

数据结构和算法-图
参考:
https://www.cnblogs.com/xiaobingqianrui/p/8902111.html
https://www.cnblogs.com/songgj/p/9107797.html
https://www.cnblogs.com/hapjin/p/4760934.html
https://www.cnblogs.com/hapjin/p/4766823.html
数据结构之图的基本概念
一 图的定义
定义:图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
在图中需要注意的是:
(1)线性表中我们把数据元素叫元素,树中将数据元素叫结点,在图中数据元素,我们则称之为顶点(Vertex)。
(2)线性表可以没有元素,称为空表;树中可以没有节点,称为空树;但是,在图中不允许没有顶点(有穷非空性)。
(3)线性表中的各元素是线性关系,树中的各元素是层次关系,而图中各顶点的关系是用边来表示(边集可以为空)。
二 图的基本概念
(1)无向图
 如果图中任意两个顶点之间的边都是无向边(简而言之就是没有方向的边),则称该图为无向图(Undirected graphs)。
如果图中任意两个顶点之间的边都是无向边(简而言之就是没有方向的边),则称该图为无向图(Undirected graphs)。
(2)有向图
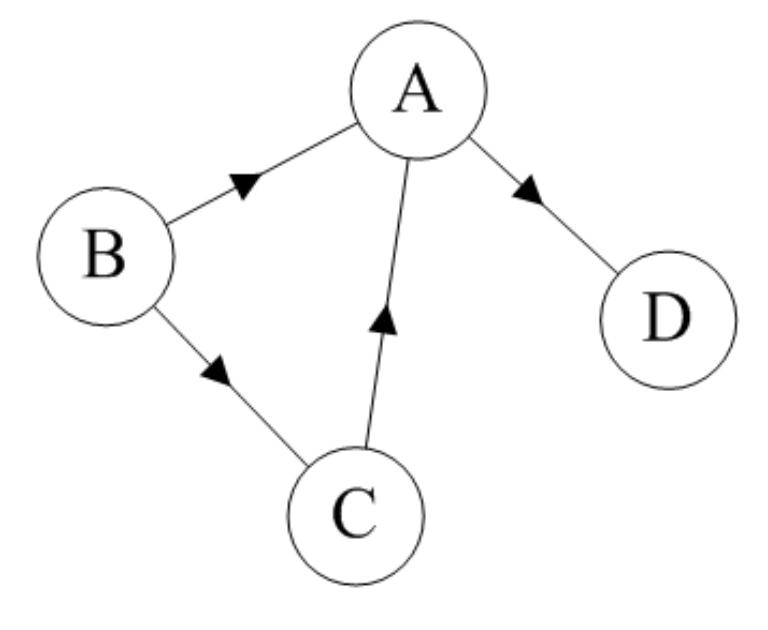
如果图中任意两个顶点之间的边都是有向边(简而言之就是有方向的边),则称该图为有向图(Directed graphs)。
(3)完全图
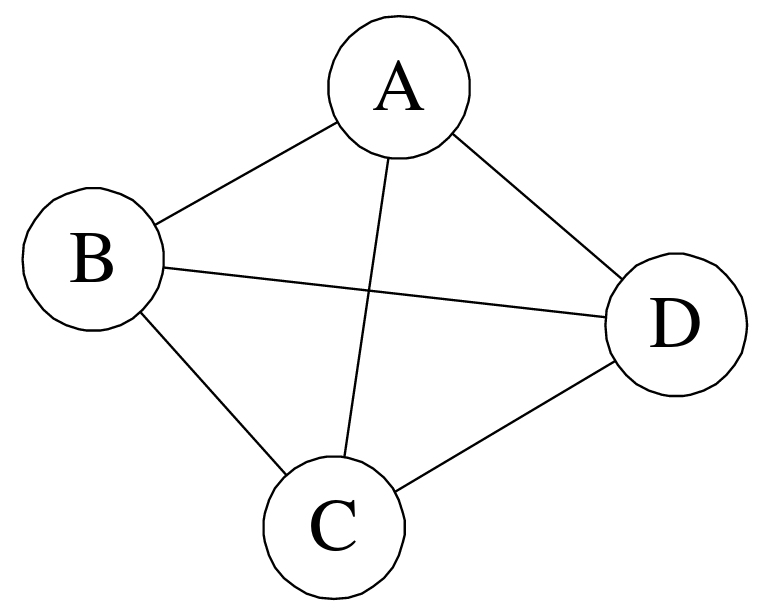
①无向完全图:在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。(含有n个顶点的无向完全图有(n×(n-1))/2条边)如下图所示:
②有向完全图:在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图。(含有n个顶点的有向完全图有n×(n-1)条边)如下图所示:
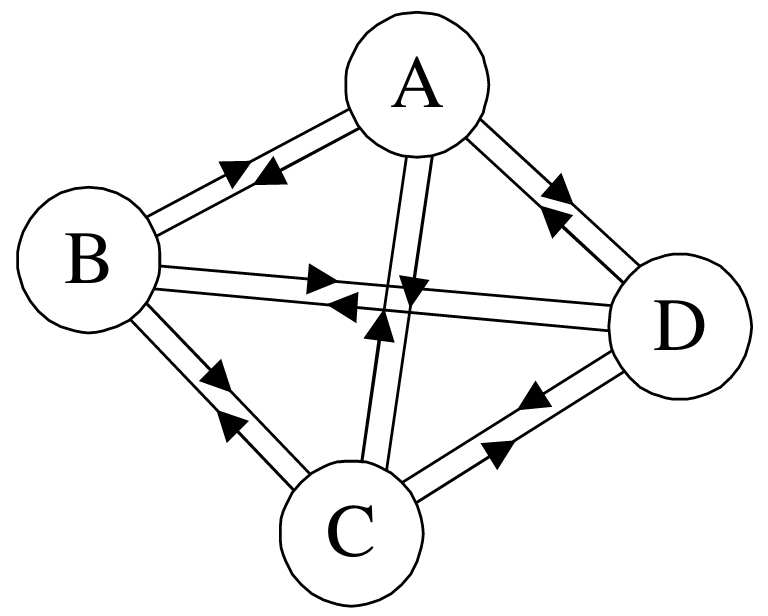
PS:当一个图接近完全图时,则称它为稠密图(Dense Graph),而当一个图含有较少的边时,则称它为稀疏图(Spare Graph)。
(4)顶点的度
顶点Vi的度(Degree)是指在图中与Vi相关联的边的条数。对于有向图来说,有入度(In-degree)和出度(Out-degree)之分,有向图顶点的度等于该顶点的入度和出度之和。
(5)邻接
①若无向图中的两个顶点V1和V2存在一条边(V1,V2),则称顶点V1和V2邻接(Adjacent);
②若有向图中存在一条边<V3,V2>,则称顶点V3与顶点V2邻接,且是V3邻接到V2或V2邻接直V3;
PS:无向图中的边使用小括号“()”表示,而有向图中的边使用尖括号“<>”表示。
(6)路径
在无向图中,若从顶点Vi出发有一组边可到达顶点Vj,则称顶点Vi到顶点Vj的顶点序列为从顶点Vi到顶点Vj的路径(Path)。
(7)连通
若从Vi到Vj有路径可通,则称顶点Vi和顶点Vj是连通(Connected)的。
(8)权
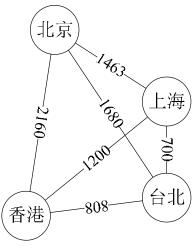
有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight)。
有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight)。
三、图的存储结构
图的存储结构除了要存储图中的各个顶点本身的信息之外,还要存储顶点与顶点之间的关系,因此,图的结构也比较复杂。常用的图的存储结构有邻接矩阵和邻接表等。
2.1 邻接矩阵表示法
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
(1)无向图:

