
架构设计-实践总结(一)
参考:
微信公众号:架构师之路
如何保证session一致性?
如何保证session一致性?
这个问题太泛了,今天系统性讲讲session常见的N种方案,不知道是不是兄弟你想要的。
什么是session?
服务器为每个用户创建一个会话,存储用户的相关信息,以便多次请求能够定位到同一个上下文。 Web开发中,web-server可以自动为同一个浏览器的访问用户自动创建session,提供数据存储功能。最常见的,会把用户的登录信息、用户信息存储在session中,以保持登录状态。
什么是session一致性问题?
只要用户不重启浏览器,每次http短连接请求,理论上服务端都能定位到session,保持会话。
当只有一台web-server提供服务时,每次http短连接请求,都能够正确路由到存储session的对应web-server。
画外音:废话,因为只有一台。
此时的web-server是无法保证高可用的,采用“冗余+故障转移”的多台web-server来保证高可用时,每次http短连接请求就不一定能路由到正确的session了。
如上图,假设用户包含登录信息的session都记录在第一台web-server上,反向代理如果将请求路由到另一台web-server上,可能就找不到相关信息,而导致用户需要重新登录。 在web-server高可用时,如何保证session路由的一致性呢?
二、session同步法
思路:多个web-server之间相互同步session,这样每个web-server之间都包含全部的session。
优点:web-server支持的功能,应用程序不需要修改代码。
不足:
- session的同步需要数据传输,占内网带宽,有时延
- 所有web-server都包含所有session数据,数据量受内存限制,无法水平扩展
- 有更多web-server时要歇菜
三、客户端存储法
思路:服务端存储所有用户的session,内存占用较大,可以将session存储到浏览器cookie中,每个端只要存储一个用户的数据了。
优点:服务端不需要存储。
缺点:
- 每次http请求都携带session,占外网带宽
- 数据存储在端上,并在网络传输,存在泄漏、篡改、窃取等安全隐患
- session存储的数据大小受cookie限制
“端存储”的方案虽然不常用,但确实是一种思路。
三、反向代理hash一致性
思路:web-server为了保证高可用,有多台冗余,反向代理层能不能做一些事情,让同一个用户的请求保证落在一台web-server上呢?
方案一:四层代理
hash反向代理层使用用户ip来做hash,以保证同一个ip的请求落在同一个web-server上。
方案二:七层代理
hash反向代理使用http协议中的某些业务属性来做hash,例如sid,city_id,user_id等,能够更加灵活的实施hash策略,以保证同一个浏览器用户的请求落在同一个web-server上。
优点:
- 只需要改nginx配置,不需要修改应用代码
- 负载均衡,只要hash属性是均匀的,多台web-server的负载是均衡的
- 可以支持web-server水平扩展
不足:
- 如果web-server重启,一部分session会丢失,产生业务影响,例如部分用户重新登录
- 如果web-server水平扩展,rehash后session重新分布,也会有一部分用户路由不到正确的session
session一般是有有效期的,所有不足中的两点,可以认为等同于部分session失效,一般问题不大。 对于四层hash还是七层hash,个人推荐前者:让专业的软件做专业的事情,反向代理就负责转发,尽量不要引入应用层业务属性。
四、后端统一存储
思路:将session存储在web-server后端的存储层,数据库或者缓存。
优点:
- 没有安全隐患
- 可以水平扩展,数据库/缓存水平切分即可
- web-server重启或者扩容都不会有session丢失
不足:增加了一次网络调用,并且需要修改应用代码。 对于db存储还是cache,个人推荐后者:session读取的频率会很高,数据库压力会比较大。如果有session高可用需求,cache可以做高可用,但大部分情况下session可以丢失,一般也不需要考虑高可用。
五、总结
保证session一致性的架构设计常见方法:
- session同步法:多台web-server相互同步数据
- 客户端存储法:一个用户只存储自己的数据
- 反向代理hash一致性:四层hash和七层hash都可以做,保证一个用户的请求落在一台web-server上
- 后端统一存储:web-server重启和扩容,session也不会丢失
对于方案3和方案4,个人建议推荐后者:
- web层、service层无状态是大规模分布式系统设计原则之一,session属于状态,不宜放在web层
- 让专业的软件做专业的事情,web-server存session?还是让cache去做这样的事情吧
第三方服务挂了,如何保证服务不受影响?
