
数据结构和算法-深搜广搜(DFS、BFS)
参考:
https://blog.csdn.net/sugarbliss/article/details/79814297
https://blog.csdn.net/hehuanchun0311/article/details/80168109
https://leetcode-cn.com/problems/generate-parentheses/
https://blog.csdn.net/weixin_42289193/article/details/81741756
深度优先搜索(DFS)
如算法名称那样,深度优先搜索所遵循的搜索策略是尽可能“深”地搜索树。它的基本思想是:为了求得问题的解,先选择某一种可能情况向前(子结点)探索,在探索过程中,一旦发现原来的选择不符合要求,就回溯至父亲结点重新选择另一结点,继续向前探索,如此反复进行,直至求得最优解。深度优先搜索的实现方式可以采用递归或者栈来实现。由此可见,把通常问题转化为树的问题是至关重要的一步,完成了树的转换基本完成了问题求解。
广度优先搜索(BFS)
BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。类似树的按层遍历,其过程为:首先访问初始点Vi,并将其标记为已访问过,接着访问Vi的所有未被访问过可到达的邻接点Vi1、Vi2……Vit,并均标记为已访问过,然后再按照Vi1、Vi2……Vit的次序,访问每一个顶点的所有未被访问过的邻接点,并均标记为已访问过,依此类推,直到图中所有和初始点Vi有路径相通的顶点都被访问过为止。数据结构--图、DFS、BFS
一、图的基本概念
线性表和树两类数据结构,线性表中的元素是“一对一”的关系,树中的元素是“一对多”的关系,本章所述的图结构中的元素则是“多对多”的关系。
图(Graph)是一种复杂的非线性结构,在图结构中,每个元素都可以有零个或多个前驱,也可以有零个或多个后继,也就是说,元素之间的关系是任意的。
无向图:
无向图是由顶点和边构成。
有向图:
有向图是由顶点和有向边构成。
完全图:
如果任意两个顶点之间都存在边叫完全图,有向的边叫有向完全图。如果无重复的边或者顶点到自身的边叫简单图。
二、图的节点表示
/**
* 无向简单图的节点
* @author hoaven
*/
public class GraphNode<T> {
T data;
List<GraphNode<T>> neighborList;
boolean visited;
public GraphNode(T data){
this.data = data;
neighborList = new ArrayList<GraphNode<T>>();
visited = false;
}
public boolean equals(GraphNode<T> node){
return this.data.equals(node.data);
}
/**
* 还原图中所有节点为未访问
*/
public void restoreVisited(){
restoreVisited(this);
}
/**
* 还原node的图所有节点为未访问
* @param node
*/
private void restoreVisited(GraphNode<T> node){
if(node.visited){
node.visited = false;
}
List<GraphNode<T>> neighbors = node.neighborList;
for(int i = 0; i < neighbors.size(); i++){
restoreVisited(neighbors.get(i));
}
}
}三、图的深度优先和广度优先搜索
1、深度优先
1.1、介绍
图的深度优先搜索(Depth First Search),和树的先序遍历比较类似。
思路:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。显然,深度优先搜索是一个递归的过程。
1.2、无向图深度优先搜索图解
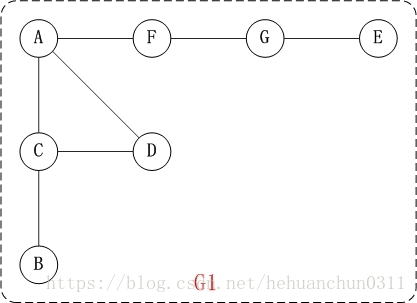
