解决公司Kafka集群问题
问题描述
Kakfa版本: 2.8.2
运行环境:阿里云主机CentOS 7、自运维
集群:三个节点,分布在三台云主机上
故障描述:
原有机器配置较低(内存4G、CPU 2核),机器上同时部署了其他服务,每个node分配了1-2G内存,多次出现OOM导致节点挂掉的问题。
于是就计划把机器升级到8G 4核。阿里云升级内存等配置,必须要重启主机,我们通过阿里云计划重启的方式,设置一个时间,到时自动重启服务器。
服务器重启完成后,手动启动Kafka broker。
说明: 有两个节点未提前stop kafka broker就直接进行服务器重启,一个节点是先stop,后重启服务器。
Kakfa重启完成后,先后遇到了几个问题:
1、一部分消费者消费不到消息,同时有大量报错:
12-08 17:06:17.316 INFO -- [ListenerForDeviceData-0-C-1] o.a.k.c.c.i.AbstractCoordinator:849: [Consumer clientId=consumer-online-persistance-group-3, groupId=online-persistance-group] Group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null) is unavailable or invalid, will attempt rediscovery
12-08 17:06:17.324 WARN -- [listenerForHeartbeat-0-C-1] o.a.k.c.c.i.ConsumerCoordinator:1165: [Consumer clientId=consumer-online-persistance-group-1, groupId=online-persistance-group] Offset commit failed on partition device-heartbeat-0 at offset 4107111163: This is not the correct coordinator.
12-08 17:06:17.325 INFO -- [listenerForHeartbeat-0-C-1] o.a.k.c.c.i.AbstractCoordinator:849: [Consumer clientId=consumer-online-persistance-group-1, groupId=online-persistance-group] Group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null) is unavailable or invalid, will attempt rediscovery
12-08 17:06:17.417 INFO -- [ListenerForDeviceData-0-C-1] o.a.k.c.c.i.AbstractCoordinator:797: [Consumer clientId=consumer-online-persistance-group-3, groupId=online-persistance-group] Discovered group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null)
12-08 17:06:17.418 INFO -- [ListenerForDeviceData-0-C-1] o.a.k.c.c.i.AbstractCoordinator:849: [Consumer clientId=consumer-online-persistance-group-3, groupId=online-persistance-group] Group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null) is unavailable or invalid, will attempt rediscovery
12-08 17:06:17.425 INFO -- [listenerForHeartbeat-0-C-1] o.a.k.c.c.i.AbstractCoordinator:797: [Consumer clientId=consumer-online-persistance-group-1, groupId=online-persistance-group] Discovered group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null)
12-08 17:06:17.426 INFO -- [listenerForHeartbeat-0-C-1] o.a.k.c.c.i.AbstractCoordinator:849: [Consumer clientId=consumer-online-persistance-group-1, groupId=online-persistance-group] Group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null) is unavailable or invalid, will attempt rediscovery
12-08 17:06:17.525 INFO -- [ListenerForDeviceData-0-C-1] o.a.k.c.c.i.AbstractCoordinator:797: [Consumer clientId=consumer-online-persistance-group-3, groupId=online-persistance-group] Discovered group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null)
12-08 17:06:17.526 INFO -- [listenerForHeartbeat-0-C-1] o.a.k.c.c.i.AbstractCoordinator:797: [Consumer clientId=consumer-online-persistance-group-1, groupId=online-persistance-group] Discovered group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null)
12-08 17:06:17.528 WARN -- [listenerForHeartbeat-0-C-1] o.a.k.c.c.i.ConsumerCoordinator:1165: [Consumer clientId=consumer-online-persistance-group-1, groupId=online-persistance-group] Offset commit failed on partition device-heartbeat-0 at offset 4107111163: This is not the correct coordinator.
12-08 17:06:17.528 INFO -- [listenerForHeartbeat-0-C-1] o.a.k.c.c.i.AbstractCoordinator:849: [Consumer clientId=consumer-online-persistance-group-1, groupId=online-persistance-group] Group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null) is unavailable or invalid, will attempt rediscovery
12-08 17:06:17.566 WARN -- [ListenerForDeviceData-0-C-1] o.a.k.c.c.i.ConsumerCoordinator:1165: [Consumer clientId=consumer-online-persistance-group-3, groupId=online-persistance-group] Offset commit failed on partition device-data-4 at offset 1906711389: This is not the correct coordinator.