上周有个朋友问我说:
沈老师,我们有很多服务依赖第三方接口,他们的接口不稳定,从而影响我们的服务,有没有什么方法避免?
今天和大家聊一聊这个问题。
首先,可以将第三方接口,收口到一个服务内。
这样,可以避免每个调用方都依赖于第三方服务:
(1)解除调用方与第三方接口的耦合;
(2)当第三方的接口变动时,只有服务需要修改,而不是所有调用方均修改;
此时,接口调用流程是什么样的呢?
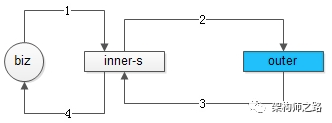
如上图1-4所述:
(1)业务调用方调用内部service;
(2)内部service跨公网调用第三方接口;
(3)第三方接口返回结果给内部service;
(4)内部service返回结果给业务调用方;
封装了服务之后,还存在什么潜在的问题呢?
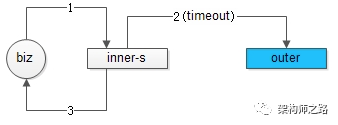
内部服务可能对上游业务提供了很多服务接口,当有一个接口跨公网第三方调用超时时,可能导致所有接口都不可用,即使大部分接口不依赖于跨公网第三方调用。
为什么会出现“一个第三方接口超时,所有接口都不可用”的情况呢?
内部服务对业务方提供的N个接口,会共用服务容器内的工作线程(假设有100个工作线程)。
假设这N个接口的某个接口跨公网依赖于第三方的接口,发生了网络抖动,或者接口超时(不妨设超时时间为5秒)。
潜台词是,这个工作线程会被占用5秒钟,然后超时返回业务调用方。
假设这个请求的吞吐量为20qps,言下之意,很短的时间内,所有的100个工作线程都会被卡在这个第三方超时等待上,而其他N-1个原本没有问题的接口,也得不到工作线程处理。
如何来进行优化呢?
常见的方案有三种:
(1)增大工作线程数(不根本解决问题);
(2)降低超时时间(不根本解决问题);
(3)垂直拆分,N个接口拆分成若干个服务,使得在出问题时,被牵连的接口尽可能少(依旧不根本解决问题,难道一个服务只提供一个接口吗?);
还能如何优化呢?
异步代理法,是一种很常见的架构实践。
业务场景:通过OpenID实时获取微信用户基本信息。
解决方案:增加一个代理,向服务屏蔽究竟是“本地实时”还是“异步远程”去获取返回结果。
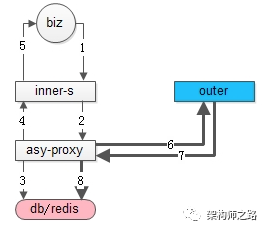
本地实时流程如上图1-5:
(1)业务调用方调用内部service;
(2)内部service调用异步代理service;
(3)异步代理service通过OpenID在本地拿取数据;
(4)异步代理service将数据返回内部service;
(5)内部service返回结果给业务调用方;
远程异步流程如上图6-8粗箭头的部分:
(6)异步代理service定期跨公网调用微信服务;
(7)微信服务返回数据;
(8)刷新本地数据;
这种方案有什么优缺点呢?
优点:公网抖动,第三方接口超时,不影响内部接口调用。
缺点:本地返回的不是最新数据(很多业务可以接受数据延时)。
画外音:有时候,内部service和异步代理service可以合成一个service。
还有其他的方法吗?
