浅层神经网络
浅层神经网络
-
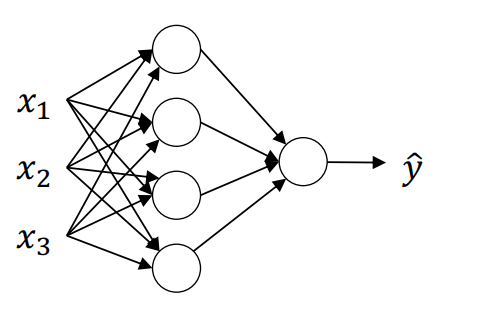
浅层神经网络通常指包含一个隐藏层的神经网络。这个网络由输入层、隐藏层和输出层构成:
-
输入层:输入层负责接收网络的输入特征,通常表示为列向量 \(x^T = [x_1, x_2, x_3]\),每个输入特征 \(x_i\) 代表样本的一个属性。输入特征的激活值 \(a^{[0]}\) 就是输入特征向量 \(X\),因此我们用 \(a^{[0]}\) 表示输入层的激活值。
-
隐藏层:隐藏层包含若干节点(或神经元),在训练过程中,节点的输出值(激活值)通过激活函数计算得到。这里隐藏层的激活值表示为 \(a^{[1]} \in \mathbb{R}^{4 \times 1}\),即四个神经元的输出。隐藏层的参数包含权重 \(\omega^{[1]} \in \mathbb{R}^{4 \times 3}\) 和偏置项 \(b^{[1]} \in \mathbb{R}^{4 \times 1}\)。权重矩阵 \(\omega^{[1]}\) 的维度由隐藏层神经元数和输入特征数决定,而偏置 \(b^{[1]}\) 则是一个列向量,长度等于隐藏层神经元数量。 \(\omega_3^{[4]}\) 就代表着第四层第三个神经元的列向量。
-
输出层:输出层负责生成最终的预测值 \(\hat{y}\)。输出层的激活值 \(a^{[2]}\) 表示为预测值 \(\hat{y}\)。输出层的权重 \(\omega^{[2]} \in \mathbb{R}^{1 \times 4}\) 和偏置 \(b^{[2]} \in \mathbb{R}^{1 \times 1}\) 用于对隐藏层激活值的线性变换。权重 \(\omega^{[2]}\) 的维度由输出层和隐藏层神经元数确定,而偏置 \(b^{[2]}\) 为一个标量。
-
激活值 \(a\):在每一层,激活值 \(a\) 表示网络在该层输出的值,并通过激活函数传递到下一层。输入层的激活值 \(a^{[0]}\) 就是输入特征 \(X\),在隐藏层的激活值为 \(a^{[1]}\),输出层的激活值为预测值 \(a^{[2]} = \hat{y}\)。
-
一般地,对于第 \(l\) 层的权重矩阵 \(\omega^{[l]}\),其维度为:
\[ \omega^{[l]} \in \mathbb{R}^{n^{[l]} \times n^{[l-1]}} \]其中, \(n^{[l]}\) 表示第 \(l\) 层的神经元数量,而 \(n^{[l-1]}\) 表示前一层(即第 \(l-1\) 层)的神经元数量。这个矩阵的维度定义确保了每个神经元都可以接收到来自上一层所有神经元的输入。
在计算网络层数时,输入层通常不计入总层数。以此标准,隐藏层为第一层,输出层为第二层,因此称输入层为第零层。通过这种结构,神经网络可以将输入特征经过层层转换后,最终输出一个预测值。
-
-
浅层神经网络的单样本前向传播过程包含以下步骤:
-
输入到隐藏层的映射:
- 输入层的激活值 \(a^{[0]} = X \in \mathbb{R}^{3 \times 1}\) 表示一个包含 3 个特征的列向量。
- 隐藏层的权重矩阵 \(\omega^{[1]} \in \mathbb{R}^{4 \times 3}\) 连接输入层和隐藏层( \(\omega_i^{[1]} \in \mathbb{R}^{3 \times 1}\)),偏置项 \(b^{[1]} \in \mathbb{R}^{4 \times 1}\) 为隐藏层每个神经元的偏置值。
