,ARGV[1]赋值为requestId。eval()方法是将Lua代码交给Redis服务端执行。
那么这段Lua代码的功能是什么呢?其实很简单,首先获取锁对应的value值,检查是否与requestId相等,如果相等则删除锁(解锁)。那么为什么要使用Lua语言来实现呢?因为要确保上述操作是原子性的。关于非原子性会带来什么问题,可以阅读【解锁代码-错误示例2】 。那么为什么执行eval()方法可以确保原子性,源于Redis的特性,下面是官网对eval命令的部分解释:

简单来说,就是在eval命令执行Lua代码的时候,Lua代码将被当成一个命令去执行,并且直到eval命令执行完成,Redis才会执行其他命令。
错误示例1
最常见的解锁代码就是直接使用jedis.del()方法删除锁,这种不先判断锁的拥有者而直接解锁的方式,会导致任何客户端都可以随时进行解锁,即使这把锁不是它的。
public static void wrongReleaseLock1(Jedis jedis, String lockKey) {
jedis.del(lockKey);
}
错误示例2
这种解锁代码乍一看也是没问题,甚至我之前也差点这样实现,与正确姿势差不多,唯一区别的是分成两条命令去执行,代码如下:
public static void wrongReleaseLock2(Jedis jedis, String lockKey, String requestId) {
// 判断加锁与解锁是不是同一个客户端
if (requestId.equals(jedis.get(lockKey))) {
// 若在此时,这把锁突然不是这个客户端的,则会误解锁
jedis.del(lockKey);
}
}
如代码注释,问题在于如果调用jedis.del()方法的时候,这把锁已经不属于当前客户端的时候会解除他人加的锁。那么是否真的有这种场景?答案是肯定的,比如客户端A加锁,一段时间之后客户端A解锁,在执行jedis.del()之前,锁突然过期了,此时客户端B尝试加锁成功,然后客户端A再执行del()方法,则将客户端B的锁给解除了。
总结
本文主要介绍了如何使用Java代码正确实现Redis分布式锁,对于加锁和解锁也分别给出了两个比较经典的错误示例。其实想要通过Redis实现分布式锁并不难,只要保证能满足可靠性里的四个条件。互联网虽然给我们带来了方便,只要有问题就可以google,然而网上的答案一定是对的吗?其实不然,所以我们更应该时刻保持着质疑精神,多想多验证。
如果你的项目中Redis是多机部署的,那么可以尝试使用Redisson实现分布式锁,这是Redis官方提供的Java组件,链接在参考阅读章节已经给出。
3种Redis分布式锁的对比
我们通常使用的synchronized或者Lock都是线程锁,对同一个JVM进程内的多个线程有效。因为锁的本质 是内存中存放一个标记,记录获取锁的线程是谁,这个标记对每个线程都可见。然而我们启动的多个订单服务,就是多个JVM,内存中的锁显然是不共享的,每个JVM进程都有自己的 锁,自然无法保证线程的互斥了,这个时候我们就需要使用到分布式锁了。常用的有三种解决方案:1.基于数据库实现 2.基于zookeeper的临时序列化节点实现 3.redis实现。本文我们介绍的就是redis的实现方式。
实现分布式锁要满足3点:多进程可见,互斥,可重入。
1) 多进程可见
redis本身就是基于JVM之外的,因此满足多进程可见的要求。
2) 互斥
即同一时间只能有一个进程获取锁标记,我们可以通过redis的setnx实现,只有第一次执行的才会成功并返回1,其它情况返回0。

释放锁
释放锁其实只需要把锁的key删除即可,使用del xxx指令。不过,如果在我们执行del之前,服务突然宕机,那么锁就永远无法删除了。所以我们可以通过setex 命令设置过期时间即可。
import java.util.UUID;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
/**
* 第一种分布式锁
*/
@Component
public class RedisService {
private final Logger log = LoggerFactory.getLogger(this.getClass());
@Autowired
JedisPool jedisPool;
// 获取锁之前的超时时间(获取锁的等待重试时间)
private long acquireTimeout = 5000;
// 获取锁之后的超时时间(防止死锁)
private int timeOut = 10000;
/**
* 获取分布式锁
* @return 锁标识
*/
public boolean getRedisLock(String lockName,String val) {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
// 1.计算获取锁的时间
Long endTime = System.currentTimeMillis() + acquireTimeout;
// 2.尝试获取锁
while (System.currentTimeMillis() < endTime) {
// 3. 获取锁成功就设置过期时间
if (jedis.setnx(lockName, val) == 1) {
jedis.expire(lockName, timeOut/1000);
return true;
}
}
} catch (Exception e) {
log.error(e.getMessage());
} finally {
returnResource(jedis);
}
return false;
