
数据结构和算法-递归
参考:
https://zhuanlan.zhihu.com/p/81952290
https://www.cnblogs.com/yanggb/p/11138049.html
https://blog.csdn.net/sinat_38052999/article/details/73303111
https://mp.weixin.qq.com/s?__biz=MzU0ODMyNDk0Mw==&mid=2247487910&idx=1&sn=2670aec7139c6b98e83ff66114ac1cf7&chksm=fb418286cc360b90741ed54fecd62fd45571b2caba3e41473a7ea0934f918d4b31537689c664&scene=21#wechat_redirect
算法一看就懂之「 递归 」
之前的文章咱们已经聊过了「 数组和链表 」、「 堆栈 」和「 队列 」,今天咱们来看看「 递归 」,当然「 递归 」并不是一种数据结构,它是很多算法都使用的一种编程方法。它太普遍了,并且用它来解决问题非常的优雅,但它又不是那么容易弄懂,所以我特意用一篇文章来介绍它。
一、「 递归 」是什么?
递归 就是指函数直接或间接的调用自己,递归是基于栈来实现的。递归的经典例子就是 斐波拉契数列(Fibonacci)。一般如果能用递归来实现的程序,那它也能用循环来实现。用递归来实现的话,代码看起来更清晰一些,但递归的性能并不占优势,时间复杂度甚至也会更大一些。
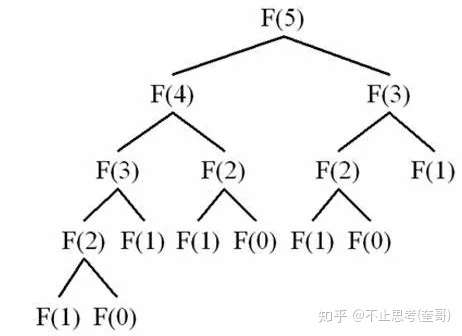
上图为 斐波拉契数列 图例。
要实现递归,必须满足2个条件:
- 可调用自己
就是我们要解决的这个问题,可以通过函数调用自己的方式来解决,即可以通过将大问题分解为子问题,然后子问题再可以分解为子子问题,这样不停的分解。并且大问题与子问题/子子问题的解决思路是完全一样的,只不过数据不一样。因此这些问题都是通过某一个函数去解决的,最终我们看到的就是不停得函数调用自己,然后就把问题化解了。
如果这个问题不能分解为子问题,或子问题的解决方法与大问题不一样,那就无法通过递归调用来解决。 - 可停止调用自己
停止调用的条件非常关键,就是大问题不停的一层层分解为小问题后,最终必须有一个条件是来终止这种分解动作的(也就是停止调用自己),做递归运算一定要有这个终止条件,否则就会陷入无限循环。
下面还是以 斐波拉契数列(Fibonacci)为例,我们来理解一下递归:
斐波拉契数列就是由数字 1,1,2,3,5,8,13…… 组成的这么一组序列,特点是每位数字都是前面相邻两项之和。如果我们希望得出第N位的数字是多少?
- 可以使用循环的方式求解:
这里就不列代码了,思路是:我们知道最基本的情况是 f(0)=0,f(1)=1,因此我们可以设置一个一个循环,循环从i=2开始,循环N-1次,在循环体内 f(i)=f(i-1)+f(i-2),直到i=N-1,这样循环结束的时候就求出了f(N)的值了。 - 更优雅的方式是使用递归的方式求解:
我们知道斐波拉契数列的逻辑就是:
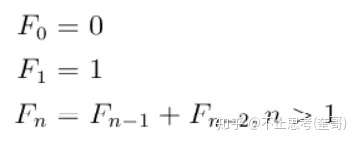
可以看出,这个逻辑是满足上面2个基本条件,假如求解 f(3),那 f(3)=f(2)+f(1),因此我们得继续去求解f(2),而 f(2)=f(1)+f(0),因此整个求解过程其实就在不断的分解问题的过程,将大问题f(3),分解为f(2)和f(1)的问题,以此类推。既然可以分解成子问题,并且子问题的解决方法与大问题一致,因此这个问题是满足“可调用自己”的递归要求。
同时,我们也知道应该在何时停止调用自己,即当子问题变成了f(0)和f(1)时,就不再需要往下分解了,因此也满足递归中“可停止调用自己”的这个要求。
所以,斐波拉契数列问题可以采用递归的方式去编写代码,先看图:
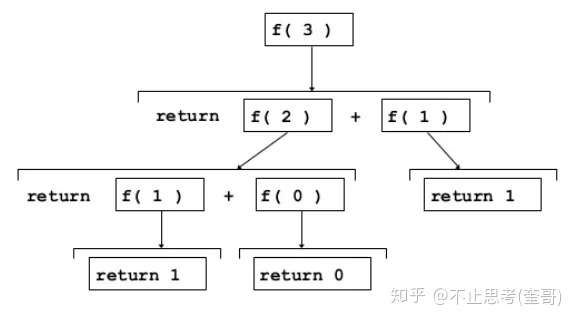
我们将代码写出来:
int Fb(int n){
if(n<=1) return n==0?0:1;
return Fb(n-1)+Fb(n-2); //这里就是函数自己调用自己
}
从上面的例子可以看出,我们写递归代码最重要的就是写2点:
- 递推公式
上面代码中,递推公式就是 Fb(n)=Fb(n-1)+Fb(n-2),正是这个公式,才可以一步步递推下去,这也是函数自己调用自己的关键点。因此我们在写递归代码的时候最首先要做的就是思考整个逻辑中的递推公式。 - 递归停止条件
上面代码中的停止条件很明显就是:if(n<=1) return n==0?0:1;这就是递归的出口,想出了递推公司之后,就要考虑递归停止条件是啥,没有停止条件就会无限循环了,通常递归的停止条件是程序的边界值。
我们对比实现斐波拉契数列问题的2种方式,可以看出递归的方式比循环的方式在程序结构上更简洁清晰,代码也更易读。但递归调用的过程中会建立函数副本,创建大量的调用栈,如果递归的数据量很大,调用层次很多,就会导致消耗大量的时间和空间,不仅性能较低,甚至会出现堆栈溢出的情况。
我们在写递归的时候,一定要注意递归深度的问题,随时做好判断,防止出现堆栈溢出。
另外,我们在思考递归逻辑的时候,没必要在大脑中将整个递推逻辑一层层的想透彻,一般人都会绕晕的。大脑很辛苦的,我们应该对它好一点。我们只需要关注当前这一层是否成立即可,至于下一层不用去关注,当前这一层逻辑成立了,下一层肯定也会成立的,最后只需要拿张纸和笔,模拟一些简单数据代入到公式中去校验一下递推公式对不对即可。
二、「 递归 」的算法实践?