\[\omega^{[1]} = \left[ \begin{array}{c} ...\omega^{[1]T}_{1}...\\ ...\omega^{[1]T}_{2}...\\ ...\omega^{[1]T}_{3}...\\ ...\omega^{[1]T}_{4}... \end{array} \right] \]- 隐藏层中每个神经元的线性组合计算如下(以第一个神经元为例),这里 \(\omega_1^{[1]T}\) 表示权重矩阵的第一个行向量转置,使得维度相符:
\[z_1^{[1]} = \omega_1^{[1]T} a^{[0]} + b_1^{[1]} \]- 通过激活函数 \(\sigma\),得到隐藏层每个神经元的激活值:
\[a^{[1]} = \left[ \begin{array}{c} a^{[1]}_{1}\\ a^{[1]}_{2}\\ a^{[1]}_{3}\\ a^{[1]}_{4} \end{array} \right] = \sigma(z^{[1]}) = \sigma(\left[ \begin{array}{c} z^{[1]}_{1}\\ z^{[1]}_{2}\\ z^{[1]}_{3}\\ z^{[1]}_{4}\\ \end{array} \right]) \] -
向量化计算隐藏层的激活值:
-
为简化计算,我们将每个神经元的激活值向量化表示。
-
令 \(z^{[1]} \in \mathbb{R}^{4 \times 1}\) 表示隐藏层的加权和,激活值 \(a^{[1]} \in \mathbb{R}^{4 \times 1}\) 表示隐藏层的输出。
-
向量化的计算公式为:
\[z^{[1]} = \omega^{[1]} a^{[0]} + b^{[1]} \\ a^{[1]} = \sigma(z^{[1]}) \] -
在这一步, \(\omega^{[1]} a^{[0]}\) 的结果是 \(\mathbb{R}^{4 \times 1}\) 的向量,与偏置项 \(b^{[1]} \in \mathbb{R}^{4 \times 1}\) 相加。
-
\[\left[ \begin{array}{c} z^{[1]}_{1}\\ z^{[1]}_{2}\\ z^{[1]}_{3}\\ z^{[1]}_{4}\\ \end{array} \right] = \overbrace{ \left[ \begin{array}{c} ...\omega^{[1]T}_{1}...\\ ...\omega^{[1]T}_{2}...\\ ...\omega^{[1]T}_{3}...\\ ...\omega^{[1]T}_{4}... \end{array} \right] }^{\omega^{[1]}} * \overbrace{ \left[ \begin{array}{c} x_1\\ x_2\\ x_3\\ \end{array} \right] }^{input} + \overbrace{ \left[ \begin{array}{c} b^{[1]}_1\\ b^{[1]}_2\\ b^{[1]}_3\\ b^{[1]}_4\\ \end{array} \right] }^{b^{[1]}} \]-
隐藏层到输出层的映射:
- 隐藏层的激活值 \(a^{[1]} \in \mathbb{R}^{4 \times 1}\) 作为输入传递到输出层。
- 输出层的权重矩阵 \(\omega^{[2]} \in \mathbb{R}^{1 \times 4}\) 和偏置 \(b^{[2]} \in \mathbb{R}\) 定义了从隐藏层到输出层的映射。
- 计算输出层的加权和:
\[z^{[2]} = \omega^{[2]} a^{[1]} + b^{[2]} \]- 输出层的激活值 \(a^{[2]}\) 是最终的预测值,通过激活函数计算得到:
\[a^{[2]} = \sigma(z^{[2]}) \] -
