问题 1
kubectl get nodes
[root@master artifactory]# kubectl get nodes The connection to the server 192.168.72.123:6443 was refused - did you specify the right host or port?
问题处理
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
- 配置KUBECONFIG 环境变量
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
- 安装网络插件 Flannel(只需要在 Master 安装 flannel)
kubectl apply -f kubeblog/docs/Chapter4/flannel.yaml
- 查看是否成功创建flannel网络
ifconfig |grep flan flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
等待大约 10 分钟,检查Kubernetes master运行情况:
[root@localhost ~]# kubectl get node NAME STATUS ROLES AGE VERSION master Ready master 10m v1.19.3
如果上面的配置都已有配置过还是报上面则还检查下三台服务器的时间是否同步已经时间是否正确。
可以把时间校正的命令写入计划任务让其每分钟执行下
还有是电脑异常关机导致的
docker images看下etcd在哪台机器上
删除etcd pod的数据
rm -rf /var/lib/etcd/
删除之后重启docker、重启kubelet
systemctl restart docker
systemctl restart kubelet
这时候可能还会出现flannel pod启动异常
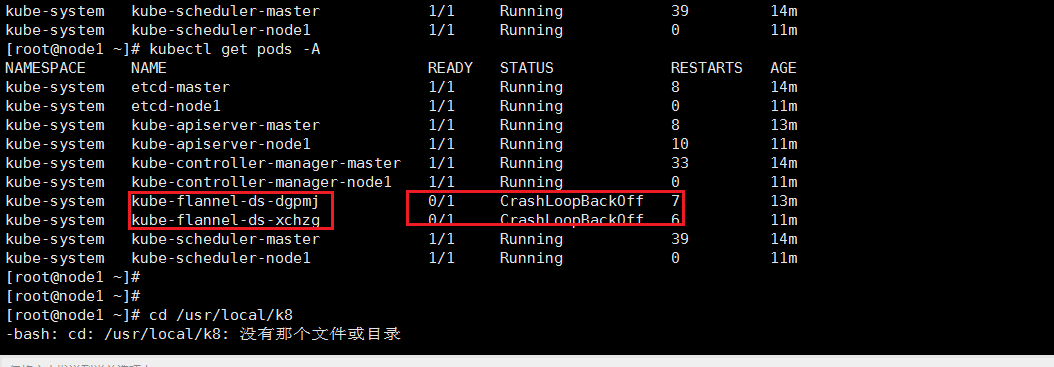
使用下面的yml文件
下面标红的这一段要改为master ip 并且要保证 kube-api是运行正常的
value: "192.168.72.123" #ip address of the host where kube-apiservice is running
--- kind: Namespace apiVersion: v1 metadata: name: kube-system labels: pod-security.kubernetes.io/enforce: privileged --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: flannel rules: - apiGroups: - "" resources: - pods verbs: - get - apiGroups: - "" resources: - nodes verbs: - list - watch - apiGroups: - "" resources: - nodes/status verbs: - patch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: flannel roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: flannel subjects: - kind: ServiceAccount name: flannel namespace: kube-system --- apiVersion: v1 kind: ServiceAccount metadata: name: flannel namespace: kube-system --- kind: ConfigMap apiVersion: v1 metadata: name: kube-flannel-cfg namespace: kube-system labels: tier: node app: flannel data: cni-conf.json: | { "name": "cbr0", "cniVersion": "0.3.1", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" } } --- apiVersion: apps/v1 kind: DaemonSet metadata: name: kube-flannel-ds namespace: kube-system labels: tier: node app: flannel spec: selector: matchLabels: app: flannel template: metadata: labels: tier: node app: flannel spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/os operator: In values: - linux hostNetwork: true priorityClassName: system-node-critical tolerations: - operator: Exists effect: NoSchedule serviceAccountName: flannel initContainers: - name: install-cni-plugin #image: flannelcni/flannel-cni-plugin:v1.1.0 for ppc64le and mips64le (dockerhub limitations may apply) image: registry.cn-beijing.aliyuncs.com/free4lab/mirrored-flannelcni-flannel-cni-plugin:v1.1.0 command: - cp args: - -f - /flannel - /opt/cni/bin/flannel volumeMounts: - name: cni-plugin mountPath: /opt/cni/bin - name: install-cni #image: flannelcni/flannel:v0.19.0 for ppc64le and mips64le (dockerhub limitations may apply) image: registry.cn-beijing.aliyuncs.com/free4lab/mirrored-flannelcni-flannel:v0.19.0 command: - cp args: - -f - /etc/kube-flannel/cni-conf.json - /etc/cni/net.d/10-flannel.conflist volumeMounts: - name: cni mountPath: /etc/cni/net.d - name: flannel-cfg mountPath: /etc/kube-flannel/ containers: - name: kube-flannel #image: flannelcni/flannel:v0.19.0 for ppc64le and mips64le (dockerhub limitations may apply) image: registry.cn-beijing.aliyuncs.com/free4lab/mirrored-flannelcni-flannel:v0.19.0 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr resources: requests: cpu: "100m" memory: "50Mi" limits: cpu: "100m" memory: "50Mi" securityContext: privileged: false capabilities: add: ["NET_ADMIN", "NET_RAW"] env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: KUBERNETES_SERVICE_HOST