我们可以设置两个数组,顶点数组为vertex[4]={v0,v1,v2,v3},边数组arc[4][4]为上图右边这样的一个矩阵。对于矩阵的主对角线的值,即arc[0][0]、arc[1][1]、arc[2][2]、arc[3][3],全为0是因为不存在顶点的边。
(2)有向图:
我们再来看一个有向图样例,如下图所示的左边。顶点数组为vertex[4]={v0,v1,v2,v3},弧数组arc[4][4]为下图右边这样的一个矩阵。主对角线上数值依然为0。但因为是有向图,所以此矩阵并不对称,比如由v1到v0有弧,得到arc[1][0]=1,而v到v没有弧,因此arc[0][1]=0。

不足:由于存在n个顶点的图需要n*n个数组元素进行存储,当图为稀疏图时,使用邻接矩阵存储方法将会出现大量0元素,这会造成极大的空间浪费。这时,可以考虑使用邻接表表示法来存储图中的数据。
2.2 邻接表表示法
首先,回忆我们在线性表时谈到,顺序存储结构就存在预先分配内存可能造成存储空间浪费的问题,于是引出了链式存储的结构。同样的,我们也可以考虑对边或弧使用链式存储的方式来避免空间浪费的问题。
邻接表由表头节点和表节点两部分组成,图中每个顶点均对应一个存储在数组中的表头节点。如果这个表头节点所对应的顶点存在邻接节点,则把邻接节点依次存放于表头节点所指向的单向链表中。
(1)无向图:下图所示的就是一个无向图的邻接表结构。

从上图中我们知道,顶点表的各个结点由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,指向边表的第一个结点,即此顶点的第一个邻接点。边表结点由adjvex和next两个域组成。adjvex是邻接点域,存储某顶点的邻接点在顶点表中的下标,next则存储指向边表中下一个结点的指针。例如:v1顶点与v0、v2互为邻接点,则在v1的边表中,adjvex分别为v0的0和v2的2。
PS:对于无向图来说,使用邻接表进行存储也会出现数据冗余的现象。例如上图中,顶点V0所指向的链表中存在一个指向顶点V3的同事,顶点V3所指向的链表中也会存在一个指向V0的顶点。
(2)有向图:若是有向图,邻接表结构是类似的,但要注意的是有向图由于有方向的。因此,有向图的邻接表分为出边表和入边表(又称逆邻接表),出边表的表节点存放的是从表头节点出发的有向边所指的尾节点;入边表的表节点存放的则是指向表头节点的某个顶点,如下图所示。
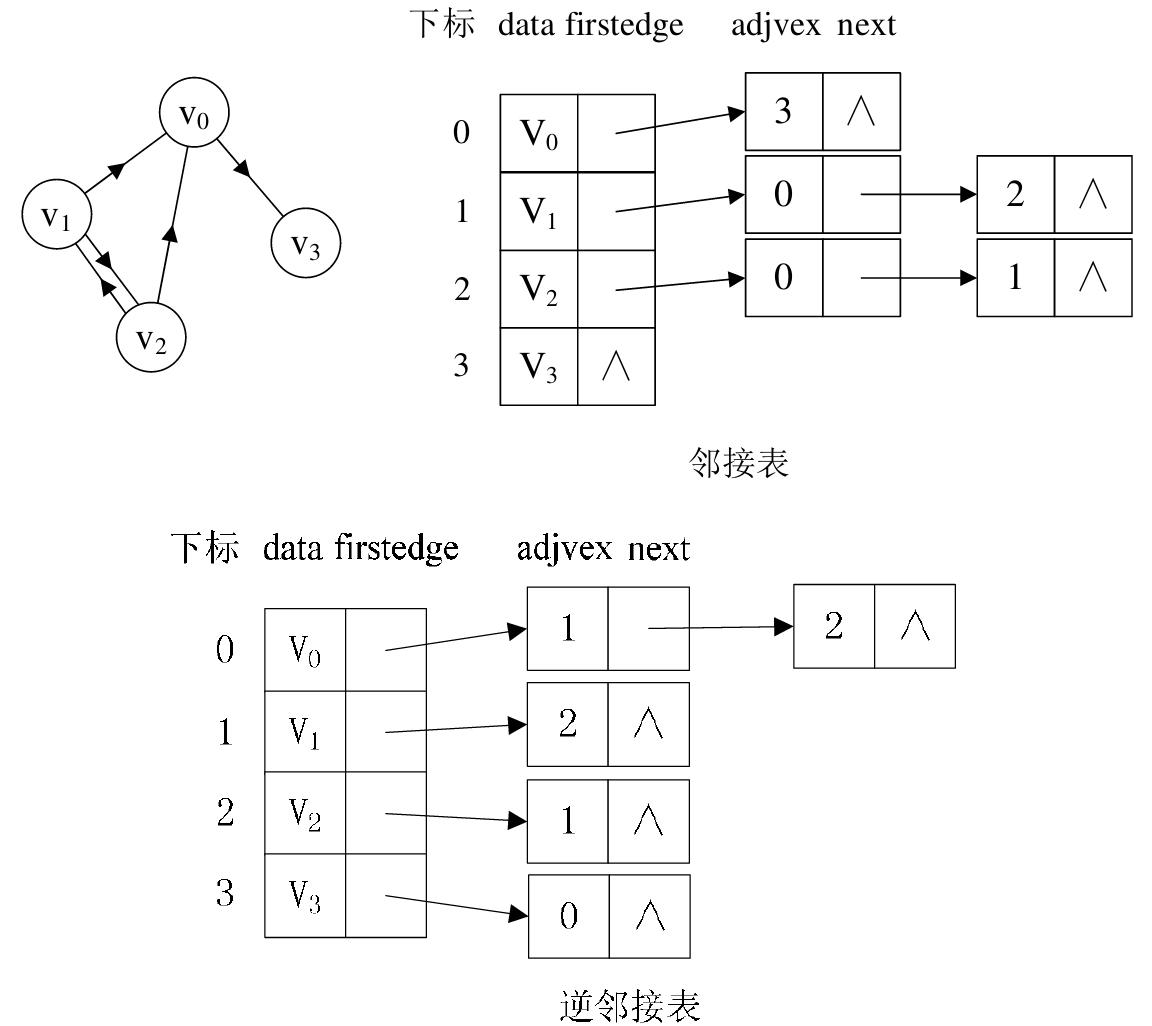
(3)带权图:对于带权值的网图,可以在边表结点定义中再增加一个weight的数据域,存储权值信息即可,如下图所示。
【数据结构】数据结构-图的基本概念
图的简介
图(Graph)结构是一种非线性的数据结构,图在实际生活中有很多例子,比如交通运输网,地铁网络,社交网络,计算机中的状态执行(自动机)等等都可以抽象成图结构。图结构比树结构复杂的非线性结构。
图结构构成
1.顶点(vertex):图中的数据元素,如图一。
2.边(edge):图中连接这些顶点的线,如图一。

