综合设计——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 组名 | 从你的全世界爬过 团队logo:  |
| 项目简介 | 项目名称:博物识植 项目logo:  项目介绍:在探索自然奥秘的旅途中,我们常与动植物相伴而行,却无法准确识别它们,更难以深入了解他们的特征。为了更好地理解和欣赏自然界的多样性,提升我们对动植物的认识和保护意识,我们需要一个智能系统。该系统能够根据用户拍摄的动植物照片,智能识别并匹配相应的信息,同时为用户提供丰富的学习资源,帮助人们更深入地了解和学习动植物知识。通过这样的方式,我们不仅能够更准确地识别和欣赏周围的生命,还能够在日常生活中,随时随地增长见识,体验探索自然的乐趣。 项目背景:人类的生活离不开动植物的支持,动植物的多样性是一切地球生物的依赖。在生活中随处可见很多动植物,动植物是人类生活必不可少的一部分。 保护大自然保护动植物就是在保护人类自己。在保护动植物的过程中,首先要解决的是动植物识别的问题。 项目意义:提供了一种我们与自然界互动的方式。其应用场景广泛,渗透到了教育、旅游等多个领域。在学校,它可以是生物课程的辅助工具,通过实践学习生物多样性;在旅游行业,它可以帮助游客更好地了解他们所参观的自然景观,提升旅行体验 |
| 团队成员学号 | 042201401陈高菲、102202107王勤琛、102202108王露洁、102202115孙佳会、102202123张铭心、102202130林烨、102202138徐婉瑜、102202140郭心怡 |
| 项目目标 | 本系统旨在实现以下功能: a.图片识别功能:用户上传动植物图片,系统通过图像识别技术自动识别物种,返回准确的物种名称。 b.物种详细信息:识别后,用户将获取该物种的详细信息,包括外形特点、生长环境、分布区域等相关数据。 c.物种图片展示:系统将提供该物种的高质量图片,帮助用户更直观地了解物种特征。 d.名称搜索功能:用户可以手动输入动植物的名称,系统将返回该物种的相关信息,方便快速查询。 e.网站部署上线:通过华为云的弹性计算服务部署网站,确保系统高可用和稳定运行,实现网站上线。 |
| 其他参考文献 | 1.yanjingang/pigimgclassification: 图像分类 2.基于改进SE-MnasNet骨干网络YOLOv5的动植物树木识别系统_开源 树木识别 |
| gitee链接 | 2024学年数据采集与融合技术大作业——博物识植 团队:从你的全世界爬过 |
一、系统总体技术概述
1.1 系统架构概述
系统分为前端、后端、数据库、AI接口、爬虫模块、部署等多个层级。前后端之间通过RESTful API进行通信。具体分为以下几个部分:
- 前端:使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。用户可以上传文本、图片等文件。
- 后端:使用Python语言和Flask框架实现,处理图像识别、查询请求、调用AI接口和爬虫数据存储等业务逻辑。
- 数据库:存储动植物物种的详细信息,包括图像、分布、特点等。存储物种识别的历史记录信息。
- 图像识别与AI接口:利用图像识别模型或调用第三方AI服务(如百度AI、Google Vision等)识别图片并返回结果。
- 爬虫:提前爬取动植物相关网站数据,补充物种数据库。使用Selenium框架进行实时图片爬取。
- 部署平台:使用华为云平台部署系统,保证系统的高可用和稳定性。
1.2 各模块技术实现
1.2.1 图像识别模块
- 目标:用户上传图片,系统通过图像识别技术返回物种名称。
- 技术方案:
使用深度学习模型:基于改进SE-MnasNet骨干网络YOLOv5和卷积神经网络cnn opencv进行图像分类和识别。
基于识别精确度的考虑调用第三方云服务百度智能云的动植物识别API提供快速而准确的图像识别。 - 流程:
用户上传图片,前端将图片通过API发送至后端。
后端调用模型或AI图像识别API分析图片,获取可能的物种标签。
后端将物种名称返回给前端,前端展示识别结果。
1.2.2 物种信息查询功能
- 目标:根据识别后的物种名称或用户输入的名称,返回该物种的详细信息。
- 技术方案:
利用selenium技术和scrapy框架爬取信息网站所有物种信息(如外形特点生长环境、分布区域等)存储在csv表导入数据库并定期更新。
利用查询语句在数据库中进行查找并返回详细信息。
若数据库中没有相关信息,则调用百度智能云的千帆大模型识别物种名称,查询物种相关信息。 - 流程:
后端识别出物种名称时,系统首先查询数据库,若没有该物种的信息,再调用AI接口获取。
1.2.3 相似图片展示
- 目标:根据用户上传的图片,返回物种的相似图片,帮助用户直观了解物种。
- 技术方案:
运用selenium爬虫技术实时爬取百度识图返回的相似图片 - 流程:
后端接收前端传入的图片后,将图片作为输入文件传入百度识图网站实时爬取相似图片,在系统返回物种详细信息时,将图片URL一并返回。
1.2.4 保存历史记录
