XmlBeanDefinitionReader解析
一、源码解析
1.首先创建一个实体类Person,一个demo.xml用于测试XmlBeanDefinitionReader。(其他类后续分析)
Person类
package com.bean;
public class Person {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "com.bean.Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
demo.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="com.bean.Person" id="person">
<property name="name" value="johnny"/>
<property name="age" value="10"/>
</bean>
</beans>
测试方法
@Test
public void XmlBeanDefinitionReaderTest() {
ResourceLoader resourceLoader = new DefaultResourceLoader();
Resource resource =resourceLoader.getResource("demo.xml");
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
XmlBeanDefinitionReader xmlBeanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
xmlBeanDefinitionReader.loadBeanDefinitions(resource);
Person person = beanFactory.getBean("person",Person.class);
System.out.println(person);
}
2.涉及XmlBeanDefinitionReader的loadBeanDefinitions()方法分析的调用主要方法链路如下:
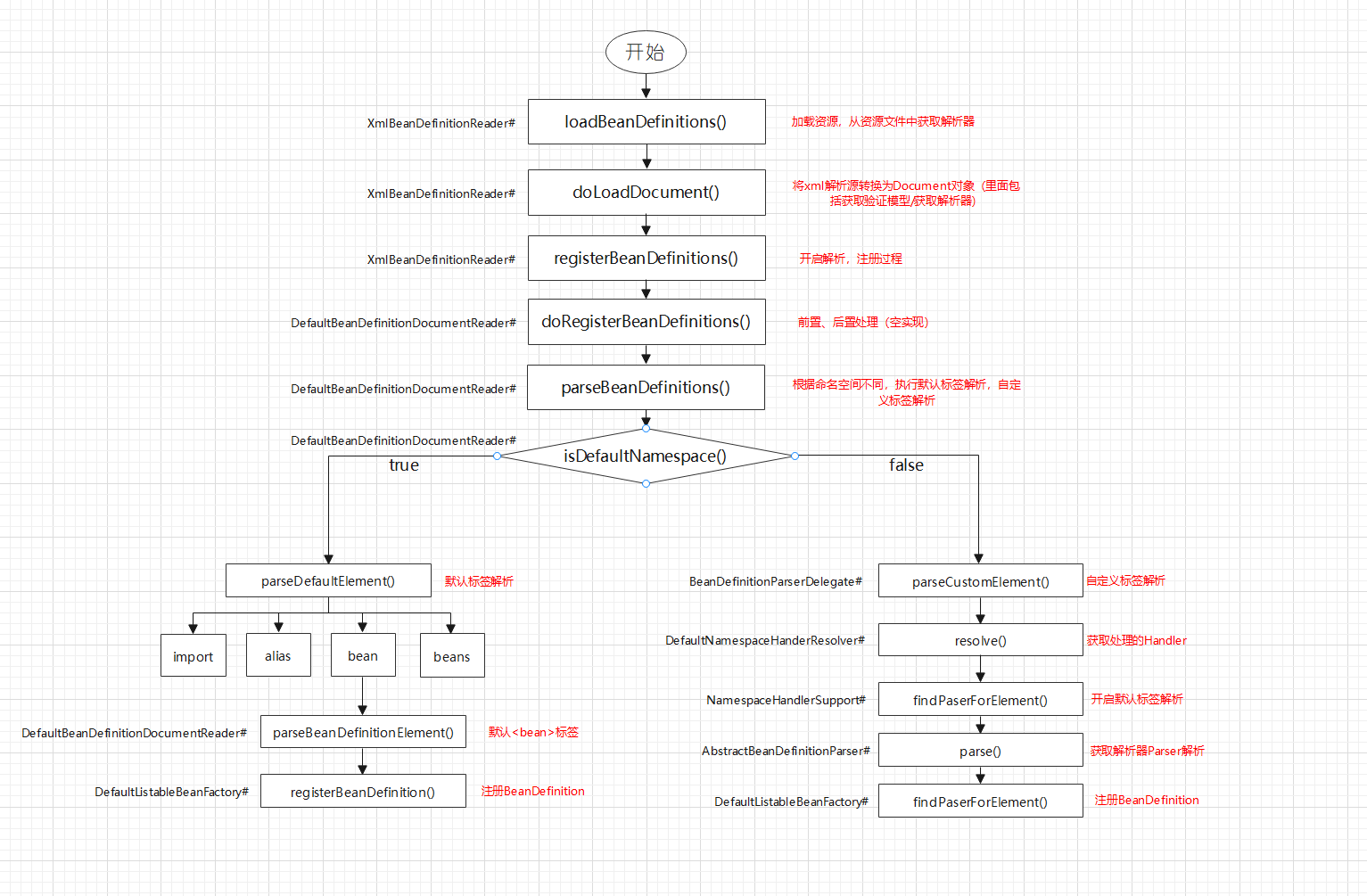
3.这里详细分析一下各个方法的作用。
(1)首先,进入到loadBeanDefinitions()方法。可以看到,这里对Resource进行了一个编码的封装,这是为了保证内容读取的正确性。
/**
* Load bean definitions from the specified XML file.