第三方接口备份与切换,也是一种常见的实践。
业务场景:调用第三方短信网关,或者电子合同等。
解决方案:同时使用(或者备份)多个第三方服务。
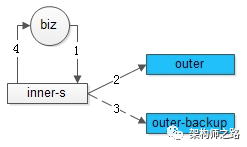
流程如上图1-4:
(1)业务调用方调用内部service;
(2)内部service调用第一个三方接口;
(3)超时后,调用第二个备份服务,未来都直接调用备份服务,直到超时的服务恢复;
(4)内部service返回结果给业务调用方;
这种方案有什么优缺点呢?
优点:公网抖动,第三方接口超时,不影响内部接口调用(初期少数几个请求会超时)。
缺点:不是所有公网调用都能够像短息网关,电子合同服务一样有备份接口的,像微信、支付宝等就只此一家。
还有其他的方法吗?
异步调用法,也是一种实践。
业务场景:本地结果,同步第三方服务,例如用户在58到家平台下单,58到家平台需要通知平台商家为用户提供服务。
解决方案:本地调用成功就返回成功,异步调用第三方接口同步数据(和异步代理有微小差别)。
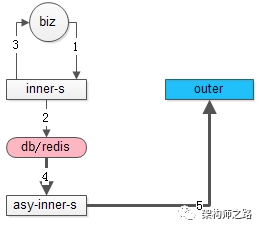
本地流程如上图1-3:
(1)业务调用方调用内部service;
(2)内部service写本地数据;
(3)内部service返回结果给业务调用方成功;
异步流程如上图4-5粗箭头的部分:
(4)异步service定期将本地数据取出(或者通知也行,实时性好);
(5)异步调用第三方接口同步数据;
这种方案有什么优缺点呢?
优点:公网抖动,第三方接口超时,不影响内部接口调用。
缺点:不是所有业务场景都可以异步同步数据。
总结
跨公网调用第三方,可能存在的问题:
(1)公网抖动,第三方服务不稳定,影响自身服务;
(2)一个接口超时,占住工作线程,影响其他接口;
降低影响的优化方案有:
(1)增大工作线程数;
(2)降低超时时间;
(3)服务垂直拆分;
任何脱离业务的架构方案都是耍流氓,可以结合业务实施方案:
(1)业务能接受旧数据:读取本地数据,异步代理定期更新数据;
(2)有多个第三方服务提供商:多个第三方互备;
(3)向第三方同步数据:本地写成功就算成功,异步向第三方同步数据;
希望第三方的服务挂掉,不再影响大家的服务。
除了解析域名,DNS还能干吗?
一个http请求,典型的执行流程是怎么样的呢?
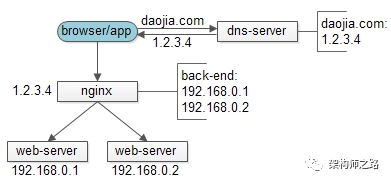
可以看到,典型流程为:
(1)客户端请求dns-server,发起域名解析;
(2)dns-server返回域名对应的外网ip(1.2.3.4);
(3)客户端通过外网ip(1.2.3.4),访问反向代理;
(4)反向代理通过内网ip(192.168.x.x),将请求分发给web-server;
(5)web-server对请求进行处理;
其中,第一个步骤,将域名转化ip的过程,发生在应用系统的外部,是通过DNS实现的。
除了域名解析,在架构设计时,还能利用DNS做一些什么事情呢?
