
flink上下游并行度不一致导致的数据乱序问题
问题描述
SingleOutputStreamOperator<Row> aggregatedStream = patrolStream
.union(timerGarbageStream)
.filter(v -> v.getFacility() != null && (v.getFacility().getType() == 11 || v.getFacility().getType() == 48))
.setParallelism(12)
.map(x -> (PatrolRecord) x)
.setParallelism(12)
.filter(x -> x.getInOutState() != 2)
.setParallelism(12)
.keyBy(v -> (Integer) v.getFacility().getId())
.window(TumblingEventTimeWindows.of(Time.seconds(86400), Time.seconds(-Constants.offsetSeconds)))
.allowedLateness(Constants.allowedLateness)
.trigger(CountAndEventTimeTrigger.of(1L))
.aggregate(new GarbageReduceFunction(), new GarbageProcessWindowFunction())
.setParallelism(12)
.returns(rowTypeInfo);
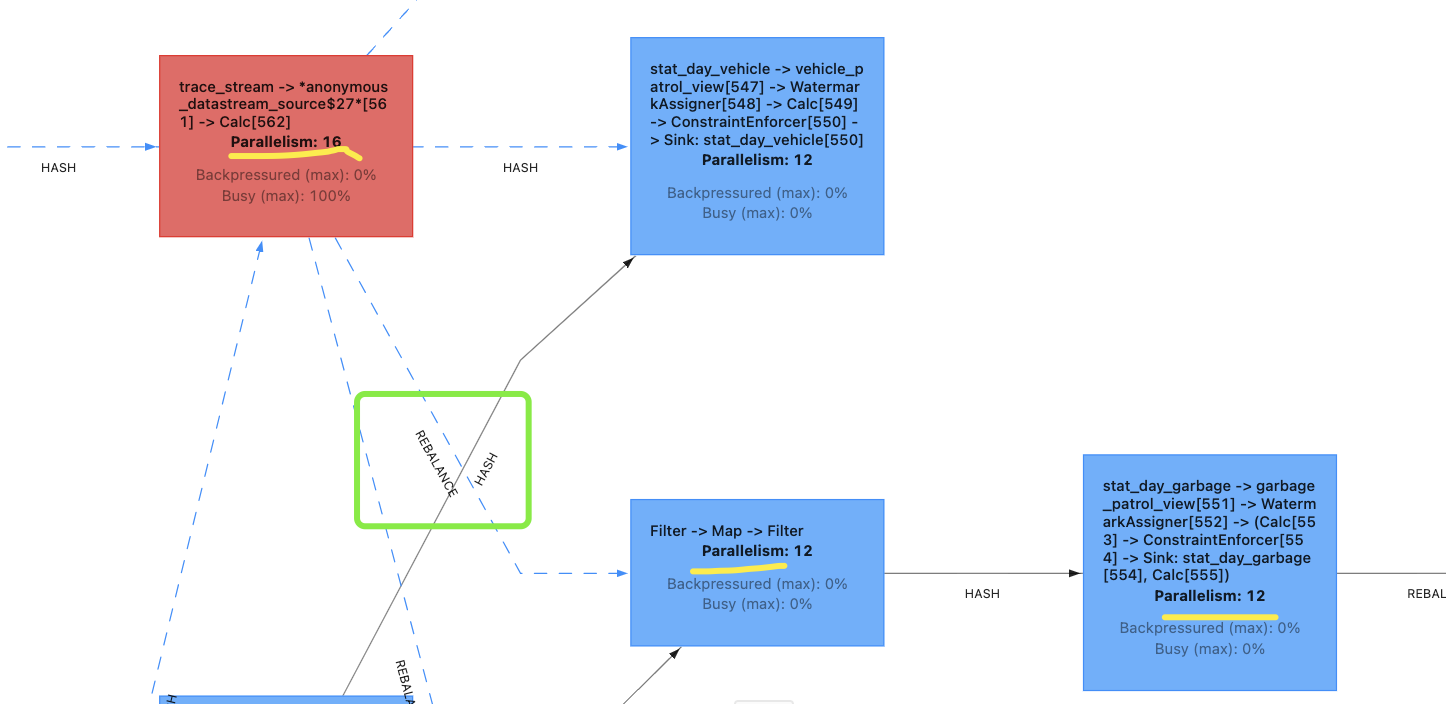
算子A(红色)往侧流中写入数据:
{"s":"2024-08-19 07:16:36","e":"2024-08-19 07:19:36","w":350000,"inferred":false,"rk":"DELETE","f_id":549737,"f_type":11,"inOutState":0,"loadCount":19}
{"s":"2024-08-19 07:16:36","e":"2024-08-19 07:19:36","w":318181,"inferred":false,"rk":"INSERT","f_id":549737,"f_type":11,"inOutState":0,"loadCount":19}