12-08 17:06:17.569 INFO -- [ListenerForDeviceData-0-C-1] o.a.k.c.c.i.AbstractCoordinator:849: [Consumer clientId=consumer-online-persistance-group-3, groupId=online-persistance-group] Group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null) is unavailable or invalid, will attempt rediscovery
12-08 17:06:17.634 INFO -- [listenerForHeartbeat-0-C-1] o.a.k.c.c.i.AbstractCoordinator:797: [Consumer clientId=consumer-online-persistance-group-1, groupId=online-persistance-group] Discovered group coordinator 10.30.84.216:9092 (id: 2147483645 rack: null)
^C
2、部分分区(副本为2)复制出现异常,只有leader能正常写入数据,副本永远是不同步状态。
3、有一个节点,CPU很高(其他节点CPU 100%左右,这个节点300%),持续几天一直降不下来。
解决办法
1、问题一无法消费数据,已经显著影响到业务,需要尽快解决。
经过排查,发现只有部分消费者组无法消费,后来经过尝试,发现通过修改consumer group name(换个组名,如果还不行,就再换,大概1/3的概率能行),能临时解决无法消费的问题。
组名更改之后,再把offset reset到服务故障前的时间点,重新进行消费。
kafka-consumer-groups.sh --bootstrap-server xxx --group influxdb_v2_consumers --reset-offsets --all-topics --to-datetime '2023-12-20T00:00:00.000+08:00' --execute
2、CPU高的问题、彻底解决无法消费的问题
通过命令top -Hp 发现只有一个线程cpu占用一直很高(150%),然后用strace命令查看这个线程在干啥:
strace -p $线程ID
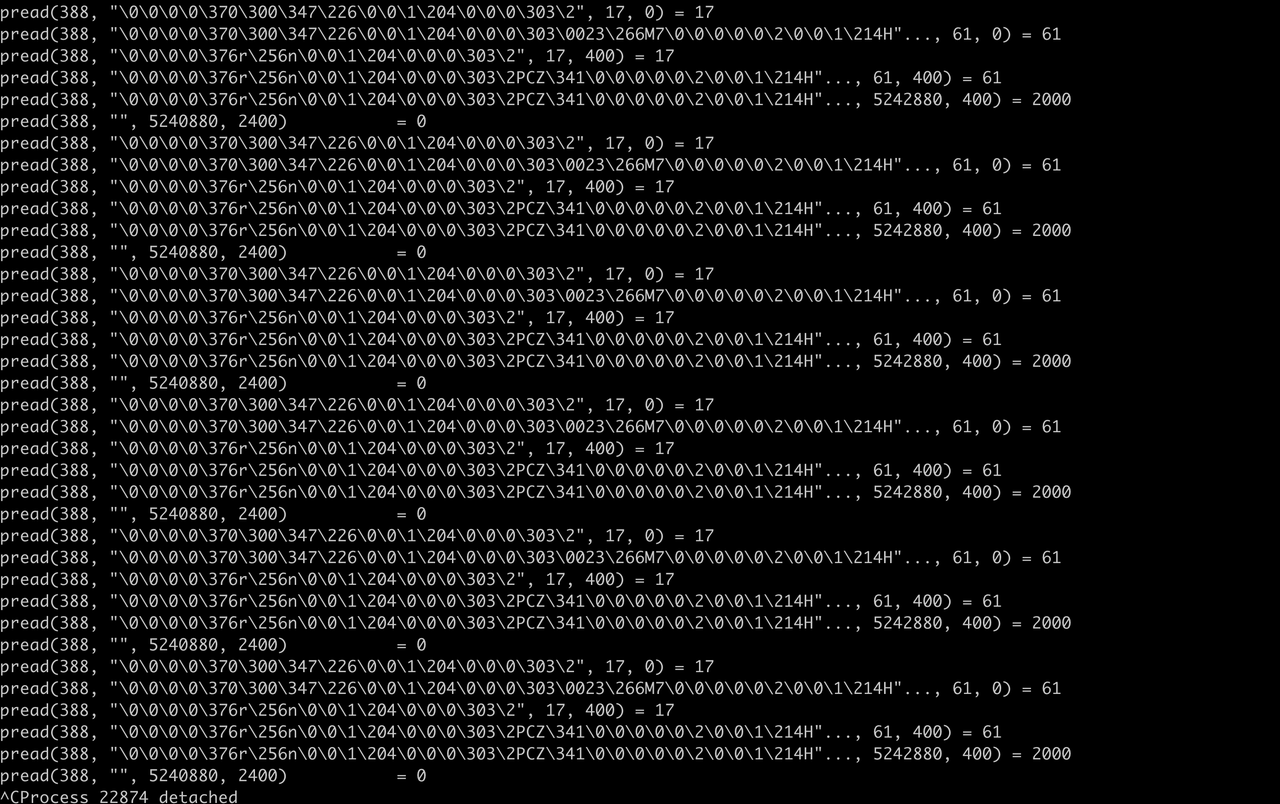
看到该线程在反复读fd为388的文件。下面看看这到底是哪个文件?