一、用户就近访问
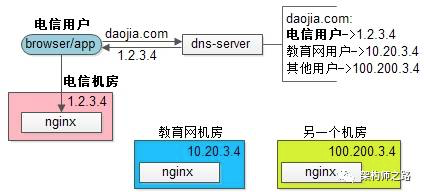
DNS可以实现,用户所需资源的就近访问:
(1)电信用户想要访问某一个服务器资源;
(2)浏览器向dns-server发起域名解析请求;
(3)dns-server识别出访问者是电信用户;
(4)dns-server将电信机房的nginx外网ip返回给访问者;
(5)访问者就近访问;
根据用户ip来返回最近的服务器ip,称为“智能DNS”,CDN以及多机房多活中最常用。
二、反向代理水平扩展
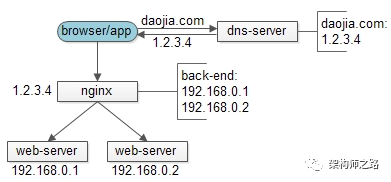
典型的互联网架构中,可以通过增加web-server来扩充web层的性能,但反向代理nginx仍是整个系统的唯一入口,如果系统吞吐超过nginx的性能极限,难以扩容,此时就需要dns-server来配合水平扩展。
具体做法是:在dns-server对于同一个域名可以配置多个nginx的外网ip,每次DNS解析请求,轮询返回不同的ip,这样就能实现nginx的水平扩展,这个方法叫“DNS轮询”。
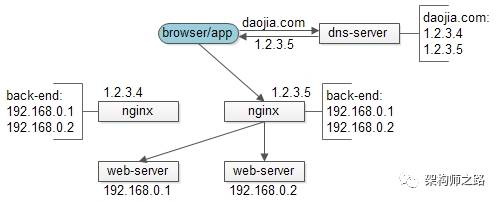
三、web-server负载均衡
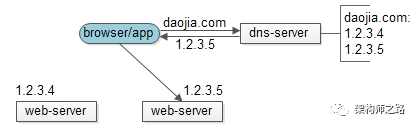
既然“dns轮询”可以将同一个域名的流量均匀分配到不同的nginx,那么也可以利用它来做web-server的负载均衡:
(1)架构中去掉nginx层;
(2)将多个web-server的内网ip直接改为外网ip;
(3)在dns-server将域名对应的外网ip进行轮询解析;
通过DNS来实施负载均衡有什么优缺点呢?
优点:
(1)利用第三方DNS实施,服务端架构不用动;
(2)少了一层网络请求;
不足:
(1)DNS只具备解析功能,不能保证对应外网ip的可用性,而nginx做反向代理时,与web-server之间有保活探测机制,当web-server挂掉时,能够自动迁移流量;
(2)当web-server需要扩容时,通过DNS扩容生效时间长,而nginx是服务端完全自己可控的部分,web-server扩容更实时更方便;
因为上面两个原因,架构上一般都使用高可用反向代理。
总结
架构设计中,除了域名解析,DNS还有其他用武之地:
(1)智能DNS,根据用户ip来就近访问服务器;
(2)DNS轮询,水平扩展反向代理层;
(3)利用DNS实施负载均衡;
用户中心,1亿数据,架构如何设计?
用户中心,几乎是所有互联网公司,必备的子系统。随着数据量不断增加,吞吐量不断增大,用户中心的架构,该如何演进呢。
什么是用户中心业务?
用户中心是一个通用业务,主要提供用户注册、登录、信息查询与修改的服务。
用户中心的数据结构是怎么样的?
用户中心的核心数据结构为:
User(uid, login_name, passwd, sex, age, nickname, …)
其中:
(1)uid为用户ID,为主键;
(2)login_name, passwd, sex 等是用户属性;
其系统架构又是怎么样的呢?
在业务初期,单库单表,配合用户中心微服务,就能满足绝大部分业务需求,其典型的架构为:
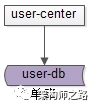
(1)user-center:用户中心服务,对调用者提供友好的RPC接口;
(2)user-db:对用户进行数据存储;
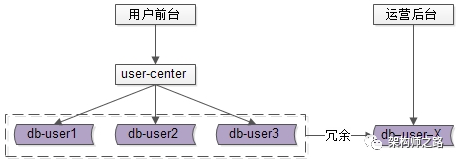
当数据量越来越大,例如达到1亿注册量时,会出现什么问题呢?
随着数据量越来越大,单库无法承载所有的数据,此时需要对数据库进行水平切分。
常见的水平切分算法有“范围法”和“哈希法”。
水平切分,什么是范围法?
范围法,以用户中心的业务主键uid为划分依据,采用区间的方式,将数据水平切分到两个数据库实例上去:
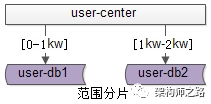
(1)user-db1:存储0到1千万的uid数据;
(2)user-db2:存储1千万到2千万的uid数据;
范围法有什么优点?
