分布式存储
转自:http://stor.51cto.com/art/201711/556946.htm
- 一、存储类型
- 二、文件系统
- 三、存储介质
- 四、Raid和副本
- 五、SRVSAN的架构
- 六、SRVSAN的安全隐患
- 七、解决的方法
一、存储类型
一般情况下,我们将存储分成了4种类型,基于本机的DAS和网络的NAS存储、SAN存储、对象存储。对象存储是SAN存储和NAS存储结合后的产物,汲取了SAN存储和NAS存储的优点。
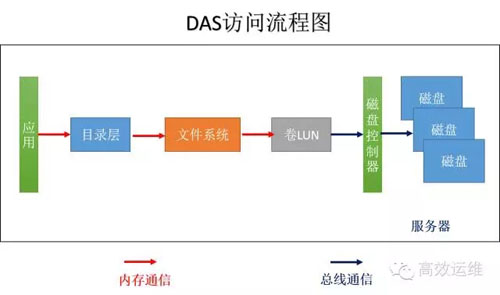
图1
我们来了解一下应用是怎么样获取它想要的存在存储里的某个文件信息,并用大家熟悉的Windows来举例,如图1。
数据访问的流程:
1、应用会发出一个指令“读取本目录下的readme.txt 文件的前1K数据”。
2、通过内存通信到目录层,将相对目录转换为实际目录,“读取C:\ test\readme.txt文件前1K数据”
3、通过文件系统,比如FAT32,通过查询文件分配表和目录项,获取文件存储的LBA地址位置、权限等信息。
文件系统先查询缓存中有没有数据,如果有直接返回数据;没有,文件系统通过内存通信传递到下一环节命令“读取起始位置LBA1000,长度1024的信息”。
4、卷(LUN)管理层将LBA地址翻译成为存储的物理地址,并封装协议,如SCSI协议,传递给下一环节。
5、磁盘控制器根据命令从磁盘中获取相应的信息。
如果磁盘扇区大小是4K,实际一次I/O读取的数据是4K,磁头读取的4K数据到达服务器上的内容后,有文件系统截取前1K的数据传递给应用,如果下次应用再发起同样的请求,文件系统就可以从服务器的内存中直接读取。
不管是DAS、NAS还是SAN,数据访问的流程都是差不多的。
DAS将计算、存储能力一把抓,封装在一个服务器里。大家日常用的电脑,就是一个DAS系统,如图1。
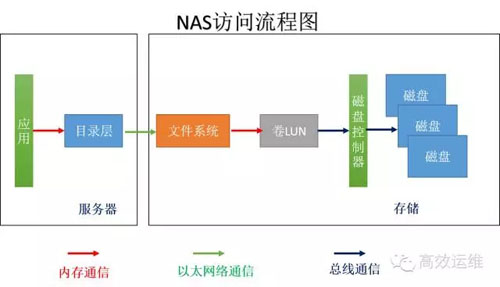
图2
如果将计算和存储分离了,存储成为一个独立的设备,并且存储有自己的文件系统,可以自己管理数据,就是NAS,如图2。
计算和存储间一般采用以太网络连接,走的是CIFS或NFS协议。服务器们可以共享一个文件系统,也就是说,不管服务器讲的是上海话还是杭州话,通过网络到达NAS的文件系统,都被翻译成为普通话。
所以NAS存储可以被不同的主机共享。服务器只要提需求,不需要进行大量的计算,将很多工作交给了存储完成,省下的CPU资源可以干更多服务器想干的事情,即计算密集型适合使用NAS。
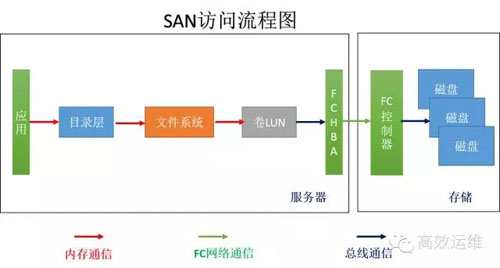
图3
计算和存储分离了,存储成为一个独立的设备,存储只是接受命令不再做复杂的计算,只干读取或者写入文件2件事情,叫SAN,如图3。
因为不带文件系统,所以也叫“裸存储”,有些应用就需要裸设备,如数据库。存储只接受简单明了的命令,其他复杂的事情,有服务器端干了。再配合FC网络,这种存储数据读取/写入的速度很高。
但是每个服务器都有自己的文件系统进行管理,对于存储来说是不挑食的只要来数据我就存,不需要知道来的是什么,不管是英语还是法语,都忠实记录下来的。
但是只有懂英语的才能看懂英语的数据,懂法语的看懂法语的数据。所以,一般服务器和SAN存储区域是一夫一妻制的,SAN的共享性不好。当然,有些装了集群文件系统的主机是可以共享同一个存储区域的。
