作业①
a、主要代码展示和分析
这个类负责从指定的 URL 抓取天气预报数据并将其插入到数据库中
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode={"深圳":"101280601"}
- init: 初始化HTTP请求头(模拟浏览器行为),并定义一个城市代码字典,将城市名称映射到其相应的天气代码(此处仅包含深圳)。
def forecastCity(self,city):
if city not in self.cityCode.keys():
print(city+" code cannot be found")
return
url="http://www.weather.com.cn/weather/"+self.cityCode[city]+".shtml"
try:
req=urllib.request.Request(url,headers=self.headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
lis=soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date=li.select('h1')[0].text
weather=li.select('p[class="wea"]')[0].text
temp=li.select('p[class="tem"] span')[0].text+"/"+li.select('p[class="tem"] i')[0].text
print(city,date,weather,temp)
self.db.insert(city,date,weather,temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
- forecastCity: 获取指定城市的天气数据:
- 检查城市是否在代码字典中。
- 构建天气网站的URL并发起请求。
- 使用UnicodeDammit处理返回的数据,确保其正确解码。
- 使用BeautifulSoup解析HTML,提取天气信息(日期、天气状况、温度)。
- 将提取到的天气数据插入到数据库中。
- 在过程中捕获可能发生的异常并打印错误信息。
这个类负责创建,数据等数据库操作数据库
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
- openDB: 连接到SQLite数据库,如果表不存在则创建一个名为weathers的表。如果表已存在,则清空表中的数据(delete from weathers)。
- closeDB: 提交数据库事务并关闭连接。
def insert(self,city,date,weather,temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)" ,(city,date,weather,temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows=self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city","date","weather","temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0],row[1],row[2],row[3]))