}
/**
* 释放分布式锁
* @param lockName 锁名称
*/
public void unRedisLock(String lockName) {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
// 释放锁
jedis.del(lockName);
} catch (Exception e) {
log.error(e.getMessage());
} finally {
returnResource(jedis);
}
}
// ===============================================
public String get(String key) {
Jedis jedis = null;
String value = null;
try {
jedis = jedisPool.getResource();
value = jedis.get(key);
log.info(value);
} catch (Exception e) {
log.error(e.getMessage());
} finally {
returnResource(jedis);
}
return value;
}
public void set(String key, String value) {
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.set(key, value);
} catch (Exception e) {
log.error(e.getMessage());
} finally {
returnResource(jedis);
}
}
/**
* 关闭连接
*/
public void returnResource(Jedis jedis) {
try {
if(jedis!=null) jedis.close();
} catch (Exception e) {
}
}
}
上面的分布式锁实现了,但是这时候还可能出现另外2个问题:
一:获取锁时
setnx获取锁成功了,还没来得及setex服务就宕机了,由于这种非原子性的操作,死锁又发生了。其实redis提供了 nx 与 ex连用的命令。

二:释放锁时
1. 3个进程:A和B和C,在执行任务,并争抢锁,此时A获取了锁,并设置自动过期时间为10s
2. A开始执行业务,因为某种原因,业务阻塞,耗时超过了10秒,此时锁自动释放了
3. B恰好此时开始尝试获取锁,因为锁已经自动释放,成功获取锁
4. A此时业务执行完毕,执行释放锁逻辑(删除key),于是B的锁被释放了,而B其实还在执行业务
5. 此时进程C尝试获取锁,也成功了,因为A把B的锁删除了。
问题出现了:B和C同时获取了锁,违反了互斥性!如何解决这个问题呢?我们应该在删除锁之前,判断这个锁是否是自己设置的锁,如果不是(例如自己 的锁已经超时释放),那么就不要删除了。所以我们可以在set 锁时,存入当前线程的唯一标识!删除锁前,判断下里面的值是不是与自己标识释放一 致,如果不一致,说明不是自己的锁,就不要删除了。
/**
* 第二种分布式锁
*/
public class RedisTool {
private static final String LOCK_SUCCESS = "OK";
private static final Long RELEASE_SUCCESS = 1L;
/**
* 尝试获取分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
/**
* 释放分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @return 是否释放成功
*/
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {
if (jedis.get(lockKey).equals(requestId)) {
System.out.println("释放锁..." + Thread.currentThread().getName() + ",identifierValue:" + requestId);
jedis.del(lockKey);
return true;
}
return false;
}
}
按照上面方式实现分布式锁之后,就可以轻松解决大部分问题了。网上很多博客也都是这么实现的,但是仍然有些场景是不满足的,例如一个方法获取到锁之后,可能在方法内调这个方法此时就获取不到锁了。这个时候我们就需要把锁改进成可重入式锁了。

3) 重入锁:
也叫做递归锁,指的是在同一线程内,外层函数获得锁之后,内层递归函数仍然可以获取到该锁。换一种说法:同一个线程再次进入同步代码时,可以使用自己已获取到的锁。可重入锁可以避免因同一线程中多次获取锁而导致死锁发生。像synchronized就是一个重入锁,它是通过moniter函数记录当前线程信息来实现的。实现可重入锁需要考虑两点:
获取锁:首先尝试获取锁,如果获取失败,判断这个锁是否是自己的,如果是则允许再次获取, 而且必须记录重复获取锁的次数。
释放锁:释放锁不能直接删除了,因为锁是可重入的,如果锁进入了多次,在内层直接删除锁, 导致外部的业务在没有锁的情况下执行,会有安全问题。因此必须获取锁时累计重入的次数,释放时则减去重入次数,如果减到0,则可以删除锁。
下面我们假设锁的key为“ lock ”,hashKey是当前线程的id:“ threadId ”,锁自动释放时间假设为20
获取锁的步骤:
1、判断lock是否存在 EXISTS lock
2、不存在,则自己获取锁,记录重入层数为1.