整体向量化公式总结:
-
使用向量化公式将输入逐层传递到输出层,前向传播过程如下:
\[\omega^{[1]} \in \mathbb{R}^{4 \times 3},a^{[0]}=X \in \mathbb{R}^{3 \times 1},b^{[1]} \in \mathbb{R}^{4 \times 1}\\ z^{[1]} = \omega^{[1]} a^{[0]} + b^{[1]}, \quad a^{[1]} = \sigma(z^{[1]}) \\ \\ \omega^{[2]} \in \mathbb{R}^{1 \times 4},a^{[1]} \in \mathbb{R}^{4 \times 1},b^{[2]} \in \mathbb{R}\\ z^{[2]} = \omega^{[2]} a^{[1]} + b^{[2]}, \quad a^{[2]} = \sigma(z^{[2]}) \] -
通过这些公式,可以高效地进行单样本的前向传播,将输入特征 \(X\) 转换为最终预测值 \(a^{[2]}\)。
-
-
-
多样本浅层神经网络向量化
在上一节中,我们推导了单个样本的前向传播过程。对于训练集中包含的所有样本,为了计算 \(m\) 个样本的预测值,传统方法需要逐个样本进行计算,通常用如下循环表示:
for i in range(m):\[z^{[1](i)}=\omega^{[1]}a^{[0](i)}+b^{[1](i)} \\ a^{[1](i)} = \sigma(z^{[1](i)}) \\ z^{[2](i)}=\omega^{[2]}a^{[1](i)}+b^{[2](i)} \\ a^{[2](i)} = \sigma(z^{[2](i)}) \]为提升计算效率,我们对这些计算进行了向量化处理,使整个批次的样本能够同时进行前向传播。首先,将输入和参数以矩阵形式表示:
- 输入矩阵 \(X\)表示所有训练样本:
\[X = \left[ \begin{array}{c} \vdots & \vdots & \vdots & \vdots\\ x^{(1)} & x^{(2)} & \cdots & x^{(m)}\\ \vdots & \vdots & \vdots & \vdots\\ \end{array} \right] \]- 第一层线性组合矩阵 \(Z^{[1]}\):
\[Z^{[1]} = \left[ \begin{array}{c} \vdots & \vdots & \vdots & \vdots\\ z^{[1](1)} & z^{[1](2)} & \cdots & z^{[1](m)}\\ \vdots & \vdots & \vdots & \vdots\\ \end{array} \right] \]- 第一层激活矩阵 \(A^{[1]}\):
\[A^{[1]} = \left[ \begin{array}{c} \vdots & \vdots & \vdots & \vdots\\ \alpha^{[1](1)} & \alpha^{[1](2)} & \cdots & \alpha^{[1](m)}\\ \vdots & \vdots & \vdots & \vdots\\ \end{array} \right] \]通过上述矩阵化的形式,我们可以简化计算流程,使得在批量处理多个样本时,神经网络层之间的操作能够一次性完成:
\[Z^{[1]}=\omega^{[1]}X+b^{[1]} \\ A^{[1]} = g(Z^{[1]}) \\ Z^{[2]}=\omega^{[2]}A^{[1]}+b^{[2]} \\ A^{[2]} = g(Z^{[2]}) \]这里的列(水平索引)表示每个训练样本,而行(垂直索引)表示网络中的不同节点。矩阵中位于最左上角的元素,对应于第一个样本在第一个隐藏单元的激活值;同理,矩阵中每个位置的值都表示特定样本在特定神经元的激活值。这种矩阵化处理方式极大地提高了多样本的计算效率,使得整个神经网络的前向传播可以借助矩阵运算并行完成。
