热迁移虚拟机报rpc超时
问题背景:
南网生产V区,热迁移虚拟机偶发性失败。
问题现象:
热迁移虚拟机有时候能成功,有时候直接报错。
影响范围:
影响热迁移功能
问题排查过程:
- 现场反馈源节点7需要做停机整改,所以需要将源节点7上的虚拟机热迁移走。现在迁移成功两台,然后再迁移就报错了。
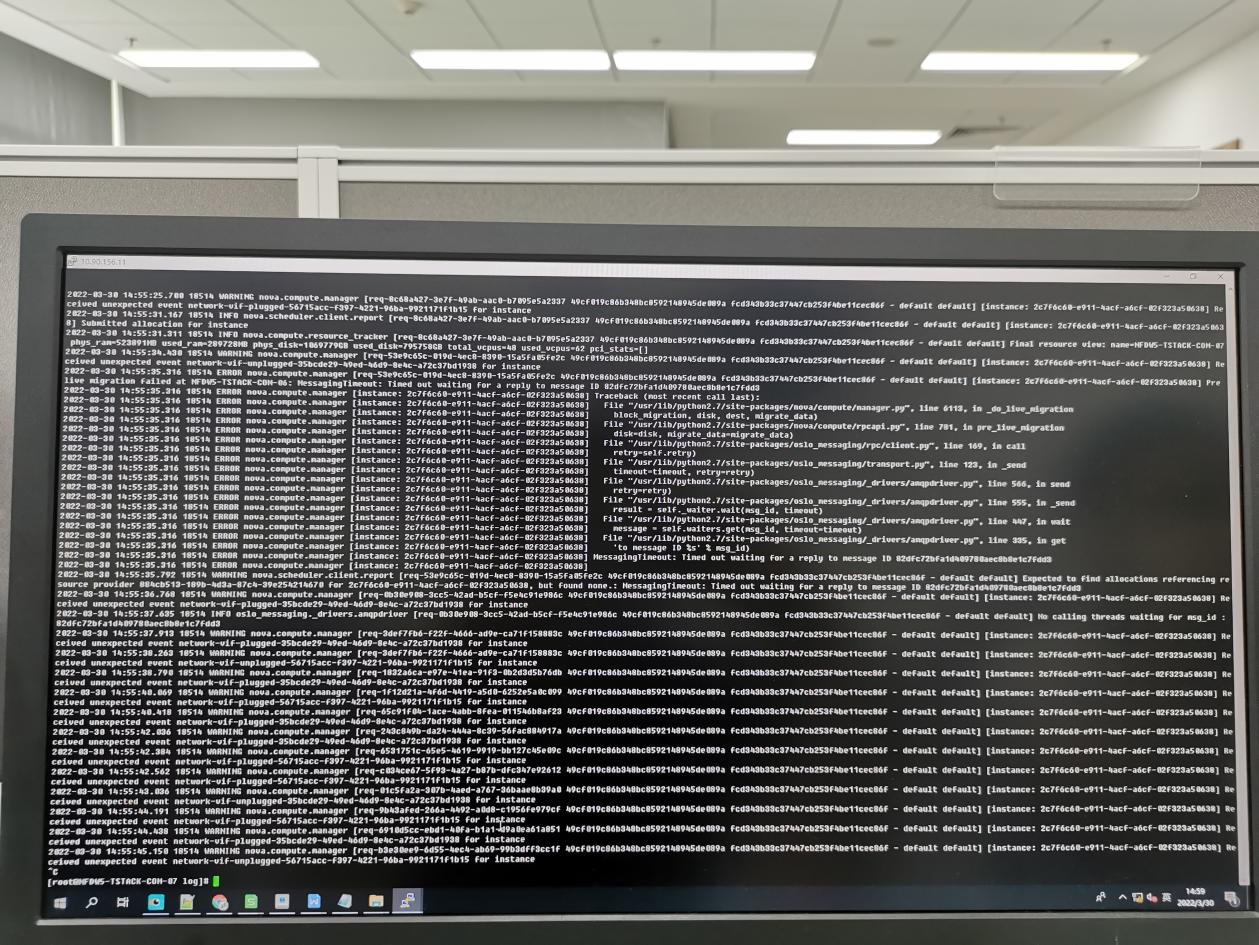
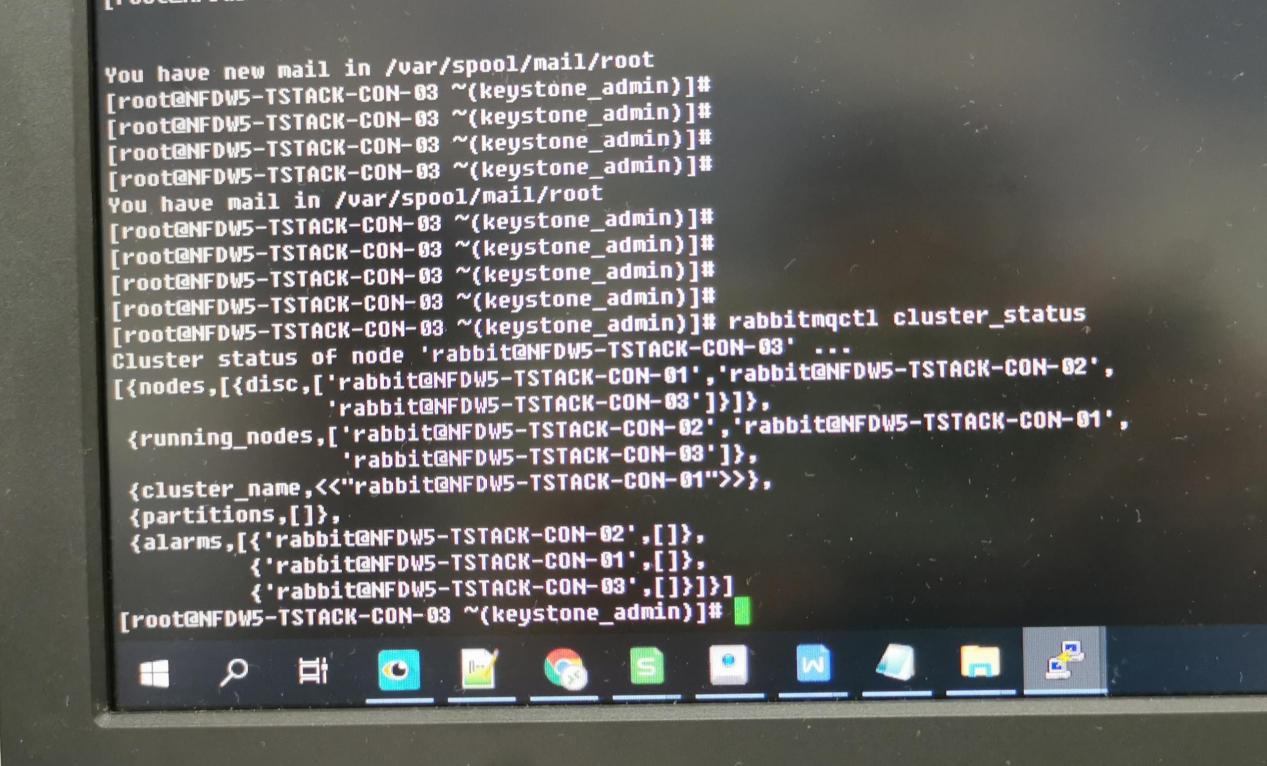
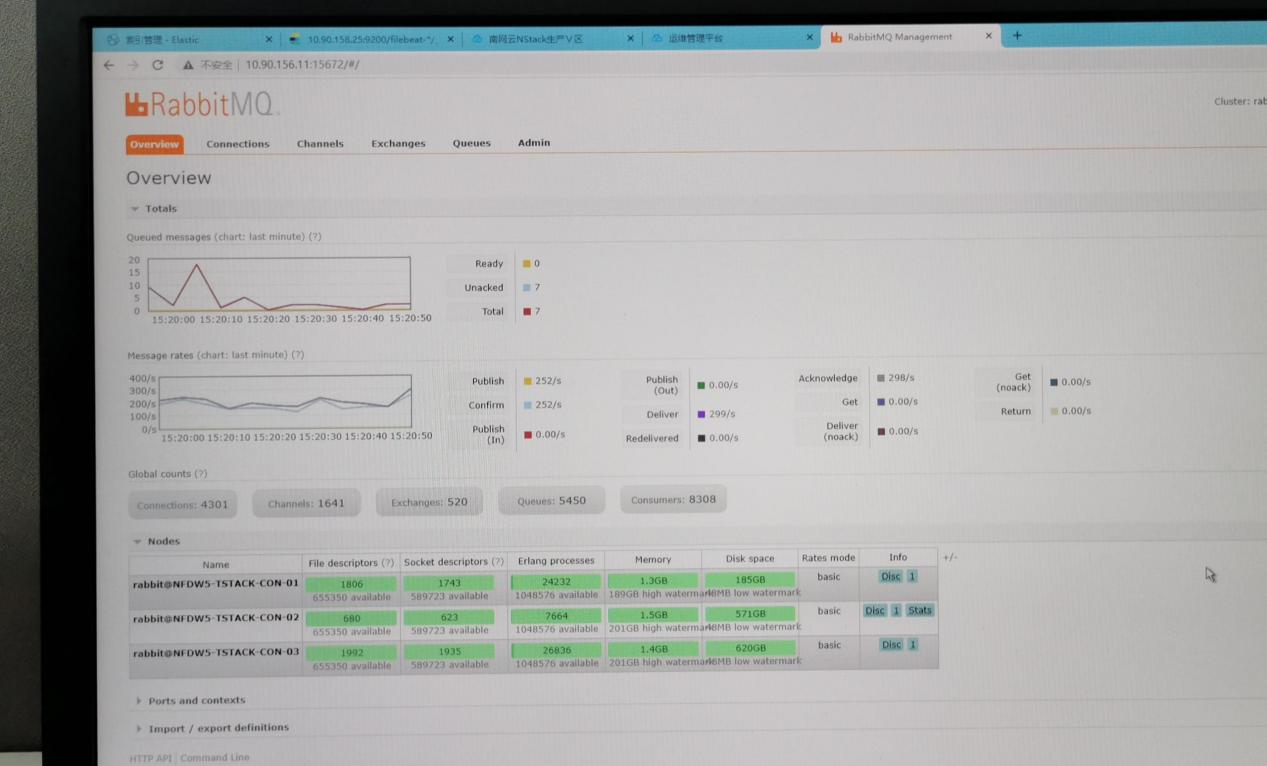
- 看到nova-compute报错第一时间想到是rabbitmq集群