(1)切分策略简单,根据uid,按照范围,user-center很快能够定位到数据在哪个库上;
(2)扩容简单,如果容量不够,只要增加user-db3,拓展2千万到3千万的uid即可;
范围法有什么缺点?
(1)uid必须要满足递增的特性;
(2)数据量不均,新增的user-db3,在初期的数据会比较少;
(3)请求量不均,一般来说,新注册的用户活跃度会比较高,故user-db2往往会比user-db1负载要高,导致服务器利用率不平衡;
画外音:数据库层面的负载均衡,既要考虑数据量的均衡,又要考虑负载的均衡。
水平切分,什么是哈希法?
哈希法,也是以用户中心的业务主键uid为划分依据,采用哈希的方式,将数据水平切分到两个数据库实例上去:
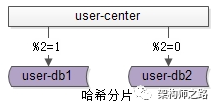
(1)user-db1:存储奇数的uid数据;
(2)user-db2:存储偶数的uid数据;
哈希法有什么优点?
(1)切分策略简单,根据uid,按照hash,user-center很快能够定位到数据在哪个库上;
(2)数据量均衡,只要uid是随机的,数据在各个库上的分布一定是均衡的;
(3)请求量均衡,只要uid是随机的,负载在各个库上的分布一定是均衡的;
画外音:如果采用分布式id生成器,id的生成,一般都是随机的。
哈希法有什么缺点?
(1)扩容麻烦,如果容量不够,要增加一个库,重新hash可能会导致数据迁移;
用户中心架构,实施了水平切分之后,会带来什么新的问题呢?
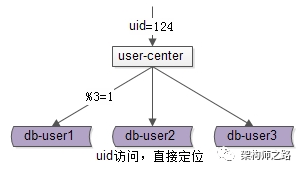
使用uid来进行水平切分之后,对于uid属性上的查询,可以直接路由到库,假设访问uid=124的数据,取模后能够直接定位db-user1:
但对于非uid属性上的查询,就悲剧了,例如login_name属性上的查询:
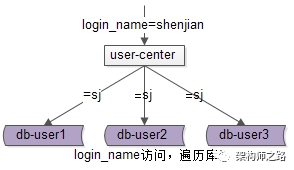
假设访问login_name=shenjian的数据,由于不知道数据落在哪个库上,往往需要遍历所有库,当分库数量多起来,性能会显著降低。
用户中心,非uid属性查询,有哪些业务场景?
任何脱离业务的架构设计都是耍流氓。
在进行架构讨论之前,先来对业务进行简要分析,用户中心非uid属性上,有两类典型的业务需求。
第一大类,用户侧,前台访问,最典型的有两类需求:
(1)用户登录:通过登录名login_name查询用户的实体,1%请求属于这种类型;
(2)用户信息查询:登录之后,通过uid来查询用户的实例,99%请求属这种类型;
用户侧的查询,基本上是单条记录的查询,访问量较大,服务需要高可用,并且对一致性的要求较高。
第二大类,运营侧,后台访问,根据产品、运营需求,访问模式各异,按照年龄、性别、头像、登陆时间、注册时间来进行查询。
运营侧的查询,基本上是批量分页的查询,由于是内部系统,访问量很低,对可用性的要求不高,对一致性的要求也没这么严格。
对于这两类不同的业务需求,应该使用什么样的架构方案来解决呢?
总的来说,针对这两类业务需求,架构设计的核心思路为:
(1)用户侧,采用“建立非uid属性到uid的映射关系”的架构方案;
(2)运营侧,采用“前台与后台分离”的架构方案;
用户侧,如何实施“建立非uid属性到uid的映射关系”呢?
常见的方法有四种:
(1)索引表法;
(2)缓存映射法;
(3)生成uid法;
(4)基因法;
接下来,咱们一一介绍。
什么是,索引表法?