value: "192.168.72.123" #ip address of the host where kube-apiservice is running - name: KUBERNETES_SERVICE_PORT value: "6443" - name: EVENT_QUEUE_DEPTH value: "5000" volumeMounts: - name: run mountPath: /run/flannel - name: flannel-cfg mountPath: /etc/kube-flannel/ - name: xtables-lock mountPath: /run/xtables.lock volumes: - name: run hostPath: path: /run/flannel - name: cni-plugin hostPath: path: /opt/cni/bin - name: cni hostPath: path: /etc/cni/net.d - name: flannel-cfg configMap: name: kube-flannel-cfg - name: xtables-lock hostPath: path: /run/xtables.lock type: FileOrCreate
资源不够,exitd状态的的容器太多了
处理方式:删除所有exited状态的容器
docker container prune
主要查看kube-system命令空间下的pod将error状态的delete销毁重建
kubectl delete pod coredns-7ff77c879f-rl6qh -n kube-system
kubectl get pods --all-namespaces
加入集群报错
问题token失效
如果之前有加入报错则需要先执行kubeadm reset 重置
然后还要删除.kube/config文件
[root@node1 ~]# kubeadm join 192.168.72.123:6443 --token e94oe2.88o6pl7h5ghxgbmb --discovery-token-ca-cert-hash sha256:93345ca08ef459b1f361e97b123e6adf038d0995beb045d96c70e2dc0c266961
W0719 16:55:24.889101 1297 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
error execution phase preflight: couldn't validate the identity of the API Server: could not find a JWS signature in the cluster-info ConfigMap for token ID "e94oe2"
重新生成token再加入
root@master ~]# kubeadm token create --print-join-command W0720 01:12:48.136121 21669 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io] kubeadm join 192.168.72.123:6443 --token 58dh6w.luoqsvoscuugft70 --discovery-token-ca-cert-hash sha256:93345ca08ef459b1f361e97b123e6adf038d0995beb045d96c70e2dc0c266961
最后为保证关机后节点状态依然为ready还需要将主节点的配置文件拷贝到从节点
拷贝后同样执行下面同样的操作
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kube-system下的很多节点服务运行不正常
kubectl get pods -A
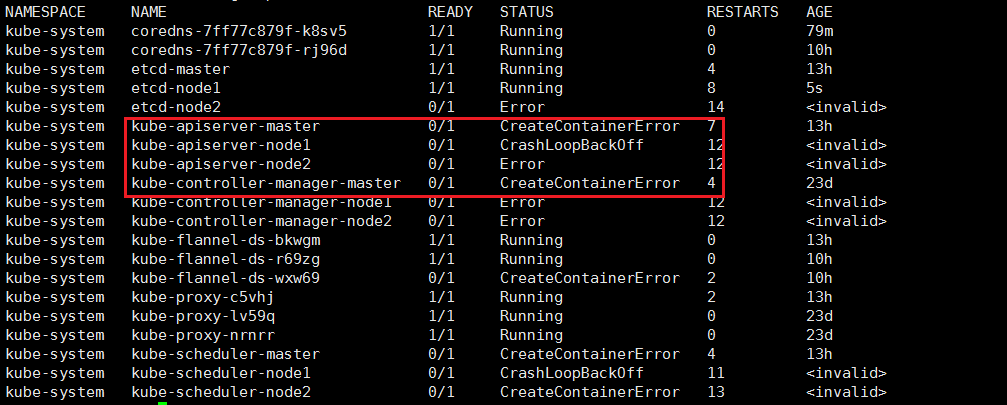
排查方法:
kubectl logs 查看
2024-07-20 09:58:54.106164 I | etcdmain: etcd Version: 3.4.3 2024-07-20 09:58:54.106269 I | etcdmain: Git SHA: 3cf2f69b5 2024-07-20 09:58:54.106278 I | etcdmain: Go Version: go1.12.12 2024-07-20 09:58:54.106286 I | etcdmain: Go OS/Arch: linux/amd64 2024-07-20 09:58:54.106294 I | etcdmain: setting maximum number of CPUs to 2, total number of available CPUs is 2 2024-07-20 09:58:54.106315 N | etcdmain: failed to detect default host (could not find default route) [WARNING] Deprecated '--logger=capnslog' flag is set; use '--logger=zap' flag instead 2024-07-20 09:58:54.106639 I | embed: peerTLS: cert = /etc/kubernetes/pki/etcd/peer.crt, key = /etc/kubernetes/pki/etcd/peer.key, trusted-ca = /etc/kubernetes/pki/etcd/ca.crt, client-cert-auth = true, crl-file = 2024-07-20 09:58:54.106887 C | etcdmain: listen tcp 192.168.72.123:2380: bind: cannot assign requested address
[root@master ~]# kubectl logs etcd-node1 -n kube-system [WARNING] Deprecated '--logger=capnslog' flag is set; use '--logger=zap' flag instead 2024-07-20 03:35:46.479416 I | etcdmain: etcd Version: 3.4.3 2024-07-20 03:35:46.479524 I | etcdmain: Git SHA: 3cf2f69b5 2024-07-20 03:35:46.479530 I | etcdmain: Go Version: go1.12.12 2024-07-20 03:35:46.479534 I | etcdmain: Go OS/Arch: linux/amd64 2024-07-20 03:35:46.479538 I | etcdmain: setting maximum number of CPUs to 2, total number of available CPUs is 2 2024-07-20 03:35:46.479617 N | etcdmain: the server is already initialized as member before, starting as etcd member... [WARNING] Deprecated '--logger=capnslog' flag is set; use '--logger=zap' flag instead 2024-07-20 03:35:46.479679 I | embed: peerTLS: cert = /etc/kubernetes/pki/etcd/peer.crt, key = /etc/kubernetes/pki/etcd/peer.key, trusted-ca = /etc/kubernetes/pki/etcd/ca.crt, client-cert-auth = true, crl-file = 