2、存在,说明有人获取锁了,下面判断是不是自己的锁,即判断当前线程id作为hashKey是否存在:HEXISTS lock threadId
3、不存在,说明锁已经有了,且不是自己获取的,锁获取失败.
3、存在,说明是自己获取的锁,重入次数+1: HINCRBY lock threadId 1 ,最后更新锁自动释放时间, EXPIRE lock 20
释放锁的步骤:
1、判断当前线程id作为hashKey是否存在: HEXISTS lock threadId
2、不存在,说明锁已经失效,不用管了
2、存在,说明锁还在,重入次数减1: HINCRBY lock threadId -1 ,
3、获取新的重入次数,判断重入次数是否为0,为0说明锁全部释放,删除key: DEL lock
因此,存储在锁中的信息就必须包含:key、线程标识、重入次数。不能再使用简单的key-value结构, 这里推荐使用hash结构。
获取锁的脚本(注释删掉,不然运行报错)
local key = KEYS[1]; -- 第1个参数,锁的key
local threadId = ARGV[1]; -- 第2个参数,线程唯一标识
local releaseTime = ARGV[2]; -- 第3个参数,锁的自动释放时间
if(redis.call('exists', key) == 0) then -- 判断锁是否已存在
redis.call('hset', key, threadId, '1'); -- 不存在, 则获取锁
redis.call('expire', key, releaseTime); -- 设置有效期
return 1; -- 返回结果
end;
if(redis.call('hexists', key, threadId) == 1) then -- 锁已经存在,判断threadId是否是自己
redis.call('hincrby', key, threadId, '1'); -- 如果是自己,则重入次数+1
redis.call('expire', key, releaseTime); -- 设置有效期
return 1; -- 返回结果
end;
return 0; -- 代码走到这里,说明获取锁的不是自己,获取锁失败
释放锁的脚本(注释删掉,不然运行报错)
local key = KEYS[1]; -- 第1个参数,锁的key
local threadId = ARGV[1]; -- 第2个参数,线程唯一标识
if (redis.call('HEXISTS', key, threadId) == 0) then -- 判断当前锁是否还是被自己持有
return nil; -- 如果已经不是自己,则直接返回
end;
local count = redis.call('HINCRBY', key, threadId, -1); -- 是自己的锁,则重入次数-1
if (count == 0) then -- 判断是否重入次数是否已经为0
redis.call('DEL', key); -- 等于0说明可以释放锁,直接删除
return nil;
end;
完整代码
import java.util.Collections;
import java.util.UUID;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.scripting.support.ResourceScriptSource;
/**
* Redis可重入锁
*/
public class RedisLock {
private static final StringRedisTemplate redisTemplate = SpringUtil.getBean(StringRedisTemplate.class);
private static final DefaultRedisScript<Long> LOCK_SCRIPT;
private static final DefaultRedisScript<Object> UNLOCK_SCRIPT;
static {
// 加载释放锁的脚本
LOCK_SCRIPT = new DefaultRedisScript<>();
LOCK_SCRIPT.setScriptSource(new ResourceScriptSource(new ClassPathResource("lock.lua")));
LOCK_SCRIPT.setResultType(Long.class);
// 加载释放锁的脚本
UNLOCK_SCRIPT = new DefaultRedisScript<>();
UNLOCK_SCRIPT.setScriptSource(new ResourceScriptSource(new ClassPathResource("unlock.lua")));
}
/**
* 获取锁
* @param lockName 锁名称
* @param releaseTime 超时时间(单位:秒)
* @return key 解锁标识
*/
public static String tryLock(String lockName,String releaseTime) {