可能有问题,让现场检查了下rabbitmq集群状态和消息队列是否有堆积。结果是集群状态正常,消息队列无堵塞
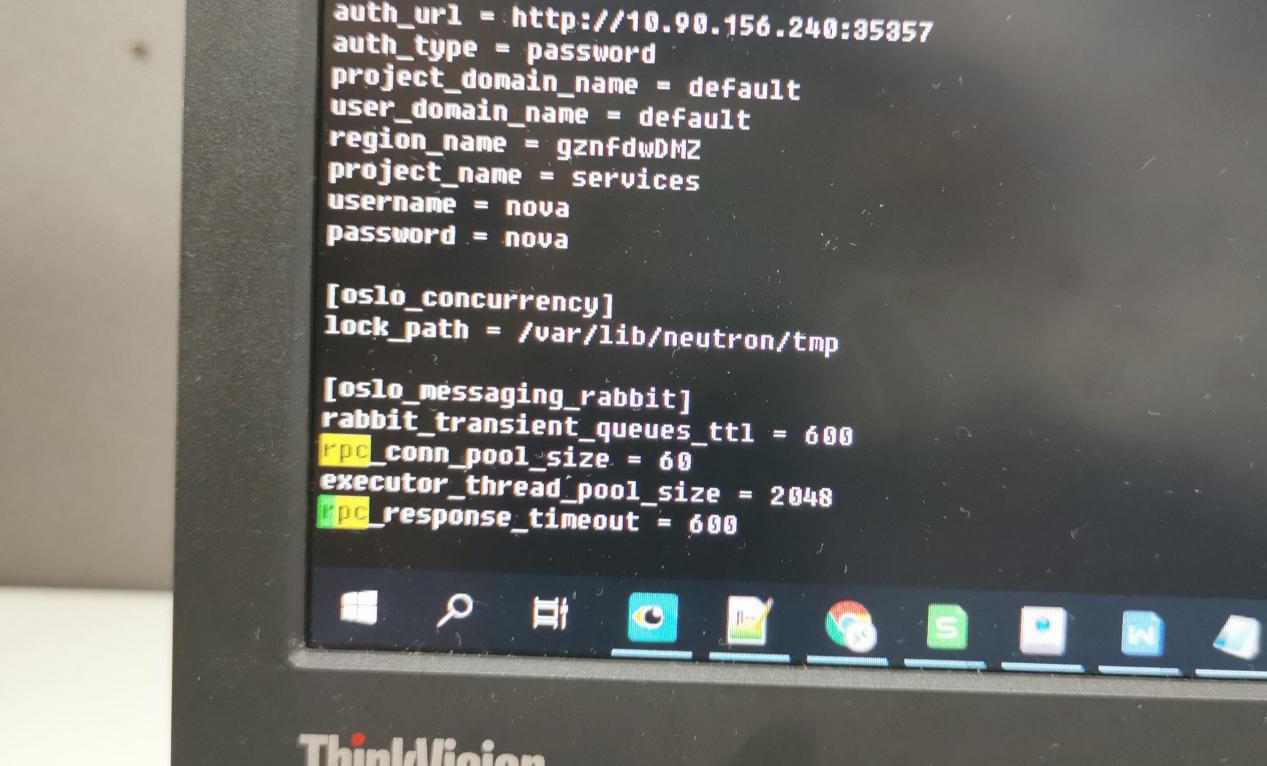
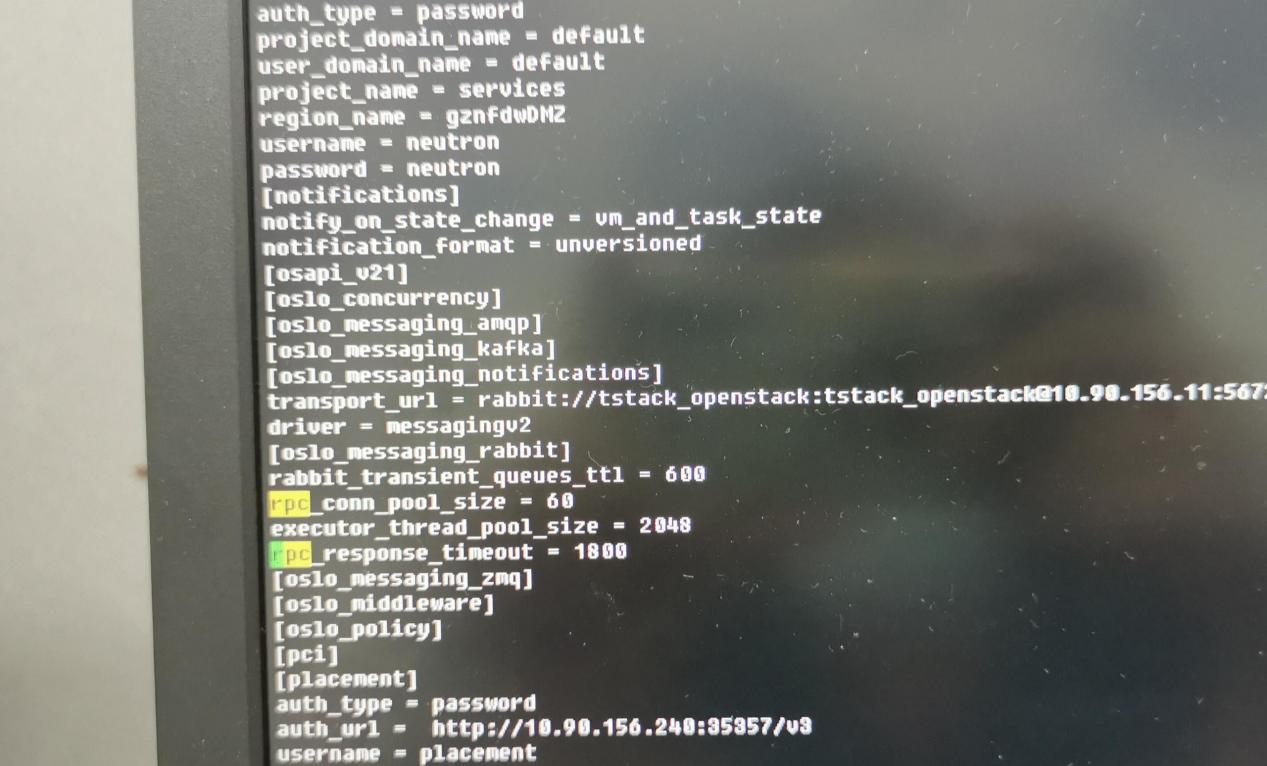
