
数据库常见知识点总结-跨库分页、脏页、单库分页
参考:
原文作者:58沈剑 架构师之路 原文地址
https://www.cnblogs.com/yjmyzz/p/why_paging_so_tough_with_sharding.html-todo
https://zhuanlan.zhihu.com/p/155799967?from_voters_page=true
https://blog.csdn.net/starleejay/article/details/78802610
为什么需要研究跨库分页?
互联网很多业务都有分页拉取数据的需求,例如:
(1)微信消息过多时,拉取第N页消息;
(2)京东下单过多时,拉取第N页订单;
(3)浏览58同城,查看第N页帖子;
这些业务场景对应的消息表,订单表,帖子表分页拉取需求,都有这样一些共同的特点:
(1)有个业务主键id, msg_id, order_id, tiezi_id;
(2)分页按照非业务主键id来排序,业务中经常按照时间time来排序order by;
在数据量不大时,如何来实现跨库分页的需求呢?
(1)在排序字段time上建立索引;
(2)利用SQL提供的offset/limit就能实现;
例如:
select * from t_msg order by time offset 200 limit 100;
select * from t_order order by time offset 200 limit 100;
select * from t_tiezi order by time offset 200 limit 100;
画外音:此处假设一页数据为100条,均拉取第3页数据。
为什么会有分库的需求?
高并发大流量的互联网架构,一般通过服务层来访问数据库,随着数据量的增大,数据库需要进行水平切分,分库后将数据分布到不同的数据库实例(甚至物理机器)上,以达到降低数据量,增加实例数的扩容目的。
一旦涉及分库,逃不开“分库依据” patition key,要使用哪一个字段来水平切分数据库呢?
大部分的业务场景,会使用业务主键id。
确定了分库依据 patition key 后,接下来怎么确定分库算法呢?
大部分的业务场景,会使用业务主键id取模的算法来分库,这样的好处是:
(1)即能够保证每个库的数据分布是均匀的;
(2)又能够保证每个库的请求分布是均匀的;
实在是简单实现负载均衡的好方法,此法在互联网架构中应用颇多。
一个更具体的例子:
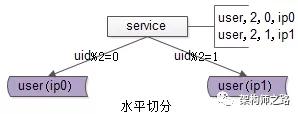
用户库user,水平切分后变为两个库:
(1)分库依据patition key是uid;
(2)分库算法是uid取模:uid%2余0的数据会落到db0,uid%2余1的数据会落到db1;
数据库进行了水平切分之后,如果业务要查询“最近注册的第3页用户”,即跨库分页查询,该如何实现呢?
单库上,可以
select * from t_user order by time offset 200 limit 100;
变成两个库后,分库依据是uid,排序依据是time,数据库层失去了time排序的全局视野,数据分布在两个库上,此时该怎么办呢?
如何满足“跨越多个水平切分数据库,且分库依据与排序依据为不同属性,并需要进行分页”的查询需求,实现:
select * from T order by time offset X limit Y;
这类跨库分页SQL,是后文将要讨论的技术问题。
方案一:全局视野法

如上图所述,服务层通过uid取模将数据分布到两个库上去之后,每个数据库都失去了全局视野,数据按照time局部排序之后,不管哪个分库的第3页数据,都不一定是全局排序的第3页数据。
那到底哪些数据才是全局排序的第3页数据呢?
需要分三种情况讨论。
(1)极端情况,两个库的数据完全一样
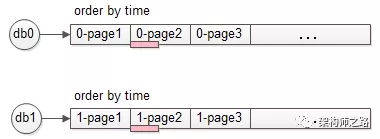
如果两个库的数据完全相同,只需要每个库offset一半,再取半页,就是最终想要的数据(如上图中粉色部分数据)。
(2)极端情况,结果数据来自一个库

也可能两个库的数据分布及其不均衡,例如db0的所有数据的time都大于db1的所有数据的time,则可能出现:一个库的第3页数据,就是全局排序后的第3页数据(如上图中粉色部分数据)。
(3)一般情况,每个库数据各包含一部分