不妨来推导一下正确性,假设忽略 \(b\) ,那么有
\[Z^{[1]}=\omega^{[1]} x = \omega^{[1]} \left[ \begin{array}{c} \vdots &\vdots & \vdots & \vdots \\ x^{(1)} & x^{(2)} & \vdots & x^{(m)}\\ \vdots &\vdots & \vdots & \vdots \\ \end{array} \right] = \left[ \begin{array}{c} \vdots &\vdots & \vdots & \vdots \\ w^{(1)}x^{(1)} & w^{(1)}x^{(2)} & \vdots & w^{(1)}x^{(m)}\\ \vdots &\vdots & \vdots & \vdots \\ \end{array} \right] =\\ \left[ \begin{array}{c} \vdots &\vdots & \vdots & \vdots \\ z^{[1](1)} & z^{[1](2)} & \vdots & z^{[1](m)}\\ \vdots &\vdots & \vdots & \vdots \\ \end{array} \right] \] -
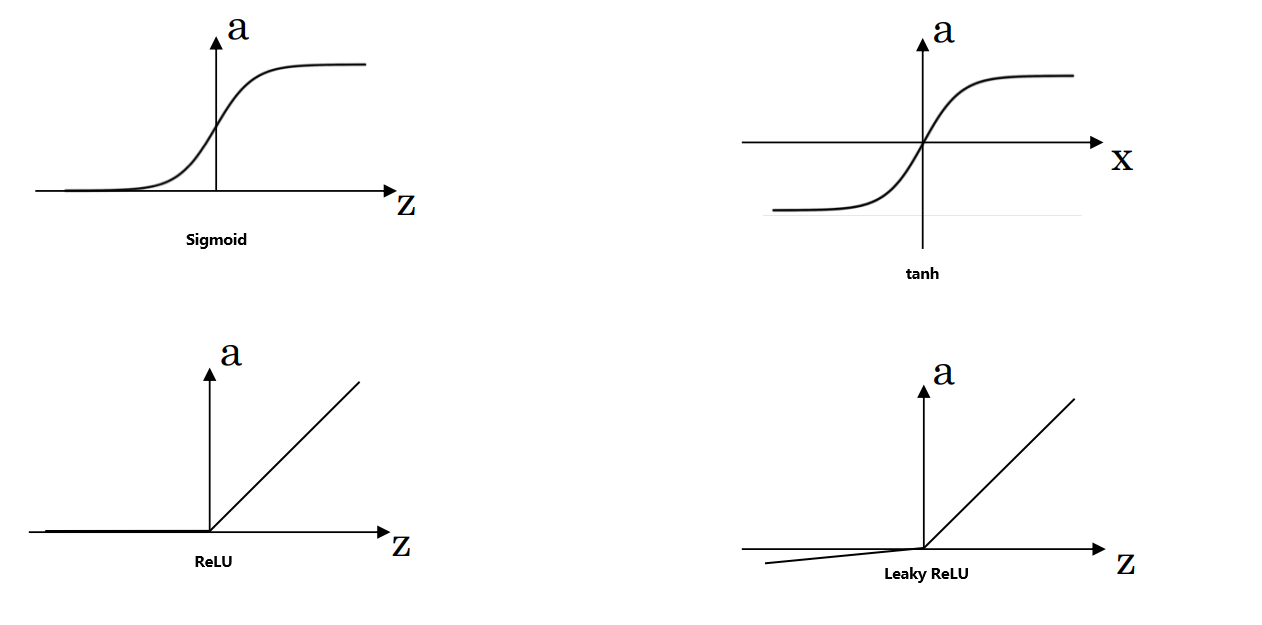
在神经网络中,激活函数用 \(g(z)\) 表示。常见的激活函数有以下几种:
-
Sigmoid函数:常用于二分类输出层,将值映射到 \([0,1]\) 区间。
\[\sigma(z)=\frac{1}{1+e^{-z}} \]优点:适用于二分类问题的输出层。
缺点:在 \(z\) 值过大或过小时,梯度趋于0,导致梯度消失,学习速率减慢。
-
tanh函数(双曲正切函数):与Sigmoid类似,但将值映射到 \([-1, 1]\) 区间。tanh函数是sigmoid的向下平移和伸缩后的结果。
\[tanh(z)=\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}} \]优点:在隐藏层中更常用,因为其输出均值接近0,可以帮助加速收敛,可以中心化数据,使得数据的平均值更接近0而不是0.5。
缺点:与Sigmoid函数一样,极端 \(z\) 值会导致梯度消失。 -
ReLU函数(线性修正单元):计算简单,适用于大多数隐藏层。
\[\text{ReLU}(x)=max(0,x) \]优点:在 \(z > 0\) 区域,导数为1,有助于解决梯度消失问题,提高学习速度。
缺点:在 \(z < 0\) 区域,导数为0,可能导致某些神经元不更新(即神经元“死亡”)。 -
Leaky ReLU函数:是ReLU的改进版,在负区间加入轻微斜率,防止神经元完全“死亡”。
\[\text{Leaky ReLU}(x)=max(0.01x,x) \]优点:解决ReLU的“神经元死亡”问题,使负区间有小的梯度。
缺点:实际应用中效果虽然较好,但并不总是显著优于ReLU。
激活函数选择的基本原则
- 二分类问题:通常在输出层使用Sigmoid函数,保证预测值在 \([0, 1]\) 之间。
- 隐层激活函数:ReLU是最常见的默认选择,因为其计算效率高且可以避免梯度消失。如果遇到ReLU导致的神经元死亡问题,可以尝试Leaky ReLU。tanh也可以用于隐藏层,尤其是在数据均值需要接近0的场合。
