
训练每个epoch初始加载数据时间长
参考
https://blog.csdn.net/a237072751/article/details/124599426
源代码:
https://github.com/huggingface/pytorch-image-models/pull/140/commits/a7f570c9b72369fd75e15733d5645d09039d5f9e
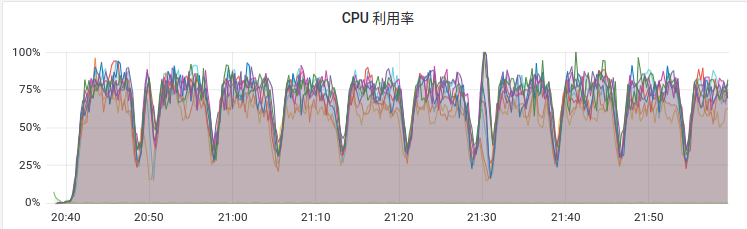
起初是实验中发现GPU利用率始终上不去,即使是扩大batchsize和显存使用量,GPU总平均值也一直是比较低。发现原因是每隔一个epoch,GPU都会闲置一小段时间,此时CPU利用率明显降低(如图),拉低了平均值。猜测是在等待CPU上的数据加载任务。
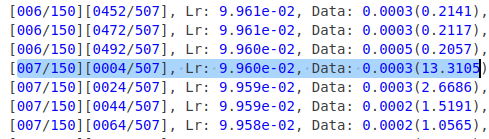
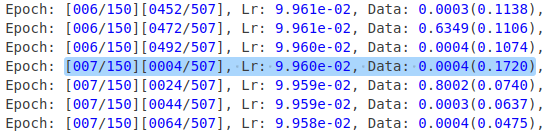
进而发现,是由于每个epoch初始时,加载数据耗时过长导致。torch.utils.data.DataLoader在每个epoch初始,都会重新建立数据的迭代顺序。由此找到了MultiEpochsDataLoader方法,迭代顺序只在首次做初始化。训练效果如图。总训练时间也大大缩短。
torch.utils.data.DataLoader数据加载时间log
MultiEpochsDataLoader数据加载时间log
使用方法:
用 MultiEpochsDataLoader 代替 torch.utils.data.DataLoader
1 train_loader = MultiEpochsDataLoader(train_dataset, 2 batch_size=xx, 3 num_workers=xx, 4 sampler=train_sampler, 5 shuffle=(train_sampler is None), 6 pin_memory=True, 7 drop_last=True) 8
1 class MultiEpochsDataLoader(torch.utils.data.DataLoader): 2 3 def __init__(self, *args, **kwargs): 4 super().__init__(*args, **kwargs) 5 self._DataLoader__initialized = False 6 self.batch_sampler = _RepeatSampler(self.batch_sampler) 7 self._DataLoader__initialized = True 8 self.iterator = super().__iter__() 9 10 def __len__(self): 11 return len(self.batch_sampler.sampler) 12 13 def __iter__(self): 14 for i in range(len(self)): 15 yield next(self.iterator) 16 17 18 class _RepeatSampler(object): 19 """ Sampler that repeats forever. 20 Args: 21 sampler (Sampler) 22 """ 23 24 def __init__(self, sampler): 25 self.sampler = sampler 26 27 def __iter__(self): 28 while True: 29 yield from iter(self.sampler)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号