
数据结构和算法-数组与链表
参考:
数组:
https://www.cnblogs.com/luanyichao/p/7867160.html
https://www.cnblogs.com/TomHe789/p/12589056.html
https://www.cnblogs.com/chenpi/p/5507806.html#_label0
链表:
https://zhuanlan.zhihu.com/p/78094287
https://blog.csdn.net/jianyuerensheng/article/details/51200274
https://blog.csdn.net/qq_29566629/article/details/88139799
https://blog.csdn.net/kerryfish/article/details/24043099
https://www.cnblogs.com/null-/p/10018892.html
算法一看就懂之「 数组与链表 」
数据结构是我们软件开发中最基础的部分了,它体现着我们编程的内功。大多数人在正儿八经学习数据结构的时候估计是在大学计算机课上,而在实际项目开发中,反而感觉到用得不多。
其实也不是真的用得少,只不过我们在使用的时候被很多高级语言和框架组件封装好了,真正需要自己去实现的地方比较少而已。但别人封装好了不代表我们就可以不关注了,数据结构作为程序员的内功心法,是非常值得我们多花时间去研究的,我这就翻开书复习复习:
本文就先从大家最经常使用的「 数组 」和「 链表 」聊起。不过在聊数组和链表之前,咱们先看一下数据的逻辑结构分类。通俗的讲,数据的逻辑结构主要分为两种:
- 线性的:就是连成一条线的结构,本文要讲的数组和链表就属于这一类,另外还有 队列、栈 等
- 非线性的:顾名思义,数据之间的关系是非线性的,比如 堆、树、图 等
知道了分类,下面我们来详细看一下「 数组 」和「 链表 」的原理。
一、「 数组 」是什么?
数组是一个有限的、类型相同的数据的集合,在内存中是一段连续的内存区域。
如下图:
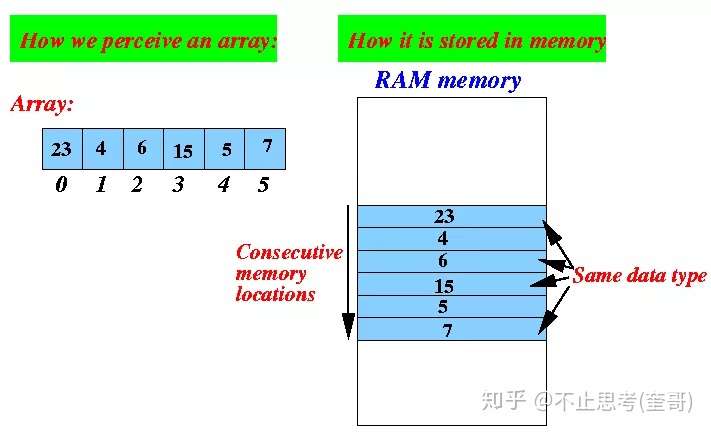
数组的下标是从0开始的,上图数组中有6个元素,对应着下标依次是0、1、2、3、4、5,同时,数组里面存的数据的类型必须是一致的,比如上图中存的都是数字类型。数组中的全部元素是“连续”的存储在一块内存空间中的,如上图右边部分,元素与元素之间是不会有别的存储隔离的。另外,也是因为数组需要连续的内存空间,所以数组在定义的时候就需要提前指定固定大小,不能改变。
- 数组的访问:
数组在访问操作方面有着独特的性能优势,因为数组是支持随机访问的,也就是说我们可以通过下标随机访问数组中任何一个元素,其原理是因为数组元素的存储是连续的,所以我们可以通过数组内存空间的首地址加上元素的偏移量计算出某一个元素的内存地址,如下:
array[n]的地址 = array数组内存空间的首地址 + 每个元素大小*n
通过上述公式可知:数组中通过下标去访问数据时并不需要遍历整个数组,因此数组的访问时间复杂度是 O(1),当然这里需要注意,如果不是通过下标去访问,而是通过内容去查找数组中的元素,则时间复杂度不是O(1),极端的情况下需要遍历整个数组的元素,时间复杂度可能是O(n),当然通过不同的查找算法所需的时间复杂度是不一样的。 - 数组的插入与删除:
同样是因为数组元素的连续性要求,所以导致数组在插入和删除元素的时候效率比较低。
如果要在数组中间插入一个新元素,就必须要将要相邻的后面的元素全部往后移动一个位置,留出空位给这个新元素。还是拿上面那图举例,如果需要在下标为2的地方插入一个新元素11,那就需要将原有的2、3、4、5几个下标的元素依次往后移动一位,新元素再插入下标为2的位置,最后形成新的数组是:
23、4、11、6、15、5、7
如果新元素是插入在数组的最开头位置,那整个原始数组都需要向后移动一位,此时的时间复杂度为最坏情况即O(n),如果新元素要插入的位置是最末尾,则无需其它元素移动,则此时时间复杂度为最好情况即O(1),所以平均而言数组插入的时间复杂度是O(n)
数组的删除与数组的插入是类似的。
所以整体而言,数组的访问效率高,插入与删除效率低。不过想改善数组的插入与删除效率也是有办法的,来来来,下面的「 链表 」了解一下。
二、「 链表 」是什么?