- insert: 向weathers表中插入一条新的天气记录。如果插入失败,捕获异常并打印错误信息。
- show: 从weathers表中选择所有记录并格式化输出。
b、输出信息
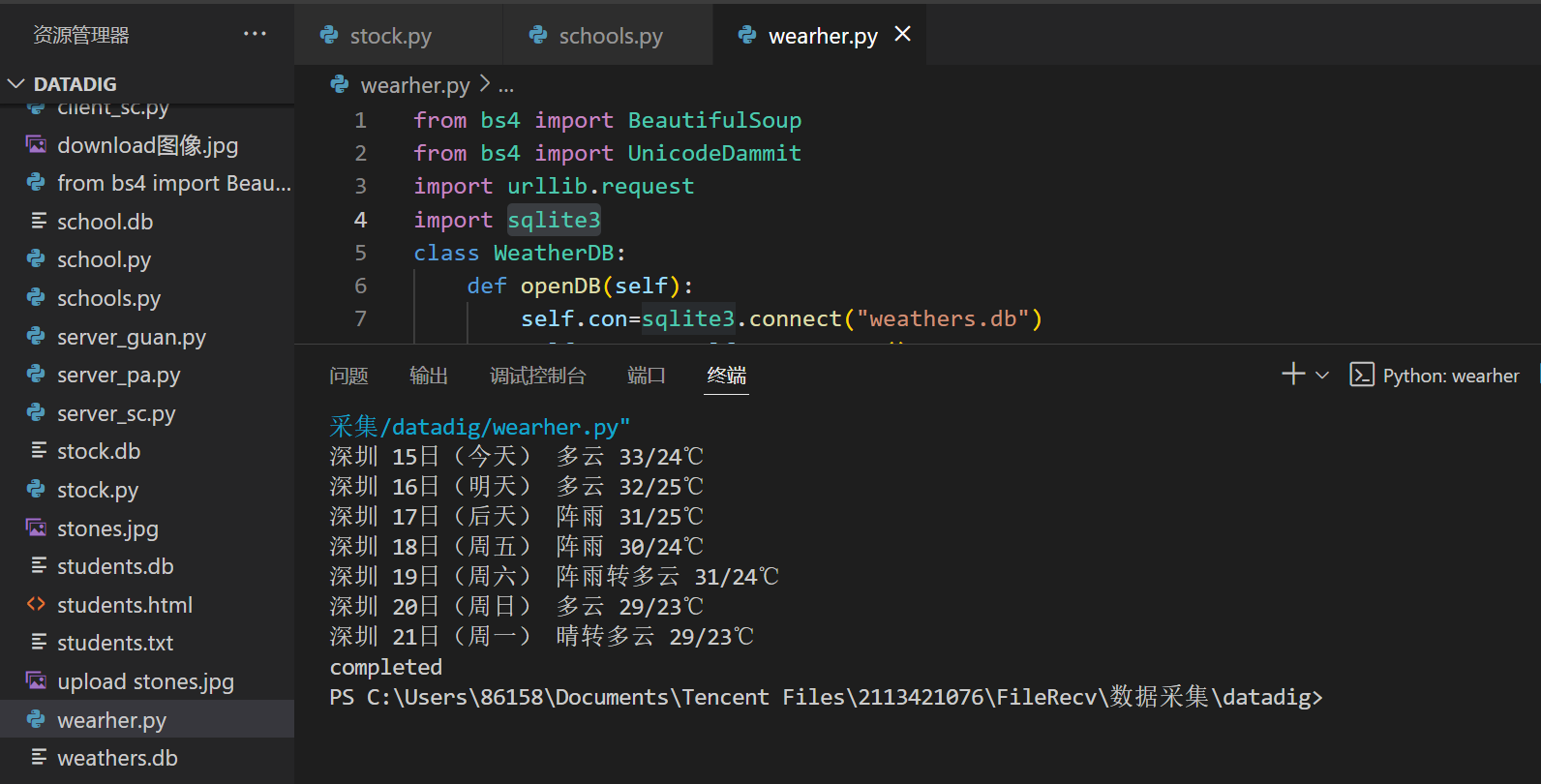
2)心得体会
- 代码结构: 代码逻辑清晰,将数据库操作和数据抓取分开,使得代码易于维护。面向对象的设计使得每个类的职责明确。
- 异常处理: 通过 try...except 块处理异常,增强了程序的健壮性,避免因某个步骤失败导致整个程序崩溃。
作业②
a、主要代码展示和分析
这个类负责从指定的 URL 抓取股票数据并将其插入到数据库中。
class StockGet:
def __init__(self):
self.loginheaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36',
}
def GetStock(self):
url="http://6.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408105779319969169_1634089326282&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1634089326289"
data = getHTMLText(url, self.loginheaders)
td1 = re.findall(r'"f14":(.*?),', data)
# 代码
td2 = re.findall(r'"f12":(.*?),', data)
# 最新报价
td3 = re.findall(r'"f2":(.*?),', data)
- init 方法:定义请求头以模拟浏览器访问,提高请求的成功率。
- GetStock 方法:通过 getHTMLText 函数获取数据,使用正则表达式提取所需的股票信息(如名称、代码、价格等)。
- 数据抓取函数 getHTMLText,使用 requests 库发送 GET 请求,获取网页内容。通过设置超时和编码来确保请求的可靠性。
将提取到的数据插入到 stockDB 的数据库中,并调用 show 方法显示结果。
这个类负责数据库的连接和操作,包括打开、关闭数据库,插入数据,以及展示数据库中的内容
class stockDB:
# 打开数据库的方法
def openDB(self):
self.con = sqlite3.connect("stock.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table equity (sID varchar(16),sName varchar(64),sPrice varchar(16),sRFExtent varchar(16),sRFQuota varchar(16),sNum varchar(16),sQuota varchar(16),sExtent varchar(16),sHigh varchar(16),sLow varchar(16),sToday varchar(16),sYesterday varchar(16),constraint pk_stock primary key (sID,sName))")