- 注意事项:Sigmoid和tanh在大范围 \(z\) 值中会导致梯度趋近0,引发梯度消失问题。ReLU和Leaky ReLU则在 \(z > 0\) 时保持较大的梯度,但ReLU在负区间导数为0,会导致稀疏性,即部分神经元不更新。Leaky ReLU提供了一种更平滑的方案。
- 在 \(z\) 的区间变动很大的情况下,激活函数的导数都会远大于0,而sigmoid函数需要进行浮点四则运算,在实践中,使用ReLU激活函数神经网络通常会比使用sigmoid或者tanh激活函数学习的更快。 \(z\) 在ReLU的梯度一半都是0,但是有足够的隐藏层使得 \(z >0\),所以对大多数的训练数据来说学习过程仍然可以很快。
在实际使用中,ReLU常作为隐层的默认选择;在输出层,激活函数的选择应根据任务需求决定。
-
-
为了使神经网络具备良好的拟合能力,必须在隐藏层中使用非线性激活函数。假设在网络中使用恒等激活函数 \(g(z)=z\) ,则模型的输出可以表示为:
\[a^{[1]} = g(z^{[1]}) = \omega^{[1]}x + b^{[1]} \\ a^{[2]} = g(z^{[2]}) = \omega^{[2]}a^{[1]}+ b^{[2]} = \omega^{[2]}\omega^{[1]}x + \omega^{[2]}b^{[1]} + b^{[2]}= \omega^{'}x + b^{'} \]这种情况下,不论网络层数如何,模型都在计算一个线性函数,其整体表达式仍然是输入 \(X\) 的线性组合。既然如此,如果在隐藏层仅使用线性激活函数,那么堆叠多个层就毫无意义,因为多层网络只是等效于一个单层的线性变换。这种情况下,完全可以去掉所有隐藏层,仅保留输入层和输出层。
为了解决这个问题,通常会在隐藏层引入非线性激活函数(如 ReLU、tanh 或 leaky ReLU),以打破线性关系并引入模型的非线性拟合能力。这使得神经网络能够表达更复杂的函数关系,从而适应不同的数据模式。唯一可以使用线性激活函数的层通常是输出层,特别是在回归问题中,我们希望输出直接反映模型预测的连续值。
-
在进行神经网络反向传播时,需要计算激活函数的导数
- Sigmoid激活函数:
\[g(z)=\text{Sigmoid}(z)=\frac{1}{1+e^{-z}} \\ g'(z)=g(z)[1-g(z)] \]- Tanh激活函数:
\[g(z)=\text{tanh}(z)=\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}} \\ g'(z)=1-[g(z)]^2 \]- ReLU激活函数:
\[g(z)=\text{ReLU}(z)=max(0,z) \\ g(z)^{'}= \begin{cases} 0& \text{if\;} z < 0\\ 1& \text{if\;} z \geq 0\\ \end{cases} \]- Leaky ReLU激活函数:
\[g(z)=\text{Leaky ReLU}(x)=\max(0.01z,z) \\ g(z)^{'}=\begin{cases}0.01& \text{if\;} z < 0\\1& \text{if\;} z \geq 0\end{cases} \] -
浅层神经网络反向传播