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的,一般用于插入与删除较为频繁的场景。
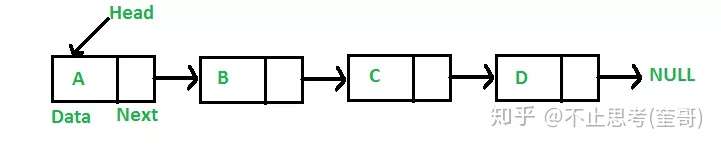
上图是“单链表”示例,链表并不需要数组那样的连续空间,它只需要一个个零散的内存空间即可,因此对内存空间的要求也比数组低。
链表的每一个节点通过“指针”链接起来,每一个节点有2部分组成,一部分是数据(上图中的Data),另一部分是后继指针(用来存储后一个节点的地址),在这条链中,最开始的节点称为Head,最末尾节点的指针指向NULL。
「 链表 」也分为好几种,上图是最简单的一种,它的每一个节点只有一个指针(后继指针)指向后面一个节点,这个链表称为:单向链表,除此之外还有 双向链表、循环链表 等。
双向链表:
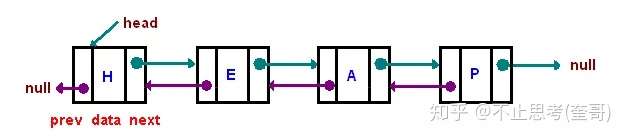
双向链表与单向链表的区别是前者是2个方向都有指针,后者只有1个方向的指针。双向链表的每一个节点都有2个指针,一个指向前节点,一个指向后节点。双向链表在操作的时候比单向链表的效率要高很多,但是由于多一个指针空间,所以占用内存也会多一点。
循环链表:
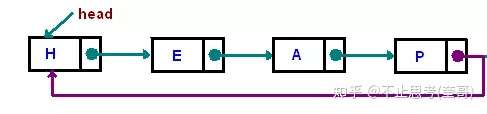
其实循环链表就是一种特殊的单向链表,只不过在单向链表的基础上,将尾节点的指针指向了Head节点,使之首尾相连。
- 链表的访问
链表的优势并不在与访问,因为链表无法通过首地址和下标去计算出某一个节点的地址,所以链表中如果要查找某个节点,则需要一个节点一个节点的遍历,因此链表的访问时间复杂度为O(n) - 链表的插入与删除
也正式因为链表内存空间是非连续的,所以它对元素的插入和删除时,并不需要像数组那样移动其它元素,只需要修改指针的指向即可。
例如:删除一个元素E:

例如:插入一个元素:
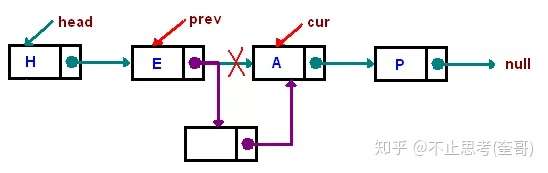
既然插入与删除元素只需要改动指针,无需移动数据,那么链表的时间插入删除的时间复杂度为O(1)不过这里指的是找到节点之后纯粹的插入或删除动作所需的时间复杂度。
如果当前还未定位到指定的节点,只是拿到链表的Head,这个时候要去删除此链表中某个固定内容的节点,则需要先查找到那个节点,这个查找的动作又是一个遍历动作了,这个遍历查找的时间复杂度却是O(n),两者加起来总的时间复杂度其实是O(n)的。
其实就算是已经定位到了某个要删除的节点了,删除逻辑也不简单。以“删除上图的E节点”为例,假如当前链表指针已经定位到了E节点,删除的时候,需要将这个E节点的前面一个节点H的后继指针改为指向A节点,那么E节点就会自动脱落了,但是当前链表指针是定位在E节点上,如何去改变H节点的后续指针呢,对于“单向链表”而言,这个时候需要从头遍历一遍整个链表,找到H节点去修改其后继指针的内容,所以时间复杂度是O(n),但如果当前是“双向链表”,则不需要遍历,直接通过前继指针即可找到H节点,时间复杂度是O(1),这里就是“双向链表”相当于“单向链表”的优势所在。
三、「 数组和链表 」的算法实战?
