k8s集群故障后中间件恢复
k8s集群故障后中间件恢复
k8s集群恢复之后,mysql、rabbitmq、redis中间件的集群状态无法自愈,需要手动修复。
mysql组复制恢复
mysql集群会只有一个主节点在线,通过启动其他节点,其他节点同步数据会出现事务日志不一致的情况,如图:


修复方法:
需要--清空从节点数据,从主节点恢复所有数据
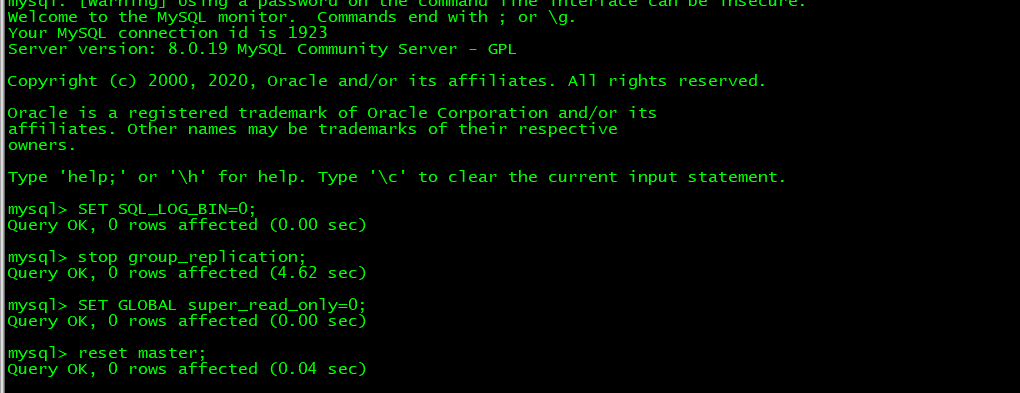
kubectl exec -it mysql-standalone-1 bash
mysql -uroot -ptest
SET SQL_LOG_BIN=0;
stop group_replication;
SET GLOBAL super_read_only=0;
reset master;
从主节点导出数据:
kubectl exec -it mysql-standalone-0 -- mysqldump -ptest -q -Q --default-character-set=utf8 --all-databases --single-transaction --routines --events >sip.sql
编辑sql删除前面几行至如下位置
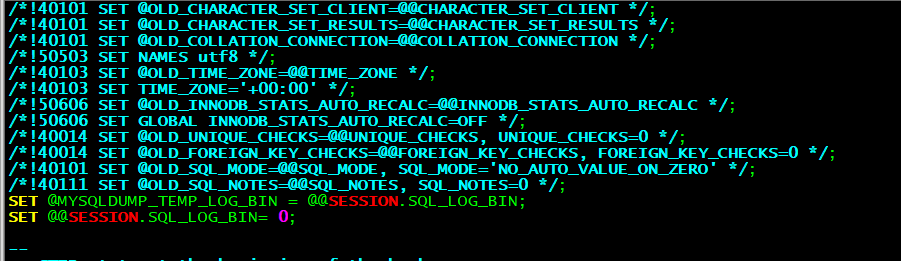
从节点操作:
导入数据
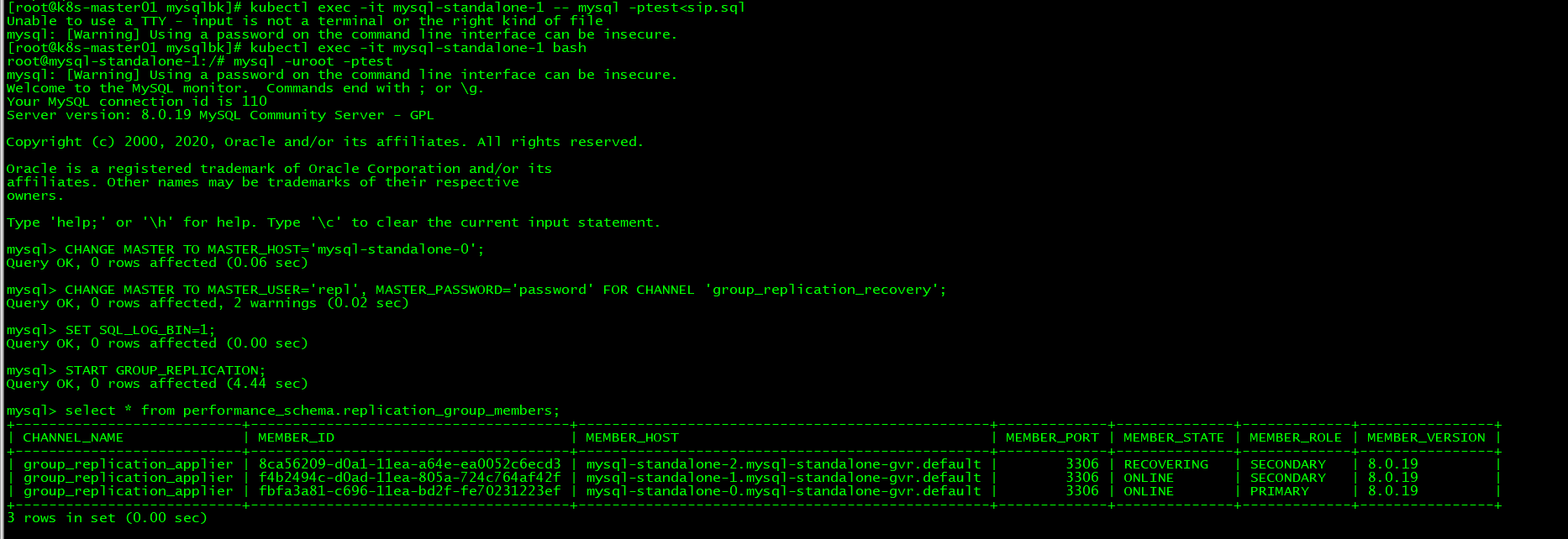
kubectl exec -it mysql-standalone-1 -- mysql -ptest<sip.sql
CHANGE MASTER TO MASTER_HOST='mysql-standalone-0';
CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='password' FOR CHANNEL 'group_replication_recovery';
SET SQL_LOG_BIN=1;
START GROUP_REPLICATION;
select * from performance_schema.replication_group_members;
再对mysql-standalone-2节点进行同样操作最后恢复集群:

