数据采集与融合技术作业4
作业①:
1)使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
代码解析
class Stock:
def getStockData(self):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=chrome_options)
driver.get("http://quote.eastmoney.com/center/gridlist.html#sz_a_board")
# Use the correct way to find elements in Selenium 4
trs = driver.find_elements(By.XPATH, '//tbody/tr') # Updated line
stocks = []
for tr in trs:
tds = tr.find_elements(By.XPATH, './td') # Updated line
td = [x.text for x in tds]
stocks.append(td)
stockInfo = []
for stock in stocks:
stockInfo.append((stock[0], stock[1], stock[2], stock[4], stock[5], stock[6], stock[7], stock[8], stock[9],
stock[10], stock[11], stock[12],stock[13]))
driver.quit() # Close the browser after data extraction
return stockInfo
- 启动一个无头的Chrome浏览器并访问指定的股票数据网页。
- 使用Selenium抓取网页中每一行股票数据。
- 提取特定的列并将其整理成元组。
- 最终返回一个包含所有股票信息的列表。
输出结果



Gitee文件夹链接
2)心得体会
- Selenium 强大的自动化能力不仅仅适用于网页抓取,也可以应用于自动化测试,这让我对自动化工具的应用有了更深的理解。
作业②
1)使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
代码解析
def login():
chromedriver_autoinstaller.install()
driver = webdriver.Chrome()
driver.get("https://www.icourse163.org")
# 等待页面加载完成,等待"登录"按钮或其他固定元素出现
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.LINK_TEXT, "登录"))