通过上面的介绍我们可以看到「 数组 」和「 链表 」各有优势,并且时间复杂度在不同的操作情况下也不相同,不能简单一句O(1)或O(n)。所以下面我们找了个常用的算法题来练习练习。
算法题:反转一个单链表
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
//定义一个前置节点变量,默认是null,因为对于第一个节点而言没有前置节点
ListNode pre = null;
//定义一个当前节点变量,首先将头节点赋值给它
ListNode curr = head;
//遍历整个链表,直到当前指向的节点为空,也就是最后一个节点了
while(curr != null){
//在循环体里会去改变当前节点的指针方向,本来当前节点的指针是指向的下一个节点,现在需要改为指向前一个节点,但是如果直接就这么修改了,那链条就断了,再也找不到后面的节点了,所以首先需要将下一个节点先临时保存起来,赋值到temp中,以备后续使用
ListNode temp = curr.next;
//开始处理当前节点,将当前节点的指针指向前面一个节点
curr.next = pre;
//将当前节点赋值给变量pre,也就是让pre移动一步,pre指向了当前节点
pre = curr;
//将之前保存的临时节点(后面一个节点)赋值给当前节点变量
curr = temp;
//循环体执行链表状态变更情况:
//NULL<-1 2->3->4->5->NULL
//NULL<-1<-2 3->4->5->NULL
//NULL<-1<-2<-3 4->5->NULL
//NULL<-1<-2<-3<-4 5->NULL
//NULL<-1<-2<-3<-4<-5
//循环体遍历完之后,pre指向5的节点
}
//完成,时间复杂度为O(n)
return pre;
}
}
数组的声明和常见使用方法
Java创建数组的几种方式
1、一维数组的声明方式:
通过二分法在已经排好序的数组中查找指定的元素,并返回该元素的下标
2. 操作接口
方法原型为:public static int binarySearch(Object[] a, Object key),该函数需要接收两个参数:数组名称,以及我们所需要查找的元素
3. 返回值
该方法的返回值的类型为整型,具体返回值具体分为以下两种情况:
-
如果数组中存在该元素,则会返回该元素在数组中的下标
-
例如:
import java.util.Arrays; public class binarySearch { public static void main(String[] args) { int[] scores = {1, 20, 30, 40, 50}; //在数组scores中查找元素20 int res = Arrays.binarySearch(scores, 20); //打印返回结果 System.out.println("res = " + res); } }运行结果:res = 2
-
-
如果数组中不存在该元素,则会返回 -(插入点 + 1),
-
这里的插入点具体指的是:如果该数组中存在该元素,那个元素在该数组中的下标
-
例如:
import java.util.Arrays; public class binarySearch { public static void main(String[] args) { int[] scores = {1, 20, 30, 40, 50}; //1.在数组scores中查找元素25 //从数组中可以看出 25位于20与30之间, //由于20的下标为1,所以25的下标为2, //最后的返回值就为:-(2 + 1) = -3 int res1 = Arrays.binarySearch(scores, 25); //2.同理在该数组中查找-2 //可以看出-2比数组中的任何一个元素都要小 //所以它应该在数组的第一个,所以-2的下标就应该为0 //最后的返回值就为:-(0 + 1) = -1 int res2 = Arrays.binarySearch(scores, -2); //3.又例如在该数组中查找55 //由于55比数组中的任何一个元素都要大 //所以他应该位于数组的最后一个,它的下标就为5 //最后的返回值就为:-(5 + 1) = -6 int res3 = Arrays.binarySearch(scores, 55); //打印返回结果 System.out.println("res1 = " + res1); System.out.println("res1 = " + res2); System.out.println("res1 = " + res3); } }运行结果:
res1 = -3
res1 = -1
res1 = -6
-
二维数组的定义
二维数组定义的一般形式为:
类型说明符 数组名[ 常量表达式][ 常量表达式];
比如:
int a[3][4];
表示定义了一个 3×4,即 3 行 4 列总共有 12 个元素的数组 a。这 12 个元素的名字依次是:a[0][0]、a[0][1]、a[0][2]、a[0][3];a[1][0]、a[1][1]、a[1][2]、a[1][3];a[2][0]、a[2][1]、a[2][2]、a[2][3]。
与一维数组一样,行序号和列序号的下标都是从 0 开始的。元素 a[i][j] 表示第 i+1 行、第 j+1 列的元素。数组 int a[m][n] 最大范围处的元素是 a[m–1][n–1]。所以在引用数组元素时应该注意,下标值应在定义的数组大小的范围内。
二维数组的初始化
可以用下面的方法对二维数组进行初始化。
1) 分行给二维数组赋初值,比如上面程序的赋值方法:
int a[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};
这种赋初值的方法比较直观,将第一个花括号内的数据赋给第一行的元素、第二个花括号内的数据赋给第二行的元素……即每行看作一个元素,按行赋初值。
2) 也可以将所有数据写在一个花括号内,按数组排列的顺序对各元素赋初值。比如:
int a[3][4] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
效果与第 1 种是一样的。但第1种方法更好,一行对一行,界限清楚。第 2 种方法如果数据多,写成一大片,容易遗漏,也不易检查。
3) 也可以只对部分元素赋初值。比如:
int a[3][4] = {{1, 2}, {5}, {9}};
它的作用是对第一行的前两个元素赋值、第二行和第三行的第一个元素赋值。其余元素自动为 0。初始化后数组各元素为:
4) 如果在定义数组时就对全部元素赋初值,即完全初始化,则第一维的长度可以不指定,但第二维的长度不能省。比如:
int a[3][4] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
等价于:
int a[][4] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
系统会根据数据总数和第二维的长度算出第一维的长度。但这种省略的写法几乎不用,因为可读性差。
5) int a[3][4]={0};
二维数组“清零”,里面每一个元素都是零。
int arr[3] [4];//这表示定义了一个3行4列的二维数组,并且行优先
以下是12个关于Java数组最常用的方法,它们是stackoverflow得票最高的问题。
声明一个数组
String[] aArray = new String[5];
String[] bArray = {"a","b","c", "d", "e"};
String[] cArray = new String[]{"a","b","c","d","e"};
打印一个数组

int[] intArray = { 1, 2, 3, 4, 5 };
String intArrayString = Arrays.toString(intArray);
// print directly will print reference value
System.out.println(intArray);
// [I@7150bd4d
System.out.println(intArrayString);
// [1, 2, 3, 4, 5]
根据数组创建ArrayList
String[] stringArray = { "a", "b", "c", "d", "e" };
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(stringArray));
System.out.println(arrayList);
// [a, b, c, d, e]