\[\left. \begin{array}{l} x \\ \omega^{[1]} \\ b^{[1]} \end{array} \right\} \Rightarrow z^{[1]} = \omega^{[1]} x + b^{[1]} \Rightarrow \left. \begin{array}{l} a^{[1]} = g^{[1]}(z^{[1]}) \\ \omega^{[2]} \\ b^{[2]} \end{array} \right\} \Rightarrow \\ z^{[2]} = \omega^{[2]} a^{[1]} + b^{[2]} \Rightarrow a^{[2]} = g^{[2]}(z^{[2]}) \Rightarrow L(a^{[2]}, y) \]\[ \frac{\partial L}{\partial a^{[2]}} = -\frac{y}{a^{[2]}} + \frac{1-y}{1-a^{[2]}} \\ \frac{\partial a^{[2]}}{\partial z^{[2]}}=g^{[2]'}(z^{[2]})=a^{[2]}(1-a^{[2]}) \\ \frac{\partial L}{\partial z^{[2]}} = a^{[2]}-y \]\[\frac{\partial z^{[2]}}{\partial \omega^{[2]}} = a^{[1]} \quad \frac{\partial z^{[2]}}{\partial b^{[2]}} = 1 \quad \frac{\partial z^{[2]}}{\partial a^{[1]}}=\omega^{[2]} \\ \frac{\partial L}{\partial \omega^{[2]}} = a^{[1]}(a^{[2]}-y) \\ \frac{\partial L}{\partial b^{[2]}} = a^{[2]}-y \\ \frac{\partial L}{\partial a^{[2]}} =\omega^{[2]}(a^{[2]}-y) \]\[\frac{\partial a^{[1]}}{\partial z^{[1]}}=g^{[1]'}(z^{[1]}) \\ \frac{\partial L}{\partial z^{[1]}} =w^{[2]}(a^{[2]}-y)g^{[1]'}(z^{[1]}) \]\[\frac{\partial z^{[1]}}{\partial \omega^{[1]}}=x \quad \frac{\partial z^{[1]}}{\partial b^{[1]}}=1 \\ \frac{\partial L}{\partial \omega^{[1]}}=xdz^{[1]} \quad \frac{\partial L}{\partial b^{[1]}}=dz^{[1]} \]使用 \(n_x\) 表示输入特征数量, \(n^{[1]}\) 表示隐藏层神经元数量, \(n^{[2]}\) 表示输出单元数量,共有 \(m\) 个样本,那么有 \(A^{[2]} \in \mathbb{R}^{n^{[2]} \times m=1\times m}\),\(A^{[1]} \in \mathbb{R}^{n^{[1]} \times m}\) ,向量化实现:
\[dZ^{[2]}=A^{[2]}-Y \in \mathbb{R}^{n^{[2]}\times m} \\ d\omega^{[2]}=\frac{1}{m}dZ^{[2]}A^{[1]T} \in \mathbb{R}^{n^{[2]} \times n^{[1]}} \\ db^{[2]}=\frac{1}{m}\sum dZ^{[2]} \in \mathbb{R}^{n^{[2]}\times 1} \\ \\ dZ^{[1]} = \underbrace{\omega^{[2]T}{\rm d}Z^{[2]}}_{(n^{[1]},m)} * \underbrace{{g^{[1]}}^{'}(z^{[1]})}_{(n^{[1]},m)}\in \mathbb{R}^{n^{[1]}\times m} \\ d\omega^{[1]}=\frac{1}{m}dZ^{[1]}X^T \in \mathbb{R}^{n^{[1]}\times n_x} \\ db^{[1]}=\frac{1}{m}\sum dZ^{[1]} \in \mathbb{R}^{n^{[1]} \times 1} \]因此有