索引表法的思路是:uid能直接定位到库,login_name不能直接定位到库,如果通过login_name能查询到uid,问题便能得到解决。
具体的解决方案如下:
(1)建立一个索引表记录login_name与uid的映射关系;
(2)用login_name来访问时,先通过索引表查询到uid,再通过uid定位相应的库;
(3)索引表属性较少,可以容纳非常多数据,一般不需要分库;
(4)如果数据量过大,可以通过login_name来分库;
索引表法,有什么缺点呢?
数据访问,会增加一次数据库查询,性能会有所下降。
什么是,缓存映射法?
缓存映射法的思路是:访问索引表性能较低,把映射关系放在缓存里,能够提升性能。
具体的解决方案如下:
(1)login_name查询先到cache中查询uid,再根据uid定位数据库;
(2)假设cache miss,扫描所有分库,获取login_name对应的uid,放入cache;
(3)login_name到uid的映射关系不会变化,映射关系一旦放入缓存,不会更改,无需淘汰,缓存命中率超高;
(4)如果数据量过大,可以通过login_name进行cache水平切分;
缓存映射法,有什么缺点呢?
仍然多了一次网络交互,即一次cache查询。
什么是,生成uid法?
生成uid法的思路是:不进行远程查询,由login_name直接得到uid。
具体的解决方案如下:
(1)在用户注册时,设计函数login_name生成uid,uid=f(login_name),按uid分库插入数据;
(2)用login_name来访问时,先通过函数计算出uid,即uid=f(login_name)再来一遍,由uid路由到对应库;
生成uid法,有什么缺点呢?
该函数设计需要非常讲究技巧,且有uid生成冲突风险。
画外音:uid冲突,是业务无法接受的,故生产环境中,一般不使用这个方法。
什么是,基因法?
基因法的思路是:不能用login_name生成uid,但可以从login_name抽取“基因”,融入uid中。
假设分8库,采用uid%8路由,潜台词是,uid的最后3个bit决定这条数据落在哪个库上,这3个bit就是所谓的“基因”。
具体的解决方案如下:
(1)在用户注册时,设计函数login_name生成3bit基因,login_name_gene = f(login_name),如上图粉色部分;
(2)同时,生成61bit的全局唯一id,作为用户的标识,如上图绿色部分;
(3)接着把3bit的login_name_gene也作为uid的一部分,如上图屎黄色部分;
(4)生成64bit的uid,由id和login_name_gene拼装而成,并按照uid分库插入数据;
(5)用login_name来访问时,先通过函数由login_name再次复原3bit基因,login_name_gene = f(login_name),通过login_name_gene%8直接定位到库;
画外音:基因法,有点意思,在分库时经常使用。
用户侧,如何实施“前台与后台分离”的架构方案呢?
前台用户侧,业务需求基本都是单行记录的访问,只要建立非uid属性login_name到uid的映射关系,就能解决问题。
后台运营侧,业务需求各异,基本是批量分页的访问,这类访问计算量较大,返回数据量较大,比较消耗数据库性能。
此时的架构,存在什么问题?
此时,前台业务和后台业务共用一批服务和一个数据库,有可能导致,由于后台的“少数几个请求”的“批量查询”的“低效”访问,导致数据库的cpu偶尔瞬时100%,影响前台正常用户的访问(例如,登录超时)。
画外音:本质上,是系统的耦合。
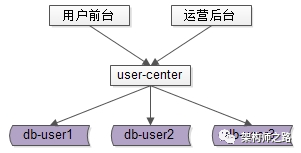
而且,为了满足后台业务各类“奇形怪状”的需求,往往会在数据库上建立各种索引,这些索引占用大量内存,会使得用户侧前台业务uid/login_name上的查询性能与写入性能大幅度降低,处理时间增长。
对于这一类业务,应该采用“前台与后台分离”的架构方案。
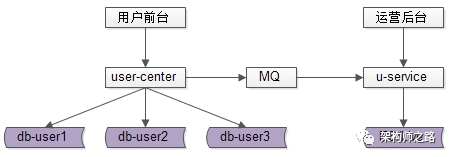
什么是,前台与后台分离的架构方案?
