

Springboot 1.5.x 集成基于Centos7的RabbitMQ集群安装及配置
RabbitMQ简介
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。
RabbitMQ是一套开源(MPL)的消息队列服务软件,是由LShift提供的一个Advanced Message Queuing Protocol(AMQP)的开源实现,由以高性能、健壮以及可伸缩性出名的Erlang写成。
选择RabbitMQ
市面上有很多MQ可以选择,如:ActiveMQ、ZeroMQ、Apache Qpid及RocketMQ,为什么要选择RabbitMQ呢?
1. 除了Qpid,RabbitMQ是唯一一个实现了AMQP标准的消息服务器;
2. 可靠性,RabbitMQ的持久化支持,保证了消息的稳定性;
3. 高并发,RabbitMQ使用了Erlang开发语言,Erlang是为电话交换机开发的语言,天生自带高并发光环和高可用特性;
4. 集群部署简单,正是应为Erlang使得RabbitMQ集群部署变的超级简单;
5. 社区活跃度高,从网上资料来看,RabbitMQ也是首选
工作机制
1. 消息模型
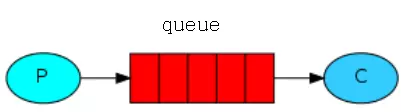
生产者、消费者和代理
生产者(producer):消息的创建者,负责创建和推送数据到消息服务器;
消费者(consumer):消息的接收方,用于处理数据和确认消息;
代理(proxy):就是RabbitMQ本身,用于扮演“快递”的角色,本身不生产消息,只是扮演“快递”的角色。
图片来源:消息队列之 RabbitMQ
2. 基本概念
RabbitMQ内部结构:
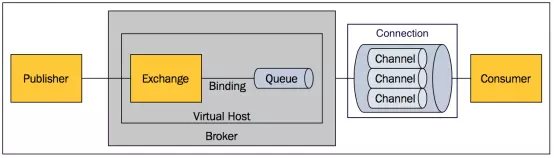
1. Message
消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。
2. Publisher
消息得生产者,也是一个向交换器发布消息的客户端应用程序。
3. Exchange
交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
4. Binding
绑定,用于消息队列和交换器之间的关联,一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。
5. Queue
消息队列,用来保存消息知道发送给消费者。他是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
6. Connection
网络连接,比如一个TCP连接
7. Channel
信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内地虚拟连接,AMQP命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁TCP都是非常昂贵的开销,所以引入了信道的概念,以复用一条TCP连接。