从上面分析,我们知道,决定存储的快慢是由网络和命令的复杂程度决定的。
内存通信速度>总线通信>网络通信
网络通信中还有FC网络和以太网络。FC网络目前可以实现8Gb/s,但以太网络通过光纤介质已经普及10Gb/s,40Gb/s的网卡也在使用了。也就是说传统以太网络已经不是存储的瓶颈了。除了FCSAN,IPSAN也是SAN存储的重要成员。
对存储的操作,除了熟悉的读/写以外,其实还有创建、打开、获取属性、设置属性、查找等等。
对于有大脑的SAN存储来说,除了读/写以外的命令,都可以在本地内存中完成,速度极快。
而NAS存储缺乏大脑,每次向存储传递命令,都需要IP封装并通过以太网络传递到NAS服务器上,这个速度就远远低于内存通信了。
- DAS特点是速度最快,但只能自己用;
- NAS的特点速度慢点但共享性好;
- SAN的特点是速度快,但共享性差。
总体上来讲,对象存储同兼具SAN高速直接访问磁盘特点及NAS的分布式共享特点。
NAS存储的基本单位是文件,SAN存储的基本单位是数据块,而对象存储的基本单位是对象,对象可以认为是文件的数据+一组属性信息的组合,这些属性信息可以定义基于文件的RAID参数、数据分布和服务质量等。
采取的是“控制信息”和“数据存储”分离的模式,客户端用对象ID+偏移量作为读写的依据,客户端先从“控制信息”获取数据存储的真实地址,再直接从“数据存储”中访问。
对象存储大量使用在互联网上,大家使用的网盘就是典型的对象存储。对象存储有很好的扩展性,可以线性扩容。并可以通过接口封装,还可以提供NAS存储服务和SAN存储服务。
VMware的vSAN本质就是一个对象存储。分布式对象存储就是SRVSAN的一种,也存在安全隐患。因为这个隐患是X86服务器带来的。
二、文件系统
计算机的文件系统是管理文件的“账房先生”。
- 首先他要管理仓库,要知道各种货物都放在哪里;
- 然后要控制货物的进出,并要确保货物的安全。
如果没有这个“账房先生”,让每个“伙计”自由的出入仓库,就会导致仓库杂乱无章、货物遗失。
就像那年轻纺城机房刚启用的时候,大家的货物都堆在机房里,没有人统一管理,设备需要上架的时候,到一大堆货物中自行寻找,安装后的垃圾也没有人打扫,最后连堆积的地方都找不到,有时自己的货物找不到了,找到别人的就使用了……。
大家都怨声载道,后来建立了一个仓库,请来了仓库管理员,用一本本子记录了货物的归宿和存储的位置,建立货物的出入库制度,问题都解决了,这就是文件系统要做的事情。
文件系统管理存取文件的接口、文件的存储组织和分配、文件属性的管理(比如文件的归属、权限、创建事件等)。
每个操作系统都有自己的文件系统。比如windows就有常用的FAT、FAT32、NTFS等,Linux用ext1-4的等。
存储文件的仓库有很多中形式,现在主要用的是(机械)磁盘、SSD、光盘、磁带等等。
拿到这些介质后,首先需要的是“格式化”,格式化就是建立文件存储组织架构和“账本”的过程。比如将U盘用FAT32格式化,我们可以看到是这样架构和账本(如图4):

图4
主引导区:记录了这个存储设备的总体信息和基本信息。比如扇区的大小,每簇的大小、磁头数、磁盘扇区总数、FAT表份数、分区引导代码等等信息。