我们看看经常涉及到 递归 的 算法题(来源leetcode):
算法题:实现 pow(x, n) ,即计算 x 的 n 次幂函数。
说明:
-100.0 < x < 100.0
n 是 32 位有符号整数,其数值范围是 [−2^31, 2^31 − 1]
示例:
输入: 2.00000, 10
输出: 1024.00000
解题思路:
方法一:
暴力解法,直接写一个循环让n个x相乘嘛,当然了这种方式就没啥技术含量了,时间复杂度O(1),代码省略了。
方法二:
基于递归原理,很容易就找出递推公式 f(n)=x*f(n-1),再找出递归停止条件即n==0或1的情况就可以了。不过稍微需要注意的是,因为n的取值可以是负数,所以当n小于0的时候,就要取倒数计算。代码如下:
class Solution {
public double myPow(double x, int n) {
if(n==0) return 1;
if(n==1) return x;
if(n<0) return 1/(x*myPow(x,Math.abs(n)-1));
return x*myPow(x,n-1);
}
}
这个方法其实也有问题,当n的数值过大时,会堆栈溢出的,看来也是不最佳解,继续往下看。
方法三:
利用分治的思路,将n个x先分成左右两组,分别求每一组的值,然后再将两组的值相乘就是总值了。即 x的n次方 等于 x的n/2次方 乘以 x的n/2次方。以此类推,左右两组其实还可以分别各自继续往下分组,就是一个递推思想了。但是这里需要考虑一下当n是奇数的情况,做一个特殊处理即可,代码如下:
class Solution {
public double myPow(double x, int n) {
//如果n是负数,则改为正数,但把x取倒数
if(n<0) {
n = -n;
x = 1/x;
}
return pow(x,n);
}
private double pow(double x, int n) {
if(n==0) return 1;
if(n==1) return x;
double half = pow(x,n/2);
//偶数个
if(n%2==0) {
return half*half;
}
//奇数个
return half*half*x;
}
}
这种方法的时间复杂度就是O(logN)了。
以上,就是对数据结构中「 递归 」的一些思考。
递归算法的三个分解步骤
递归是一个重要的算法,希望你也能学得会。
递归的三大步骤
编写递归函数的步骤,可以分解为三个。
递归第一个步骤:明确函数要做什么
对于递归,一个最重要的事情就是要明确这个函数的功能。这个函数要完成一样什么样的事情,是完全由程序员来定义的,当写一个递归函数的时候,先不要管函数里面的代码是什么,而要先明确这个函数是实现什么功能的。
比如,我定义了一个函数,这个函数是用来计算n的阶乘的。
// 计算n的阶乘(假设n不为0)
int f(int n) {
// 先不管内部实现逻辑
}
这样,就完成了第一个步骤:明确递归函数的功能。
递归第二个步骤:明确递归的结束(退出递归)条件
所谓递归,就是会在函数的内部逻辑代码中,调用这个函数本身。因此必须在函数内部明确递归的结束(退出)递归条件,否则函数会一直调用自己形成死循环。意思就是说,需要有一个条件(标识符参数)去引导递归结束,直接将结果返回。要注意的是,这个标识符参数需要是可以预见的,对于函数的执行返回结果也是可以预见的。
比如在上面的计算n的阶乘的函数中,当n=1的时候,肯定能知道f(n)对应的结果是1,因为1的阶乘就是1,那么我们就可以接着完善函数内部的逻辑代码,即将第二元素(递归结束条件)加进代码里面。

// 计算n的阶乘(假设n不为0)
int f(int n) {
if (n == 1) {
return 1;
}
}
当然了,当n=2的时候,也可以知道n的阶乘是2,那么也可以把n=2作为递归的结束条件。
// 计算n的阶乘(假设n>=2)
int f(int n) {
if (n == 2) {
return 2;
}
}
这里就可以看出,递归的结束条件并不局限,只要递归能正常结束,任何结束条件都是允许的,但是要注意一些逻辑上的细节。比如说上面的n==2的条件就需要n>2,否则当n=1的时候就会被漏掉,可能导致递归不能正常结束。完善一下就是当n<=2的时候,f(n)都会等于n。
// 计算n的阶乘(假设n不为0)
int f(int n) {
if (n <= 2) {
return n;
}
}
这样,就完成了第二步骤:明确递归的退出条件。
递归的第三个步骤:找到函数的等价关系式
递归的第三个步骤就是要不断地缩小参数的范围,缩小之后就可以通过一些辅助的变量或操作使原函数的结果不变。比如在上面的计算n的阶乘的函数中,要缩小f(n)的范围,就可以让f(n)=n* f(n-1),这样范围就从n变成了n-1,范围变小了,直到范围抵达n<=2退出递归。并且为了维持原函数不变,我们需要让f(n-1)乘上n。说白了,就是要找到一个原函数的等价关系式。在这里,f(n)的等价关系式为n*f(n-1),即f(n)=n*f(n-1)。
// 计算n的阶乘(假设n不为0)
int f(int n) {
if (n <= 2) {
return n;
}
// 把n打出来看一下,你就能明白递归的原理了
System.out.println(n);
// 加入f(n)的等价操作逻辑
return n * f(n - 1);
}
到这里f(n)的功能就基本实现了。每次写递归函数的时候,强迫自己跟着这三个步骤走,能达到事半功倍的效果。另外也可以看出,第三个步骤几乎是最难的一个步骤。
递归案例1:斐波那契数列
斐波那契数列的是这样一个数列:1、1、2、3、5、8、13、21、34、….,即第一项 f(1) = 1、第二项 f(2) = 1、…..、第 n 项目为 f(n)=f(n-1)+f(n-2),求第 n 项的值是多少。
递归第一个步骤:明确函数要做什么
假设f(n)的功能是求第n项的值,代码如下:
int f(int n) {
}
递归第二个步骤:明确递归的结束(退出递归)条件
显然,当n=1或者n=2的时候,我们可以轻易得知结果是f(1)=f(2)=1。所以递归结束的条件可以是n<=2,代码如下:
int f(int n) {
if (n <= 2) {
return 1;
}
}
递归的第三个步骤:找到函数的等价关系式
在题目中已经有等价关系式了,即f(n) = f(n-1) + f(n-2)。
int f(int n) {
// 先写递归结束条件
if (n <= 2) {
return 1;
}
// 写等价关系式
return f(n - 1) + f(n - 2);
}
这个案例非常简单。
递归案例2:小青蛙跳台阶
一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个n级的台阶总共有多少种跳法。
递归第一个步骤:明确函数要做什么
假设f(n)的功能是求青蛙跳上一个n级台阶总共有多少种跳法,代码如下:
int f(int n) {
}
递归第二个步骤:明确递归的结束(退出递归)条件
上面说了,求递归结束的条件,直接把n压缩到很小很小就行了,因为n越小我们就能越直观地算出f(n)的多少。这里,当n=1的时候,f(1)=1,因此可以将n=1作为递归结束条件。
int f(int n) {
if (n == 1) {
return 1;
}
}
递归的第三个步骤:找到函数的等价关系式
接下来找到函数的等价关系式就是这个函数的难点了,下面来分析一下。
1.假设台阶只有一级,那么显然只有一种跳法。
2.要是有两级台阶,那么就有两种跳法:一种是一次跳一级台阶,一种是一次跳两级台阶。
3.要是有三级台阶,青蛙的第一步就有两种跳法:当青蛙第一步跳了一级台阶,那么就只剩下了两级台阶,将问题转化成为两级台阶的跳法,当青蛙第一步跳了两级台阶,那么就只剩下了一级台阶,就将问题转化为了一级台阶的跳法。
4.n阶台阶与三阶台阶的分析是一样的。
我们把跳n级台阶时的跳法看成是n的函数,记为f(n)。当n=1时,f(1)=1;当n=2时,f(2)=2;当n=3时,f(3)=f(2)+f(1);当n=4时,f(4)=f(3)+f(2)......当n=n的时候,f(n)=f(n-2)+f(n-1),显然这是一个斐波那契数列。
int f(int n) {
// 先写递归结束条件
if (n == 1) {
return 1;