cd /prod/进程ID/fd :

这个文件就是/mnt/kafka-logs-new/__consumer_offsets-6/00000000004173391766.log
于是猜测:程序一直在尝试读这个文件,可能是文件出现了损坏,于是出现了死循环,反复读,就导致了CPU很高。
于是就下载了Kafka源码,通过线程名称,找到了相关代码:
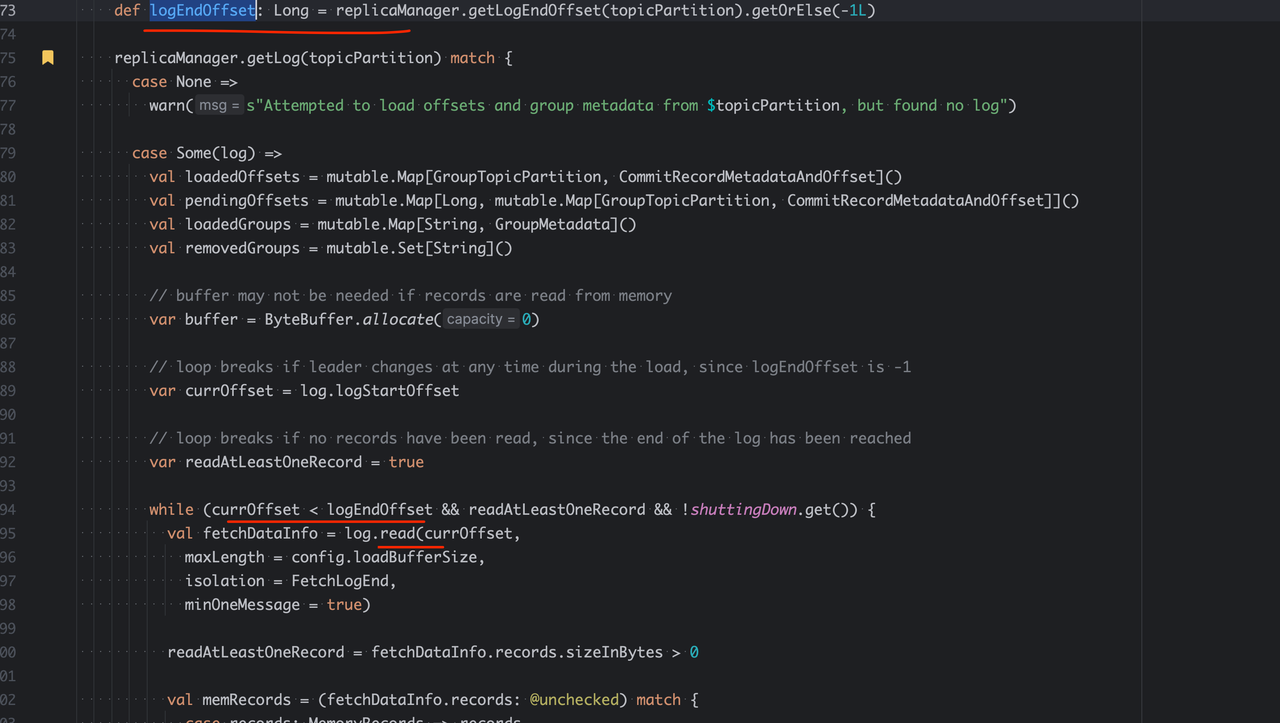
currOffset永远小于logEndOffset,出现了死循环。
然后,我们来验证下/mnt/kafka-logs-new/__consumer_offsets-6/00000000004173391766.log 这个文件是否真的损坏了:
/usr/local/kafka2.8/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files xxx