- 目标:将用户的历史搜索记录保存至数据库,方便用户在“我的图鉴”页面查看并跳转至物种详情页,随时查看过去的搜索记录。
- 技术方案:
创建一个数据库表专门用来保存用户的搜索记录,包括用户上传的图片、识别出来的物种名称、物种的详细信息(如描述、分布、图片URL等) - 流程:
当用户获取识别结果时,后端系统会将物种信息保存至数据库中。在点击我的图鉴中的物种名称时,后端调取数据库信息展示在前端界面。
1.2.5 部署与部署架构
- 目标:将整个系统部署到华为云服务器上,让非本地用户可以访问。
- 技术方案:
使用华为云ECS(Elastic Cloud Server)部署后端服务。
使用华为云OBS 存储图片等静态资源。
使用RDS(Relational Database Service)存储物种信息数据库。
前端可以使用 Nginx 进行负载均衡和反向代理 - 流程:
前后端文件上传部署完成后即可实现非本地用户的访问。
1.3 源码运行步骤
- gitee仓库下载源码
- 启动文件中的ai.py与database.py文件
- 运行index.html文件
(!注意在本地主机运行代码时请更换代码中的路径名)
二、个人分工及具体实现
在本次团队实践中,我主要负责深度学习模型cnn的训练及千帆大模型接口的调用
2.1CNN识别模型训练
- 以下是部分代码展示
def load_and_preprocess_image(img_path):
img = image.load_img(img_path, target_size=(32, 32)) # 根据模型输入调整大小
img_array = image.img_to_array(img) # 转换为数组
img_array = img_array.astype('float32') / 255.0 # 归一化到 [0, 1] 之间
img_array = np.expand_dims(img_array, axis=0) # 增加一维,生成批量形状
return img_array
# (1)Prepare the Data
def load_data():
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# One-hot encoding for labels
num_classes = 10
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
return (x_train, y_train), (x_test, y_test)
# (2)Define the Model
class ConvBNReLU(layers.Layer):
def __init__(self, out_channel, kernel_size=3, strides=1, **kwargs):
super(ConvBNReLU, self).__init__(**kwargs)
self.conv = layers.Conv2D(filters=out_channel,
kernel_size=kernel_size,
strides=strides,
padding='SAME',
use_bias=False,
name='Conv2d')
self.bn = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='BatchNorm')
self.activation = layers.ReLU(max_value=6.0) # ReLU6
def call(self, inputs, training=False, **kargs):
x = self.conv(inputs)
x = self.bn(x, training=training)
x = self.activation(x)
return x
class InvertedResidualBlock(layers.Layer):
def __init__(self, in_channel, out_channel, strides, expand_ratio, **kwargs):
super(InvertedResidualBlock, self).__init__(**kwargs)
self.hidden_channel = in_channel * expand_ratio
self.use_shortcut = (strides == 1) and (in_channel == out_channel)
layer_list = []
# first bottleneck does not need 1*1 conv
if expand_ratio != 1:
# 1x1 pointwise conv
layer_list.append(ConvBNReLU(out_channel=self.hidden_channel, kernel_size=1, name='expand'))
layer_list.extend([