except:
self.cursor.execute("delete from equity")
# 关闭数据库的方法
def closeDB(self):
self.con.commit()
self.con.close()
# 插入数据的方法
def insert(self, ID, name, price, RFextent, RFquota, num, quota, extent, high, low, today, yesterday):
try:
self.cursor.execute(
"insert into equity (sID,sName,sPrice,sRFExtent,sRFQuota,sNum,sQuota,sExtent,sHigh,sLow,sToday,sYesterday) values (?,?,?,?,?,?,?,?,?,?,?,?)",
(ID, name, price, RFextent, RFquota, num, quota, extent, high, low, today, yesterday))
except Exception as err:
print(err)
# 打印数据库内容的方法
def show(self):
self.cursor.execute("select * from equity")
rows = self.cursor.fetchall()
print(
"{:^10}\t{:^8}\t{:^10}\t{:^20}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t".format(
"序号", "代码", "名称", "最新价(元)", "涨跌幅(%)", "跌涨额(元)", "成交量", "成交额(元)", "振幅(%)", "最高", "最低", "今开", "昨收"))
i = 1
for row in rows:
print("{:^10}\t{:^8}\t{:^10}\t{:^20}\t{:^10}\t{:^18}\t{:^16}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t".format(i, row[0],row[1],row[2],row[3],row[4],row[5],row[6],row[7],row[8],row[9],row[10],row[11],))
i += 1
- openDB 方法:尝试连接 SQLite 数据库并创建一个名为 equity 的表。如果表已经存在,则删除其中的所有记录;使用 try...except 块来处理表创建的异常,这样在表已存在的情况下不会中断程序。
- closeDB 方法:
提交任何未保存的更改并关闭数据库连接。
- insert 方法:插入一条股票记录。使用 try...except 块捕捉可能的异常,确保代码的健壮性。
- show 方法:从数据库中查询所有记录并打印。格式化输出使得结果在控制台上看起来整齐。
b、输出信息
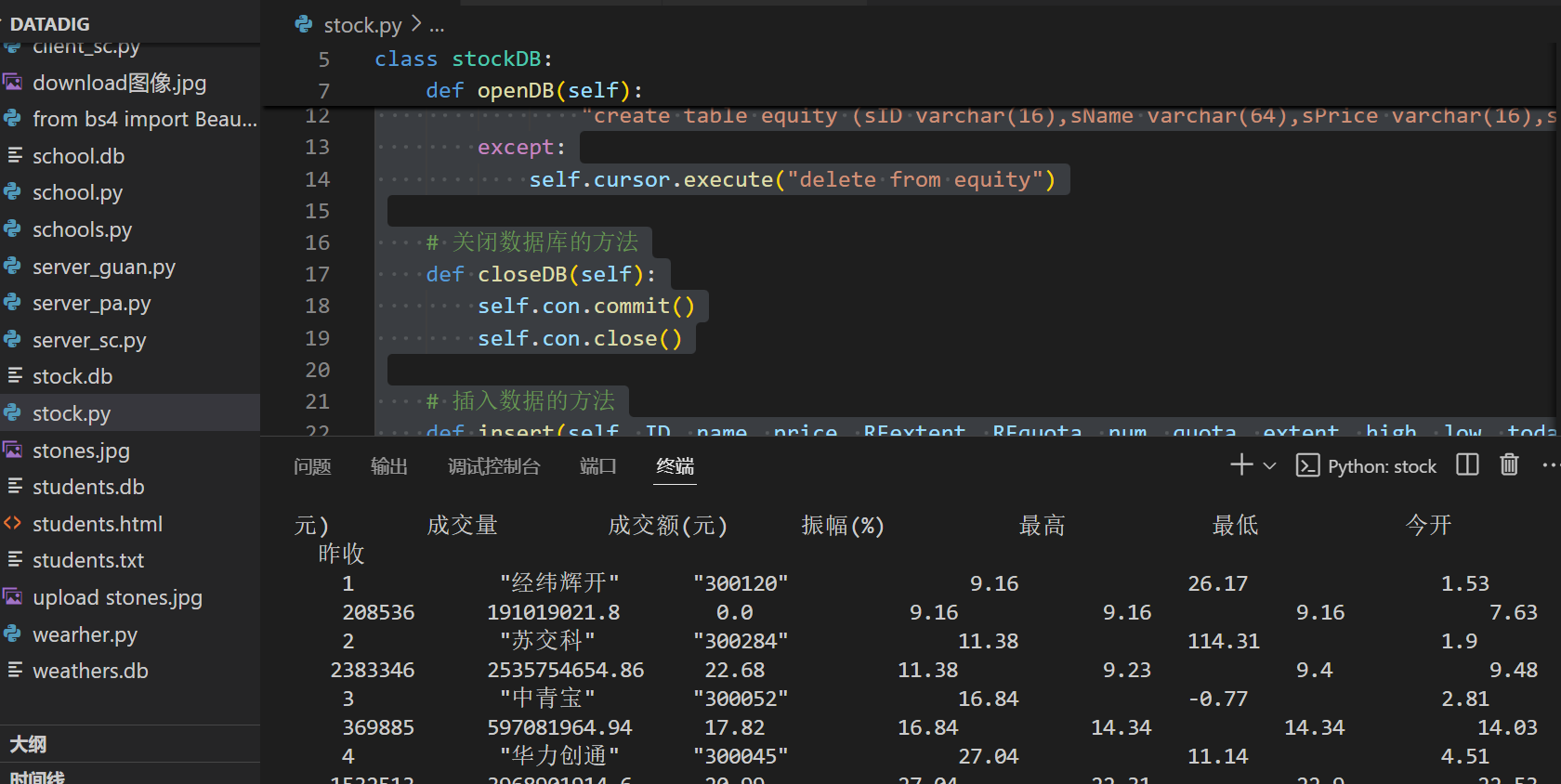
2)心得体会
- 正则表达式在数据提取方面非常有效,但过度使用可能会导致代码可读性降低。可以考虑使用 JSON 解析库(如 json 模块)直接处理 API 返回的数据,这样可以简化代码并提高可读性。