图一
所有的顶点构成一个顶点集合,所有的边构成边的集合,一个完整的图结构就是由顶点集合和边集合组成。图结构在数学上记为以下形式:
G=(V,E) 或者 G=(V(G),E(G))
其中 V(G)表示图结构所有顶点的集合,顶点可以用不同的数字或者字母来表示。E(G)是图结构中所有边的集合,每条边由所连接的两个顶点来表示。
图结构中顶点集合V(G)不能为空,必须包含一个顶点,而图结构边集合可以为空,表示没有边。
图的基本概念
1.无向图(undirected graph)
如果一个图结构中,所有的边都没有方向性,那么这种图便称为无向图。典型的无向图,如图二所示。由于无向图中的边没有方向性,这样我们在表示边的时候对两个顶点的顺序没有要求。例如顶点VI和顶点V5之间的边,可以表示为(V2, V6),也可以表示为(V6,V2)。

图二 无向图
对于图二无向图,对应的顶点集合和边集合如下:
V(G)= {V1,V2,V3,V4,V5,V6}
E(G)= {(V1,V2),(V1,V3),(V2,V6),(V2,V5),(V2,V4),(V4,V3),(V3,V5),(V5,V6)}
2.有向图(directed graph)
一个图结构中,边是有方向性的,那么这种图就称为有向图,如图三所示。由于图的边有方向性,我们在表示边的时候对两个顶点的顺序就有要求。我们采用尖括号表示有向边,例如<V2,V6>表示从顶点V2到顶点V6,而<V6,V2>表示顶点V6到顶点V2。

图三 有向图
对于图三有向图,对应的顶点集合和边集合如下:
V(G)= {V1,V2,V3,V4,V5,V6}
E(G)= {<V2,V1>,<V3,V1>,<V4,V3>,<V4,V2>,<V3,V5>,<V5,V3>,<V2,V5>,<V6,V5>,<V2,V6>,<V6,V2>}
注意:
无向图也可以理解成一个特殊的有向图,就是边互相指向对方节点,A指向B,B又指向A。
3.混合图(mixed graph)
一个图结构中,边同时有的是有方向性有的是无方向型的图。
在生活中混合图这种情况比较常见,比如城市道路中有些道路是单向通行,有的是双向通行。
4.顶点的度
连接顶点的边的数量称为该顶点的度。顶点的度在有向图和无向图中具有不同的表示。对于无向图,一个顶点V的度比较简单,其是连接该顶点的边的数量,记为D(V)。 例如,图二所示的无向图中,顶点V5的度为3。而V6的度为2。
对于有向图要稍复杂些,根据连接顶点V的边的方向性,一个顶点的度有入度和出度之分。
- 入度是以该顶点为端点的入边数量, 记为ID(V)。
- 出度是以该顶点为端点的出边数量, 记为OD(V)。
这样,有向图中,一个顶点V的总度便是入度和出度之和,即D(V) = ID(V) + OD(V)。例如,图三所示的有向图中,顶点V5的入度为3,出度为1,因此,顶点V5的总度为4。
5.邻接顶点
邻接顶点是指图结构中一条边的两个顶点。 邻接顶点在有向图和无向图中具有不同的表示。对于无向图,邻接顶点比较简单。例如,在图二所示的无向图中,顶点V2和顶点V6互为邻接顶点,顶点V2和顶点V5互为邻接顶点等。
对于有向图要稍复杂些,根据连接顶点V的边的方向性,两个顶点分别称为起始顶点(起点或始点)和结束顶点(终点)。有向图的邻接顶点分为两类:
-
入边邻接顶点:连接该顶点的边中的起始顶点。例如,对于组成<V2,V6>这条边的两个顶点,V2是V6的入边邻接顶点。
-
出边邻接顶点:连接该顶点的边中的结束顶点。例如,对于组成<V2,V6>这条边的两个顶点,V6是V2的出边邻接顶点。
6.无向完全图
如果在一个无向图中, 每两个顶点之间都存在条边,那么这种图结构称为无向完全图。典型的无向完全图,如图四所示。

图四 无向完全图
理论上可以证明,对于一个包含M个顶点的无向完全图,其总边数为M(M-1)/2。比如图四总边数就是5(5-1)/ 2 = 10。
7.有向完全图
如果在一个有向图中,每两个顶点之间都存在方向相反的两条边,那么这种图结构称为有向完全图。典型的有向完全图,如图五所示。

图五 有向完全图
理论上可以证明,对于一个包含N的顶点的有向完全图,其总的边数为N(N-1)。这是无向完全图的两倍,这个也很好理解,因为每两个顶点之间需要两条边。
8.有向无环图(DAG图)
如果一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是一个有向无环图。
有向无环图可以利用在区块链技术中。
9.无权图和有权图

这里的权可以理解成一个数值,就是说节点与节点之间这个边是否有一个数值与它对应,对于无权图来说这个边不需要具体的值。对于有权图节点与节点之间的关系可能需要某个值来表示,比如这个数值能代表两个顶点间的距离,或者从一个顶点到另一个顶点的时间,所以这时候这个边的值就是代表着两个节点之间的关系,这种图被称为有权图;
10.图的连通性
图的每个节点不一定每个节点都会被边连接起来,所以这就涉及到图的连通性,如下图:

可以发现上面这个图不是完全连通的。
11.简单图 ( Simple Graph)
对于节点与节点之间存在两种边,这两种边相对比较特殊
1.自环边(self-loop):节点自身的边,自己指向自己。
2.平行边(parallel-edges):两个节点之间存在多个边相连接。