对上面的图G1进行深度优先遍历,从顶点A开始。
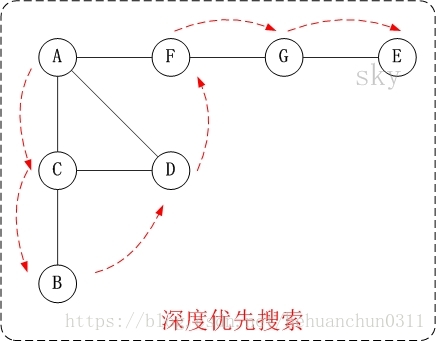
- 第1步:访问A。
- 第2步:访问(A的邻接点)C。在第1步访问A之后,接下来应该访问的是A的邻接点,即”C,D,F”中的一个。但在本文的实现中,顶点ABCDEFG是按照顺序存储,C在”D和F”的前面,因此,先访问C。
- 第3步:访问(C的邻接点)B。在第2步访问C之后,接下来应该访问C的邻接点,即”B和D”中一个(A已经被访问过,就不算在内)。而由于B在D之前,先访问B。
- 第4步:访问(C的邻接点)D。
- 第5步:访问(A的邻接点)F。
- 第6步:访问(F的邻接点)G。
- 第7步:访问(G的邻接点)E。
访问顺序是:A -> C -> B -> D -> F -> G -> E
1.3、有向图深度优先搜索图解
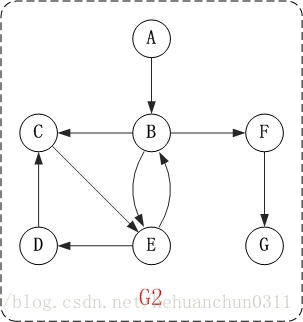
对上面的图G2进行深度优先遍历,从顶点A开始。
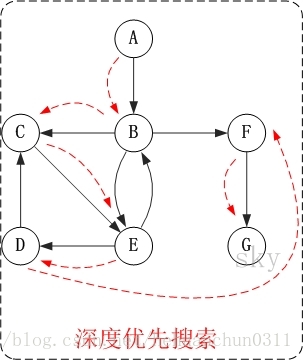
访问顺序是:A -> B -> C -> E -> D -> F -> G
2、广度优先
2.1、介绍
从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。换句话说,广度优先搜索遍历图的过程是以v为起点,由近至远。
2.2、无向图广度优先搜索图解
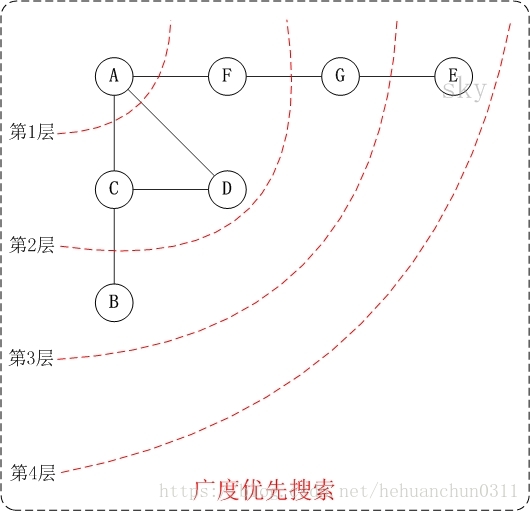
访问顺序是:A -> C -> D -> F -> B -> G -> E
2.3、有向图广度优先搜索图解
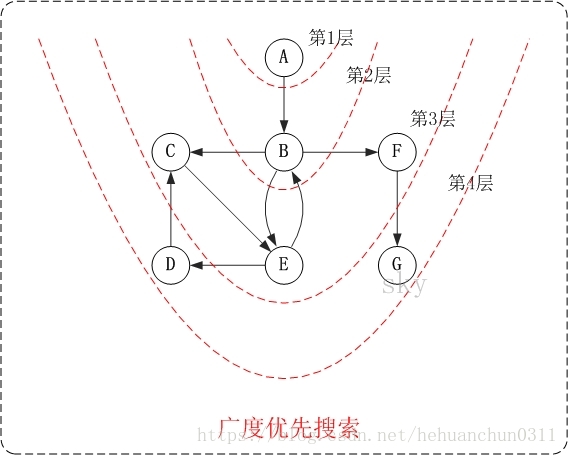
访问顺序是:A -> B -> C -> E -> F -> D -> G
3、实现
/**
* 图的广度优先搜索和深度优先搜索实现
*
* @author hoaven
* @see GraphNode
*/
public class GraphSearch<T> {
public StringBuffer searchPathDFS = new StringBuffer();
public StringBuffer searchPathBFS = new StringBuffer();
/**
* 深度优先搜索实现
*
* @param root
*/
public void searchDFS(GraphNode<T> root) {
if (root == null) {
return;
}
// visited root
if (searchPathDFS.length() > 0) {
searchPathDFS.append("->");
}
searchPathDFS.append(root.data.toString());
root.visited = true;
for (GraphNode<T> node : root.neighborList) {
if (!node.visited) {
searchDFS(node);
}
}
}
/**
* 广度优先搜索实现,使用队列
*
* @param root
*/
public void searchBFS(GraphNode<T> root) {
IQueue<GraphNode<T>> queue = new Queue<GraphNode<T>>();
// visited root
if (searchPathBFS.length() > 0) {
searchPathBFS.append("->");
}
searchPathBFS.append(root.data.toString());
root.visited = true;
// 加到队列队尾
queue.enqueue(root);
while (!queue.isEmpty()) {
GraphNode<T> r = queue.dequeue();
for (GraphNode<T> node : r.neighborList) {