Rabbitmq集群恢复
Rabbitmq集群无法启动,会一直卡在0/1 runing的状态。
此时需要删除rabbitmq对应pod里面/var/lib/rabbitmq/目录下的数据,让pod自动去重新初始化队列信息。
/var/lib/rabbitmq/对应挂载的数据卷为rbd
也可以通过pv查找到对应的rbd,然后进入到rbd挂载目录下进行删除操作。
以rabbitmq-0为例,查看rabbitmq-0运行的节点:
kubectl get po -o wide |grep rabbitmq

找到对应的pv:
kubectl get pv |grep rabbitmq-0

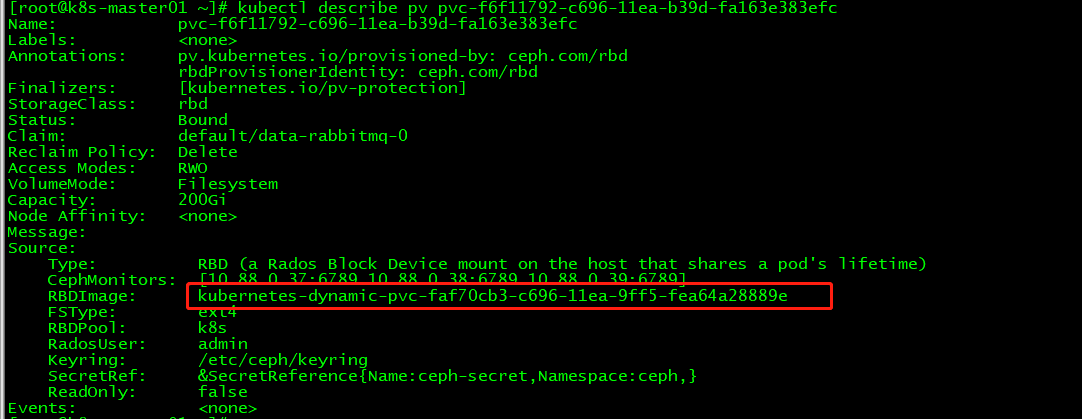
查看pv的详细信息:
kubectl describe pv pvc-f6f11792-c696-11ea-b39d-fa163e383efc
进入到rabbitm-0所在的node节点
查看rbd卷挂载的目录:
df -h |grep kubernetes-dynamic-pvc-faf70cb3-c696-11ea-9ff5-fea64a28889e

可以进入到此目录,进行删除操作,删除前记得备份。

重启rabbitmq-0的pod,让其自动初始化。
接着用同样的方式处理rabbitmq-1、rabbitmq-2
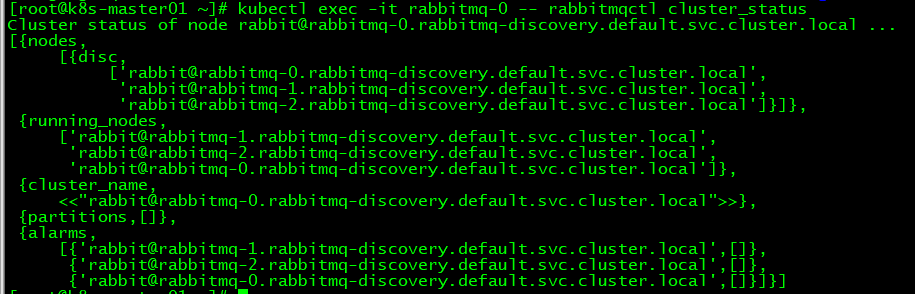
查询最终的rabbitmq集群状态:
kubectl exec -it rabbitmq-0 -- rabbitmqctl cluster_status
Redis集群修复
情况1:redis的6个pod会存在起不来的情况。
查看pod日志有如下报错:

此时需要删除appedonly.aof文件,删除前进行下备份。
由于pv是 基于rbd创建的,需要找到对应的rbd并挂载到本地。
kubectl get pv|grep redis-shard0-0
查看对应的pv名称
kubectl get pv pvc-xxxxxxxxxx -o yaml
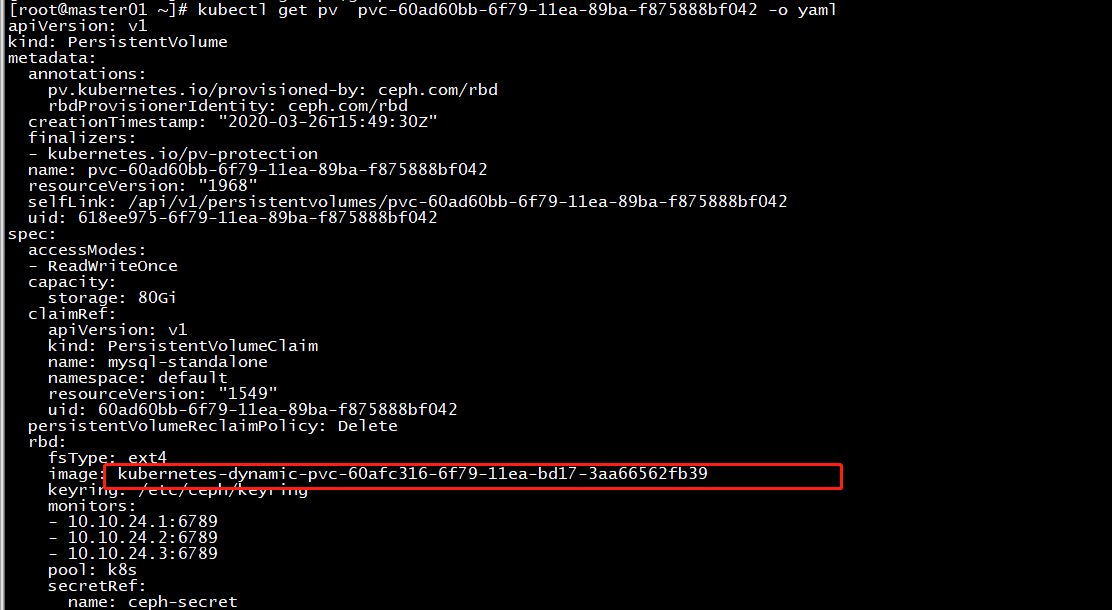
image部分为对应的rbd卷
找到redis-shard0-0所运行的node节点,到该节点上面找到对应的rbd挂载目录,
df -h |grep kubernets-dynamic-pvc-60afc316-6f79-11ea-bd17-3aa66562fb39
cd /var/lib/kubelet/plugins/kubernetes.io/rbd/mounts/kubernets-dynamic-pvc-60afc316-6f79-11ea-bd17-3aa66562fb39
rm appedonly.aof
重启pod。
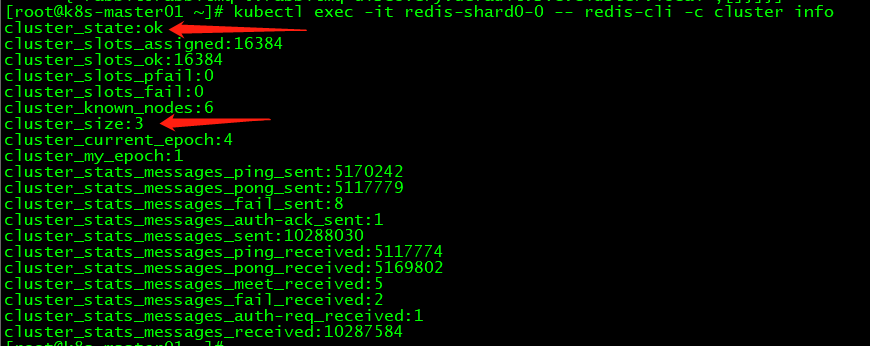
查看集群状态:
kubectl exec -it redis-shard0-0 -- redis-cli -c cluster info
情况2:
Pod运行正常,在是集群状态为fail
kubectl exec -it redis-shard0-0 -- redis-cli -c cluster info
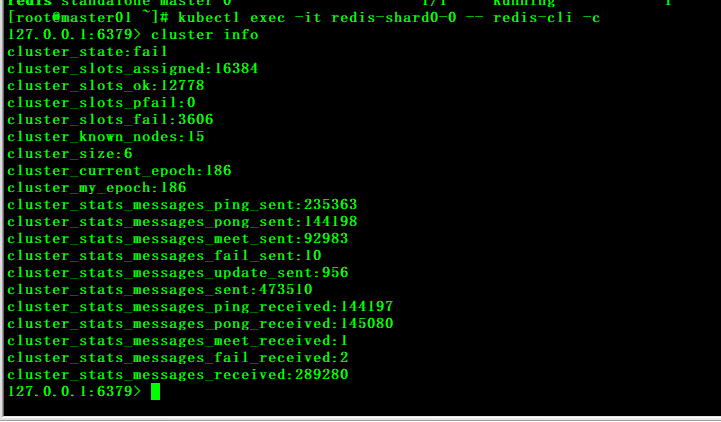
cluster node查看到的redis节点ip信息和实际查看到的redis ip信息没对应。