__consumer_offsets 这个系统内置的topic中,存储的是消费者消费到的offset。前面提到的reset命令,就是通过修改这个topic的值,来重置offset
利用DumpLogSegments这个工具,分析文件,可以看到,最后一个offset(最后一行)的值小于前一行的baseOffset,明显是脏数据。
baseoffset一定是单调自增的才对。 这里涉及到日志压实算法
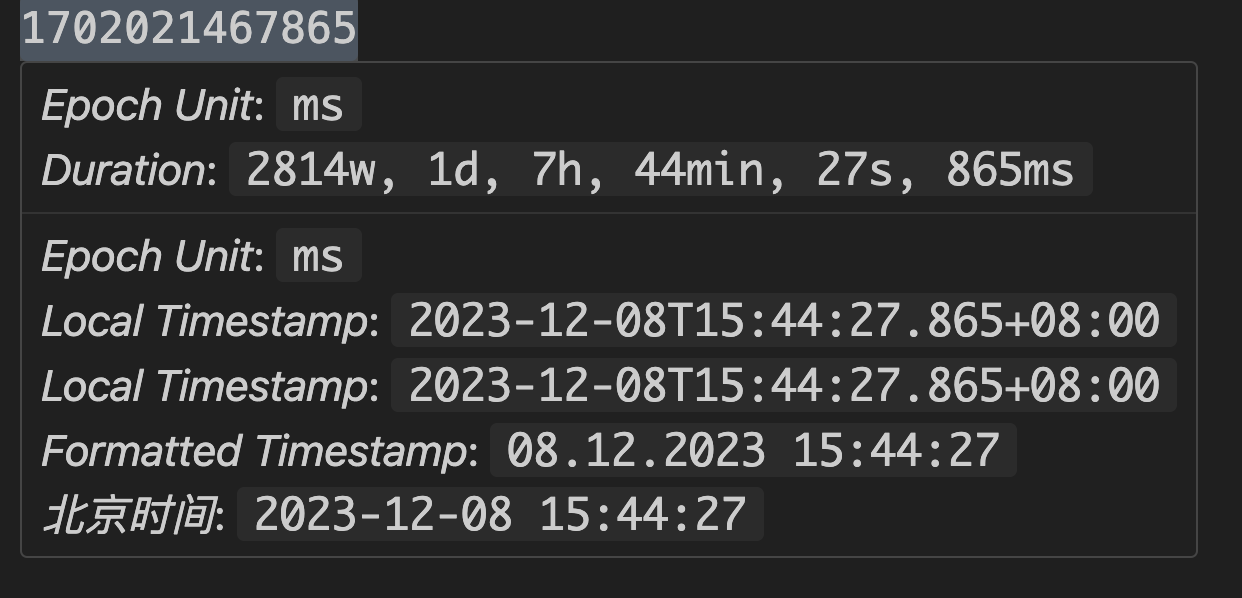
脏数据这一行,正好是当时重启kafka的时间。
到这里,我们有理由相信,由于重启服务器时,Linux系统强制杀死了Kafka进程,导致部分数据丢失。这里涉及到Kafka持久化相关知识:
我们往Kakfa写入数据时,数据并不会实时写入磁盘。数据开始是在内存中,定期调用fsync函数刷新到磁盘。正常情况下,我们通过kafka-server-stop.sh停止kakfa时,会触发flush到磁盘操作。
当linux系统强制杀死kakfa进程时,未刷新到磁盘的数据可能就丢失了。(甚至可能只刷新部分数据到磁盘导致脏数据)
对于Mysql这种强持久性的数据库来讲,即使机器突然关机,我们知道数据也是不会丢失的。这是Kafka的设计缺陷吗?