# 3x3 depthwise conv
layers.DepthwiseConv2D(kernel_size=3, padding='SAME', strides=strides, use_bias=False, name='depthwise'),
layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='depthwise_BatchNorm'),
layers.ReLU(max_value=6.0),
#1x1 pointwise conv(linear)
layers.Conv2D(filters=out_channel, kernel_size=1, strides=1, padding='SAME', use_bias=False, name='project'),
layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='project_BatchNorm')
])
self.main_branch = Sequential(layer_list, name='expanded_conv')
def call(self, inputs, **kargs):
if self.use_shortcut:
return inputs + self.main_branch(inputs)
else:
return self.main_branch(inputs)
class MobileNetV1(Model): # 自定义模型
def __init__(self, num_classes):
super(MobileNetV1, self).__init__()
self.model = Sequential([
ConvBNReLU(32, kernel_size=3, strides=2),
InvertedResidualBlock(32, 64, strides=1, expand_ratio=6),
InvertedResidualBlock(64, 128, strides=2, expand_ratio=6),
InvertedResidualBlock(128, 128, strides=1, expand_ratio=6),
InvertedResidualBlock(128, 256, strides=2, expand_ratio=6),
InvertedResidualBlock(256, 256, strides=1, expand_ratio=6),
InvertedResidualBlock(256, 512, strides=2, expand_ratio=6),
*[InvertedResidualBlock(512, 512, strides=1, expand_ratio=6) for _ in range(5)],
InvertedResidualBlock(512, 1024, strides=2, expand_ratio=6),
InvertedResidualBlock(1024, 1024, strides=1, expand_ratio=6),
layers.GlobalAveragePooling2D(),
layers.Dense(num_classes, activation='softmax')
])
def call(self, inputs):
return self.model(inputs)
def main():
(x_train, y_train), (x_test, y_test) = load_data()
model = MobileNetV1(num_classes=10)
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
Evaluate the Model
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'Test accuracy: {test_acc:.4f}')
# 加载并预测新图片
img_path = './5.jpg' # 替换为您的图片路径
img = load_and_preprocess_image(img_path)
# 进行预测
predictions = model.predict(img)
predicted_class_index = np.argmax(predictions, axis=1)[0]
predicted_class_name = class_names[predicted_class_index]
print(f'Predicted class (index): {predicted_class_index}')
print(f'Predicted class (name): {predicted_class_name}')
if __name__ == "__main__":
main()
- 事实上,使用深度学习模型进行图像识别的效果非常差,简直令人发笑。