8. Consumer
消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。
9. Virtual Host
虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个vhost本质上就是一个mini版的RabbitMQ服务器,拥有自己的队列、交换器、绑定和权限机制。vhost是AMQP概念的基础,必须在连接时指定,RabbitMQ默认的vhost是 / 。
10. Broker
表示消息队列服务器实体。
3. AMQP中的消息路由
AMQP中消息的路由过程和Java开发者熟悉的JMS存在一些差异,AMQP中增加了Exchange和Binding的角色。生产者把消息发布到Exchange上,消息最终达到队列并被消费者接收,而Binding决定交换器的消息应该发送到哪个队列。
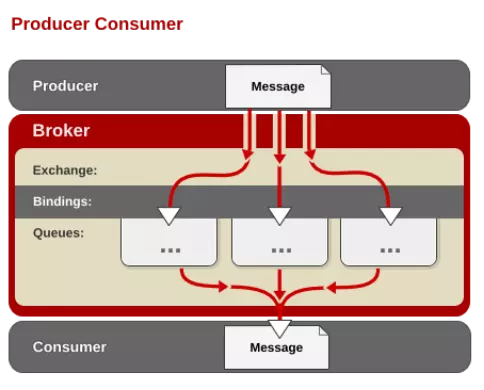
4. 交换机Exchange
Exchange分发消息时根据类型的不同分发策略有区别,目前存在四种类型:direct、fanout、topic、headers。headers匹配AMQP消息的header而不是路由主键,此外headers交换机和direct交换机完全一致,但性能差很多,目前基本上用不到了,所以直接看其他类型。
1. direct
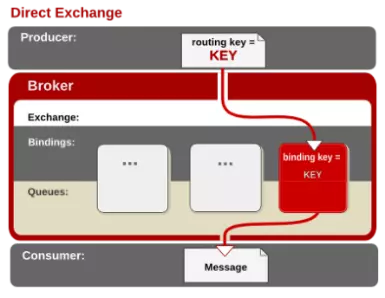
消息中的路由主键(routing key)如何和Binding中的binding key一致,交换机就将消息发到对应的队列中。路由键和队列名完全匹配,如果一个队列绑定到交换机要求路由键为“dog”,则只能转发routing key标记为“dog”的消息。它是完全匹配,单播的模式。
2. fanout
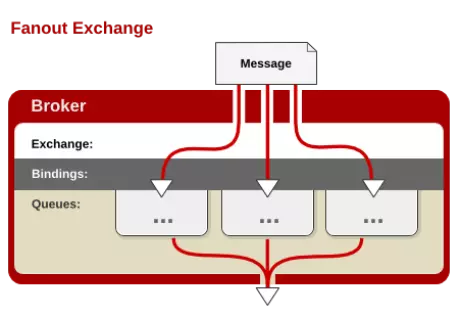
每个发到fanout类型交换器的消息都会分到所有绑定的队列上去。fanout交换机不处理路由键,只是简单的将队列绑定到交换机上,每个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。它是转发消息最快的。
3. topic
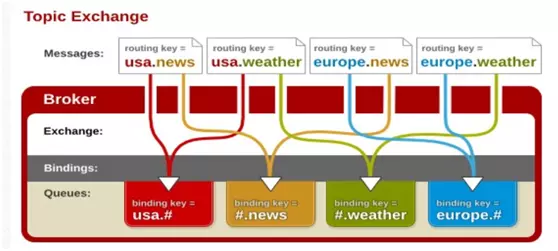
topic交换机通过模式匹配分配消息的路由键属性,将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开。它同样也会识别两个通配符:符号“#”和符号“”。#匹配0个活多个单词,“”匹配不多不少一个单词。
5. 消息持久化