if (!node.visited) {
searchPathBFS.append("->");
searchPathBFS.append(node.data.toString());
node.visited = true;
queue.enqueue(node);
}
}
}
}
}
//测试用例
/**
* GraphSearch测试
* @author hoaven
* @see GraphNode
* @see GraphSearch
*/
public class GraphSearchTest {
GraphNode<Integer> node1;
GraphNode<Integer> node2;
GraphNode<Integer> node3;
GraphNode<Integer> node4;
GraphNode<Integer> node5;
GraphNode<Integer> node6;
GraphNode<Integer> node7;
GraphNode<Integer> node8;
GraphNode<Integer> node9;
GraphNode<Integer> node10;
@Before
public void before(){
node1 = new GraphNode<Integer>(1);
node2 = new GraphNode<Integer>(2);
node3 = new GraphNode<Integer>(3);
node4 = new GraphNode<Integer>(4);
node5 = new GraphNode<Integer>(5);
node6 = new GraphNode<Integer>(6);
node7 = new GraphNode<Integer>(7);
node8 = new GraphNode<Integer>(8);
node9 = new GraphNode<Integer>(9);
node10 = new GraphNode<Integer>(10);
node1.neighborList.add(node2);
node1.neighborList.add(node3);
node2.neighborList.add(node4);
node2.neighborList.add(node5);
node2.neighborList.add(node6);
node3.neighborList.add(node1);
node3.neighborList.add(node6);
node3.neighborList.add(node7);
node3.neighborList.add(node8);
node4.neighborList.add(node2);
node4.neighborList.add(node5);
node5.neighborList.add(node2);
node5.neighborList.add(node4);
node5.neighborList.add(node6);
node6.neighborList.add(node2);
node6.neighborList.add(node5);
node6.neighborList.add(node3);
node6.neighborList.add(node8);
node6.neighborList.add(node9);
node6.neighborList.add(node10);
node7.neighborList.add(node3);
node8.neighborList.add(node3);
node8.neighborList.add(node6);
node8.neighborList.add(node9);
node9.neighborList.add(node6);
node9.neighborList.add(node8);
node9.neighborList.add(node10);
node10.neighborList.add(node6);
node10.neighborList.add(node9);
}
@Test