这两种边都是有意义的,比如从A城市到B城市可能不仅仅有一条路,比如有三条路,这样平行边就可以用到这种情况。不过这两种边在算法设计上会加大实现的难度。而简单图就是不考虑这两种边。
数据结构--图 的JAVA实现(上)
1,摘要:
本系列文章主要学习如何使用JAVA语言以邻接表的方式实现了数据结构---图(Graph),这是第一篇文章,学习如何用JAVA来表示图的顶点。从数据的表示方法来说,有二种表示图的方式:一种是邻接矩阵,其实是一个二维数组;一种是邻接表,其实是一个顶点表,每个顶点又拥有一个边列表。下图是图的邻接表表示。
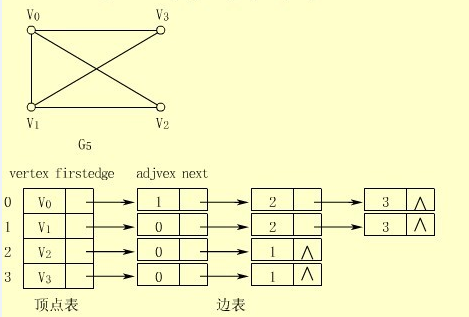
从图中可以看出,图的实现需要能够表示顶点表,能够表示边表。邻接表指是的哪部分呢?每个顶点都有一个邻接表,一个指定顶点的邻接表中,起始顶点表示边的起点,其他顶点表示边的终点。这样,就可以用邻接表来实现边的表示了。如顶点V0的邻接表如下:

与V0关联的边有三条,因为V0的邻接表中有三个顶点(不考虑V0)。
2,具体分析
先来分析边表:
在图中如何来表示一条边?很简单,就是:起始顶点指向结束顶点、就是顶点对<startVertex, endVertex>。在这里,为了考虑边带有权值的情况,单独设计一个类Edge.java,作为Vertex.java的内部类,Edge.java如下:
1 protected class Edge implements java.io.Serializable {
2 private VertexInterface<T> vertex;// 终点
3 private double weight;//权值
Edge类中只有两个属性,vertex 用来表示顶点,该顶点是边的终点。weight 表示边的权值。若不考虑带权的情况,就不需要weight属性,那么可以直接定义一个顶点列表 来存放 终点 就可以表示边了。这是因为:这些属性是定义在Vertex.java中,而Vertex本身就表示顶点,如果在Vertex内部定义一个List存放终点,那么该List再加上Vertex所表示的顶点本身,就可以表示与起点邻接的各个点了(称之为这个 起点的邻接表)。这样的边的特点是:边的所有的起始点都相同。
但是为了表示带权的边,因此,新增加weight属性,并用类Edge来封装,这样不管是带权的边还是不带权的边都可以用同一个Edge类来表示。不带权的边将weight赋值为0即可。
再分析顶点表:
定义接口VertexInterface<T>表示顶点的接口,所有的顶点都需要实现这个接口,该接口中定义了顶点的基本操作,如:判断顶点是否有邻接点,将顶点与另一个顶点连接起来...。其次,顶点表中的每个顶点有两个域,一个是标识域:V0,V1,V2,V3 。一个是指针域,指针域指向一个"单链表"。综上,设计一个类Vertex.java 用来表示顶点,其数据域如下:


class Vertex<T> implements VertexInterface<T>, java.io.Serializable {
private T label;//标识标点,可以用不同类型来标识顶点如String,Integer....
private List<Edge> edgeList;//到该顶点邻接点的边,实际以java.util.LinkedList存储
private boolean visited;//标识顶点是否已访问
private VertexInterface<T> previousVertex;//该顶点的前驱顶点
private double cost;//顶点的权值,与边的权值要区别开来
现在一一解释Vertex类中定义的各个属性:
label : 用来标识顶点,如图中的 V0,V1,V2,V3,在实际代码中,V0...V3 以字符串的形式表示,就可以用来标识不同的顶点了。因此,需要在Vertex类中添加获得顶点标识的方法---getLabel()
1 public T getLabel() {
2 return label;
3 }
edgeList : 存放与该顶点关联的边。从上面Edge.java中可以看到,Edge的实质是“顶点”,因为,Edge类除去wight属性,就只剩表示顶点的vertex属性了。借助edgeList,当给定一个顶点时,就可以访问该顶点的所有邻接点。因此,Vertex.java中就需要实现根据edgeList中存放的边来遍历 某条边的终点(也即相应顶点的各个邻接点) 的迭代器了。
1 public Iterator<VertexInterface<T>> getNeighborInterator() {
2 return new NeighborIterator();
3 }
迭代器的实现如下:
1 /**Task: 遍历该顶点邻接点的迭代器--为 getNeighborInterator()方法 提供迭代器
2 * 由于顶点的邻接点以边的形式存储在java.util.List中,因此借助List的迭代器来实现
3 * 由于顶点的邻接点由Edge类封装起来了--见Edge.java的定义的第一个属性
4 * 因此,首先获得遍历Edge对象的迭代器,再根据获得的Edge对象解析出邻接点对象
5 */
6 private class NeighborIterator implements Iterator<VertexInterface<T>>{
7
8 Iterator<Edge> edgesIterator;
9 private NeighborIterator() {
10 edgesIterator = edgeList.iterator();//获得遍历edgesList 的迭代器
11 }
12 @Override
13 public boolean hasNext() {
14 return edgesIterator.hasNext();
15 }
16
17 @Override
18 public VertexInterface<T> next() {
19 VertexInterface<T> nextNeighbor = null;
20 if(edgesIterator.hasNext()){
21 Edge edgeToNextNeighbor = edgesIterator.next();//LinkedList中存储的是Edge
22 nextNeighbor = edgeToNextNeighbor.getEndVertex();//从Edge对象中取出顶点
23 }
24 else
25 throw new NoSuchElementException();
26 return nextNeighbor;
27 }
28
29 @Override
30 public void remove() {
31 throw new UnsupportedOperationException();
32 }
33 }
visited : 之所以给每个顶点设置一个用来标记它是否被访问的属性,是因为:实现一个数据结构,是要用它去完成某些功能的,如遍历、查找…… 而在图的遍历过程中,就需要标记某个顶点是否被访问了,因此:设置该属性以便实现这些功能。那么,也就需要定义获取顶点是否被访问的isVisited()方法了。
1 public boolean isVisited() {
2 return visited;
3 }
previousVertex 属性 ,在求图中某两个顶点之间的最短路径时,在从起始顶点遍历过程中,需要记录下遍历到某个顶点时的前驱顶点, previousVertex 属性就派上用场了。因此,需要有判断和获取顶点的前驱顶点的方法:
1 public boolean hasPredecessor() {//判断顶点是否有前驱顶点
2 return this.previousVertex != null;
3 }
1 public VertexInterface<T> getPredecessor() {//获得前驱顶点
2 return this.previousVertex;
3 }
cost 属性:用来表示顶点的权值。注意,顶点的权值与边的权值是不同的。比如求无权图(默认是边不带权值)的最短路径时,如何求出顶点A到顶点B的最短的路径?由定义,该最短路径其实就是A走到B经历的最少边数目。因此,就可以用 cost 属性来记录A到B之间的距离是多少了。比如说,A 先走到 C 再走到B;初始时,A的 cost = 0,由于 A 是 C 的前驱,A到B需要经历C,C 的 cost 就是 c.previousVertex.cost + 1,直至 B,就可以求出 A 到 B 的最短路径了。详细算法及实现将会在第二篇博客中给出。
因此,针对 cost 属性,Vertex.java需要实现的方法如下:
1 public void setCost(double newCost) {
2 cost = newCost;
3 }
4 public double getCost() {
5 return cost;
6 }
3,总结:
从上可以看出,设计一个数据结构时,该数据结构需要包含哪些属性不是随意的,而是先确定该数据结构需要完成哪些功能(如,图的DFS、BFS、拓扑排序、最短路径),这些功能的实现需要借助哪些属性(如,求最短路径需要记录每个顶点的前驱顶点,就需要 previousVertex)。然后,去定义这些属性以及关于该属性的基本操作。设计一个合适的数据结构,当借助该数据结构来实现算法时,可以有效地降低算法的实现难度和复杂度!
Vertex.java的完整代码如下:
1 package graph;
2
3 import java.util.Iterator;
4 import java.util.LinkedList;
5 import java.util.List;
6 import java.util.NoSuchElementException;
7
8 class Vertex<T> implements VertexInterface<T>, java.io.Serializable {
9
10 private T label;//标识标点,可以用不同类型来标识顶点如String,Integer....
11 private List<Edge> edgeList;//到该顶点邻接点的边,实际以java.util.LinkedList存储
12 private boolean visited;//标识顶点是否已访问
13 private VertexInterface<T> previousVertex;//该顶点的前驱顶点
14 private double cost;//顶点的权值,与边的权值要区别开来
15
16 public Vertex(T vertexLabel){
17 label = vertexLabel;
18 edgeList = new LinkedList<Edge>();//是Vertex的属性,说明每个顶点都有一个edgeList用来存储所有与该顶点关系的边
19 visited = false;
20 previousVertex = null;
21 cost = 0;
22 }
23
24 /**
25 *Task: 这里用了一个单独的类来表示边,主要是考虑到带权值的边
26 *可以看出,Edge类封装了一个顶点和一个double类型变量
27 *若不需要考虑权值,可以不需要单独创建一个Edge类来表示边,只需要一个保存顶点的列表即可
28 * @author hapjin
29 */
30 protected class Edge implements java.io.Serializable {
31 private VertexInterface<T> vertex;// 终点
32 private double weight;//权值
33
34 //Vertex 类本身就代表顶点对象,因此在这里只需提供 endVertex,就可以表示一条边了
35 protected Edge(VertexInterface<T> endVertex, double edgeWeight){
36 vertex = endVertex;
37 weight = edgeWeight;
38 }
39
40 protected VertexInterface<T> getEndVertex(){
41 return vertex;
42 }
43 protected double getWeight(){
44 return weight;
45 }
46 }
47
48 /**Task: 遍历该顶点邻接点的迭代器--为 getNeighborInterator()方法 提供迭代器
49 * 由于顶点的邻接点以边的形式存储在java.util.List中,因此借助List的迭代器来实现
50 * 由于顶点的邻接点由Edge类封装起来了--见Edge.java的定义的第一个属性
51 * 因此,首先获得遍历Edge对象的迭代器,再根据获得的Edge对象解析出邻接点对象
52 */
53 private class NeighborIterator implements Iterator<VertexInterface<T>>{
54
55 Iterator<Edge> edgesIterator;
56 private NeighborIterator() {
57 edgesIterator = edgeList.iterator();//获得遍历edgesList 的迭代器
58 }
59 @Override