RabbitMQ队列和交换器在默认情况下,重启服务器会导致消息丢失,如何保证RabbitMQ在重启的时候消息不丢失呢?答案:消息持久化
RabbitMQ持久化会将你的持久化消息写入到磁盘中的持久化日志文件中,等消息被消费后,RabbitMQ会把这条消息标识为等待垃圾回收。
当你把消息发送到RabbitMQ服务器的时候,你需要选择是否要进行持久化,但这并不能保证RabbitMQ能从崩溃中恢复,想要消息恢复必须满足以下3个条件:
1. 投递消息的时候durable设置为true,消息持久化,代码:channel.queueDeclare(x, true, false, false, null),参数2设置为true持久化;
2. 设置投递模式deliveryMode设置为2(持久),代码:channel.basicPublish(x, x, MessageProperties.PERSISTENT_TEXT_PLAIN,x),参数3设置为存储纯文本到磁盘;
3. 消息已经到达持久化交换器上;
4. 消息已经到达持久化的队列;
4. 持久化缺点
消息持久化的优点显而易见,但缺点也很明显,那就是性能,因为要写入硬盘要比写入内存性能较低很多,从而降低了服务器的吞吐量,尽管使用SSD硬盘可以使事情得到缓解,但他仍然吸干了Rabbit的性能,当消息成千上万条要写入磁盘的时候,性能是很低的。所以需要根据自己项目的实际情况,选择适合自己的方式。
5. 虚拟主机
每个Rabbit都能创建很多vhost,我们称之为虚拟主机,每个虚拟主机其实都是mini版的RabbitMQ,拥有自己的队列,交换机和绑定,拥有自己的权限机制。
vhost 特性:
1. RabbitMQ默认的vhost是“/”开箱即用
2. 多个vhost是隔离的,多个vhost无法通讯,并且不用担心命名冲突(队列和交换机进行绑定),实现了多层分离
3. 创建用户的时候必须指定vhost
vhost操作:
1. 可以通过rabbitmqctl工具命令创建:
rabbitmqctl add_vhost[vhost_name]
2. 删除vhost:
rabbitmqctl delete_vhost[vhost_name]
3. 查看所有的vhost:
rabbitmqctl list_vhosts
RabbitMQ安装及搭建
1. 选择版本
选择Erlang与RabbitMQ对应版本 RabbitMQ Erlang Version Requirements
2. 安装Erlang
2.1 下载Erlang需要依赖的包
cd /
mkdir downloads

2.2 将Erlang需要的依赖通过yum下载并安装
yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel
注:Erlang所需依赖下载安装完成后,开始下载Erlang。
2.3 开始下载Erlang
cd /usr/local/
mkdir rabbitmq
cd rabbitmq