public void searchDFSTest(){
GraphSearch<Integer> graphSearch = new GraphSearch<Integer>();
graphSearch.searchDFS(node1);
String expectedSearchPath = "1->2->4->5->6->3->7->8->9->10";
Assert.assertEquals(expectedSearchPath, graphSearch.searchPathDFS.toString());
}
@Test
public void searchBFSTest(){
GraphSearch<Integer> graphSearch = new GraphSearch<Integer>();
graphSearch.searchBFS(node1);
String expectedSearchPath = "1->2->3->4->5->6->7->8->9->10";
Assert.assertEquals(expectedSearchPath, graphSearch.searchPathBFS.toString());
}
}
leetcode:22. 括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例:
输入:n = 3
输出:[
"((()))",
"(()())",
"(())()",
"()(())",
"()()()"
]
解法:回溯算法(深度优先遍历)+ 广度优先遍历(Java)
这一类问题是在一棵隐式的树上求解,可以用深度优先遍历,也可以用广度优先遍历。
一般用深度优先遍历。原因是:
代码好写,使用递归的方法,直接借助系统栈完成状态的转移;
广度优先遍历得自己编写结点类和借助队列。
这里的「状态」是指程序执行到 隐式树 的某个结点的语言描述,在程序中用不同的 变量 加以区分。

方法一:深度优先遍历
我们以 n = 2 为例,画树形结构图。方法是 「做减法」。
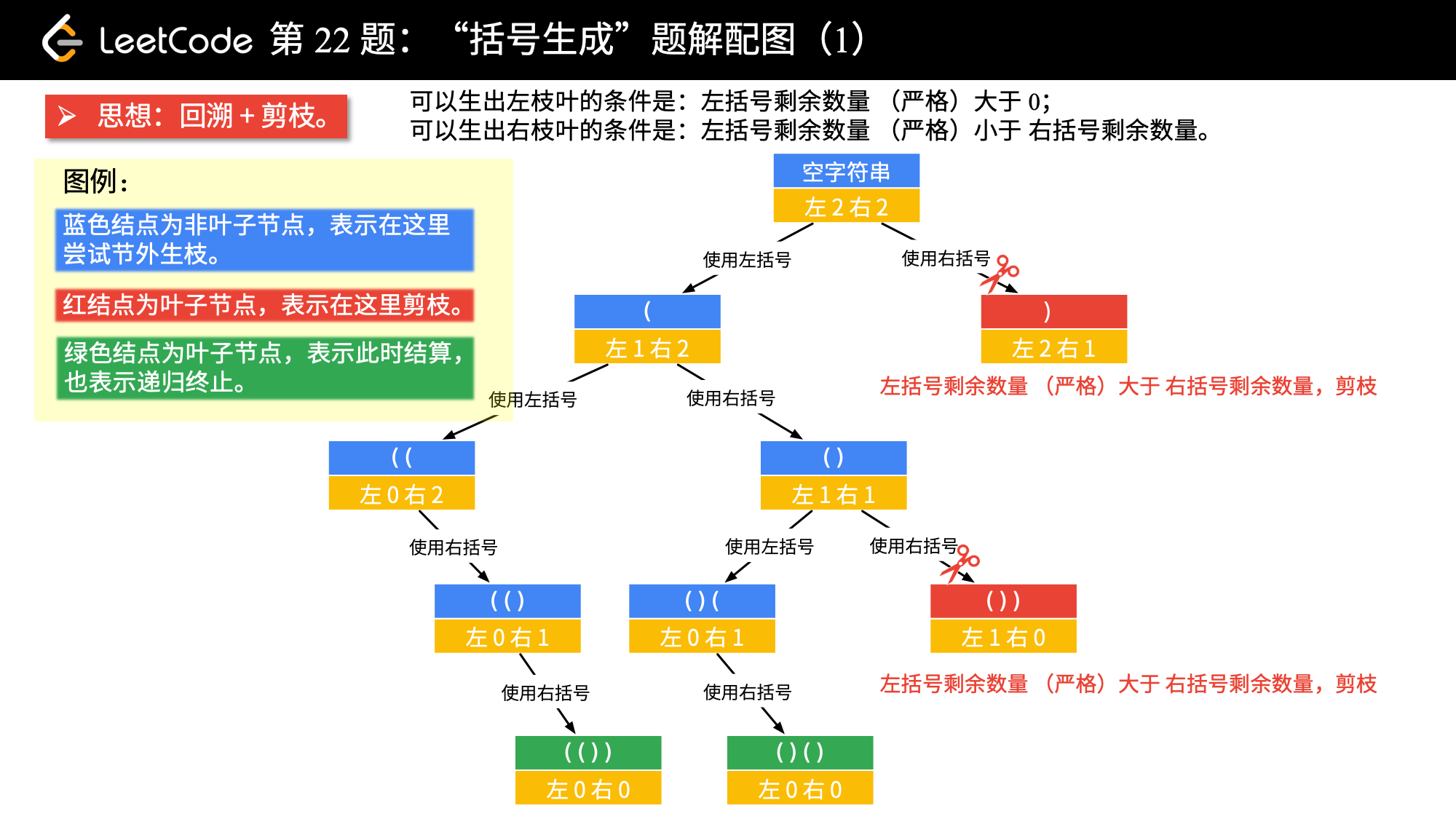
画图以后,可以分析出的结论:
当前左右括号都有大于 00 个可以使用的时候,才产生分支;
产生左分支的时候,只看当前是否还有左括号可以使用;
产生右分支的时候,还受到左分支的限制,右边剩余可以使用的括号数量一定得在严格大于左边剩余的数量的时候,才可以产生分支;
在左边和右边剩余的括号数都等于 00 的时候结算。
参考代码 1:
import java.util.ArrayList; import java.util.List; public class Solution { // 做减法 public List<String> generateParenthesis(int n) { List<String> res = new ArrayList<>(); // 特判 if (n == 0) { return res; } // 执行深度优先遍历,搜索可能的结果 dfs("", n, n, res); return res; } /** * @param curStr 当前递归得到的结果 * @param left 左括号还有几个可以使用 * @param right 右括号还有几个可以使用 * @param res 结果集 */ private void dfs(String curStr, int left, int right, List<String> res) { // 因为每一次尝试,都使用新的字符串变量,所以无需回溯 // 在递归终止的时候,直接把它添加到结果集即可,注意与「力扣」第 46 题、第 39 题区分 if (left == 0 && right == 0) { res.add(curStr); return; } // 剪枝(如图,左括号可以使用的个数严格大于右括号可以使用的个数,才剪枝,注意这个细节) if (left > right) { return; } if (left > 0) { dfs(curStr + "(", left - 1, right, res); } if (right > 0) { dfs(curStr + ")", left, right - 1, res); } } }