我记得《Kafka权威指南》上是这么解释的:
当出现broker异常挂掉,或者磁盘损坏等意外时,即使一个broker上数据出现了丢失,由于两台机器同时出现问题的概率极低(几乎不可能),这时候只需要重新进行分区leader选举,选举数据完整的副本作为leader即可。
Kakfa正是结合集群(分区多副本)的特性,即保证了数据写入高性能,由保证了不丢数据。(当然,Kafka要想做到极致可靠,还需要结合其他配置)。
基于这个理论,由于我们集群中__consumer_offset这个topic的副本都是1(数据在服务器上只存在一份)。那么当出现数据损坏之后,就没有可用的副本了。
我们的集群中,__consumer_offset一共有50个分区,大概有1/3 group_name可用,即大概有1/3分区数据未损坏。
前面提到我们重启服务器的方式,有一个broker先stop后重启服务器的,这台机器上的分区未损坏。
分析到这里,原因至少明确了:由于Kafka进程意外被kill,同时__consumer_offset副本是1,重启服务器时有2/3分区数据发生损坏,因此,部分消费者组无法往分区中提交最新的offset。
知识扩展:consumer group name和__consumer_offset分区的关系
public static int getPartationId(String groupName, int numPartitions) {
return Math.abs(groupName.hashCode()) % numPartitions;
}
Kafka是通过这个Hash算法,把消费者组均匀分布到不同的分区上的。
如:组名"test-1211" 对应的分区是2,那么查询这个组的最新offset、以及提交offset,相关数据都存储在分区2
通过这个对应关系,我通过不断尝试,找到了所有数据损坏的分区。
原因找到了,解决方案如下:
1、手动删除损坏的分区的磁盘文件。操作方式参考我在stackoverflow的回答
删除之后,重启集群,会自动重新选举这些分区的leader,此时不管消费者组如何命名都能正常消费了。
另外,CPU高的问题也解决了。
2、把__consumer_offset副本修改为2。后续即使出现一个broker数据损坏,大概率也不会影响到业务。
副本无法同步数据的问题
https://arthas.aliyun.com/doc/ 阿里巴巴这个强大的debug工具要登场了。
我利用这个工具,在线上进行了debug,此种方式不需要重启集群就可以debug,理论上不会影响到java服务正常运行。
但是,我debug的过程中,导致两个broker分别挂掉一次,也有一个broker没挂。猜测是那两台broker剩余内存不足(不足1G),debug过程中需要额外消耗一些内存,可能是内存不足导致jvm进程挂掉。
当然,也可以修改kakfa的log level为debug,然后重启服务,通过打印更多日志,进行问题分析。
我们知道,kakfa数据复制的原理,是在副本节点,单独启动一个(线程数量可配置)线程从leader节点请求最新的数据并写入本地磁盘。
如某一个分区,leader是node1, follower是node2、node3,在node2、3上的复制线程就会不间断地从node1请求数据,然后分别写入本地磁盘。

使用arthas步骤如下:
1、执行thread 线程id命令,查看ReplicaFetcherThread线程的调用栈:
"ReplicaFetcherThread-0-2" Id=64 RUNNABLE (in native)
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at org.apache.kafka.common.network.Selector.select(Selector.java:869)
at org.apache.kafka.common.network.Selector.poll(Selector.java:465)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:561)
at org.apache.kafka.clients.NetworkClientUtils.sendAndReceive(NetworkClientUtils.java:96)
at kafka.server.ReplicaFetcherBlockingSend.sendRequest(ReplicaFetcherBlockingSend.scala:110)
at kafka.server.ReplicaFetcherThread.fetchFromLeader(ReplicaFetcherThread.scala:217)
at kafka.server.AbstractFetcherThread.processFetchRequest(AbstractFetcherThread.scala:325)
at kafka.server.AbstractFetcherThread.$anonfun$maybeFetch$3(AbstractFetcherThread.scala:141)
at kafka.server.AbstractFetcherThread.$anonfun$maybeFetch$3$adapted(AbstractFetcherThread.scala:140)
at kafka.server.AbstractFetcherThread$$Lambda$1111/1577844503.apply(Unknown Source)