2024-07-20 03:35:46.479837 C | etcdmain: open /etc/kubernetes/pki/etcd/peer.crt: no such file or directory [root@master ~]# ll /etc/kubernetes/pki/etcd/peer.crt -rw-r--r-- 1 root root 1127 6月 26 17:28 /etc/kubernetes/pki/etcd/peer.crt [root@master ~]# ll /etc/kubernetes/pki/etcd/peer.crt -rw-r--r-- 1 root root 1127 6月 26 17:28 /etc/kubernetes/pki/etcd/peer.crt
根据报错发现是node1节点的/etc/kubernetes/manifests/etcd.yaml的地址绑定不正确
解决方法把下面的etcd.yaml文件里的对应地址改为相对应的地址
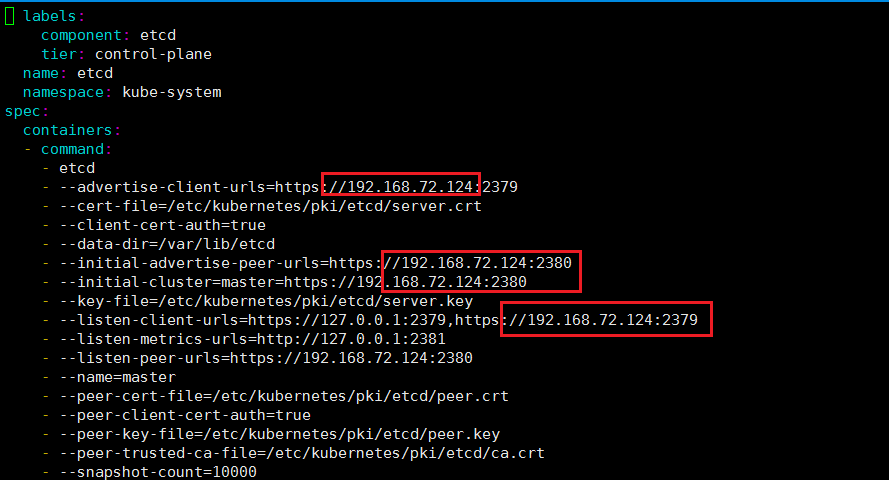
针对第二个问题的peer.cart则可以把主节点的文件拷贝到从节点
scp /etc/kubernetes/pki/etcd/* root@192.168.72.124:/etc/kubernetes/pki/etcd/
同理其他kube-system的pod也是同样的排查方法
scp /etc/kubernetes/pki/apiserver* root@192.168.72.125:/etc/kubernetes/pki/
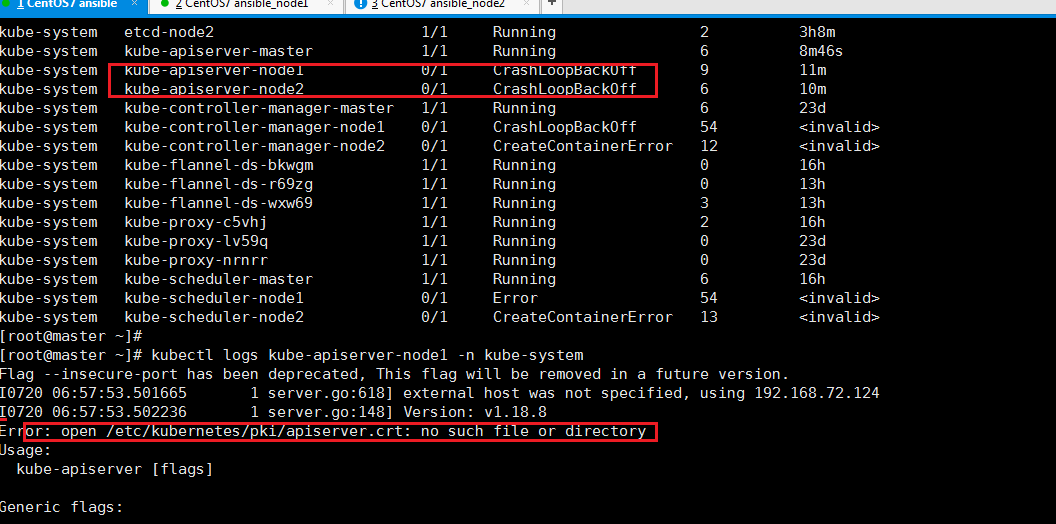
拷贝过去后都要重启kubelet
scp /etc/kubernetes/controller-manager.conf root@192.168.72.124:/etc/kubernetes/
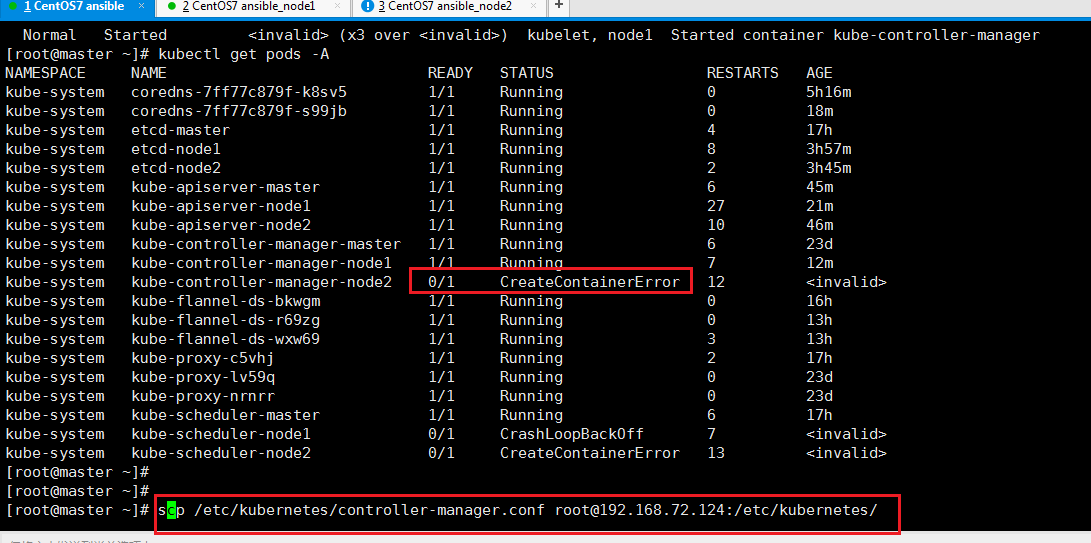
如果还是不行可以先删除 Exited的的容器然后再重启kubelet并且再销毁重建pod
删除所有已退出的容器:
docker container prune
查看事件
kubectl get events -n kube-system
查看kubelet最后100行日志
journalctl -u kubelet -n 100
健康检查的报错
使用下面的kubectl describe命令可以看到健康检查的报错
kubectl describe pod jenkins-74f9d74bb4-m9p5z -n jenkins-k8s
Warning Unhealthy 64s (x3 over 82s) kubelet, master Liveness probe failed: HTTP probe failed with statuscode: 503
pod的状态是running READY的为 0/1
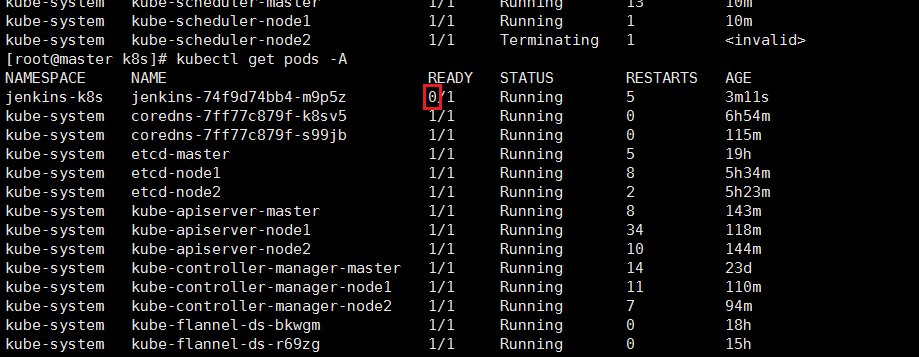
解决方法:更改健康检查的配置,调大时间。如果还是不行可以先去掉试下然后再调试健康检查的时间参数
name: agent protocol: TCP resources: limits: cpu: 1000m memory: 700Mi requests: cpu: 500m memory: 512Mi #livenessProbe: # httpGet: # path: /login # port: 8080 #initialDelaySeconds: 60 #timeoutSeconds: 5 #failureThreshold: 12 #readinessProbe: # httpGet: # path: /login # port: 8080 #initialDelaySeconds: 60 #timeoutSeconds: 5 #failureThreshold: 12 volumeMounts: - name: jenkins-volume

 浙公网安备 33010602011771号
浙公网安备 33010602011771号