3、然后想的是网络超时问题,让现场检查了下neutron.conf配置文件中的rpc_response_timeout配置。结果是优化了的,默认60,他们配置的600
- 让现场检查下nova manager和schduler等相关日志。在schduler日志中提示无法指定调度策略,但是想了下有迁移成功的虚拟机,应该和这个发现没啥关系。
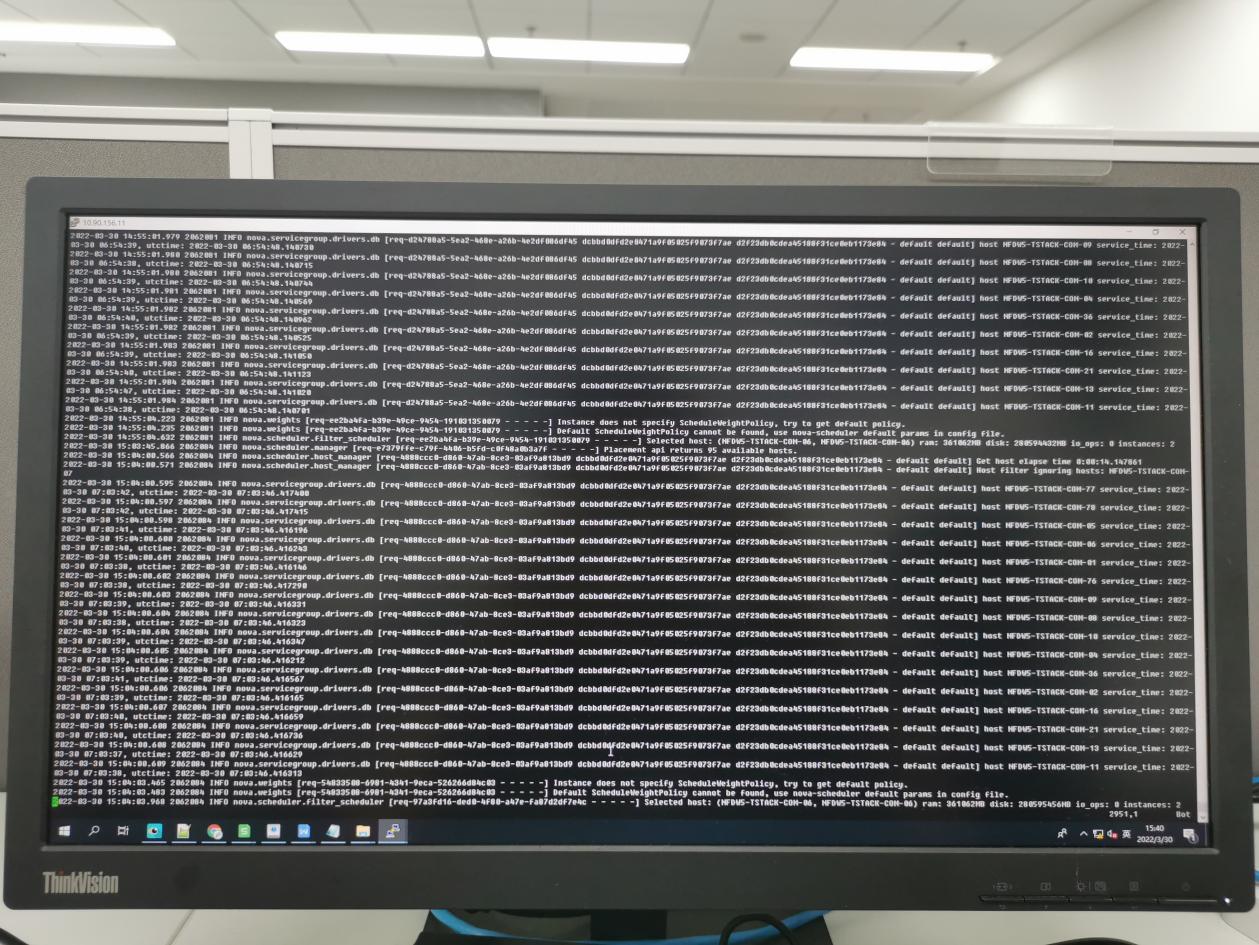
- 让现场看了下源节点和目标节点的nova-compute服务,发现是没问题的。
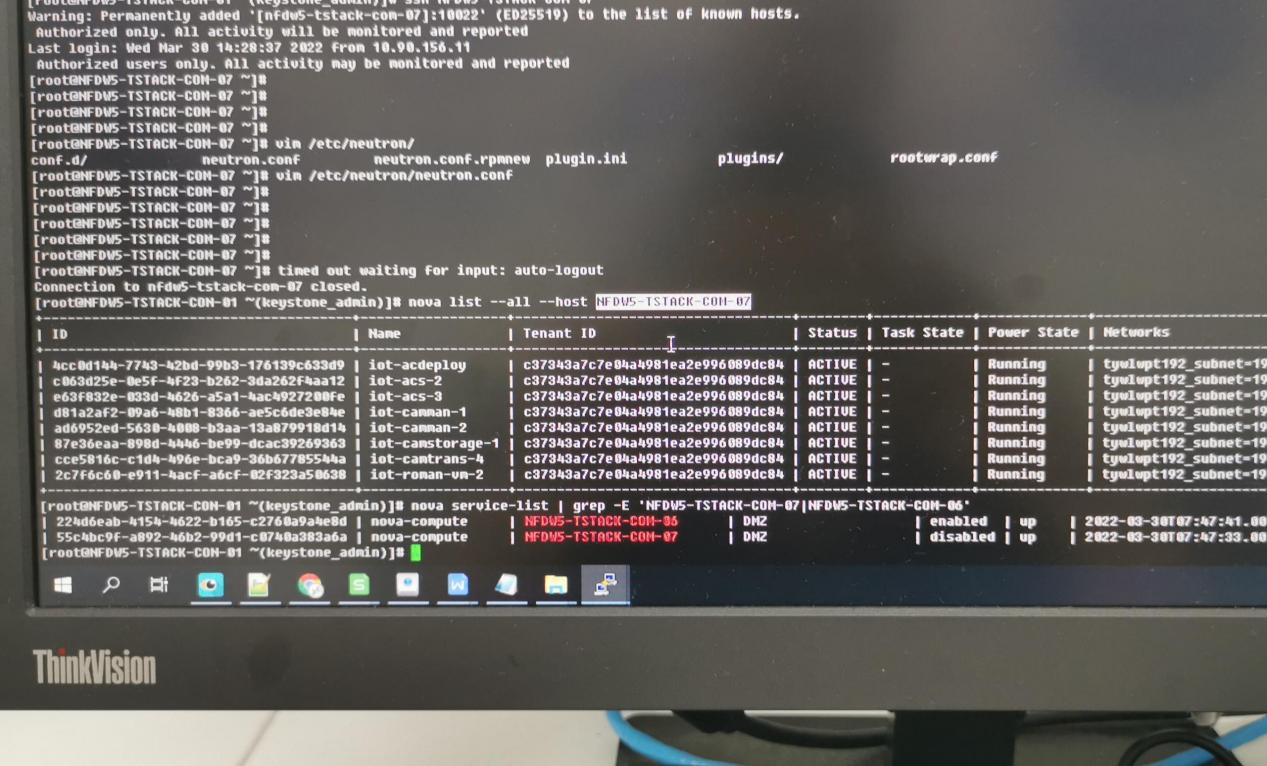
- 目前的思路还是得围绕超时走,消息队列没问题,那就有可能是网络超时。