分区表:,即此存储的账本,如果分区表丢失了,就意味着数据的丢失,所以一般就保留2份,即FAT1和FAT2。分区表主要记录每簇使用情况,当这位置的簇是空的,就代表还没有使用,有特殊标记的代表是坏簇,位置上有数据的,是指示文件块的下一个位置。
目录区:目录和记录文件所在的位置信息。
数据区:记录文件具体信息的区域。
通过以下的例子来帮助理解什么是FAT文件系统。
假设每簇8个扇区组成一个簇,大小是512*8=4K。根目录下的readme.txt文件大小是10K,如图5:
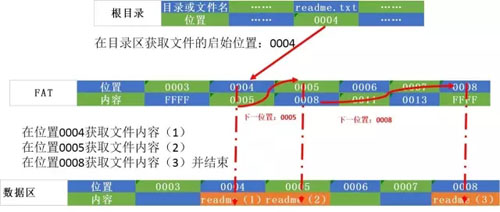
图5
- 1、在目录区找到根目录下文件readme.txt在FAT表中的位置是0004
- 2、在0004位置对应簇的8个扇区读取相应文件块readme(1)保存在内存,并获取下一个数据块的位置0005。
- 3、在0005位置对应簇的8个扇区读取相应文件块readme(2)保存在内存,并获取下一个数据块的位置0008。
- 4、在0005位置对应簇的4个扇区读取相应文件块readme(3)保存在内存,并获得结束标志。
- 5、将readme(1)、readme(2)、readme(3)组合成为readme文件。
在这个例子中,我们看到在FAT文件系统,是通过查询FAT表和目录项来确定文件的存储位置,文件分布是以簇为单位的数据块,通过“链条”的方式来指示文件数据保存的文字。
当要读取文件时,必须从文件头开始读取。这样的方式,读取的效率不高。
不同的Linux文件系统大同小异,一般都采取ext文件系统,如图6.

图6
启动块内是服务器开机启动使用的,即使这个分区不是启动分区,也保留。
超级块存储了文件系统的相关信息,包括文件系统的类型,inode的数目,数据块的数目
Inodes块是存储文件的inode信息,每个文件对应一个inode。包含文件的元信息,具体来说有以下内容:
文件的字节数
文件拥有者的User ID
文件的Group ID
文件的读、写、执行权限
文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
链接数,即有多少文件名指向这个inode
文件数据block的位置
当查看某个目录或文件时,会先从inode table中查出文件属性及数据存放点,再从数据块中读取数据。
数据块:存放目录和文件数据。
通过读取\var\readme.txt文件流程,来理解ext文件系统,如图7。
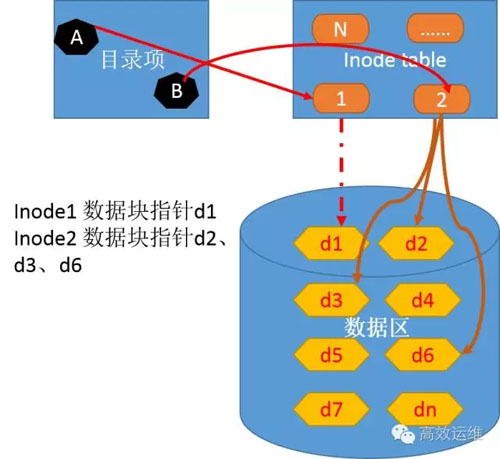
图7
- 1、根目录A所对应的inode节点是2,inode1对应的数据块是d1。
- 2、在检索d1内容发现,目录var对应的inode=28,对应的数据块是d5。
- 3、检索d5内容发现readme.txt对应的是inode=70。
- 4、Inode70指向数据区d2、d3、d6块。读取这些数据块,在内存中组合d2、d3、d6数据块。
硬盘格式化的时候,操作系统自动将硬盘分成两个区域。
- 一个是数据区,存放文件数据;
- 另一个是inode区,存放inode所包含的信息。
当inode资源消耗完了,尽管数据区域还有空余空间,都不能再写入新文件。
总结:Windows的文件系统往往是“串行”的,而linux的文件系统是“并行”的。
再来看分布式的文件系统。