wget http://www.rabbitmq.com/releases/erlang/erlang-19.0.4-1.el7.centos.x86_64.rpm
2.4 开始安装Erlang
rpm -ivh erlang-19.0.4-1.el7.centos.x86_64.rpm

3. 安装RabbitMQ
3.1 下载RabbitMQ
cd /usr/local/rabbitmq/
wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.6/rabbitmq-server-3.6.6-1.el7.noarch.rpm
rpm -ivh rabbitmq-server-3.6.6-1.el7.noarch.rpm

3.2 在安装RabbitMQ过程中提示依赖socat软件
yum install socat
3.3 安装完socat,重新执行安装RabbitMQ

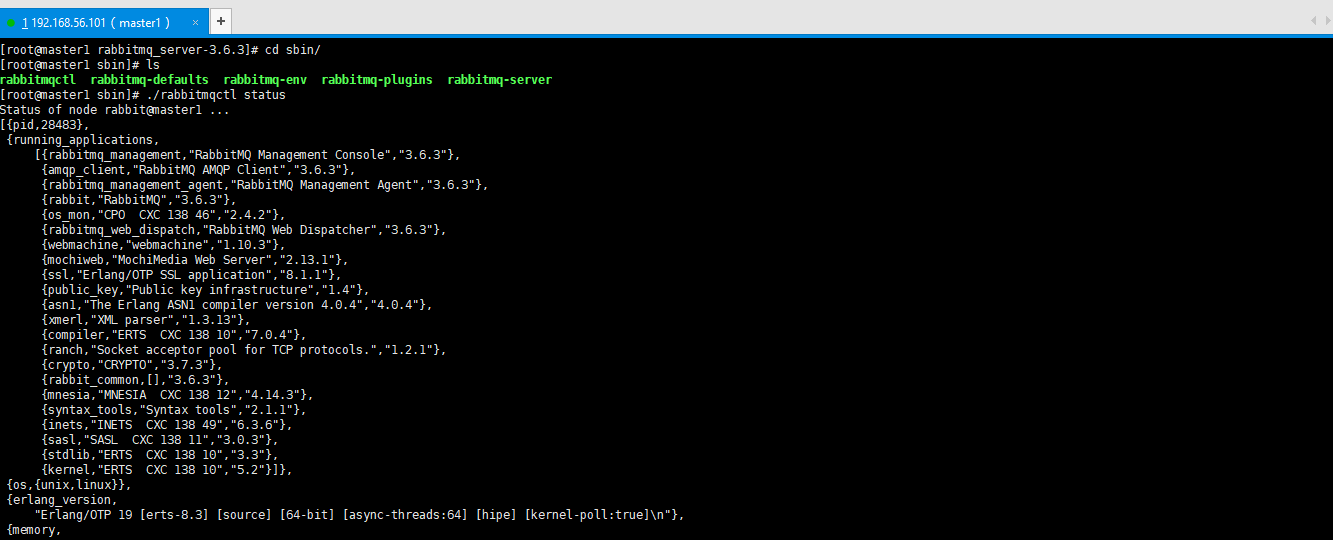
3.4 查找安装RabbitMQ bin的位置

3.5 启动RabbitMQ
cd /sbin/
./rabbitmq-server -detached # 启动服务命令
./rabbitmqctl stop # 停止服务命令
./rabbitmq-plugins enable rabbitmq_management # 安装管理插件
./rabbitmq-server -detached # 重新启动服务命令
./rabbitmqctl status # 查看服务运行状态
wget http://master1:15672 # 验证是否成功安装
3.6 创建用户
./rabbitmqctl add_user admin admin ./rabbitmqctl set_user_tags admin administrator ./rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*" ./rabbitmqctl list_users
如果发现远程访问不了:http://192.168.56.101:15672
应该是iptables的原因
1.关闭firewall [root@localhost ~]# systemctl stop firewalld.service //停止firewall [root@localhost ~]# systemctl disable firewalld.service //禁止firewall开机启动 2.安装iptables [root@localhost ~]# yum install iptables-services //安装 [root@localhost ~]# systemctl restart iptables.service #重启防火墙使配置生效 [root@localhost ~]# systemctl enable iptables.service #设置防火墙开机启动 [root@localhost ~]# systemctl disable iptables.service #禁止防火墙开机启动