}
// 写等价关系式
return f(n - 1) + f(n - 2);
}
要注意的是,上面的递归结束条件显然不够严谨,因为当n=2的时候,这里的递归退出条件就不能够限制递归的正常退出了,需要稍微完善一下。
int f(int n) {
// 先写递归结束条件
if (n < 1) {
return 0;
}
if (n == 1) {
return 1;
}
if (n == 2) {
return 2;
}
// 写等价关系式
return f(n - 1) + f(n - 2);
}
因此建议在写完递归函数之后要回头去校验递归退出条件。
递归案例3:反转单链表
反转单链表是一个常见的算法。例如链表为1->2->3->4。反转后为 4->3->2->1。
链表的节点定义如下:
class Node {
int date;
Node next; // 存储下一个节点
}
递归第一个步骤:明确函数要做什么
假设函数reverseList(head)的功能是反转单链表,其中head表示链表的头节点。代码如下:
Node reverseList(Node head) {
}
递归第二个步骤:明确递归的结束(退出递归)条件
当链表只有一个节点,或者如果是空链表的话,就直接返回head就行了。
Node reverseList(Node head) {
if (head == null || head.next == null){
return head;
}
}
递归的第三个步骤:找到函数的等价关系式
// 用递归的方法反转链表
public static Node reverseList2(Node head) {
// 递归结束条件
if (head == null || head.next == null) {
return head;
}
// 递归反转子链表
Node newList = reverseList2(head.next);
// 改变1,2节点的指向
// 通过head.next获取节点2
Node t1 = head.next;
// 让2的next指向 2
t1.next = head;
// 1的next指向null
head.next = null;
// 把调整之后的链表返回
return newList;
}
递归的一些优化思路
递归的优化也是一门学问,这里列出两个优化思路。
考虑是否重复计算
递归的时候很可能会出现子运算重复计算的问题。什么是子运算?f(n-1),f(n-2)等就是子运算。
例如,在上面的案例中,等价表达式是f(n)=f(n-1)+f(n-2),递归调用的状态图如下:
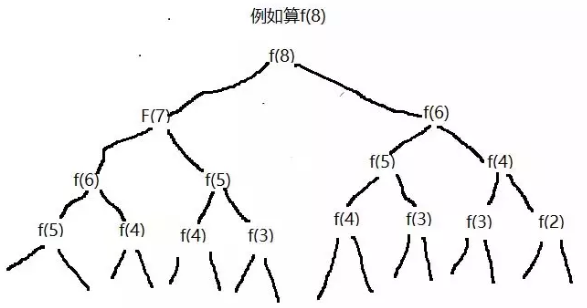
可以看出,在递归调用的时候,重复计算了两次f(5),五次f(4)等......这时非常恐怖的,因为n越大,重复计算的就越多,因此必须想办法优化。
如何优化呢,一般的做法是把计算的结果保存起来,例如把f(4)的结果保存起来,当再次要计算f(4)的时候,先判断一下之前是否计算过,计算过就可以直接取结果了。用什么保存呢,可以用数组或者HashMap保存,这里用数组保存好了。把n作为数组下标,f(n)作为值,例如arr[n]=f(n)这样子。当f(n)还没有计算过的时候,我们让arr[n]等于一个特殊值,例如arr[n]=-1。当我们要判断的时候,如果arr[n]=-1,则证明f(n)没有计算过,否则,f(n)就已经计算过了,且f(n)=arr[n]。
// 假定arr数组已经初始化好
int f(int n) {
if (n <= 1) {
return n;
}
// 先判断有没计算过
if (arr[n] != -1) {
// 计算过,直接返回
return arr[n];
} else {
// 没有计算过,递归计算,并且把结果保存到 arr数组里
arr[n] = f(n - 1) + f(n - 1);
reutrn arr[n];
}
}
也就是说,使用递归的时候,必须要考虑有没有重复计算,如果重复计算了,一定要把计算过的状态值保存起来。
考虑是否可以自底向上
对于递归,一般的思路是从上往下递归,直到递归到达最底层,再一层一层地把值返回。
这样的话,在n比较大的情况下,比如当n=10000的时候,就必须要往下递归10000层直到n<=1的时候才开始将结果逐层返回,可能会导致栈空间不够用而报出StackOverflowException的异常。
对于这种情况就可以考虑自底向上递归的做法。
int f (int n) {
if (n <= 2) {
return n;
}
int f1 = 1;
int f2 = 2;
int sum = 0;
for (int i = 3; i <= n; i++) {
sum = f1 + f2;
f1 = f2;
f2 = sum;
}
return sum;
}
另外的,这种方法也可以被称为递推。
总结
其实递归并不一定总是从上往下,也有很多从下往上的写法。比如可以从n=1开始,一直递归到n=1000,常用在一些排序组合的场景。而对于这种从下往上的写法,也是有相应的优化技巧。
最后要说的是,对于递归这种比较抽象的思想,需要自己多思考和多写才能对较好地掌握递归,可能要秃头才敢说对递归熟练吧(手动滑稽)。
递归算法讲解
原作者:书呆子Rico 《递归的内涵与经典应用》 http://my.csdn.net/justloveyou_
摘要:
大师 L. Peter Deutsch 说过:To Iterate is Human, to Recurse, Divine.中文译为:人理解迭代,神理解递归。毋庸置疑地,递归确实是一个奇妙的思维方式。对一些简单的递归问题,我们总是惊叹于递归描述问题的能力和编写代码的简洁,但要想真正领悟递归的精髓、灵活地运用递归思想来解决问题却并不是一件容易的事情。本文剖析了递归的思想内涵,分析了递归与循环的联系与区别,给出了递归的应用场景和一些典型应用,并利用递归和非递归的方式解决了包括阶乘、斐波那契数列、汉诺塔、杨辉三角的存取、字符串回文判断、字符串全排列、二分查找、树的深度求解在内的八个经典问题。
版权声明:
本文原创作者:书呆子Rico
作者博客地址:http://blog.csdn.net/justloveyou_/
友情提示:
若读者需要本博文相关完整代码,请移步我的Github自行获取,项目名为 SwordtoOffer,链接地址为:https://github.com/githubofrico/SwordtoOffer。
一. 引子
大师 L. Peter Deutsch 说过:To Iterate is Human, to Recurse, Divine.中文译为:人理解迭代,神理解递归。毋庸置疑地,递归确实是一个奇妙的思维方式。对一些简单的递归问题,我们总是惊叹于递归描述问题的能力和编写代码的简洁,但要想真正领悟递归的精髓、灵活地运用递归思想来解决问题却并不是一件容易的事情。在正式介绍递归之前,我们首先引用知乎用户李继刚(https://www.zhihu.com/question/20507130/answer/15551917)对递归和循环的生动解释:
递归:你打开面前这扇门,看到屋里面还有一扇门。你走过去,发现手中的钥匙还可以打开它,你推开门,发现里面还有一扇门,你继续打开它。若干次之后,你打开面前的门后,发现只有一间屋子,没有门了。然后,你开始原路返回,每走回一间屋子,你数一次,走到入口的时候,你可以回答出你到底用这你把钥匙打开了几扇门。
循环:你打开面前这扇门,看到屋里面还有一扇门。你走过去,发现手中的钥匙还可以打开它,你推开门,发现里面还有一扇门(若前面两扇门都一样,那么这扇门和前两扇门也一样;如果第二扇门比第一扇门小,那么这扇门也比第二扇门小,你继续打开这扇门,一直这样继续下去直到打开所有的门。但是,入口处的人始终等不到你回去告诉他答案。
上面的比喻形象地阐述了递归与循环的内涵,那么我们来思考以下几个问题:
什么是递归呢?
递归的精髓(思想)是什么?
递归和循环的区别是什么?
什么时候该用递归?
使用递归需要注意哪些问题?
递归思想解决了哪些经典的问题?
这些问题正是笔者准备在本文中详细阐述的问题。
二. 递归的内涵
1、定义 (什么是递归?)
在数学与计算机科学中,递归(Recursion)是指在函数的定义中使用函数自身的方法。实际上,递归,顾名思义,其包含了两个意思:递 和 归,这正是递归思想的精华所在。
2、递归思想的内涵(递归的精髓是什么?)