// 存入的线程信息的前缀,防止与其它JVM中线程信息冲突
String key = UUID.randomUUID().toString();
// 执行脚本
Long result = redisTemplate.execute(
LOCK_SCRIPT,
Collections.singletonList(lockName),
key + Thread.currentThread().getId(), releaseTime);
// 判断结果
if(result != null && result.intValue() == 1) {
return key;
}else {
return null;
}
}
/**
* 释放锁
* @param lockName 锁名称
* @param key 解锁标识
*/
public static void unlock(String lockName,String key) {
// 执行脚本
redisTemplate.execute(
UNLOCK_SCRIPT,
Collections.singletonList(lockName),
key + Thread.currentThread().getId(), null);
}
}
至此,一个比较完善的redis锁就开发完成了。
分布式锁的几种实现方式
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。在单机环境中,Java中其实提供了很多并发处理相关的API,但是这些API在分布式场景中就无能为力了。也就是说单纯的Java Api并不能提供分布式锁的能力。所以针对分布式锁的实现目前有多种方案。
针对分布式锁的实现,目前比较常用的有以下几种方案:
基于数据库实现分布式锁 基于缓存(redis,memcached,tair)实现分布式锁 基于Zookeeper实现分布式锁
在分析这几种实现方案之前我们先来想一下,我们需要的分布式锁应该是怎么样的?(这里以方法锁为例,资源锁同理)
可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
这把锁要是一把可重入锁(避免死锁)
这把锁最好是一把阻塞锁(根据业务需求考虑要不要这条)
有高可用的获取锁和释放锁功能
获取锁和释放锁的性能要好
基于数据库实现分布式锁
基于数据库表
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。
当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
创建这样一张数据库表:
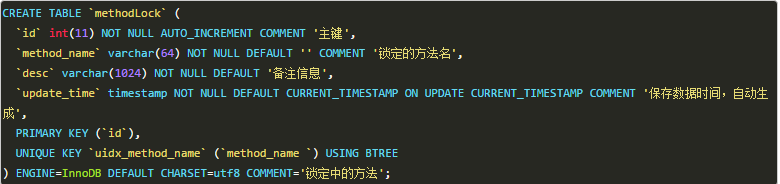
当我们想要锁住某个方法时,执行以下SQL:

因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
当方法执行完毕之后,想要释放锁的话,需要执行以下Sql:

上面这种简单的实现有以下几个问题:
1、这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
2、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
3、这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
4、这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
当然,我们也可以有其他方式解决上面的问题。
- 数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
- 没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
- 非阻塞的?搞一个while循环,直到insert成功再返回成功。
- 非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
基于数据库排他锁
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。
我们还用刚刚创建的那张数据库表。可以通过数据库的排他锁来实现分布式锁。 基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作:
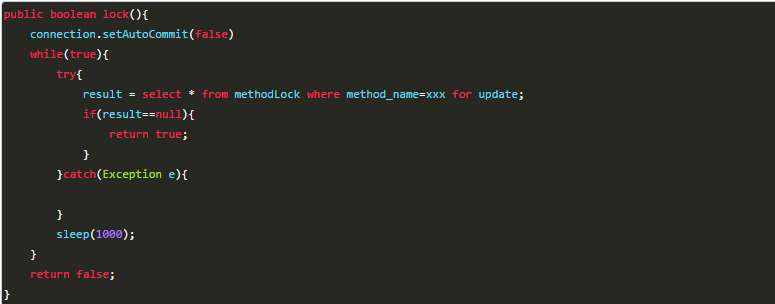
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁(这里再多提一句,InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上。)。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:

通过connection.commit()操作来释放锁。
这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题。
- 阻塞锁?