at scala.Option.foreach(Option.scala:407)
at kafka.server.AbstractFetcherThread.maybeFetch(AbstractFetcherThread.scala:140)
at kafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:123)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)
writev(415, [{"\0\0\0n\0\1\0\f\0\5\357?\0\22broker-0-fetcher-0"..., 114}], 1) = 114
gettimeofday({1702472083, 17182}, NULL) = 0
clock_gettime(CLOCK_MONOTONIC, {446866, 366197869}) = 0
gettimeofday({1702472083, 17637}, NULL) = 0
gettimeofday({1702472083, 17732}, NULL) = 0
gettimeofday({1702472083, 17851}, NULL) = 0
clock_gettime(CLOCK_MONOTONIC, {446866, 366899839}) = 0
epoll_ctl(428, EPOLL_CTL_MOD, 415, {EPOLLIN, {u32=415, u64=14527132901922832799}}) = 0
gettimeofday({1702472083, 18224}, NULL) = 0
epoll_wait(428, {{EPOLLIN, {u32=415, u64=14527132901922832799}}}, 8192, 30000) = 1
clock_gettime(CLOCK_MONOTONIC, {446866, 367390944}) = 0
gettimeofday({1702472083, 18740}, NULL) = 0
read(415, "\0\0\1\264", 4) = 4
read(415, "\0\5\357?\0\0\0\0\0\0\0+\227 ]\2\23iot-message-pac"..., 436) = 436
gettimeofday({1702472083, 19299}, NULL) = 0
clock_gettime(CLOCK_MONOTONIC, {446866, 368473431}) = 0
gettimeofday({1702472083, 19683}, NULL) = 0
gettimeofday({1702472083, 19969}, NULL) = 0
gettimeofday({1702472083, 20175}, NULL) = 0
write(256, "\0\0\0\0\0006\264\177\0\0\1\\\0\0\0N\2g\370t\305\0\0\0\0\0\0\0\0\1\214c"..., 360) = 360
gettimeofday({1702472083, 20549}, NULL) = 0
clock_gettime(CLOCK_MONOTONIC, {446866, 369913681}) = 0
epoll_wait(428, {}, 8192, 0) = 0
clock_gettime(CLOCK_MONOTONIC, {446866, 370200788}) = 0
gettimeofday({1702472083, 21863}, NULL) = 0
clock_gettime(CLOCK_MONOTONIC, {446866, 370900045}) = 0
gettimeofday({1702472083, 22145}, NULL) = 0
gettimeofday({1702472083, 22299}, NULL) = 0
gettimeofday({1702472083, 22439}, NULL) = 0
gettimeofday({1702472083, 22659}, NULL) = 0
gettimeofday({1702472083, 22910}, NULL) = 0
clock_gettime(CLOCK_MONOTONIC, {446866, 371934106}) = 0
epoll_ctl(428, EPOLL_CTL_MOD, 415, {EPOLLIN|EPOLLOUT, {u32=415, u64=2594990103185064351}}) = 0
gettimeofday({1702472083, 23406}, NULL) = 0
epoll_wait(428, {{EPOLLOUT, {u32=415, u64=2594990103185064351}}}, 8192, 30000) = 1
clock_gettime(CLOCK_MONOTONIC, {446866, 372568772}) = 0
gettimeofday({1702472083, 23791}, NULL) = 0
writev(415, [{"\0\0\0p\0\1\0\f\0\5\357@\0\22broker-0-fetcher-0"..., 116}], 1) = 116
gettimeofday({1702472083, 24115}, NULL) = 0