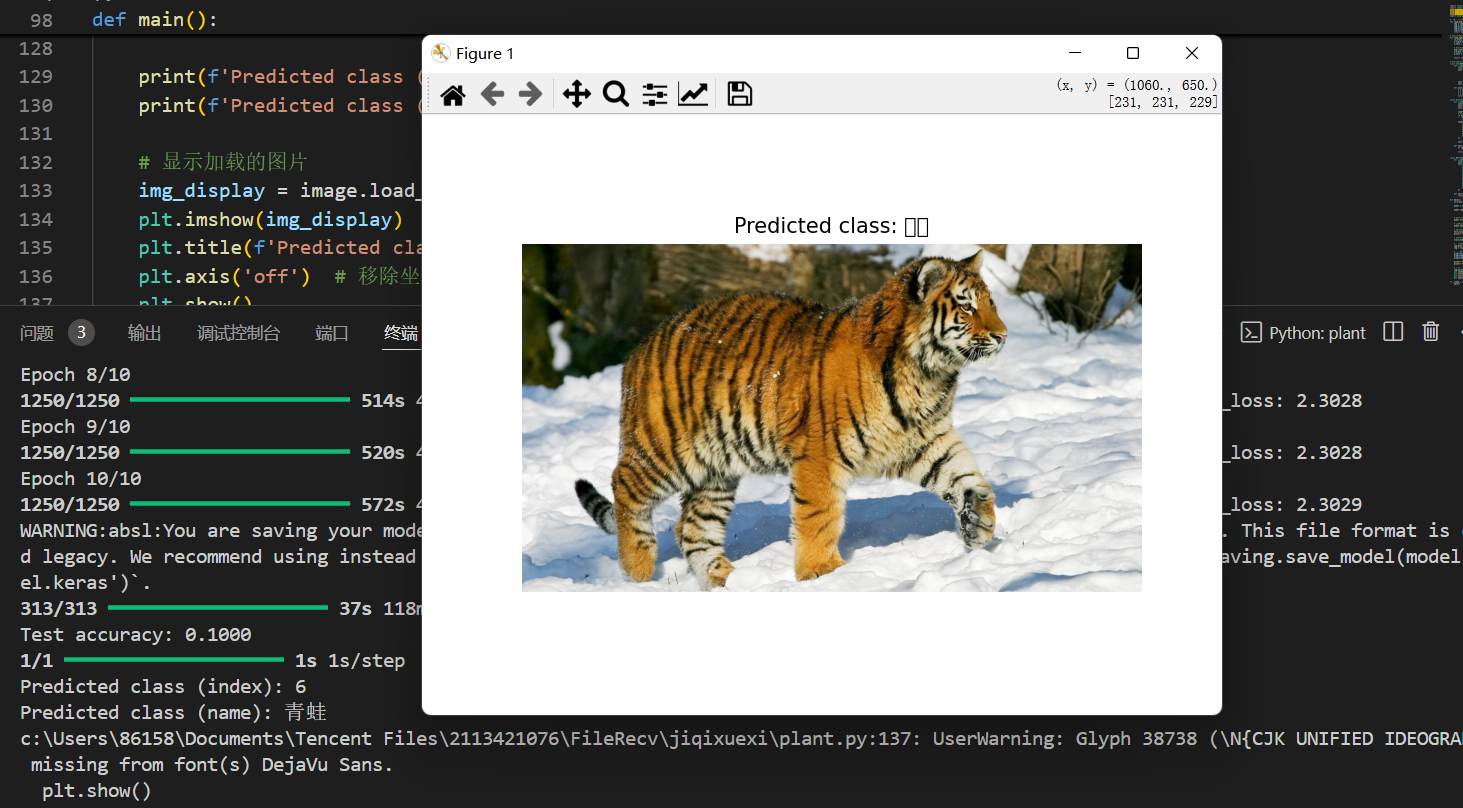
- 用算法模型实现物种识别要提高精确度比较困难,经讨论后我们决定使用大模型接口进行识别。
2.1千帆大模型调用 - 在百度智能云的千帆大模型创建应用获取APIkey
- 在编写代码时遇上了一些问题,求助组长之后得到了解决,感谢组长(偷偷拍下组长马屁,我们组长太厉害啦!)。以下是组长经指正后成功运行的代码。
import requests
import json
import datetime
class QIANFAN:
_api_url = "https://aip.baidubce.com"
def __init__(self, api_key, secret_key):
self.API_KEY = ' '
self.SECRET_KEY = ' '
url = self._api_url + "/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": self.API_KEY, "client_secret": self.SECRET_KEY}
result = self.http_request_v2(url, method="POST", params=params)
if 'access_token' in result:
self.access_token = result["access_token"]
else:
print(result)
exit()
def chat(self, model="ernie-lite-8k", message=None, **kwargs):
url = f"{self._api_url}/rpc/2.0/ai_custom1/wenxinworkshopat/{model}?access_token={self.access_token}"
payload = json.dumps({
"messages": [{"role": "user", "content": message}],
"temperature": 0.95,
"penalty_score": 1
})
for key, value in kwargs.items():
payload[key] = value
print(payload)
response = self.http_request_v2(url, method="POST", params=payload)
return response
# 生成headers头
def headers(self, params=None):
headers = {}
headers['Content-Type'] = 'application/json'
return headers
def http_request_v2(self, url, method="GET", headers={}, params=None):
headers['User-Agent'] = 'Mozilla/5.0 \(Windows NT 6.1; WOW64\) AppleWebKit/537.36 \(KHTML, like Gecko\) Chrome/39.0.2171.71 Safari/537.36'
if method == "GET":
response = requests.get(url)
elif method == "POST":
# data = bytes(json.dumps(params), 'utf-8')
response = requests.post(url, data= params)
elif method == "DELETE":
response = requests.delete(url, data= data)
result = response.json()
return result
# 示例用法
API_KEY = 'ohkUn0XAJnynNC5OjEZN6EUs'
SECRET_KEY = '0EusjiaxuY6Z6Q40z4Q7LBD7IrgpQlPb'
chat_client = QIANFAN(API_KEY, SECRET_KEY)
print(vars(chat_client))
result = chat_client.chat(model='ernie_speed', message="请详细说明一下榕树这个植物")
print(result["result"])
三、心得体会
小组作业过程中,我深刻体会到了团队合作、技术实现和实际应用之间的紧密联系。我的任务主要分为两个部分:图像识别算法的实现和一个AI接口的接入。我负责了图像识别算法的部分,虽然我的模型最终没有应用到网站搭建之中,通过这个过程,我不仅增强了自己在计算机视觉和机器学习领域的技能,也对如何将复杂的技术转化为实际可用的功能有了更深的理解。同时我也熟悉了如何去使用大语言模型接口实现需求,感受到了AI大模型的强大功能和可用性。最后,真的很佩服我的队友们!向你们看齐!