for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。 - 锁定之后服务宕机,无法释放?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
但是还是无法直接解决数据库单点和可重入问题。
这里还可能存在另外一个问题,虽然我们对method_name 使用了唯一索引,并且显示使用for update来使用行级锁。但是,MySql会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。如果发生这种情况就悲剧了。。。
还有一个问题,就是我们要使用排他锁来进行分布式锁的lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆
总结
总结一下使用数据库来实现分布式锁的方式,这两种方式都是依赖数据库的一张表,一种是通过表中的记录的存在情况确定当前是否有锁存在,另外一种是通过数据库的排他锁来实现分布式锁。
数据库实现分布式锁的优点
直接借助数据库,容易理解。
数据库实现分布式锁的缺点
会有各种各样的问题,在解决问题的过程中会使整个方案变得越来越复杂。
操作数据库需要一定的开销,性能问题需要考虑。
使用数据库的行级锁并不一定靠谱,尤其是当我们的锁表并不大的时候。
基于缓存实现分布式锁
相比较于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现的更好一点。而且很多缓存是可以集群部署的,可以解决单点问题。
目前有很多成熟的缓存产品,包括Redis,memcached以及我们公司内部的Tair。
这里以Tair为例来分析下使用缓存实现分布式锁的方案。关于Redis和memcached在网络上有很多相关的文章,并且也有一些成熟的框架及算法可以直接使用。
基于Tair的实现分布式锁其实和Redis类似,其中主要的实现方式是使用TairManager.put方法来实现。
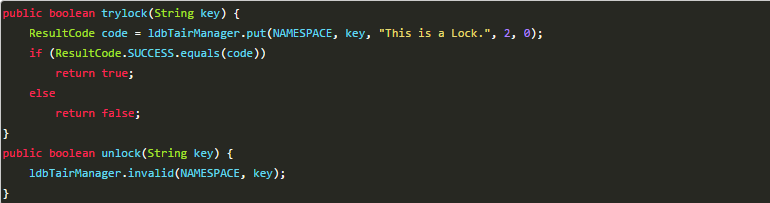
以上实现方式同样存在几个问题:
1、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在tair中,其他线程无法再获得到锁。
2、这把锁只能是非阻塞的,无论成功还是失败都直接返回。
3、这把锁是非重入的,一个线程获得锁之后,在释放锁之前,无法再次获得该锁,因为使用到的key在tair中已经存在。无法再执行put操作。
当然,同样有方式可以解决。
- 没有失效时间?tair的put方法支持传入失效时间,到达时间之后数据会自动删除。
- 非阻塞?while重复执行。
- 非可重入?在一个线程获取到锁之后,把当前主机信息和线程信息保存起来,下次再获取之前先检查自己是不是当前锁的拥有者。
但是,失效时间我设置多长时间为好?如何设置的失效时间太短,方法没等执行完,锁就自动释放了,那么就会产生并发问题。如果设置的时间太长,其他获取锁的线程就可能要平白的多等一段时间。这个问题使用数据库实现分布式锁同样存在
总结
可以使用缓存来代替数据库来实现分布式锁,这个可以提供更好的性能,同时,很多缓存服务都是集群部署的,可以避免单点问题。并且很多缓存服务都提供了可以用来实现分布式锁的方法,比如Tair的put方法,redis的setnx方法等。并且,这些缓存服务也都提供了对数据的过期自动删除的支持,可以直接设置超时时间来控制锁的释放。
使用缓存实现分布式锁的优点
性能好,实现起来较为方便。
使用缓存实现分布式锁的缺点
通过超时时间来控制锁的失效时间并不是十分的靠谱。
基于Zookeeper实现分布式锁
基于zookeeper临时有序节点可以实现的分布式锁。
让我们来回顾一下Zookeeper节点的概念:
Zookeeper的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做Znode。
Znode分为四种类型:
1.持久节点 (PERSISTENT)
默认的节点类型。创建节点的客户端与zookeeper断开连接后,该节点依旧存在 。
2.持久节点顺序节点(PERSISTENT_SEQUENTIAL)
所谓顺序节点,就是在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号:
3.临时节点(EPHEMERAL)
和持久节点相反,当创建节点的客户端与zookeeper断开连接后,临时节点会被删除:
4.临时顺序节点(EPHEMERAL_SEQUENTIAL)
顾名思义,临时顺序节点结合和临时节点和顺序节点的特点:在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号;当创建节点的客户端与zookeeper断开连接后,临时节点会被删除。
Zookeeper分布式锁的原理
Zookeeper分布式锁恰恰应用了临时顺序节点。具体如何实现呢?让我们来看一看详细步骤:
获取锁
首先,在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1。