判断数组内部是否包含某个值
String[] stringArray = { "a", "b", "c", "d", "e" };
boolean b = Arrays.asList(stringArray).contains("a");
System.out.println(b);
// true
连接两个数组
int[] intArray = { 1, 2, 3, 4, 5 };
int[] intArray2 = { 6, 7, 8, 9, 10 };
// Apache Commons Lang library
int[] combinedIntArray = ArrayUtils.addAll(intArray, intArray2);
声明一个内联数组(array inline)
method(new String[]{"a", "b", "c", "d", "e"});
根据分隔符拼接数组元素(去掉最后一个分隔符)
// containing the provided list of elements
// Apache common lang
String j = StringUtils.join(new String[] { "a", "b", "c" }, ", ");
System.out.println(j);
// a, b, c
ArrayList转数组
String[] stringArray = { "a", "b", "c", "d", "e" };
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(stringArray));
String[] stringArr = new String[arrayList.size()];
arrayList.toArray(stringArr);
for (String s : stringArr)
System.out.println(s);
Array转Set
Set<String> set = new HashSet<String>(Arrays.asList(stringArray)); System.out.println(set); //[d, e, b, c, a]
反转数组
int[] intArray = { 1, 2, 3, 4, 5 };
ArrayUtils.reverse(intArray);
System.out.println(Arrays.toString(intArray));
//[5, 4, 3, 2, 1]
删除数组元素
int[] intArray = { 1, 2, 3, 4, 5 };
int[] removed = ArrayUtils.removeElement(intArray, 3);//create a new array
System.out.println(Arrays.toString(removed));
整形转字节数组
byte[] bytes = ByteBuffer.allocate(4).putInt(8).array();
for (byte t : bytes) {
System.out.format("0x%x ", t);
}
译文链接:http://www.programcreek.com/2013/09/top-10-methods-for-java-arrays/
如何判断一个数组中是否包含某个元素
方法一、使用List
public static boolean useList(String[] arr, String targetValue) { return Arrays.asList(arr).contains(targetValue);}方法二、使用Set
public static boolean useSet(String[] arr, String targetValue) { Set<String> set = new HashSet<String>(Arrays.asList(arr)); return set.contains(targetValue);}方法三、使用循环判断
public static boolean useLoop(String[] arr, String targetValue) { for(String s: arr){ if(s.equals(targetValue)) { return true; } } return false;}
链表的常见使用方法
【数据结构】链表的原理及java实现
一:单向链表基本介绍
链表是一种数据结构,和数组同级。比如,Java中我们使用的ArrayList,其实现原理是数组。而LinkedList的实现原理就是链表了。链表在进行循环遍历时效率不高,但是插入和删除时优势明显。下面对单向链表做一个介绍。
单向链表是一种线性表,实际上是由节点(Node)组成的,一个链表拥有不定数量的节点。其数据在内存中存储是不连续的,它存储的数据分散在内存中,每个结点只能也只有它能知道下一个结点的存储位置。由N各节点(Node)组成单向链表,每一个Node记录本Node的数据及下一个Node。向外暴露的只有一个头节点(Head),我们对链表的所有操作,都是直接或者间接地通过其头节点来进行的。
上图中最左边的节点即为头结点(Head),但是添加节点的顺序是从右向左的,添加的新节点会被作为新节点。最先添加的节点对下一节点的引用可以为空。引用是引用下一个节点而非下一个节点的对象。因为有着不断的引用,所以头节点就可以操作所有节点了。
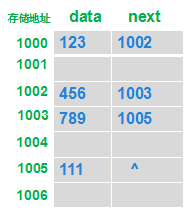
下图描述了单向链表存储情况。存储是分散的,每一个节点只要记录下一节点,就把所有数据串了起来,形成了一个单向链表。
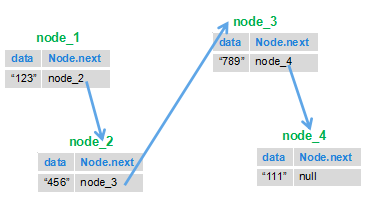
节点(Node)是由一个需要储存的对象及对下一个节点的引用组成的。也就是说,节点拥有两个成员:储存的对象、对下一个节点的引用。下面图是具体的说明:

二、单项链表的实现
package com.zjn.LinkAndQueue; /** * 自定义链表设计 * * @author zjn * */ public class MyLink { Node head = null; // 头节点 /** * 链表中的节点,data代表节点的值,next是指向下一个节点的引用 * * @author zjn * */ class Node { Node next = null;// 节点的引用,指向下一个节点 int data;// 节点的对象,即内容 public Node(int data) { this.data = data; } } /** * 向链表中插入数据 * * @param d */ public void addNode(int d) { Node newNode = new Node(d);// 实例化一个节点 if (head == null) { head = newNode; return; } Node tmp = head; while (tmp.next != null) { tmp = tmp.next; } tmp.next = newNode; } /** * * @param index:删除第index个节点 * @return */ public boolean deleteNode(int index) { if (index < 1 || index > length()) { return false; } if (index == 1) { head = head.next; return true; } int i = 1; Node preNode = head; Node curNode = preNode.next; while (curNode != null) { if (i == index) { preNode.next = curNode.next; return true; } preNode = curNode; curNode = curNode.next; i++; } return false; } /** * * @return 返回节点长度 */ public int length() { int length = 0; Node tmp = head; while (tmp != null) { length++; tmp = tmp.next; } return length; } /** * 在不知道头指针的情况下删除指定节点 * * @param n * @return */ public boolean deleteNode11(Node n) { if (n == null || n.next == null) return