让现场去看看neutron相关的日志。结果neutron日志没有报错。
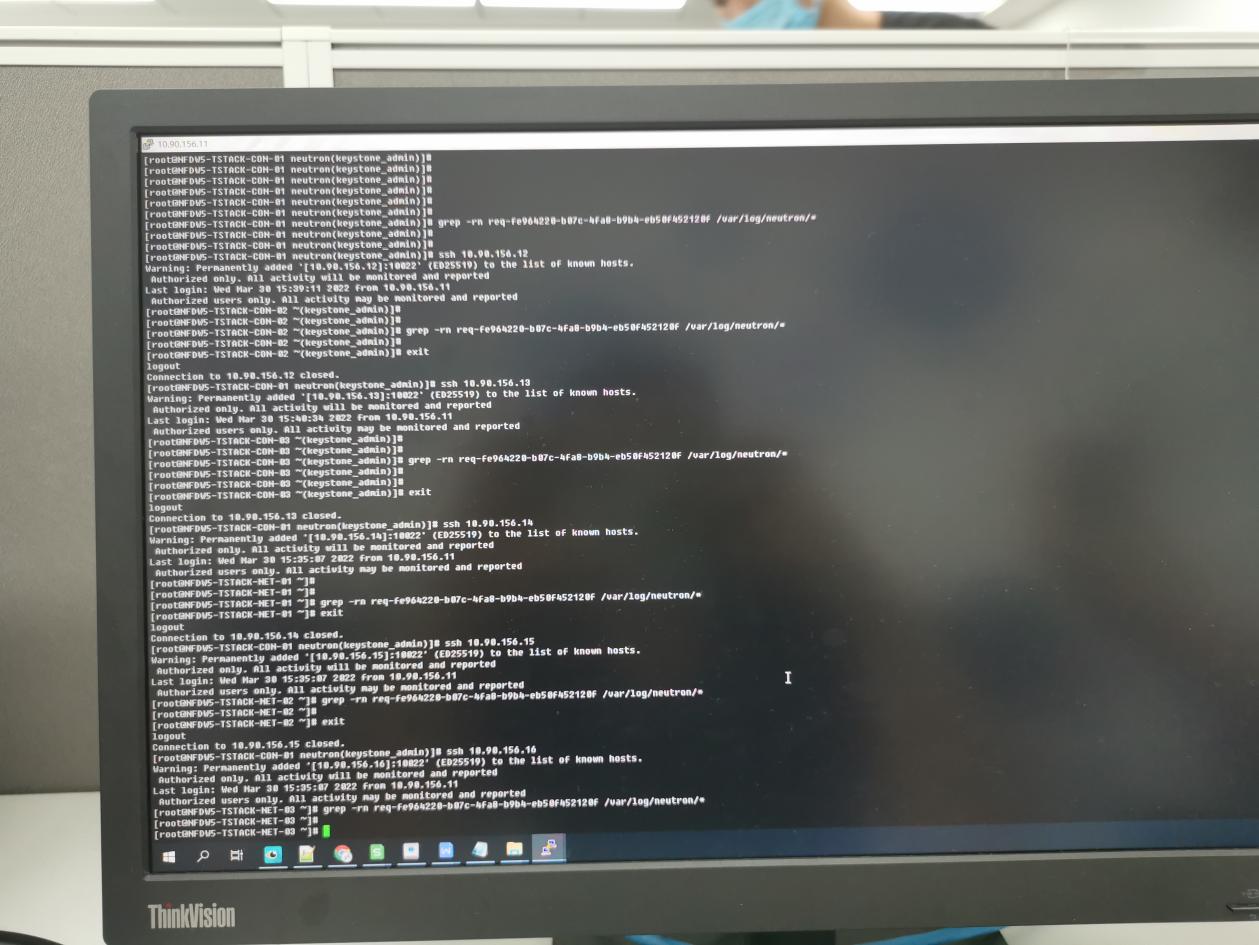
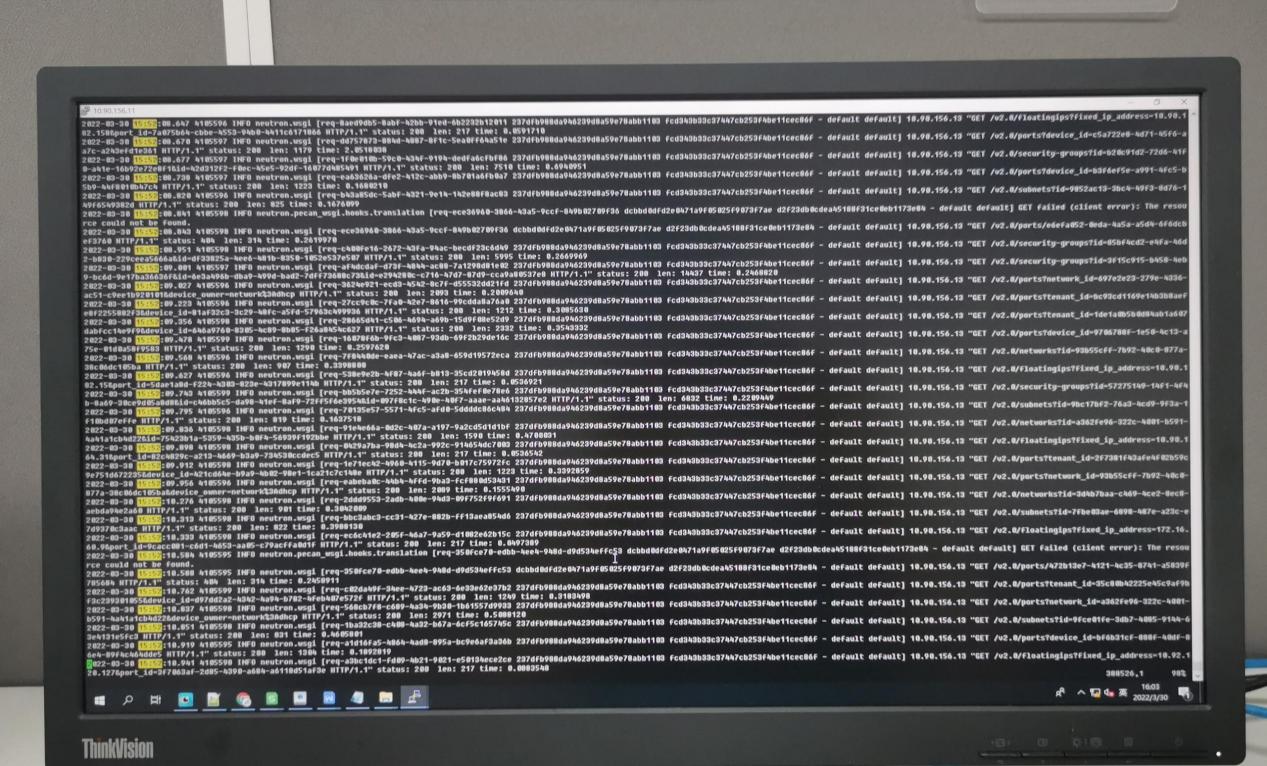
- 让现场将计算节点的neutron.conf配置文件中的超时时间改长一点,然后测试还是不行。