正如上面所描述的场景,递归就是有去(递去)有回(归来),如下图所示。“有去”是指:递归问题必须可以分解为若干个规模较小,与原问题形式相同的子问题,这些子问题可以用相同的解题思路来解决,就像上面例子中的钥匙可以打开后面所有门上的锁一样;“有回”是指 : 这些问题的演化过程是一个从大到小,由近及远的过程,并且会有一个明确的终点(临界点),一旦到达了这个临界点,就不用再往更小、更远的地方走下去。最后,从这个临界点开始,原路返回到原点,原问题解决。
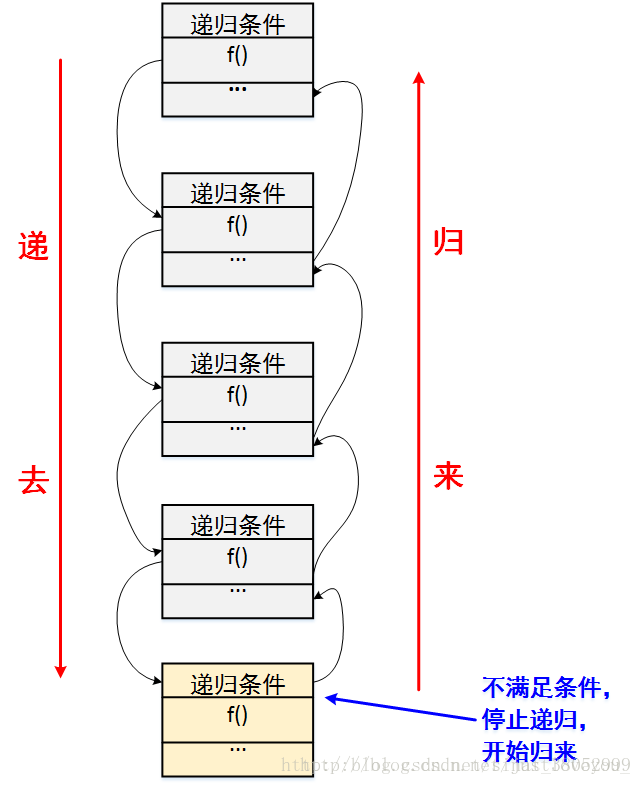
更直接地说,递归的基本思想就是把规模大的问题转化为规模小的相似的子问题来解决。特别地,在函数实现时,因为解决大问题的方法和解决小问题的方法往往是同一个方法,所以就产生了函数调用它自身的情况,这也正是递归的定义所在。格外重要的是,这个解决问题的函数必须有明确的结束条件,否则就会导致无限递归的情况。
3、用归纳法来理解递归
数学都不差的我们,第一反应就是递归在数学上的模型是什么,毕竟我们对于问题进行数学建模比起代码建模拿手多了。观察递归,我们会发现,递归的数学模型其实就是 数学归纳法,这个在高中的数列里面是最常用的了,下面回忆一下数学归纳法。
数学归纳法适用于将解决的原问题转化为解决它的子问题,而它的子问题又变成子问题的子问题,而且我们发现这些问题其实都是一个模型,也就是说存在相同的逻辑归纳处理项。当然有一个是例外的,也就是归纳结束的那一个处理方法不适用于我们的归纳处理项,当然也不能适用,否则我们就无穷归纳了。总的来说,归纳法主要包含以下三个关键要素:
步进表达式:问题蜕变成子问题的表达式
结束条件:什么时候可以不再使用步进表达式
直接求解表达式:在结束条件下能够直接计算返回值的表达式
事实上,这也正是某些数学中的数列问题在利用编程的方式去解决时可以使用递归的原因,比如著名的斐波那契数列问题。
4、递归的三要素
在我们了解了递归的基本思想及其数学模型之后,我们如何才能写出一个漂亮的递归程序呢?笔者认为主要是把握好如下三个方面:
1、明确递归终止条件;
2、给出递归终止时的处理办法;
3、提取重复的逻辑,缩小问题规模。- 1
- 2
- 3
- 4
- 5
1). 明确递归终止条件
我们知道,递归就是有去有回,既然这样,那么必然应该有一个明确的临界点,程序一旦到达了这个临界点,就不用继续往下递去而是开始实实在在的归来。换句话说,该临界点就是一种简单情境,可以防止无限递归。
2). 给出递归终止时的处理办法
我们刚刚说到,在递归的临界点存在一种简单情境,在这种简单情境下,我们应该直接给出问题的解决方案。一般地,在这种情境下,问题的解决方案是直观的、容易的。
3). 提取重复的逻辑,缩小问题规模*
我们在阐述递归思想内涵时谈到,递归问题必须可以分解为若干个规模较小、与原问题形式相同的子问题,这些子问题可以用相同的解题思路来解决。从程序实现的角度而言,我们需要抽象出一个干净利落的重复的逻辑,以便使用相同的方式解决子问题。
5、递归算法的编程模型
在我们明确递归算法设计三要素后,接下来就需要着手开始编写具体的算法了。在编写算法时,不失一般性,我们给出两种典型的递归算法设计模型,如下所示。
模型一: 在递去的过程中解决问题
function recursion(大规模){
if (end_condition){ // 明确的递归终止条件
end; // 简单情景
}else{ // 在将问题转换为子问题的每一步,解决该步中剩余部分的问题
solve; // 递去
recursion(小规模); // 递到最深处后,不断地归来
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
模型二: 在归来的过程中解决问题
function recursion(大规模){
if (end_condition){ // 明确的递归终止条件
end; // 简单情景
}else{ // 先将问题全部描述展开,再由尽头“返回”依次解决每步中剩余部分的问题
recursion(小规模); // 递去
solve; // 归来
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6、递归的应用场景
在我们实际学习工作中,递归算法一般用于解决三类问题:
(1). 问题的定义是按递归定义的(Fibonacci函数,阶乘,…);
(2). 问题的解法是递归的(有些问题只能使用递归方法来解决,例如,汉诺塔问题,…);
(3). 数据结构是递归的(链表、树等的操作,包括树的遍历,树的深度,…)。
在下文我们将给出递归算法的一些经典应用案例,这些案例基本都属于第三种类型问题的范畴。
三. 递归与循环
递归与循环是两种不同的解决问题的典型思路。递归通常很直白地描述了一个问题的求解过程,因此也是最容易被想到解决方式。循环其实和递归具有相同的特性,即做重复任务,但有时使用循环的算法并不会那么清晰地描述解决问题步骤。单从算法设计上看,递归和循环并无优劣之别。然而,在实际开发中,因为函数调用的开销,递归常常会带来性能问题,特别是在求解规模不确定的情况下;而循环因为没有函数调用开销,所以效率会比递归高。递归求解方式和循环求解方式往往可以互换,也就是说,如果用到递归的地方可以很方便使用循环替换,而不影响程序的阅读,那么替换成循环往往是好的。问题的递归实现转换成非递归实现一般需要两步工作:
(1). 自己建立“堆栈(一些局部变量)”来保存这些内容以便代替系统栈,比如树的三种非递归遍历方式;
(2). 把对递归的调用转变为对循环处理。
特别地,在下文中我们将给出递归算法的一些经典应用案例,对于这些案例的实现,我们一般会给出递归和非递归两种解决方案,以便读者体会。
四. 经典递归问题实战
- 第一类问题:问题的定义是按递归定义的
(1). 阶乘
/**
* Title: 阶乘的实现
* Description:
* 递归解法
* 非递归解法
* @author rico
*/
public class Factorial {
/**
* @description 阶乘的递归实现
* @author rico
* @created 2017年5月10日 下午8:45:48
* @param n
* @return
*/
public static long f(int n){
if(n == 1) // 递归终止条件
return 1; // 简单情景
return n*f(n-1); // 相同重复逻辑,缩小问题的规模
}
--------------------------------我是分割线-------------------------------------
/**
* @description 阶乘的非递归实现
* @author rico
* @created 2017年5月10日 下午8:46:43
* @param n
* @return
*/
public static long f_loop(int n) {
long result = n;
while (n > 1) {
n--;
result = result * n;
}
return result;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
(2). 斐波纳契数列
/**
* Title: 斐波纳契数列
*
* Description: 斐波纳契数列,又称黄金分割数列,指的是这样一个数列:1、1、2、3、5、8、13、21、……
* 在数学上,斐波纳契数列以如下被以递归的方法定义:F0=0,F1=1,Fn=F(n-1)+F(n-2)(n>=2,n∈N*)。
*
* 两种递归解法:经典解法和优化解法
* 两种非递归解法:递推法和数组法
*
* @author rico
*/
public class FibonacciSequence {
/**
* @description 经典递归法求解
*
* 斐波那契数列如下:
*
* 1,1,2,3,5,8,13,21,34,...
*
* *那么,计算fib(5)时,需要计算1次fib(4),2次fib(3),3次fib(2),调用了2次fib(1)*,即:
*
* fib(5) = fib(4) + fib(3)
*
* fib(4) = fib(3) + fib(2) ;fib(3) = fib(2) + fib(1)
*
* fib(3) = fib(2) + fib(1)
*
* 这里面包含了许多重复计算,而实际上我们只需计算fib(4)、fib(3)、fib(2)和fib(1)各一次即可,
* 后面的optimizeFibonacci函数进行了优化,使时间复杂度降到了O(n).
*
* @author rico
* @created 2017年5月10日 下午12:00:42
* @param n
* @return
*/
public static int fibonacci(int n) {
if (n == 1 || n == 2) { // 递归终止条件
return 1; // 简单情景
}
return fibonacci(n - 1) + fibonacci(n - 2); // 相同重复逻辑,缩小问题的规模
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
——————————–我是分割线————————————-
/**
* @description 对经典递归法的优化
*
* 斐波那契数列如下:
*
* 1,1,2,3,5,8,13,21,34,...