用户侧前台业务需求架构依然不变,产品运营侧后台业务需求则抽取独立的 web / service / db 来支持,解除系统之间的耦合,对于“业务复杂”“并发量低”“无需高可用”“能接受一定延时”的后台业务:
(1)可以去掉service层,在运营后台web层通过dao直接访问db;
(2)不需要反向代理,不需要集群冗余;
(3)不需要访问实时库,可以通过MQ或者线下异步同步数据;
(4)在数据库非常大的情况下,可以使用更契合大量数据允许接受更高延时的“索引外置”或者“HIVE”的设计方案;
总结
用户中心,是典型的“单KEY”类业务,这一类业务,都可以使用上述架构方案。
常见的数据库水平切分方式有两种:
(1)范围法;
(2)哈希法;
水平切分后碰到的问题是:
(1)通过uid属性查询能直接定位到库,通过非uid属性查询不能定位到库;
非uid属性查询,有两类典型的业务:
(1)用户侧,前台访问,单条记录的查询,访问量较大,服务需要高可用,并且对一致性的要求较高;
(2)运营侧,后台访问,根据产品、运营需求,访问模式各异,基本上是批量分页的查询,由于是内部系统,访问量很低,对可用性的要求不高,对一致性的要求也没这么严格;
针对这两类业务,架构设计的思路是:
(1)用户侧,采用“建立非uid属性到uid的映射关系”的架构方案;
(2)运营侧,采用“前台与后台分离”的架构方案;
前台用户侧,“建立非uid属性到uid的映射关系”,有四种常见的实践:
(1)索引表法:数据库中记录login_name与uid的映射关系;
(2)缓存映射法:缓存中记录login_name与uid的映射关系;
(3)生成uid法:login_name生成uid;
(4)基因法:login_name基因融入uid;
后台运营侧,“前台与后台分离”的最佳实践是:
(1)前台、后台系统 web/service/db 分离解耦,避免后台低效查询引发前台查询抖动;
(2)可以采用数据冗余的设计方式;
(3)可以采用“外置索引”(例如ES搜索系统)或者“大数据处理”(例如HIVE)来满足后台变态的查询需求;
任何脱离业务的架构设计都是耍流氓。
不敢相信,技术栈,居然被P站秒了
PornHub的FE,分享了P站前端一些实践,英文比较晦涩难懂,故翻译整理了一下,很多同学对前端技术不是很熟悉,故加入了简单解释,希望对大家理解相关技术有帮助。
提问:能分享一下,P站架构使用了哪些技术栈么?
答,除了大数据体系,都是比较常用的技术栈:
(1)核心架构采用的是Nginx,PHP,MySQL;
(2)使用Memcached和Reids来做缓存;
(3)使用Varnish来做页面缓存加速;
(4)使用ES来解决搜索问题;
(5)服务用的是go;
(6)大数据体系用的Vertica;
画外音:Vertica是一款基于列存储的,支持PB级别结构化数据存储的数据库。
(7)前端NodeJS也有使用;
提问:一个页面至少包含一个视频,一个GIF广告,一些直播视频的预览,一些视频的微缩图,如何监控页面性能,如何找到花时间最长的地方?
答:我们使用第三方RUM(Real User Monitoring)来监控页面性能。
由于我们是国际性的大站,通过RUM监控,能够检测到哪些地域流畅,哪些地域卡顿,哪些地域流量高,哪些地域没有流量。
画外音,页面性能监控,常见的有两种方式:
(1)模拟性能监控
主要通过外部代理,模拟真实用户行为(登陆,点击等),执行固定监控脚本,收集页面性能数据。这是国内主流页面性能监控方式。
(2)真实用户性能监控
在用户真实流量的过程中,加入了一些埋点,收集相关性能数据。这种方式的优缺点都很明显:优点,代表最真实的用户性能体验;缺点,对用户体验有影响。
至于找到页面性能瓶颈,我们使用最常见的页面抓包,看执行时间“瀑布流”。
提问:前端交互对P站来说尤为重要,你们如何看待前端技术的变化?哪些新的WebAPI最吸引你们?