此时需要手动meet为正确的redis ip。
cluster meet 9.130.2.12 6379 依次meet 6个redis pod的ip
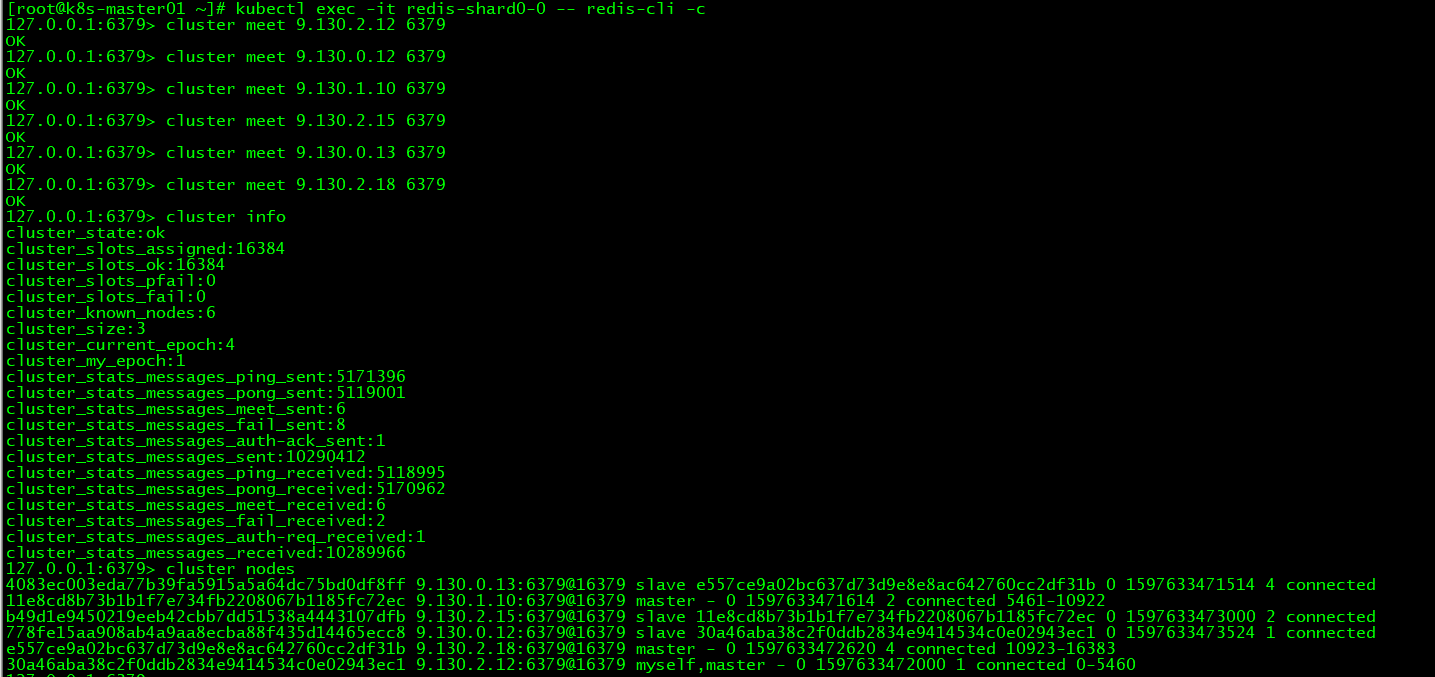
恢复正常状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号