*
* 那么,我们可以这样看:fib(1,1,5) = fib(1,2,4) = fib(2,3,3) = 5
*
* 也就是说,以1,1开头的斐波那契数列的第五项正是以1,2开头的斐波那契数列的第四项,
* 而以1,2开头的斐波那契数列的第四项也正是以2,3开头的斐波那契数列的第三项,
* 更直接地,我们就可以一步到位:fib(2,3,3) = 2 + 3 = 5,计算结束。
*
* 注意,前两个参数是数列的开头两项,第三个参数是我们想求的以前两个参数开头的数列的第几项。
*
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
* 时间复杂度:O(n)
*
* @author rico
* @param first 数列的第一项
* @param second 数列的第二项
* @param n 目标项
* @return
*/
public static int optimizeFibonacci(int first, int second, int n) {
if (n > 0) {
if(n == 1){ // 递归终止条件
return first; // 简单情景
}else if(n == 2){ // 递归终止条件
return second; // 简单情景
}else if (n == 3) { // 递归终止条件
return first + second; // 简单情景
}
return optimizeFibonacci(second, first + second, n - 1); // 相同重复逻辑,缩小问题规模
}
return -1;
}
--------------------------------我是分割线-------------------------------------
/**
* @description 非递归解法:有去无回
* @author rico
* @created 2017年5月10日 下午12:03:04
* @param n
* @return
*/
public static int fibonacci_loop(int n) {
if (n == 1 || n == 2) {
return 1;
}
int result = -1;
int first = 1; // 自己维护的"栈",以便状态回溯
int second = 1; // 自己维护的"栈",以便状态回溯
for (int i = 3; i <= n; i++) { // 循环
result = first + second;
first = second;
second = result;
}
return result;
}
--------------------------------我是分割线-------------------------------------
/**
* @description 使用数组存储斐波那契数列
* @author rico
* @param n
* @return
*/
public static int fibonacci_array(int n) {
if (n > 0) {
int[] arr = new int[n]; // 使用临时数组存储斐波纳契数列
arr[0] = arr[1] = 1;
for (int i = 2; i < n; i++) { // 为临时数组赋值
arr[i] = arr[i-1] + arr[i-2];
}
return arr[n - 1];
}
return -1;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
(3). 杨辉三角的取值
/**
* @description 递归获取杨辉三角指定行、列(从0开始)的值
* 注意:与是否创建杨辉三角无关
- 1
- 2
- 3
* @author rico
* @x 指定行
* @y 指定列
*/
/**
* Title: 杨辉三角形又称Pascal三角形,它的第i+1行是(a+b)i的展开式的系数。
* 它的一个重要性质是:三角形中的每个数字等于它两肩上的数字相加。
*
* 例如,下面给出了杨辉三角形的前4行:
* 1
* 1 1
* 1 2 1
* 1 3 3 1
* @description 递归获取杨辉三角指定行、列(从0开始)的值
* 注意:与是否创建杨辉三角无关
* @author rico
* @x 指定行
* @y 指定列
*/
public static int getValue(int x, int y) {
if(y <= x && y >= 0){
if(y == 0 || x == y){ // 递归终止条件
return 1;
}else{
// 递归调用,缩小问题的规模
return getValue(x-1, y-1) + getValue(x-1, y);
}
}
return -1;
}
}
题目
按要求输入如下格式的杨辉三角
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
输入
输入只包括一个整数n,表示将要输出的杨辉三角的层数。
输出
对应于该输入,请输出相应层数的杨辉三角,每一层的整数之间用一个空格隔开。
样例输入
5样例输出
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
public class YangHui { //杨辉三角 public static int YangHui(int i,int j){ //判断参数合法性 if (j<=i&&i>=0&&j>=0){ //递归终止条件 if (j==0||i==j){ //满足递归终止条件的解决办法 return 1; } //提取重复逻辑,递归调用 return YangHui(i-1,j-1)+YangHui(i-1,j); //arr[i][j]=arr[i-1][j-1]+arr[i-1][j]; } return -1; } public static void main(String[] args) { for(int i=0;i<=5;i++){ for(int j=0;j<=i;j++){ System.out.print(YangHui(i,j)+" "); } System.out.println(); } } }
输出:
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
/**
* Title: 回文字符串的判断
* Description: 回文字符串就是正读倒读都一样的字符串。如”98789”, “abccba”都是回文字符串
*
* 两种解法:
* 递归判断;
* 循环判断;
*
* @author rico
*/
public class PalindromeString {
/**
* @description 递归判断一个字符串是否是回文字符串
* @author rico
* @created 2017年5月10日 下午5:45:50
* @param s
* @return
*/
public static boolean isPalindromeString_recursive(String s){
int start = 0;
int end = s.length()-1;
if(end > start){ // 递归终止条件:两个指针相向移动,当start超过end时,完成判断
if(s.charAt(start) != s.charAt(end)){
return false;
}else{
// 递归调用,缩小问题的规模
return isPalindromeString_recursive(s.substring(start+1).substring(0, end-1));
}
}
return true;
}
--------------------------------我是分割线-------------------------------------
/**
* @description 循环判断回文字符串
* @author rico
* @param s
* @return
*/
public static boolean isPalindromeString_loop(String s){
char[] str = s.toCharArray();
int start = 0;
int end = str.length-1;
while(end > start){ // 循环终止条件:两个指针相向移动,当start超过end时,完成判断
if(str[end] != str[start]){
return false;
}else{
end --;
start ++;
}
}
return true;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
(5). 字符串全排列
递归解法
/**
* @description 从字符串数组中每次选取一个元素,作为结果中的第一个元素;然后,对剩余的元素全排列
* @author rico
* @param s
* 字符数组
* @param from
* 起始下标
* @param to
* 终止下标
*/
public static void getStringPermutations3(char[] s, int from, int to) {
if (s != null && to >= from && to < s.length && from >= 0) { // 边界条件检查
if (from == to) { // 递归终止条件
System.out.println(s); // 打印结果
} else {
for (int i = from; i <= to; i++) {
swap(s, i, from); // 交换前缀,作为结果中的第一个元素,然后对剩余的元素全排列
getStringPermutations3(s, from + 1, to); // 递归调用,缩小问题的规模
swap(s, from, i); // 换回前缀,复原字符数组
}
}
}
}
/**
* @description 对字符数组中的制定字符进行交换
* @author rico
* @param s
* @param from
* @param to
*/
public static void swap(char[] s, int from, int to) {
char temp = s[from];
s[from] = s[to];
s[to] = temp;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
非递归解法(字典序全排列)
/**
* Title: 字符串全排列非递归算法(字典序全排列)
* Description: 字典序全排列,其基本思想是:
* 先对需要求排列的字符串进行字典排序,即得到全排列中最小的排列.
* 然后,找到一个比它大的最小的全排列,一直重复这一步直到找到最大值,即字典排序的逆序列.