答:我们在前端技术栈上做了很多改进。
CSS层面,从最初的纯CSS,到LESS,再到现在的Grid,用户在观看视频的场景很多,我们必须适应不同的分辨率和屏幕尺寸。
画外音:
LESS(Leaner Style Sheets),是一门向后兼容的CSS扩展语言,它和CSS非常像,并对CSS增加了一些有用的扩展,例如:变量,混合(Mixins),嵌套,函数,作用域,注释等等一些特性。
Grid,是目前最强大的CSS网格布局方案,它将网页划分成一个个网格,可以任意组合不同的网格,做出不同的布局。对跨终端,多屏幕适配尤为有效。
JS层面,我们逐步淘汰了jQuery和jQuery UI,而使用Vanilla JS这款更加高效的JS框架。
画外音:Vanilla JS,世界上最轻量级的JS框架,没有之一。特点是快速、轻量、跨平台,可以用它快速构建JS应用程序。其官方网站是:
http://vanilla-js.com/
别的JS库都需要显示引用地址,例如:
<script src="http://cdn.xo.org/jquery/2.1.4/jquery.min.js">
而Vanilla JS不需要任何引用,在部署引用的时候,只需要:
你没看错,没有任何代码,由于它过于流行,所有的浏览器都必须内置它。
至于新特性,我们非常喜欢IntersectionObserver API,用它可以更有效的动态加载图像。
画外音:IntersectionObserver API提供了一种异步观察目标元素是否进入视口(viewport)的方法,它可以方便的实现,懒加载图片,页面无限下滑,根据滚动到相应区域灵活执行任务或动画等需求。
同时,我们也非常喜欢Picture-in-Picture API,它能方便的在某些页面上播放浮动视频,主要用于获取用户的反馈。
画外音:
(1)画中画,是近几年推出的新特性;
(2)用户在浏览P站视频的时候,真的能腾出手来,进行反馈么?
提问:WebVR技术一直在进步,请问WebVR目前发挥了多大的作用?
答:过去几年,我们一直在研究WebVR。作为全球最大的发布平台,我们需要支持创作者和用户,无论他们想如何创作以及体验我们的内容。
非常自豪的说,我们是第一个支持VR,以及虚拟表演的平台,我们也将持续推进新技术的应用。
画外音:WebVR,顾名思义,Web端的VR技术,百度上说,该技术在电子商务,虚拟社区,虚拟展馆等领域有非常广阔的应用前景。
提问:图片、音频、视频,页面上有多种多媒体内容,你们在PC端和移动端是怎么考虑的?
答:主要受限于操作系统与浏览器。
例如,IOS在全屏模式下就不允许自定义播放器,而强制使用本地的QuickTime,而Android则不存在这个问题。
又例如,HLS,IE和Edge遇到高清HLS流时偶尔会出现卡顿,我们必须防止这种现象出现。
画外音:HLS(HTTP Live Streaming),是苹果的动态码率自适应技术。
提问:你们支持哪些浏览器?还会支持IE么?
答:我们一直支持IE,但最近我们决定放弃支持IE11之前的IE版本(兼容性太难搞了),言下之意,我们会放弃对Flash视频播放的支持。我们将专注于Chrome,Firefox和Safari的支持。
提问:你们的播放器,除了播放相对可控的视频资源,你们还引入了很多第三方的广告,在开发的过程中,你们是如何模拟这些动态脚本的加载的?
答:播放器分为两个部分:
(1)基本播放核心功能实现,它是相对独立的;
(2)第三方脚本与广告加载,我们会尽早的集成,以便尽早发现问题,我们与第三方合作,手动触发相关事件;
提问:站在技术的角度展望未来,有没有哪些技术是希望改进的?
答:那就多了去了:
(1)Beacon:在IOS上存在pageHide 事件无正常工作的问题,希望改进;
(2)Fetch:没有下载进度,也没有提供拦截请求的方法,很不爽;
(3)WebRTC:如果分辨率不够大,则即使进行屏幕共享,Simulcast 层也会受到限制;
(4)Service Workers:调用navigator.serviceWorker.register 不会被任何 Service Workers 的 Fetch 事件处理程序拦截;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号