我们运行 n = 2 的情况,得到结果 [(()), ()()] ,说明分析的结果是正确的。
如果我们不用减法,使用加法,即 left 表示「左括号还有几个没有用掉」,right 表示「右括号还有几个没有用掉」,可以画出另一棵递归树。
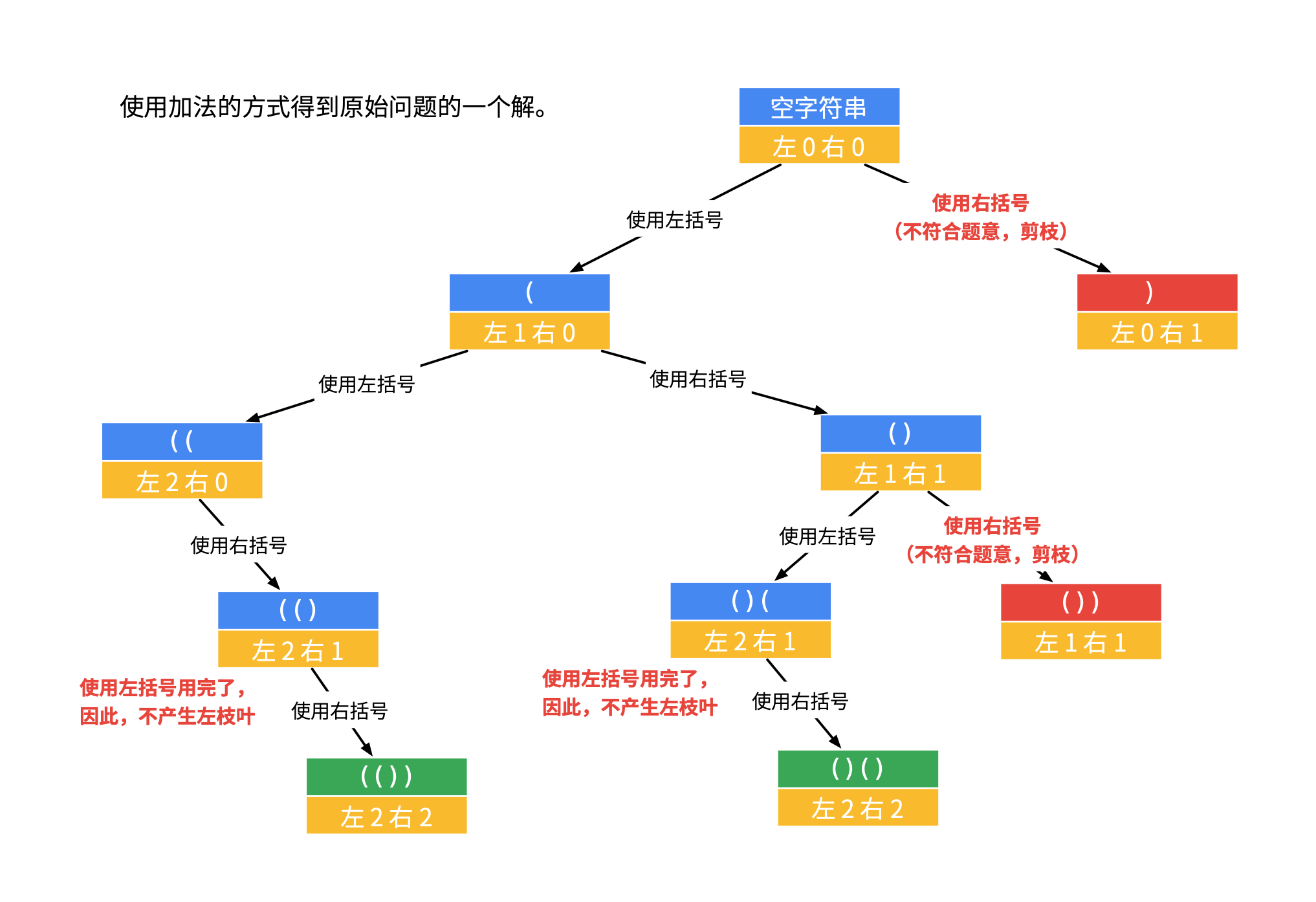
下面是参考代码。
参考代码 2:
import java.util.ArrayList;
import java.util.List;
public class Solution {
// 做加法
public List<String> generateParenthesis(int n) {
List<String> res = new ArrayList<>();
// 特判
if (n == 0) {
return res;
}
dfs("", 0, 0, n, res);
return res;
}
/**
* @param curStr 当前递归得到的结果
* @param left 左括号已经用了几个
* @param right 右括号已经用了几个
* @param n 左括号、右括号一共得用几个
* @param res 结果集
*/
private void dfs(String curStr, int left, int right, int n, List<String> res) {
if (left == n && right == n) {
res.add(curStr);
return;
}
// 剪枝
if (left < right) {
return;
}
if (left < n) {
dfs(curStr + "(", left + 1, right, n, res);
}
if (right < n) {
dfs(curStr + ")", left, right + 1, n, res);
}
}
}
方法二:广度优先遍历
通过编写广度优先遍历的代码,读者可以体会一下,为什么搜索几乎都是用深度优先遍历(回溯算法)。
广度优先遍历,得程序员自己编写结点类,显示使用队列这个数据结构。深度优先遍历的时候,就可以直接使用系统栈,在递归方法执行完成的时候,系统栈顶就把我们所需要的状态信息直接弹出,而无须编写结点类和显示使用栈。
下面的代码,读者可以把 Queue 换成 Stack,提交以后,也可以得到 Accept。
读者可以通过比较:
广度优先遍历;
自己使用栈编写深度优先遍历;
使用系统栈的深度优先遍历(回溯算法)。
来理解「回溯算法」作为一种「搜索算法」的合理性。
还是上面的题解配图(1),使用广度优先遍历,结果集都在最后一层,即叶子结点处得到所有的结果集,编写代码如下。
参考代码 3:(前 2 个 Java 代码写法没有本质不同,仅供参考。第 3 个 Java 代码仅仅是把 Queue 换成了 Stack ,广度优先遍历就改成了深度优先遍历。)
import java.util.ArrayDeque; import java.util.ArrayList; import java.util.Deque; import java.util.LinkedList; import java.util.List; import java.util.Queue; public class Solution { class Node { /** * 当前得到的字符串 */ private String res; /** * 剩余左括号数量 */ private int left; /** * 剩余右括号数量 */ private int right; public Node(String str, int left, int right) { this.res = str; this.left = left; this.right = right; } } public List<String> generateParenthesis(int n) { List<String> res = new