4. RabbitMQ集群配置
4.1 服务器
192.168.56.101,192.168.56.102
4.2 在102机器按照之上101模式重新安装RabbitMQ即可
4.3 两台RabbitMQ服务重启后,通过cluster_status命令查看集群状态

4.4 连接集群
为了连接集群中的两个节点,我们把rabbit@slave1加入到rabbit@master1节点集群中,调整两台服务器hosts文件,加入域名
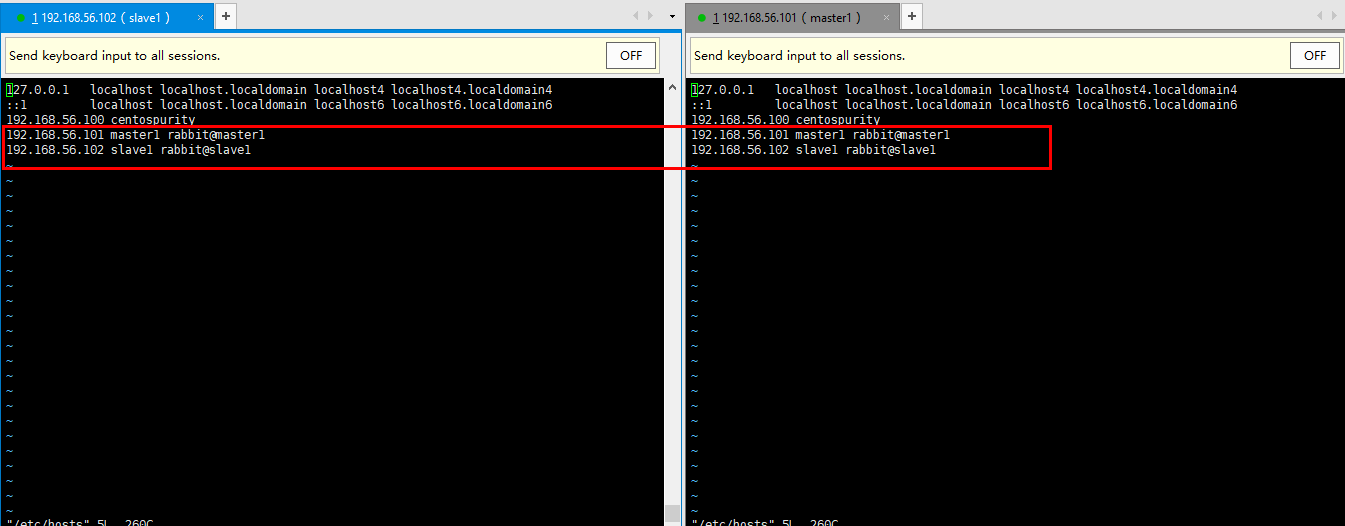
1、停止rabbit@salve1的rabbitmq应用
2、加入rabbit@master1集群
3、启动rabbit@salve1
4、在master1/slave1任意一个节点查看集群状态
cd /sbin/ ./rabbitmqctl stop_app ./rabbitmqctl join_cluster rabbit@master1 ./rabbitmqctl start_app ./rabbitmqctl cluster_status


4.5 停止master1查看集群状态
针对master1操作:
cd /sbin/
./rabbitmqctl stop
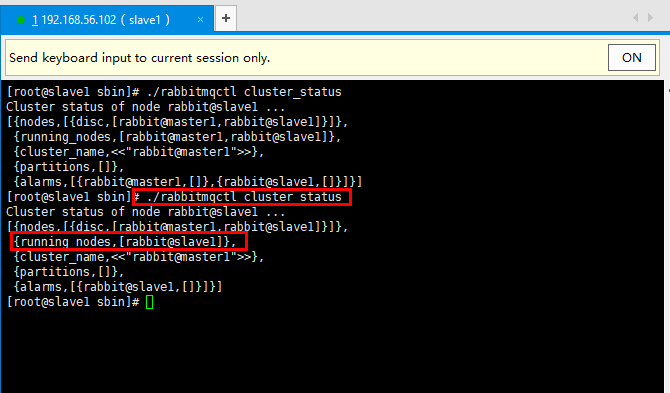
4.6 重启master1查看集群状态

4.7 注意问题
当整个集群关闭时,最后一个关闭的节点必须是第一个要联机的节点。
如果要脱机的最后一个节点无法恢复,可以使用forget_cluster_node命令将其从群集中删除
如果所有集群节点同时停止并且不受控制(例如断电),则可能会留下所有节点都认为其他节点在其后停止的情况。在这种情况下,您可以在一个节点上使用force_boot命令使其再次可引导
4.8 移除集群
当节点不再是节点的一部分时,需要从集群中明确地删除节点。我们首先从集群中删除rabbit@slave1,并将其返回到独立操作。
在rabbit@slave1上:
1、停止RabbitMQ应用程序
2、重置节点
3、重新启用RabbitMQ应用程序
./rabbitmqctl stop_app ./rabbitmqctl reset ./rabbitmqctl start_app ./rabbitmqctl cluster_status
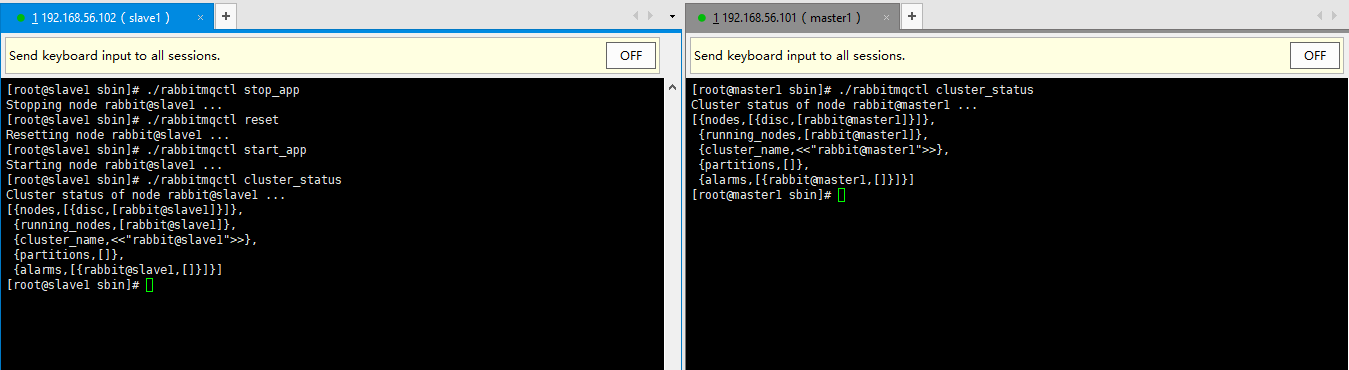
4、远程删除节点,在处理无响应的节点服务
例如我们在master1上将slave1从集群中移除
- 停止节点slave1
- 在master1上通过forget_cluster_node命令移除slave1