)
# 确保页面上存在"登录"按钮,尝试点击
try:
login_button = driver.find_element(By.LINK_TEXT, "登录")
login_button.click()
except Exception as e:
print("未找到登录按钮:", e)
# 等待登录页面加载
time.sleep(2)
# 输入账号和密码
username_input = driver.find_element(By.NAME, " ")
password_input = driver.find_element(By.NAME, " ")
username_input.send_keys(" ") #
password_input.send_keys(" ") #
# 点击登录
password_input.send_keys(Keys.RETURN)
time.sleep(5) # 等待登录完成
# 处理弹窗(同意按钮)
try:
agree_button = WebDriverWait(driver, 5).until(
EC.element_to_be_clickable((By.XPATH, "//button[contains(text(), '同意')]"))
)
agree_button.click()
time.sleep(2)
except Exception as e:
print("未发现同意弹窗,跳过该步骤。")
return driver
- 使用 Selenium 模拟登录到中国 MOOC 网站。
- 采用了显性等待(WebDriverWait)来处理元素加载
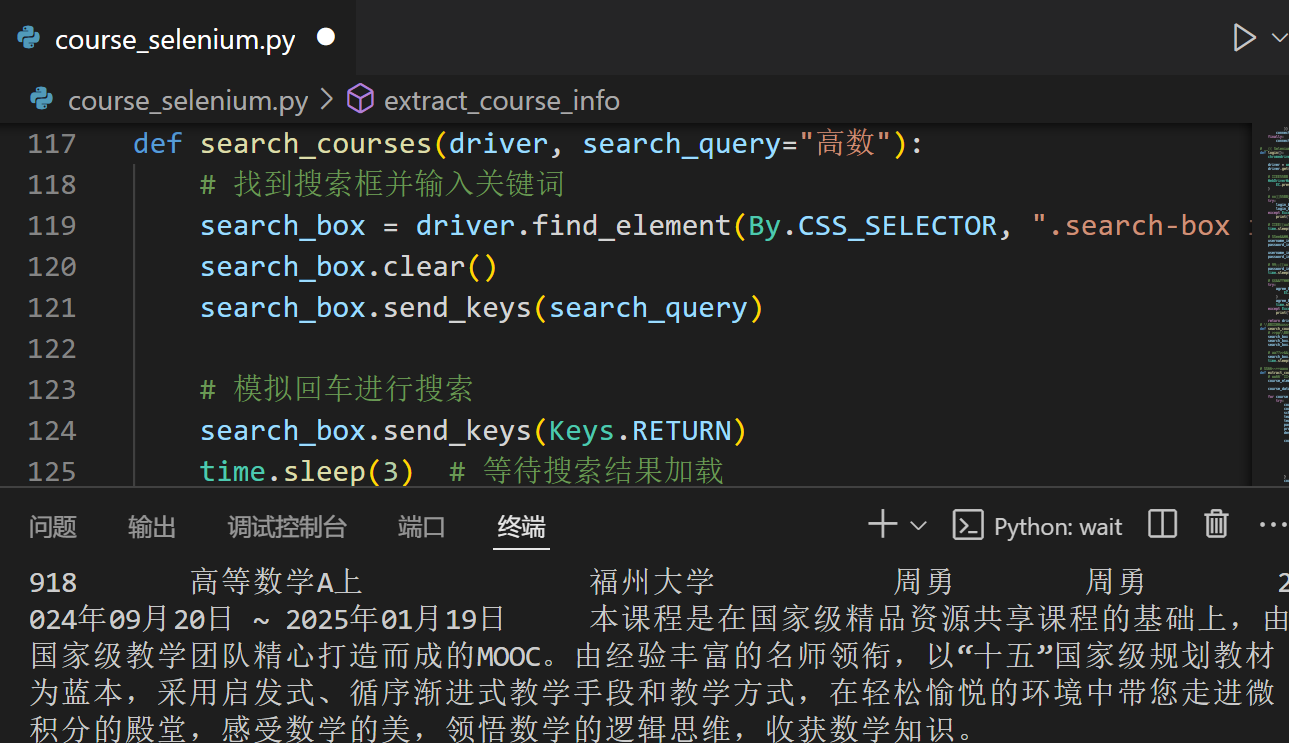
def extract_course_info(driver):
# 获取所有课程的元素
course_elements = driver.find_elements(By.CSS_SELECTOR, ".course-card-container .course-card")
course_data = []
for course in course_elements:
try:
course_id = course.get_attribute("data-id") # 课程 ID
course_name = course.find_element(By.CSS_SELECTOR, ".course-card-name").text # 课程名称
school_name = course.find_element(By.CSS_SELECTOR, ".course-card-school").text # 学校名称