- 数据库表的设计较为简单,适用于小型项目。对于大规模数据,可能需要考虑更复杂的表设计和索引策略。
作业③
1)爬取中国大学 2020主榜所有院校信息,并存储在数据库中
a、主要代码展示和分析
该函数从获取的JSON数据中提取前 num 名大学的信息,并将这些信息存储到 ulist 列表中,同时格式化输出这些大学的排名信息
def printUnivList(ulist, html, num):
'''提取 html 网页内容中 前 num 名大学信息到 ulist列表中 '''
data = json.loads(html) # 对数据进行解码
# 提取 数据 rankings 包含的内容
content = data['data']['rankings']
# 把 学校的相关信息放到 ulist 里面
for i in range(num):
index = content[i]['rankOverall']
name = content[i]['univNameCn']
score = content[i]['score']
category = content[i]['univCategory']
province = content[i]['province'] # 提取省份信息
ulist.append([index, name, score, category, province])
# 打印前 num 名的大学
tplt = "{0:^10}\t{1:^10}\t{2:^10}\t{3:^10}\t{4:^10}" # 更新格式,而不使用{3}
print(tplt.format("排名 ", "学校名称", "总分", "类型", "省份")) # 更新这里,保持一致
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4])) # 直接传入值
- 使用了 json.loads 对网页的返回内容进行JSON解码,这意味着该网页返回的数据是一个JSON格式的结构。
- 从 data['data']['rankings'] 提取大学的具体排名信息,包含排名、学校名称、得分、类别(如综合类、理工类等)以及所在省份。
- 使用 tplt 定义了表格的输出格式,确保打印的大学信息整齐对齐。使用了 center(^) 方式格式化输出。
该函数 将提取到的大学信息存储到SQLite数据库中
def save_to_db(ulist):
'''将大学信息存储到SQLite数据库'''
conn = sqlite3.connect('school.db')
cursor = conn.cursor()
# 创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS university_rankings (
rank INTEGER,
name TEXT,
score REAL,
category TEXT,
province TEXT -- 新增省份列
)
''')
# 插入数据
cursor.executemany('''
INSERT INTO university_rankings (rank, name, score, category, province)
VALUES (?, ?, ?, ?, ?)