60 public boolean hasNext() {
61 return edgesIterator.hasNext();
62 }
63
64 @Override
65 public VertexInterface<T> next() {
66 VertexInterface<T> nextNeighbor = null;
67 if(edgesIterator.hasNext()){
68 Edge edgeToNextNeighbor = edgesIterator.next();//LinkedList中存储的是Edge
69 nextNeighbor = edgeToNextNeighbor.getEndVertex();//从Edge对象中取出顶点
70 }
71 else
72 throw new NoSuchElementException();
73 return nextNeighbor;
74 }
75
76 @Override
77 public void remove() {
78 throw new UnsupportedOperationException();
79 }
80 }
81
82 /**Task: 生成一个遍历该顶点所有邻接边的权值的迭代器
83 * 权值是Edge类的属性,因此先获得一个遍历Edge对象的迭代器,取得Edge对象,再获得权值
84 * @author hapjin
85 *
86 * @param <Double> 权值的类型
87 */
88 private class WeightIterator implements Iterator{//这里不知道为什么,用泛型报编译错误???
89
90 private Iterator<Edge> edgesIterator;
91 private WeightIterator(){
92 edgesIterator = edgeList.iterator();
93 }
94 @Override
95 public boolean hasNext() {
96 return edgesIterator.hasNext();
97 }
98 @Override
99 public Object next() {
100 Double result;
101 if(edgesIterator.hasNext()){
102 Edge edge = edgesIterator.next();
103 result = edge.getWeight();
104 }
105 else throw new NoSuchElementException();
106 return (Object)result;//从迭代器中取得结果时,需要强制转换成Double
107 }
108 @Override
109 public void remove() {
110 throw new UnsupportedOperationException();
111 }
112
113 }
114
115 @Override
116 public T getLabel() {
117 return label;
118 }
119
120 @Override
121 public void visit() {
122 this.visited = true;
123 }
124
125 @Override
126 public void unVisit() {
127 this.visited = false;
128 }
129
130 @Override
131 public boolean isVisited() {
132 return visited;
133 }
134
135 @Override
136 public boolean connect(VertexInterface<T> endVertex, double edgeWeight) {
137 // 将"边"(边的实质是顶点)插入顶点的邻接表
138 boolean result = false;
139 if(!this.equals(endVertex)){//顶点互不相同
140 Iterator<VertexInterface<T>> neighbors = this.getNeighborInterator();
141 boolean duplicateEdge = false;
142 while(!duplicateEdge && neighbors.hasNext()){//保证不添加重复的边
143 VertexInterface<T> nextNeighbor = neighbors.next();
144 if(endVertex.equals(nextNeighbor)){
145 duplicateEdge = true;
146 break;
147 }
148 }//end while
149 if(!duplicateEdge){
150 edgeList.add(new Edge(endVertex, edgeWeight));//添加一条新边
151 result = true;
152 }//end if
153 }//end if
154 return result;
155 }
156
157 @Override
158 public boolean connect(VertexInterface<T> endVertex) {
159 return connect(endVertex, 0);
160 }
161
162 @Override
163 public Iterator<VertexInterface<T>> getNeighborInterator() {
164 return new NeighborIterator();
165 }
166
167 @Override
168 public Iterator getWeightIterator() {
169 return new WeightIterator();
170 }
171
172 @Override
173 public boolean hasNeighbor() {
174 return !(edgeList.isEmpty());//邻接点实质是存储是List中
175 }
176
177 @Override
178 public VertexInterface<T> getUnvisitedNeighbor() {
179 VertexInterface<T> result = null;
180 Iterator<VertexInterface<T>> neighbors = getNeighborInterator();
181 while(neighbors.hasNext() && result == null){//获得该顶点的第一个未被访问的邻接点
182 VertexInterface<T> nextNeighbor = neighbors.next();
183 if(!nextNeighbor.isVisited())
184 result = nextNeighbor;
185 }
186 return result;
187 }
188
189 @Override
190 public void setPredecessor(VertexInterface<T> predecessor) {
191 this.previousVertex = predecessor;
192 }
193
194 @Override
195 public VertexInterface<T> getPredecessor() {
196 return this.previousVertex;
197 }
198
199 @Override
200 public boolean hasPredecessor() {
201 return this.previousVertex != null;
202 }
203
204 @Override
205 public void setCost(double newCost) {
206 cost = newCost;
207 }
208
209 @Override
210 public double getCost() {
211 return cost;
212 }
213
214 //判断两个顶点是否相同
215 public boolean equals(Object other){
216 boolean result;
217 if((other == null) || (getClass() != other.getClass()))
218 result = false;
219 else
220 {
221 Vertex<T> otherVertex = (Vertex<T>)other;
222 result = label.equals(otherVertex.label);//节点是否相同最终还是由标识 节点类型的类的equals() 决定
223 }
224 return result;
225 }
226 }
数据结构--图 的JAVA实现(下)
在上一篇文章中记录了如何实现图的邻接表。本文借助上一篇文章实现的邻接表来表示一个有向无环图。
1,概述
图的实现与邻接表的实现最大的不同就是,图的实现需要定义一个数据结构来存储所有的顶点以及能够对图进行什么操作,而邻接表的实现重点关注的图中顶点的实现,即怎么定义JAVA类来表示顶点,以及能够对顶点进行什么操作。
为了存储图中所有的顶点,定义了一个Map<key, value>,实际实现为LinkedHashMap<T, VertexInterface<T>>,key 为 顶点的标识,key 是泛型,这样就可以用任意数据类型来标识顶点了,如String、Integer……
value 当然就是表示顶点的类了,因为我们需要存储的是顶点嘛。即value 为 VertexInterface<T> 。这里为什么不用List而用Map来存储顶点呢?用Map的好处就是方便查询顶点,即可以用顶点标识来查找顶点。这也是为了方便后面实现图的DFS、BFS 等算法而考虑的。
此外,还定义了一个整型变量 edgeCount 用来保存图中边的数目,这也是必要的。讨论一个图,当然要有图的顶点,由Map保存,顶点数目可以通过 Map.size() 方法获得;也要有边,而边已经隐含在Vertex.java中了(具体参考上一篇文章),因此这里只定义一个保存图中边的总数的变量即可。图的定义 部分代码如下:
1 public class DirectedGraph<T> implements GraphInterface<T>,java.io.Serializable{