ArrayList<>(); if (n == 0) { return res; } Queue<Node> queue = new LinkedList<>(); queue.offer(new Node("", n, n)); while (!queue.isEmpty()) { Node curNode = queue.poll(); if (curNode.left == 0 && curNode.right == 0) { res.add(curNode.res); } if (curNode.left > 0) { queue.offer(new Node(curNode.res + "(", curNode.left - 1, curNode.right)); } if (curNode.right > 0 && curNode.left < curNode.right) { queue.offer(new Node(curNode.res + ")", curNode.left, curNode.right - 1)); } } return res; } }
import java.util.ArrayList; import java.util.LinkedList; import java.util.List; import java.util.Queue; public class Solution { class Node { /** * 当前得到的字符串 */ private String res; /** * 剩余左括号数量 */ private int left; /** * 剩余右括号数量 */ private int right; public Node(String res, int left, int right) { this.res = res; this.left = left; this.right = right; } @Override public String toString() { return "Node{" + "res='" + res + '\'' + ", left=" + left + ", right=" + right + '}'; } } public List<String> generateParenthesis(int n) { List<String> res = new ArrayList<>(); if (n == 0) { return res; } Queue<Node> queue = new LinkedList<>(); queue.offer(new Node("", n, n)); // 总共需要拼凑的字符总数是 2 * n n = 2 * n; while (n > 0) { int size = queue.size(); for (int i = 0; i < size; i++) { Node curNode = queue.poll(); if (curNode.left > 0) { queue.offer(new Node(curNode.res + "(", curNode.left - 1, curNode.right)); } if (curNode.right > 0 && curNode.left < curNode.right) { queue.offer(new Node(curNode.res + ")", curNode.left, curNode.right - 1)); } } n--; } // 最后一层就是题目要求的结果集 while (!queue.isEmpty()) { res.add(queue.poll().res); } return res; } }