clock_gettime(CLOCK_MONOTONIC, {446866, 373251612}) = 0
gettimeofday({1702472083, 24962}, NULL) = 0
gettimeofday({1702472083, 25068}, NULL) = 0
gettimeofday({1702472083, 25234}, NULL) = 0
clock_gettime(CLOCK_MONOTONIC, {446866, 374293502}) = 0
epoll_ctl(428, EPOLL_CTL_MOD, 415, {EPOLLIN, {u32=415, u64=14527132901922832799}}) = 0
gettimeofday({1702472083, 26226}, NULL) = 0
epoll_wait(428, ^CProcess 22739 detached
然后我阅读相关源码,“副本复制”步骤如下:
(1)查询所有需要从分区leader复制到本机的分区
(2)循环,依次进行复制。
2、跟踪相关函数的参数、返回值
watch -s kafka.server.ReplicaFetcherThread buildFetch
@ResultWithPartitions[ResultWithPartitions(Some(ReplicaFetch({issue_report_topic-1=PartitionData(fetchOffset=2806, logStartOffset=2362, maxBytes=1048576, currentLeaderEpoch=Optional[89], lastFetchedEpoch=Optional[89]), lx-paper-out-2=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[96], lastFetchedEpoch=Optional.empty), weight-handle-0=PartitionData(fetchOffset=137065, logStartOffset=136635, maxBytes=1048576, currentLeaderEpoch=Optional[12], lastFetchedEpoch=Optional[12]), wifi-data-0=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[120], lastFetchedEpoch=Optional.empty), AIWorkPlan-0=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[109], lastFetchedEpoch=Optional.empty), device-klt-gps-0=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[91], lastFetchedEpoch=Optional.empty), device-jingwei-work-card-1=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[116], lastFetchedEpoch=Optional.empty), device-jinjiang-gp-0=PartitionData(fetchOffset=100970, logStartOffset=100970, maxBytes=1048576, currentLeaderEpoch=Optional[92], lastFetchedEpoch=Optional.empty), pingpp_event_topic-0=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[98], lastFetchedEpoch=Optional.empty), iot-message-gbt-0=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[97], lastFetchedEpoch=Optional.empty), toilet_event_tmp-2=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[88], lastFetchedEpoch=Optional.empty), rfidData-0=PartitionData(fetchOffset=23627, logStartOffset=21654, maxBytes=1048576, currentLeaderEpoch=Optional[101], lastFetchedEpoch=Optional[101]), paas-device-data-2=PartitionData(fetchOffset=2548544, logStartOffset=2425758, maxBytes=1048576, currentLeaderEpoch=Optional[39], lastFetchedEpoch=Optional[39]), water-usage-state-0=PartitionData(fetchOffset=913, logStartOffset=778, maxBytes=1048576, currentLeaderEpoch=Optional