*
* 不需要关心字符串长度
*
* @author rico
*/
public class StringPermutationsLoop {
/**
* @description 字典序全排列
*
* 设一个字符串(字符数组)的全排列有n个,分别是A1,A2,A3,...,An
*
* 1. 找到最小的排列 Ai
* 2. 找到一个比Ai大的最小的后继排列Ai+1
* 3. 重复上一步直到没有这样的后继
*
* 重点就是如何找到一个排列的直接后继:
* 对于字符串(字符数组)a0a1a2……an,
* 1. 从an到a0寻找第一次出现的升序排列的两个字符(即ai < ai+1),那么ai+1是一个极值,因为ai+1之后的字符为降序排列,记 top=i+1;
* 2. 从top处(包括top)开始查找比ai大的最小的值aj,记 minMax = j;
* 3. 交换minMax处和top-1处的字符;
* 4. 翻转top之后的字符(包括top),即得到一个排列的直接后继排列
*
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
* @author rico
* @param s
* 字符数组
* @param from
* 起始下标
* @param to
* 终止下标
*/
public static void getStringPermutations4(char[] s, int from, int to) {
Arrays.sort(s,from,to+1); // 对字符数组的所有元素进行升序排列,即得到最小排列
System.out.println(s);
char[] descendArr = getMaxPermutation(s, from, to); // 得到最大排列,即最小排列的逆序列
while (!Arrays.equals(s, descendArr)) { // 循环终止条件:迭代至最大排列
if (s != null && to >= from && to < s.length && from >= 0) { // 边界条件检查
int top = getExtremum(s, from, to); // 找到序列的极值
int minMax = getMinMax(s, top, to); // 从top处(包括top)查找比s[top-1]大的最小值所在的位置
swap(s, top - 1, minMax); // 交换minMax处和top-1处的字符
s = reverse(s, top, to); // 翻转top之后的字符
System.out.println(s);
}
}
}
/**
* @description 对字符数组中的制定字符进行交换
* @author rico
* @param s
* @param from
* @param to
*/
public static void swap(char[] s, int from, int to) {
char temp = s[from];
s[from] = s[to];
s[to] = temp;
}
/**
* @description 获取序列的极值
* @author rico
* @param s 序列
* @param from 起始下标
* @param to 终止下标
* @return
*/
public static int getExtremum(char[] s, int from, int to) {
int index = 0;
for (int i = to; i > from; i--) {
if (s[i] > s[i - 1]) {
index = i;
break;
}
}
return index;
}
/**
* @description 从top处查找比s[top-1]大的最小值所在的位置
* @author rico
* @created 2017年5月10日 上午9:21:13
* @param s
* @param top 极大值所在位置
* @param to
* @return
*/
public static int getMinMax(char[] s, int top, int to) {
int index = top;
char base = s[top-1];
char temp = s[top];
for (int i = top + 1; i <= to; i++) {
if (s[i] > base && s[i] < temp) {
temp = s[i];
index = i;
}
continue;
}
return index;
}
/**
* @description 翻转top(包括top)后的序列
* @author rico
* @param s
* @param from
* @param to
* @return
*/
public static char[] reverse(char[] s, int top, int to) {
char temp;
while(top < to){
temp = s[top];
s[top] = s[to];
s[to] = temp;
top ++;
to --;
}
return s;
}
/**
* @description 根据最小排列得到最大排列
* @author rico
* @param s 最小排列
* @param from 起始下标
* @param to 终止下标
* @return
*/
public static char[] getMaxPermutation(char[] s, int from, int to) {
//将最小排列复制到一个新的数组中
char[] dsc = Arrays.copyOfRange(s, 0, s.length);
int first = from;
int end = to;
while(end > first){ // 循环终止条件
char temp = dsc[first];
dsc[first] = dsc[end];
dsc[end] = temp;
first ++;
end --;
}
return dsc;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
(6). 二分查找
/**
* @description 二分查找的递归实现
* @author rico
* @param array 目标数组
* @param low 左边界
* @param high 右边界
* @param target 目标值
* @return 目标值所在位置
*/
public static int binarySearch(int[] array, int low, int high, int target) {
//递归终止条件
if(low <= high){
int mid = (low + high) >> 1;
if(array[mid] == target){
return mid + 1; // 返回目标值的位置,从1开始
}else if(array[mid] > target){
// 由于array[mid]不是目标值,因此再次递归搜索时,可以将其排除
return binarySearch(array, low, mid-1, target);
}else{
// 由于array[mid]不是目标值,因此再次递归搜索时,可以将其排除
return binarySearch(array, mid+1, high, target);
}
}
return -1; //表示没有搜索到
}
--------------------------------我是分割线-------------------------------------
/**
* @description 二分查找的非递归实现
* @author rico
* @param array 目标数组
* @param low 左边界
* @param high 右边界
* @param target 目标值
* @return 目标值所在位置
*/
public static int binarySearchNoRecursive(int[] array, int low, int high, int target) {
// 循环
while (low <= high) {
int mid = (low + high) >> 1;
if (array[mid] == target) {
return mid + 1; // 返回目标值的位置,从1开始
} else if (array[mid] > target) {
// 由于array[mid]不是目标值,因此再次递归搜索时,可以将其排除
high = mid -1;
} else {
// 由于array[mid]不是目标值,因此再次递归搜索时,可以将其排除
low = mid + 1;
}
}
return -1; //表示没有搜索到
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 第二类问题:问题解法按递归算法实现
(1). 汉诺塔问题
/**
* Title: 汉诺塔问题
* Description:古代有一个梵塔,塔内有三个座A、B、C,A座上有64个盘子,盘子大小不等,大的在下,小的在上。
* 有一个和尚想把这64个盘子从A座移到C座,但每次只能允许移动一个盘子,并且在移动过程中,3个座上的盘子始终保持大盘在下,
* 小盘在上。在移动过程中可以利用B座。要求输入层数,运算后输出每步是如何移动的。
*
* @author rico
*/
public class HanoiTower {
/**
* @description 在程序中,我们把最上面的盘子称为第一个盘子,把最下面的盘子称为第N个盘子
* @author rico
* @param level:盘子的个数
* @param from 盘子的初始地址
* @param inter 转移盘子时用于中转
* @param to 盘子的目的地址
*/
public static void moveDish(int level, char from, char inter, char to) {
if (level == 1) { // 递归终止条件
System.out.println("从" + from + " 移动盘子" + level + " 号到" + to);
} else {
// 递归调用:将level-1个盘子从from移到inter(不是一次性移动,每次只能移动一个盘子,其中to用于周转)
moveDish(level - 1, from, to, inter); // 递归调用,缩小问题的规模
// 将第level个盘子从A座移到C座
System.out.println("从" + from + " 移动盘子" + level + " 号到" + to);
// 递归调用:将level-1个盘子从inter移到to,from 用于周转
moveDish(level - 1, inter, from, to); // 递归调用,缩小问题的规模
}
}
public static void main(String[] args) {
int nDisks = 30;
moveDish(nDisks, 'A', 'B', 'C');
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 第三类问题:数据的结构是按递归定义的
(1). 二叉树深度
/**
* Title: 递归求解二叉树的深度
* Description:
* @author rico
* @created 2017年5月8日 下午6:34:50
*/
public class BinaryTreeDepth {
/**
* @description 返回二叉数的深度
* @author rico
* @param t
* @return
*/
public static int getTreeDepth(Tree t) {
// 树为空
if (t == null) // 递归终止条件
return 0;
int left = getTreeDepth(t.left); // 递归求左子树深度,缩小问题的规模
int right = getTreeDepth(t.left); // 递归求右子树深度,缩小问题的规模
return left > right ? left + 1 : right + 1;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(2). 二叉树深度
/**
* @description 前序遍历(递归)
* @author rico
* @created 2017年5月22日 下午3:06:11
* @param root
* @return
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
public String preOrder(Node<E> root) {
StringBuilder sb = new StringBuilder(); // 存到递归调用栈
if (root == null) { // 递归终止条件