''', ulist)
conn.commit() # 提交事务
conn.close() # 关闭连接
- 首先使用 sqlite3.connect() 连接到本地的 school.db 数据库文件,如果该文件不存在,会自动创建。
- 使用 CREATE TABLE IF NOT EXISTS 创建一个名为 university_rankings 的表,这个表包含了排名、学校名称、得分、类别和省份信息。
- executemany() 方法批量插入大学信息, ? 占位符用于防止SQL注入风险。
- 在插入数据后,调用 commit() 提交事务,然后关闭数据库连接。
b、输出信息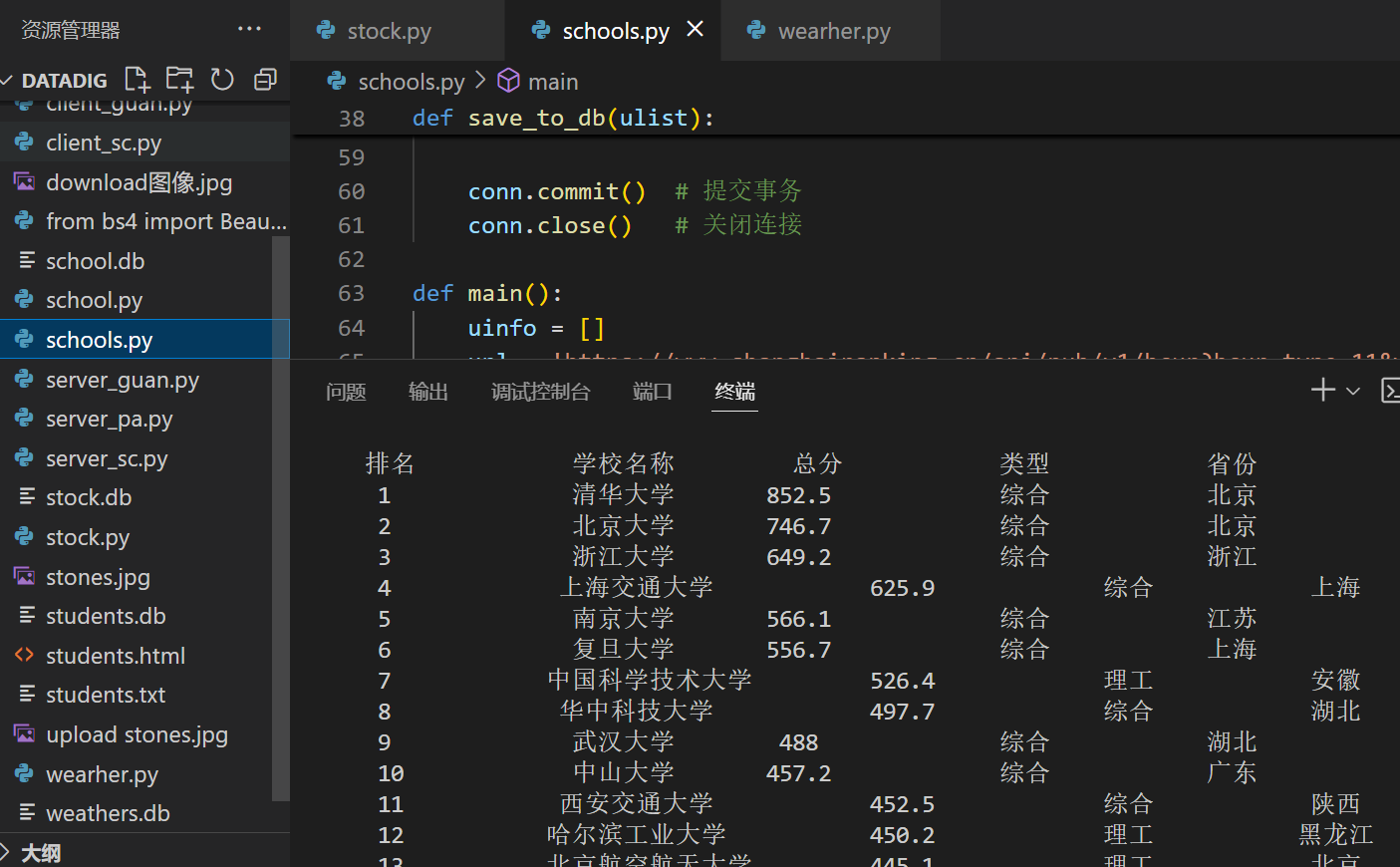
c、浏览器 F12 调试分析的过程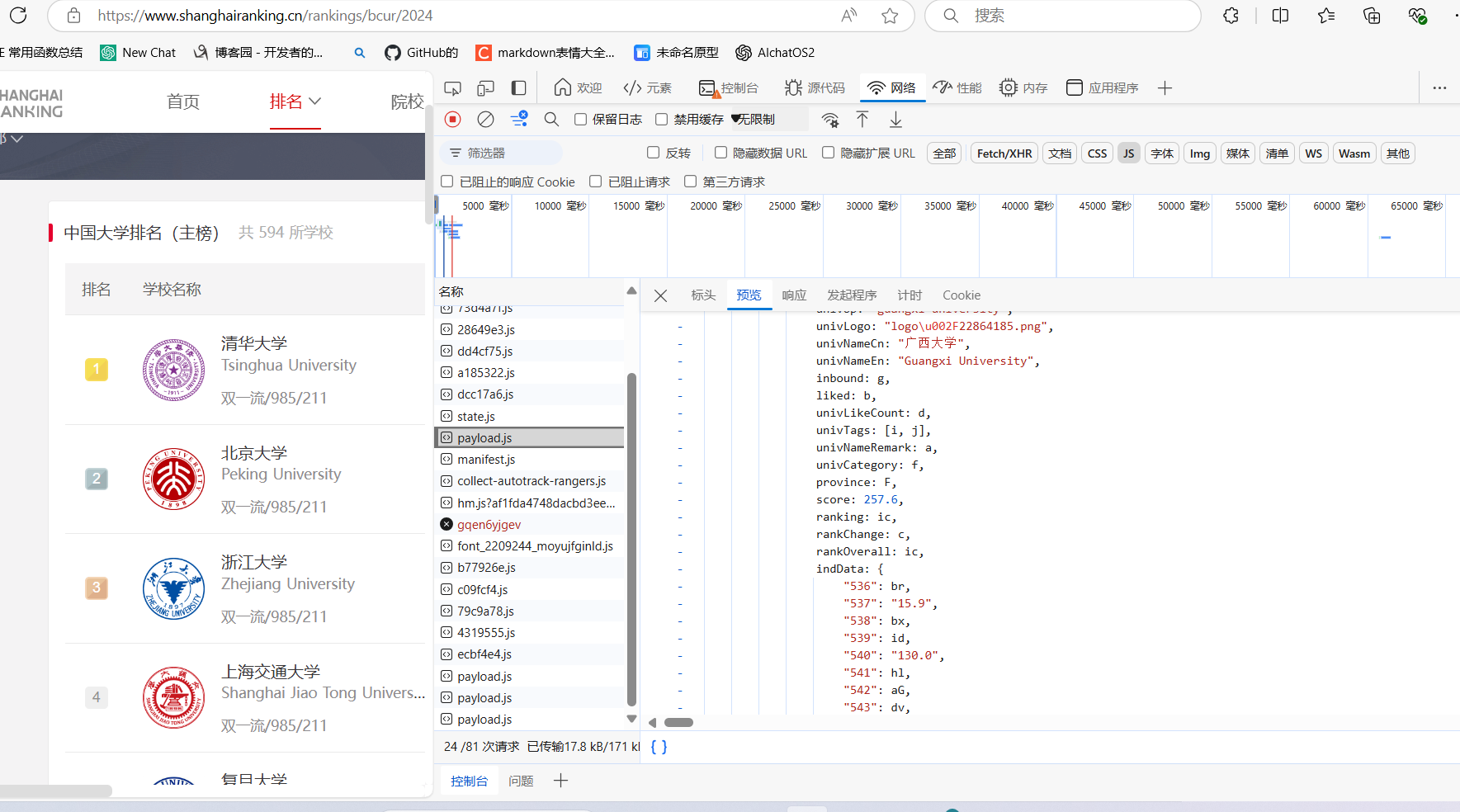