正常情况下,全局排序的第3页数据,每个库都会包含一部分(如上图中粉色部分数据)。
由于不清楚到底是哪种情况,所以必须:
(1)每个库都返回3页数据;
(2)所得到的6页数据在服务层进行内存排序,得到数据全局视野;
(3)再取第3页数据,便能够得到想要的全局分页数据。
再总结一下这个方案的步骤:
(1)将SQL语句改写,即
order by time offset X limit Y;
改写成
order by time offset 0 limit X+Y;
(2)服务层将改写后的SQL语句发往各个分库;
(3)假设共分为N个库,服务层将得到N*(X+Y)条数据;
(4)服务层对得到的N*(X+Y)条数据进行内存排序;
(5)内存排序后再取偏移量X后的Y条记录,就是全局视野所需的一页数据;
全局视野法有什么优点?
通过服务层修改SQL语句,扩大数据召回量,能够得到全局视野,业务无损,精准返回所需数据。
全局视野法的缺点呢?
缺点显而易见:
(1)每个分库需要返回更多的数据,增大了网络传输量(耗网络);
(2)除了数据库按照time进行排序,服务层还需要进行二次排序,增大了服务层的计算量(耗CPU);
(3)最致命的,这个算法随着页码的增大,性能会急剧下降,这是因为SQL改写后每个分库要返回X+Y行数据:返回第3页,offset中的X=200;假如要返回第100页,offset中的X=9900,即每个分库要返回100页数据,数据量和排序量都将大增,性能平方级下降。
“全局视野法”虽然性能较差,但其业务无损,数据精准,不失为一种方案,有没有性能更优的方案呢?
“任何脱离业务的架构设计都是耍流氓”,技术方案需要折衷,在技术难度较大的情况下,业务需求的折衷能够极大的简化技术方案。
方案二:禁止跳页查询法
在数据量很大,翻页数很多的时候,很多产品并不提供“直接跳到指定页面”的功能,而只提供“下一页”的功能,这一个小小的业务折衷,就能极大的降低技术方案的复杂度。

如上图,不能跳页,那么第一次只能够查第一页:
(1)将查询
order by time offset 0 limit 100;
改写成
order by time where time>0 limit 100;
(2)上述改写和offset 0 limit 100的效果相同,都是每个分库返回了一页数据(上图中粉色部分);

(3)服务层得到2页数据,内存排序,取出前100条数据,作为最终的第一页数据,这个全局的第一页数据,一般来说每个分库都包含一部分数据(如上图粉色部分);
这个方案也需要服务器内存排序,岂不是和“全局视野法”一样么?第一页数据的拉取确实一样,但每一次“下一页”拉取的方案就不一样了。
点击“下一页”时,需要拉取第二页数据,在第一页数据的基础之上,能够找到第一页数据time的最大值:

这个上一页记录的time_max,会作为第二页数据拉取的查询条件:
(1)将查询
order by time offset 100 limit 100;
改写成
order by time where time>$time_max limit 100;

(2)这下不是返回2页数据了(“全局视野法,会改写成offset 0 limit 200”),每个分库还是返回一页数据(如上图中粉色部分);