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
(2)再点进loadBeanDefinitions(),这里注意看每一步的注释。
/**
* Load bean definitions from the specified XML file.
* @param encodedResource the resource descriptor for the XML file,
* allowing to specify an encoding to use for parsing the file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
*/
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isTraceEnabled()) {//调用此方法判断是为了避免不必要的额外操作
logger.trace("Loading XML bean definitions from " + encodedResource);
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();//获取已经加载过的资源
if (!currentResources.add(encodedResource)) {//往当前的资源容器添加编码后的资源,如果已存在,则抛出异常。(通过 resourcesCurrentlyBeingLoaded.get() 代码,来获取已经加载过的资源,然后将 encodedResource 加入其中,如果 resourcesCurrentlyBeingLoaded 中已经存在该资源,则抛出 BeanDefinitionStoreException 异常。!!!-》避免一个 EncodedResource 在加载时,还没加载完成,又加载自身,从而导致死循环。
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
//从 encodedResource 获取封装的 Resource 资源,并从 Resource 中获取相应的 InputStream ,然后将 InputStream 封装为 InputSource ,最后调用 #doLoadBeanDefinitions(InputSource inputSource, Resource resource) 方法,执行加载 Bean Definition 的真正逻辑。
try (InputStream inputStream = encodedResource.getResource().getInputStream()) {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {// 设置编码
inputSource.setEncoding(encodedResource.getEncoding());
}
// 核心逻辑部分,执行加载 BeanDefinition
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {//TODO 从缓存中剔除该资源
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
(3)接下来的doLoadBeanDefinition()看似代码多,实际上就两步操作。1.获取XML 的Document实例 ;2.根据Document实例,注册Bean信息。
/**
* Actually load bean definitions from the specified XML file.
* @param inputSource the SAX InputSource to read from
* @param resource the resource descriptor for the XML file
* @return the number of bean definitions found
* @throws BeanDefinitionStoreException in case of loading or parsing errors
* @see #doLoadDocument
* @see #registerBeanDefinitions
*/
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
//1. 获取XML 的Document实例
Document doc = doLoadDocument(inputSource, resource);
//2.根据Document实例,注册Bean信息
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
(3-1)首先看doLoadDocument()里面做了什么操作。这里其实是获取指定资源(xml)的验证模式,获取 XML Document 实例。第4个参数getValidationModeForResource(resource)是为了获得给资源获取验证模板。
/**
* Actually load the specified document using the configured DocumentLoader.
* @param inputSource the SAX InputSource to read from
* @param resource the resource descriptor for the XML file
* @return the DOM Document
* @throws Exception when thrown from the DocumentLoader
* @see #setDocumentLoader
* @see DocumentLoader#loadDocument
*/
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
第2个参数getEntityResolver()方法返回了什么呢?需要进一步剖析一下。具体可以参考这篇博客:https://blog.csdn.net/wlyang666/article/details/104589624 或者 https://blog.csdn.net/u012702547/article/details/107013604/ 更为详细一点。xml解析的时候会遇到你所配置的xml格式是否符合规范的问题,而sax解析,可以通过你在xml的声明上配置的publicid 和 连接地址获取配置文件需要执行的一些规范,考虑到网络下载不稳定以及断网等问题,大多数框架会在自己内部jar包内放一份文件,然后自定义类实现EntityResolver 接口,这样代码运行先从本地尝试获取规范文件,获取不到才会从网络下载。对于xml格式验证具体可以这篇博客:https://blog.csdn.net/jie1336950707/article/details/48956727
/**
* Return the EntityResolver to use, building a default resolver
* if none specified.
* 创建一个可以使用的EntityResolver ,如果没有指定的话创建一个默认的
*/
protected EntityResolver getEntityResolver() {
if (this.entityResolver == null) {
// Determine default EntityResolver to use.
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader != null) {
this.entityResolver = new ResourceEntityResolver(resourceLoader);
}
else {
this.entityResolver = new DelegatingEntityResolver(getBeanClassLoader());
}
}
return this.entityResolver;
}
返回来,我们继续向下走,DocumentLoader接口里面只有这一个loadDocument()方法。
/**
* Load a {@link Document document} from the supplied {@link InputSource source}.
* @param inputSource the source of the document that is to be loaded
* @param entityResolver the resolver that is to be used to resolve any entities
* @param errorHandler used to report any errors during document loading
* @param validationMode the type of validation
* {@link org.springframework.util.xml.XmlValidationModeDetector#VALIDATION_DTD DTD}
* or {@link org.springframework.util.xml.XmlValidationModeDetector#VALIDATION_XSD XSD})
* @param namespaceAware {@code true} if support for XML namespaces is to be provided
* @return the loaded {@link Document document}
* @throws Exception if an error occurs
*/
Document loadDocument(
InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware)
throws Exception;
看它的实现方法,如下:
/**
* Load the {@link Document} at the supplied {@link InputSource} using the standard JAXP-configured
* XML parser.
*/
@Override
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isTraceEnabled()) {
logger.trace("Using JAXP provider [" + factory.getClass().getName() + "]");
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号