return ""; // ji
}else { // 递归终止条件
sb.append(root.data + " "); // 前序遍历当前结点
sb.append(preOrder(root.left)); // 前序遍历左子树
sb.append(preOrder(root.right)); // 前序遍历右子树
return sb.toString();
}
}
什么是递归,通过这篇文章,让你彻底搞懂递归
啥叫递归
tips:文章有点长,可以慢慢看,如果来不及看,也可以先收藏以后有时间在看。
聊递归之前先看一下什么叫递归。
递归,就是在运行的过程中调用自己。
构成递归需具备的条件:
1. 子问题须与原始问题为同样的事,且更为简单;
2. 不能无限制地调用本身,须有个出口,化简为非递归状况处理。
递归语言例子
我们用2个故事来阐述一下什么叫递归。
1,从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?“从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?‘从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事呢!故事是什么呢?……’”
2,大雄在房里,用时光电视看着从前的情况。电视画面中的那个时候,他正在房里,用时光电视,看着从前的情况。电视画面中的电视画面的那个时候,他正在房里,用时光电视,看着从前的情况……
递归模板
我们知道递归必须具备两个条件,一个是调用自己,一个是有终止条件。这两个条件必须同时具备,且一个都不能少。并且终止条件必须是在递归最开始的地方,也就是下面这样
public void recursion(参数0) {if (终止条件) {return;}recursion(参数1);}
不能把终止条件写在递归结束的位置,下面这种写法是错误的
public void recursion(参数0) {recursion(参数1);if (终止条件) {return;}}
如果这样的话,递归永远退不出来了,就会出现堆栈溢出异常(StackOverflowError)。
但实际上递归可能调用自己不止一次,并且很多递归在调用之前或调用之后都会有一些逻辑上的处理,比如下面这样。
public void recursion(参数0) {if (终止条件) {return;}可能有一些逻辑运算recursion(参数1)可能有一些逻辑运算recursion(参数2)……recursion(参数n)可能有一些逻辑运算}
实例分析
我对递归的理解是先往下一层层传递,当碰到终止条件的时候会反弹,最终会反弹到调用处。下面我们就以5个最常见的示例来分析下
1,阶乘
我们先来看一个最简单的递归调用-阶乘,代码如下
1public int recursion(int n) {
2 if (n == 1)
3 return 1;
4 return n * recursion(n - 1);
5}
这个递归在熟悉不过了,第2-3行是终止条件,第4行是调用自己。我们就用n等于5的时候来画个图看一下递归究竟是怎么调用的
如果看不清,图片可点击放大。
这种递归还是很简单的,我们求f(5)的时候,只需要求出f(4)即可,如果求f(4)我们要求出f(3)……,一层一层的调用,当n=1的时候,我们直接返回1,然后再一层一层的返回,直到返回f(5)为止。
递归的目的是把一个大的问题细分为更小的子问题,我们只需要知道递归函数的功能即可,不要把递归一层一层的拆开来想,如果同时调用多次的话这样你很可能会陷入循环而出不来。比如上面的题中要求f(5),我们只需要计算f(4)即可,即f(5)=5*f(4);至于f(4)是怎么计算的,我们就不要管了。因为我们知道f(n)中的n可以代表任何正整数,我们只需要传入4就可以计算f(4)。
2,斐波那契数列
我们再来看另一道经典的递归题,就是斐波那契数列,数列的前几项如下所示
[1,1,2,3,5,8,13……]
我们参照递归的模板来写下,首先终止条件是当n等于1或者2的时候返回1,也就是数列的前两个值是1,代码如下
1public int fibonacci(int n) {
2 if (n == 1 || n == 2)
3 return 1;
4 这里是递归调用;
5}
递归的两个条件,一个是终止条件,我们找到了。还一个是调用自己,我们知道斐波那契数列当前的值是前两个值的和,也就是
fibonacci(n) =fibonacci(n - 1) + fibonacci(n - 2)
所以代码很容易就写出来了
1//1,1,2,3,5,8,13……
2public int fibonacci(int n) {
3 if (n == 1 || n == 2)
4 return 1;
5 return fibonacci(n - 1) + fibonacci(n - 2);
6}
3,汉诺塔
通过前面两个示例的分析,我们对递归有一个大概的了解,下面我们再来看另一个示例-汉诺塔,这个其实前面讲过,有兴趣的可以看下362,汉诺塔
汉诺塔的原理这里再简单提一下,就是有3根柱子A,B,C。A柱子上由上至下依次由小至大排列的圆盘。把A柱子上的圆盘借B柱子全部移动到C柱子上,并且移动的过程始终是小的圆盘在上,大的在下。我们还是用递归的方式来解这道题,先来定义一个函数
public void hanoi(int n, char A, char B, char C)
他表示的是把n个圆盘从A借助B成功的移动到C。
我们先来回顾一下递归的条件,一个是终止条件,一个是调用自己。我们先来看下递归的终止条件就是当n等于1的时候,也就是A柱子上只有一个圆盘的时候,我们直接把A柱子上的圆盘移动到C柱子上即可。
1//表示的是把n个圆盘借助柱子B成功的从A移动到C
2public static void hanoi(int n, char A, char B, char C) {
3 if (n == 1) {
4 //如果只有一个,直接从A移动到C即可
5 System.out.println("从" + A + "移动到" + C);
6 return;
7 }
8 这里是递归调用
9}
再来看一下递归调用,如果n不等于1,我们要分3步,
1,先把n-1个圆盘从A借助C成功的移动到B
2,然后再把第n个圆盘从A移动到C
3,最后再把n-1个圆盘从B借助A成功的移动到C。
那代码该怎么写呢,我们知道函数
hanoi(n, 'A', 'B', 'C')表示的是把n个圆盘从A借助B成功的移动到C
所以hanoi(n-1, 'A', 'C', 'B')就表示的是把n-1个圆盘从A借助C成功的移动到B
hanoi(n-1, 'B', 'A', 'C')就表示的是把n-1个圆盘从B借助A成功的移动到C
所以上面3步如果用代码就可以这样来表示
1,hanoi(n-1, 'A', 'C', 'B')
2,System.out.println("从" + A + "移动到" + C);
3,hanoi(n-1, 'B', 'A', 'C')
所以最终完整代码如下
1//表示的是把n个圆盘借助柱子B成功的从A移动到C
2public static void hanoi(int n, char A, char B, char C) {
3 if (n == 1) {
4 //如果只有一个,直接从A移动到C即可
5 System.out.println("从" + A + "移动到" + C);
6 return;
7 }
8 //表示先把n-1个圆盘成功从A移动到B
9 hanoi(n - 1, A, C, B);
10 //把第n个圆盘从A移动到C
11 System.out.println("从" + A + "移动到" + C);
12 //表示把n-1个圆盘再成功从B移动到C
13 hanoi(n - 1, B, A, C);
14}
通过上面的分析,是不是感觉递归很简单。所以我们写递归的时候完全可以套用上面的模板,先写出终止条件,然后在写递归的逻辑调用。还有一点非常重要,就是一定要明白递归函数中每个参数的含义,这样在逻辑处理和函数调用的时候才能得心应手,函数的调用我们一定不要去一步步拆开去想,这样很有可能你会奔溃的。
4,二叉树的遍历
再来看最后一个常见的示例就是二叉树的遍历,在前面也讲过,如果有兴趣的话可以看下373,数据结构-6,树,我们主要来看一下二叉树的前中后3种遍历方式,
1,先看一下前序遍历(根节点最开始),他的顺序是
根节点→左子树→右子树
我们来套用模板看一下
1public void preOrder(TreeNode node) {
2 if (终止条件)// (必须要有)
3 return;
4 逻辑处理//(不是必须的)
5 递归调用//(必须要有)
6}
终止条件是node等于空,逻辑处理这块直接打印当前节点的值即可,递归调用是先打印左子树在打印右子树,我们来看下
1public static void preOrder(TreeNode node) {
2 if (node == null)
3 return;
4 System.out.printf(node.val + "");
5 preOrder(node.left);
6 preOrder(node.right);
7}
中序遍历和后续遍历直接看下
2,中序遍历(根节点在中间)
左子树→根节点→右子树
1public static void inOrder(TreeNode node) {
2 if (node == null)
3 return;
4 inOrder(node.left);
5 System.out.println(node.val);
6 inOrder(node.right);
7}
3,后序遍历(根节点在最后)
左子树→右子树→根节点
1public static void postOrder(TreeNode tree) {
2 if (tree == null)
3 return;
4 postOrder(tree.left);
5 postOrder(tree.right);
6 System.out.println(tree.val);
7}
5,链表的逆序打印
这个就不在说了,直接看下
1public void printRevers(ListNode root) {
2 //(终止条件)
3 if (root == null)
4 return;
5 //(递归调用)先打印下一个
6 printRevers(root.next);
7 //(逻辑处理)把后面的都打印完了在打印当前节点
8 System.out.println(root.val);
9}
分支污染问题
通过上面的分析,我们对递归有了更深一层的认识。但总觉得还少了点什么,其实递归我们还可以通过另一种方式来认识他,就是n叉树。在递归中如果只调用自己一次,我们可以把它想象为是一棵一叉树(这是我自己想的,我们可以认为只有一个子节点的树),如果调用自己2次,我们可以把它想象为一棵二叉树,如果调用自己n次,我们可以把它想象为一棵n叉树……。就像下面这样,当到达叶子节点的时候开始往回反弹。
递归的时候如果处理不当可能会出现分支污染导致结果错误。为什么会出现这种情况,我先来解释一下,因为除了基本类型是值传递以外,其他类型基本上很多都是引用传递。看一下上面的图,比如我开始调用的时候传入一个list对象,在调用第一个分支之后list中的数据修改了,那么后面的所有分支都能感知到,实际上也就是对后面的分支造成了污染。
我们先来看一个例子吧
给定一个数组nums=[2,3,5]和一个固定的值target=8。找出数组sums中所有可以使数字和为target的组合。先来画个图看一下
图中红色的表示的是选择成功的组合,这里只画了选择2的分支,由于图太大,所以选择3和选择5的分支没画。在仔细一看这不就是一棵3叉树吗,OK,我们来使用递归的方式,先来看一下函数的定义
1private void combinationSum(List<Integer> cur, int sums[], int target) {
2
3}
在把递归的模板拿出来
1private void combinationSum(List<Integer> cur, int sums[], int target) {
2 if (终止条件) {
3 return;
4 }
5 //逻辑处理
6
7 //因为是3叉树,所以这里要调用3次
8 //递归调用
9 //递归调用
10 //递归调用
11
12 //逻辑处理
13}
这种解法灵活性不是很高,如果nums的长度是3,我们3次递归调用,如果nums的长度是n,那么我们就要n次调用……。所以我们可以直接写成for循环的形式,也就是下面这样
1private void combinationSum(List<Integer> cur, int sums[], int target) {
2 //终止条件必须要有
3 if (终止条件) {
4 return;
5 }
6 //逻辑处理(可有可无,是情况而定)
7 for (int i = 0; i < sums.length; i++) {
8 //逻辑处理(可有可无,是情况而定)
9 //递归调用(递归调用必须要有)
10 //逻辑处理(可有可无,是情况而定)
11 }
12 //逻辑处理(可有可无,是情况而定)
13}
下面我们再来一步一步看
1,终止条件是什么?
