江苏人社局ceph命令iops高现象说明
江苏人社局ceph -s命令iops高问题说明
现象描述:
Ceph存储执行健康状态查看命令时,读IOPS偏高,如下图:
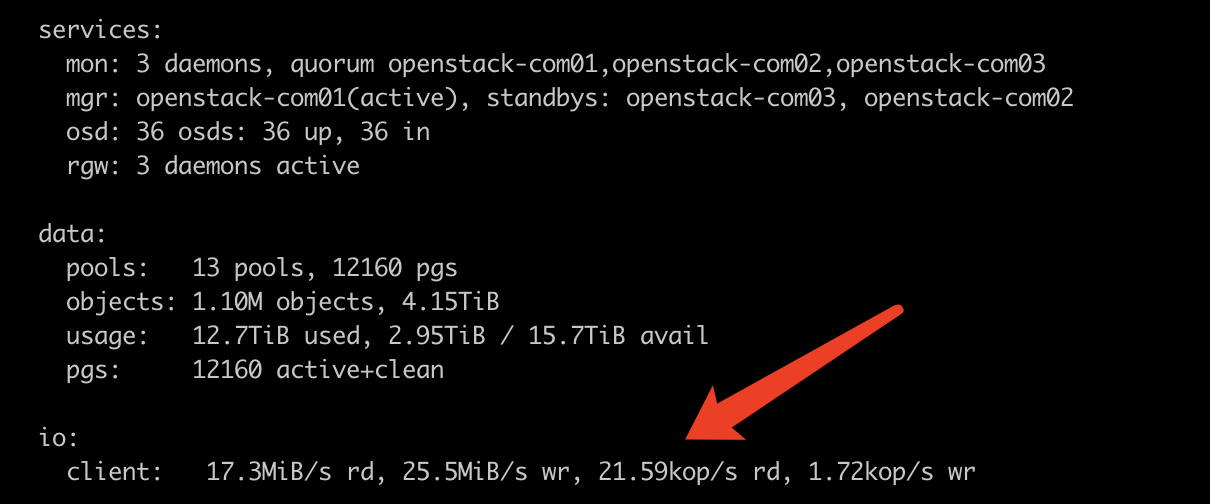
现象说明:
ceph -s 命令看到的读iops是通过pg io读取计数器来获得的,一般有如下io操作会使计数器数值增大:
- 数据读取
- stat原数据读取
- getxattr原数据读取等
查看一个osd上的所有pg iops发现有个别pg io读取计数器数值很大,这些pg都为基础云镜像卷元数据所在。
现在虚拟机秒起的原理为:
- 上传镜像时创建镜像卷
- 以镜像卷做快照
- 快照克隆新的卷
- 以新卷启动虚拟机,新卷进行读写操作时,操作的数据源分为三部分:
- 新卷本来有的数据直接读写新卷
- 新卷没有的数据从快照拷贝到新卷进行读写操作
- 新卷与快照都没有的数据从原始镜像卷拷贝数据进行读写操作