false; int tmp = n.data; n.data = n.next.data; n.next.data = tmp; n.next = n.next.next; System.out.println("删除成功!"); return true; } public void printList() { Node tmp = head; while (tmp != null) { System.out.println(tmp.data); tmp = tmp.next; } } public static void main(String[] args) { MyLink list = new MyLink(); list.addNode(5); list.addNode(3); list.addNode(1); list.addNode(2); list.addNode(55); list.addNode(36); System.out.println("linkLength:" + list.length()); System.out.println("head.data:" + list.head.data); list.printList(); list.deleteNode(4); System.out.println("After deleteNode(4):"); list.printList(); } }
三、链表相关的常用操作实现方法
1. 链表反转
/**
* 链表反转
*
* @param head
* @return
*/
public Node ReverseIteratively(Node head) {
Node pReversedHead = head;
Node pNode = head;
Node pPrev = null;
while (pNode != null) {
Node pNext = pNode.next;
if (pNext == null) {
pReversedHead = pNode;
}
pNode.next = pPrev;
pPrev = pNode;
pNode = pNext;
}
this.head = pReversedHead;
return this.head;
}2. 查找单链表的中间节点
采用快慢指针的方式查找单链表的中间节点,快指针一次走两步,慢指针一次走一步,当快指针走完时,慢指针刚好到达中间节点。
/**
* 查找单链表的中间节点
*
* @param head
* @return
*/
public Node SearchMid(Node head) {
Node p = this.head, q = this.head;
while (p != null && p.next != null && p.next.next != null) {
p = p.next.next;
q = q.next;
}
System.out.println("Mid:" + q.data);
return q;
}3. 查找倒数第k个元素
采用两个指针P1,P2,P1先前移K步,然后P1、P2同时移动,当p1移动到尾部时,P2所指位置的元素即倒数第k个元素 。
/**
* 查找倒数 第k个元素
*
* @param head
* @param k
* @return
*/
public Node findElem(Node head, int k) {
if (k < 1 || k > this.length()) {
return null;
}
Node p1 = head;
Node p2 = head;
for (int i = 0; i < k; i++)// 前移k步
p1 = p1.next;
while (p1 != null) {
p1 = p1.next;
p2 = p2.next;
}
return p2;
}4. 对链表进行排序
/**
* 排序
*
* @return
*/
public Node orderList() {
Node nextNode = null;
int tmp = 0;
Node curNode = head;
while (curNode.next != null) {
nextNode = curNode.next;
while (nextNode != null) {
if (curNode.data > nextNode.data) {
tmp = curNode.data;
curNode.data = nextNode.data;
nextNode.data = tmp;
}
nextNode = nextNode.next;
}
curNode = curNode.next;
}
return head;
}5. 删除链表中的重复节点
/**
* 删除重复节点
*/
public void deleteDuplecate(Node head) {
Node p = head;
while (p != null) {
Node q = p;
while (q.next != null) {
if (p.data == q.next.data) {
q.next = q.next.next;
} else
q = q.next;
}
p = p.next;
}
}6. 从尾到头输出单链表,采用递归方式实现
/**
* 从尾到头输出单链表,采用递归方式实现
*
* @param pListHead
*/
public void printListReversely(Node pListHead) {
if (pListHead != null) {
printListReversely(pListHead.next);
System.out.println("printListReversely:" + pListHead.data);
}
}7. 判断链表是否有环,有环情况下找出环的入口节点
/** * 判断链表是否有环,单向链表有环时,尾节点相同 * * @param head * @return */ public boolean IsLoop(Node head) { Node fast = head, slow = head; if (fast == null) { return false; } while (fast != null && fast.next != null) { fast = fast.next.next; slow = slow.next; if (fast == slow) { System.out.println("该链表有环"); return true; } } return !(fast == null || fast.next == null); } /** * 找出链表环的入口 * * @param head * @return */ public Node FindLoopPort(Node head) { Node fast = head, slow = head; while (fast != null && fast.next != null) { slow = slow.next; fast = fast.next.next; if (slow == fast) break; } if (fast == null || fast.next == null) return null; slow = head; while (slow != fast) { slow = slow.next; fast = fast.next; } return slow; }
链表的基本操作(java版)
引言
最近在刷剑指offer和LeetCode的时候,看到了很多关于链表的问题,以前只学过c版本的链表,而且学的不是太好,现在总结一下java版本实现链表基本操作的问题
基本操作
先新建一个节点类:
public class ListNode { int val; ListNode next = null; ListNode(int val) { this.val = val; } }
基本操作:
ListNode head = null; @SuppressWarnings("null") public void add(int data) { ListNode newnode = new ListNode(data); if(head==null) { head = newnode; return; } ListNode temp = head; while(temp.next!=null) { temp=temp.next; } temp.next=newnode; } public void printLink(){ ListNode curNode = head; while(curNode !=null){ System.out.print(curNode.val+" "); curNode = curNode.next; } System.out.println(); } public void length() { ListNode temp = head; int i =0; while(temp!=null) { i++; temp = temp.next; } System.out.println(i); } public static void main(String[] args) { SinglyLinkedList list = new SinglyLinkedList(); list.add(1); list.add(2); list.printLink(); list.length(); }
JAVA中关于链表的操作和基本算法
import java.util.HashMap; import java.util.Scanner; import java.util.Stack; /** * * @author kerryfish * 关于java中链表的操作 * 1. 求单链表中结点的个数: getListLength * 2. 将单链表反转: reverseList(遍历),reverseListRec(递归) * 3. 查找单链表中的倒数第K个结点(k > 0): reGetKthNode * 4. 查找单链表的中间结点: getMiddleNode * 5. 从尾到头打印单链表: reversePrintListStack,reversePrintListRec(递归) * 6. 已知两个单链表pHead1 和pHead2 各自有序,把它们合并成一个链表依然有序: mergeSortedList, mergeSortedListRec * 7. 对单链表进行排序,listSort(归并),insertionSortList(插入) * 8. 判断一个单链表中是否有环: hasCycle * 9. 判断两个单链表是否相交: isIntersect * 10. 已知一个单链表中存在环,求进入环中的第一个节点: getFirstNodeInCycle, getFirstNodeInCycleHashMap * 11. 给出一单链表头指针head和一节点指针delete,O(1)时间复杂度删除节点delete: deleteNode */ public class LinkedListSummary { /** * @param args * */ public static class Node{ int value; Node next; public Node(int n){ this.value=n; this.next=null; } } public static void main(String[] args) { // TODO Auto-generated method stub Scanner in=new Scanner(System.in); Node head=null; if(in.hasNextInt()){ head=new Node(in.nextInt()); } Node temp=head; while(in.hasNextInt()){ temp.next=new Node(in.nextInt()); temp=temp.next; } in.close(); //int len=getListLength(head); //Node reHead=reverseList(head); //reHead=reverseListRec(reHead); //Node node_k=reGetKthNode(head,3); //Node mid=getMiddleNode(head); //reversePrintListRec(head); //reversePrintListStack(head); //Node mergeHead=mergeSortedList(head,null); //Node sortHead=listSort(head); } //求单链表中结点的个数: getListLength public static int getListLength(Node head){ int len=0; while(head!=null){ len++; head=head.next; } return len; } //将单链表反转,循环 public static Node reverseList(Node head){ if(head==null||head.next==null)return head; Node pre=null; Node nex=null; while(head!=null){ nex=head.next; head.next=pre; pre=head; head=nex; } return pre; } //将单链表反转,递归 public static Node reverseListRec(Node head){ if(head==null||head.next==null)return head; Node reHead=reverseListRec(head.next); head.next.next=head; head.next=null; return reHead; } //查找单链表中的倒数第K个结点(k > 0) public static Node reGetKthNode(Node head,int k){ if(head==null)return head; int len=getListLength(head); if(k>len)return null; Node target=head; Node nexk=head; for(int i=0;i<k;i++){ nexk=nexk.next; } while(nexk!=null){ target=target.next; nexk=nexk.next; } return target; } //查找单链表的中间结点 public static Node getMiddleNode(Node head){ if(head==null||head.next==null)return head; Node target=head; Node temp=head; while(temp!=null&&temp.next!=null){ target=target.next; temp=temp.next.next; } return target; } //从尾到头打印单链表,递归 public static void reversePrintListRec(Node head){ if(head==null)return; else{ reversePrintListRec(head.next); System.out.println(head.value); } } //从尾到头打印单链表,栈 public static void reversePrintListStack(Node head){ Stack<Node> s=new Stack<Node>(); while(head!=null){ s.push(head); head=head.next; } while(!s.isEmpty()){ System.out.println(s.pop().value); } } //合并两个有序的单链表head1和head2,循环 public static Node mergeSortedList(Node head1,Node head2){ if(head1==null)return head2; if(head2==null)return head1; Node target=null; if(head1.value>head2.value){ target=head2; head2=head2.next; } else{ target=head1; head1=head1.next; } target.next=null; Node mergeHead=target; while(head1!=null && head2!