2
3 private static final long serialVersionUID = 1L;
4
5 private Map<T, VertexInterface<T>> vertices;//map 对象用来保存图中的所有顶点.T 是顶点标识,VertexInterface为顶点对象
6 private int edgeCount;//记录图中 边的总数
7
8 public DirectedGraph() {
9 vertices = new LinkedHashMap<>();//按顶点的插入顺序保存顶点
10 }
2,图的基本操作
这里的基本操作不是对图进行DFS、BFS、拓扑排序、求最短路径……而是一系列的如何构造图的方法,这些方法是实现图的遍历、求最短路径、拓扑排序的基础。
在 1 中说明了用Map保存图的顶点,那么如何把顶点对象添加到Map中呢?
1 public void addVertex(T vertexLabel) {
2 //若顶点相同时,新插入的顶点将覆盖原顶点,这是由LinkedHashMap的put方法决定的
3 //每添加一个顶点,会创建一个LinkedList列表,它存储该顶点对应的邻接点,或者说是与该顶点相关联的边
4 vertices.put(vertexLabel, new Vertex(vertexLabel));//new Vertex 对象,会创建一个LinkedList,该LinkedList用来表示该顶点的邻接表
5 }
如何表示图中两个顶点之间的边呢?
1 public boolean addEdge(T begin, T end, double edgeWeight) {
2 boolean result = false;
3 VertexInterface<T> beginVertex = vertices.get(begin);//获得表示边的起始顶点
4 VertexInterface<T> endVertex = vertices.get(end);//获得表示 边的终点
5
6 if(beginVertex != null && endVertex != null)
7 result = beginVertex.connect(endVertex, edgeWeight);//起始点与终点连接,即成一条边
8 if(result)
9 edgeCount++;
10 return result;//当添加重复边时会返回 false
11 }
3,图的相关算法的JAVA实现及分析
正如上一篇文章中的总结提到:算法的实现依赖于采用了何种数据结构,依赖于数据结构--图的具体实现。由于这里的数据结构--图的实现与《算法导论》中描述的图的数据结构有一点差别,如:没有定义表示图的访问状态的"白色顶点、灰色顶点、黑色顶点",因此算法的实现也与《算法导论》中算法的实现有轻微的差别。
对于不带权的图而言(边上没有权值) 广度优先遍历算法与最短路径算法很相似,对广度优先遍历算法稍加修改,就可以变成最短路径算法了。
可参考:无向图的最短路径算法JAVA实现 和 带权图的最短路径算法(Dijkstra)实现
理解:
深度优先遍历算法与拓扑算法也很相似,拓扑排序算法的实现可以借助深度优先遍历算法。
理解:
具体参考《算法导论》
①广度优先遍历算法:若顶点A先于顶点B被访问,则顶点A的邻接点也先于顶点B的邻接点被访问。特点:先把起始顶点附近的顶点访问完,再访问远处的顶点。
在广度优先遍历算法的具体实现中,需要两个队列。一个辅助遍历,保存遍历过程中遇到的顶点,当访问完成了某个顶点A后,将A出队列,紧接着将A的所有邻接点都入队列,并访问。
另一个队列用来保存访问的顺序,另一个队列的顶点入队顺序就是图的广度遍历顺序,因此,该队列保持 与 前一个队列的顶点入队操作 一致。由于前一个队列是辅助遍历的,它有出队的操作,它就不能记录整个顶点的访问序列了,因此才需要一个保存访问顺序的队列。当整个过程遍历完成后,将 保存访问顺序的队列 进行出队操作,即可得到整个图的广度优先遍历的顺序了。具体算法如下:
1 public Queue<T> getBreadthFirstTraversal(T origin) {//origin 标识遍历的初始顶点
2 resetVertices();//将顶点的必要数据域初始化,复杂度为O(V)
3 Queue<VertexInterface<T>> vertexQueue = new LinkedList<>();//保存遍历过程中遇到的顶点,它是辅助遍历的,有出队列操作
4 Queue<T> traversalOrder = new LinkedList<>();//保存遍历过程中遇到的 顶点标识--整个图的遍历顺序就保存在其中,无出队操作
5 VertexInterface<T> originVertex = vertices.get(origin);//根据顶点标识获得初始遍历顶点
6 originVertex.visit();//访问该顶点
7 traversalOrder.offer(originVertex.getLabel());
8 vertexQueue.offer(originVertex);
9
10 while(!vertexQueue.isEmpty()){
11 VertexInterface<T> frontVertex = vertexQueue.poll();//出队列,poll()在队列为空时返回null
12 Iterator<VertexInterface<T>> neighbors = frontVertex.getNeighborInterator();
13 while(neighbors.hasNext())//对于 每个顶点都遍历了它的邻接表,即遍历了所有的边,复杂度为O(E)
14 {
15 VertexInterface<T> nextNeighbor = neighbors.next();
16 if(!nextNeighbor.isVisited()){
17 nextNeighbor.visit();//广度优先遍历未访问的顶点
18 traversalOrder.offer(nextNeighbor.getLabel());
19 vertexQueue.offer(nextNeighbor);//将该顶点的邻接点入队列
20 }
21 }//end inner while
22 }//end outer while
23 return traversalOrder;
24 }
从中可以看出,该算法的时间复杂度为--遍历之前,给每个顶点进行初始化时需要遍历所有顶点V,在遍历过程中需要判断顶点的邻接点是否被遍历,也即遍历该顶点的邻接表,邻接表代表的实质是边,边总数为E,故总的时间复杂度为O(V+E),空间复杂度为O(V)--辅助队列的长度为顶点的长度
②最短路径算法:在边不带权值的图中求顶点A到顶点B的最短路径--其实就是顶点A到顶点B之间的最少边的条数
调用最短路径算法之前,首先要确定一个初始顶点,图中其他顶点的路径长度都是相对于初始顶点而言的。求两个顶点间最短路径,其实并不是找出两个顶点间所有的路径长度,然后取最小值。而是借助于广度优先遍历算法,将每个顶点相对于初始顶点的最短路径长度保存在 cost 属性中,广度优先算法的性质保证了顶点间的路径是最短的。在最短路径的计算中,设初始点为 i,顶点A相对于初始点的最短路径长度为 length,则 顶点A的邻接点 相对于初始顶点 i 的最短长度为 length+1.
因此,执行最短路径算法后,实际上求得了图中所有顶点相对于初始顶点的最短路径。
初始顶点的路径长度为0(每个顶点有一个 cost 属性---见上一文章分析,由 cost 来记录每个顶点相对于初始顶点的路径长度)。因此,获得某顶点的最短路径只需要调用它的getCost方法即可。
最短路径算法的代码如下,可以看出它和广度优先算法的代码非常的相似,其实就是广度优先算法的应用而已。
1 public int getShortestPath(T begin, T end, Stack<T> path) {
2 resetVertices();//图中顶点的初始化
3 boolean done = false;//标记整个遍历过程是否完成
4 Queue<VertexInterface<T>> vertexQueue = new LinkedList<>();//辅助队列,保存遍历过程中遇到的顶点
5 VertexInterface<T> beginVertex = vertices.get(begin);//获得起始顶点
6 VertexInterface<T> endVertex = vertices.get(end);//获得终点,求起始顶点到终点的最短路径
7
8 beginVertex.visit();
9 vertexQueue.offer(beginVertex);//起始顶点入队列
10 //Assertion: resetVertices() 已经对 beginVertex 执行了 setCost(0)
11
12 while(!done && !vertexQueue.isEmpty()){//while循环完成后,实际上求得了图中所有顶点相对于初始点的 cost 属性值
13 VertexInterface<T> frontVertex = vertexQueue.poll();
14 Iterator<VertexInterface<T>> neighbors = frontVertex.getNeighborInterator();
15 while(!done && neighbors.hasNext()){//计算 frontVertex的所有邻接顶点的 路径长度
16 VertexInterface<T> nextNeighbor = neighbors.next();
17 if(!nextNeighbor.isVisited()){
18 nextNeighbor.visit();
19 nextNeighbor.setPredecessor(frontVertex);//设置frontVertex 的前驱顶点
20 nextNeighbor.setCost(frontVertex.getCost() + 1);//该顶点的路径长度是 它的前驱顶点的路径长度+1
21 vertexQueue.offer(nextNeighbor);
22 }//end if
23
24 if(nextNeighbor.equals(endVertex))
25 done = true;
26 }//end inner while