如果提供持久化层的存储空间不是一台设备,而是多台,每台之间通过网络连接,数据是打散保存在多台存储设备上。也就是说元数据记录的不仅仅记录在哪块数据块的编号,还要记录是哪个数据节点的。
这样,元数据需要保存在每个数据节点上,而且必须实时同步。做到这一点其实很困难。如果把元数据服务器独立出来,做成“主从”架构,就不需要在每个数据节点维护元数据表,简化了数据维护的难度,提高了效率。
Hadoop的文件系统HDFS就是一个典型的分布式文件系统。
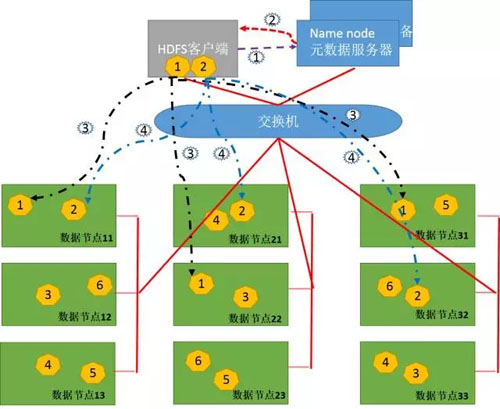
图8
- 1、Client将FileA按64M分块。分成两块,block1和Block2。
- 2、Client向nameNode发送写数据请求,如图紫色虚线1。
- 3、NameNode节点,记录block信息。并返回可用的DataNode给客户端,如图红色虚线2。
Block1: host11,host22,host31
Block2: host11,host21,host32
- 4、client向DataNode发送block1;发送过程是以流式写入。
流式写入过程:
1)将64M的block1按64k的package划分;
2)然后将第一个package发送给host11;
3)host11接收完后,将第一个package发送给host22,同时client想host11发送第二个package;
4)host22接收完第一个package后,发送给host31,同时接收host11发来的第二个package。
5)以此类推,如图黑色虚线3所示,直到将block1发送完毕。
6)host11,host22,host31向NameNode和 Client发送通知,说“消息发送完了”。
7)client收到发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。
8)发送完block1后,再向host11,host21,host32发送block2,如图蓝色虚线4所示。
……….
HDFS是分布式存储的雏形,分布式存储将在以后详细介绍。
三、存储介质
仓库有很多种存储的介质,现在最常用的是磁盘和SSD盘,还有光盘、磁带等等。磁盘一直以性价比的优势占据了霸主的地位。
圆形的磁性盘片装在一个方的密封盒子里,运行起来吱吱的响,这就是我们常见的磁盘。磁片是真正存放数据的介质,每个磁片正面和背面上都“悬浮”着磁头。
磁盘上分割为很多个同心圆,每个同心圆叫做磁道,每个磁道又被分割成为一个个小扇区,每个扇区可以存储512B的数据。当磁头在磁片上高速转动和不停换道,来读取或者写入数据。
其实磁片负责高速转动,而磁头只负责在磁片上横向移动。决定磁盘性能的主要是磁片的转速、磁头的换道、磁盘、每片磁片的容量和接口速度决定的。转速越高、换道时间越短、单片容量越高,磁盘性能就越好。

图9

图10
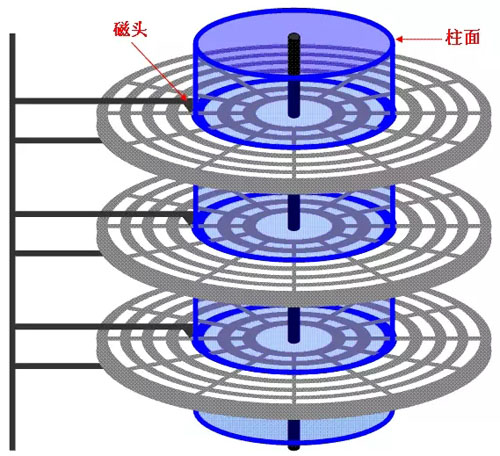
图11
衡量磁盘性能主要参考 IOPS 和吞吐量两个参数。
IOPS就是一秒钟内磁盘进行了多少次的读写。
吞吐量就是读出了多少数据。
其实这些指标应该有前提,即是大包(块)还是小包(块),是读还是写,是随机的还是连续的。一般我们看到厂家给的磁盘IOPS性能一般是指小包、顺序读下的测试指标。这个指标一般就是最大值。