(3)服务层得到2页数据,内存排序,取出前100条数据,作为最终的第2页数据,这个全局的第2页数据,一般来说也是每个分库都包含一部分数据(如上图粉色部分);
如此往复,查询全局视野第100页数据时,不是将查询条件改写为
offset 0 limit 9900+100;(返回100页数据)
而是改写为
time>$time_max99 limit 100;(仍返回一页数据)
以保证数据的传输量和排序的数据量不会随着不断翻页而导致性能下降。
方案三:允许数据精度损失法
“全局视野法”能够返回业务无损的精确数据,在查询页数较大,例如第100页时,会有性能问题,此时业务上是否能够接受,返回的100页不是精准的数据,而允许有一些数据偏差呢?
先来了解一下,数据库分库-数据均衡原理。
什么是,数据库分库-数据均衡原理?
使用patition key进行分库,在数据量较大,数据分布足够随机的情况下,各分库所有非patition key属性,在各个分库上,数据分布的统计概率情况是一致的。
例如,在uid随机的情况下,使用uid取模分两库,db0和db1:
(1)性别属性,如果db0库上的男性用户占比70%,则db1上男性用户占比也应为70%;
(2)年龄属性,如果db0库上18-28岁少女用户比例占比15%,则db1上少女用户比例也应为15%;
(3)时间属性,如果db0库上每天10:00之前登录的用户占比为20%,则db1上应该是相同的统计规律;
…
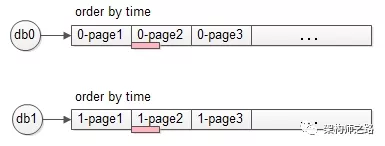
利用这一原理,要查询全局100页数据,只要将:
offset 9900 limit 100;
改写为
offset 4950 limit 50;
即每个分库偏移一半(4950),获取半页数据(50条),得到的数据集的并集,基本能够认为,是全局数据的offset 9900 limit 100的数据,当然,这一页数据并不是精准的。
根据实际业务经验,用户都要查询第100页网页、帖子、邮件的数据了,这一页数据的精准性损失,业务上往往是可以接受的,但此时技术方案的复杂度大大降低了,既不需要返回更多的数据,也不需要进行服务内存排序了。
画外音:如果业务能够接受,这种方案的性能最好,强烈推荐。
方案四:二次查询法
有没有一种技术方案,即能够满足业务的精确需要,无需业务折衷,又高性能的方法呢?这就是接下来要介绍的终极武器,“二次查询法”。
为了方便举例,假设一页只有5条数据,查询第200页的SQL语句为:
select * from T order by time offset 1000 limit 5;
步骤一:查询改写
select * from T order by time offset 1000 limit 5;
改写为
select * from T order by time offset 500 limit 5;
并投递给所有的分库,注意,这个offset的500,来自于全局offset的总偏移量1000,除以水平切分数据库个数2。
画外音:因为数据量比较大,数据随机性较强,不妨设仍然符合“数据库分库-数据均衡定理”。
如果是3个分库,则可以改写为
select * from T order by time offset 333 limit 5;
假设这三个分库返回的数据(time, uid)如下:

可以看到,每个分库都是返回的按照time排序的一页数据。
步骤二:找到所返回3页全部数据的最小值
第一个库,5条数据的time最小值是1487501123;
第二个库,5条数据的time最小值是1487501133;
第三个库,5条数据的time最小值是1487501143;
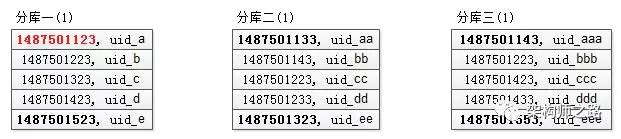
故,三页数据中,time最小值来自第一个库,time_min=1487501123,这个过程只需要比较各个分库第一条数据,时间复杂度很低。
画外音:这个time_min非常重要,后文每一个步骤要都要用到time_min。
步骤三:查询二次改写
第一次改写的SQL语句是
select * from T order by time offset 333 limit 5;
第二次要改写成一个between语句:
-
between的起点是time_min
-
between的终点是原来每个分库各自返回数据的最大值
第一个分库,第一次返回数据的最大值是1487501523
所以查询改写为:
select * from T order by time where time between time_min and 1487501523;
第二个分库,第一次返回数据的最大值是1487501323
所以查询改写为
select * from T order by time where time between time_min and 1487501323;
第三个分库,第一次返回数据的最大值是1487501553
所以查询改写为
select * from T order by time where time between time_min and 1487501553;
相对第一次查询,第二次查询条件放宽了,故第二次查询会返回比第一次查询结果集更多的数据,假设这三个分库返回的数据(time, uid)如下:

可以看到:
分库一的结果集,由于time_min来自原来的分库一,所以分库一的返回结果集和第一次查询相同(所以其实这次访问是可以省略的);
分库二的结果集,比第一次多返回了1条数据,头部的1条记录(time最小的记录)是新的(上图中粉色记录);
分库三的结果集,比第一次多返回了2条数据,头部的2条记录(time最小的2条记录)是新的(上图中粉色记录);
步骤四:在每个结果集中虚拟一个time_min记录,找到time_min在全局的offset
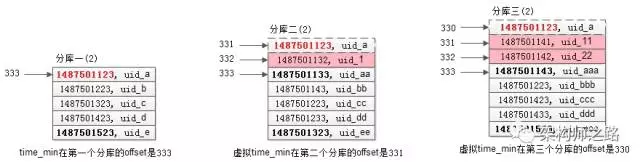
在第一个库中,time_min在第一个库的offset是333;
在第二个库中,(1487501133, uid_aa)的offset是333(根据第一次查询条件得出的),故虚拟time_min在第二个库的offset是331;
画外音:从333往前推演。
在第三个库中,(1487501143, uid_aaa)的offset是333(根据第一次查询条件得出的),故虚拟time_min在第三个库的offset是330;
画外音:从333往前推演。
综上,time_min在全局的offset是333+331+330=994。
步骤五:既然得到了time_min在全局的offset,就相当于有了全局视野,根据第二次的结果集,就能够得到全局offset 1000 limit 5的记录
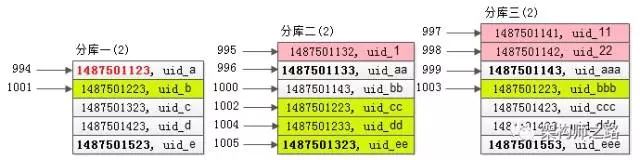
第二次查询在各个分库返回的结果集是有序的,又知道了time_min在全局的offset是994,一路排下来,容易知道全局offset 1000 limit 5的一页记录(上图中黄色记录)。
这种方法的优点是:可以精确的返回业务所需数据,每次返回的数据量都非常小,不会随着翻页增加数据的返回量。
帅气不帅气!!!
总结
今天介绍了解决“跨N库分页”这一难题的四种方法:
方法一:全局视野法
(1)SQL改写,将
order by time offset X limit Y;
改写成
order by time offset 0 limit X+Y;
(2)服务层对得到的N*(X+Y)条数据进行内存排序,内存排序后再取偏移量X后的Y条记录;
这种方法随着翻页的进行,性能越来越低。
方法二:禁止跳页查询法
(1)用正常的方法取得第一页数据,并得到第一页记录的time_max;
(2)每次翻页,将
order by time offset X limit Y;
改写成
order by time where time>$time_max limit Y;
以保证每次只返回一页数据,性能为常量。
方法三:允许模糊数据法
(1)SQL查询改写,将
order by time offset X limit Y;
改写成
order by time offset X/N limit Y/N;
性能很高,但拼接的结果集不精准。
方法四:二次查询法
(1)SQL改写,将
order by time offset X limit Y;
改写成
order by time offset X/N limit Y;
(2)多页返回,找到最小值time_min;
(3)between二次查询
order by time between 𝑡𝑖𝑚𝑒𝑚𝑖𝑛𝑎𝑛𝑑timeminandtime_i_max;
(4)设置虚拟time_min,找到time_min在各个分库的offset,从而得到time_min在全局的offset;
(5)得到了time_min在全局的offset,自然得到了全局的offset X limit Y;
分表分页/跨库分页为什么这么难?
当业务数据达到一定量级(比如:mysql单表记录量>1千万)后,通常会考虑“分库分表”将数据分散到不同的库或表中,这样可以大大提高读/写性能。但是问题来了,对于 select * from table limit offset , pagesize 这种分页方式,原来一条语句就可以简单搞定的事情会变得很复杂,本文将与大家一起探讨分库分表后"分页"面临的新问题。
一、分表对分页的影响
比如有一张表,里面有8条记录(为简单起见,假设该表上只有1个自增ID),数学上可以抽象成1个(有序)数列(注:为方便讨论,不加特殊说明的情况下,文本中数列的顺序,均指升序)
(1,2,3,4,5,6,7,8)
如果要取出上面红色标识的2,3这二条记录,limit 1,2 就行了。
现在假如分成2张表(即:原来的数列,拆分成2个非空子数列),一般来讲,有二种常用分法:
1.1 分段法(比如:有时间属性的数据,类似订单这种,可以按下单时间拆分,每个月1张表)
(1,2,3,4)
(5,6,7,8)
沿用之前的limit x,y的思路,每个分表上 limit 1,2,会得到如下2个子数列:
(2,3)
(6,7)
然后在内存中合并排序,再取前2条 (2,3,6,7) => (2,3) ,貌似看上去也符合预期(这个思路也称为归并),但这只是假象。当要取的分页数据落在不同的子数列上时,就能发现问题:
(1,2,3,4,5,6,7,8) 比如,我们要从4个位置开始,连续取2个元素,即: limit 3,2