e是事件时间,相同的key、相同的事件时间,写入程序一定是先写入RowKind为DELETE的数据,后写入RowKind为INSERT的数据。
下游算子C(右下角)从侧流中消费数据,并写入DB。
问题在于,消费到的数据,部分数据的顺序乱了,先消费到RowKind为INSERT的数据,后消费到RowKind为DELETE的数据。
问题分析
算子A(红色)的并行度是16
算子B(中间的filter)并行度是12
算子C(右下角)并行度是12
从A到B,进行了rebalance
rebalance 是一个数据重分布(redistribution)操作,它将上游算子的输出数据重新分配到下游的并行子任务中。rebalance 通过循环(round-robin)的方式将数据均匀地分配到所有下游任务槽(task slot)上,从而实现负载均衡。
也就是说,这一步一定存在打乱顺序的可能性。可能出现的结果:
key1、eventTime1、DELETE => 子任务1
key1、eventTime1、INSERT => 子任务2
本来连续的两行数据,被路由到两个不同的算子。
接下来从算子B到算子C,执行的是HASH分区:
hash 是一种分区策略,用于将数据根据其 key 的哈希值分配到不同的并行任务槽(task slot)上。这种分区方式可以确保相同的 key 始终被分配到同一个任务槽中,从而实现数据的分组操作。
此时,尽管key1一定会被路由到同一个子任务上,但是顺序已经无法保证了。
接下来把所有算子并行度都修改为12,看下效果
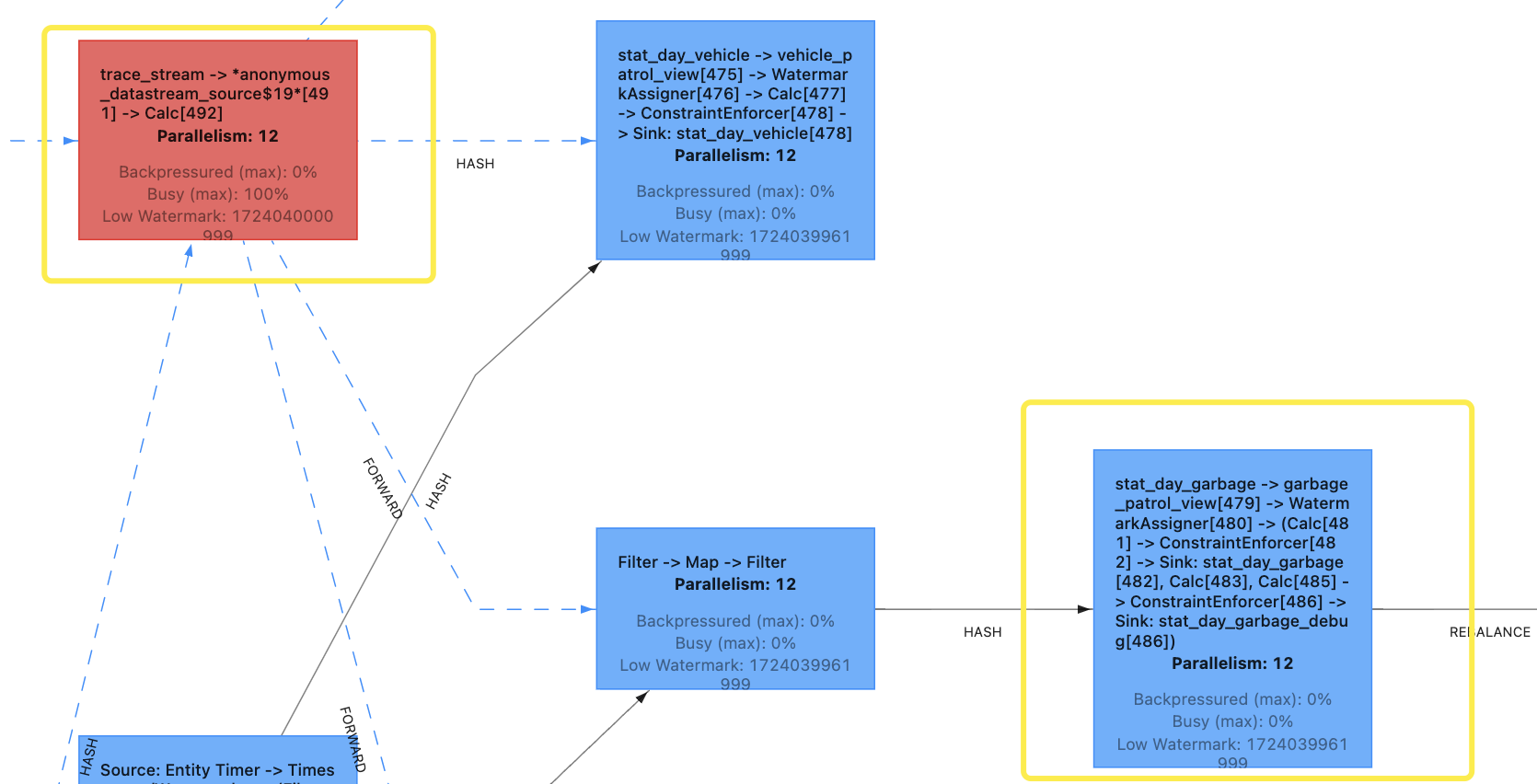
这时候从A到B,执行的是forward分区策略。
forward 是一种分区策略,用于将数据从上游算子直接传递到下游算子的对应并行实例中,而不进行任何重新分区或重新分配。也就是说,forward 保证了数据会直接从上游的一个并行子任务传递到下游的同一个并行子任务。
接下来再执行HASH分区,因此呢,同一个KEY的数据的相对顺序并没有改变。
结论
虽然验证结果还没出来,但是大概率这就是答案了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号