目前在X86服务器上我们常使用的 SATA、SAS磁盘性能:

图12
实际生产中估算,SATA 7200转的磁盘,提供的IOPS为60次左右,吞吐量在70MB/s。
我们2014年首次使用的裸容量2P的SRVSAN存储的数据持久化层采用57台X86服务器,内置12块SATA7200 3TB硬盘。共684块磁盘,大约只提供41040次IOPS和47.88GB/s。
这些指标显然是不能满足存储需要的,需要想办法“加速”。
机械磁盘其实也做了很多优化,比如扇区地址的编号不是连续的。
因为磁片转的够快(7200转/分钟即1秒钟转120转,转一圈是8.3毫秒,也就是在读写同一个磁道最大时延是8.3秒),防止磁头的读写取错过了,所以扇区的地址并不是连续的,而是跳跃编号的,比如2:1的交叉因子(1、10、2、11、3、12…..)。
同时磁盘也有缓存,具有队列,并不是来一个I/O就读写一个,而是积累到一定I/O,根据磁头的位置和算法完成的。I/O并不是一定是“先到先处理”,而是遵守效率。
加速最好的办法就是使用SSD盘。磁盘的控制部分是由机械部分+控制电路来构成,机械部分的速度限制,使磁盘的性能不可能有大的突破。而SSD采用了全电子控制可以获得很好的性能。
SSD是以闪存作为存储介质再配合适当的控制芯片组成的存储设备。目前用来生产固态硬盘的NAND Flash有三种:
- 单层式存储(SLC,存储1bit数据)
- 二层式存储(MLC,存储4bit数据)
- 三层式存储(TLC,存储8bit数据)
SLC成本最高、寿命最长、但访问速度最快,TLC成本最低、寿命最短但访问速度最慢。为了降低成本,用于服务器的企业级SSD都用了MLC,TLC可以用来做U盘。

图13
SSD普及起来还有一点的障碍,比如成本较高、写入次数限制、损坏时的不可挽救性及当随着写入次数增加或接近写满时候速度会下降等缺点。
对应磁盘的最小IO单位扇区,page是SSD的最小单位。
比如每个page存储512B的数据和218b的纠错码,128个page组成一个块(64KB),2048个块,组成一个区域,一个闪存芯片有2个区域组成。Page的尺寸越大,这个闪讯芯片的容量就越大。
但是SSD有一个坏习惯,就是在修改某1个page的数据,会波及到整块。需要将这个page所在的整块数据读到缓存中,然后再将这个块初始化为1,再从缓存中读取数据写入。
对于SSD来说,速度可能不是问题,但是写的次数是有限制的,所以块也不是越大越好。当然对于机械磁盘来说也存在类似问题,块越大,读写的速度就越快,但浪费也越严重,因为写不满一块也要占一块的位置。
不同型号不同厂家的SSD性能差异很大,下面是我们的分布式块存储作为缓存使用的SSD参数:
采用PCIe 2.0接口,容量是1.2T,综合读写IOPS(4k小包)是260000次,读吞吐量1.55GB/s,写吞吐量1GB/s。
在1台SRVSAN的服务器配置了一块SSD作为缓存和12块7200转 3T SATA盘,磁盘只提供1200次、1200M的吞出量。
远远小于缓存SSD提供的能力,所以直接访问缓存可以提供很高的存储性能,SRVSAN的关键是计算出热点数据的算法,提高热点数据的命中率。
用高成本的SSD做为缓存,用廉价的SATA磁盘作为容量层。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号