\[\text{Forward Propagation:} \\ Z^{[1]}=\omega^{[1]}X+b^{[1]} \\ A^{[1]} = g(Z^{[1]}) \\ Z^{[2]}=\omega^{[2]}A^{[1]}+b^{[2]} \\A^{[2]} = g(Z^{[2]}) \\ \text{Backward Propagation:} \\ dZ^{[2]}=A^{[2]}-Y \\ d\omega^{[2]}=\frac{1}{m}dZ^{[2]}A^{[1]T} \\ db^{[2]}=\frac{1}{m}\sum dZ^{[2]} \\ dZ^{[1]}=\omega^{[2]T}dZ^{[2]}*g^{[1]'}(Z^{[1]}) \\ d\omega^{[1]}=\frac{1}{m}dZ^{[1]}X^T \\ db^{[1]}=\frac{1}{m}\sum dZ^{[1]} \]db1 = 1. / m * np.sum(dZ1, axis=1, keepdims=True)这样,我们可以完整地描述向量化浅层神经网络的前向和反向传播过程。这种向量化操作大大提高了计算效率,尤其适用于多样本训练情况。
-
在训练神经网络时,随机初始化权重是至关重要的。如果仅仅是逻辑回归,把权重初始化为0是可行的,因为只有一个层次。但在神经网络中,若将所有权重初始化为0,梯度下降将不起作用,这主要是因为对称性问题 (Symmetry Breaking)。
假设一个浅层神经网络有2个输入特征和2个隐藏神经元。如果将隐藏层的权重 \(\omega^{[1]}\) 全部初始化为0,那么两个隐藏神经元 \(a_{1}^{[1]}\) 和 \(a_{2}^{[1]}\) 会计算完全相同的函数,即对称的隐含单元会一直保持对称。即使经过多次迭代训练,两个神经元的计算结果仍然相同。这会导致输出层的权重更新也完全一致,因此无法有效训练出不同的特征。为了使每个隐含单元学习不同的特征,我们需要随机初始化权重,使每个神经元的输出有所区别。
我们通常对权重 \(\omega\) 生成符合高斯分布的随机值,并乘以一个小的常数,比如0.01:
\[\omega^{[1]} = np.random.randn(2,2) \times 0.01, \quad b^{[1]} = np.zeros((2,1)) \\ \omega^{[2]} = np.random.randn(2,2) \times 0.01, \quad b^{[2]} = 0 \]这里,将权重初始化为小的随机数可以打破对称性,确保每个神经元学习到不同的特征。而偏置项 \(b\) 没有对称性问题,因此可以初始化为0。
选择小常数的原因,即为什么乘以0.01,而不是更大的数。对于使用 tanh 或 sigmoid 激活函数的网络,若权重初始化过大,会导致 \(z^{[1]} = W^{[1]}x + b^{[1]}\) 的数值幅度变大。这样,激活值 \(a^{[1]} = g^{[1]}(z^{[1]})\) 将接近 tanh 或 sigmoid 函数的平坦区域,这些区域的梯度很小,梯度下降会很慢,导致训练速度缓慢。这就是为什么在浅层神经网络中,我们通常选择一个较小的常数(例如0.01)来进行权重初始化。对于非常深的神经网络,仅仅使用0.01可能不够理想,可能需要使用更为复杂的初始化方法来应对梯度消失或梯度爆炸的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号