- 重置slave1节点
- 启动slave1节点
Slave1服务器:
./rabbitmqctl stop_app ./rabbitmqctl reset # 执行此命令前 先执行master1 上的forget命令 ./rabbitmqctl start_app ./rabbitmqctl cluster_status
master1服务器:
./rabbitmqctl forget_cluster_node rabbit@slave1 # 执行此命令前 先执行slave1 停止节点
./rabbitmqctl cluster_status
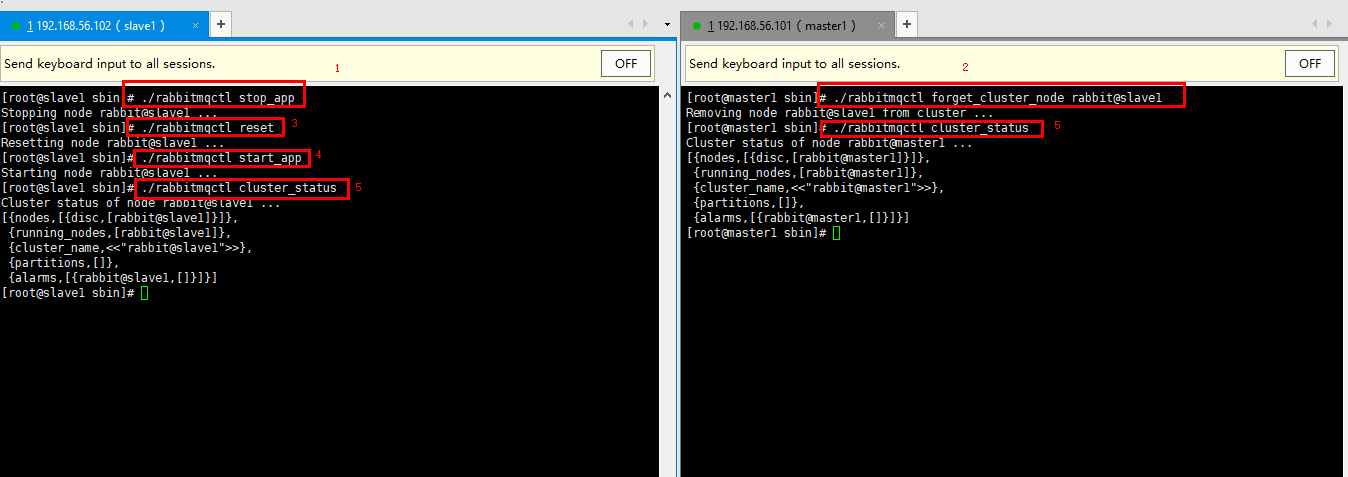
4.9 主机名更改
RabbitMQ节点使用主机名相互通信。因此,所有节点名称必须能够解析所有集群对等的名称。像rabbitmqctl这样的工具也是如此
除此之外,默认情况下RabbitMQ使用系统的当前主机名来命名数据库目录。如果主机名更改,则会创建一个新的空数据库。为了避免数据丢失,建立一个固定和可解析的主机名至关重要。每当主机名更改时,您应该重新启动RabbitMQ
如果要使用节点名称的完整主机名(RabbitMQ默认为短名称),并且可以使用DNS解析完整的主机名,则可能需要调查设置环境变量 RABBITMQ_USE_LONGNAME = true
5. 使用HAProxy实现RabbitMQ集群的负载
5.1 资源包下载,并上传服务器
https://download.csdn.net/download/u014518626/10122459?web=web
cd /usr/local/
mkdir haproxy
5.2 解压
tar -xzvf haproxy-1.7.9.tar.gz
5.3 查看内核
uname -r
5.4 编译安装
make TARGET=linux2628
make install
安装后,查看版本
./haproxy -v
复制haproxy文件到/usr/sbin下,因为下面的haproxy.init启动脚本默认会去/usr/sbin下找,当然你也可以修改,不过比较麻烦。
cp haproxy /usr/sbin/
复制haproxy脚本,到/etc/init.d下
cp ./examples/haproxy.init /etc/init.d/haproxy
chmod 755 /etc/init.d/haproxy
5.5 创建系统账号
useradd -r haproxy
5.6 创建配置文件
mkdir /etc/haproxy
vi /etc/haproxy/haproxy.cfg
Haproxy.cfg内容如下:
global log 127.0.0.1 local0 info chroot /usr/local/haproxy user haproxy group haproxy daemon maxconn 4096 defaults log global mode tcp option tcplog option dontlognull retries 3 option abortonclose maxconn 4096 timeout connect 5000ms timeout client 3000ms timeout server 3000ms balance roundrobin listen private_monitoring bind 0.0.0.0:8100 mode http option httplog stats refresh 5s stats uri /stats stats realm Haproxy stats auth admin:admin listen rabbitmq_admin bind 0.0.0.0:8102 server master1 192.168.56.101:15672 server slave1 192.168.56.102:15672 listen rabbitmq_cluster bind 0.0.0.0:8101 mode tcp option tcplog balance roundrobin timeout client 3h timeout server 3h server master1 192.168.56.101:5672 check inter 3000 rise 2 fall 3 server slave1 192.168.56.102:5672 check inter 3000 rise 2 fall 3
由于我打开了 log 127.0.0.1 local0 info 日志,需要调整rsyslog配置文件。
打开rsyslog配置
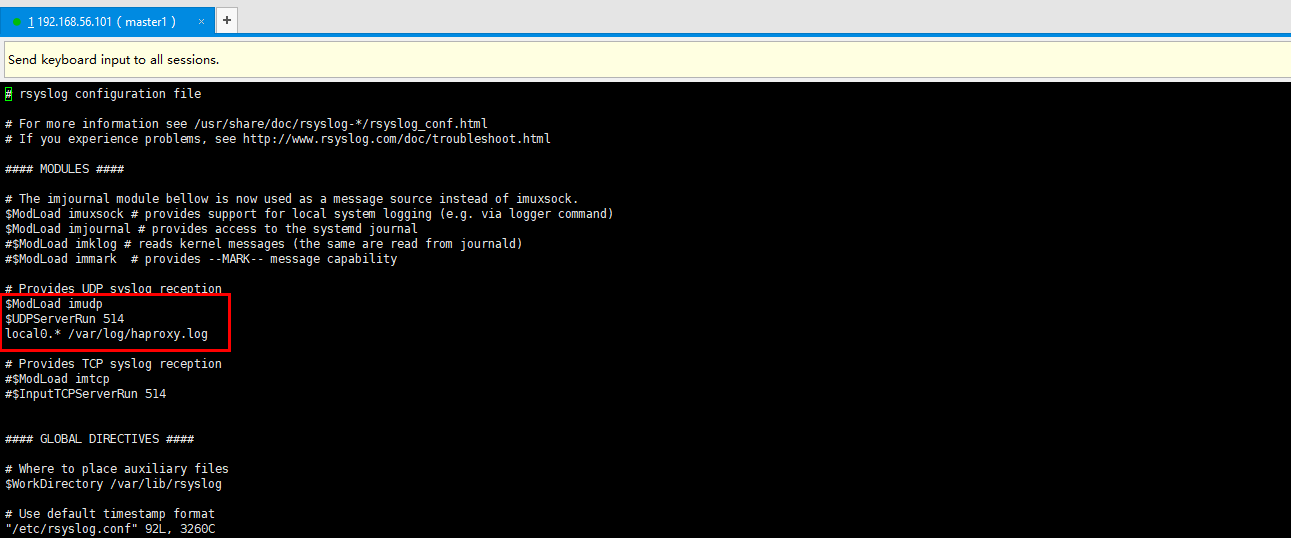
vi /etc/rsyslog.conf
去掉下面两行前面的#号
$ModLoad imudp
$UDPServerRun 514
并添加下面一行
local0.* /var/log/haproxy.log
重新启动rsyslog
systemctl restart rsyslog
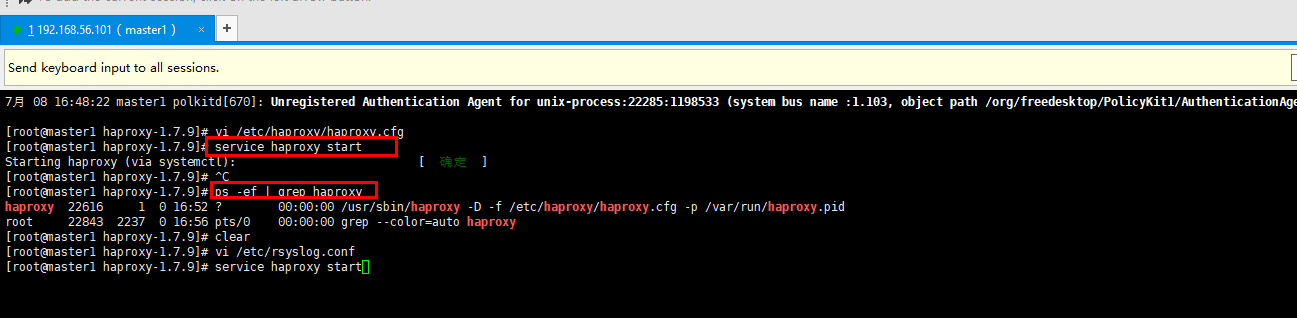
启动haproxy
service haproxy start
6. Springboot 集成RabbitMQ集群
6.1 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
6.2 地址配置
--- # 集群 RabbitMQ spring: rabbitmq: host: 192.168.56.101 port: 8101 username: admin password: admin
注意:8101 是 haproxy 负载均衡器的地址,因为之上我已经使用了 haproxy作为 rabbitmq集群的负载器