(1,2,3,4) => limit 3,2 =>(4)
(5,6,7,8) => limit 3,2 =>(8)
最后合并出来的结果是(4,8) 与正确结果 (4,5)相比,显然不对。
1.2 模余均摊法(比如:字段值对2取模求余数,根据余数决定分到哪个表,该方法也简称为取余法)
(1,3,5,7)
(2,4,6,8)
归并排序的思路在分段法上行不通,对于取模均摊同样也不行,仍以 limit 1,2为例,原始序列取出来的结果是(2,3),如果用归并的思路:
(1,3,5,7)=> limit 1,2 =>(3 ,5)
(2,4,6,8)=> limit 1,2 =>(4, 6)
内存合并排序后,取前2个,最终结果为(3 , 4)
结论:不管分库分表采用什么分法,简单归并的思路,都无法正确解决分页问题。
二、全局法(limit x+y)
反思一下刚才的归并思路,本质上我们在每个子数列(即:分表)上limit x,y 时,取出来的数据就有可能已经产生缺失了。网上有一篇广为流转的文章"业界难题-跨库分页”,作者在文中提出了一个方案:把范围扩大,分表sql上的limit x,y 变成 limit 0, x+y ,这样改写后,相当于分表中把"每页最后一条数据"之前的所有数据全都取出来了(当然:这里面可能会有不需要的多余数据),然后内存中合并在一起,再取x偏移量后的y条数据。
用前面的例子验证一下:
原序列:(1,2,3,4,5,6,7,8),需要取出limit 1,2 ,即:(2,3)
2.1 按分段法拆成2段:
(1 , 2 , 3 , 4) => limit 1,2 =>改写成 limit 0, 1+2 => (1,2,3)
(5 , 6 , 7 , 8) => limit 1,2 =>改写成 limit 0, 1+2 => (5,6,7)
将子数列合并排序=> { 1,2,3,5,6,7} => 按原始偏移量 limit 1,2 =>{2,3} 正确
如果原数列中要取的数据,正好落在2个子数列上(1,2,3,4,5,6,7,8),需要取出limit 3,2 ,即:(4,5)
(1 , 2 , 3 , 4) => limit 3,2 =>改写成 limit 0, 3+2 => (1,2,3,4)
(5 , 6 , 7 , 8) => limit 3,2 =>改写成 limit 0, 3+2 => (5,6,7,8)
将子数列合并排序=> (1,2,3,4,5,6,7,8) => 按原始偏移量 limit 3,2 => (4,5) 也符合预期。
2.2 取模均摊拆成2段
(1,3,5,7) => limit 1,2 ->改写成 limit 0, 1+2 => (1,3 ,5)
(2,4,6,8) => limit 1,2 ->改写成 limit 0, 1+2=> (2,4,6)
将子序列合并=> (1,2,3,4,5,6) => 按原始偏移量 limit 1,2 =>(2,3) 正确
该方法缺点也很明显:取出的记录太多了,比如 limit 10000000,10 -> 改写后变成 limit 0, 10000010 遇到海量数据,mysql中查询有可能直接超时,这么多数据从db传到应用层,网络开销也很大,更不用说如果是java应用,大量数据放到List或Map中,容易出现OOM。(注:一般情况下,需要用分库分表的场景,数据量必然很大,所以这个方法,实际中基本上没法用)
三、二次查询法
这也是"业界难题-跨库分页”一文中提到的一个方法,大致思路如下:在某1页的数据均摊到各分表的前提下(注:这个前提很重要,也就是说不会有一个分表的数据特别多或特别少),换句话说:这个方案不适用分段法,按如下步骤操作:
1)原sql中的limit offset,pagesize 改写成 limit offset/n ,pagesize (注:n为分表个数,如果offset/n除不尽,向下取整,避免最后的结果丢数据)-- 这个的意思,其实就是假设原表这一页的数据,会均分到各个分表(所以,我一再强调,前提是数据是均摊的,如果某个分表的记录很少,极端情况下,甚至是空的,这个就不对了,最终结果会少数据)
2)分表上,执行改写后的sql,得到一堆结果集,然后找出这堆结果中的最小id (假设id是关键的排序字段),记为min_id -- 这一步的目的,是为了找出最小的起始点,保证第1页数据起点正确。
3)各分表上的sql,where条件部分改写成 id between min_id and origin_max_id (注:origin_max_id为上一步,每个分表查询结果集中的最大值,显然min_id=自身最小id的那张分表,不用再重复查询) -- 这一步的目的在于,因为步骤1)查出来的结果,通常会比原表上该页的数据少,所以这里重新将起始点设置到正确的位置,即:min_id,再查1次,相当于范围扩大了,以保证数据不会丢。不过,这里有一个可优化的地方,仔细想想,这1次查询出来的结果,跟步骤1)中的查出来的结果,必然有一部分是重复的,因此改写部分,只需要 id between min_id and origin_min_id就可以了(origin_min_id 即为原来分表结果上的最小id)