=null){ if(head1.value>head2.value){ target.next=head2; head2=head2.next; } else{ target.next=head1; head1=head1.next; } target=target.next; target.next=null; } if(head1==null)target.next=head2; else target.next=head1; return mergeHead; } //合并两个有序的单链表head1和head2,递归 public static Node mergeSortedListRec(Node head1,Node head2){ if(head1==null)return head2; if(head2==null)return head1; if(head1.value>head2.value){ head2.next=mergeSortedListRec(head2.next,head1); return head2; } else{ head1.next=mergeSortedListRec(head1.next,head2); return head1; } } //对单链表进行排序,归并排序,在排序里面不建议选用递归的合并有序链表算法,如果链表长度较长,很容易出现栈溢出 public static Node listSort(Node head){ Node nex=null; if(head==null||head.next==null)return head; else if(head.next.next==null){ nex=head.next; head.next=null; } else{ Node mid=getMiddleNode(head); nex=mid.next; mid.next=null; } return mergeSortedList(listSort(head),listSort(nex));//合并两个有序链表,不建议递归 } //对单链表进行排序,插入排序 public Node insertionSortList(Node head) { if(head==null||head.next==null)return head; Node pnex=head.next; Node pnex_nex=null; head.next=null; while(pnex!=null){ pnex_nex=pnex.next; Node temp=head; Node temp_pre=null; while(temp!=null){ if(temp.value>pnex.value)break; temp_pre=temp; temp=temp.next; } if(temp_pre==null){ head=pnex; pnex.next=temp; } else{ temp_pre.next=pnex; pnex.next=temp; } pnex=pnex_nex; } return head; } //判断一个单链表中是否有环,快慢指针 public static boolean hasCycle(Node head){ boolean flag=false; Node p1=head; Node p2=head; while(p1!=null&&p2!=null){ p1=p1.next; p2=p2.next.next; if(p2==p1){ flag=true; break; } } return flag; } //判断两个单链表是否相交,如果相交返回第一个节点,否则返回null //如果单纯的判断是否相交,只需要看最后一个指针是否相等 public static Node isIntersect(Node head1,Node head2){ Node target=null; if(head1==null||head2==null)return target; int len1=getListLength(head1); int len2=getListLength(head2); if(len1>=len2){ for(int i=0;i<len1-len2;i++){ head1=head1.next; } }else{ for(int i=0;i<len2-len1;i++){ head2=head2.next; } } while(head1!=null&&head2!=null){ if(head1==head2){ target=head1; break; } else{ head1=head1.next; head2=head2.next; } } return target; } //已知一个单链表中存在环,求进入环中的第一个节点,利用hashmap,不要用ArrayList,因为判断ArrayList是否包含某个元素的效率不高 public static Node getFirstNodeInCycleHashMap(Node head){ Node target=null; HashMap<Node,Boolean> map=new HashMap<Node,Boolean>(); while(head!=null){ if(map.containsKey(head))target=head; else{ map.put(head, true); } head=head.next; } return target; } //已知一个单链表中存在环,求进入环中的第一个节点,不用hashmap //用快慢指针,与判断一个单链表中是否有环一样,找到快慢指针第一次相交的节点,此时这个节点距离环开始节点的长度和链表投距离环开始的节点的长度相等 public static Node getFirstNodeInCycle(Node head){ Node fast=head; Node slow=head; while(fast!=null&&fast.next!=null){ slow=slow.next; fast=fast.next.next; if(slow==fast)break; } if(fast==null||fast.next==null)return null;//判断是否包含环 //相遇节点距离环开始节点的长度和链表投距离环开始的节点的长度相等 slow=head; while(slow!=fast){ slow=slow.next; fast=fast.next; }//同步走 return slow; } //给出一单链表头指针head和一节点指针delete,O(1)时间复杂度删除节点delete //可惜采用将delete节点value值与它下个节点的值互换的方法,但是如果delete是最后一个节点,则不行,但是总得复杂度还是O(1) public static void deleteNode(Node head,Node delete){ //首先处理delete节点为最后一个节点的情况 if(delete==null)return; if(delete.next==null){ if(head==delete)head=null; else{ Node temp=head; while(temp.next!=delete){ temp=temp.next; } temp.next=null; } } else{ delete.value=delete.next.value; delete.next=delete.next.next; } return; } }
Java_实现单链表-基本操作
一、通过JAVA实现单链表
增删改查、返回长度、反转、查找、排序
二、代码
1 package officeCoding;
2
3 import java.util.ArrayList;
4 import java.util.Stack;
5
6 /**
7 * 从尾到头遍历链表 输入一个链表,按链表值从尾到头的顺序返回一个ArrayList
8 *
9 * @author Administrator
10 */
11 class ListNode {// 单链表节点构建
12 int val;
13 ListNode next = null;
14
15 ListNode(int val) {
16 this.val = val;
17 }
18 }
19
20 public class Pro_03 {
21
22 static ListNode head = null;// 创建一个头节点
23
24 public static void main(String[] args) {
25 addNode(5);
26 addNode(8);
27 ArrayList<Integer> list = printListFromTailToHead(head);
28 System.out.println(list);
29 }
30
31 // 队列和栈是一对好基友,从尾到头打印链表,当然离不开借助栈的帮忙啦
32 // 所以,先把链表里的东西,都放到一个栈里去,然后按顺序把栈里的东西pop出来,就这么简单
33 public static ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