6.3 创建队列
package com.sinosoft.config; import org.springframework.amqp.core.Queue; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * Created by xushuyi on 2017/7/20. */ @Configuration public class Queues { /** * 创建队列 hello.foo * @return */ @Bean public Queue helloQueue() { return new Queue("hello.foo"); } }
6.4 生产消息
package com.sinosoft.rabbit; import org.springframework.amqp.core.AmqpTemplate; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import java.util.Date; /** * Created by xushuyi on 2017/7/20. */ @Component public class RabbitSend { @Autowired private AmqpTemplate rabbitTemplate; public void send(String val) { String context = "hello " + new Date(); System.out.println("Sender : " + val); this.rabbitTemplate.convertAndSend("hello.foo", val); } }
6.5 消息消费
package com.sinosoft.rabbit; import org.springframework.amqp.rabbit.annotation.RabbitListener; import org.springframework.stereotype.Component; /** * Created by xushuyi on 2017/7/20. */ @Component public class RabbitReceive { /** * 接收通道 * * @param i */ @RabbitListener(queues = "hello.foo") public void process(String i) { System.out.println("执行接收Receiver1 : " + i.toString()); } }
注:这是一个非常精简的demo示例,已经可以达到队列消息的生产与消费,当然还有很多详细的配置内容,在这里就不多赘述了。
技术参考:
2. RabbitMQ集群