当target等于0的时候,说明我们找到了一组组合,我们就把他打印出来,所以终止条件很容易写,代码如下
1 if (target == 0) {
2 System.out.println(Arrays.toString(cur.toArray()));
3 return;
4 }
2,逻辑处理和递归调用
我们一个个往下选的时候如果要选的值比target大,我们就不要选了,如果不比target大,就把他加入到list中,表示我们选了他,如果选了他之后在递归调用的时候target值就要减去选择的值,代码如下
1 //逻辑处理
2 //如果当前值大于target我们就不要选了
3 if (target < sums[i])
4 continue;
5 //否则我们就把他加入到集合中
6 cur.add(sums[i]);
7 //递归调用
8 combinationSum(cur, sums, target - sums[i]);
终止条件和递归调用都已经写出来了,感觉代码是不是很简单,我们再来把它组合起来看下完整代码
1private void combinationSum(List<Integer> cur, int sums[], int target) {
2 //终止条件必须要有
3 if (target == 0) {
4 System.out.println(Arrays.toString(cur.toArray()));
5 return;
6 }
7 for (int i = 0; i < sums.length; i++) {
8 //逻辑处理
9 //如果当前值大于target我们就不要选了
10 if (target < sums[i])
11 continue;
12 //否则我们就把他加入到集合中
13 cur.add(sums[i]);
14 //递归调用
15 combinationSum(cur, sums, target - sums[i]);
16 }
我们还用上面的数据打印测试一下
1public static void main(String[] args) {
2 new Recursion().combinationSum(new ArrayList<>(), new int[]{2, 3, 5}, 8);
3}
运行结果如下
是不是很意外,我们思路并没有出错,结果为什么不对呢,其实这就是典型的分支污染,我们再来看一下图
当我们选择2的时候是一个分支,当我们选择3的时候又是另外一个分支,这两个分支的数据应该是互不干涉的,但实际上当我们沿着选择2的分支走下去的时候list中会携带选择2的那个分支的数据,当我们再选择3的那个分支的时候这些数据还依然存在list中,所以对选择3的那个分支造成了污染。有一种解决方式就是每个分支都创建一个新的list,也就是下面这样,这样任何一个分支的修改都不会影响到其他分支。
再来看下代码
1private void combinationSum(List<Integer> cur, int sums[], int target) {
2 //终止条件必须要有
3 if (target == 0) {
4 System.out.println(Arrays.toString(cur.toArray()));
5 return;
6 }
7 for (int i = 0; i < sums.length; i++) {
8 //逻辑处理
9 //如果当前值大于target我们就不要选了
10 if (target < sums[i])
11 continue;
12 //由于List是引用传递,所以这里要重新创建一个
13 List<Integer> list = new ArrayList<>(cur);
14 //把数据加入到集合中
15 list.add(sums[i]);
16 //递归调用
17 combinationSum(list, sums, target - sums[i]);
18 }
19}
我们看到第13行是重新创建了一个list。再来打印一下看下结果,结果完全正确,每一组数据的和都是8
上面我们每一个分支都创建了一个新的list,所以任何分支修改都只会对当前分支有影响,不会影响到其他分支,也算是一种解决方式。但每次都重新创建数据,运行效率很差。我们知道当执行完分支1的时候,list中会携带分支1的数据,当执行分支2的时候,实际上我们是不需要分支1的数据的,所以有一种方式就是从分支1执行到分支2的时候要把分支1的数据给删除,这就是大家经常提到的回溯算法,我们来看下
1private void combinationSum(List<Integer> cur, int sums[], int target) {
2 //终止条件必须要有
3 if (target == 0) {
4 System.out.println(Arrays.toString(cur.toArray()));
5 return;
6 }
7 for (int i = 0; i < sums.length; i++) {
8 //逻辑处理
9 //如果当前值大于target我们就不要选了
10 if (target < sums[i])
11 continue;
12 //把数据sums[i]加入到集合中,然后参与下一轮的递归
13 cur.add(sums[i]);
14 //递归调用
15 combinationSum(cur, sums, target - sums[i]);
16 //sums[i]这个数据你用完了吧,我要把它删了
17 cur.remove(cur.size() - 1);
18 }
19}
我们再来看一下打印结果,完全正确
递归分支污染对结果的影响
分支污染一般会对结果造成致命错误,但也不是绝对的,我们再来看个例子。生成一个2^n长的数组,数组的值从0到(2^n)-1,比如n是3,那么要生成
[0, 0, 0][0, 0, 1][0, 1, 0][0, 1, 1][1, 0, 0][1, 0, 1][1, 1, 0][1, 1, 1]
我们先来画个图看一下
这不就是个二叉树吗,对于递归前面已经讲的很多了,我们来直接看代码
1private void binary(int[] array, int index) {
2 if (index == array.length) {
3 System.out.println(Arrays.toString(array));
4 } else {
5 int temp = array[index];
6 array[index] = 0;
7 binary(array, index + 1);
8 array[index] = 1;
9 binary(array, index + 1);
10 array[index] = temp;
11 }
12}
上面代码很好理解,首先是终止条件,然后是递归调用,在调用之前会把array[index]的值保存下来,最后再还原。我们来测试一下
new Recursion().binary(new int[]{0, 0, 0}, 0);看下打印结果
结果完全正确,我们再来改一下代码
1private void binary(int[] array, int index) {
2 if (index == array.length) {
3 System.out.println(Arrays.toString(array));
4 } else {
5 array[index] = 0;
6 binary(array, index + 1);
7 array[index] = 1;
8 binary(array, index + 1);
9 }
10}
再来看一下打印结果
和上面结果一模一样,开始的时候我们没有把array[index]的值保存下来,最后也没有对他进行复原,但结果丝毫不差。原因就在上面代码第5行array[index]=0,这是因为,上一分支执行的时候即使对array[index]造成了污染,在下一分支又会对他进行重新修改。即使你把它改为任何数字也都不会影响到最终结果,比如我们在上一分支执行完了时候我们把它改为100,你在试试
1private void binary(int[] array, int index) {
2 if (index == array.length) {
3 System.out.println(Arrays.toString(array));
4 } else {
5 array[index] = 0;
6 binary(array, index + 1);
7 array[index] = 1;
8 binary(array, index + 1);
9 //注意,这里改成100了
10 array[index] = 100;
11 }
12}
我们看到第10行,把array[index]改为100了,最终打印结果也是不会变的,所以这种分支污染并不会造成最终的结果错误。
总结
对递归的理解,看完这篇文章应该没有什么疑问了,记住上面模板,其实代码很好写的,后面也会再写一些关于递归的算法题的,让你彻底搞懂递归。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号