34 Stack<Integer> stack = new Stack<Integer>();
35 while (listNode != null) {
36 stack.push(listNode.val);
37 listNode = listNode.next;
38 }
39 ArrayList<Integer> list = new ArrayList<Integer>();
40 while (!stack.isEmpty()) {
41 list.add(stack.pop());
42 }
43 return list;
44 }
45
46 // input
47 public static void addNode(int d) {
48 ListNode newNode = new ListNode(d);
49 if (head == null) {
50 head = newNode;
return;
51 }
52 ListNode tmp = head;
53 while (tmp.next != null) {
54 tmp = tmp.next;
55 }
56 tmp.next = newNode;
57 }
58
59 // delete
60 public boolean deleteNode(int index) {
61 if (index < 1 || index > length()) {
62 return false;// 如果当前index在链表中不存在
63 }
64 if (index == 1) {// 如果index指定的是头节点
65 head = head.next;
66 return true;
67 }
68 int i = 2;
69 ListNode preNode = head;// 前一个节点(从头节点开始)
70 ListNode curNode = preNode.next;// 当前节点
71 while (curNode != null) {
72 if (i == index) {
73 preNode.next = curNode.next;// 删除当节点,前节点连接到下节点
74 return true;
75 }
76 preNode = curNode;
77 curNode = curNode.next;
78 i++;
79 }
80 return false;
81 }
82
83 // 返回节点长度
84
85 public int length() {
86 int length = 0;
87 ListNode tmp = head;
88 while (tmp != null) {
89 length++;
90 tmp = tmp.next;
91 }
92 return length;
93 }
94
95 // 链表反转
96
97 public ListNode ReverseIteratively(ListNode head) {
98 ListNode pReversedHead = head;
99 ListNode pNode = head;
100 ListNode pPrev = null;
101 while (pNode != null) {
102 ListNode pNext = pNode.next;
103 if (pNext == null) {
104 pReversedHead = pNode;
105 }
106 pNode.next = pPrev;
107 pPrev = pNode;
108 pNode = pNext;
109 }
110 this.head = pReversedHead;
111 return this.head;
112 }
113
114 // 查找单链表的中间节点
115
116 public ListNode SearchMid(ListNode head) {
117 ListNode p = this.head, q = this.head;
118 while (p != null && p.next != null && p.next.next != null) {
119 p = p.next.next;
120 q = q.next;
121 }
122 System.out.println("Mid:" + q.val);
123 return q;
124 }
125
126 // 查找倒数 第k个元素
127
128 public ListNode findElem(ListNode head, int k) {
129 if (k < 1 || k > this.length()) {
130 return null;
131 }
132 ListNode p1 = head;
133 ListNode p2 = head;
134 for (int i = 0; i < k; i++)// 前移k步
135 p1 = p1.next;
136 while (p1 != null) {
137 p1 = p1.next;
138 p2 = p2.next;
139 }
140 return p2;
141 }
142
143 // 排序
144
145 public ListNode orderList() {
146 ListNode nextNode = null;
147 int tmp = 0;
148 ListNode curNode = head;
149 while (curNode.next != null) {
150 nextNode = curNode.next;
151 while (nextNode != null) {
152 if (curNode.val > nextNode.val) {
153 tmp = curNode.val;
154 curNode.val = nextNode.val;
155 nextNode.val = tmp;
156 }
157 nextNode = nextNode.next;
158 }
159 curNode = curNode.next;
160 }
161 return head;
162 }
163
164 // 从尾到头输出单链表,采用递归方式实现
165
166 public void printListReversely(ListNode pListHead) {
167 if (pListHead != null) {
168 printListReversely(pListHead.next);
169 System.out.println("printListReversely:" + pListHead.val);
170 }
171 }
172
173 // 判断链表是否有环,单向链表有环时,尾节点相同
174
175 public boolean IsLoop(ListNode head) {
176 ListNode fast = head, slow = head;
177 if (fast == null) {
178 return false;
179 }
180 while (fast != null && fast.next != null) {
181 fast = fast.next.next;
182 slow = slow.next;
183 if (fast == slow) {
184 System.out.println("该链表有环");
185 return true;
186 }
187 }
188 return !(fast == null || fast.next == null);
189 }
190
191 // 找出链表环的入口
192
193 public ListNode FindLoopPort(ListNode head) {
194 ListNode fast = head, slow = head;
195 while (fast != null && fast.next != null) {
196 slow = slow.next;
197 fast = fast.next.next;
198 if (slow == fast)
199 break;
200 }
201 if (fast == null || fast.next == null)
202 return null;
203 slow = head;
204 while (slow != fast) {
205 slow = slow.next;
206 fast = fast.next;
207 }
208 return slow;
209 }
210 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号