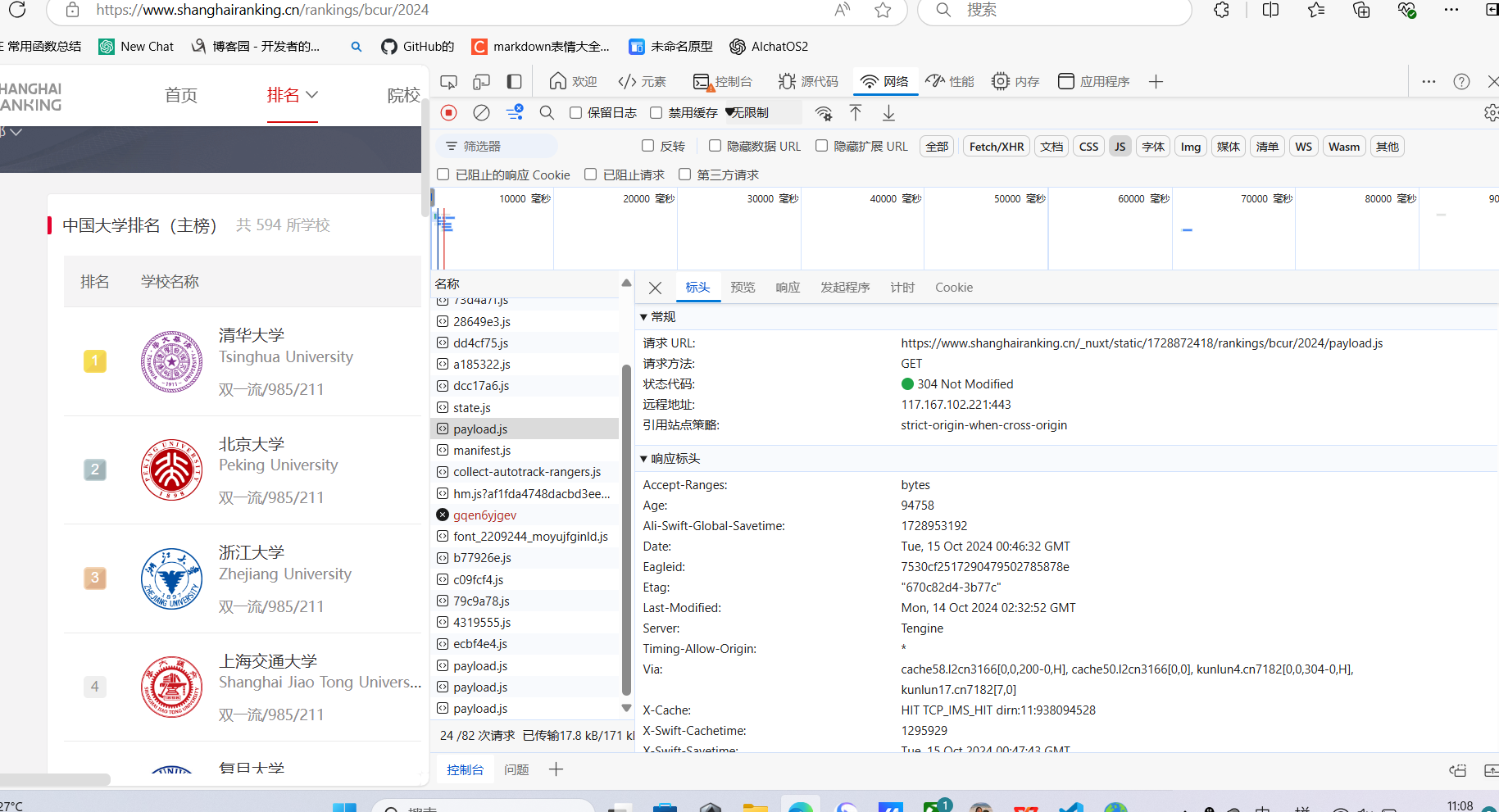
2)心得体会
- 使用SQLite数据库存储数据是一种轻量级的选择,适用于小型项目。这种方式无需安装复杂的数据库系统,适合初学者学习数据库操作。
- 整个程序按照功能划分为多个函数,每个函数都执行一个特定的任务:获取网页、提取数据、打印数据、存储数据。这样的设计使得代码易于维护和扩展。