8、找现场确认今天迁移成功两台虚拟机前后是否有改动什么配置,现场反馈没有。然后现场测试换一台目标主机再热迁移,发现还是提示超时。
三线排查:
- 根据报错日志,可知是rpc 响应超时

- 检查计算节点的nova 配置文件 DEFAULT 下的rpc_response_timeout 配置的是30,
改为300(现场改成600) 重启nova 服务
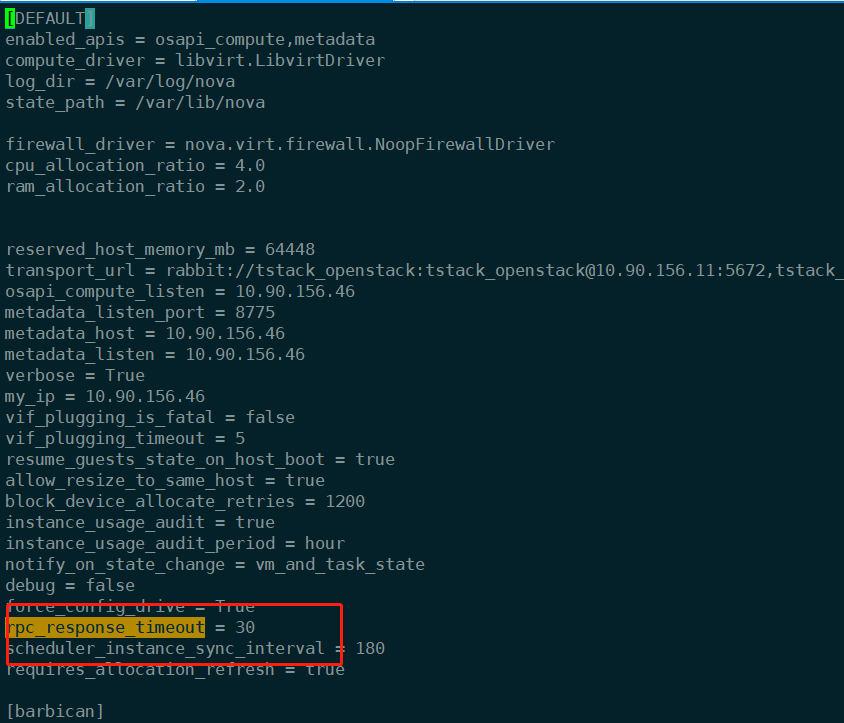
- 再次测试热迁移每次都成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号