teacher_name = course.find_element(By.CSS_SELECTOR, ".course-card-teacher").text # 主讲教师
team_members = course.find_element(By.CSS_SELECTOR, ".course-card-team").text # 团队成员
participants = course.find_element(By.CSS_SELECTOR, ".course-card-participants").text # 参加人数
progress = course.find_element(By.CSS_SELECTOR, ".course-card-progress").text # 课程进度
description = course.find_element(By.CSS_SELECTOR, ".course-card-description").text # 课程简介
course_info = {
"课程号": course_id,
"课程名称": course_name,
"学校名称": school_name,
"主讲教师": teacher_name,
"团队成员": team_members,
"参加人数": participants,
"课程进度": progress,
"课程简介": description
}
course_data.append(course_info)
except Exception as e:
print(f"Error extracting data for one course: {e}")
return course_data
- 获取所有课程模块,遍历每个课程提取信息,如课程名、学校、教师等
输出结果

Gitee文件夹链接
2)心得体会
- Selenium 提供了一套强大而灵活的 API,使得我能够模拟真实用户的浏览行为,执行一系列操作,避免了不必要的图形界面加载,提高了抓取效率。
作业③:
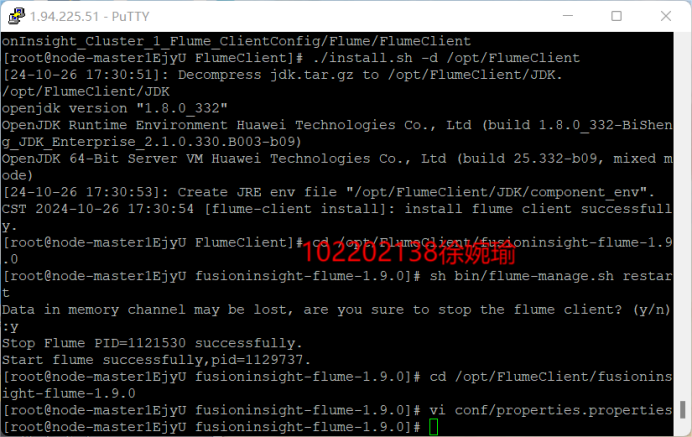
1)完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务
-
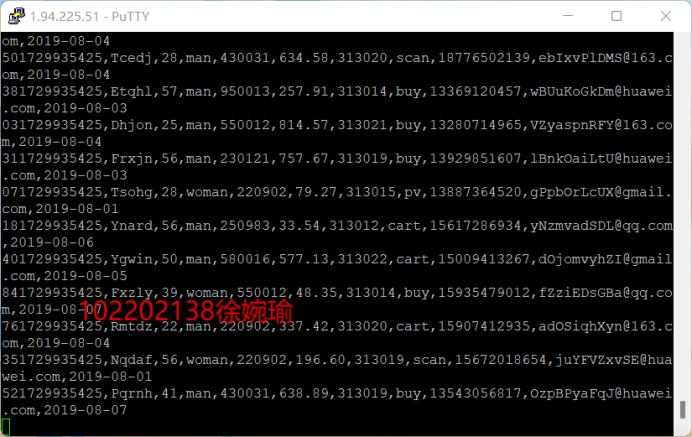
Python脚本生成测试数据
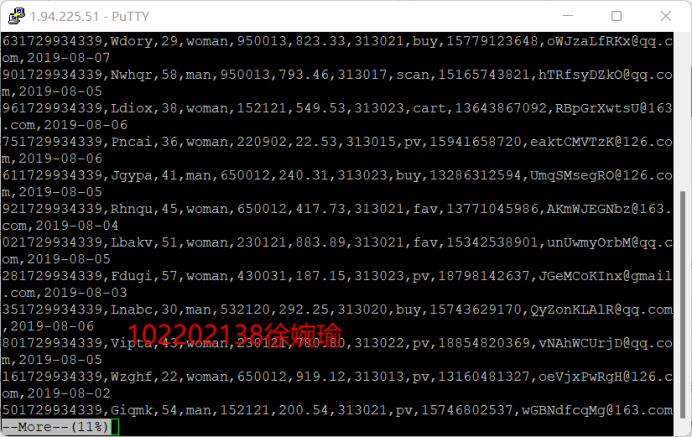
-
配置Kafka
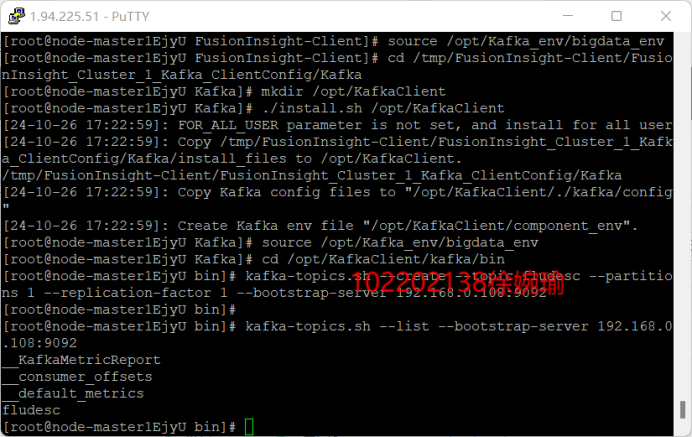
-
安装Flume客户端
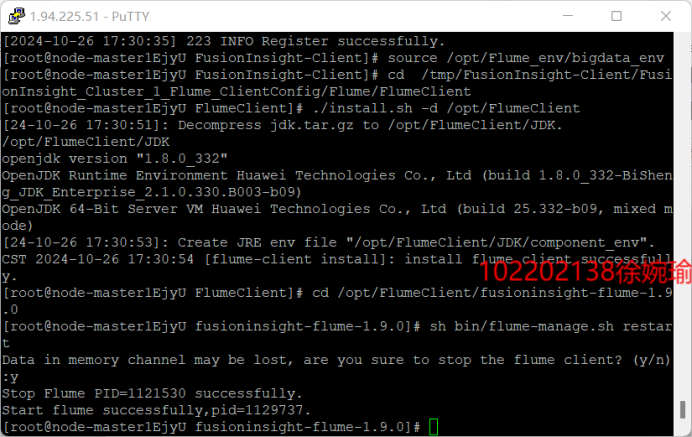
-
配置Flume采集数据