[119], lastFetchedEpoch=Optional[119]), global_exception-0=PartitionData(fetchOffset=1238226, logStartOffset=1221531, maxBytes=1048576, currentLeaderEpoch=Optional[72], lastFetchedEpoch=Optional[72]), rfid_heartbeat-0=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[117], lastFetchedEpoch=Optional.empty), mqtt_publish-0=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[120], lastFetchedEpoch=Optional.empty), data-1=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[92], lastFetchedEpoch=Optional.empty), bdevice-bsj-2=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[60], lastFetchedEpoch=Optional.empty), topic-2=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[83], lastFetchedEpoch=Optional.empty), device-hengsheng-work-card-1=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[121], lastFetchedEpoch=Optional.empty), iot-message-packet-0=PartitionData(fetchOffset=3585399, logStartOffset=3389482, maxBytes=1048576, currentLeaderEpoch=Optional[78], lastFetchedEpoch=Optional[78]), iot-message-tianze-0=PartitionData(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[99], lastFetchedEpoch=Optional.empty)},(type=FetchRequest, replicaId=0, maxWait=500, minBytes=1, maxBytes=10485760, fetchData={}, isolationLevel=READ_UNCOMMITTED, toForget=, metadata=(sessionId=731324509, epoch=391210), rackId=))),Set())],
副本不同步的分区,不在这个待复制分区列表中。
然后又完整搜索了下kafka日志:
server.log.2023-12-12-00:kafka.common.OffsetsOutOfOrderException: Out of order offsets found in append to device-paoxiong-2:
server.log.2023-12-08-20:kafka.common.OffsetsOutOfOrderException: Out of order offsets found in append to data-collector-5:
有不少这样的报错,并且,副本不同步的分区,都有这个报错。看起来是因为这些副本的分区数据损坏了,所以复制线程排除了这些分区的数据同步。
解决办法:
1、删除这些分区的数据。涉及分区较多,风险较大。
2、手动移动副本到其他节点。举例,某一个分区原来副本是【2、0】,2是leader,无法复制到0(因为0上的数据损坏了),然后通过工具,把该分区的副本修改为【2、1】,此时数据就能正常复制到1
手动修改副本方法参考
我通过方案2,顺利解决了副本无法复制的问题。
说明:我们开始尝试通过cmake的后台界面进行分区重分配,始终无法成功。
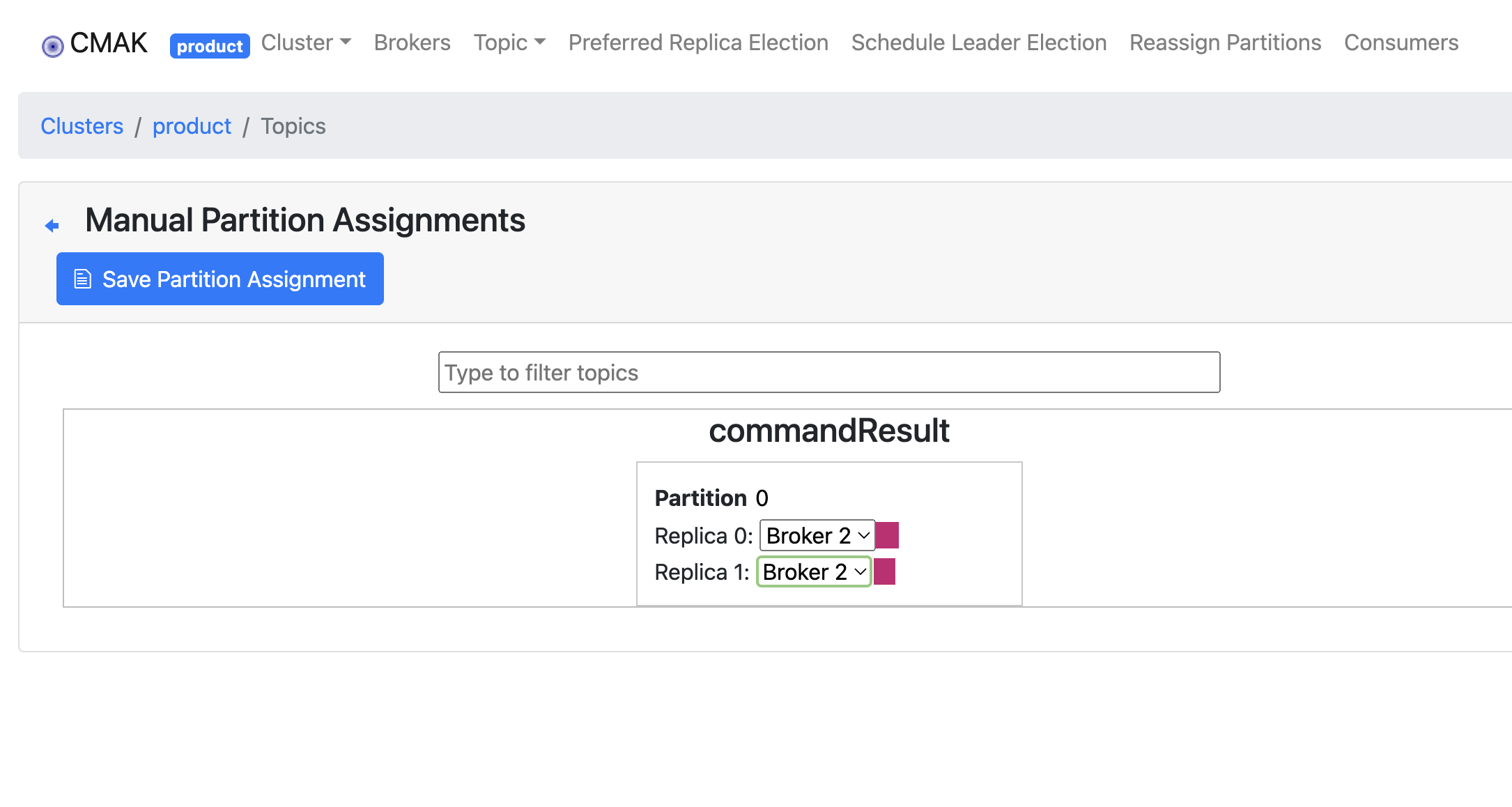
我猜测是因为这个命令的逻辑中,少了一个参数(大概是命令中要加--override选项)。
总结
1、上述描述的问题,我们实际上遇到过两次,一次是kafka2.0升级kafka2.8,集群出现过类似故障,当时找不到解决办法,后来通过清空集群数据,解决了问题。
2、经历过这两次集群重大故障,团队对Kakfa服务的可靠运维出现了担忧,感觉不可控,不知道啥时候就要出幺蛾子。
3、这三个问题的解决,我花费了不少时间(投入时间可能超过36小时)。经历这个过程,至少我对掌控线上Kafka集群信心提升了很多。 后来事实证明也是这样的,最近1个月集群未出现任何问题。
4、解决问题的过程,恰好证明了后端程序员懂Java的重要性。如果不懂Java,就无法通过“阅读源码了解内部机制”的方式定位问题。 因为我们遇到的问题网上资料很少,开始花了大量时间搜索问题,匹配问题很少、关联答案很少。
5、Kafka集群平滑重启很重要、副本大于 1 同样很重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号