4)将上一步查询出来的结果,在内存中合并排序去重(注:如果上一步采用了优化方案,就应该是把1)与3)这二次查询的结果全取出来合并排序去重),然后从开始连续取pagesize条数据即可(注:offset/n除不尽的话,向下取整了,也就是起始点可能向前多移了,所以有可能开始的第1条记录,其实是上1页的最后1条记录,要追求精确的话,可以在应用层记录上一页最后1条记录的id,然后跟本次查询结果前1条记录对比,如果发现是一样的,开始取数据的位置,就要向后移1位,如果考虑id有重复的话,就要根据情况多移几位)
验证一下看看效果:
场景1(前提:取余法)
原序列:(1,2,3,4,5,6,7,8),需要取出limit 2,2 ,即:(3,4)
--------------------------------------------------------
场景3(前提:分段法)
参考文章:
https://juejin.im/post/5d1f52e46fb9a07eb3099bbf
https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/pagination/
http://kmiku7.github.io/2019/08/01/Do-Pagination-With-Table-Database-Sharding/
https://segmentfault.com/a/1190000013225860?utm_source=tag-newest
mysql脏页是什么
1. 脏页(内存页)
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。
内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。
平时很快的更新操作,都是在写内存和日志,他并不会马上同步到磁盘数据,这时内存数据页跟磁盘数据页内容不一致,我们称之为“脏页”。
一条 SQL 语句,正常执行的时候特别快,偶尔很慢。那这时候可能就是在将脏页同步到磁盘中了
2. 什么时候会引起将脏页同步到磁盘中?
(1) 当 redo log写满了。这时候系统就会停止所有的更新操作,将更新的这部分日志对应的脏页同步到磁盘中,此时所有的更新全部停
止,此时写的性能变为0,必须待刷一部分脏页后才能更新,这时就会导致 sql语句 执行的很慢。
(2) 也可能是系统内存不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,则需要先将脏页同步到磁盘,空出来的给别的数据页使用。
(3) MySQL 认为系统“空闲”的时候,反正闲着也是闲着反正有机会就同步到磁盘一些数据
(4) MySQL 正常关闭。这时候,MySQL 会把内存的脏页都同步到磁盘上,这样下次 MySQL 启动的时候,就可以直接从磁盘上读数据,启动速度会很快。
3.会造成的影响
1 如果是redo log写满了
尽量要避免的。因为出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都都会停止。此时写的性能变为0,必须待刷一部分脏页后才能更新,这时就会导致 sql语句 执行的很慢
2 内存不够用了
常态,很正常。
MySQL实现单库分页查询
limit 基本实现方式
一般情况下,客户端通过传递 pageNo(页码)、pageSize(每页条数)两个参数去分页查询数据库中的数据,在数据量较小(元组百/千级)时使用 MySQL自带的 limit 来解决这个问题:
收到客户端{pageNo:1,pagesize:10}
select * from table limit (pageNo-1)*pageSize, pageSize;
收到客户端{pageNo:5,pageSize:30}
select * from table limit (pageNo-1)*pageSize,pageSize;
建立主键或者唯一索引
在数据量较小的时候简单的使用 limit 进行数据分页在性能上面不会有明显的缓慢,但是数据量达到了 万级到百万级 sql语句的性能将会影响数据的返回。这时需要利用主键或者唯一索引进行数据分页;
假设主键或者唯一索引为 good_id
收到客户端{pageNo:5,pagesize:10}
select * from table where good_id > (pageNo-1)*pageSize limit pageSize;
–返回good_id为40到50之间的数据
基于数据再排序
当需要返回的信息为顺序或者倒序时,对上面的语句基于数据再排序。order by ASC/DESC 顺序或倒序 默认为顺序
select * from table where good_id > (pageNo-1)*pageSize order by good_id limit pageSize;
–返回good_id为40到50之间的数据,数据依据good_id顺序排列

 浙公网安备 33010602011771号
浙公网安备 33010602011771号