如果原始镜像卷的快照或者源卷读取数据时,原始镜像卷的pg io读取计数器会被放大。测试发现一个虚拟机卷上初次写操作在集群中为7个读5个写,以该镜像启动的虚拟机越多,io操作也越多。
Ceph集群对IO的处理方式也会使IO操作增多, 例如虚拟机写一个4K的数据,有2K在Ceph的4M对象A上,有2K在Ceph的4M对象B上,这时一个业务IO写入Ceph上为2个IO。
Ceph集群IO统计以集群IO为纬度,包括业务IO与集群本身产生的IO。
监控云数据与ceph命令数据取样对比
kubectl exec -it mysql-0 -- mysql -ptstack_monitor \
-hproxysql-proxysql-cluste -A cloud
SELECT t1.uuid
, IF(t2.disk_usage = 0, 0, IF(t2.disk_usage = -1, 0, IFNULL(t2.disk_usage, 0))) AS disk_usage
, IF(t2.disk_total = 0, 0, IF(t2.disk_total = -1, 0, IFNULL(t2.disk_total, 0))) AS disk_total
, t2.io_read, t2.io_write
FROM server_info_ex t1
LEFT JOIN (
SELECT server_performance.uuid
, SUM(IF(index_id = 5, value, NULL)) AS disk_usage
, ROUND(SUM(IF(index_id = 10, value, NULL)) / 1024) AS disk_total
, SUM(IF(index_id = 3, value, NULL)) AS io_read
, SUM(IF(index_id = 4, value, NULL)) AS io_write
FROM server_performance