之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2。
Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。
于是,Client2向排序仅比它靠前的节点Lock1注册Watcher,用于监听Lock1节点是否存在。这意味着Client2抢锁失败,进入了等待状态。
这时候,如果又有一个客户端Client3前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock3。
Client3查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock3是不是顺序最靠前的一个,结果同样发现节点Lock3并不是最小的。
于是,Client3向排序仅比它靠前的节点Lock2注册Watcher,用于监听Lock2节点是否存在。这意味着Client3同样抢锁失败,进入了等待状态。
这样一来,Client1得到了锁,Client2监听了Lock1,Client3监听了Lock2。这恰恰形成了一个等待队列,很像是Java当中ReentrantLock所依赖的
释放锁
释放锁分为两种情况:
1.任务完成,客户端显示释放
当任务完成时,Client1会显示调用删除节点Lock1的指令。
2.任务执行过程中,客户端崩溃
获得锁的Client1在任务执行过程中,如果Duang的一声崩溃,则会断开与Zookeeper服务端的链接。根据临时节点的特性,相关联的节点Lock1会随之自动删除。
由于Client2一直监听着Lock1的存在状态,当Lock1节点被删除,Client2会立刻收到通知。这时候Client2会再次查询ParentLock下面的所有节点,确认自己创建的节点Lock2是不是目前最小的节点。如果是最小,则Client2顺理成章获得了锁。
同理,如果Client2也因为任务完成或者节点崩溃而删除了节点Lock2,那么Client3就会接到通知。
最终,Client3成功得到了锁。
大致思想即为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
来看下Zookeeper能不能解决前面提到的问题。
-
锁无法释放?使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
-
非阻塞锁?使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
-
不可重入?使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
-
单点问题?使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
可以直接使用zookeeper第三方库Curator客户端,这个客户端中封装了一个可重入的锁服务。
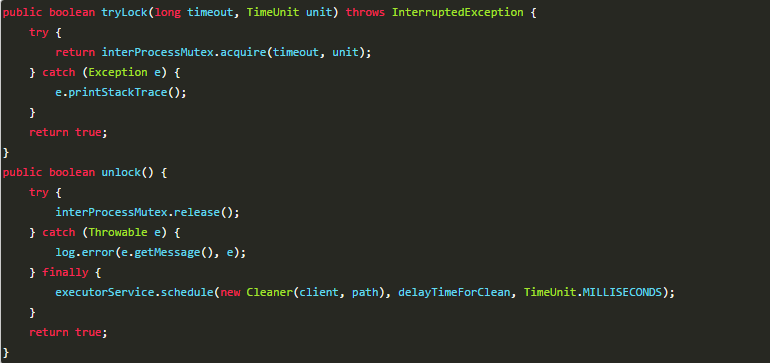
Curator提供的InterProcessMutex是分布式锁的实现。acquire方法用户获取锁,release方法用于释放锁。
使用ZK实现的分布式锁好像完全符合了本文开头我们对一个分布式锁的所有期望。但是,其实并不是,Zookeeper实现的分布式锁其实存在一个缺点,那就是性能上可能并没有缓存服务那么高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同不到所有的Follower机器上。
其实,使用Zookeeper也有可能带来并发问题,只是并不常见而已。考虑这样的情况,由于网络抖动,客户端可ZK集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。这个问题不常见是因为zk有重试机制,一旦zk集群检测不到客户端的心跳,就会重试,Curator客户端支持多种重试策略。多次重试之后还不行的话才会删除临时节点。(所以,选择一个合适的重试策略也比较重要,要在锁的粒度和并发之间找一个平衡。)
总结
使用Zookeeper实现分布式锁的优点
有效的解决单点问题,不可重入问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。
使用Zookeeper实现分布式锁的缺点
性能上不如使用缓存实现分布式锁。 需要对ZK的原理有所了解。
三种方案的比较
上面几种方式,哪种方式都无法做到完美。就像CAP一样,在复杂性、可靠性、性能等方面无法同时满足,所以,根据不同的应用场景选择最适合自己的才是王道。
从理解的难易程度角度(从低到高)
数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高)
Zookeeper >= 缓存 > 数据库
从性能角度(从高到低)
缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)
Zookeeper > 缓存 > 数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号