27 }//end outer while. and traverse over
28
29 int pathLength = (int)endVertex.getCost();//初始顶点的 cost为 0,每个顶点的 cost 属性记录了它相对于初始顶点的最短长度
30 path.push(endVertex.getLabel());
31
32 VertexInterface<T> vertex = endVertex;
33 while(vertex.hasPredecessor()){
34 vertex = vertex.getPredecessor();
35 path.push(vertex.getLabel());
36 }
37 return pathLength;
38 }
③深度优先遍历算法:
在深度优先遍历中,需要两个栈,这里可以看出深度优先遍历带有递归的性质。一个栈用来辅助遍历,即用来保存遍历过程中里面的顶点,另一个栈用来保存遍历的顺序。之所以另外需要一个栈来保存遍历的顺序的原因 与 广度优先遍历 中需要用另一个队列来保存 遍历顺序 的原因相同。当深度优先遍历到某个顶点时,若该顶点的所有邻接点均已经被访问,则发生回溯,即返回去遍历 该顶点 的 前驱顶点 的 未被访问的某个邻接点。
深度优先遍历的代码与广度优先遍历的代码很大的一个不同就是,在while 循环里面,当取出栈顶/队头 顶点时,深度优先是用一个 if 语句 来执行逻辑,而广度优先 则是用一个 while 循环来执行逻辑。
这是因为:对于深度优先而言,访问了 顶点A 时,紧接着只需要找到 顶点A 的一个未被访问的邻接点,再访问该邻接点即可。而对于广度优先,访问了 顶点A 时,就是要寻找 顶点A的 所有未被访问的邻接点,再访问 所有的这些邻接点。
代码对比如下:
1 while(!vertexStack.isEmpty()){
2 VertexInterface<T> topVertex = vertexStack.peek();
3 //找到该顶点的一个未被访问的邻接点,从该邻接点出发又去遍历邻接点的邻接点
4 VertexInterface<T> nextNeighbor = topVertex.getUnvisitedNeighbor();
5 if(nextNeighbor != null){
6 nextNeighbor.visit();
7 //由于用的是if,在这里push邻接点后,下一次while循环pop的是该邻接点,然后又获得它的邻接点,---DFS
8 vertexStack.push(nextNeighbor);
9 traversalOrder.offer(nextNeighbor.getLabel());
10 }
11 else
12 vertexStack.pop();//当某顶点的所有邻接点都被访问了时,直接将该顶点pop,这样下一次while pop 时就回溯到前一个顶点
1 while(!vertexQueue.isEmpty()){
2 VertexInterface<T> frontVertex = vertexQueue.poll();//出队列,poll()在队列为空时返回null
3 Iterator<VertexInterface<T>> neighbors = frontVertex.getNeighborInterator();
4 while(neighbors.hasNext())//对于 每个顶点都遍历了它的邻接表,即遍历了所有的边,复杂度为O(E)
5 {
6 VertexInterface<T> nextNeighbor = neighbors.next();
7 if(!nextNeighbor.isVisited()){
8 nextNeighbor.visit();//广度优先遍历未访问的顶点
9 traversalOrder.offer(nextNeighbor.getLabel());
10 vertexQueue.offer(nextNeighbor);//将该顶点的邻接点入队列
11 }
12 }//end inner while
13 }//end outer while
整个深度优先遍历算法代码如下:
1 public Queue<T> getDepthFirstTraversal(T origin) {
2 resetVertices();//先将所有的顶点初始化--时间复杂度为O(V)
3 LinkedList<VertexInterface<T>> vertexStack = new LinkedList<>();//辅助DFS递归遍历
4 Queue<T> traversalOrder = new LinkedList<>();//保存DFS遍历顺序
5
6 VertexInterface<T> originVertex = vertices.get(origin);//根据起始顶点的标识获得起始顶点
7 originVertex.visit();//访问起始顶点,起始顶点的出度不能为0(只考虑多于一个顶点的连通图),若为0,它就没有邻接点了
8 vertexStack.push(originVertex);//各个顶点的入栈顺序就是DFS的遍历顺序
9 traversalOrder.offer(originVertex.getLabel());//每当一个顶点入栈时,就将它入队列,从而队列保存了整个遍历顺序
10
11 while(!vertexStack.isEmpty()){
12 VertexInterface<T> topVertex = vertexStack.peek();
13 //找到该顶点的一个未被访问的邻接点,从该邻接点出发又去遍历邻接点的邻接点
14 VertexInterface<T> nextNeighbor = topVertex.getUnvisitedNeighbor();//判断所有未被访问的邻接点,也即遍历了所有的边--复杂度O(E)
15 if(nextNeighbor != null){
16 nextNeighbor.visit();
17 //由于用的是if,在这里push邻接点后,下一次while循环pop的是该邻接点,然后又获得它的邻接点,---DFS
18 vertexStack.push(nextNeighbor);
19 traversalOrder.offer(nextNeighbor.getLabel());
20 }
21 else
22 vertexStack.pop();//当某顶点的所有邻接点都被访问了时,直接将该顶点pop,这样下一次while pop 时就回溯到前一个顶点
23 }//end while
24 return traversalOrder;
25 }
深度优先遍历的算法的时间复杂度:O(V+E)--遍历之前,给每个顶点进行初始化时需要遍历所有顶点V,在遍历过程中需要判断顶点的邻接点是否被遍历,也即遍历该顶点的邻接表,邻接表代表的实质是边,边总数为 E,故总的时间复杂度为O(V+E);空间复杂度:O(V)--用了两个辅助栈
④拓扑排序算法
求图的拓扑序列的思路就是:先找到图中一个出度为0的顶点,访问该顶点并将之入栈。访问了该顶点之后,相当于指向该顶点的所有的边都已经被删除了。然后,继续在图中寻找下一个出度为0且未被访问的顶点,直至图中所有的顶点都已被访问。寻找这样的顶点的方法实现如下:
1 private VertexInterface<T> getNextTopologyOrder(){//最坏情况下复杂度为O(V+E)
2 VertexInterface<T> nextVertex = null;
3 Iterator<VertexInterface<T>> iterator = vertices.values().iterator();//获得图的顶点的迭代器
4 boolean found = false;
5 while(!found && iterator.hasNext()){
6 nextVertex = iterator.next();
7 //寻找出度为0且未被访问的顶点
8 if(nextVertex.isVisited() == false && nextVertex.getUnvisitedNeighbor() == null)
9 found = true;
10 }
11 return nextVertex;
12 }
图的拓扑排序实现代码如下:
1 public Stack<T> getTopologicalSort() {
2 /**
3 *相比于《算法导论》中的拓扑排序借助了DFS复杂度为O(V+E),该算法的时间复杂度较大
4 *因为算法导论中介绍的图的数据结构与此处实现的图的数据结构不同
5 *此算法的最坏时间复杂度为O(V*(V+E))==V * max{V,E}
6 */
7 resetVertices();//先将所有的顶点初始化
8
9 Stack<T> vertexStack = new Stack<>();//存放已访问的顶点的栈,该栈就是一个拓扑序列
10 int numberOfVertices = vertices.size();//获得图中顶点的个数
11
12 for(int counter = 1; counter <= numberOfVertices; counter++){
13 VertexInterface<T> nextVertex = getNextTopologyOrder();//获得一个未被访问的且出度为0的顶点
14 if(nextVertex != null){
15 nextVertex.visit();
16 vertexStack.push(nextVertex.getLabel());//遍历完成后,出栈就可以获得图的一个拓扑序列
17 }
18 }
19 return vertexStack;
20 }
此拓扑排序算法实现的最坏情况下时间复杂度为:O(V*max(V,E));空间复杂度为:O(V)--定义一个辅助栈来保存遍历顺序
4,总结
本文实现了有向无环图及四个常用的图的遍历算法,在客户程序中只需要 new 一个图对象,然后就可以调用这些算法了。哈哈,以后可以用这个类来测试一些复杂的算法了。。。
在实现过程中让我明白了,数据结构与算法是紧密相关的,算法实现的难易程序及好坏依赖于你所设计的数据结构。
整个数据结构的学习至此为止告一段落了。在整个学习过程中,用JAVA语言把常用的数据结构数组、链表、栈、队列、树、词典、图都实现了一遍。感觉学到最多的是加深了对JAVA集合类库的理解和基本算法的理解(树的遍历算法和图的遍历算法)。

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步