import java.util.ArrayDeque; import java.util.ArrayList; import java.util.Deque; import java.util.LinkedList; import java.util.List; import java.util.Queue; import java.util.Stack; public class Solution { class Node { /** * 当前得到的字符串 */ private String res; /** * 剩余左括号数量 */ private int left; /** * 剩余右括号数量 */ private int right; public Node(String str, int left, int right) { this.res = str; this.left = left; this.right = right; } } // 注意:这是深度优先遍历 public List<String> generateParenthesis(int n) { List<String> res = new ArrayList<>(); if (n == 0) { return res; } // 查看了 Stack 源码,官方推荐使用 Deque 对象, // 注意:只使用栈相关的接口,即只使用 `addLast()` 和 `removeLast()` Deque<Node> stack = new ArrayDeque<>(); stack.addLast(new Node("", n, n)); while (!stack.isEmpty()) { Node curNode = stack.removeLast(); if (curNode.left == 0 && curNode.right == 0) { res.add(curNode.res); } if (curNode.left > 0) { stack.addLast(new Node(curNode.res + "(", curNode.left - 1, curNode.right)); } if (curNode.right > 0 && curNode.left < curNode.right) { stack.addLast(new Node(curNode.res + ")", curNode.left, curNode.right - 1)); } } return res; } }
Java实现深度优先遍历和广度优先遍历【二叉树】
概念定义:
深度优先遍历:深度优先遍历是图论中的经典算法。其利用了深度优先搜索算法可以产生目标图的相应拓扑排序表,采用拓扑排序表可以解决很多相关的图论问题,如最大路径问题等等。
根据深度优先遍历的特点我们利用Java集合类的栈Stack先进后出的特点来实现。我用二叉树来进行深度优先搜索。
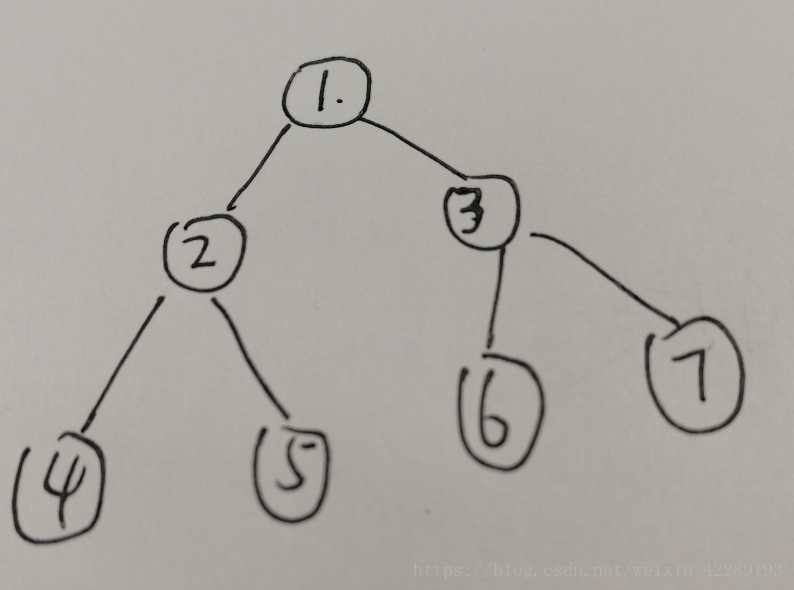
深度优先搜索的步骤为:
(1)、首先节点 1 进栈,节点1在栈顶;
(2)、然后节点1出栈,访问节点1,节点1的孩子节点3进栈,节点2进栈;
(3)、节点2在栈顶,然后节点2出栈,访问节点2
(4)、节点2的孩子节点5进栈,节点4进栈
(5)、节点4在栈顶,节点4出栈,访问节点4,
(6)、节点4左右孩子为空,然后节点5在栈顶,节点5出栈,访问节点5;
(7)、节点5左右孩子为空,然后节点3在站顶,节点3出栈,访问节点3;
(8)、节点3的孩子节点7进栈,节点6进栈
(9)、节点6在栈顶,节点6出栈,访问节点6;
(10)、节点6的孩子为空,这个时候节点7在栈顶,节点7出栈,访问节点7
(11)、节点7的左右孩子为空,此时栈为空,遍历结束。
广度优先遍历:广度优先遍历是连通图的一种遍历策略,因为它的思想是从一个顶点V0开始,辐射状地优先遍历其周围较广的区域故得名。
根据广度优先遍历的特点我们利用Java数据结构队列Queue来实现。
广度优先搜索的步骤为:
(1)、节点1进队,节点1出队,访问节点1
(2)、节点1的孩子节点2进队,节点3进队。
(3)、节点2出队,访问节点2,节点2的孩子节点4进队,节点5进队;
(4)、节点3出队,访问节点3,节点3的孩子节点6进队,节点7进队;
(5)、节点4出队,访问节点4,节点4没有孩子节点。
(6)、节点5出队,访问节点5,节点5没有孩子节点。
(7)、节点6出队,访问节点6,节点6没有孩子节点。
(8)、节点7出队,访问节点7,节点7没有孩子节点,结束。
代码:
二叉树的基础代码:
/** * 二叉树数据结构 * * */ public class TreeNode { int data; TreeNode leftNode; TreeNode rightNode; public TreeNode() { } public TreeNode(int d) { data=d; } public TreeNode(TreeNode left,TreeNode right,int d) { leftNode=left; rightNode=right; data=d; } }
广度优先和深度优先遍历算法实现代码:
import java.util.LinkedList; import java.util.Queue; import java.util.Stack; /** * 深度优先遍历 * * */ public class DeepFirstSort { public static void main(String[] args) { TreeNode head=new TreeNode(1); TreeNode second=new TreeNode(2); TreeNode three=new TreeNode(3); TreeNode four=new TreeNode(4); TreeNode five=new TreeNode(5); TreeNode six=new TreeNode(6); TreeNode seven=new TreeNode(7); head.rightNode=three; head.leftNode=second; second.rightNode=five; second.leftNode=four; three.rightNode=seven; three.leftNode=six; System.out.print("广度优先遍历结果:"); new DeepFirstSort().BroadFirstSearch(head); System.out.println(); System.out.print("深度优先遍历结果:"); new DeepFirstSort().depthFirstSearch(head); } //广度优先遍历是使用队列实现的 public void BroadFirstSearch(TreeNode nodeHead) { if(nodeHead==null) { return; } Queue<TreeNode> myQueue=new LinkedList<>(); myQueue.add(nodeHead); while(!myQueue.isEmpty()) { TreeNode node=myQueue.poll(); System.out.print(node.data+" "); if(null!=node.leftNode) { myQueue.add(node.leftNode); //深度优先遍历,我们在这里采用每一行从左到右遍历 } if(null!=node.rightNode) { myQueue.add(node.rightNode); } } } //深度优先遍历 public void depthFirstSearch(TreeNode nodeHead) { if(nodeHead==null) { return; } Stack<TreeNode> myStack=new Stack<>(); myStack.add(nodeHead); while(!myStack.isEmpty()) { TreeNode node=myStack.pop(); //弹出栈顶元素 System.out.print(node.data+" "); if(node.rightNode!=null) { myStack.push(node.rightNode); //深度优先遍历,先遍历左边,后遍历右边,栈先进后出 } if(node.leftNode!=null) { myStack.push(node.leftNode); } } } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号