WHERE server_performance.sample_time >= UNIX_TIMESTAMP(NOW() - INTERVAL 300 SECOND)
GROUP BY server_performance.uuid
) t2
ON t1.uuid = t2.uuid
WHERE t1.category = 'Virtual'
AND t2.io_read IS NOT NULL
AND t2.io_write IS NOT NULL
ORDER BY t2.io_read DESC;
20201024 17:33
项目 | 读IOPS | 写IOPS |
监控云虚拟机合计 | 49 | 1289 |
ceph -s命令显示 | 1280 | 1690 |
Top 10 读

Top 10 写

20201024 19:58
项目 | 读IOPS | 写IOPS |
监控云虚拟机合计 | 4 | 1627 |
ceph -s命令显示 | 2710 | 2230 |
Top 10 读

TOP10 写
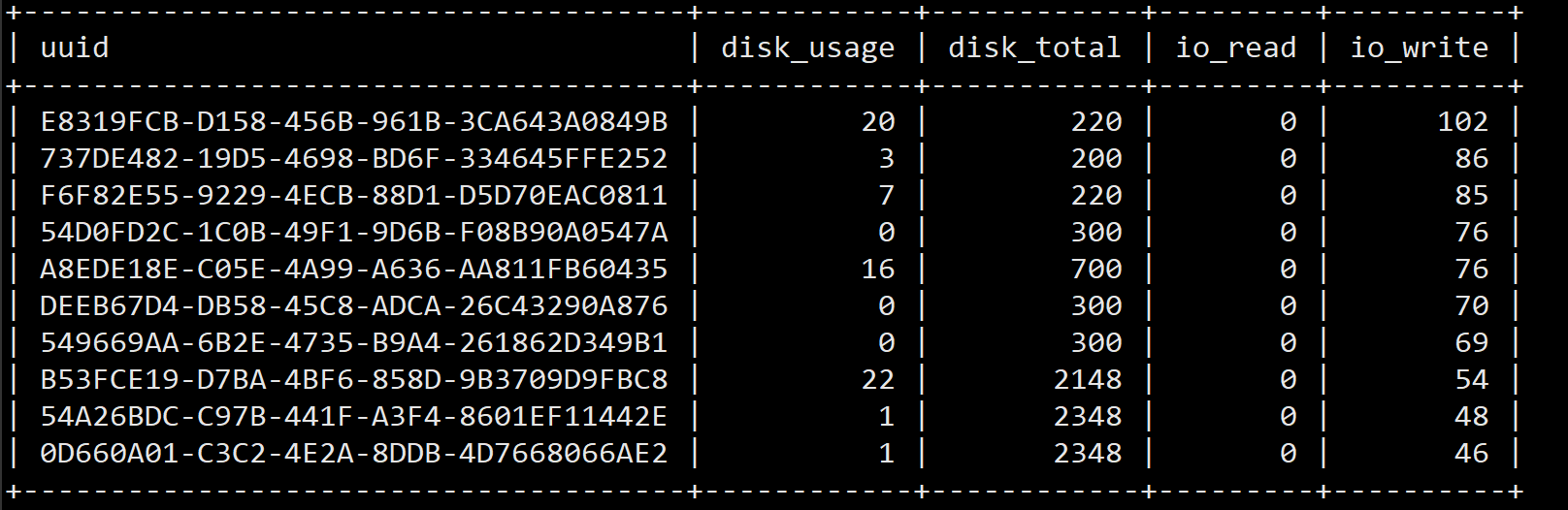
20201024 22:04
项目 | 读IOPS | 写IOPS |
监控云虚拟机合计 | 1 | 1624 |
ceph -s命令显示 | 875 | 3100 |
Top 10 读
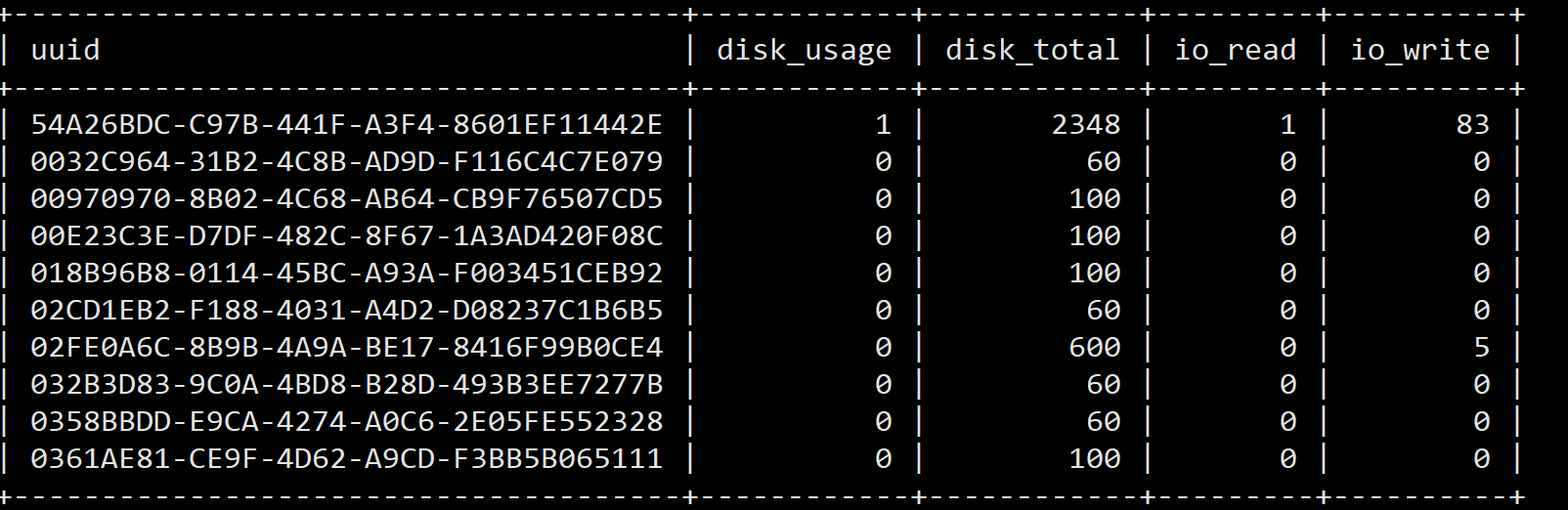
Top 10 写
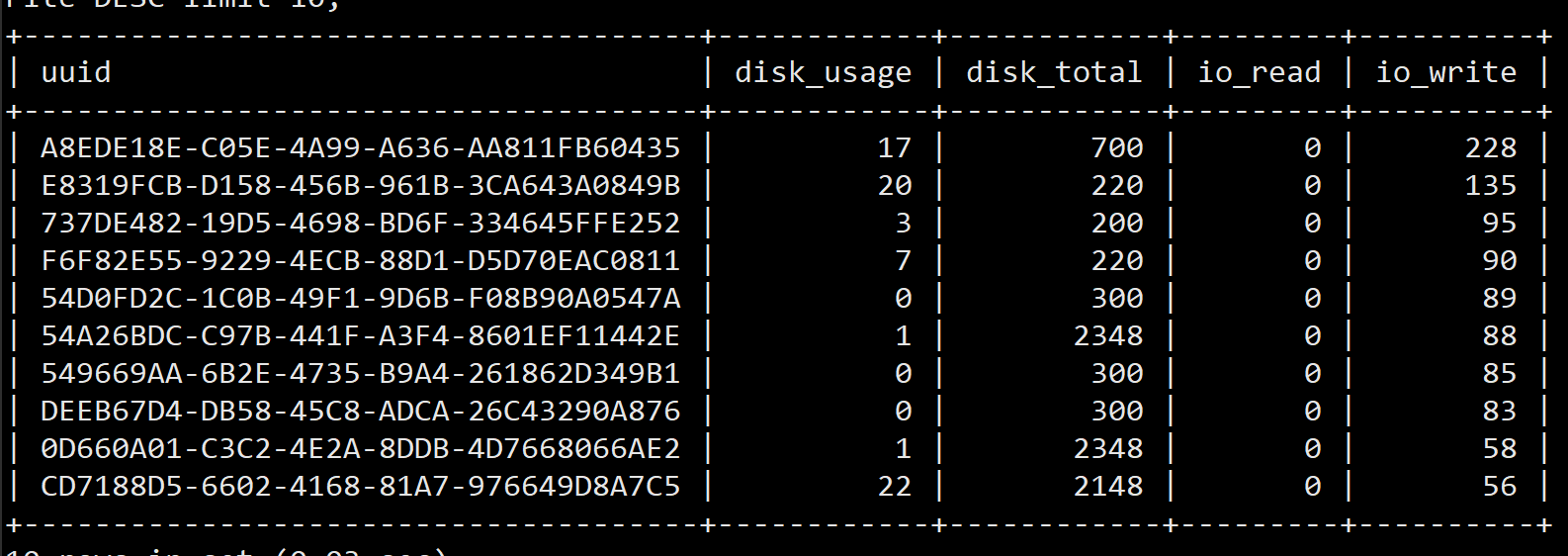
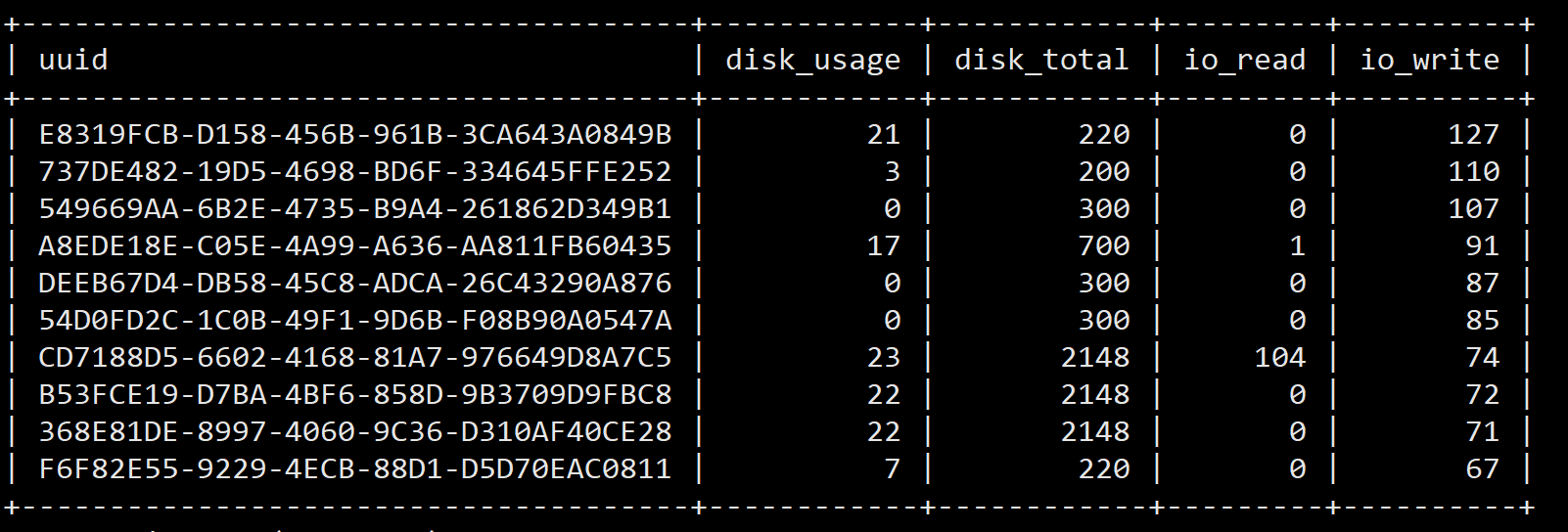
20201024 15:25
项目 | 读IOPS | 写IOPS |
监控云虚拟机合计 | 107 | 1864 |
ceph -s命令显示 | 4040 | 3910 |
Top 10 读
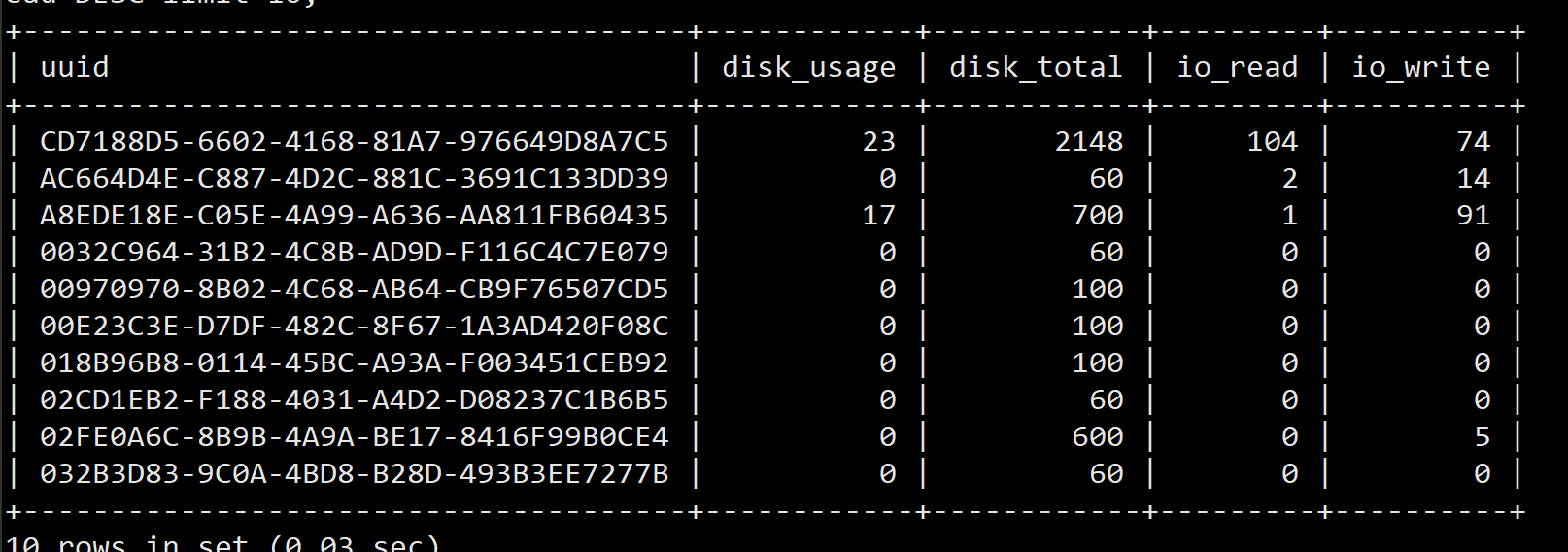
Top 10 写

 浙公网安备 33010602011771号
浙公网安备 33010602011771号